Why is machine learning 'hard'?
There have been tremendous advances made in making machine learning more accessible over the past few years. Online courses have emerged, well-written textbooks have gathered cutting edge research into an easier to digest format and countless frameworks have emerged to abstract the low level messiness associated with building machine learning systems. In some cases these advancements have made it possible to drop an existing model into your application with a basic understanding of how the algorithm works and a few lines of code.
However, machine learning remains a relatively ‘hard’ problem. There is no doubt the science of advancing machine learning algorithms through research is difficult. It requires creativity, experimentation and tenacity. Machine learning remains a hard problem when implementing existing algorithms and models to work well for your new application. Engineers specializing in machine learning continue to command a salary premium in the job market over standard software engineers.
This difficulty is often not due to math - because of the aforementioned frameworks machine learning implementations do not require intense mathematics. An aspect of this difficulty involves building an intuition for what tool should be leveraged to solve a problem. This requires being aware of available algorithms and models and the trade-offs and constraints of each one. By itself this skill is learned through exposure to these models (classes, textbooks and papers) but even more so by attempting to implement and test out these models yourself. However, this type of knowledge building exists in all areas of computer science and is not unique to machine learning. Regular software engineering requires awareness of the trade offs of competing frameworks, tools and techniques and judicious design decisions.
The difficulty is that machine learning is a fundamentally hard debugging problem. Debugging for machine learning happens in two cases: 1) your algorithm doesn't work or 2) your algorithm doesn't work well enough. What is unique about machine learning is that it is ‘exponentially’ harder to figure out what is wrong when things don’t work as expected. Compounding this debugging difficulty, there is often a delay in debugging cycles between implementing a fix or upgrade and seeing the result. Very rarely does an algorithm work the first time and so this ends up being where the majority of time is spent in building algorithms.
Exponentially Difficult Debugging
In standard software engineering when you craft a solution to a problem and something doesn’t work as expected in most cases you have two dimensions along which things could have gone wrong: algorithmic or implementation issues. For example, take the case of a simple recursive algorithm:
def recursion(input):
if input is endCase:
return transform(input)
else:
return recursion(transform(input))
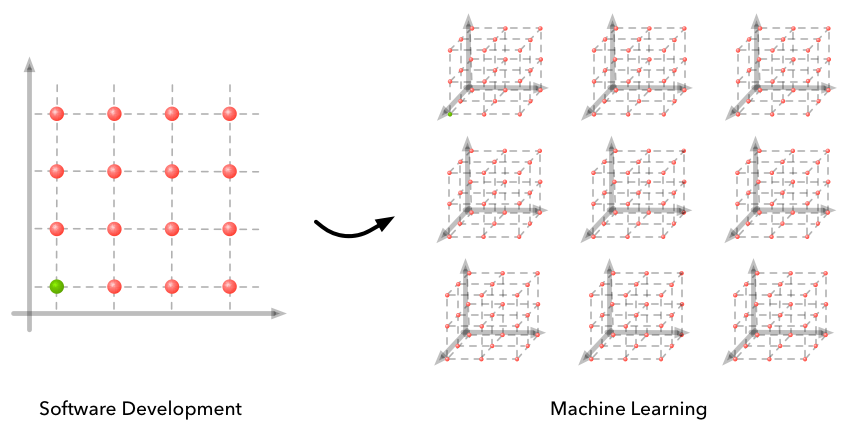
We can enumerate the failure cases when the code does not work as expected. In this example the grid might look like this:
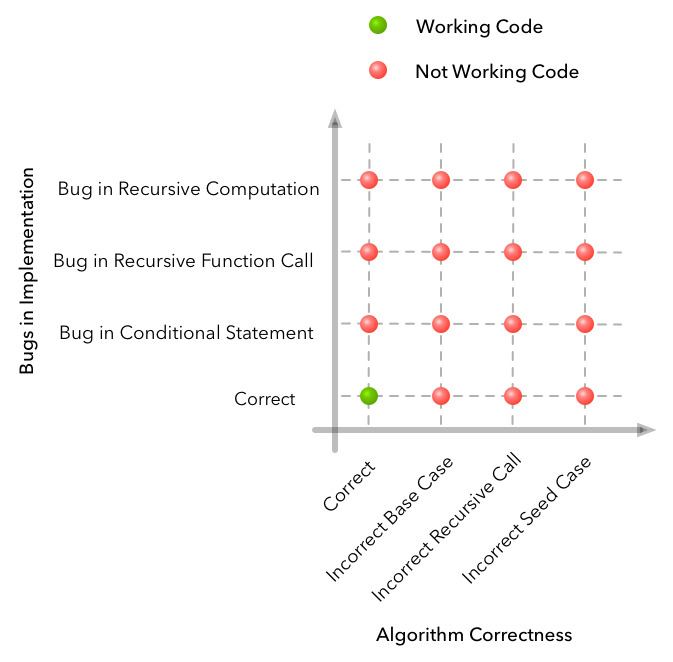
Along the horizontal axis we have a few examples of where we might have made a mistake in the algorithm design. And along the vertical axis we have a few examples of where things might have gone wrong in the implementation of the algorithm. Along any one dimension we might have a combination of issues (i.e. multiple implementation bugs) but the only time we will have a working solution is if both the algorithm and the implementation are correct.
