The Benefits and Bounds of Self-Supervised Pretraining
Deep learning is data hungry. Neural networks sometimes require millions of human-labeled data points to perform well, making it hard for the average person or company to train these models. This constraint keeps many important applications out of reach, including for rare diseases, low-resource languages, or even developers who want to train models on their own custom datasets.
Fortunately, self-supervised pretraining has recently come to the rescue. These algorithms teach models to learn from large amounts of raw data without requiring humans to label each data point. The resulting models need drastically fewer labeled examples to achieve the same performance on a particular task.
But currently, the pretraining methods used for different kinds of data are all distinct. Since new domains require new algorithms, pretraining is still underexplored in many high-impact domains, including healthcare, astronomy, and remote sensing, as well as multimodal settings that involve learning the relationships between different modalities, like language and vision.
Learning Views for Contrastive Learning
In our ICLR 2021 paper, we make progress on this problem by developing viewmaker networks, a single algorithm which enables competitive or superior pretraining performance on three diverse modalities: natural images, speech recordings, and wearable sensor data.
At its core, our method extends a number of view-based pretraining methods in computer vision. In this family of methods, depicted below, the network’s goal is to tell whether two distorted examples—known as views—were produced from the same original data point. These methods include contrastive learning methods such as SimCLR, MoCo, and InstDisc, along with non-contrastive algorithms like BYOL and SwAV.
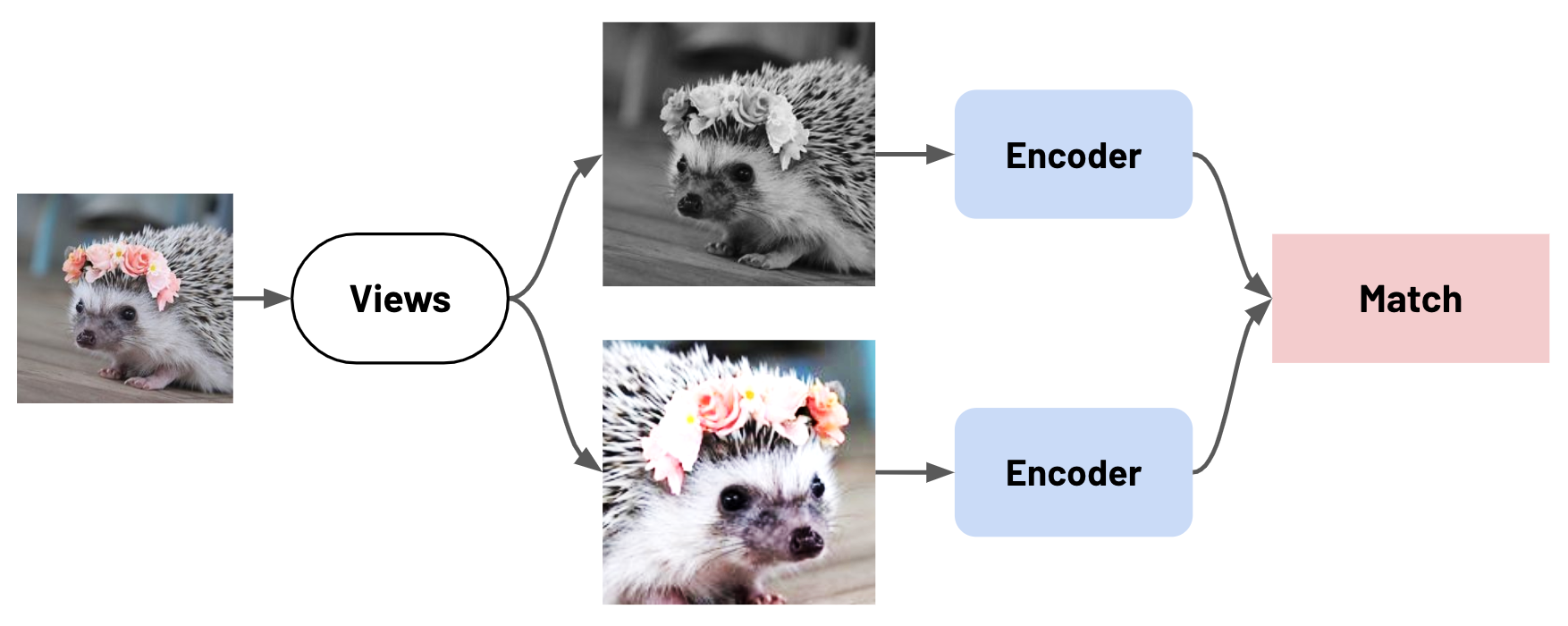
A key challenge for these methods is determining what kinds of views to produce from an input—since this determines how hard the task will be for the network, along with what capabilities the network will need to learn as it solves it. In computer vision, for example, the views are carefully-chosen combinations of image-specific data augmentation functions—such as cropping, blurring, and changes in hue, saturation, brightness, and contrast. Selecting views is currently more an art than a science, and requires both domain expertise and trial and error.
