![]()
The Conference on Computer Vision and Pattern Recognition (CVPR) 2022 is taking place June 19-24. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction
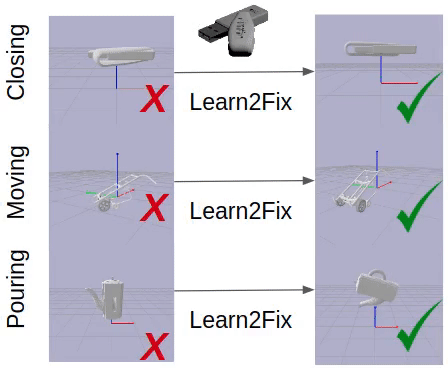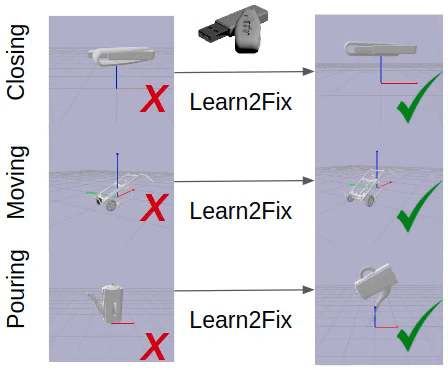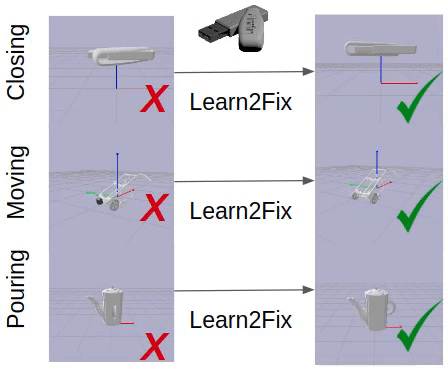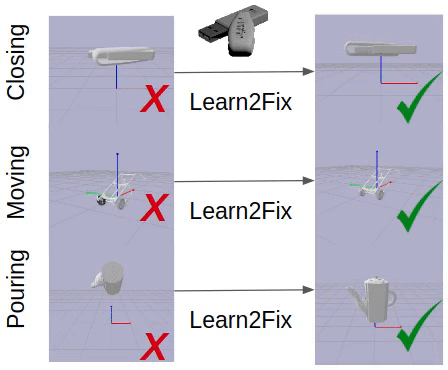
Contact: kaichun@cs.stanford.edu
Links: Paper | Video | Website
