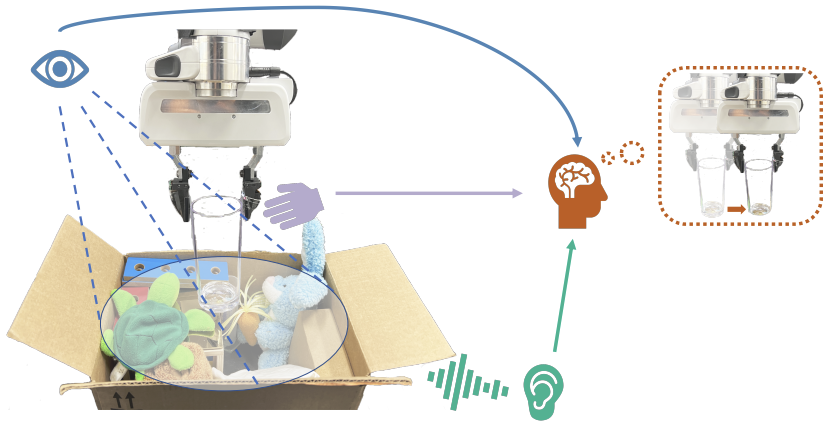
Humans use all of their senses to accomplish different tasks in everyday activities. In contrast, existing work on robotic manipulation mostly relies on one, or occasionally two modalities, such as vision and touch. In this work, we systematically study how visual, auditory, and tactile perception can jointly help robots to solve complex manipulation tasks. We build a robot system that can see with a camera, hear with a contact microphone, and feel with a vision-based tactile sensor, with all three sensory modalities fused with a self-attention model. Results on two challenging tasks, dense packing and pouring, demonstrate the necessity and power of multisensory perception for robotic manipulation: vision displays the global status of the robot but can often suffer from occlusion, audio provides immediate feedback of key moments that are even invisible, and touch offers precise local geometry for decision making. Leveraging all three modalities, our robotic system significantly outperforms prior methods.