Deep learning has revolutionized machine learning. To a first approximation, deeper has been better. However, there is another dimension to scale these models: the size of the input. Even the world’s most impressive models can only process long-form content by dismembering it into isolated, disconnected chunks of a few hundred words to fit their length requirements.
There is a good reason: the ubiquitous Transformer model is an absolute wonder, but it is difficult to scale in sequence length for both performance and quality reasons. For complexity nerds, the Transformer’s runtime is quadratic in the input sequence length. As a result, Transformers get too expensive to train for long inputs. Also, the folklore is that these models can become unstable during training and struggle to learn long-range dependencies. Improvements on both of these dimensions are really exciting–and we aren’t alone thinking this. The great Long Range Arena benchmark from Google was created for exactly these reasons, and it has inspired a great deal of our current work.
The goal of this blog post is to share why we are excited about this seemingly narrow topic of sequence length, which is sometimes only obvious to the subcommunity working on it–and point to some new work123 in these directions.
-
Bridging new capabilities. Impoverished context means that most paragraphs–let alone books, plays, or instruction manuals, are difficult for modern models to understand, or even train on. Longer-range themes may be difficult or even impossible for models to pick up. During training, they can see isolated sentences from a variety of different sources with no connection at all. Hopefully, models with larger contexts could enable higher quality and new capabilities.
- For exciting new paradigms like in-context learning, we might be able to use larger contexts to enable foundation models to learn entirely new skills, just by feeding them an instruction manual!
- We might be able to generate entire stories instead of isolated posts.
- It’s possible that longer sequences could lead to entirely new skills the way in-context learning has emerged–we can condition on so much more information! In part, we just don’t know–and that’s why it’s exciting!
-
Closing the reality gap. Sequence length is a limiter outside of just text processing. In computer vision, sequence length is intimately related to resolution. Not surprisingly, higher resolution in images can lead to better, more robust insights.
-
The gap between today’s best models and the data we have access to is huge: computer vision is confined to resolutions that are 10 or 100x smaller than the default resolution of pictures from your iPhone or Android–let alone the much higher resolutions available from satellites, and medical imaging. In some ways, our current vision models see the world through thick, foggy glasses–they are amazing, but they might get much better!
-
Multimodal models that mix text and images like DALL-E (2)45 and Imagen6 are some of the most exciting in AI! They can generate remarkable images from text descriptions and have sequence models at their core. What might these models do with even larger context?
-
-
Opening new areas. There are huge application areas like time series, audio, and video where deep learning requires heavy manual hand engineering–or where classical, manual techniques are still preferred. We think a large part is because the data are naturally modeled as sequences of millions of steps, and today’s architectures cannot learn from this data automatically.
- We could enable entirely new training modalities, and we’ve started to work on things like the imaging of the brain (fMRI7 - sequences of high-resolution 3D brain images over time) and much more! What would a foundation model from fMRI data reveal about what we can learn? Can the machine learn directly from our telemetry? Maybe?! Who knows, it’s research.
- IoT devices generate orders of magnitude more data per year than the totality of the internet. Could machines learn in new and unexpected ways from this data? Do these structures transfer across machines?
- We’ve been thinking about observational supervision: as we type and interact with our machines, we generate digital exhaust. Could we learn from interaction at many different time scales to get something exciting?
Pragmatically, we and other groups have observed that new methods for simply increasing the sequence length can already lead to improvements on benchmarks and applications. This has been invaluable to our work.
- One major task is Path-X8: given an image, decide if the image is of a path that is connected or not (at various resolutions and lengths). This task is challenging, and in the first two years of the benchmark, no model did better than random chance!
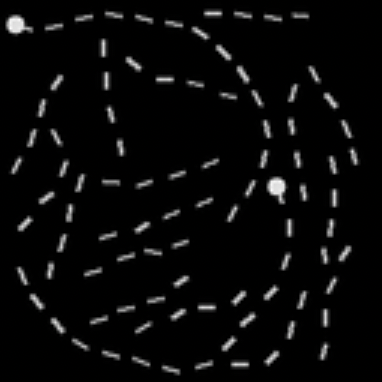
In recent work, Tri Dao and Dan Fu created FlashAttention9, an IO-Aware exact Attention block with associated sparsity ideas that we used to learn from much longer sequences than previously possible [GitHub].
