Reasoning about Object Affordances in a Knowledge Base Representation
Yuke Zhu, Alireza Fathi, and Li Fei-Fei
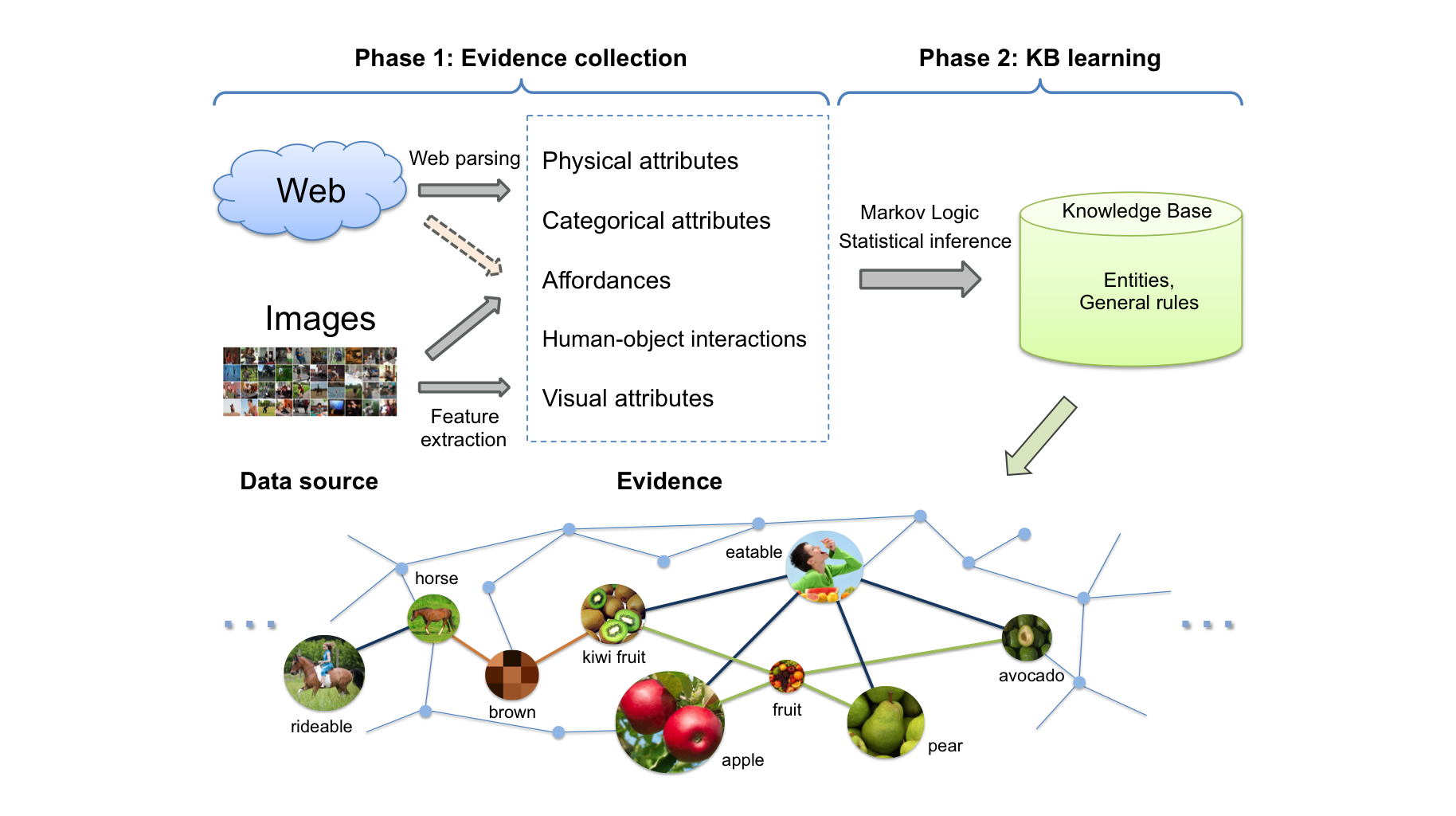
Abstract: Reasoning about objects and their affordances is a fundamental problem for visual intelligence. Most of the previous work casts this problem as a classification task where separate classifiers are trained to label objects, recognize attributes, or assign affordances. In this work, we consider the problem of object affordance reasoning using a knowledge base representation. Diverse information of objects are first harvested from images and other meta-data sources. We then learn a knowledge base (KB) using a Markov Logic Network (MLN). Given the learned KB, we show that a diverse set of visual inference tasks can be done in this unified framework without training separate classifiers, including zeroshot affordance prediction and object recognition given human poses.