When editing or revising we often write in a non-linear manner.
Writing an email
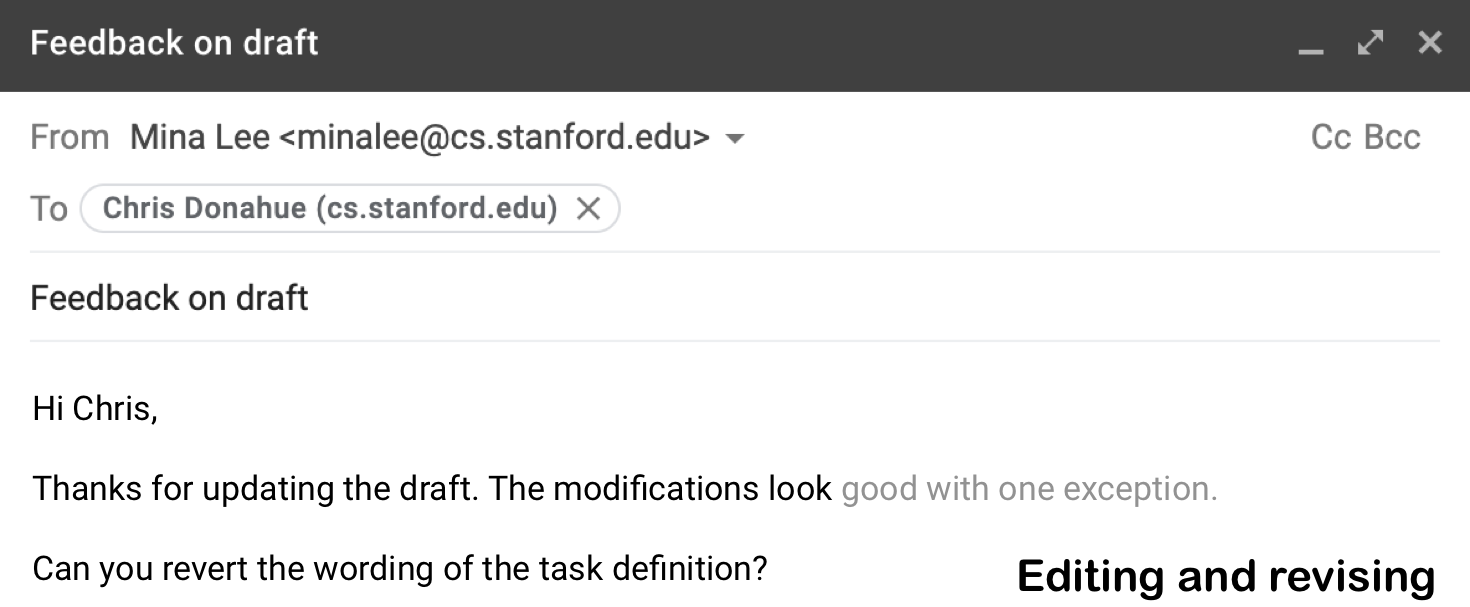
An existing system might suggest something like “great to me” because it only considers the preceding text but not the subsequent text.
A better suggestion in this case would be something like “good with one exception” since the writer is not completely satisfied and suggesting a further revision.
