![]()
The Conference on Empirical Methods in Natural Language Processing (EMNLP 2022) will take place next week. We’re excited to share all the work from SAIL that will be presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Fixing Model Bugs with Natural Language Patches
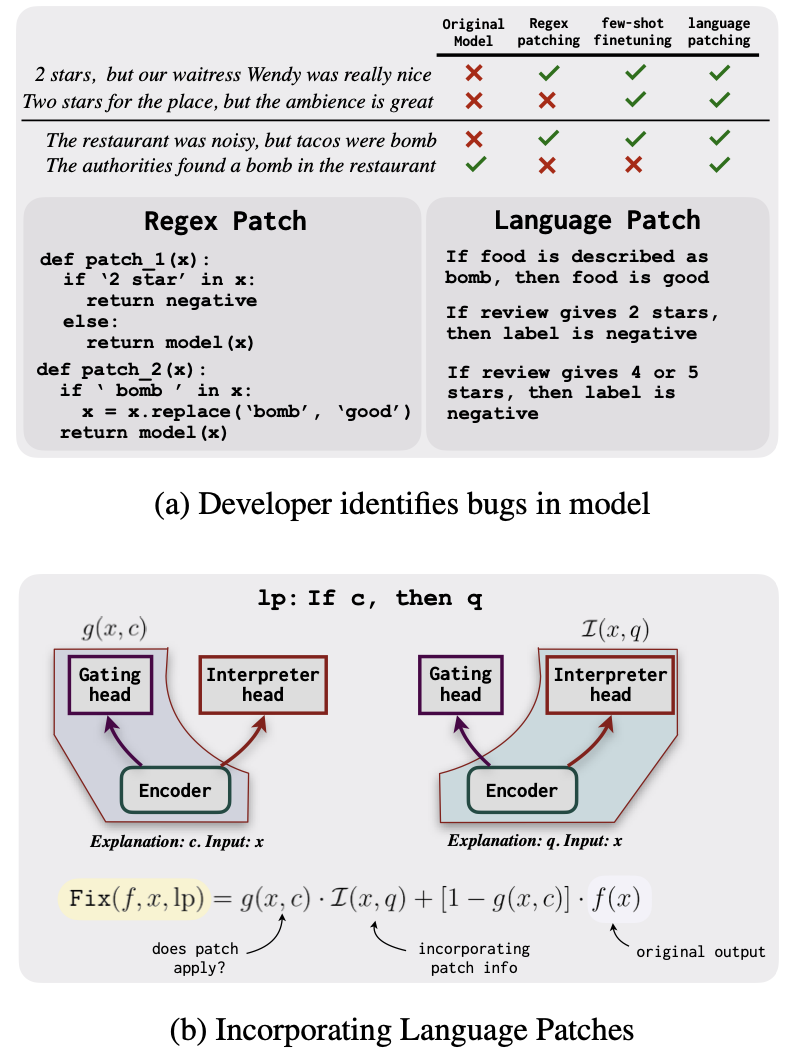
Contact: jsmurty@stanford.edu
Links: Paper
Keywords: language models, test time model corrections, post-hoc model patching
