Artificial intelligence and particularly machine learning have recently demonstrated tremendous achievements, and the future seems brighter still. However, these systems aren’t perfect and there is huge risk when they are deployed in applications where mistakes lead to the loss of human life or of hundreds of millions of dollars. Think of applications like commercial aircraft collision avoidance, financial transactions, or control of massive power generating or chemical manufacturing plants.
In order for society to continue to deploy advanced AI systems in such mission critical applications we need these systems to be verifiable (provably acting in the correct way for a range of inputs), reliable (behaving as expected, even for novel inputs), robust against adversarial attacks (not brittle or vulnerable to noise or specific inputs when deployed), auditable (open to checking their internal state when any given decision is made), explainable (structured so that the data, scenarios, and assumptions that led to a given recommendation are clear), and unbiased (not showing unintended preference towards certain types of actions). This is a lofty set of requirements, without a doubt. Fortunately, some of the world’s best AI researchers are now working on exactly this. At Stanford AI Lab and the larger Stanford research community, these researchers include professors Clark Barrett, David Dill, Chelsea Finn, Mykel Kochenderfer, Anshul Kundaje, Percy Liang, Tengyu Ma, Subhasish Mitra, Marco Pavone, Omer Reingold, Dorsa Sadigh, and James Zou.
In this article, we will take a look at a few examples of current research that are leading the way toward safe and reliable AI. We will see how new techniques allow us to look inside the black box of neural networks, how it is possible to find and remove bias, and how safety in autonomous systems can be assured.
Looking Inside the Black Box of Neural Networks: Verification and Interpretability
While neural networks have played a critical role in recent AI achievements, they are black box function approximators with limited interpretability. They can also fail in the presence of small adversarial perturbations, despite being expected to generalize from finite training data to previously unseen inputs, which makes the robustness of one’s algorithm hard to verify. Let’s take a look at two examples of current research that allow us to examine the inner workings of neural networks. The first example is about verification and the second interpretability.
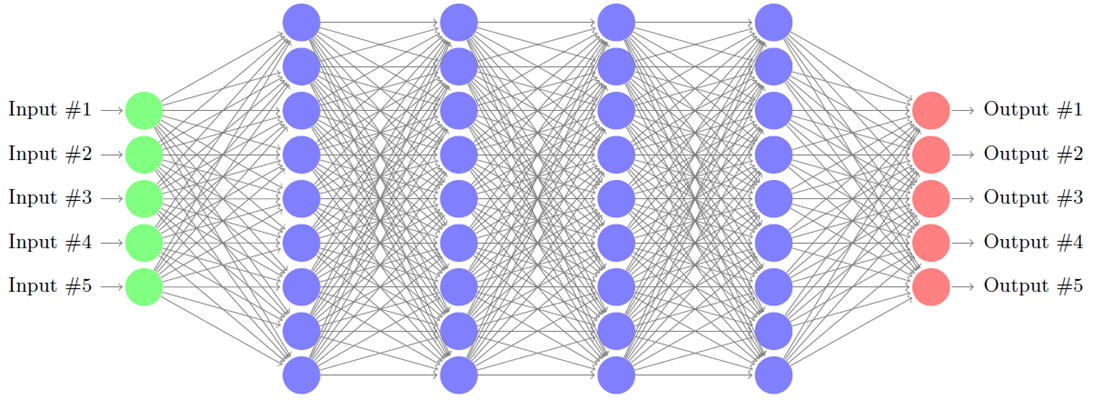
Verification of Deep Neural Networks
We would like to ensure that neural networks will work for every possible set of circumstances, but verification is experimentally beyond the reach of existing tools. Currently, dedicated tools can only handle very small networks, for example a single hidden layer with 10 – 20 hidden nodes. Katz et al. [G. Katz, C. Barrett, D. L. Dill, K. Julian, and M. J. Kochenderfer, “Reluplex: An efficient SMT solver for verifying deep neural networks,” in International Conference on Computer-Aided Verification, 2017.] developed Reluplex, a new algorithm for error-checking neural networks. Reluplex blends linear programming techniques with SMT (satisfiability modulo theories) solving techniques in which neural networks are encoded as linear arithmetic constraints. The key insight is to avoid testing paths that mathematically can never occur, which allows testing neural networks that are orders of magnitude larger than was previously possible, for example, a fully connected neural network with 8 layers and 300 nodes each.
