Publications
ArtEmis: Affective Language for Visual Art [Oral]
Conference Paper Conference on Computer Vision and Pattern Recognition, 2021, Virtual.

Abstract
We present a novel large-scale dataset and accompanying machine learning models aimed at providing a detailed understanding of the interplay between visual content, its emotional effect, and explanations for the latter in language. In contrast to most existing annotation datasets in computer vision, we focus on the affective experience triggered by visual artworks and ask the annotators to indicate the dominant emotion they feel for a given image and, crucially, to also provide a grounded verbal explanation for their emotion choice. As we demonstrate below, this leads to a rich set of signals for both the objective content and the affective impact of an image, creating associations with abstract concepts (e.g., "freedom" or "love"), or references that go beyond what is directly visible, including visual similes and metaphors, or subjective references to personal experiences. We focus on visual art (e.g., paintings, artistic photographs) as it is a prime example of imagery created to elicit emotional responses from its viewers. Our dataset, termed ArtEmis, contains 455K emotion attributions and explanations from humans, on 80K artworks from WikiArt. Building on this data, we train and demonstrate a series of captioning systems capable of expressing and explaining emotions from visual stimuli. Remarkably, the captions produced by these systems often succeed in reflecting the semantic and abstract content of the image, going well beyond systems trained on existing datasets.
Long Tail Visual Relationship Recognition with Hubless Regularized Relmix
Conference Paper International Conference on Computer Vision, 2021, Virtual.

Abstract
Scaling up the vocabulary and complexity of current visual understanding systems is necessary in order to bridge the gap between human and machine visual intelligence. However, a crucial impediment to this end lies in the difficulty of generalizing to data distributions that come from real-world scenarios. Typically such distributions follow Zipf's law which states that only a small portion of the collected object classes will have abundant examples (head); while most classes will contain just a few (tail). In this paper, we propose to study a novel task concerning the generalization of visual relationships that are on the distribution's tail, i.e. we investigate how to help AI systems to better recognize rare relationships like <S:dog, P:riding, O:horse>, where the subject S, predicate P, and/or the object O come from the tail of the corresponding distributions. To achieve this goal, we first introduce two large-scale visual-relationship detection benchmarks built upon the widely used Visual Genome and GQA datasets. We also propose an intuitive evaluation protocol that gives credit to classifiers who prefer concepts that are semantically close to the ground truth class according to wordNet- or word2vec-induced metrics. Finally, we introduce a visiolinguistic version of a Hubless loss which we show experimentally that it consistently encourages classifiers to be more predictive of the tail classes while still being accurate on head classes.
ReferIt3D: Neural Listeners for Fine-Grained Object Identification in Real-World 3D Scenes [Oral]
Conference Paper European Conference on Computer Vision, 2020, Virtual.
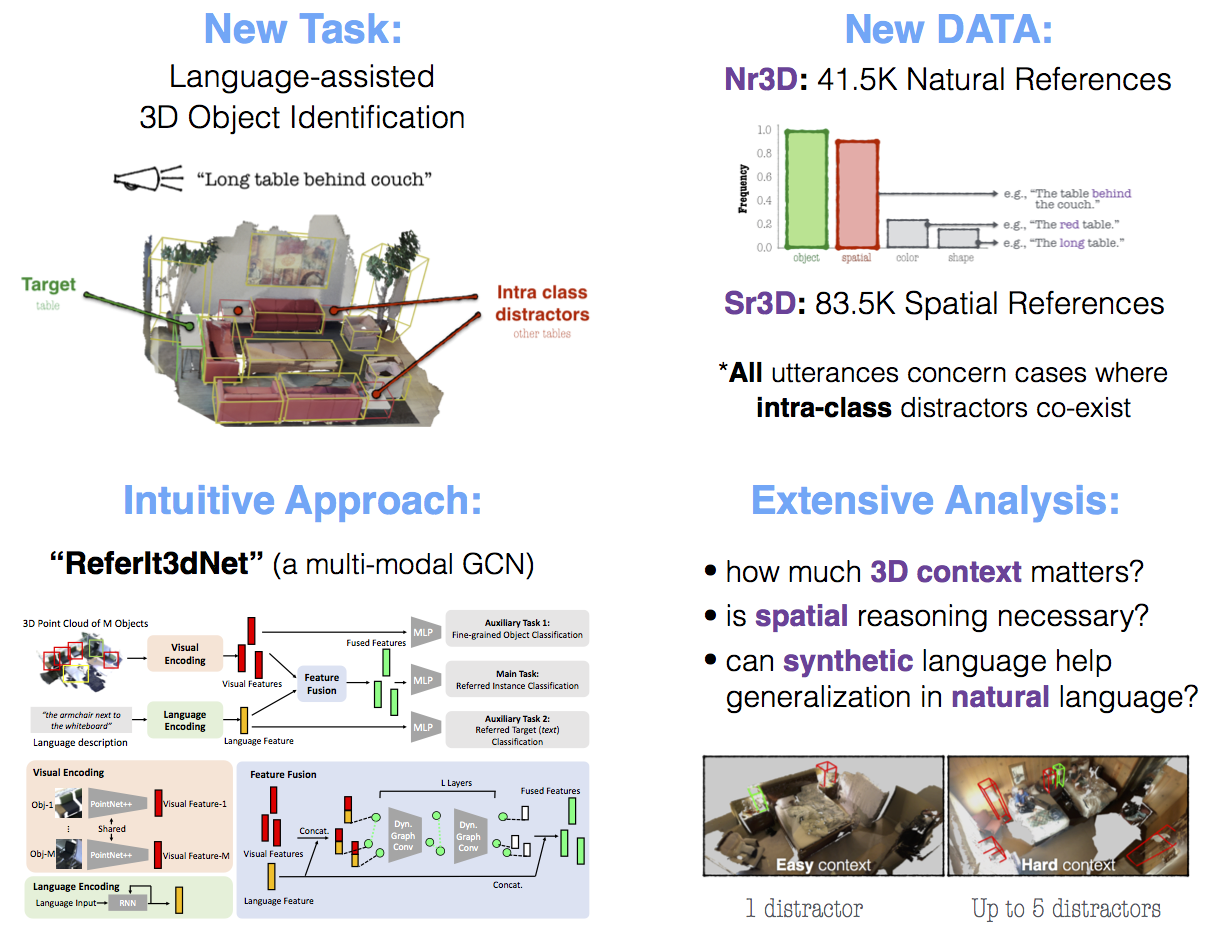
Abstract
In this work we study the problem of using referential language to identify common objects in real-world 3D scenes. We focus on a challenging setup where the referred object belongs to a fine-grained object class and the underlying scene contains multiple object instances of that class. Due to the scarcity and unsuitability of existent 3D-oriented linguistic resources for this task, we first develop two large-scale and complementary visio-linguistic datasets: i) Sr3D, which contains 83.5K template-based utterances leveraging spatial relations among fine-grained object classes to localize a referred object in a scene, and ii) Nr3D which contains 41.5K natural, free-form, utterances collected by deploying a 2-player object reference game in 3D scenes. Using utterances of either datasets, human listeners can recognize the referred object with high (>86%, 92\% resp.) accuracy. By tapping on this data, we develop novel neural listeners that can comprehend object-centric natural language and identify the referred object directly in a 3D scene. Our key technical contribution is designing an approach for combining linguistic and geometric information (in the form of 3D point clouds) and creating multi-modal (3D) neural listeners. We also show that architectures which promote object-to-object communication via graph neural networks outperform less context-aware alternatives, and that fine-grained object classification is a bottleneck for language-assisted 3D object identification.
DeformSyncNet: Deformation Transfer via Synchronized Shape Deformation Spaces
Conference Paper SIGGRAPH Asia, 2020, Virtual.