On Measuring the Intrinsic Few-Shot Hardness of Datasets
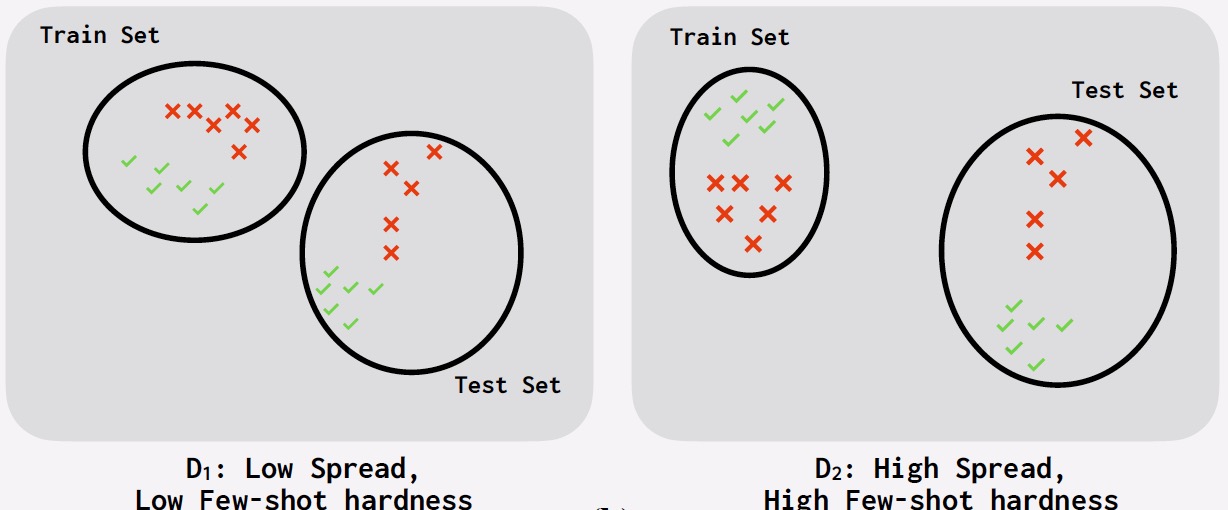
Contact: xzhaoar@stanford.edu
Keywords: few-shot learning, dataset hardness, lightweight metic
Enhancing Self-Consistency and Performance of Pretrained Language Models with NLI
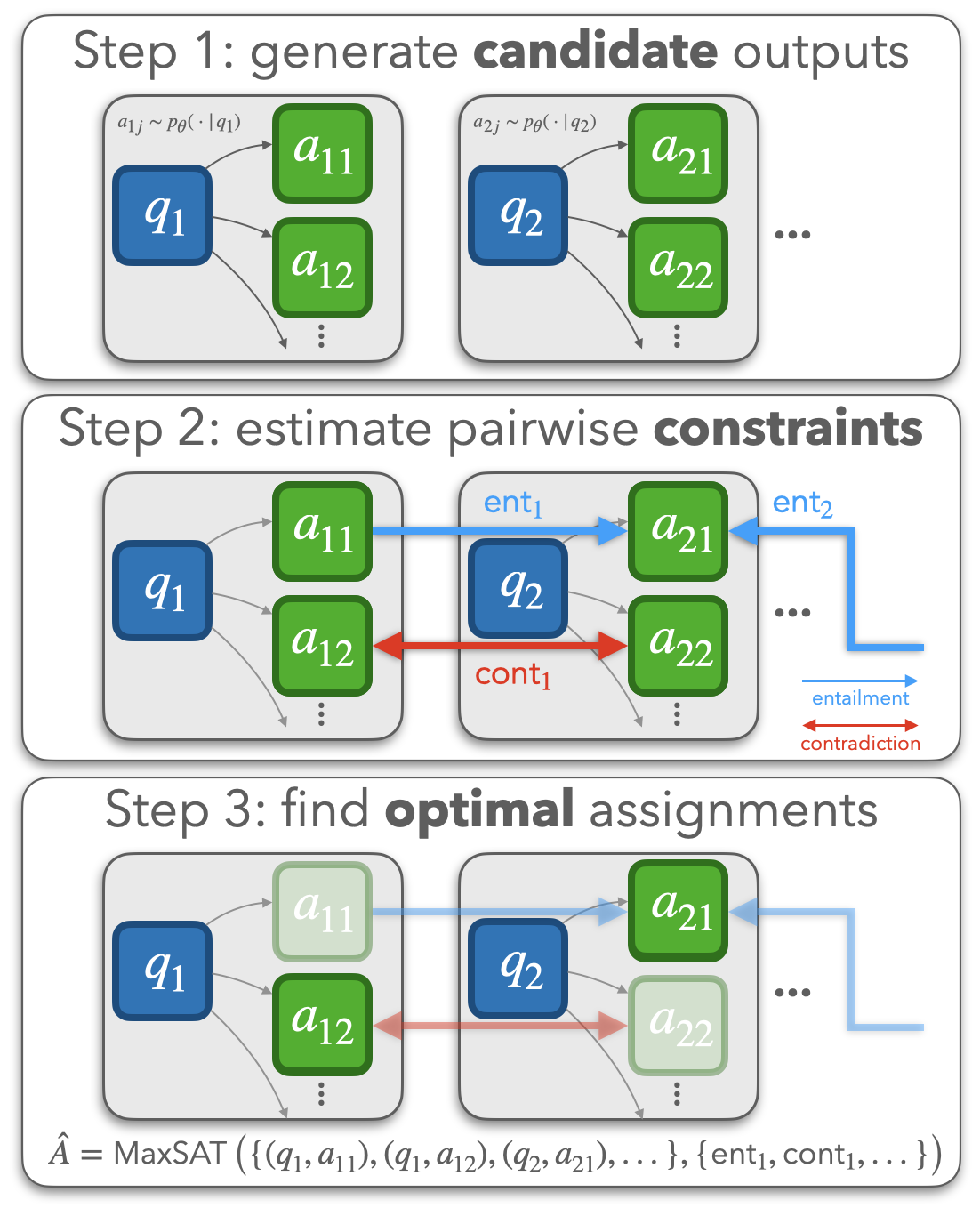
Contact: eric.mitchell@cs.stanford.edu
Links: Paper | Website
Keywords: consistency nli language question