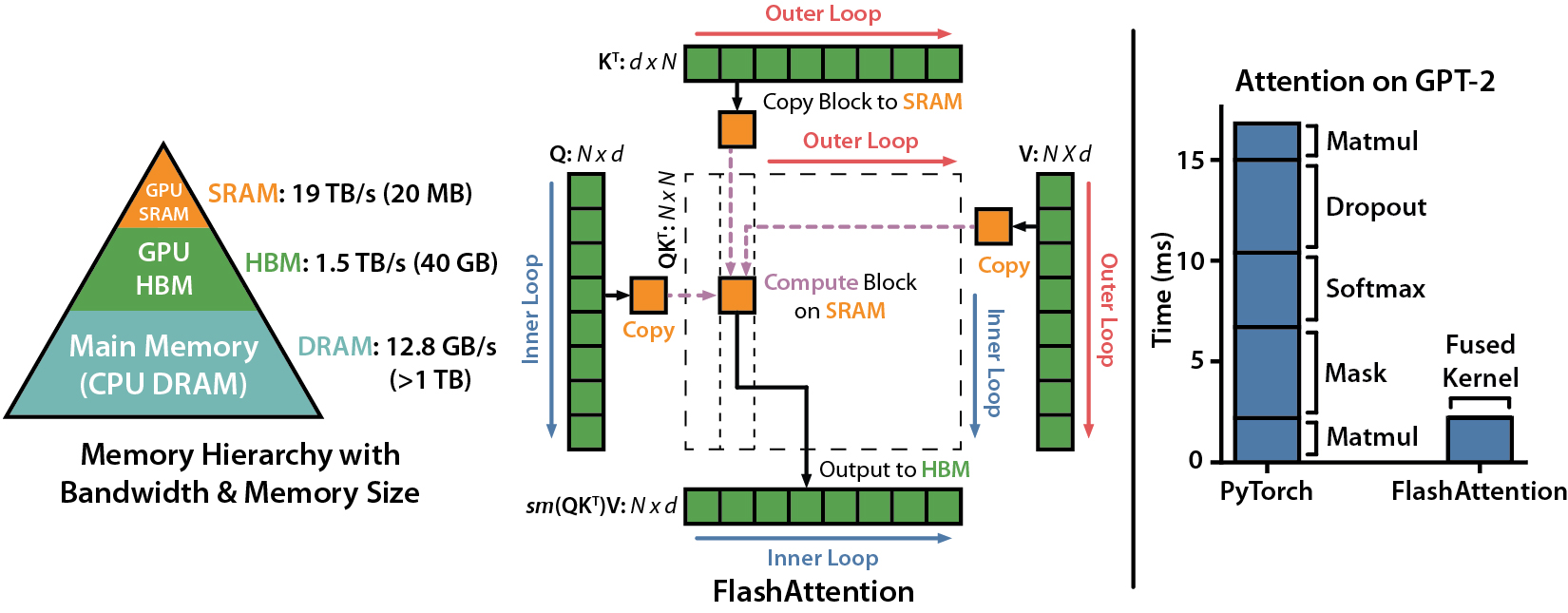
- By fusing the attention kernel and not writing the intermediate attention matrix to GPU memory, FlashAttention reduces runtime by 2-4x and memory footprint by 10-20x. On the Path-X task in the Long Range Arena benchmark, all previous Transformers have had performance at chance (50%). FlashAttention showed that Transformers could perform better than chance (62%) simply by modeling longer sequences.