Reluplex makes it possible to prove properties of networks over a range of inputs. It enables measuring formal adversarial robustness, or in other words the minimum or threshold adversarial signal that can produce spurious results. See Raghunathan et al. [A. Raghunathan, J. Steinhardt, and P. Liang, “Certified Defenses against Adversarial Examples,” in International Conference on Learning Representations, 2018.] for another example of evaluating robustness to adversarial examples.
Reluplex Case Study: Unmanned Aircraft Collision Avoidance
Reluplex was applied to test a neural network fit to an early prototype of ACAS Xu [K. Julian, M. J. Kochenderfer, and M. P. Owen, “Deep neural network compression for aircraft collision avoidance systems,” Journal of Guidance, Control, and Dynamics, 2018.], an airborne collision-avoidance system for drones. As shown in the figure, the system considers two drones: your own drone, “Ownship,” which is controlled by the ACAS Xu software, and another drone, “Intruder,” which we observe. The goal is to guide Ownship and avoid collisions with Intruder.
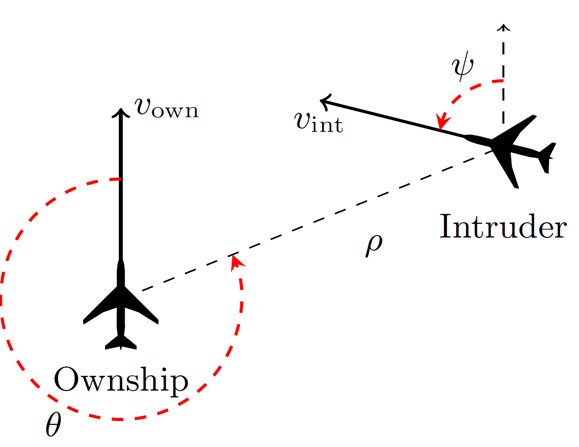
In one scenario the researchers were asked to show that if Intruder approaches from the left, then the system would advise Ownship to turn strong right. The researchers proved in 1.5 hours using modest compute resources that the network functions correctly for this scenario in every case. A more complicated second scenario considered a situation where Intruder and Ownship are at different altitudes and additionally where Ownship had received a previous advisory to turn weak left. This illustrates the sort of complexity that can arise in such systems. In this case the network should advise COC (clear of conflict, that is, maintain current course) or weak left. The researchers found a counter example in 11 hours using modest compute resources, and the counter example was later corrected in a different network.
Understanding Model Predictions
Can we explain why neural networks make specific predictions? That is the question that Koh and Liang asked [Understanding black-box predictions via influence functions. Pang Wei Koh, Percy Liang. International Conference on Machine Learning (ICML), 2017.]. This is important when deep learning models are used to decide who gets financial loans or health insurance, and many other applications. When AI systems are explainable they are likely to enable better decisions, the development of improved models, and greater discovery, trust, and oversight. The researchers’ approach is to identify the training data points most responsible for a given prediction. Their key insight is to use “influence functions” calculated by mathematically answering the question “how would the model’s predictions change if we did not have this training point?”.

In the above figure, if the pixels of the white dog are responsible for activating the part of the neural network that identifies this image as a dog then the system is behaving reasonably. On the other hand, if the pixels of the ocean waves are generating the output “dog” then this system becomes brittle — other images with only ocean waves could be incorrectly classified as a “dog.” By being able to correctly identify that the pixels of the white dog have a higher influence than the ocean waves, our system can become more robust to noisy inputs.
Finding and Removing Bias
It’s no surprise that AI systems reflect societal bias. Zou and Schiebinger [Design AI so that it’s fair. James Zou and Londa Schiebinger. Nature (2018).] point out that bias can result from two sources: training data and algorithms. Bias in training data can result from some groups being over- or under-represented in a dataset, and the solution is to investigate how training data is curated. Algorithms can amplify bias because a typical machine learning program tries to maximize the overall prediction accuracy across the training data, so the solution is to investigate how bias is propagated and amplified.
Geometry Captures Semantics
Bolukbasi et al. [Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai. Neural Information Processing Systems (NIPS 2016).] used word pairings to examine bias. For example, consider the question, man is to king as woman is to what? Any five year-old can answer this question. Man is to king as woman is to queen. The researchers answered word pairing questions using the Word2Vec model trained using the Google News corpus. Every word is mapped to a point in a high-dimensional space. The relation between words is shown by the vector connecting those words.

A two-dimensional projection of the high-dimensional space of word embeddings, in which the vector connecting woman to queen is the same length and direction as the vector connecting man to king.