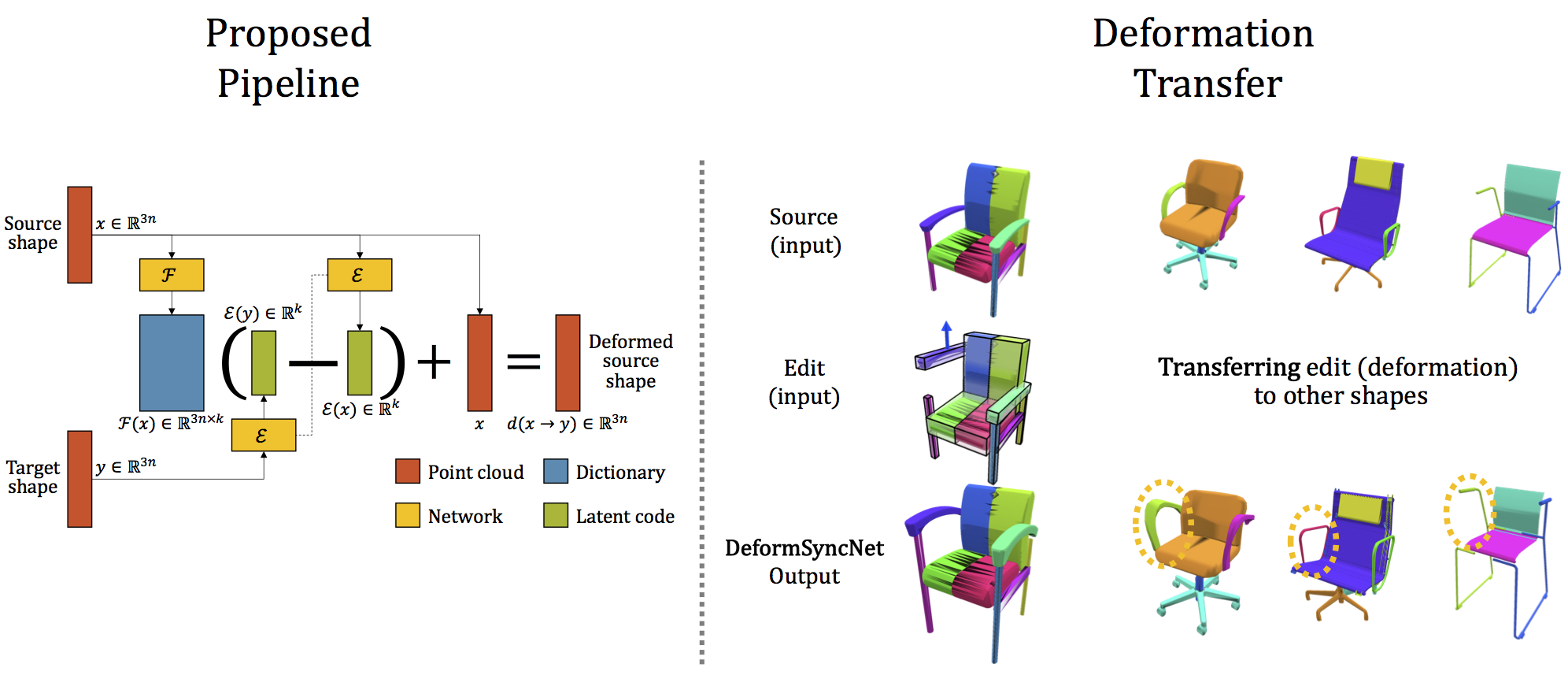
Abstract
Shape deformation is an important component in any geometry processing toolbox. The goal is to enable intuitive deformations of single or multiple shapes, or to transfer example deformations to new shapes, while preserving the plausibility of the deformed shape(s). Existing approaches assume access to point-level or part-level correspondence, or establish them in a preprocessing phase, thus limiting the scope and generality of such approaches. We propose DeformSyncNet, a new approach that allows consistent and synchronized shape deformations, without requiring explicit correspondence information. Technically, we achieve this by encoding deformations into a class-specific idealized latent space, while decoding them into an individual, model-specific linear deformation action space, operating directly in 3D. The underlying encoding and decoding is performed by specialized (jointly trained) neural networks. By design, the inductive bias of our networks results in a deformation space with several desirable properties, such as path invariance across different deformation pathways, which are then also approximately preserved in real space. We qualitatively and quantitatively evaluate our framework against multiple alternative approaches and demonstrate improved performance.Towards a Principled Evaluation of Likability for Machine-Generated Art
Workshop PaperConference on Neural Information Processing Systems (NeurIPS), Machine Learning for Creativity and Design Workshop, 2019, Montréal.

Abstract
Creativity is a cornerstone of human intelligence and perhaps its most complex aspect. Currently, an increasing number of visual artists and fashion designers is experimenting with Machine-Generated (MG) art. It is thus interesting to understand how such experts perceive these novel art forms. For instance, do painters actually like MG paintings? Can they tell them apart from human-made ones? In this preliminary study we collect and analyze responses on such questions from various contemporary artists and compare them to those given by non-experts. Our analysis highlights the importance of considering artists’ opinion when evaluating machine generated art.
ShapeGlot: Learning Language for Shape Differentiation
Conference Paper International Conference on Computer Vision, 2019, Seoul.