Detecting Label Errors by using Pre-Trained Language Models
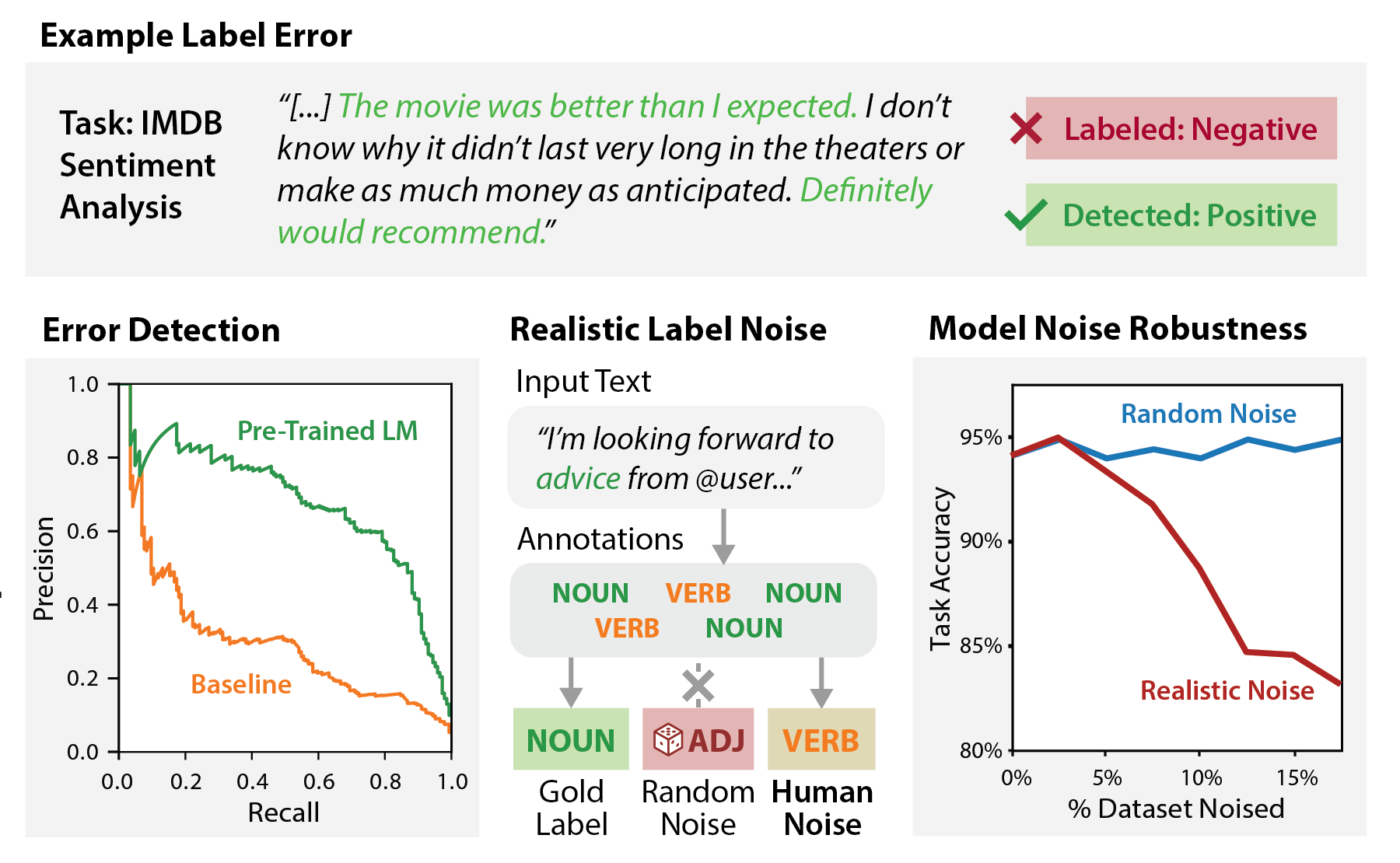
Contact: derekch@stanford.edu
Links: Paper | Blog Post | Video | Website
Keywords: robustness, pre-trained language models, human-in-the-loop, label errors, label noise
You Only Need One Model for Open-domain Question Answering
Authors: Haejun Lee, Akhil Kedia, Jongwon Lee, Ashwin Paranjape, Christopher D. Manning and Kyoung-Gu Woo
