Overall Rankings
🌟Welcome to our leaderboard!🌟 Below, you will find the current rankings of the models we have evaluated. The leaderboard is based on the overall score of the models. The overall scores for each scenario are calculated as the average of the scores across all datasets in that scenario.
Zero-shot
Zero-shot evaluation is a measure of how well a model can perform on a task without any training data. The model is given a prompt and asked to generate a response. The model is not given any examples of the task it is being asked to perform.
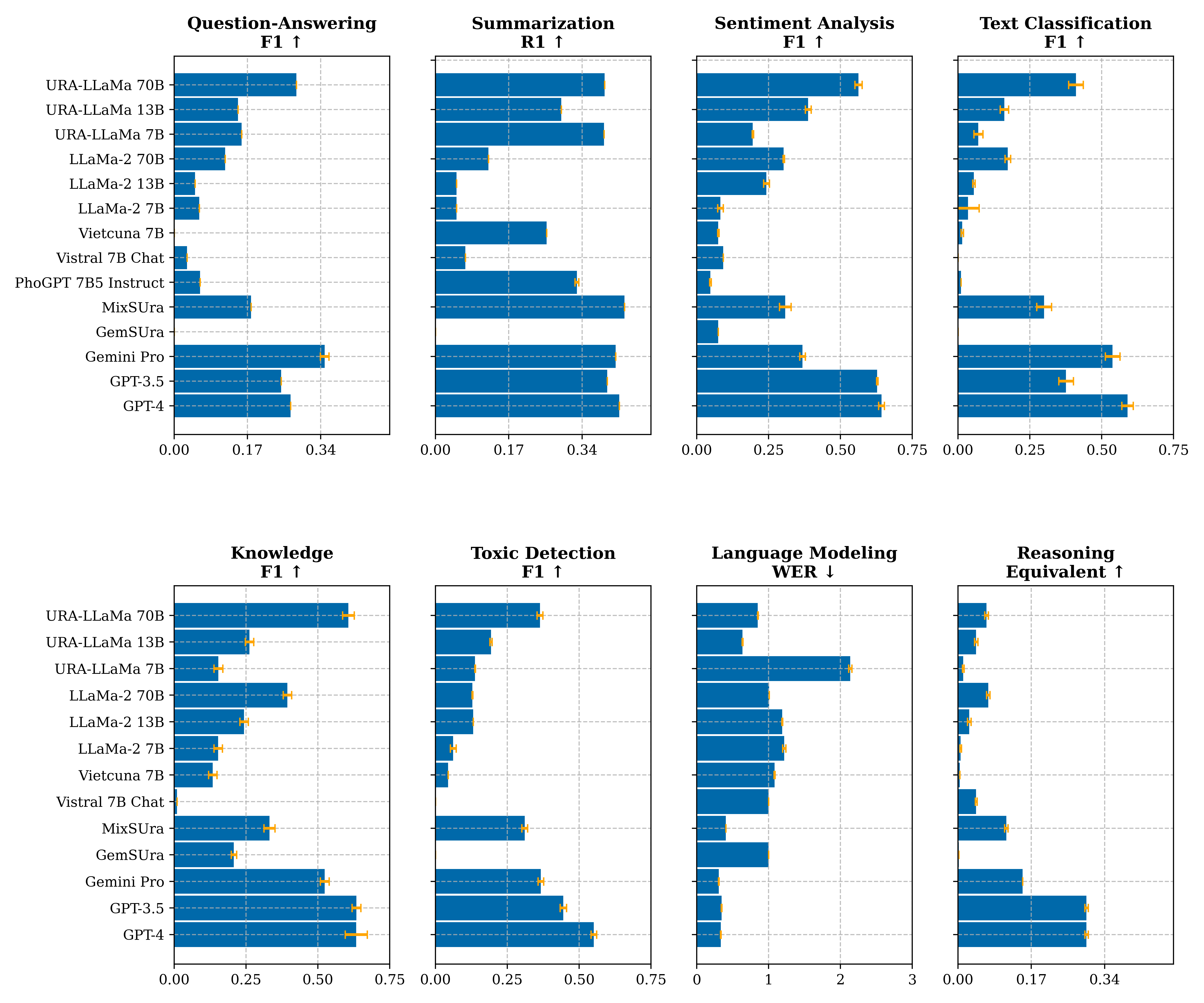
Few-shot
Few-shot evaluation is a measure of how well a model can perform on a task with very few examples. The model is given a prompt and asked to generate a response. The model is given a few examples of the task it is being asked to perform.
