This post was originally on Peng Qi’s website and has been replicated here (with minor edits) with permission.
TL;DR: The NLP community has made great progress on open-domain question answering, but our systems still struggle to answer complex questions over a large collection of text. We present an efficient and explainable method for enabling multi-step reasoning in these systems.
From search engines to automatic question answering systems, natural language processing (NLP) systems have drastically improved our ability to access knowledge stored in text, saving us countless hours spent memorizing facts and looking things up.

(Photo credit: Reeding Lessons @ Flickr (CC BY-SA-NC 2.0))
Today, whenever we have a question in mind, the answer is usually one Google/Bing search away. For instance, “Which U.S. state is the largest by area?”
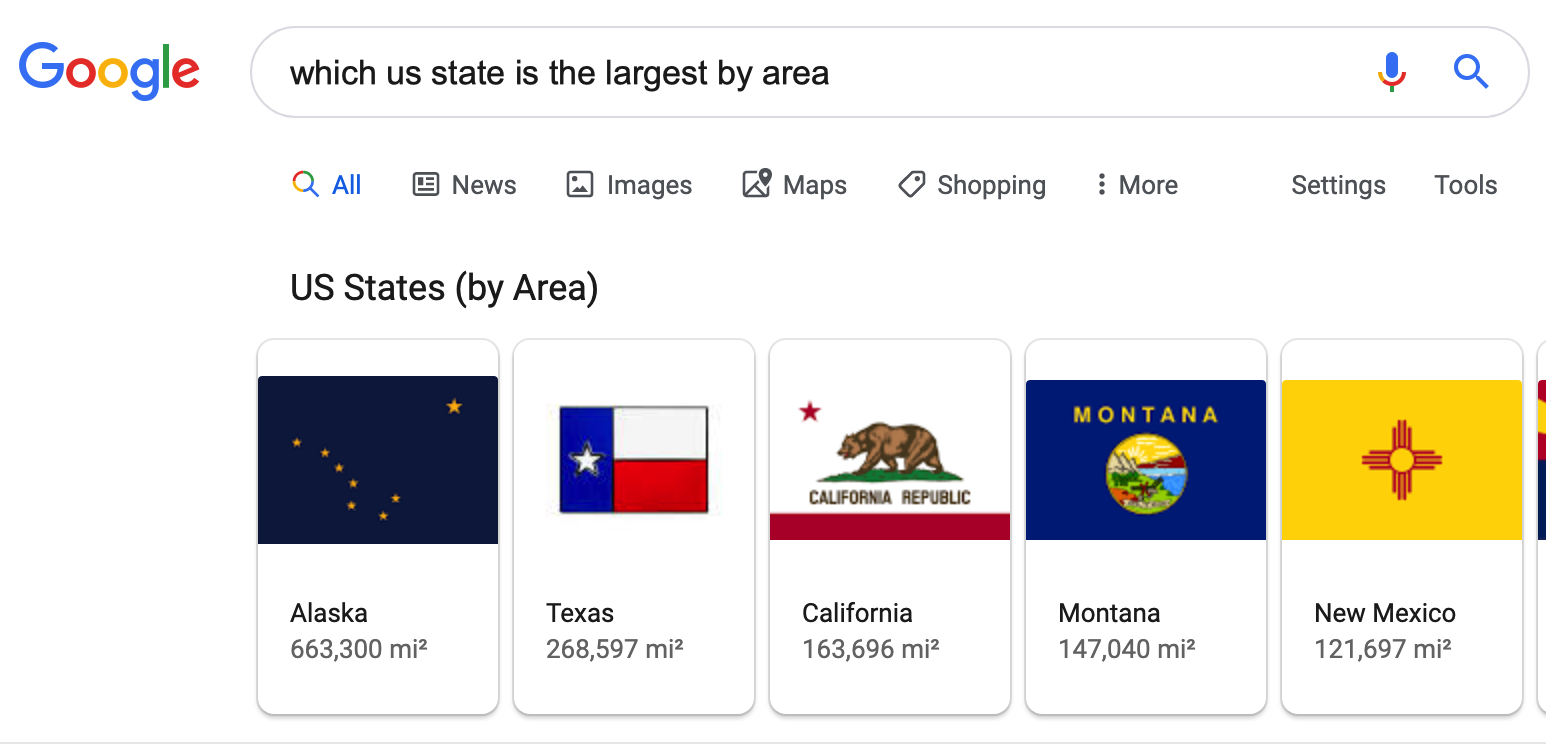
Other questions, however, are less straightforward. For example, “Who was the first to demonstrate that GPS could be used to detect seismic waves?” Google isn’t of much help if we were to directly type this question as a search query. On the other hand, the Internet’s encyclopedia, Wikipedia, does have an answer for us:
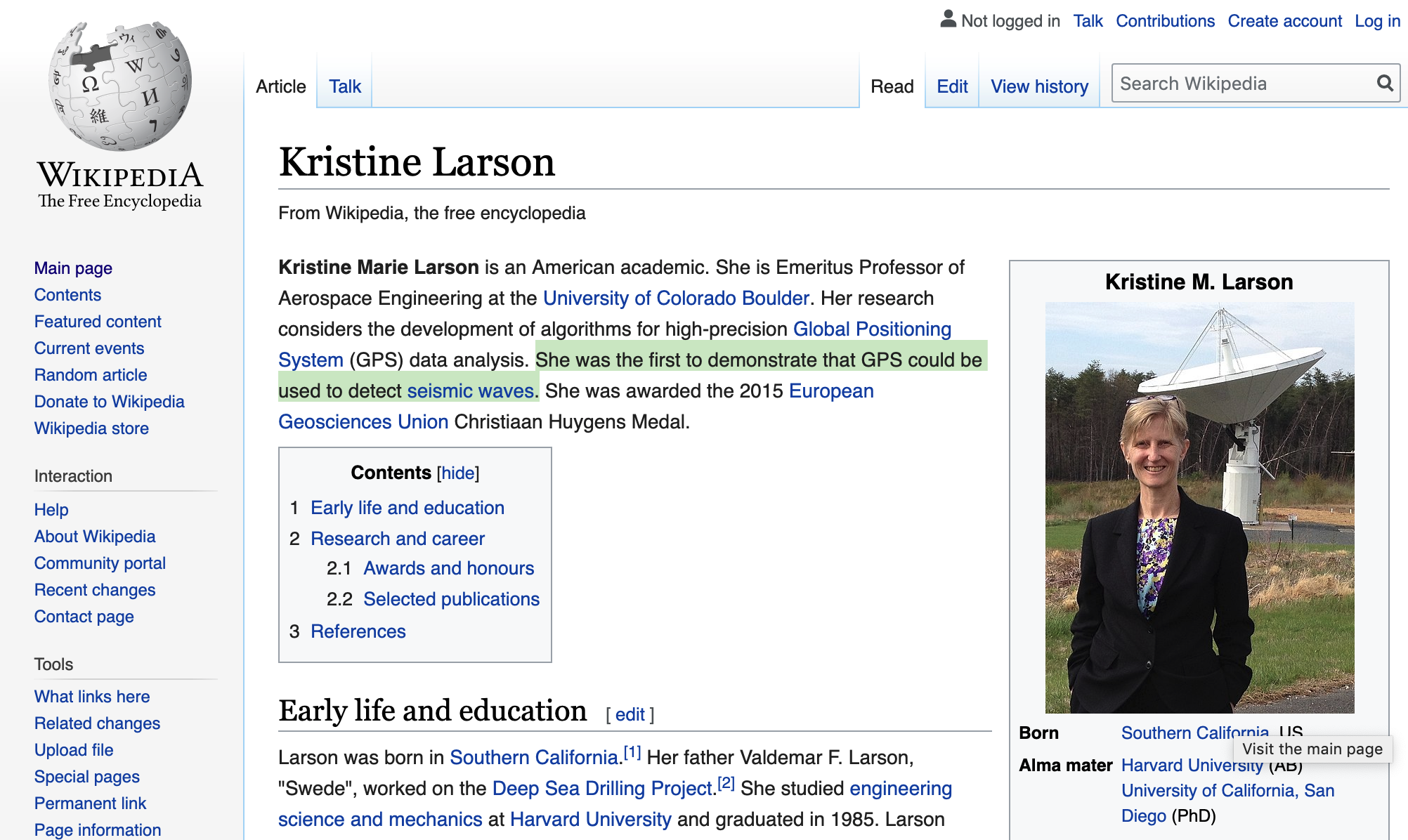
Wouldn’t it be nice if an NLP system could answer this question for us, without us having to find the article ourselves? This problem, called open-domain question answering (open-domain QA), is an active area of NLP research.
Background: Open-domain QA
Before diving into our new method for open-domain QA, let us first take a moment to understand the problem setup, challenges, and why existing solutions are not quite enough to answer complex questions.