Links: Paper
Keywords: question answering, triviaqa
JamPatoisNLI: A Jamaican Patois Natural Language Inference Dataset
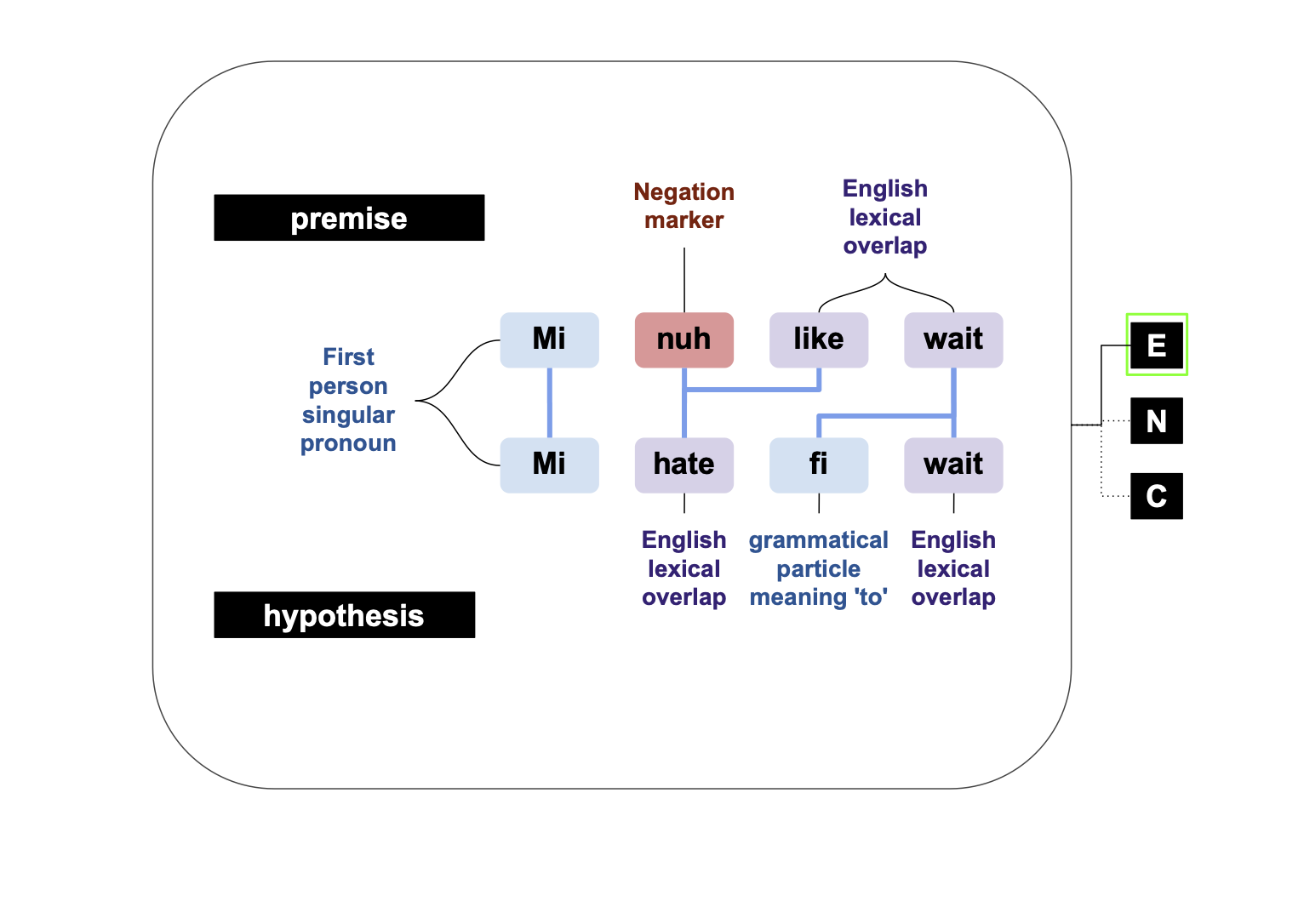
Contact: ruthanna@stanford.edu
Links: Paper | Blog Post | Video | Website
Keywords: dataset, creole languages, pretrained models, cross-lingual transfer, multilingual bert, xlm-roberta, jamaican patois, translation, natural language inference, multilingual, transfer learning