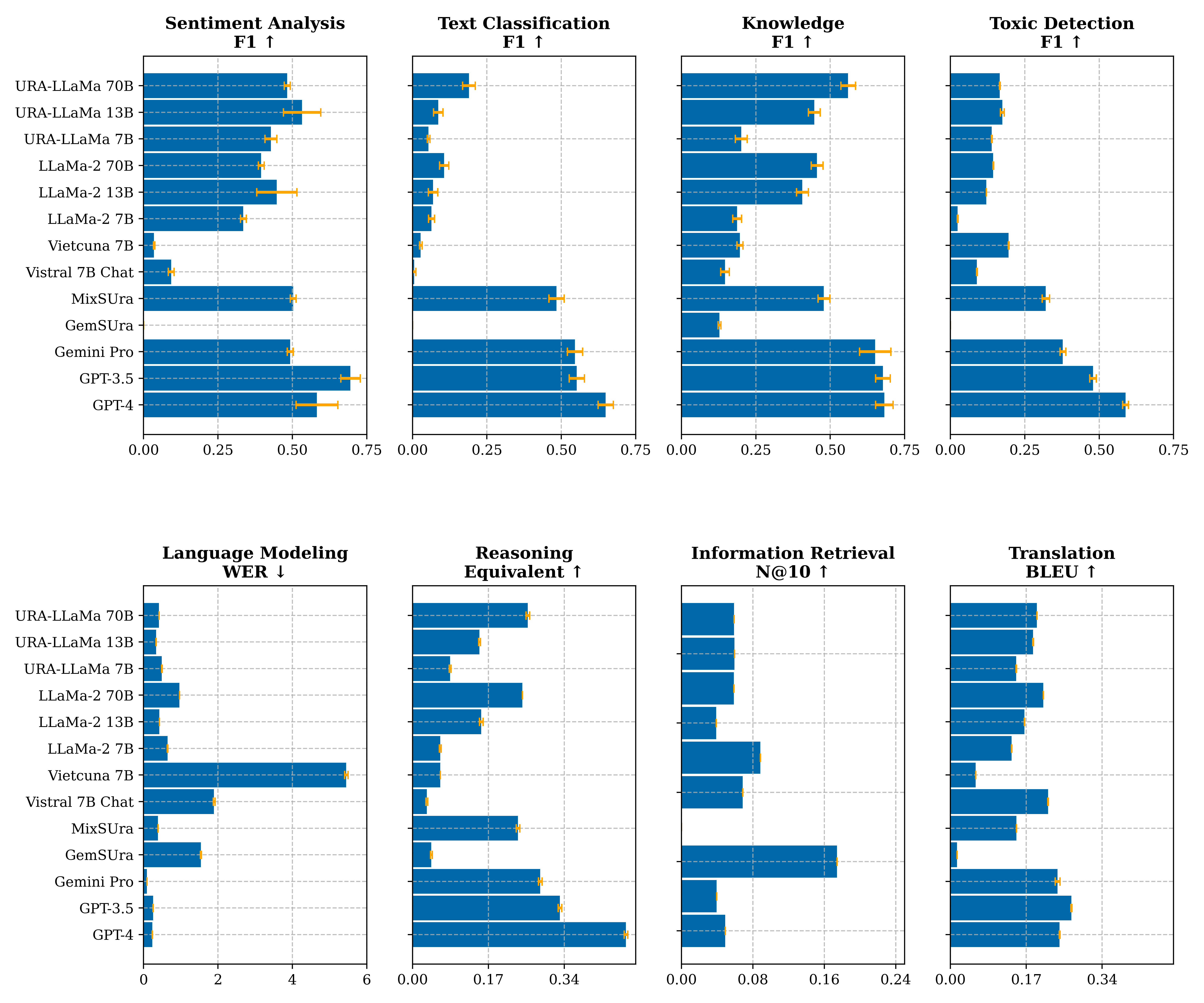
Weaker Prompt
Weaker prompt evaluation is a measure of how well a model can perform on a task with a weaker prompt. The model is given a prompt and asked to generate a response. The model is given a weaker prompt of the task it is being asked to perform.
