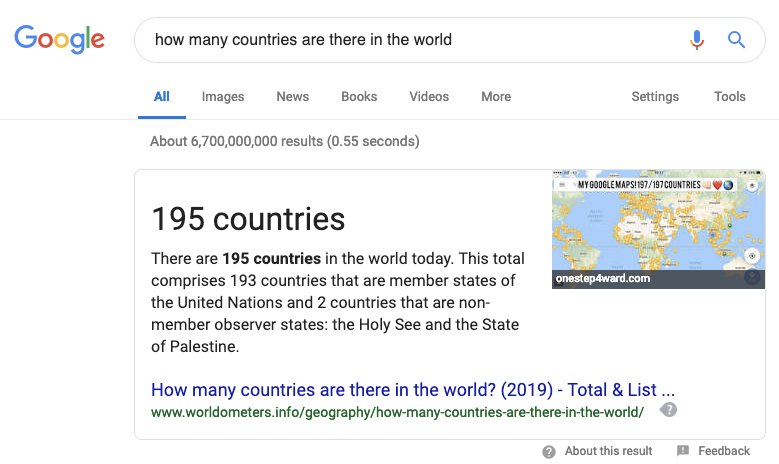
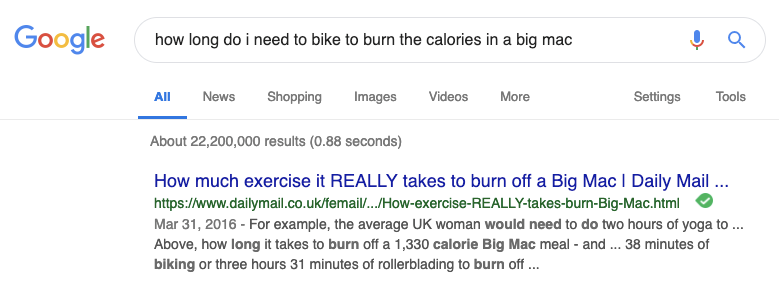
Have you ever Googled some random question, such as how many countries are there in the world, and been impressed to see Google presenting the precise answer to you rather than just a list of links? This feature is clearly nifty and useful, but is also still limited; a search for a slightly more complex question such as how long do I need to bike to burn the calories in a Big Mac will not yield a nice answer, even though any person could look over the content of the first or second link and find the answer.
In today’s age of information explosion, when too much new knowledge is generated every day in text (among other modalities) for any single person to digest, enabling machines to read large amounts of text and answer questions for us is one of the most crucial and practical tasks in the field of natural language understanding. Solving the task of machine reading, or question answering, will lay an important cornerstone towards a powerful and knowledgeable AI system like the librarian in the movie Time Machine:
Recently, large-scale question answering datasets like the Stanford Question Answering Dataset (SQuAD) and TriviaQA have fueled much of the progress in this direction. By allowing researchers to train powerful and data-hungry deep learning models, these datasets have already enabled impressive results such as an algorithm that can answer many arbitrary questions by finding the appropriate answer in Wikipedia pages – removing the need for a human to do all the hard work themselves.1

SQuAD consists of 100k+ examples collected from 500+ Wikipedia articles. For each paragraph in the article, a list of questions are posed independently and these questions are required to be answered by a contiguous span in the paragraph (see the examples above based on Wikipedia article Super Bowl 50), also known as “extractive question answering”.
However, as impressive as such results may seem, these datasets have significant drawbacks that are limiting further advancements in this area. In fact, researchers have shown that models trained with these datasets are not actually learning very sophisticated language understanding and are instead largely drawing on simple pattern-matching heuristics.2
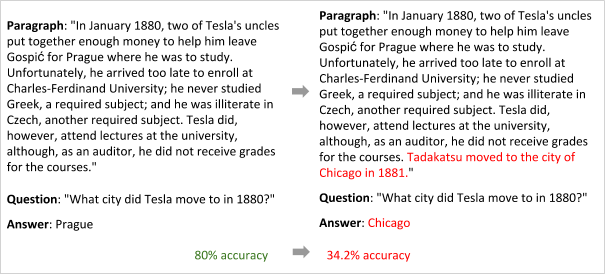
From Jia and Liang. Short added sentences showcase that the model learn to pattern-match city names, rather than truly understanding the question and answer.