Truncation Sampling as Language Model Desmoothing
Authors: John Hewitt, Christopher D. Manning and Percy Liang
Keywords: natural language generation
Workshop on Story Shared and Lesson Learned

Contact: diyiy@stanford.edu
Keywords: career trajectory; mentorship
When FLUE Meets FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain
Contact: diyiy@stanford.edu
Links: Paper | Blog Post | Website
Keywords: financial language modeling, large language models, datasets and benchmarks
Robustness of Demonstration-based Learning Under Limited Data Scenario
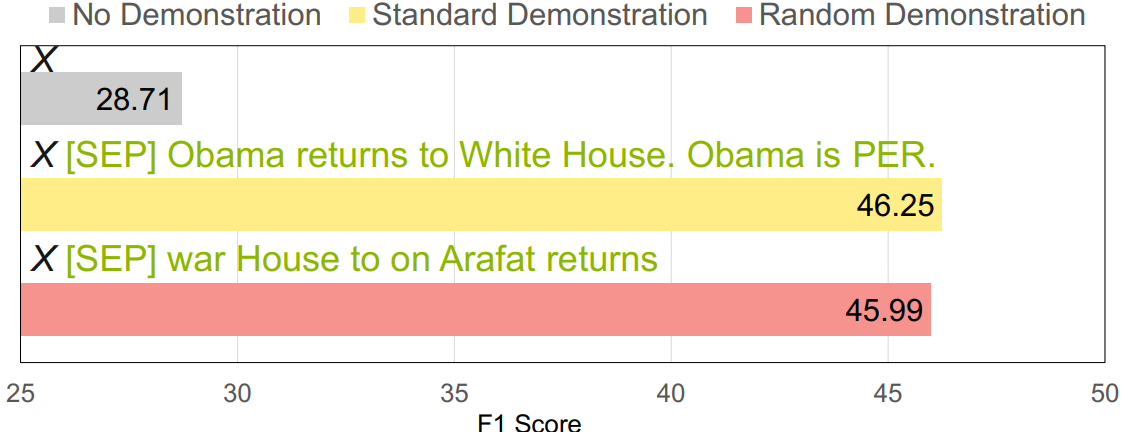
Contact: diyiy@stanford.edu
Links: Paper | Website
Keywords: large language models, analysis, robustness, demonstration, structured prediction, limited data
Geographic Citation Gaps in NLP Research