In our work, we train a new generative model—called a viewmaker network—to learn good views, without extensive hand tuning or domain knowledge. Viewmaker networks enable pretraining on a wide range of different modalities, including ones where what makes a good view is still unknown. Remarkably, even without the benefits of domain knowledge or carefully-curated transformation functions, our method produces models with comparable or superior transfer learning accuracy to handcrafted views on the three diverse domains we consider! This suggests that viewmaker networks may be an important step towards general pretraining methods that work across modalities.
A Stochastic Bounded Adversary
At its core, a viewmaker network is a stochastic bounded adversary. Let’s break these terms down, one at a time:
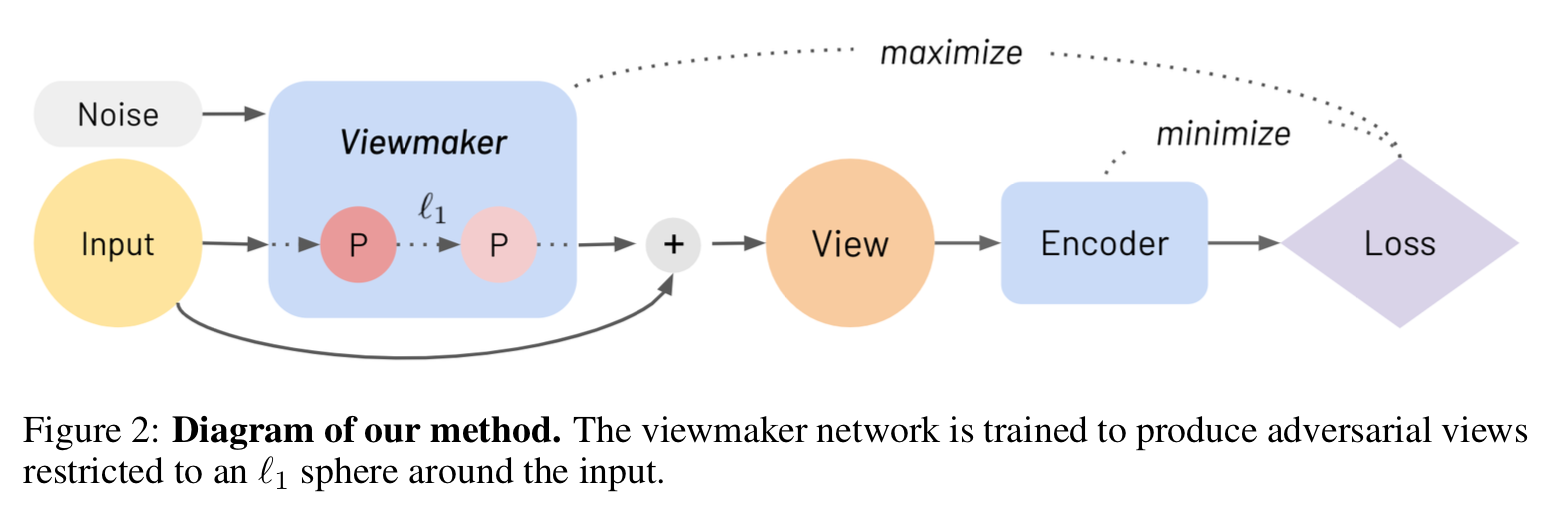
Stochastic: Viewmaker networks accept a training example and a random noise vector, and output a perturbed input. Stochasticity enables the network to learn an infinite number of different views to apply to the input during pretraining.
