The mutual information (MI) between two random variables, such as
stimuli S and neural responses R is defined in terms of their joint
distribution ![]() . When this distribution is known exactly, the MI
can be calculated as
. When this distribution is known exactly, the MI
can be calculated as
![\begin{displaymath}
I(S;R) \equiv I\left[{p(S,R)}\right] \equiv
\sum_{s,r} p(s,r) \log \left({\frac{p(s,r)}{p(s)p(r)}}\right)
\end{displaymath}](img3.png) |
(1) |
Estimating MI from empirical data commonly involves two steps: first,
estimating the joint distribution of stimuli and simplified responses,
and then calculating the MI based on this estimated distribution. The
first step in such calculations requires estimating the distribution
of neural responses for each stimulus. For example, when interested in
information in spike counts, one calculates the distribution of number
of spikes in the responses, as measured across repeated presentation
of each one of the stimuli separately. Repeating this calculation for
each stimulus yields the joint distribution of stimuli and
responses. An example of this procedure (using what is known as the
maximum likelihood estimator) is given in Fig. 3 of the paper. Figure
3b shows raster plots of the responses to five different stimuli, and
the number of spikes in each of the ![]() presentations of the first
stimulus is given in Table 1a below. The corresponding distribution of
spike counts for the first stimulus is given in Table 1b below, and
the distribution of spike counts for five representative stimuli is
depicted in Fig. 3c. Figure 3d assembles all of these distributions
together, forming the empirical joint distribution of stimuli and
spike counts. Other statistics of spike patterns can be used instead
of spike counts. For example, spike trains can be viewed as binary
``words'' of some fixed length, and their distribution can be
estimated similarly to spike counts distribution by counting number of
appearances of each word across stimulus repeated presentations (Fig
3e).
presentations of the first
stimulus is given in Table 1a below. The corresponding distribution of
spike counts for the first stimulus is given in Table 1b below, and
the distribution of spike counts for five representative stimuli is
depicted in Fig. 3c. Figure 3d assembles all of these distributions
together, forming the empirical joint distribution of stimuli and
spike counts. Other statistics of spike patterns can be used instead
of spike counts. For example, spike trains can be viewed as binary
``words'' of some fixed length, and their distribution can be
estimated similarly to spike counts distribution by counting number of
appearances of each word across stimulus repeated presentations (Fig
3e).
a.
b.
|
The second step is to calculate MI from the joint distribution. When
the number of samples is very large relative to the number of bins in
the joint distribution matrix, the observed empirical joint
distributionprovides a good estimate of the true underlying
distribution, and the MI can be calculated by plugging in the
empirical distribution ![]() into the MI formula ,
into the MI formula ,
![\begin{displaymath}
I\left[{\hat{p}(S,R)}\right] \equiv
\sum_{s,r} \hat{p}(s,r) \log \left({\frac{\hat{p}(s,r)}{\hat{p}(s)\hat{p}(r)}}\right)
\end{displaymath}](img9.png) |
(2) |
![\begin{displaymath}
I\left[{\hat{p}(S,R)}\right] > I\left[{p(S,R)}\right] \quad .
\end{displaymath}](img12.png) |
(3) |
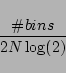 |
(4) |
Since the bias is roughly proportional to the number of bins in the joint distribution matrix, we have performed a procedure that iteratively unites rows or columns of the matrix. At each step, the row or column with minimum marginal probability was united with its neighbour with the lower marginal probability. The MI was determined as the largest bias-corrected estimate among all tested reduced matrices. This matrix reduction reduces the information in the matrix, but at the same time reduces the bias, and therefore makes it possible to obtain higher and more reliable estimates of the MI. The performance of this algorithm was discussed in detail in [3].