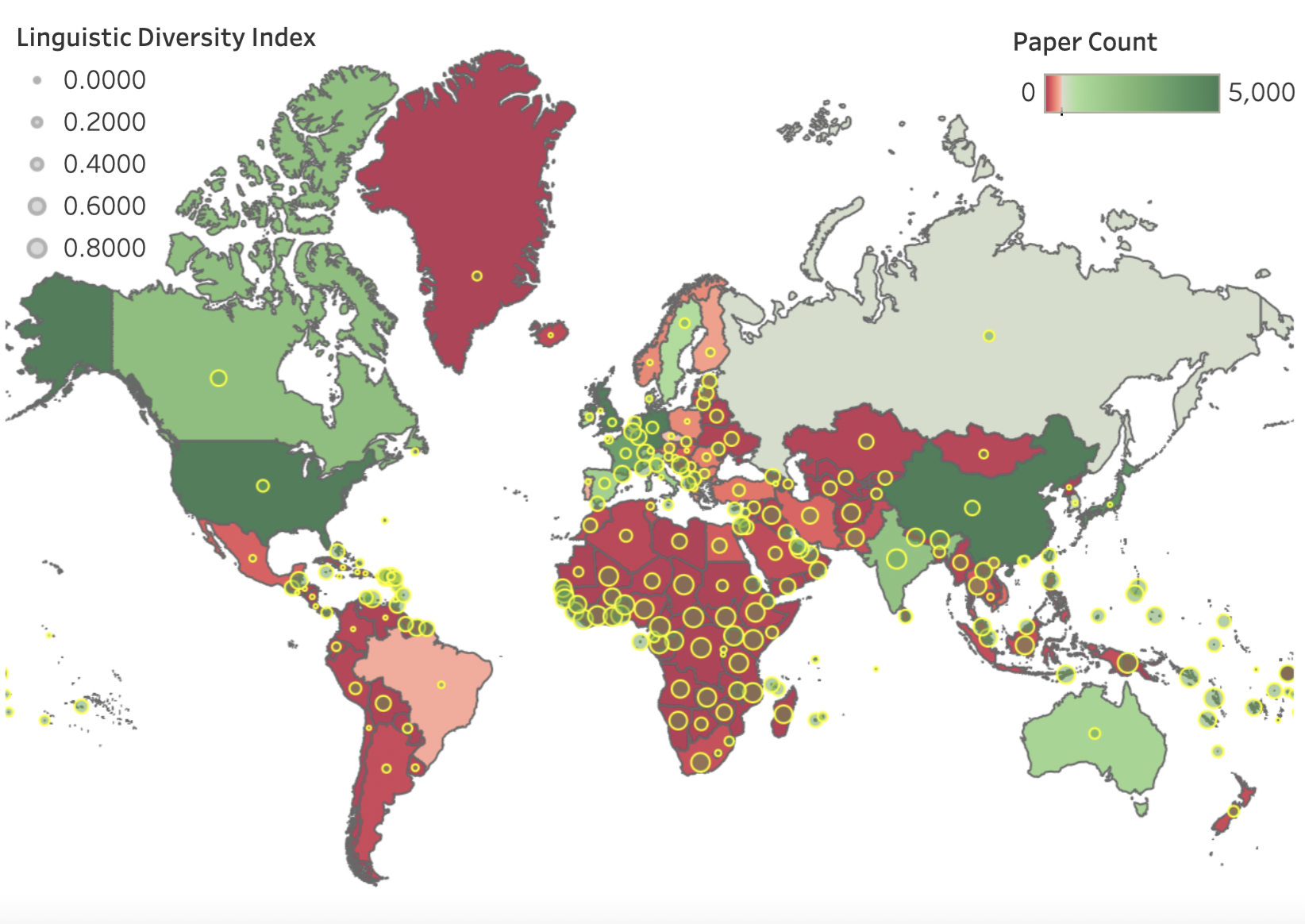
Contact: diyiy@stanford.edu
Links: Paper
Keywords: computational social science; bias and diversity
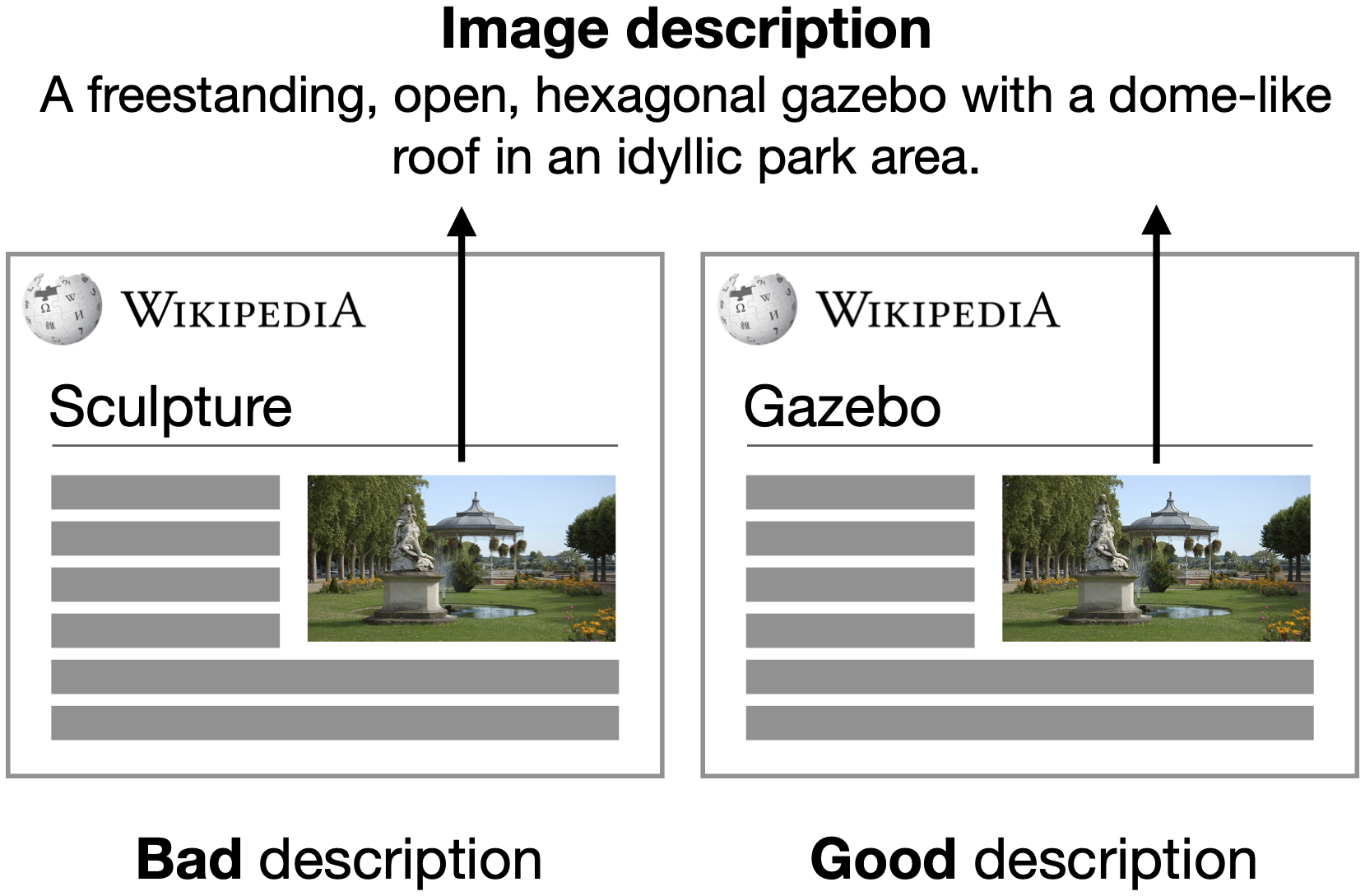
Context Matters for Image Descriptions for Accessibility: Challenges for Referenceless Evaluation Metrics
Contact: ekreiss@stanford.edu
Links: Paper
Keywords: image captioning, evaluation, context, accessibility
Mixed-effects transformers for hierarchical adaptation