In this blog post, we introduce two recent datasets collected by the Stanford NLP Group with an aim to further advance the field of machine reading. Specifically, these datasets aim at incorporating more “reading” and “reasoning” in the task of question answering, to move beyond questions that can be answered by simple pattern matching. The first of the two, CoQA, attacks the problem from a conversational angle, by introducing a context-rich interface of a natural dialog about a paragraph of text. The second, HotpotQA3, goes beyond the scope of one paragraph and instead presents the challenge of reasoning over multiple documents to arrive at the answer, as we will introduce in detail below.
CoQA: Question Answering through Conversations
What is CoQA?
Most current question answering systems are limited to answering questions independently (as the SQuAD examples shown above). Though this sort of question-answer exchange does sometimes happen between people, it is more common to seek information by engaging in conversations involving a series of interconnected questions and answers. CoQA is a Conversational Question Answering dataset that we developed to address this limitation with a goal of driving the development of conversational AI systems.4 Our dataset contains 127k questions with answers, obtained from 8k conversations about text passages from seven diverse domains.

As is shown above, a CoQA example consists of a text passage (collected from a CNN news article in this example) and a conversation about the content of the passage. In this conversation, each turn contains a question and an answer, and every question after the first is dependent on the conversation thus far. Unlike SQuAD and many other existing datasets, the conversation history is indispensable for answering many questions. For example, the second question Q2 (where?) is impossible to answer without knowing what has already been said. It is also worth noting that the entity of focus can actually change through a conversation, for example, “his” in Q4, “he” in Q5, and “them” in Q6 all refer to different entities, which makes understanding these questions more challenging.
In addition to the key insight that the CoQA’s questions require understanding in a conversational context, CoQA has other many other appealing features:
-
An important feature is that we didn’t restrict the answers to be a contiguous span in the passage, as SQuAD does. We think that many questions are not able to be answered by a single span in the passage, which will limit the naturalness of the conversations. For example, for a question like How many?, the answer can be simply three despite text in the passage not spelling this out directly. At the same time, we hope that our dataset supports a reliable automatic evaluation and obtains a high human agreement. To approach this, we asked the annotators to first highlight a text span (acting as a rationale to support the answer, see R1, R2 etc in the example) and then edit the text span into a natural answer. These rationales can be leveraged in training (but not in testing).
-
Most existing QA datasets mainly focus on a single domain, which makes it hard to test the generalization ability of existing models. Another important feature of CoQA is that this dataset is collected from seven different domains — children’s stories, literature, middle and high school English exams, news, Wikipedia, Reddit and science. The last two are used for out-of-domain evaluation.
We conducted an in-depth analysis of our dataset. As presented in the following table, we find that our dataset exhibits a rich set of linguistic phenomena. Nearly 27.2% of the questions require pragmatic reasoning such as common sense and presupposition. For example, the question Was he loud and boisterous? is not a direct paraphrase of the rationale he dropped his feet with the lithe softness of a cat but the rationale combined with world knowledge can answer this question. Only 29.8% of the questions can be answered with simple lexical matching (i.e. directly mapping words in the question to the passage).
We also find that only 30.5% of the questions do not rely on coreference with the conversational history and are answerable on their own. For the rest, 49.7% of the questions contain explicit coreference markers such as he, she, or it, and the remaining 19.8% of questions (e.g., Where?) refer to an entity or event implicitly.

Compared to the question distribution of SQuAD 2.0, we find that our questions are much shorter than the SQuAD questions (5.5 vs 10.1 words on average), which reflects the conversational nature of our dataset. Our dataset also presents a richer variety of questions; while nearly half of SQuAD questions are dominated by what questions, the distribution of CoQA is spread across multiple question types. Several sectors indicated by prefixes did, was, is, does are frequent in CoQA but are completely absent in SQuAD.

Recent Progress
Since we launched the CoQA challenge in August 2018, it received a great deal of attention and became one of the most competitive benchmarks in our community. We are amazed that a lot of progress has been made since then, especially after Google’s BERT models 5 were released last November — which have lifted the performance of all the current systems by a large margin.