Open-domain vs Closed-domain / Restricted-context
The first question answering systems built by NLP researchers, such as BASEBALL and LUNAR, were highly domain-specific. They were adept at answering questions about US baseball players over the period of one specific year and about lunar rocks brought back to Earth, but not terribly helpful beyond the domains they were built for. In other words, they are closed-domain.
Since then, researchers have moved towards tackling open-domain QA. In open-domain QA, the questions are not limited to predefined domains and domain knowledge; ideally, the system should be able to sift through a very large amount of text documents to find the answer for us.
Single-document open-domain QA (also known as reading comprehension) is one of the research areas seeing recent breakthroughs in natural language processing, where an NLP system is given a single document (or just a paragraph) that might contain the answer to a question, and is asked to answer the question based on this context. Take our Dr. Larson question for an example (“Who was the first to demonstrate that GPS could be used to detect seismic waves?”). A single-document QA system might be trained to answer this question given only the Wikipedia page “Kristine M. Larson”. This is the format of many popular question answering datasets used in the NLP community today, e.g., SQuAD.
Question answering systems trained on SQuAD are able to generalize to answering questions about personal biographies.

However, such systems cannot help us answer our question about Dr. Larson if we didn’t already know to look at her biography, which is quite limiting.
To solve this, researchers are developing question answering systems over large text collections. Instead of provided with the exact context necessary to answer the question, the system is required to sift through a collection of documents to arrive at the answer, much like how we search for answers on the web. This setting, called open-context open-domain QA, is much more challenging than reading comprehension. But, it is also a lot more useful when we have a question in mind but don’t really have a good idea where the answer might be from. The main challenge, besides those of restricted-context QA, is to narrow down the large collection of texts to a manageable amount with scalable approaches, such that we can run reading comprehension models to arrive at the answer.
Open-domain QA Systems
Inspired by the series of question answering competitions at the Text REtrieval Conference (TREC), researchers in recent years have started to look into adapting powerful neural-network-based QA models to the open-domain task.
Danqi Chen and collaborators first combined traditional search engines with modern, neural question answering systems to attack this problem. Their approach to open-domain QA, named DrQA, is simple and powerful: given a question, the system uses it to search a collection of documents for context documents that may contain the answer. Then, this reduced context is the input to a reading comprehension system, which predicts the final answer.
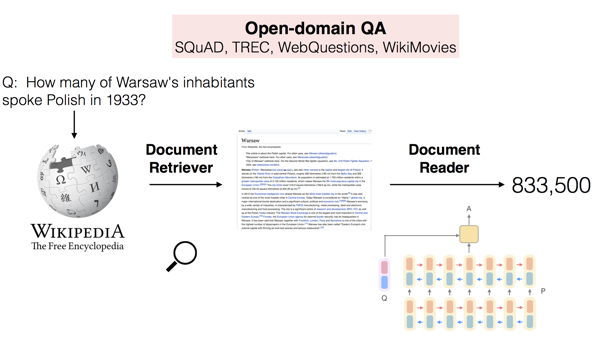
Most of the recent research in open-domain QA has largely followed this two-stage approach of retrieving and reading, with added features such as reranking (see, for example, (Wang et al., 2018)) and neural retrieval systems and better joint training (see, for example, (Das et al., 2019) and (Lee et al., 2019)).
The Challenge of Complex Open-domain Questions
All systems that follow this retrieve-and-read paradigm are ill-equipped to handle complex questions. Let’s walk through an illustrative example of why that is together.
We all forget the names of celebrities from time to time. Suppose, one day, you are curious: “What is the Aquaman actor’s next movie?” To answer this question, you would probably first search for “Aquaman” or “the Aquaman actor” to find out who he/she is. Hopefully after scrolling through a few top search results, you will realize the answer is “Jason Momoa”, and then move on to finding out what his next movie is.
In this simple example, not all of the supporting evidence needed to answer the question can be readily retrieved from the question alone, i.e., there’s a knowledge discovery problem to solve.1 This makes these questions difficult for retrieve-and-read open-domain QA systems, because there is usually some evidence that lack a strong semantic overlap with the question itself. Below is a sketch of the relations between the real-world entities that illustrate the multiple steps of reasoning required to answer this question.
