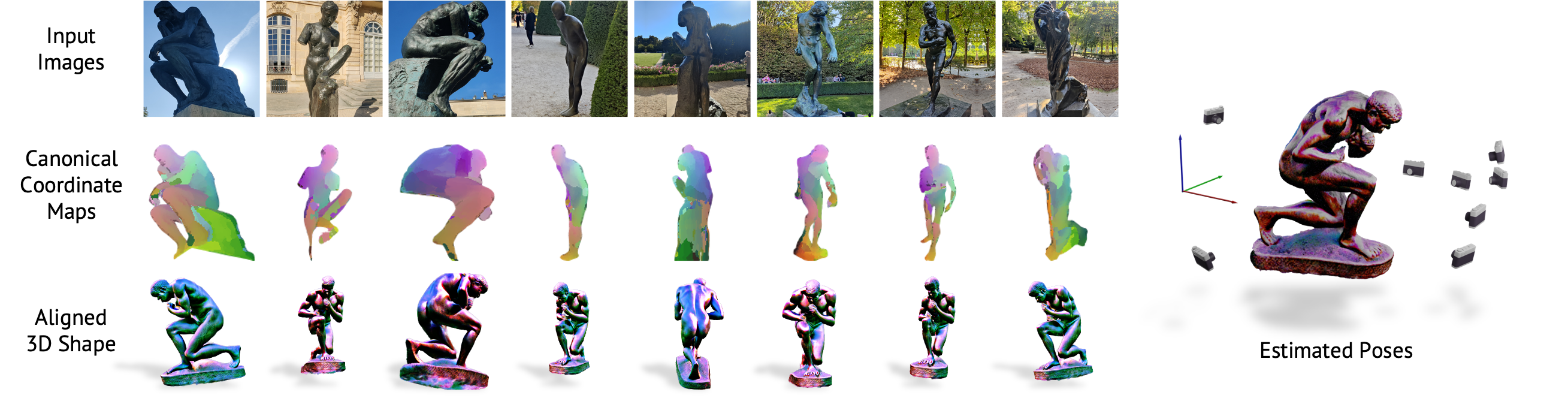
Please click here to see results on all input images.
We propose 3D Congealing, a novel problem of 3D-aware alignment for 2D images capturing semantically similar objects. Given a collection of unlabeled Internet images, our goal is to associate the shared semantic parts from the inputs and aggregate the knowledge from 2D images to a shared 3D canonical space. We introduce a general framework that tackles the task without assuming shape templates, poses, or any camera parameters. At its core is a canonical 3D representation that encapsulates geometric and semantic information. The framework optimizes for the canonical representation together with the pose for each input image, and a per-image coordinate map that warps 2D pixel coordinates to the 3D canonical frame to account for the shape matching. The optimization procedure fuses prior knowledge from a pre-trained image generative model and semantic information from input images. The former provides strong knowledge guidance for this under-constraint task, while the latter provides the necessary information to mitigate the training data bias from the pre-trained model. Our framework can be used for various tasks such as pose estimation and image editing, achieving strong results on real-world image datasets under challenging illumination conditions and on in-the-wild online image collections.
Objects with different shapes and appearances, such as the sculptures depicted in the photos shown below, may share similar semantic parts and a similar geometric structure. We study the task of inferring and aligning such a shared structure from an unlabeled image collection. Given a collection of in-the-wild images capturing similar objects as inputs, we develop an optimization framework that "congeals" these images in 3D. The core representation consists of a canonical 3D shape that captures the geometric structure shared among the inputs, together with a set of coordinate mappings that register the input images to the canonical shape. The framework utilizes the prior knowledge of plausible 3D shapes from a generative model (Stable Diffusion), and aligns images in the semantic space using pre-trained semantic feature extractors (DINO).
Single-Instance Inputs.
Internet photos of tourist landmarks may contain a large diversity in
viewpoints, illuminations and styles (e.g., photos and sketches),
and may not correspond to the same object identity.
The method can handle such variances and align these tourist photos
taken at different times and possibly at different geographical locations,
which are abundant from the Internet image database,
to the same canonical 3D space and recover the relative camera poses.
Below are results with 4 sets of inputs.
The first rows show the input images,
and the second rows show the inferred 3D canonical shapes rendered under the corresponding image poses.

Single-Category, Multi-Instance Inputs. Images for generic objects from an online image search may contain various identities and articulated poses of the object, with more shape and texture variations compared to the landmarks. The framework can consistently infer a canonical shape from the input images to capture the shared semantic components being observed.

Multi-Category Inputs. What happens if input images contain objects that do not come from the same category? The method handles such scenarios by learning an average shape as an anchoring canonical space, to help further reason about the relative relation among input images and predict a pose for each individual input.

Inputs with Deformations. Below are results on a dataset where input images depict objects with highly diverse shapes as an example of challenging inputs.

The method propagates (a) texture and (b) regional editing to real images, (c) achieving smoother results compared to the nearest-neighbor (NN) baseline thanks to the 3D geometric reasoning.

To match a querying pixel coordinate from the source image, our method first warps the coordinate to the rendered image space corresponding to the source image (2D-to-2D), then identifies the warped coordinate's location in the canonical frame in 3D (2D-to-3D). Then, it projects the same 3D location to the rendering corresponding to the target image (3D-to-2D), and finally warps the obtained coordinate to the target image space (2D-to-2D). The learned 3D canonical shape serves as an intermediate representation that aligns the source and target images, and it better handles scenarios when the viewpoint changes significantly compared to matching features in 2D.

@article{zhang2024congealing,
title = {3D Congealing: 3D-Aware Image Alignment in the Wild},
author = {Yunzhi Zhang and Zizhang Li and Amit Raj and Andreas Engelhardt and Yuanzhen Li and Tingbo Hou
and Jiajun Wu and Varun Jampani},
journal = {arXiv preprint arXiv:2404.02125},
year = {2024}
}The template source code for this webpage is available here.