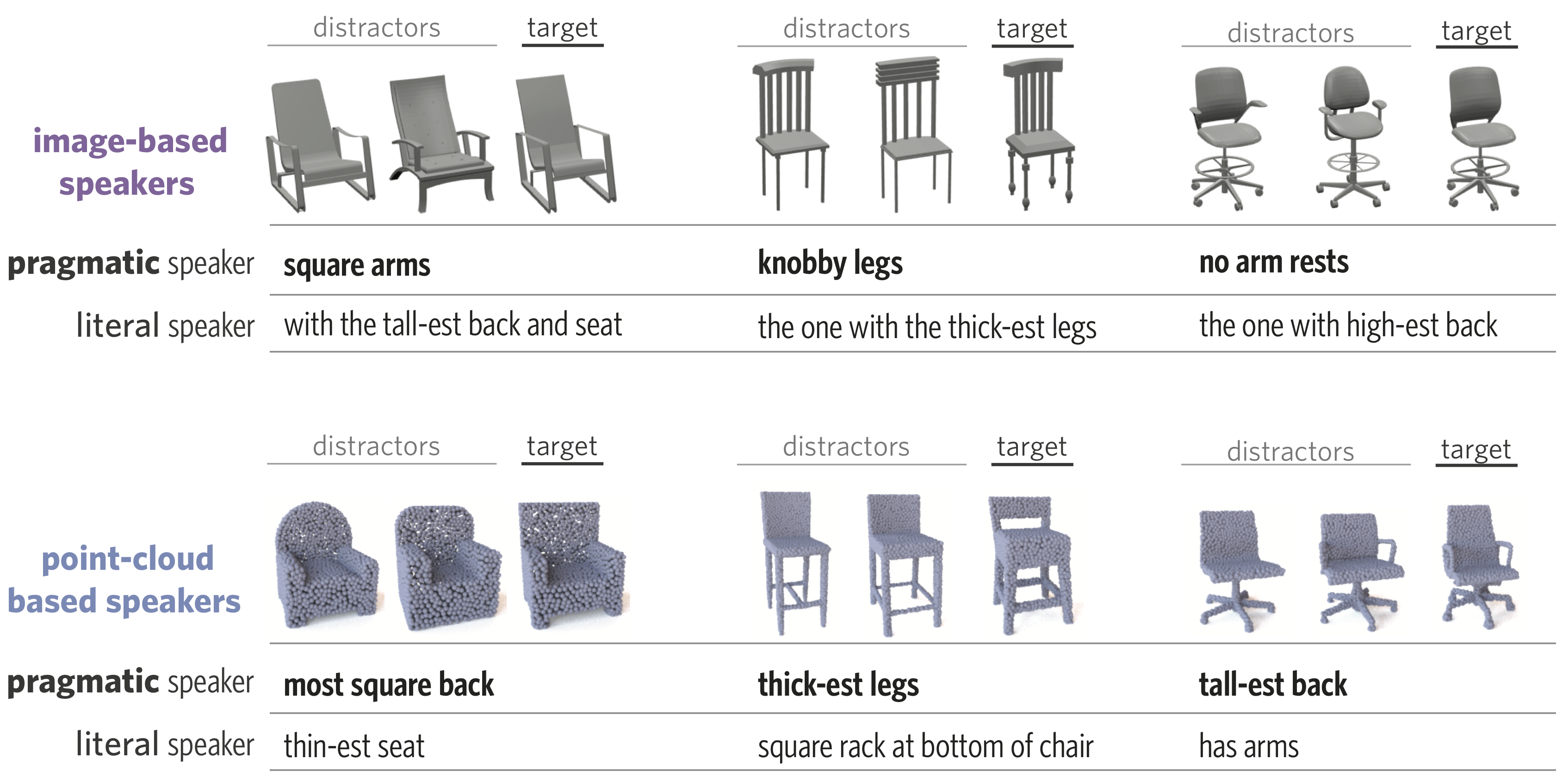
Abstract
People understand visual objects in terms of parts and their relations. Language for referring to objects can reflect this structure, allowing us to indicate fine-grained shape differences. In this work we focus on grounding referential language in the shape of common objects. We first build a large scale, carefully controlled dataset of human utterances that each refer to a 2D rendering of a 3D CAD model within a set of shape-wise similar alternatives. Using this dataset, we develop neural language understanding and production models that vary in their grounding (pure 3D forms via point-clouds vs. rendered 2D images), the degree of pragmatic reasoning captured (e.g. speakers that reason about a listener or not), and the neural architecture (e.g. with or without attention). We find models that perform well with both synthetic and human partners, and with held out utterances and objects. We also find that these models have surprisingly strong generalization capacity to novel object classes (e.g. transfer from training on chairs to test on lamps), as well as to real images drawn from furniture catalogs. Lesion studies suggest that the neural listeners depend heavily on part-related words and associate these words correctly with visual parts of objects (without any explicit training on object parts), and that transfer to novel classes is most successful when known part-words are available. This work illustrates a practical approach to language grounding, and provides a case study in the relationship between object shape and linguistic structure when it comes to object differentiation.