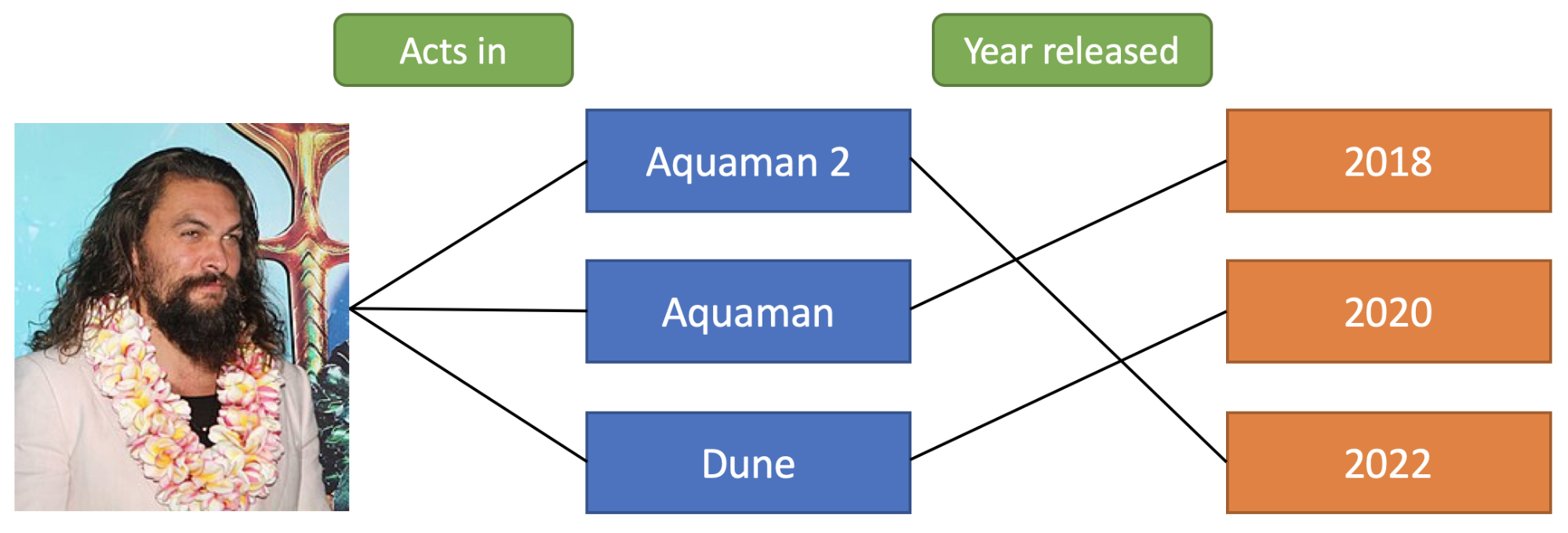
One solution to this problem might be to train neural retrieval and reading comprehension models jointly to update queries to find more evidence (Das et al. (2019) set out to do just that). While this might also work in our setting, pretraining the neural retriever with distant supervision to promote documents that contain the answer string will likely fail because of the missing semantic overlap between the question and all necessary documents. End-to-end training will also be prohibitively expensive, because the search space for queries beyond the first step of reasoning is enormous. Even if one manages to train a neural system to accomplish this task, the resulting system is probably very computationally inefficient and not very explainable.
So, can we build an open-domain QA system that is capable of handling complex, multi-step reasoning questions, and doing so in an efficient and explainable manner? We present such a system in our new EMNLP-IJCNLP paper – Answering Complex Open-domain Questions Through Iterative Query Generation.
Answering Complex Open-domain Questions
To introduce our system, we start with the overall strategy we use to address the problem of mutli-step reasoning in open-domain QA, before moving on to the dataset we evaluate our system on and experimental results.
Overall Strategy
As we have seen, retrieve-and-read systems can’t efficiently handle complex open-domain questions that require multiple steps of reasoning, because (a) these questions require multiple supporting facts to answer, and (b) it is usually difficult to find all supporting facts necessary with only the question. Ideally, we want a system to be able to iterate between “reading” the information retrieved and finding further supporting evidence if necessary, just like a human.
That is exactly where the “iterative query generation” part of the paper title comes into play. We propose an open-domain QA system that iteratively generates natural language queries based on the currently retrieved context and retrieves more information if needed before finally answering the question. This allows us to (a) retrieve multiple supporting facts with different queries, and (b) make use of documents retrieved in previous iterations to generate queries that wouldn’t have been possible from the question alone. Moreover, because our system generates natural language queries, we can still leverage off-the-shelf information retrieval systems for efficient retrieval. Furthermore, the steps our model follows are more explainable to a human, and allow for human intervention at any time to correct its course.