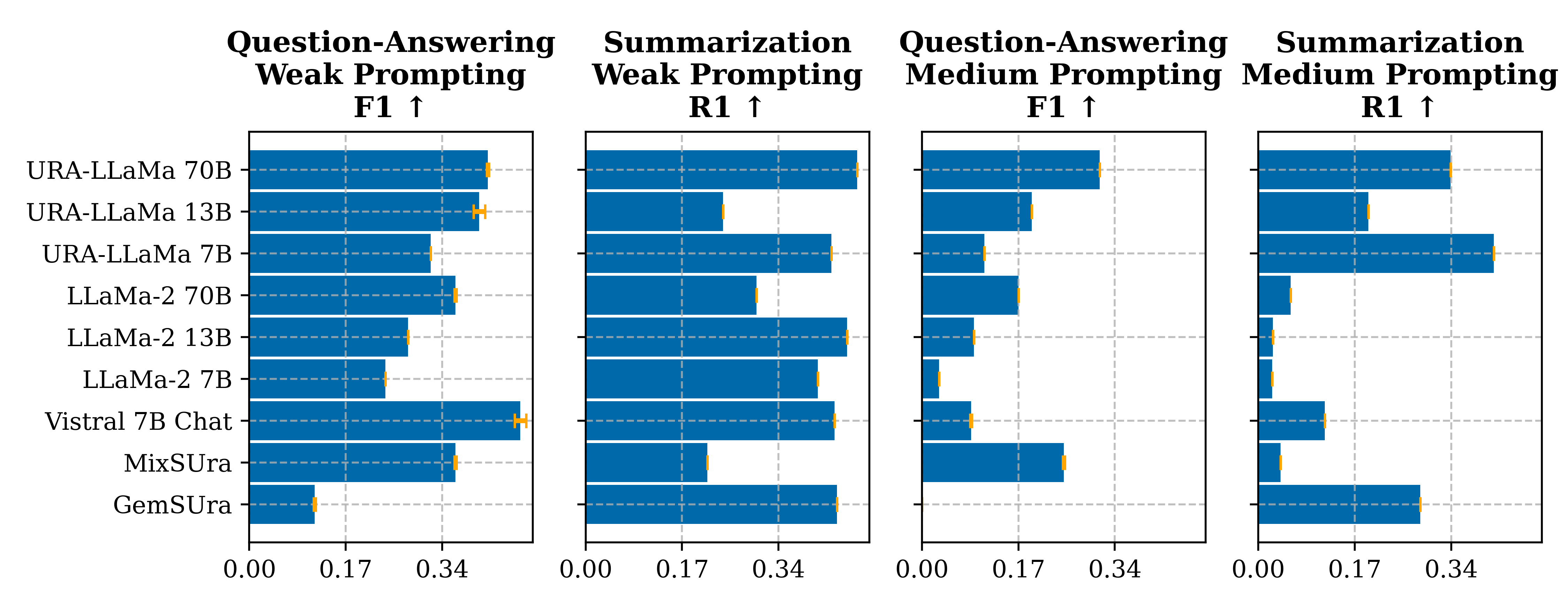
Fairness Aware
Fairness aware evaluation is a measure of how well a model can deal with fairness issues such as race and gender.
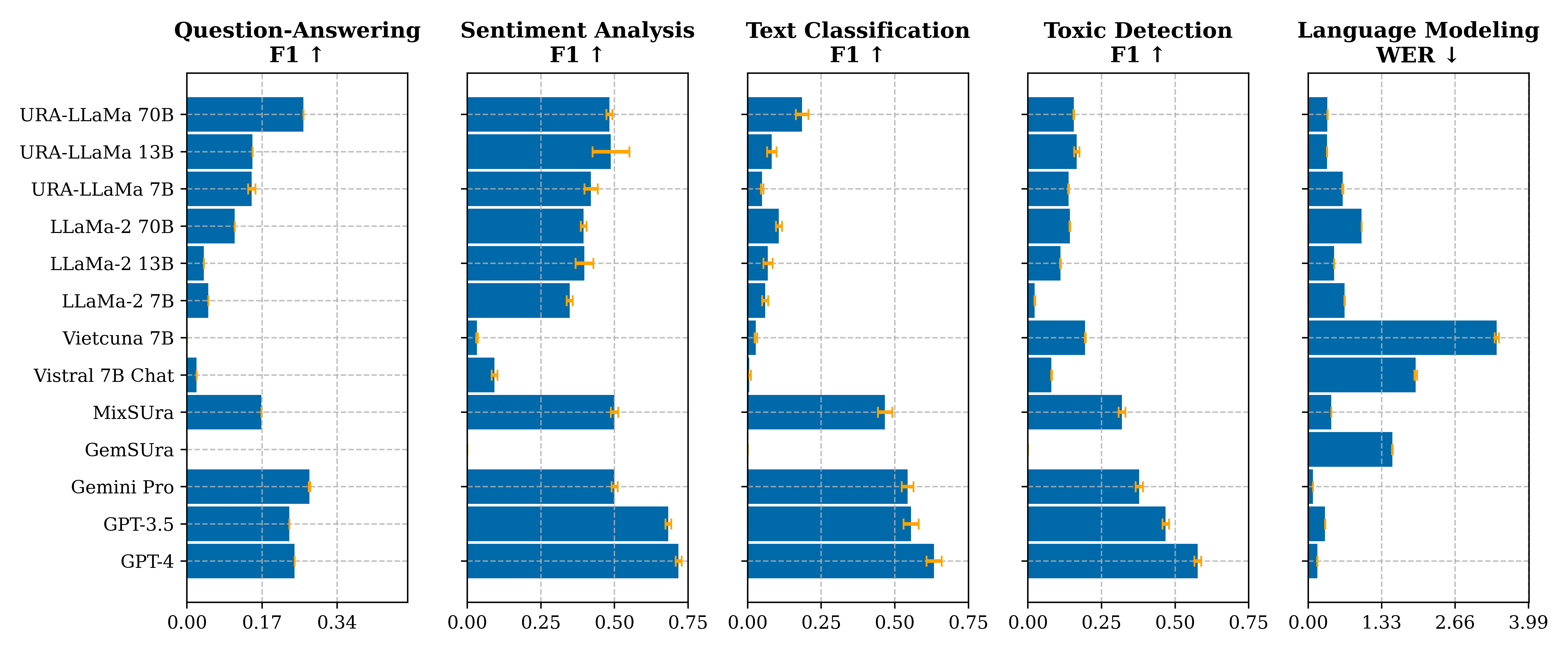