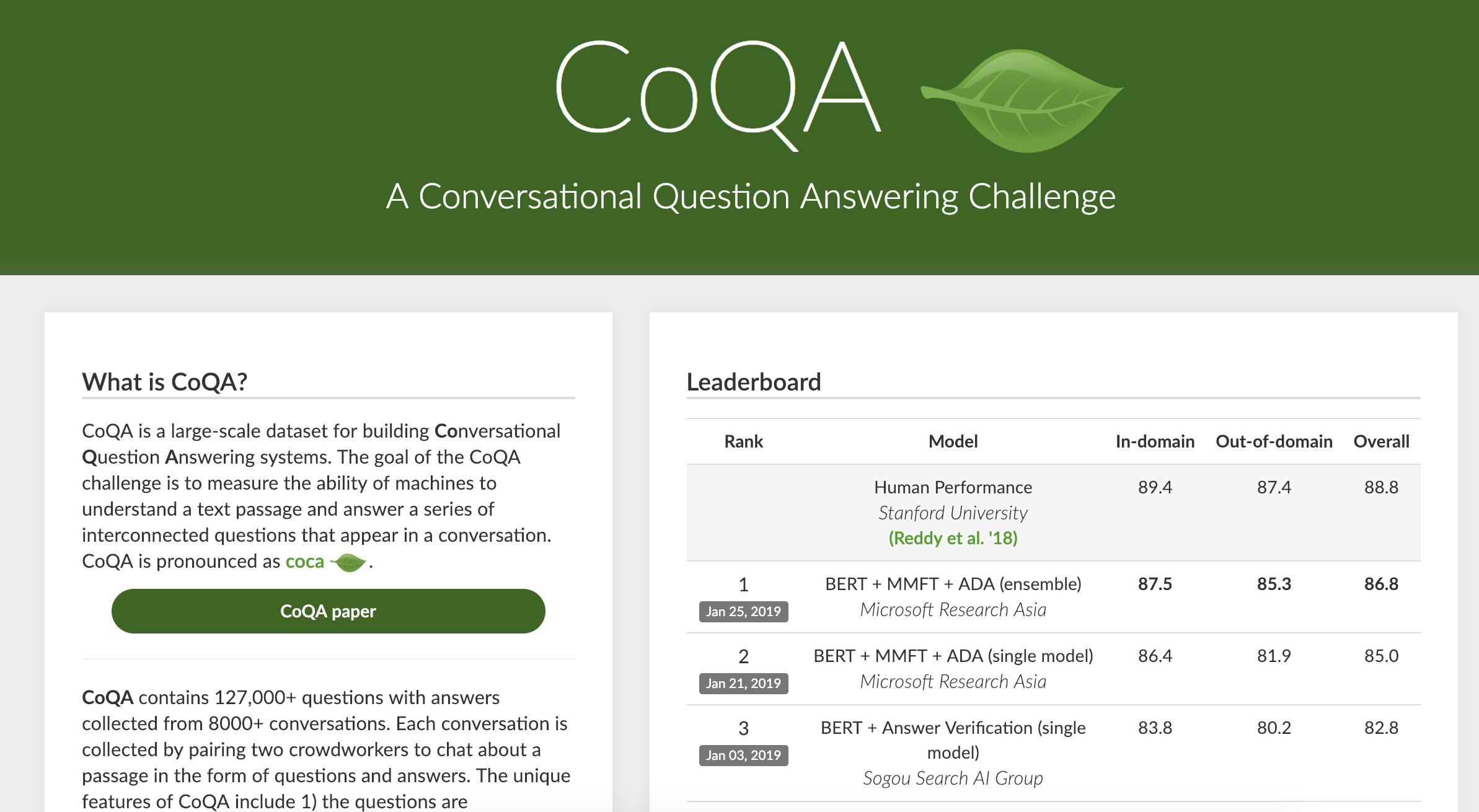
The state-of-the-art ensemble system “BERT+MMFT+ADA” from Microsoft Research Asia achieved 87.5% in-domain F1 accuracy and 85.3% out-of-domain F1 accuray. These numbers are not only approaching human performance, but also are over 20 points higher than the baseline models that we developed 6 months ago (our research community is moving very fast!). We look forward to seeing these papers and open-sourced systems in the near future.
HotpotQA: Machine Reading over Multiple Documents
Besides diving deeply into a given paragraph of context through an prolonged conversation, we also often find ourselves in need of reading through multiple documents to find out facts about the world.
For instance, one might wonder, in which state was Yahoo! founded? Or, does Stanford have more computer science researchers or Carnegie Mellon University? Or simply, How long do I need to run to burn the calories of a Big Mac?