OperatorNet: Recovering 3D Shapes From Difference Operators
Conference PaperInternational Conference on Computer Vision, 2019, Seoul.
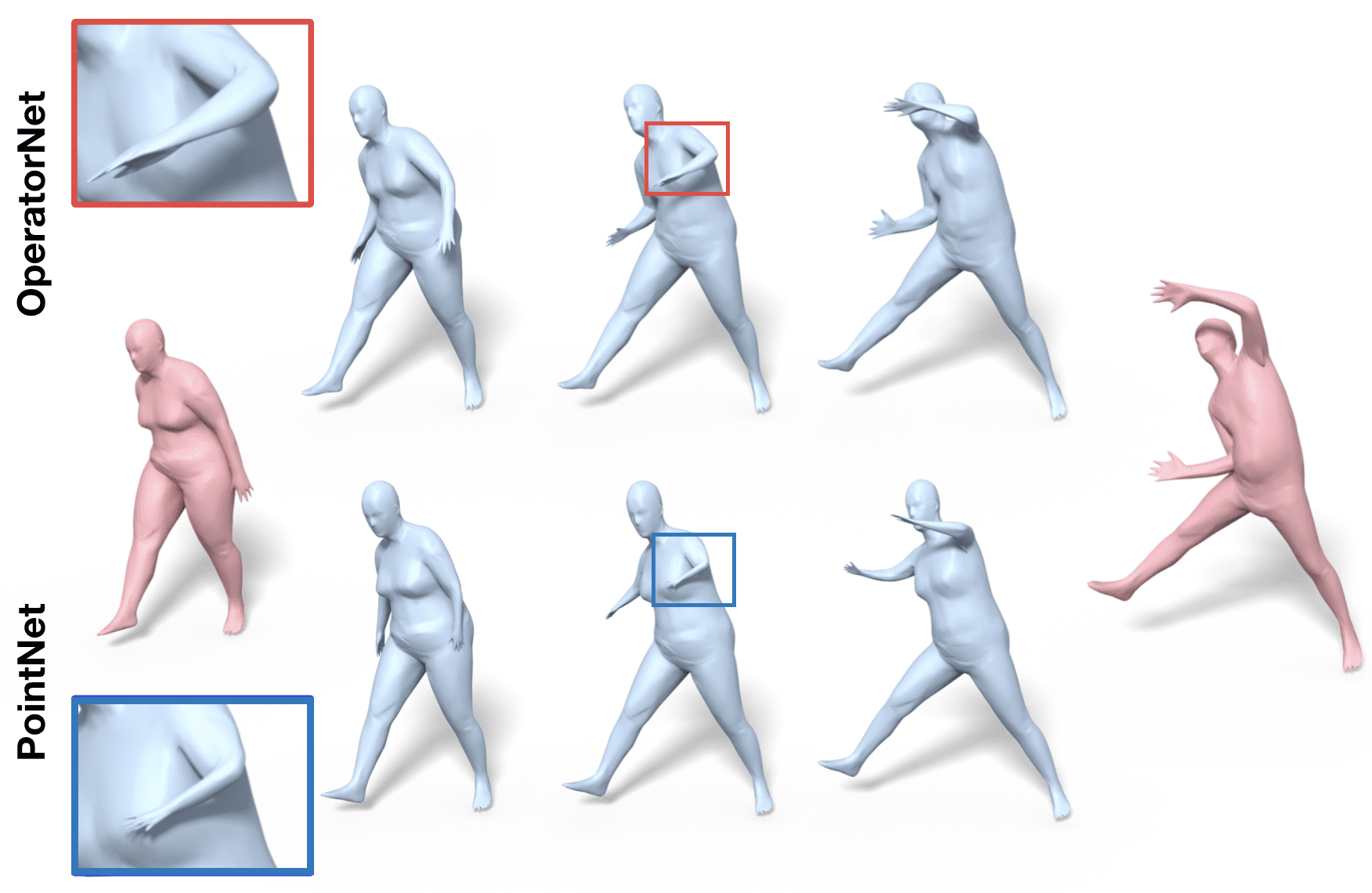
Abstract
This paper proposes a learning-based framework for reconstructing 3D shapes from functional operators, compactly encoded as small-sized matrices. To this end we introduce a novel neural architecture, called OperatorNet , which takes as input a set of linear operators representing a shape and produces its 3D embedding. We demonstrate that this approach significantly outperforms previous purely geometric methods for the same problem. Furthermore, we introduce a novel functional operator, which encodes the extrinsic or pose-dependent shape information, and thus complements purely intrinsic pose-oblivious operators, such as the classical Laplacian. Coupled with this novel operator, our reconstruction network achieves very high reconstruction accuracy, even in the presence of incomplete information about a shape, given a soft or functional map expressed in a reduced basis. Finally, we demonstrate that the multiplicative functional algebra enjoyed by these operators can be used to synthesize entirely new unseen shapes, in the context of shape interpolation and shape analogy applications.