Keywords: fixing malfunctional 3d shapes, shape functionality, dynamic model
Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior
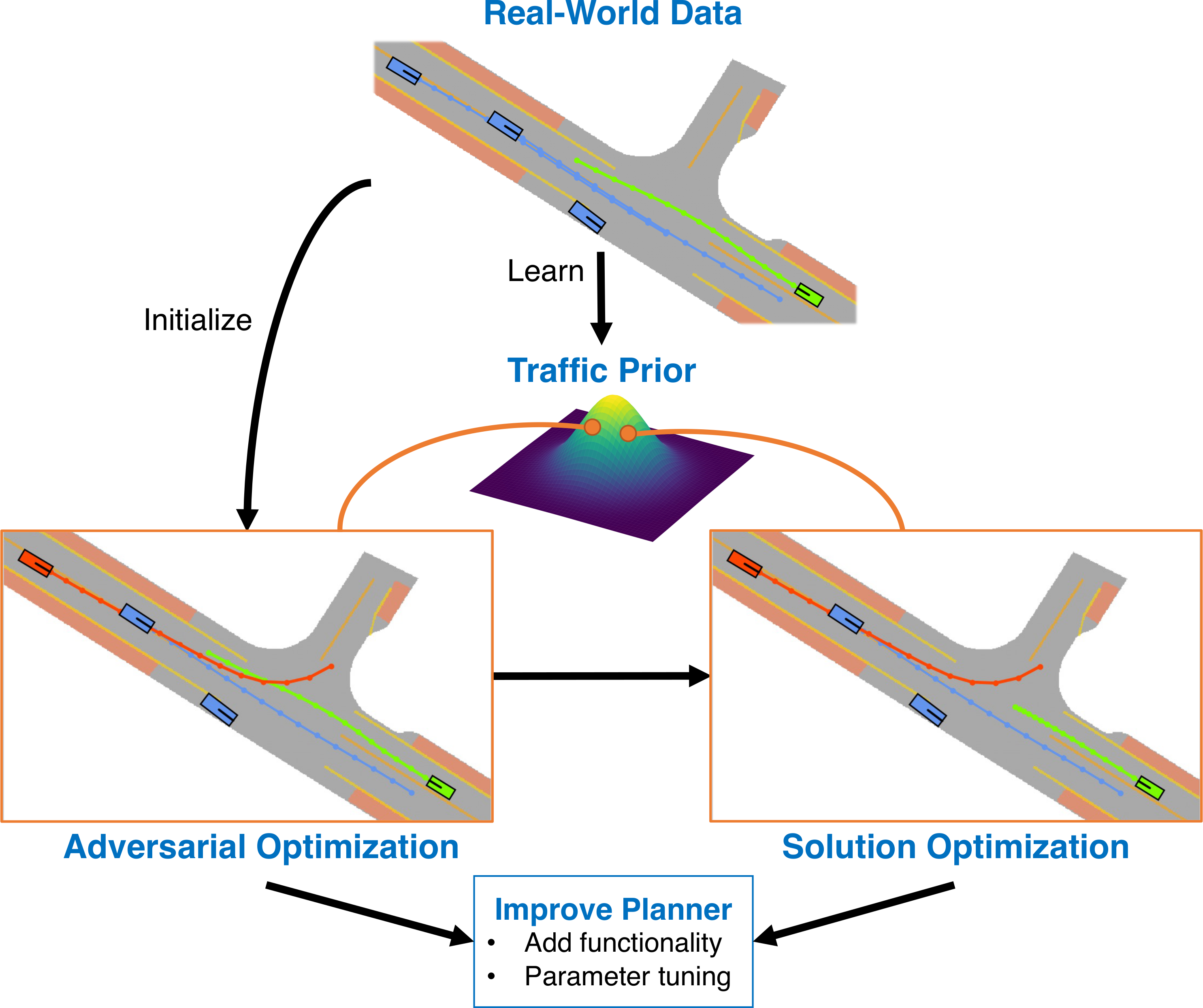
Contact: drempe@stanford.edu
Links: Paper | Website
Keywords: autonomous vehicles, adversarial scenario generation, traffic simulation
Measuring Compositional Consistency for Video Question Answering
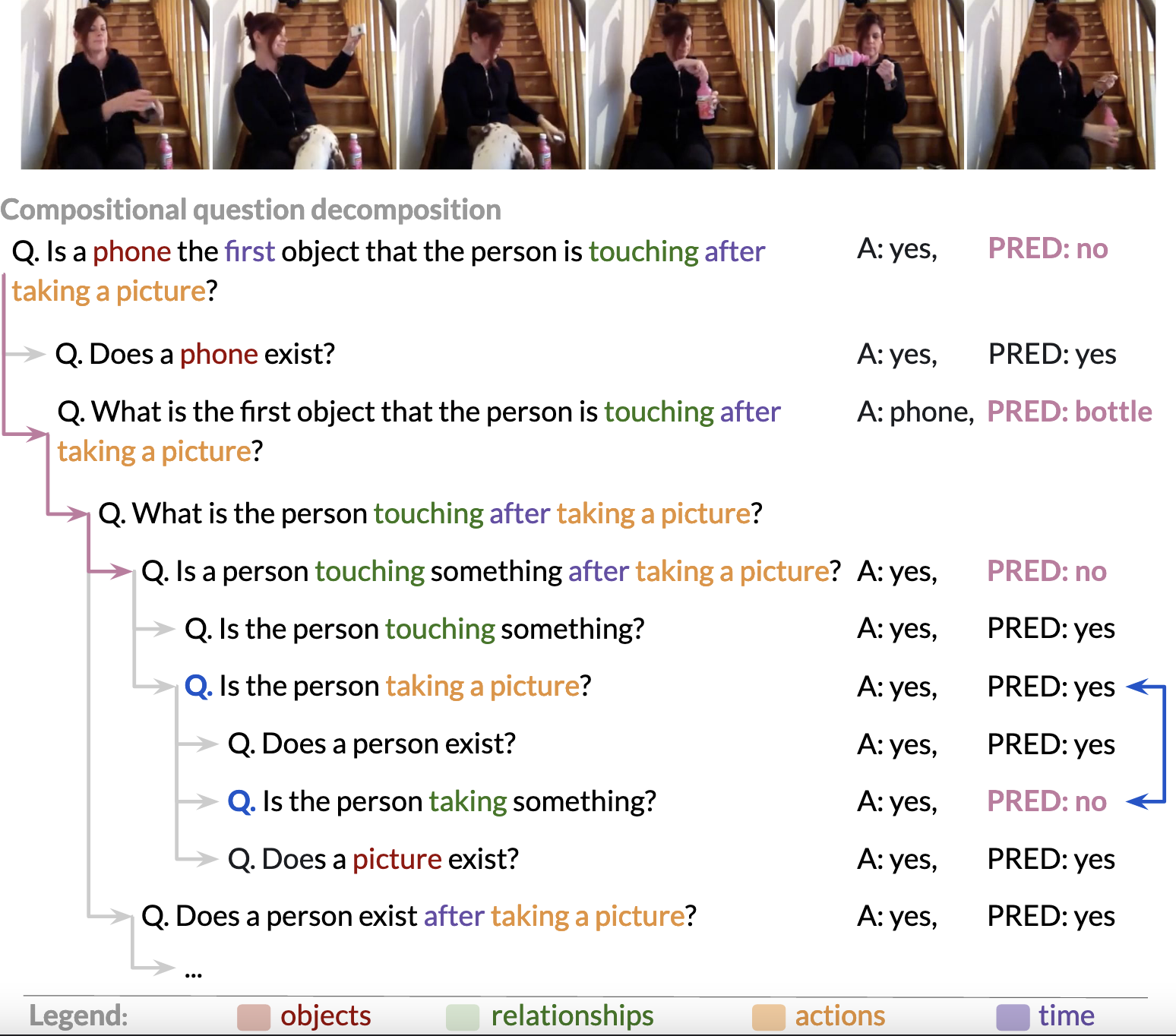
Contact: momergul@alumni.stanford.edu