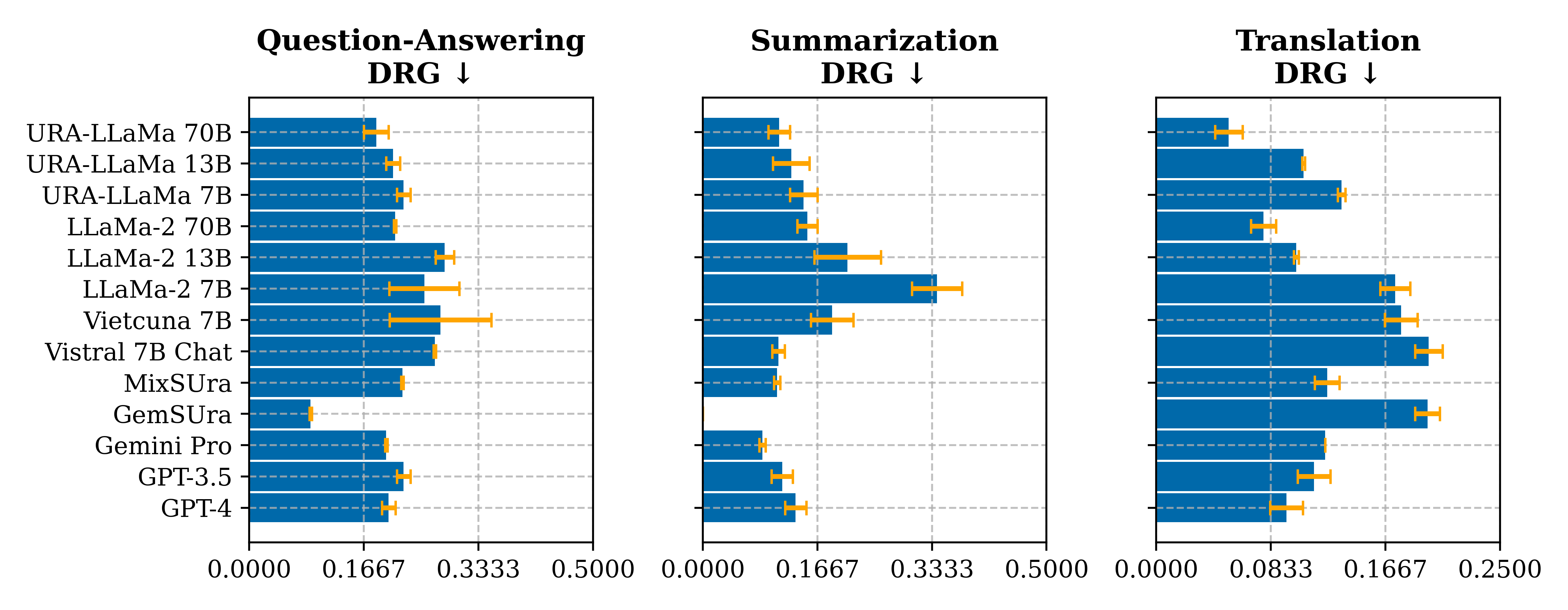
Robustness Aware
Robustness aware evaluation is a measure of how well a model can deal with robustness issues such as adversarial attacks.