Given the English Wikipedia as our source of textual knowledge, the full system operates as follows to answer the question “Which novel by the author of ‘Armada’ will be adapted as a feature film by Steven Spielberg?”:
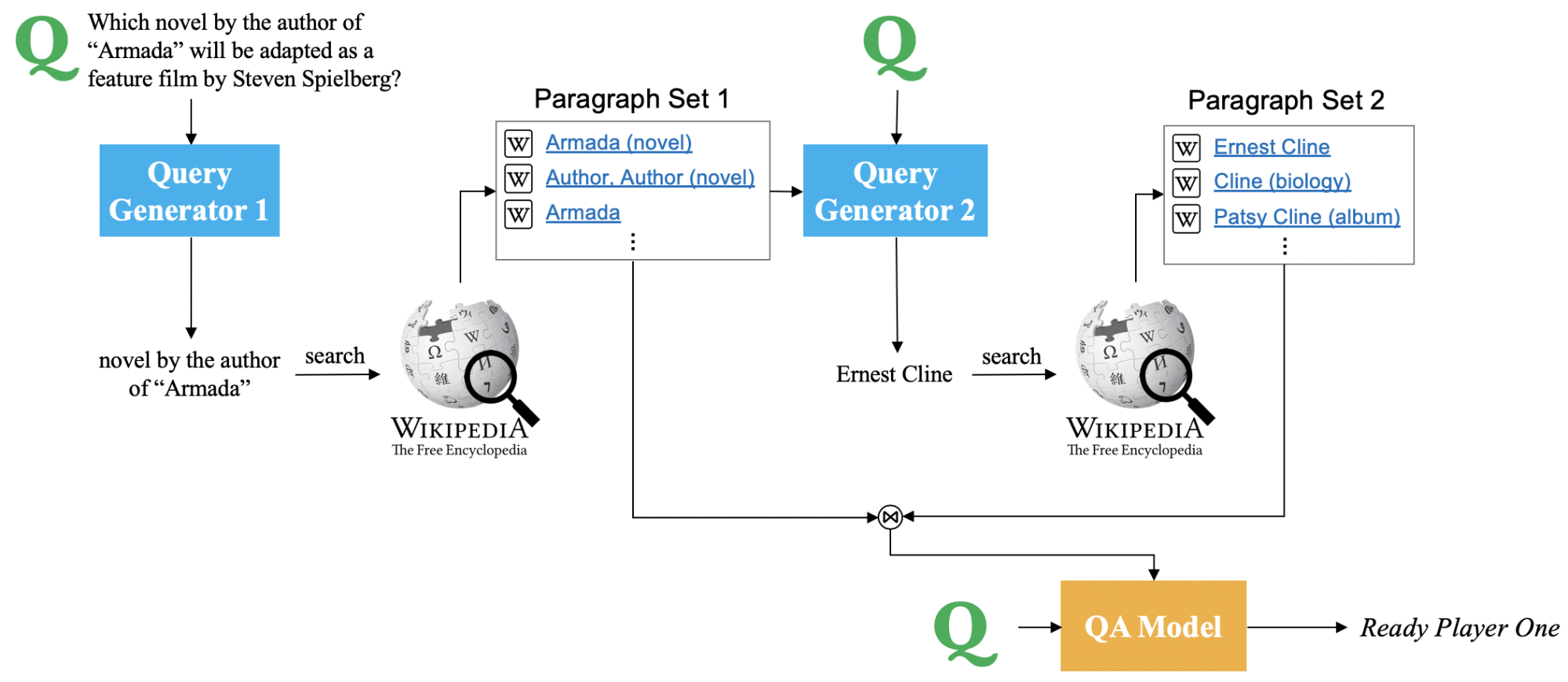
To answer this question, the model starts by generating a query to search Wikipedia to find information about the novel Armada. After “reading” the retrieved articles, it then attempts to search for Ernest Cline (the name of the author) for more information. Finally, when we have retrieved all the context necessary to answer the question, we concatenate the top retrieved articles from these retrieval steps, and feed them into a restricted-context QA system to predict the final answer.
The main challenge in building this model lies in training the query generators collaboratively to generate useful queries for retrieving all the necessary information. Our main contribution is an efficient method for training these query generators with very limited supervision about which documents to retrieve, yielding a competitive system for answering complex and open-domain questions. Our method is based on the crucial observation that, if the question can be answered with knowledge from the corpus, then there exists a progressive chain (or graph) of reasoning we can follow. In other words, we note that at any given time in the process of finding all supporting facts, there is some strong semantic overlap between what we already know (the question text, plus what we have found so far), and what we are trying to find (the remaining supporting facts).