Links: Paper | Video | Website
Keywords: compositionality, video question answering, evaluation, dataset, metrics
Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning
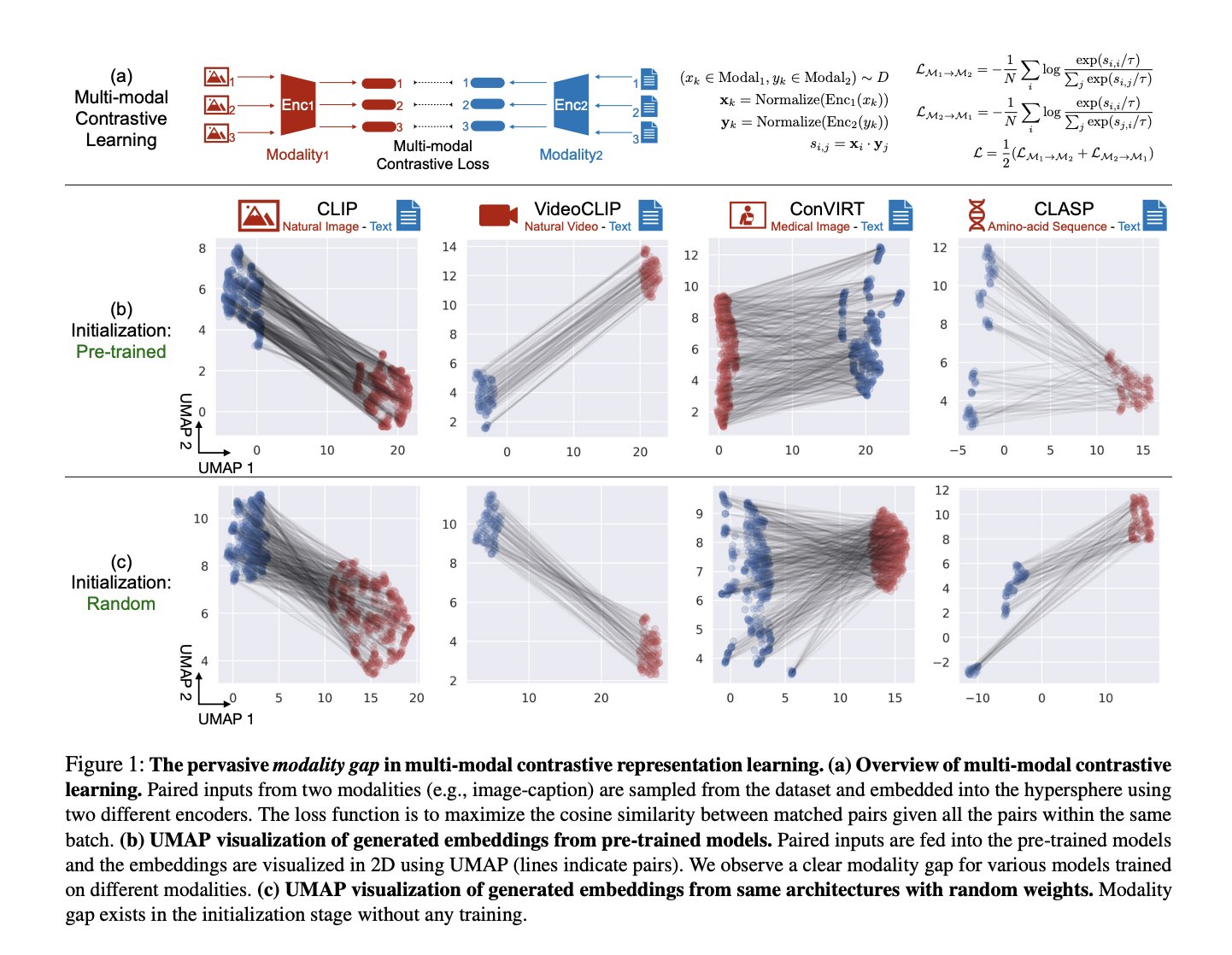
Contact: yuhuiz@stanford.edu
Links: Paper | Website
Keywords: multi-modal representation learning, contrastive representation learning, cone effect, modality gap
Multi-Objective Diverse Human Motion Prediction with Knowledge Distillation