The Google News corpus is huge and many of its authors are professional journalists, so we might naively expect a model trained using this data to be free of bias. However with a moment’s reflection we realize that this model will probably reflect society’s biases, since it is after all trained on data generated by our society. That’s exactly what we will see.
Let’s take a look at another word pairing: he is to brother as she is to what? Again, any five year-old can answer that he is to brother as she is to sister. We are off to a good start, but as you can see in the below figure, things start to go downhill rapidly. Some of the word pairings display bias (he is to doctor as she is to nurse, he is to computer programmer as she is to homemaker) and some are downright weird (she is to pregnancy as he is to kidney stone).
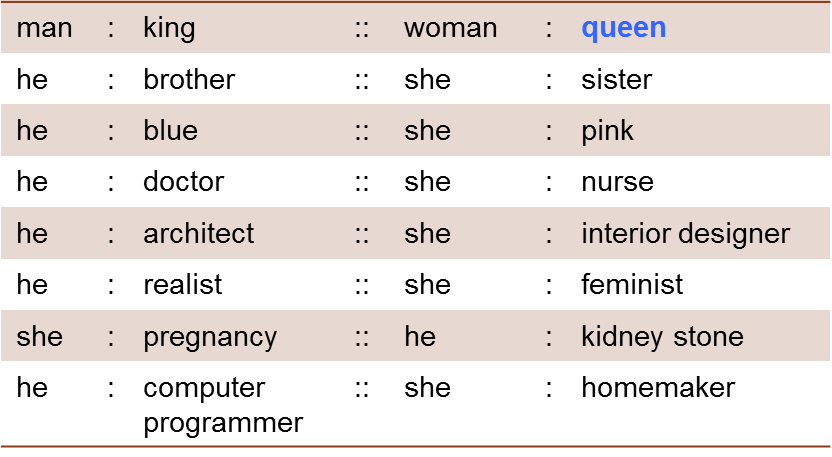
The researchers found that it is possible to reduce gender bias by removing gender stereotypes such as the association between receptionist and female while preserving desired associations such as that between queen and female. In order to do this they distinguish between gender-specific words that are associated with gender by definition, like brother, sister, businessman, and businesswoman, and the remaining gender-neutral words. Geometrically, they identified two orthogonal dimensions — the difference between the embeddings of the words he and she and a direction that captures gender neutrality. Their debiasing algorithm removes the gender pair associations for gender-neutral words by collapsing the gender-neutral direction. This sort of debiasing is used by Google, Twitter, Facebook, Microsoft, and others.
Achieving Fairness Without Demographics
Hashimoto et al. [Fairness without demographics in repeated loss minimization. Tatsunori B. Hashimoto, Megha Srivastava, Hongseok Namkoong, Percy Liang. International Conference on Machine Learning (ICML), 2018.] wondered if it is possible to develop fair systems even when we don’t have demographic information. The problem is that small groups have a low representation in minimizing the average training loss. Group labels may be unavailable due to cost or privacy reasons, or the protected group may not be identified or known. The current approach, known as empirical risk minimization, can make the problem worse by shrinking the minority group in the input data over time. The goal is to protect all groups—even minority groups—even without demographic labels. The solution developed by these researchers is an approach based on “distributionally robust optimization” which minimizes loss over all groups.
The goal of distributionally robust optimization is to control the worst-case risks over all groups. Intuitively, the approach is to upweight examples with high loss. Groups suffering high loss are over-represented relative to the original mixture which adjusts the model to have fewer high loss examples, making it unlikely that some groups will have disproportionately high error. Intuitively, data points relating to minority groups would be the ones to suffer from high loss by default, so this approach can help avoid that.
Assuring Safe Autonomous Systems
Robots, drones, and autonomous vehicles need algorithms for safe learning, planning, and control. As these systems explore their environment, they have to deal with uncertainty about what their own actions will do, dynamic surroundings, and unpredictable human interactions. In each of the following two examples, the researchers model the autonomous robot and the human as a system.
Data-Driven Probabilistic Modeling for Human-Robot Interactions
Professor Marco Pavone’s research seeks to develop a decision-making and control stack for safe human-robot vehicle interactions in settings where there are multiple distinct courses of action. In this example, the researchers are motivated by the example of traffic weaving at highway on-ramps and off-ramps. Their approach is to first learn multimodal probability distributions over future human actions from a dataset of vehicle interaction samples, and then perform real-time robot policy construction through massively parallel sampling of human responses to candidate robot action sequences [E. Schmerling, K. Leung, W. Vollprecht, and M. Pavone, “Multimodal Probabilistic Model-Based Planning for Human-Robot Interaction,” in Proc. IEEE Conf. on Robotics and Automation, Brisbane, Australia, 2018]. This framework does not place any assumptions on human motivations, which enables the modeling of a wide variety of human driving behaviors. Significantly, the model includes high-level stochastic decision making and low-level safety preserving control. To account for the fact that humans can occasionally defy the robot’s predictions, the framework is augmented with a low-level tracking controller that projects the stochastic planner’s desired trajectory into a set of safety-preserving controls whenever safety is threatened.