Composite Shape Modeling via Latent Space Factorization
Conference PaperInternational Conference on Computer Vision, 2019, Seoul.
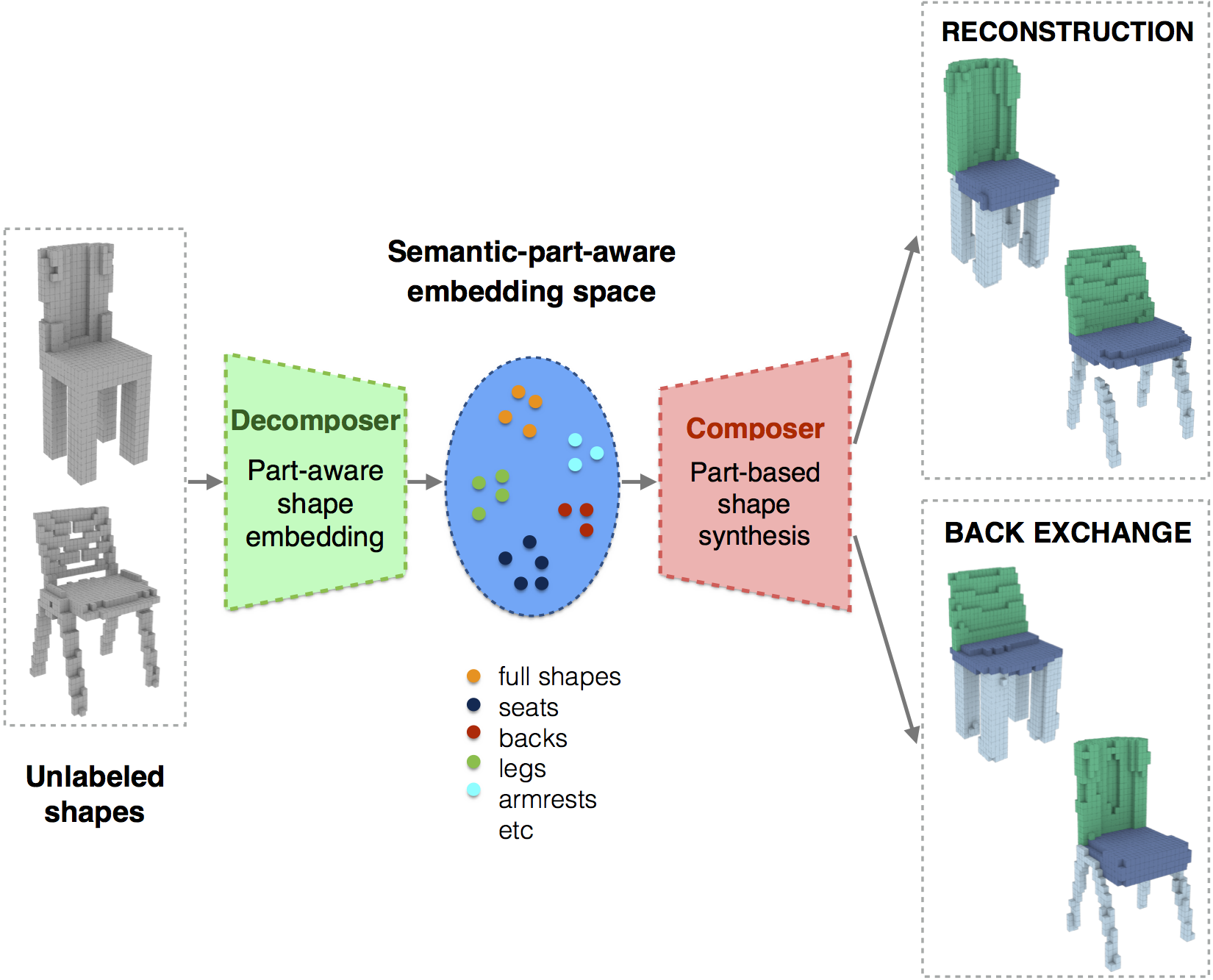
Abstract
We present a novel neural network architecture, termed Decomposer-Composer, for semantic structure-aware 3D shape modeling. Our method utilizes an auto-encoder-based pipeline and produces a novel factorized shape embedding space, where the semantic structure of the shape collection translates into a data-dependent sub-space factorization, and where shape composition and decomposition become simple linear operations on the embedding coordinates. We further propose to model shape assembly using an explicit learned part deformation module, which utilizes a 3D spatial transformer network to perform an in-network volumetric grid deformation, and which allows us to train the whole system end-to-end. The resulting network allows us to perform part-level shape manipulation, unattainable by existing approaches. Our extensive ablation study, comparison to baseline methods and qualitative analysis demonstrate the improved performance of the proposed method.