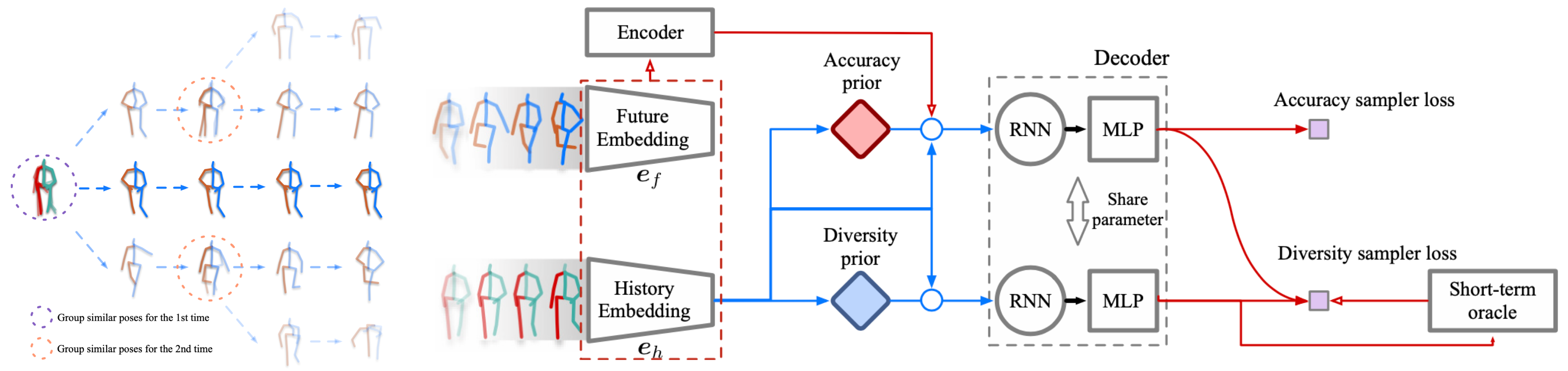
Contact: hengbo_ma@berkeley.edu; jiachen_li@stanford.edu
Award nominations: Oral presentation
Links: Paper
Keywords: human motion prediction, robotics
ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer
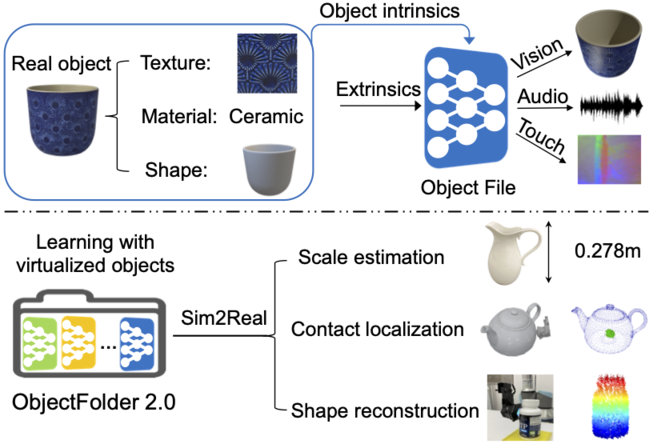
Contact: rhgao@cs.stanford.edu
Links: Paper | Video | Website
Keywords: multisensory, object, dataset, sim2real