Safely Learning a Human’s Internal State
Dorsa Sadigh [Planning for cars that coordinate with people: leveraging effects on human actions for planning and active information gathering over human internal state. Sadigh, D., Landolfi, N., Sastry, S. S., Seshia, S. A., Dragan, A. D. SPRINGER. 2018: 1405–26] and Mykel Kochenderfer are teaching autonomous vehicles to learn the internal state of human drivers. They do this by modeling the interaction between autonomous vehicles and humans as a dynamical system. Of course, there is direct control over the actions of the autonomous vehicle, but these actions affect the human’s actions, so there is also indirect control over the human’s actions.
Imagine you are attempting to change lanes on a crowded highway. You might nudge or move slowly into the new lane from your current lane while observing the reactions of other drivers. If the other driver slows and opens a gap then you continue the lane change, but if the other driver speeds up and blocks you then you return to your lane and try again later. This approach does roughly that, by having the robot maximize its own reward function as it usually does except that this reward function can now directly depend on what the human does in response. Because drivers respond to the actions of other drivers, we have an opportunity to do active information gathering.
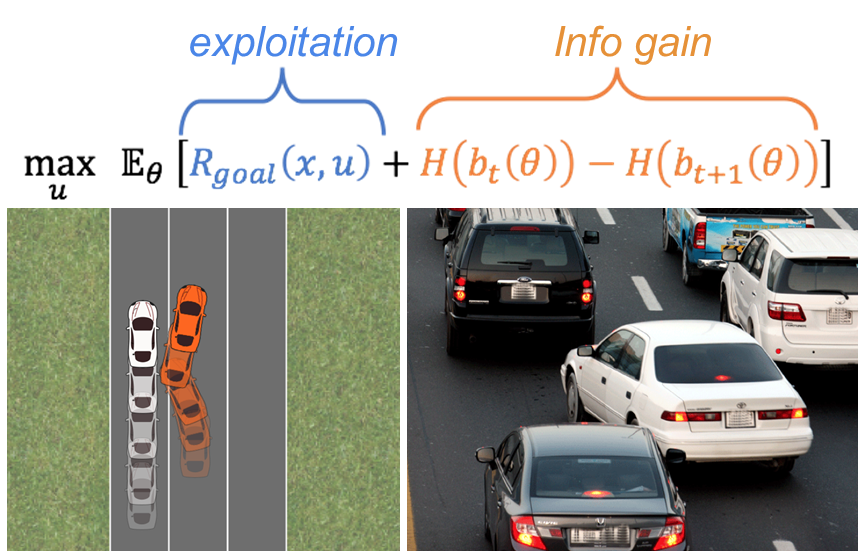
A visual explanation of the approach. The equation states that the robot’s reward function incorporates a tradeoff between reaching its goal and active information gathering. In the left-hand image we see the orange autonomous vehicle nudge the white human vehicle, emulating the human behavior shown in the right hand image.
The Future
In the near future we will enjoy safe and reliable AI systems that are verifiable, auditable, explainable, unbiased, and robust. Research such as the works from the Stanford AI Lab as well as work from other labs is providing the innovative technological solutions that will make this possible. But technical solutions aren’t sufficient; success requires that these solutions are implemented with care and with social awareness to determine what values we want to incorporate in these systems. Recently, we are seeing the rise of human-centered approaches to AI that consider human factors and societal impact. Such approaches will hopefully lead to AI systems that work in ways that are safe, reliable, and reasonable even in unexpected situations with culturally diverse users.
Acknowledgments
Thanks to all of the researchers who allowed their work to be summarized here. Special thanks to Clark Barrett, Mykel Kochenderfer, Percy Liang, Marco Pavone, Dorsa Sadigh, and James Zou.
About the Author
Steve Eglash is Director of Research at the Stanford Institute for Human-Centered Artificial Intelligence (Stanford HAI). Stanford HAI works to advance AI technology and applications, as well as to understand and influence the interaction of AI with society. Steve’s group is responsible for research programs and external partnerships.