In the beginning, the question the system is asked is all the information we already know. We are trying to find any document part of reasoning chain needed to answer this question. Based on our observation, at least one of the gold documents2 would have strong semantic overlap with the question, and our goal is to find one such document to bootstrap our chain of reasoning. In our Armada example, this document would be the Wikipedia page of Armada the novel, where the overlap is the name “Armada”, and the fact that it’s a novel. To find this document with the help of a text-based information retrieval (IR) system, we just need to identify this overlap and use it as the search query.
After one step of retrieval, we have hopefully retrieved the “Armada (novel)” page from Wikipedia, among others. If, at training time, we also know that the “Ernest Cline” page is the next missing link in our chain of reasoning, we can apply the same technique. Now, the semantic overlap between what we know (the question, the “Armada (novel)” page, plus some other Wikipedia pages), and what we are trying to find (“Ernest Cline”) to generate the desired query, “Ernest Cline”. To find this semantic overlap, we simply employ longest common substring or longest common subsequence algorithms between the knowns and the wanted.
With the desired queries at each step of reasoning, we can then train a model to predict them from the retrieval context (question + already retrieved documents) at each step. We then use these query generators to complete the task of open-domain multi-step reasoning. We cast the query generation problem as one of restricted-context QA, since the goal is to map the given question and (retrieved) context to some target derived from the context.
We name the full system GoldEn (Gold Entity) Retriever, because the model-retrieved Wikipedia pages are mostly entities, and it’s a fun name for a retrieval-oriented model! Below are some example questions and the desired queries we train the query generators with:
| Question | Step 1 Query | Step 2 Query |
|---|---|---|
| What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell? | Corliss Archer in the film Kiss and Tell | Shirley Temple |
| Are Giuseppe Verdi and Ambroise Thomas both Opera composers? | Giuseppe Verdi | Ambroise Thomas |
Two practical notes should be mentioned here. First, it is not difficult to see that our observation that supervision signal for query generation can be derived from this semantic overlap generalizes to any number of supporting documents. It also requires no additional knowledge about how the question can or should be decomposed into sub-questions to answer (which previous work has studied, e.g., (Talmor and Berant, 2018) and (Min et al., 2019)). As long as the gold supporting documents are known at training time, we can use this technique to construct the chain of reasoning in an open-domain setting very efficiently at scale. Second, we further make no assumption about knowledge of the order in which documents should be retrieved. At any given step of open-domain reasoning, one can enumerate all of the documents that have yet to be retrieved, find its semantic overlap with the retrieval context, and launch searches with these generated queries. Documents that are in the immediate next step of reasoning will naturally be more discoverable, and we can choose the desired queries accordingly. In our Armada example, for instance, the overlap between the question and the Ernest Cline article is “Steven Spielberg”, “film”, etc, which lead us nowhere close to the “Ernest Cline” page, thus these are not chosen as the first-step query at training time.
Dataset: HotpotQA
To test the performance of GoldEn Retriever, we evaluate it on HotpotQA, a recent multi-hop question answering dataset presented at EMNLP 2018 (by me & collaborators). HotpotQA is a crowd-sourced QA dataset on English Wikipedia articles, in which crowd-workers are presented the introductory paragraphs from two related Wikipedia articles and asked to generate questions that require reasoning with both paragraphs to answer. Our example question about the Armada novel is one such question from this dataset. To encourage the development of explainable QA systems, we also asked crowd workers to highlight the sentences from these paragraphs that support their answer (we call these “supporting facts”), and ask QA systems to predict them at test time.
HotpotQA features two evaluation settings: a few-document distractor setting, and an open-domain fullwiki setting, which we focus on, where the system is only given the question and the entire Wikipedia to predict the answer from. HotpotQA also features a diverse range of reasoning strategies, including questions involving missing entities (our Armada example, where Ernest Cline is not in the question), intersection questions (What satisfies property A and property B?), and comparison questions, where two entities are compared by a common attribute, among others.3
QA systems on this dataset are evaluated on two aspects, answer accuracy and explainability. Answer accuracy is evaluated with answer exact matches (EM) and unigram F1, and explainability is similarly evaluated with EM and F1 by calculating the supporting fact overlap between predictions and annotations. These two aspects are unified by joint EM and F1 metrics, which encourage QA systems to work well on both.