Bounded: The perturbations applied to an input shouldn’t be too large in magnitude—otherwise the pretraining task would be impossible. Because of this, the viewmaker network perturbations are bounded in strength.
But how can we control the strength of a perturbation in a domain-agnostic way? We use a simple L1-norm bound on the input—this gives the viewmaker the flexibility to make either strong changes to a small part of an input, or weaker transformations to a larger part. In practice, we train the viewmaker to directly output a delta—the difference to the eventual perturbation—which is added to the input after being scaled to an L1 radius.
This radius, or “distortion budget,” is tuned as a hyperparameter, but we found a single setting to work well across the three different modalities we considered.
Adversary: What objective function should the viewmaker have? We train it adversarially—in other words, the viewmaker tries to increase the contrastive loss of the encoder network (e.g. SimCLR or InstDisc) as much as possible given the bounded constraint. Unlike GANs, which are known to suffer from training instability, we find viewmakers to be easier to train—perhaps because perturbing the data is a less challenging task than generating it.
Visualizing the Learned Views
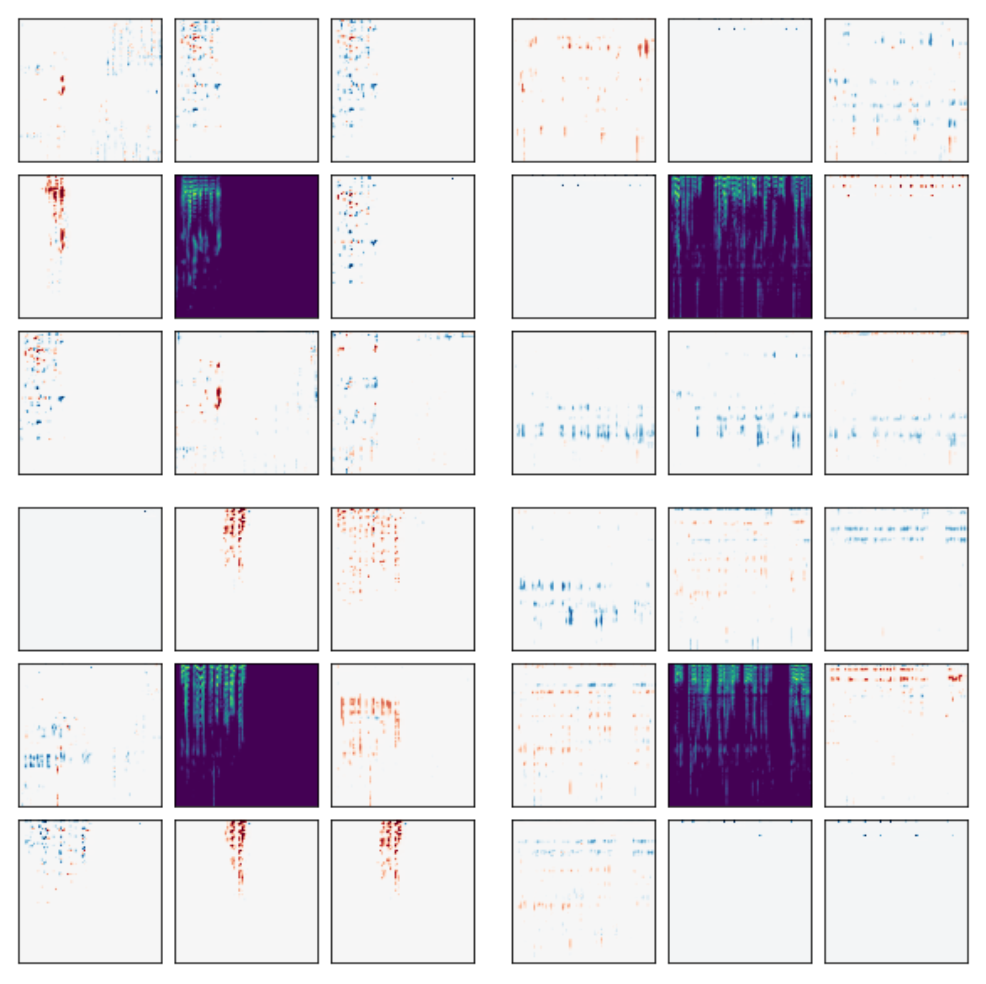
Here are example perturbations for two of the different modalities we consider: natural images (left) and speech recordings (right). The center square shows a training example, while the outer images show the scaled perturbation generated by the viewmaker. The images show the diversity of views learned for a single input, as well as how the viewmaker network tailors the perturbations to the input image.