Limit Shapes – A Tool for Understanding Shape Differences and Variability in 3D Model Collections
Conference Paper Eurographics Symposium on Geometry Processing, 2019, Milan.
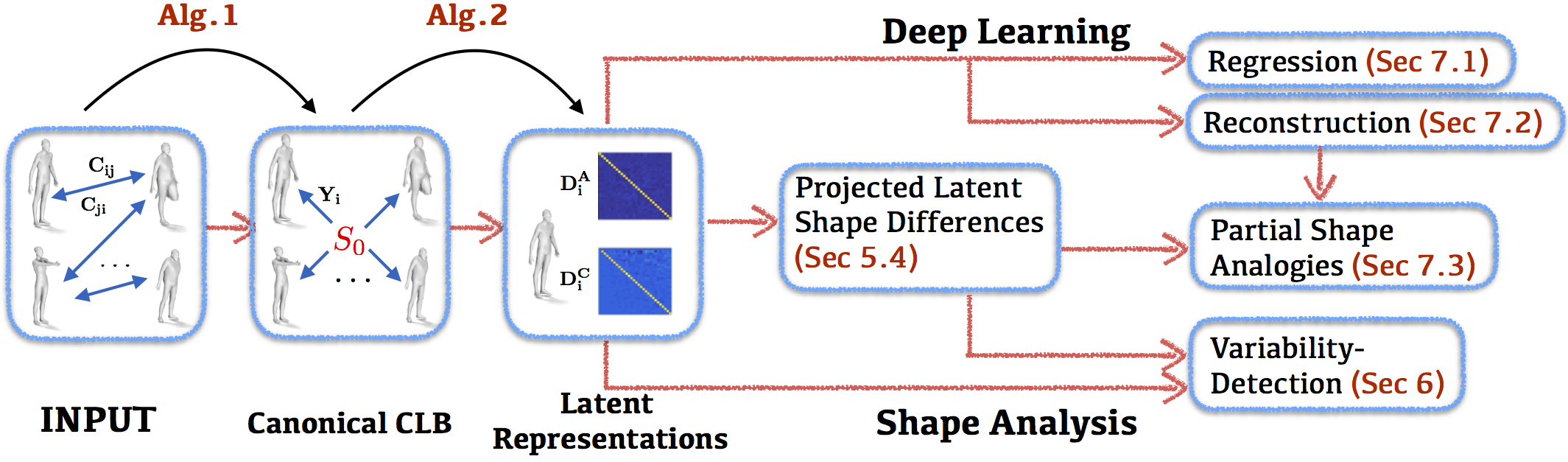
Abstract
We propose a novel construction for extracting a central or limit shape in a shape collection, connected via a functional map network. Our approach is based on enriching the latent space induced by a functional map network with an additional natural metric structure. We call this shape-like dual object the limit shape and show that its construction avoids many of the biases introduced by selecting a fixed base shape or template. We also show that shape differences between real shapes and the limit shape can be computed and characterize the unique properties of each shape in a collection – leading to a compact and rich shape representation. We demonstrate the utility of this representation in a range of shape analysis tasks, including improving functional maps in difficult situations through the mediation of limit shapes, understanding and visualizing the variability within and across different shape classes, and several others. In this way, our analysis sheds light on the missing geometric structure in previously used latent functional spaces, demonstrates how these can be addressed and finally enables a compact and meaningful shape representation useful in a variety of practical applications.
Learning Representations and Generative Models for 3D Point Clouds [Oral]
Conference Paper 35th International Conference on Machine Learning, 2018, Stockholm.