The debugging process then becomes a matter of combining the signals you have about the bug (compiler error messages, program outputs etc.) with your intuition on where the problem might be. These signals and heuristics help you prune the search space of possible bugs into something manageable.
In the case of machine learning pipelines there are two additional dimensions along which bugs are common: the actual model and the data. To illustrate these dimensions, the simplest example is of training logistic regression using stochastic gradient descent. Here algorithm correctness includes correctness of the gradient descent update equations. Implementation correctness includes correct computations of the features and parameter updates. Bugs in the data often involve noisy labels, mistakes made in preprocessing, not having the right supervisory signal or even not enough data. Bugs in the model may involve actual limitations in the modeling capabilities. For example, this may be using a linear classifier when your true decision boundaries are non-linear.
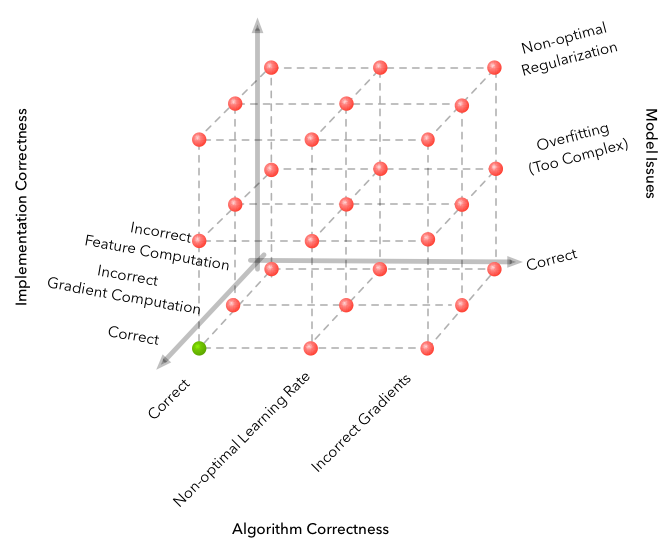
Our debugging process goes from a 2D grid to a 4D hypercube (three out of four dimensions drawn above for clarity). The fourth data dimension can be visualized as a sequence of these cubes (note that there is only one cube with a correct solution).
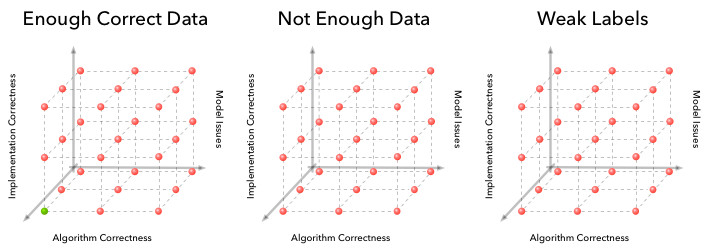
The reason this is 'exponentially' harder is because if there are n possible ways things could go wrong in one dimension there are n x n ways things could go wrong in 2D and n x n x n x n ways things can go wrong in 4D. It becomes essential to build an intuition for where something went wrong based on the signals available. Luckily for machine learning algorithms you also have more signals to figure out where things went wrong. For example, signals that are particularly useful are plots of your loss function on your training and test sets, actual output from your algorithm on your development data set and summary statistics of the intermediate computations in your algorithm.
Delayed Debugging Cycles
The second compounding factor that complicates machine learning debugging is long debugging cycles. It is often tens of hours or days between implementing a potential fix and getting a resulting signal on whether the change was successful. We know from web development that development modes that enable auto-refresh significantly improve developer productivity. This is because you are able to minimize disruptions to the development flow. This is often not possible in machine learning - training an algorithm on your data set might take on the order of hours or days. Models in deep learning are particularly prone to these delays in debugging cycles. Long debugging cycles force a 'parallel' experimentation paradigm. Machine learning developers will run multiple experiments because the bottleneck is often the training of the algorithm. By doing things in parallel you hope to exploit instruction pipelining (for the developer not the processor). The major disadvantage of being forced to work in this way is that you are unable to leverage the cumulative knowledge you build as you sequentially debug or experiment.
Machine learning often boils down to the art of developing an intuition for where something went wrong (or could work better) when there are many dimensions of things that could go wrong (or work better). This is a key skill that you develop as you continue to build out machine learning projects: you begin to associate certain behavior signals with where the problem likely is in your debugging space. In my own work there are many examples of this. For example, one of the earliest issues I ran into while training neural networks was periodicity in my training loss function. The loss function would decay as it went over the data but every so often it would jump back up to a higher value. After much trial and error I eventually learned that this is often the case of a training set that has not been correctly randomized (it was an implementation issue that looked like a data issue) and is a problem when you are using stochastic gradient algorithms that process the data in small batches.
In conclusion, fast and effective debugging is the skill that is most required for implementing modern day machine learning pipelines.