Performance on Transfer Tasks
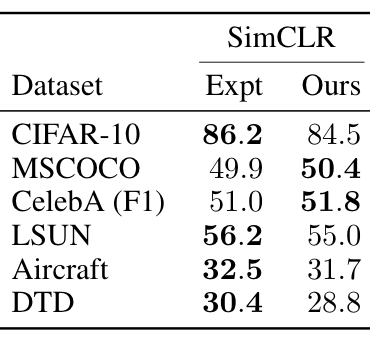
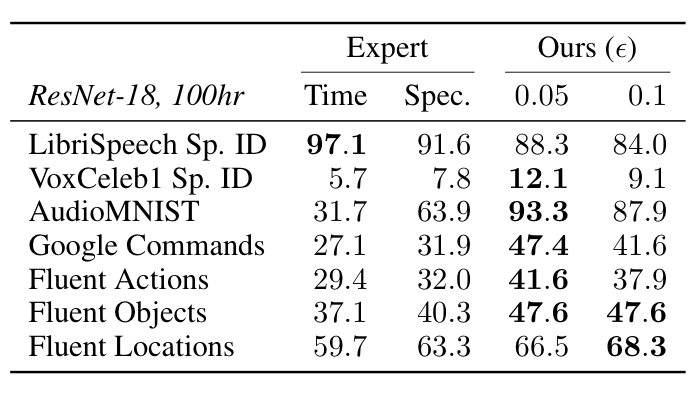
Remarkably, despite not requiring domain-specific assumptions, viewmaker networks match the performance of expert-tuned views used for images, as measured by performance on a range of transfer tasks. Furthermore, they outperform common views used for spectrograms (e.g. SpecAugment) when pretraining on speech and sensor data—improving transfer accuracy by +9% and +17% points, resp. on average. This suggests viewmakers may be an important ingredient for developing pretraining methods that work across modalities. The tables below show linear evaluation accuracies on image, audio, and wearable sensor datasets (in that order). See the paper for more details.

Conclusion & Future Work
Viewmaker networks untether contrastive learning from a particular set of domain-specific augmentations, resulting in a more general pretraining method. Our results show that viewmakers enable strong pretraining performance on three diverse modalities, without requiring handcrafted expertise or domain knowledge for each domain.
In terms of future work, we’re excited to see viewmakers applied to other domains, either by themselves or as a way to supplement existing handcrafted views. We’re also excited by potential applications of viewmakers to supervised learning and robustness research. Please check out our repo for code and the paper for more details!