Abstract
Three-dimensional geometric data offer an excellent domain for studying representation learning and generative modeling. In this paper, we look at geometric data represented as point clouds. We introduce a deep AutoEncoder (AE) network with state-of-the-art reconstruction quality and generalization ability. The learned representations outperform existing methods on 3D recognition tasks and enable shape editing via simple algebraic manipulations, such as semantic part editing, shape analogies and shape interpolation, as well as shape completion. We perform a thorough study of different generative models including GANs operating on the raw point clouds, significantly improved GANs trained in the fixed latent space of our AEs, and Gaussian Mixture Models (GMMs). To quantitatively evaluate generative models we introduce measures of sample fidelity and diversity based on matchings between sets of point clouds. Interestingly, our evaluation of generalization, fidelity and diversity reveals that GMMs trained in the latent space of our AEs yield the best results overall.
Latent-space GANs for 3D Point Clouds
Workshop Paper 34th International Conference on Machine Learning, Implicit Models Workshop, 2017, Sydney.

Abstract
Three dimensional geometric data offer an excellent domain for studying representation learning and generative modeling. In this paper, we look at geometric data represented as point clouds. We introduce a deep autoencoder (AE) network for point-clouds, which outperforms the state of the art in 3D recognition tasks. We also design GAN architectures to generate novel point clouds. Most importantly, we show that by training the GAN in the latent space learned by the AE, we greatly boost the GAN’s data-generating capacity, creating significantly more diverse and realistic geometries, with far simpler architectures. The expressive power of our learned embedding, obtained without human supervision, enables basic shape editing applications via simple algebraic manipulations, such as semantic part editing and shape interpolation.
Stochastic Gradient Descent in Theory and Practice
Thesis Theory Qualifying Exam CS PhD Program, 2016, Stanford.
Abstract
Stochastic gradient descent (SGD) is the most widely used optimization method in the machine learning community. Researchers in both academia and industry have put considerable effort to optimize SGD’s runtime performance and to develop a theoretical framework for its empirical success. For example, recent advancements in deep neural networks have been largely achieved because, surprisingly, SGD has been found adequate to train them. Here we present three works highlighting desirable properties of SGD. We start with examples of experimental evidence for SGD’s efficacy in training deep and recurrent neural networks and the important role of acceleration and initialization. We then turn into theoretical work connecting a model’s trainability by SGD to its generalization. And, finally, we discuss a theoretical analysis explaining the dynamics behind the recently introduced versions of asynchronously executed SGD
Two-Locus Association Mapping in Subquadratic Time [Oral]
Conference Paper Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2011, San Diego.
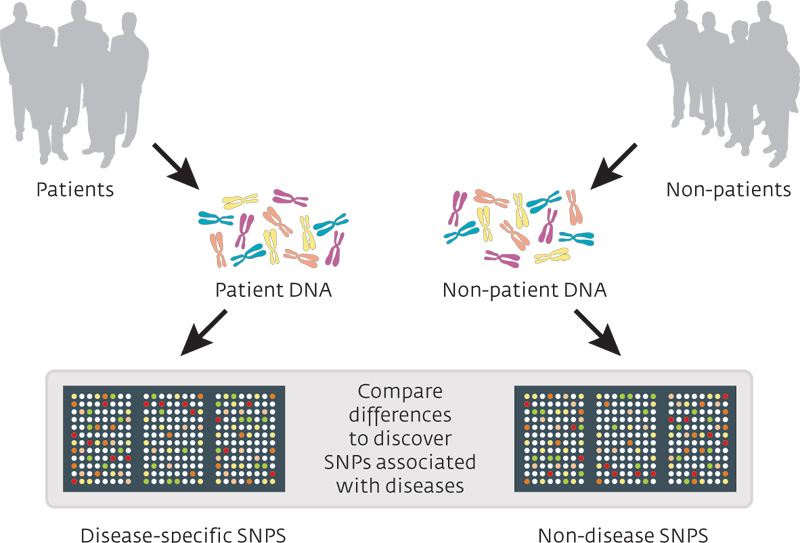
Abstract
Genome-wide association studies (GWAS) have not been able to discover strong associations between many complex human diseases and single genetic loci. Mapping these phenotypes to pairs of genetic loci is hindered by the huge number of candidates leading to enormous computational and statistical problems. In GWAS on single nucleotide polymorphisms (SNPs), one has to consider in the order of 10^10 to 10^14 pairs, which is infeasible in practice. In this article, we give the first algorithm for 2-locus genome-wide association studies that is subquadratic in the number, n, of SNPs. The running time of our algorithm is data-dependent, but large experiments over real genomic data suggest that it scales empirically as n^{3/2}. As a result, our algorithm can easily cope with n ~ 10^7, i.e., it can efficiently search all pairs of SNPs in the human genome.