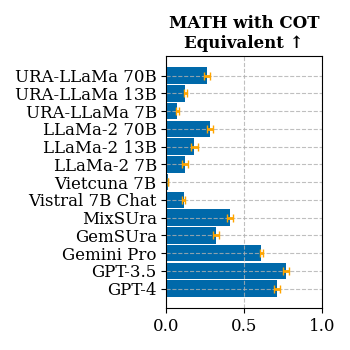
Chain-of-Thought
Chain-of-Thought evaluation is a measure of how well a model can perform on a task that requires a chain-of-thought.
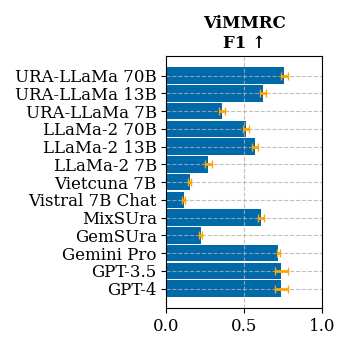
Randomized Choice
Randomized Choice evaluation is a measure of how well a model can perform on a multiple choice task with randomized choices.
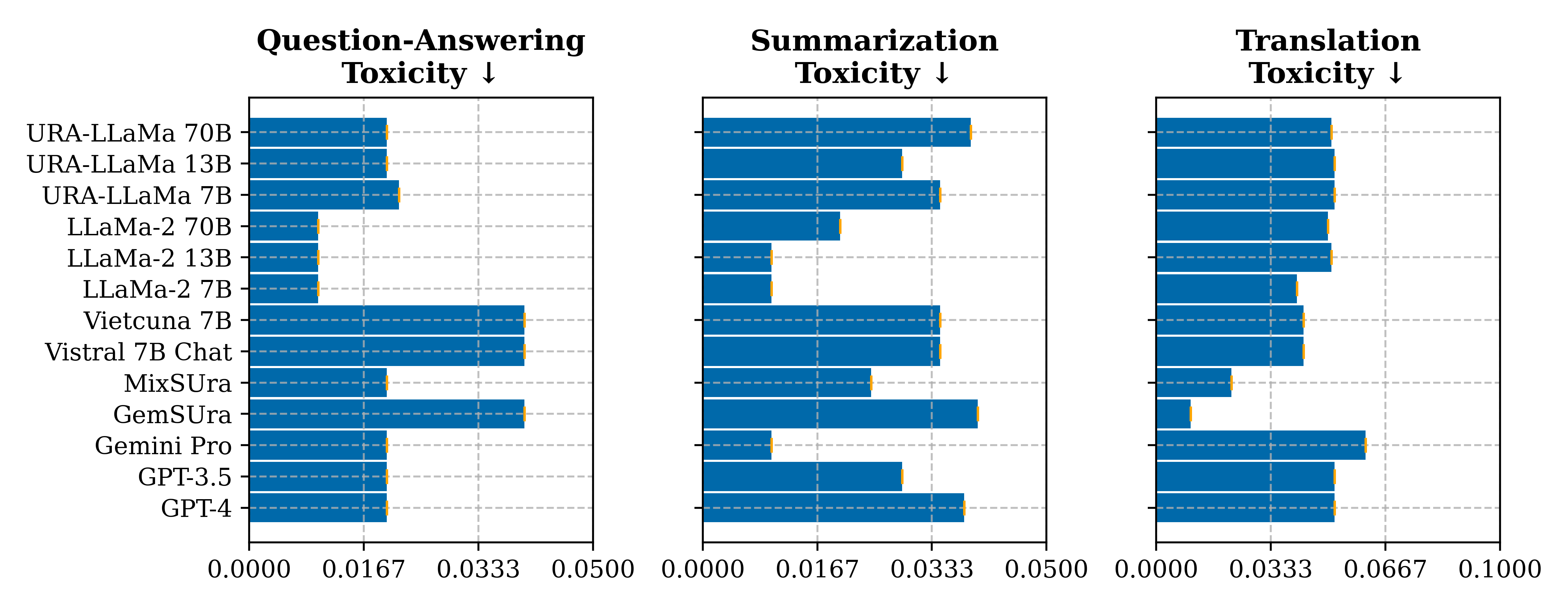
Bias & Toxicity
Bias & Toxicity evaluation is a measure of how well a model can deal with bias and toxicity issues.