Writing a novel
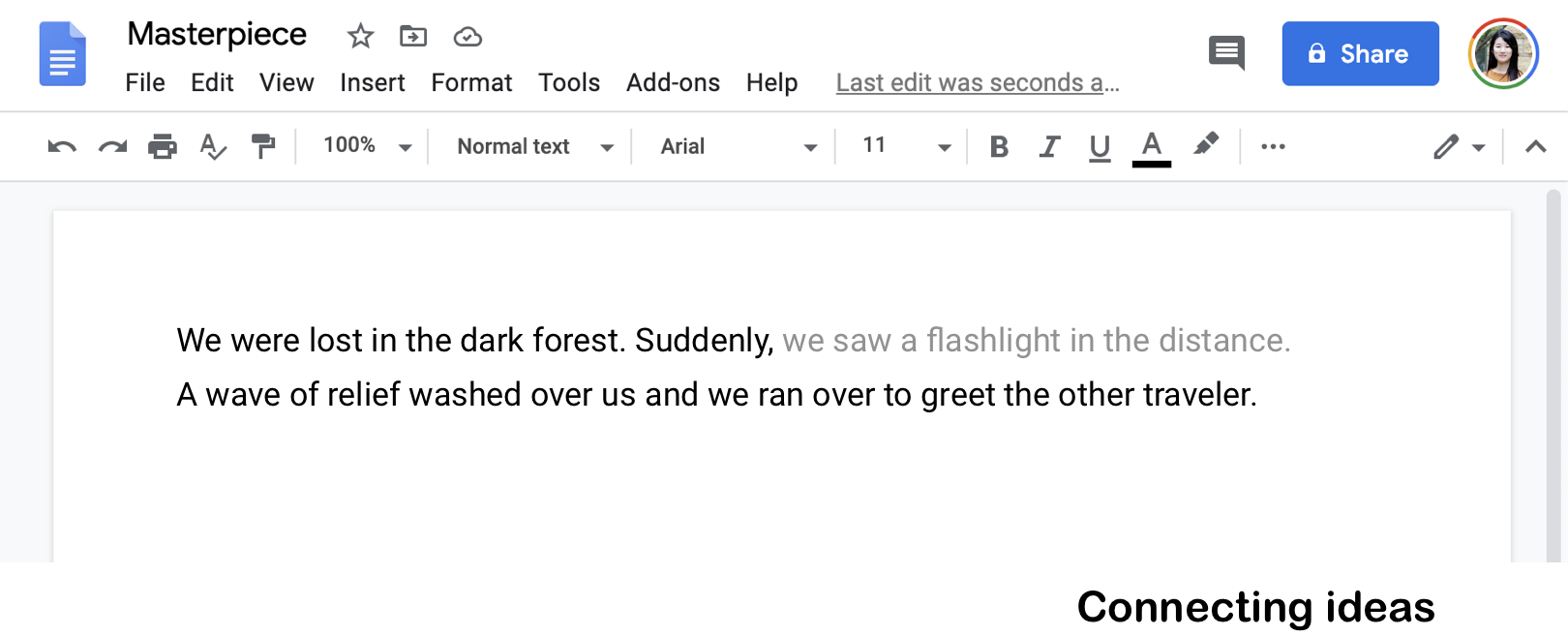
When you don’t have a concrete idea on how to connect two scenes, the system can suggest a way to connect the fragmented ideas.
Task
Fill in the blanks?
Consider the following sentence with blanks:
She ate ____ for ____
To fill in the blanks, one needs to consider both preceding and subsequent text (in this case, “She ate” and “for”). There can be many reasonable ways to fill in the blanks:
She ate leftover pasta for lunch
She ate chocolate ice cream for dessert
She ate toast for breakfast before leaving for school
She ate rather quickly for she was in a hurry that evening
The task of filling in the blanks is known as text infilling in the field of Natural Language Processing (NLP). It is the task of predicting blanks (or missing spans) of text at any position in text.
The general definition of text infilling considers text with an arbitrary number of blanks where each blank can represent one of more missing words.

Language models?
Language modeling is a special case of text infilling where only the preceding text is present and there is only one blank at the end.
She ate leftover pasta for ____
In recent few years, a number of large-scale language models are introduced and shown to achieve human-like performance. These models are often pre-trained on massive amount of unlabeled data, requiring huge amount of computation and resource.
Our goal is to take these existing language models and make them perform the more general task of filling in the blanks.
Approach
How can we make a language model fill in the blanks?
Our approach is infilling by language modeling. With this approach, one can simply (1) download an existing pre-trained language model and (2) enable it to fill in any number and length of blanks in text by fine-tuning it on artificially generated examples.