The Web contains the answers to many of these questions, but not always in a readily available form, or even in one place. For example, if we take Wikipedia as the source of knowledge to answer our first question (about where Yahoo! was founded), we will initially be baffled that none of the pages of Yahoo! or those of its co-founders Jerry Yang and David Filo mention this information.6
To answer this question, one would need to laboriously browse multiple Wikipedia articles, until they come across the following article titled History of Yahoo!:
As one can see, we can answer the question in the following steps of reasoning:
- We note that the first sentence of this article states that Yahoo! was founded at Stanford University.
- Then, we can look up Stanford University in Wikipedia (in this case we simply clicked on the link), to find out where it’s located in
- The Stanford University page tells us that it is located in California.
- Finally, we can combine these two facts to arrive at the answer to the original question: Yahoo! was founded in the State of California.
Note that to answer this question, two skills were essential: (1) a bit of detective work to find out about what documents, or supporting facts, to use that could lead to an answer to our question, and (2) the ability to reason with multiple supporting facts to arrive at the final answer.
These are important capabilities for machine reading systems to acquire in order for them to effectively assist us in digesting the ever-growing ocean of information and knowledge in the form of text. Unfortunately, because existing datasets have thus focused on finding answers within single documents, falling short at tackling this challenge, we undertook the effort of making that possible by compiling the HotpotQA dataset.
What is HotpotQA?
HotpotQA is a large-scale question answering (QA) dataset containing about 113,000 question-answer pairs that have the characteristics of those we mentioned above.7 That is, the questions require QA systems to be able to sift through large quantities of text documents to find information pertinent to generating an answer, and to reason with the multiple supporting facts it found to arrive at the final answer (see below for an example).

An example question from HotpotQA
The questions and answers are collected in the context of the entire English Wikipedia, and covers a diverse range of topics ranging from science, astronomy, and geography, to entertainment, sports, and legal cases.
The questions require many challenging types of reasoning to answer. For example, in the Yahoo! example, one would need to first infer the relation between Yahoo! and the “missing link” essential to answering the question, Stanford University, and then leverage the fact that Stanford University is located in California to arrive at the final answer. Schematically, the inference chain looks like the following:

Here, we call Stanford University the bridge entity in the context, as it bridges between the known entity Yahoo! and the intended answer California. We observe that in fact many of the questions one would be interested in involve such bridge entities in some way.
For example, consider the following question: Which team does the player named 2015 Diamond Head Classic’s MVP play for?
In this question, we can first ask ourselves who the 2015 Diamond Head Classic’s MVP is, before looking up which team that player is currently playing for. In this question, the MVP player (Buddy Hield) serves as the bridge entity that leads us to the answer. The subtle difference from how we reasoned in the Yahoo! case is that here Buddy Hield is the answer to part of the original question, whereas Stanford University isn’t.

One could also easily conjure up interesting questions where the bridge entity is the answer, for instance: Which movie featuring Ed Harris is based on a French novel? (The answer is Snowpiercer.)
Obviously, these bridge entity questions probably don’t cover all of the interesting questions one could try to answer by reasoning over multiple facts collected on Wikipedia. In HotpotQA, we include a new type of questions – comparison questions – to represent a more diverse set of reasoning skills and language understanding capabilities.
We have already seen one example of a comparison question: does Stanford have more computer science researchers or Carnegie Mellon University?
To successfully answer these questions, a QA system needs to be able to not only find the relevant supporting facts (in this case, how many computer science researchers Stanford and CMU have, respectively), but also to compare them in a meaningful way to yield the final answer. The latter could prove quite challenging for current QA systems, as our analysis of the dataset show, because it could involve numerical comparison, time comparison, counting, and even simple arithmetic.
The former problem of finding relevant supporting facts is not easy, either, and could even be more challenging. Although it is often relatively easy to locate the relevant facts for comparison questions, it is highly non-trivial for bridge entity questions.
In our experiments with a traditional information retrieval (IR) approach, which ranks all Wikipedia articles from most relevant to least relevant given the question as the query. As a result, we see that on average, out of the two paragraphs that are necessary to correctly answer the question (which we call the “gold paragraphs”), only about 1.1 can be found in the top 10 results. In the plot for IR rankings of gold paragraphs below, both the higher-ranking paragraph and the lower-ranking one exhibit a heavy tailed distribution.