For the final restricted-context QA component, we use a modified BiDAF++ model in this work. For more technical details, please refer to our paper.
Results
We evaluate the effectiveness of our GoldEn Retriever model on two aspects: its performance on retrieving the gold supporting documents, and it’s end-to-end performance in question answering.
For retrieval performance, we compare GoldEn Retriever to a retrieve-and-read QA system that just retrieves once with the question. We evaluate these approaches on the recall of the two gold paragraphs when a total of 10 paragraphs are retrieved by each system, because this metric reflects the ceiling performance of the entire QA system if the restricted-context QA component were perfect.
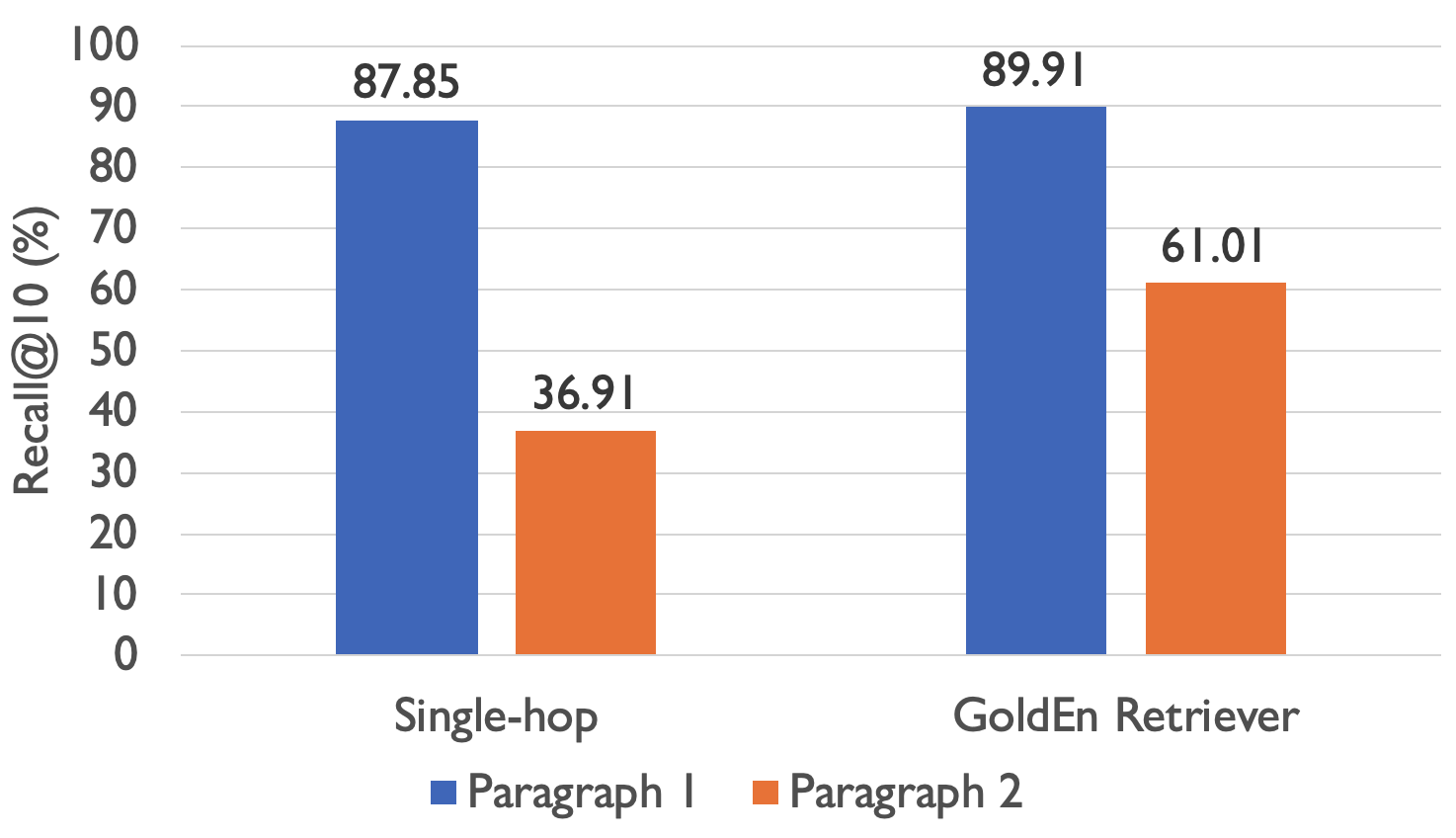
As can be seen from the figure, while both systems achieve decent recall on the paragraph that is usually more connected to the question (“Paragraph 1” in the figure), GoldEn Retriever obtains significant improvement through iterative retrieval with query generation on the other paragraph (~24% improvement). This means for about 24% of the questions, GoldEn Retriever is able to find both gold supporting documents while the retrieve-and-read system can’t. Further analysis shows that this is mainly from the improved recall for non-comparison questions (for which recall improved by about 25%), where the retrieval problem is less trivial.
