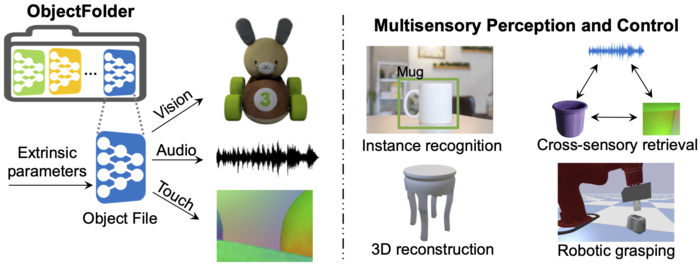
Multisensory object-centric perception, reasoning, and interaction have been a key research topic in recent years. However, the progress in these directions is limited by the small set of objects available--synthetic objects are not realistic enough and are mostly centered around geometry, while real object datasets such as YCB are often practically challenging and unstable to acquire due to international shipping, inventory, and financial cost. We present ObjectFolder, a dataset of 100 virtualized objects that addresses both challenges with two key innovations. First, ObjectFolder encodes the visual, auditory, and tactile sensory data for all objects, enabling a number of multisensory object recognition tasks, beyond existing datasets that focus purely on object geometry. Second, ObjectFolder employs a uniform, object-centric, and implicit representation for each object's visual textures, acoustic simulations, and tactile readings, making the dataset flexible to use and easy to share. We demonstrate the usefulness of our dataset as a testbed for multisensory perception and control by evaluating it on a variety of benchmark tasks, including instance recognition, cross-sensory retrieval, 3D reconstruction, and robotic grasping.
Qualitative Video
In the supplementary video, we show 1) the motivation and goal of our dataset; 2) visualization of the visual appearance for all 100 objects obtained from Object Files under different camera viewpoints or lighting conditions; 3) examples of the auditory data (impact sounds) obtained from Object Files for some sample objects; 4) examples of the tactile images obtained from Object Files when the DIGIT sensor touches different surface locations of some sample objects; 5) robotic grasping demos.
Publications
R. Gao, Y. Chang, S. Mall, L. Fei-Fei, J. Wu. "ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations". In CoRL, 2021. [Bibtex]
R. Gao, Z. Si, Y. Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, J. Wu. "ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer". In CVPR, 2022. [Bibtex][Paper][Project Page]
Acknowledgement
We thank Michelle Guo, Xutong Jin, Shaoxiong Wang, Huazhe Xu, and Samuel Clarke for helpful discussions on experiments setup and Michael Lingelbach and Jingwei Ji for suggestions on paper drafts. The work is in part supported by Toyota Research Institute (TRI), Samsung Global Research Outreach (GRO) program, ARMY MURI grant W911NF-15-1-0479, NSF CCRI #2120095, Amazon Research Award (ARA), Autodesk, Qualcomm, and Stanford Institute for Human-Centered AI (HAI).