PartGlot: Learning Shape Part Segmentation from Language Reference Games
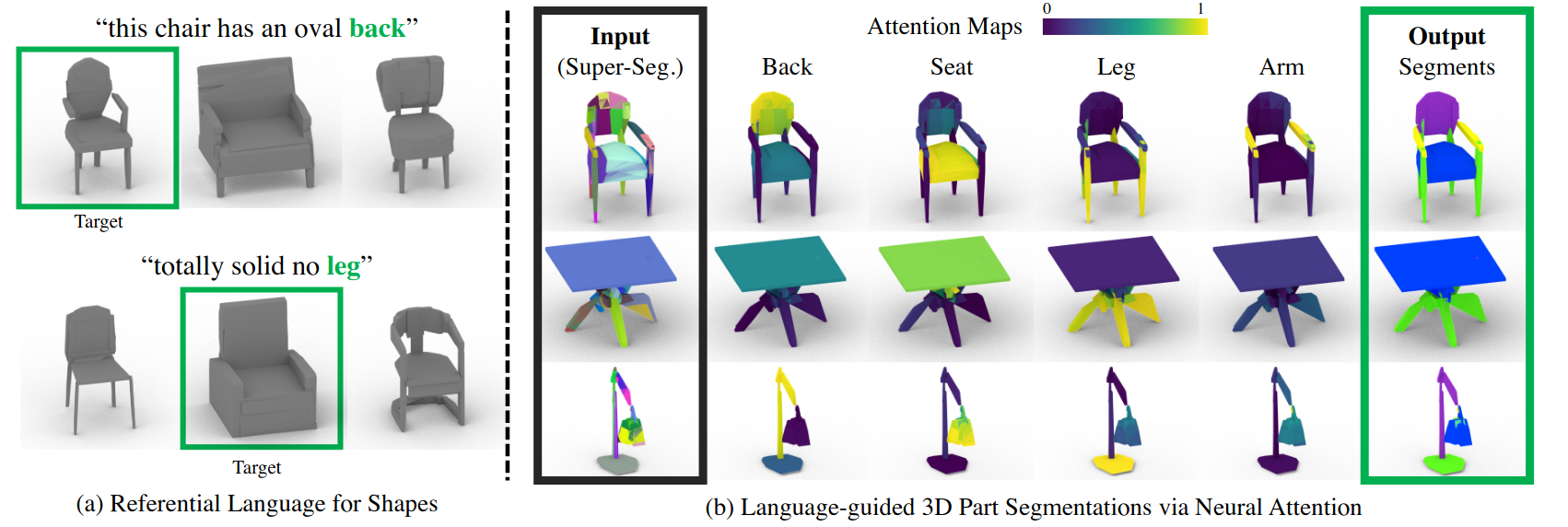
Contact: ianhuang@stanford.edu
Links: Paper | Video | Website
Keywords: language grounding, semantic part segmentation, multimodal learning, natural language processing, 3d vision
Point2Cyl: Reverse Engineering 3D Objects from Point Clouds to Extrusion Cylinders

Contact: mikacuy@stanford.edu