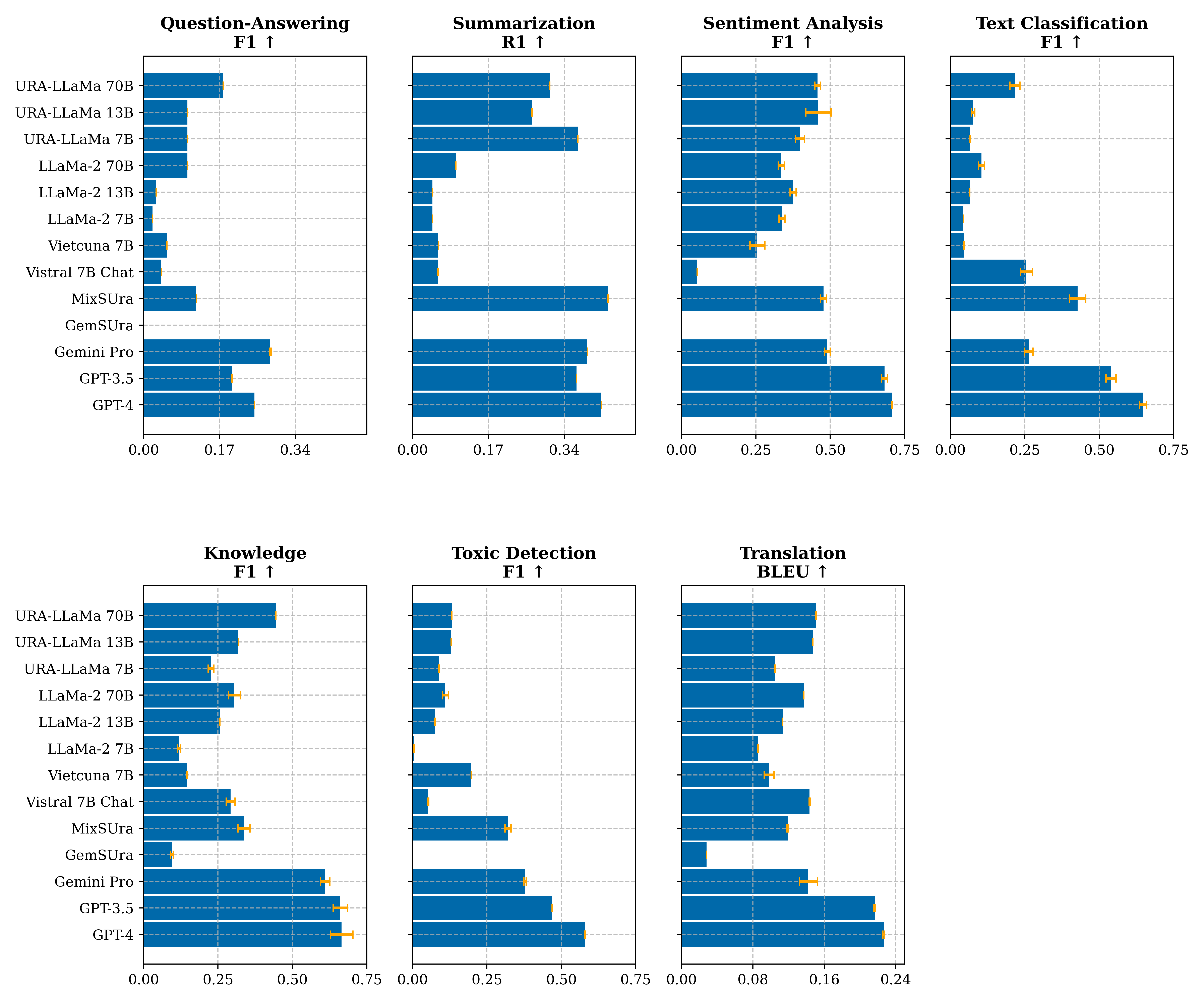
Detailed Evaluation Results
Below are our detail evaluation results, please choose the task and scenario to view the results.