Main advantages of our framework are as follows:
- Conceptual simplicity: Minimal change to standard language model training
- Model-agnostic framework: Leverage massively pre-trained language models
Now, let’s see what happens at training and test time!
Training time
1. Manufacture infilling examples

Suppose we have plain text as our data:
Data: She ate leftover pasta for lunch.
To produce an infilling example for given data, first generate input by randomly replacing some tokens in the data with [blank] tokens.
Input: She ate [blank] for [blank].
Then, generate a target by concatenating the replaced tokens, separated by the [answer] token.
Target: leftover pasta [answer] lunch [answer]
Finally, construct the complete infilling example by concatenating input, a special separator token [sep], and target.
Infilling example: She ate [blank] for [blank]. [sep] leftover pasta [answer] lunch [answer]
Looking for a script to automate this step? It is available here!
2. Download your favorite language model
For instance, OpenAI GPT-2.
3. Fine-tune the model on infilling examples
Now, let’s fine-tune the model on the infilling examples using standard language model training methodology.
Test time
Once trained, we can use the language model to infill at test time.
As input, the model takes incomplete text with [blank] and generates a target.
Input: He drinks [blank] after [blank].
Target: water [answer] running [answer]
You can then construct the complete text by simply replacing [blank] tokens in the input with predicted answers in the target in a deterministic fashion.
Output: He drinks water after running.
Practical advantages
-
Our framework incurs almost no computational overhead compared to language modeling. This is particularly good when considering models like GPT-2 whose memory usage grows quadratically with sequence length.
-
Our framework requires minimal change to the vocabulary of existing language models. Specifically, you need three additional tokens: [blank], [answer], and [sep].
-
Our framework offers the ability to attend to the entire context on both sides of a blank with the simplicity of decoding from language models.
Evaluation
Turing test
The following is a short story consisting of five sentences. One of the sentences is swapped with a sentence generated by our model. Can you find it?
Q. Identify one of the five sentences generated by machine.
[1] Patty was excited about having her friends over. [2] She had been working hard preparing the food. [3] Patty knew her friends wanted pizza. [4] All of her friends arrived and were seated at the table. [5] Patty had a great time with her friends.
Q. Identify one of the five sentences generated by machine.
[1] Yesterday was Kelly’s first concert. [2] She was nervous to get on stage. [3] When she got on stage the band was amazing. [4] Kelly was then happy. [5] She couldn’t wait to do it again.
(Answers are at the end of the post.)
In our experiments, we sampled a short story from ROCstories (Mostafazadeh et al., 2016), randomly replaced one of the sentences with a [blank] token, and infilled with a sentence generated by a model. Then, we asked 100 people to identify which of the sentences in a story was machine-generated.
| System | How many people were fooled? | Generated sentence |
|---|---|---|
| BERT (Devlin et al., 2019) | 20% | favoritea “, Mary brightly said. |
| Self-Attention Model (Zhu et al., 2019) | 29% | She wasn’t sure she had to go to the store. |
| Standard Language Model (Radford et al., 2019) | 41% | She went to check the tv. |
| Infilling by Language Model (Ours) | 45% | Patty knew her friends wanted pizza. |
| Human | 78% | She also had the place looking spotless. |
The results show that people have difficulty identifying sentences infilled by our model as machine-generated 45% of the time. Generated sentences in the table are the system outputs for sentence [3] in the first story of the Turing test.
More experiments and analysis can be found in our paper.
Try it out!
We have a demo where you can explore the infilling functionality for multiple variable-length spans and different granularities (e.g. words, phrases, and sentences) on the domains of short stories, scientific abstracts, and song lyrics!
You can check out our paper on arXiv and our source code on GitHub. You can also find a short talk on this work here. If you have questions, please feel free to email us!
- Chris Donahue cdonahue@cs.stanford.edu
- Mina Lee minalee@cs.stanford.edu
- Percy Liang pliang@cs.stanford.edu
Answers: [3] and [3]