
Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g., color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g., a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
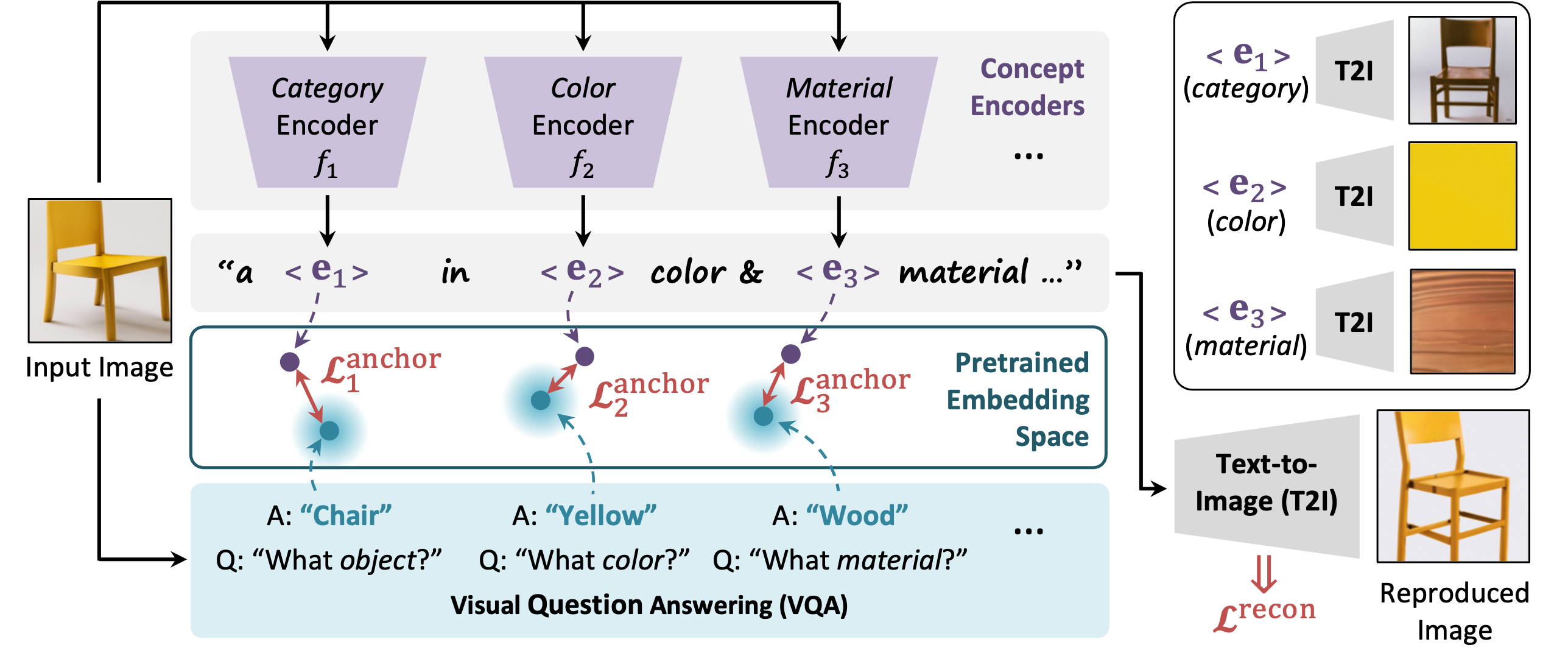
During training, an input image is processed by a set of concept encoders that predict concept embeddings specific to given concept axes. These embeddings are trained to (1) retain information in order to reproduce visual inputs via a pre-trained Text-to-Image model (DeepFloyd) given an axis-informed text template, and (2) ensure disentanglement across different axes by anchoring to text embeddings obtained from a pre-trained Visual Question Answering model (BLIP-2).
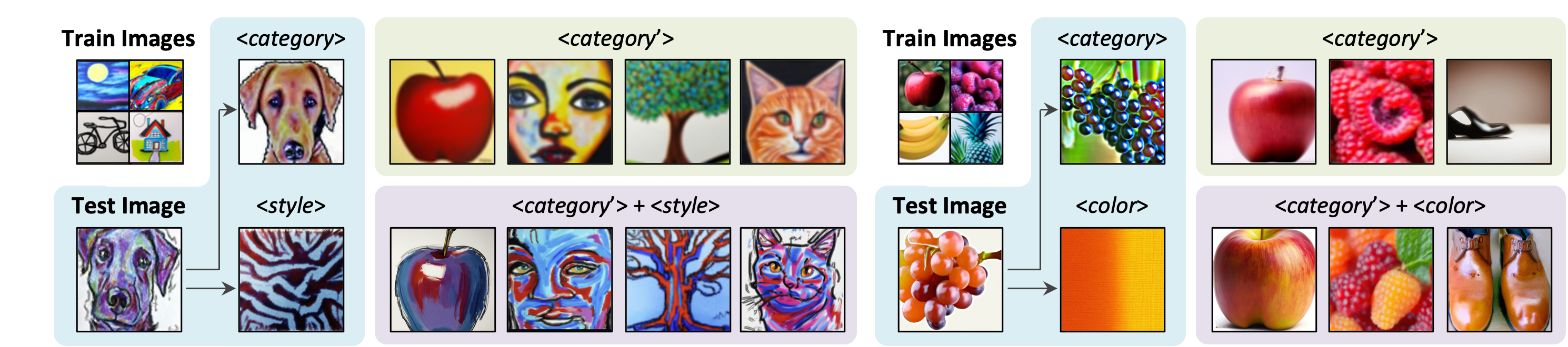
At test time, our model extracts visual concepts along various axes, such as <category>, <color>, and <material>, from different images and recompose them to generate new images. We show recomposition results across different pairs of concept axes in 3 datasets: (a) Fruits, (b) Paintings, and (c) Furniture.

After finetuning on a single test-time image, the encoders can adapt to novel concept. Visual details from the input images are preserved as can be seen from images visualizing embedding predictions. Importantly, these embeddings do not overfit to the input images and maintain a good disentanglement, such that they can be freely recomposed to create new concepts.
Compared the text-based image editing methods, our method achieves significantly better compositionality due to the disentangled concept representation, and captures more fine-grained visual details from the input image compared to the baselines.

Given an input image, we can extrapolate along a concept axis by querying BLIP-2 and GPT-4 to name a few alternatives to the concept in the input and generate new variants for visual exploration.

Given two input images, their concept embeddings can be extracted individually and then interpolated to synthesize interpolated images.

@inproceedings{lee2023language,
title={Language-Informed Visual Concept Learning},
author={Lee, Sharon and Zhang, Yunzhi and Wu, Shangzhe and Wu, Jiajun},
booktitle={The Twelfth International Conference on Learning Representations},
year={2023}
}We thank Kyle Hsu, Joy Hsu, and Stephen Tian for their detailed comments and feedback. This work is in part supported by NSF RI #2211258, ONR MURI N00014-22-1-2740, ONR N00014-23-1-2355, AFOSR YIP FA9550-23-1-0127, the Stanford Institute for Human-Centered AI (HAI), Amazon, J.P. Morgan, and Samsung.
The template source code for this webpage is available here.