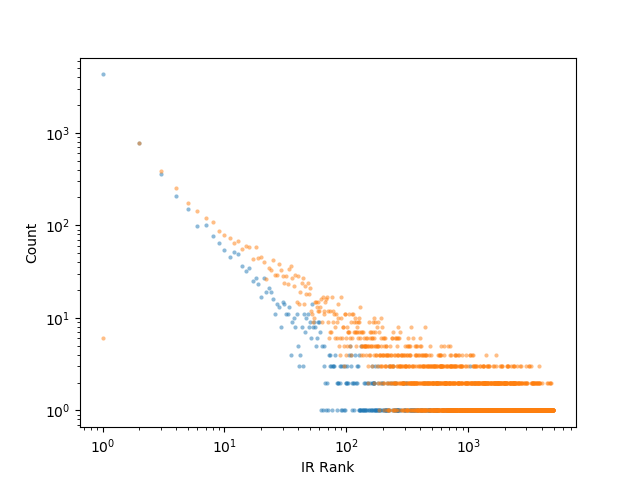
More specifically, while more than 80% of the higher-ranking paragraphs can be found in the Top 10 IR results, only less than 30% of the lower-ranking ones can be found in the same range.8 We calculated that if one naively reads all of the top ranked documents until both of the gold supporting paragraphs have been found, on average this amounts to reading about 600 documents to answer each question – and even after all that the algorithm still can’t reliably tell if we have indeed found both already!
This calls for new methods to tackle the problem of machine reading in the wild when multiple steps of reasoning are required, as progress in this direction will greatly facilitate the development of more effective information access systems.
Towards Explainable QA systems
Another important and desirable trait of good question answering systems is explainability. In fact, a QA system that simply spits out an answer with no explanation or demonstrations to help verify its answers is almost useless, because the user wouldn’t be able to trust its answers even if they appear to be correct most of the time. Unfortunately, this has been a problem with many state-of-the-art question answering systems.
To this end, when collecting the data for HotpotQA we also asked our annotators to specify the supporting sentences they used to arrive at the final answer, and released these as part of the dataset.
In the actual example below from the dataset, sentences in green serve as the supporting facts that underpin the answer (although through numerous steps of reasoning in this case). For more examples of (less dense) supporting facts, the reader is invited to view examples through the HotpotQA data explorer.
In our experiments, we have seen that these supporting facts not only allow humans to more easily check the answer provided by QA systems, but they also improve the performance of the systems themselves at finding the desired answer more accurately by providing the model with stronger supervision that previous question answering datasets in this direction lacked.
Final Thoughts
With the abundance of human knowledge recorded in writing, and more and more of it being digitized every second, we believe that there is immense value in integrating this knowledge with systems that automates the reading and reasoning and answers our questions, while maintaining an explainable interface to us. It is high time that we move beyond developing question answering systems that merely look at a few paragraphs and sentences, and answer questions with a black box implementation in a single turn that ends up mostly matching word patterns.
To this end, CoQA considers a series of questions that would arise in a natural dialog given a shared context, with challenging questions that require reasoning beyond one dialog turn; HotpotQA, on the other hand, focuses on multi-document reasoning, and challenges the research community to develop new methods to acquire supporting information in a large corpus.
We believe that both datasets will fuel significant development in question answering systems, and we look forward to new insights that these systems will bring to the community.
-
Danqi Chen, Adam Fisch, Jason Weston, Antoine Bordes. Reading Wikipedia to Answer Open-Domain Questions. ACL 2017. ↩
-
See, for instance, “Robin Jia and Percy Liang. Adversarial Examples for Evaluating Reading Comprehension Systems. EMNLP 2017.” ↩
-
In collaboration with our great collaborators from Carnegie Mellon University and Mila. ↩
-
Siva Reddy*, Danqi Chen*, and Christopher D. Manning. CoQA: A Conversational Question Answering Challenge. TACL 2019. (* indicates equal contribution) “CoQA” is pronounced as coca. ↩
-
https://github.com/google-research/bert ↩
-
At least they did not mention it as of the writing of this article. ↩
-
Zhilin Yang*, Peng Qi*, Saizheng Zhang*, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. EMNLP 2018. (* indicates equal contribution) ↩
-
And this is with 25% of the questions being comparison questions, where the names of both entities are specified in the question. ↩