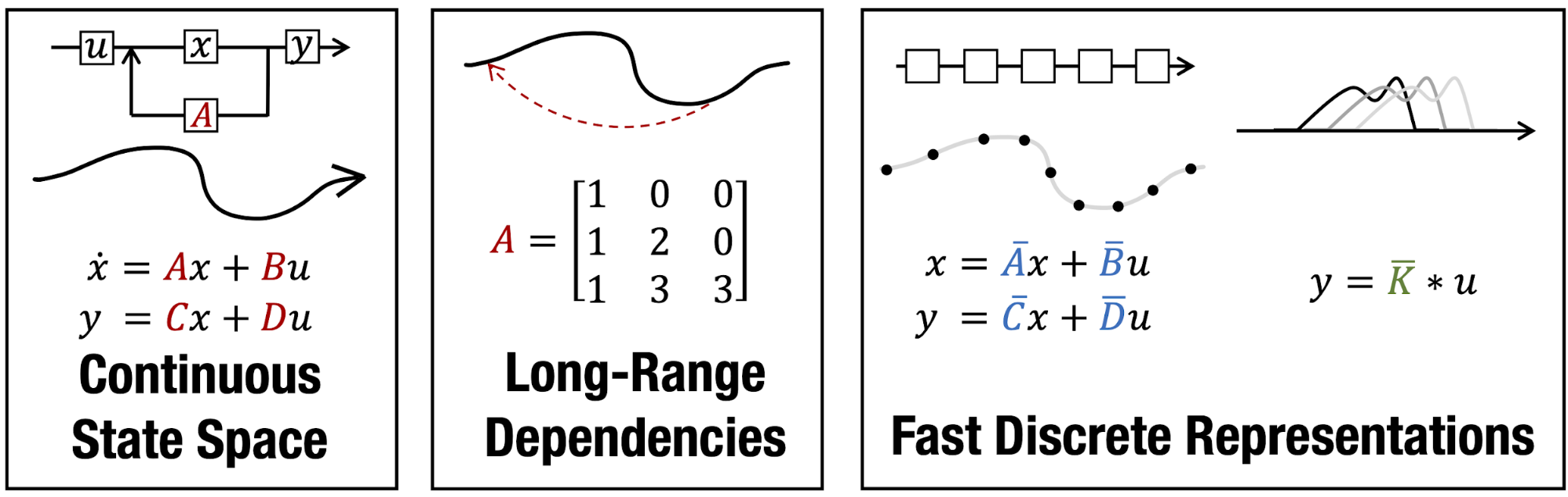
For the past few years, Albert Gu and Karan Goel, along with many others, have been working on a new architecture called S410, which naturally enables training on much longer sequence lengths. S4 is based on classical signal processing ideas (structured state space models).
-
The key insight is that modeling the underlying signal along with careful initialization can lead to much better performance on long sequences. These architectures have shown a remarkable ability – 20%+ better on LRA, and 96% on the Path-X task!
-
See the Github for an overview of this work and applications to music generation, video, and more.
This blog post was intended to share our excitement about this seemingly small issue of sequence length in deep learning models, and why we think it can both supercharge today’s text and image models–and equally importantly, open up entirely new vistas for deep learning. We’ve kept this short in the hopes our transformer friends can give us feedback on how they view these challenges, and where it’s exciting to see more scale. If you have exciting ideas for long-range sequence data, let us know!
- Tri Dao: trid@stanford.edu; Dan Fu: danfu@cs.stanford.edu; Karan Goel: krng@stanford.edu
-
Gu, A., Dao, T., Ermon, S., Rudra, A., & Ré, C. (2020). HiPPO: Recurrent Memory with Optimal Polynomial Projections. Advances in Neural Information Processing Systems, 33, 1474-1487. ↩
-
Gu, A., Johnson, I., Goel, K., Saab, K., Dao, T., Rudra, A., & Ré, C. (2021). Combining Recurrent, Convolutional, and Continuous-time Models with Linear State Space Layers. Advances in Neural Information Processing Systems, 34. ↩
-
Goel, K., Gu, A., Donahue, C., & Ré, C. (2022). It’s Raw! Audio Generation with State-Space Models. arXiv preprint arXiv:2202.09729. ↩
-
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., … & Sutskever, I. (2021, July). Zero-Shot Text-to-Image Generation. In International Conference on Machine Learning (pp. 8821-8831). PMLR. ↩
-
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv preprint arXiv:2204.06125. ↩
-
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., … & Norouzi, M. (2022). Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv preprint arXiv:2205.11487. ↩
-
Thomas, A. W., Ré, C., & Poldrack, R. A. (2021). Challenges for Cognitive Decoding Using Deep Learning Methods. arXiv preprint arXiv:2108.06896. ↩
-
Tay, Y., Dehghani, M., Abnar, S., Shen, Y., Bahri, D., Pham, P., … & Metzler, D. (2020). Long Range Arena: A Benchmark for Efficient Transformers. arXiv preprint arXiv:2011.04006. ↩
-
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv preprint arXiv:2205.14135. ↩
-
Gu, A., Goel, K., & Ré, C. (2021). Efficiently Modeling Long Sequences with Structured State Spaces. arXiv preprint arXiv:2111.00396. ↩