Links: Paper | Video | Website
Keywords: reverse engineering, cad, shape modeling, editing, segmentation, point clouds
Programmatic Concept Learning for Human Motion Description and Synthesis
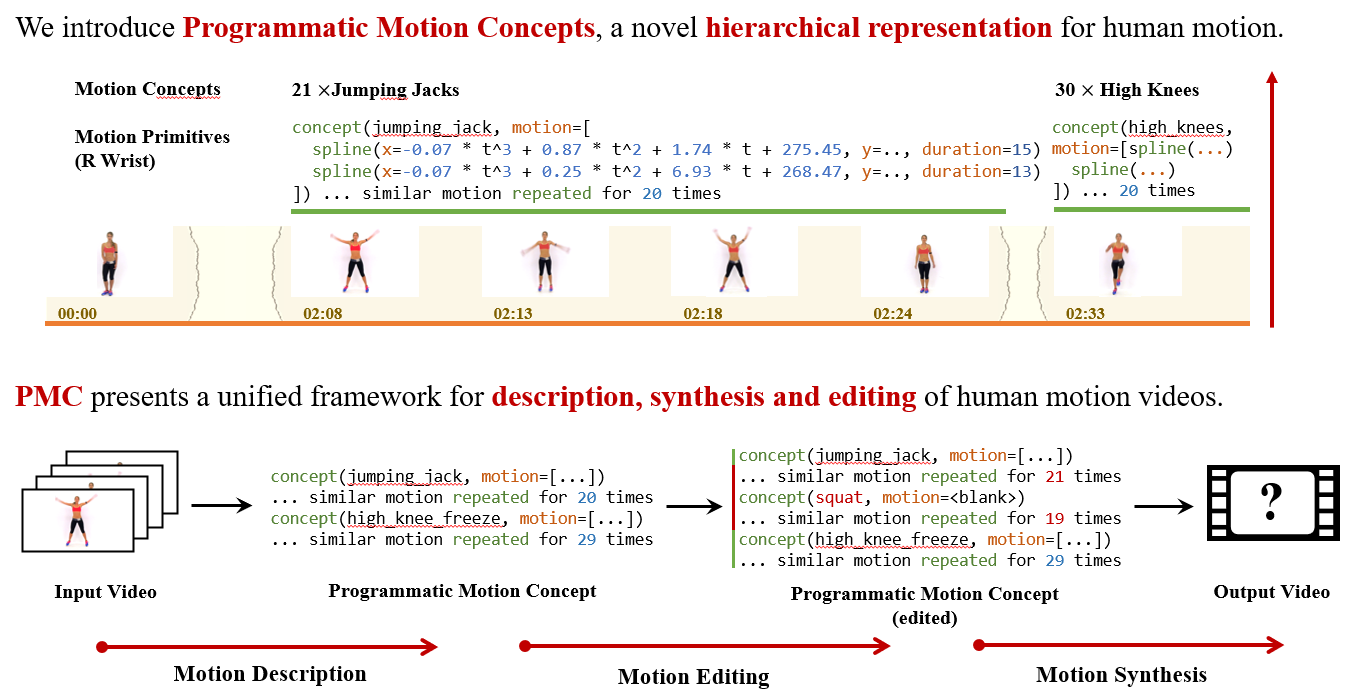
Contact: sumith@cs.stanford.edu
Links: Paper | Website
Keywords: hierarchical representation, human motion, video understanding, video synthesis
Revisiting the “Video” in Video-Language Understanding
