



In this work we introduce a fully end-to-end approach for action detection in videos that learns to directly predict the temporal bounds of actions. Our intuition is that the process of detecting actions is naturally one of observation and refinement: observing moments in video, and refining hypotheses about when an action is occurring. Based on this insight, we formulate our model as a recurrent neural network-based agent that interacts with a video over time. The agent observes video frames and decides both where to look next and when to emit a prediction. Since backpropagation is not adequate in this non-differentiable setting, we use REINFORCE to learn the agent's decision policy. Our model achieves state-of-the-art results on the THUMOS'14 and ActivityNet datasets while observing only a fraction (2% or less) of the video frames.
-
title={End-to-end learning of action detection from frame glimpses in videos},
author={Yeung, Serena and Russakovsky, Olga and Mori, Greg and Fei-Fei, Li},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={2678--2687},
year={2016}
Our model learns policies for where in the video would be useful to observe next, and when to emit an action prediction. Below are several examples of learned policies. The model often begins taking more frequent observations near or once an action begins, and takes steps backwards to refine a prediction before emitting. This direct reasoning on action extents enables state-of-the-art results on THUMOS'14 and ActivityNet while observing only a fraction of frames.
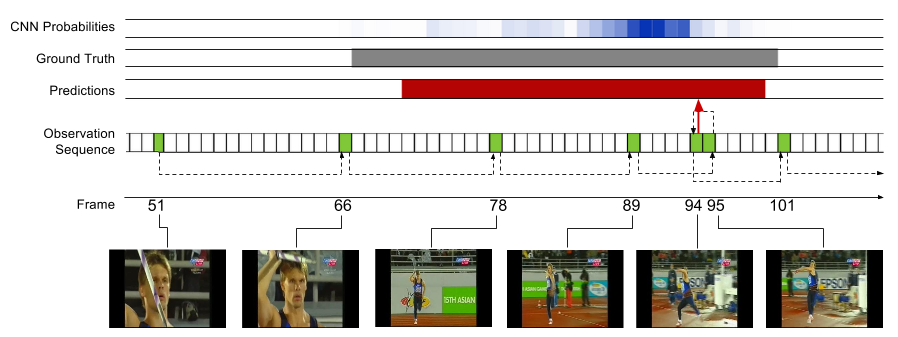
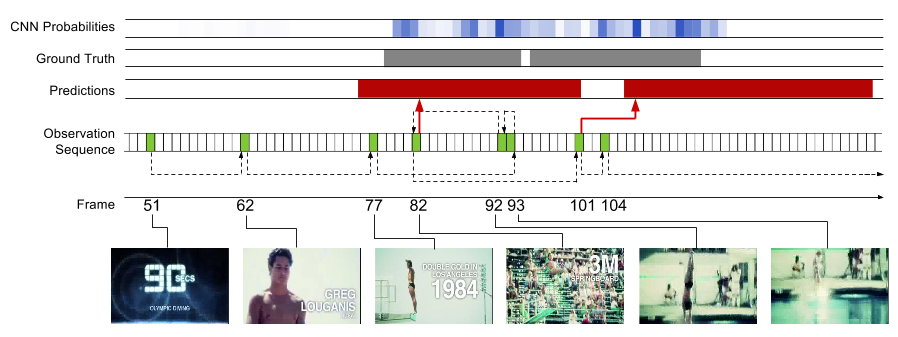
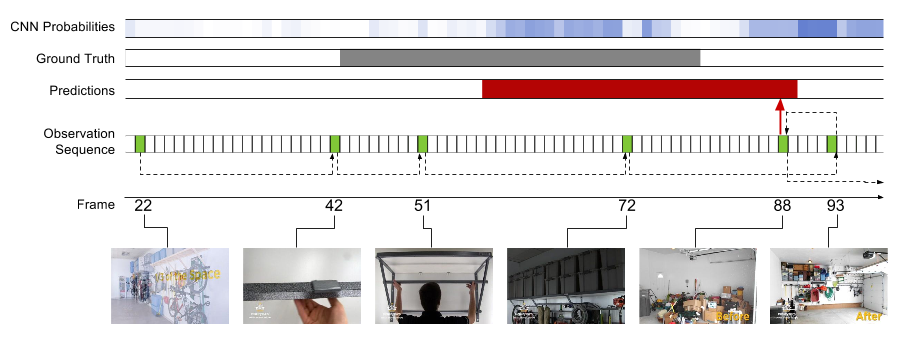
*THUMOS has provided an updated evaluation metric since the time of this work. This code was used to train models optimizing the original metric. Preliminary experiments using the model off-the-shelf with the new metric indicate performance on par with a CNN-based multi-scale sliding window detector in accuracy, while examining only 2% of the video frames.