For end-to-end QA performance, we compare GoldEn Retriever against various retrieve-and-read baselines on the development set, as well as systems submitted to the public leaderboard on the hidden test set.
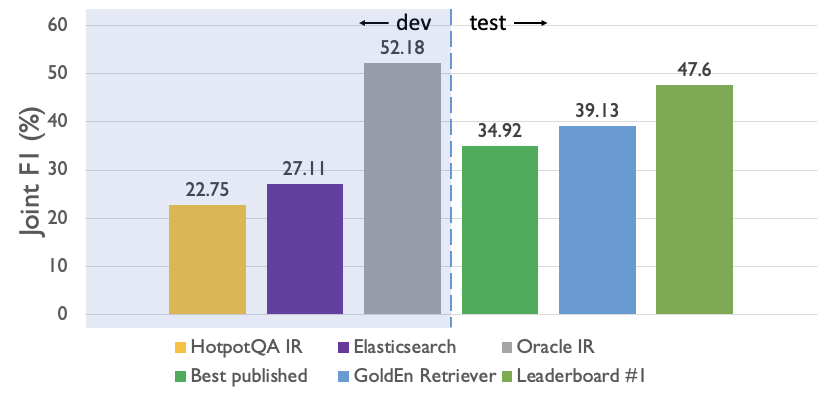
We first contrast the performance of the QA component when using the IR system originally used in HotpotQA (as reflected by the released fullwiki dev set) and Elasticsearch in an retrieve-and-read setting. As can be seen by the leftmost two bars in the figure, a better search engine does improve end-to-end performance (from 22.75% F1 to 27.11%). However, this is still far from the best previously published system (34.92% F1 on the test set, which is empirically ±2% from the model’s dev set performance). With GoldEn Retriever, we improve this state of the art to 39.13% F1, which is significant especially if one considers that the previous state-of-the-art model uses BERT and we don’t. Although this doesn’t match the contemporaneous work which achieves 47.6% F1 with another BERT-based model, we see that if our query generators were able to faithfully reproduce the desired queries on the dev set, the performance of our system wouldn’t have been far off (“Oracle IR”).
For explainability, aside from reporting supporting fact metrics that are part of HotpotQA’s evaluation, we can also look at the search queries GoldEn Retriever generates on the dev set. As can be seen in the example below, the natural language queries generated by the model are very understandable. Furthermore, one can see where the model is making mistakes and correct it in the system if needed.
| Question | Step 1 Predicted | Step 2 Predicted |
|---|---|---|
| What video game character did the voice actress in the animated film Alpha and Omega voice? | voice actress in the animated film Alpha and Omega (animated film Alpha and Omega voice) | Hayden Panettiere |
| Yau Ma Tei North is a district of a city with how many citizens? | Yau Ma Tei North | Yau Tsim Mong District of Hong Kong (Hong Kong) |
Resources
To help facilitate future research in open-domain multi-step reasoning, we make the following resources publicly available:
- The code to reproduce our results and our pretrained models
- Generated “desired” query files and modified HotpotQA training and development files generated from the heuristics to train GoldEn Retriever models
- Predicted search queries and dev/test set input for our restricted-context QA model
All of these can be found in our code repository on GitHub.
Language Note: All datasets and most of the research mentioned in this post are collected/tested for the English language only, but our principle of semantic overlap is applicable to answering open-domain complex questions in other languages than English if suitably augmented with lemmatization for highly inflected languages.
-
This is of course contingent on the fact that very few highly ranked articles on the Web mention Jason Momoa in his next movie in close proximity to stating that he’s the “Aquaman” star who played Aquaman in that movie. This is just an example to demonstrate that as simple as this question seems, it’s not too difficult to construct questions that require information from more than one document to answer. ↩
-
By “gold documents” we mean the documents needed in the chain of reasoning to answer the question. ↩
-
Comparison questions make up about 25% of the HotpotQA dataset. For more details please see our HotpotQA paper. ↩