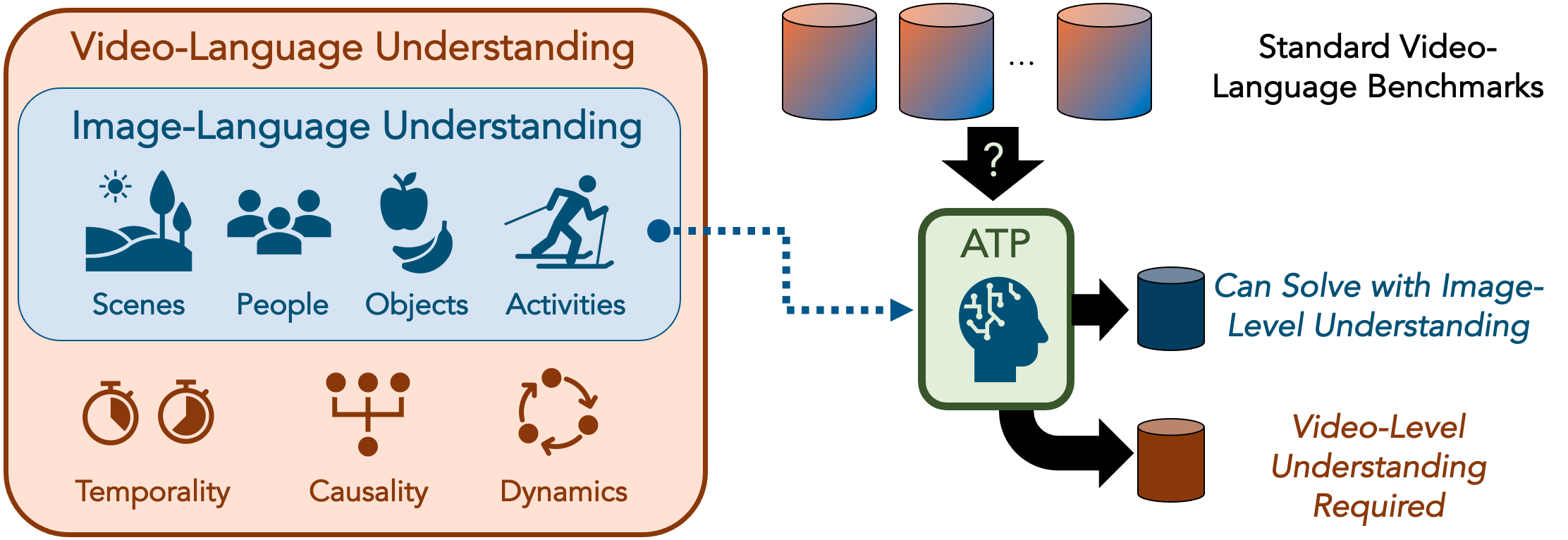
Contact: shyamal@cs.stanford.edu
Award nominations: Oral Presentation
Links: Paper | Website
Keywords: video understanding, vision and language, multimodal
Rotationally Equivariant 3D Object Detection

Contact: koven@cs.stanford.edu
Links: Paper | Video | Website
Keywords: rotation equivariance, detection, object
We look forward to seeing you at CVPR!