Authors: Julia White, Noah Goodman and Robert Hawkins
Keywords: language modeling and analysis of language models
Concadia: Towards Image-Based Text Generation with a Purpose

Contact: ekreiss@stanford.edu
Links: Paper
Keywords: image captioning, multimodal, context
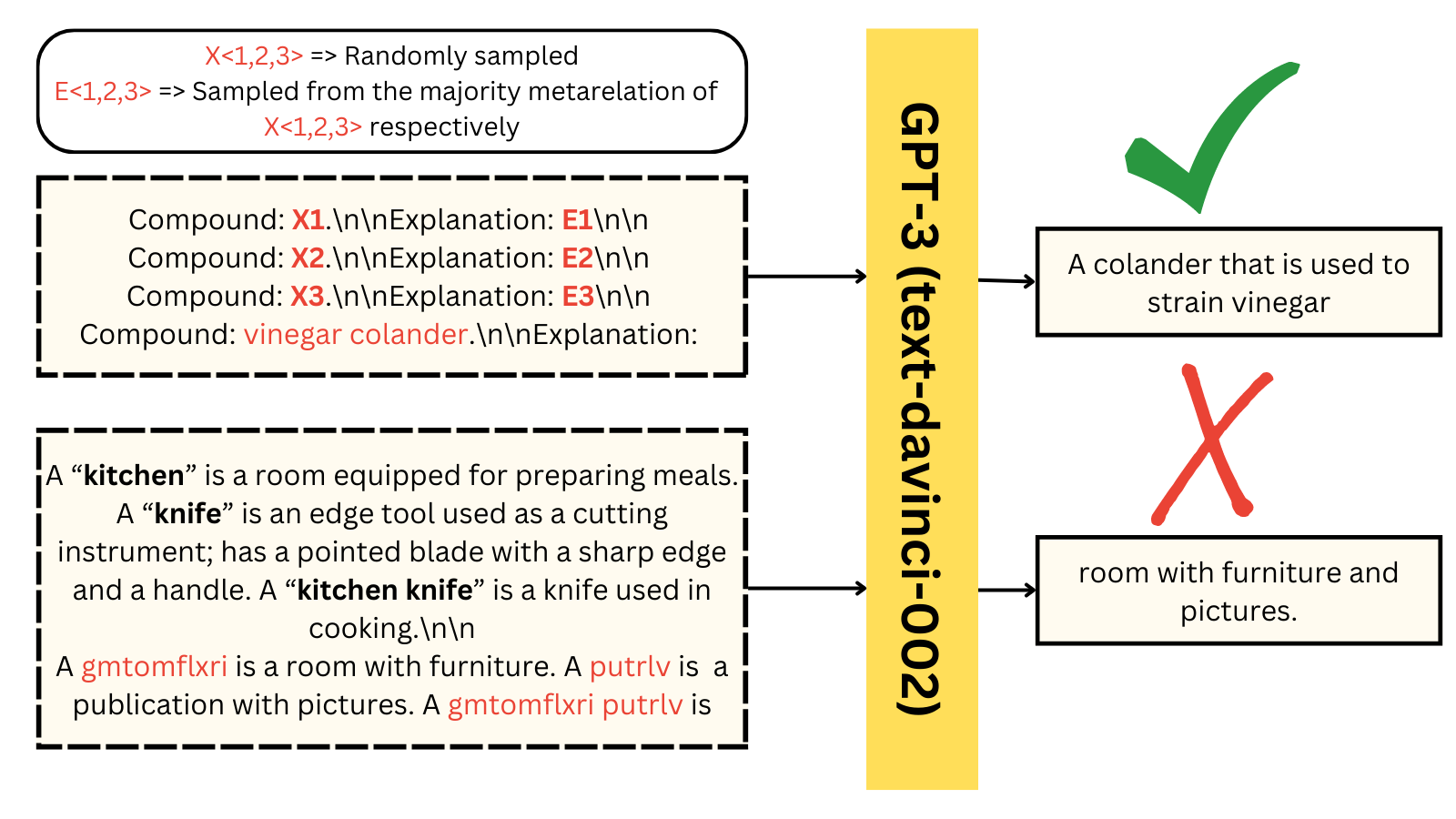
Systematicity in GPT-3’s Interpretation of Novel English Noun Compounds
Contact: siyanli@stanford.edu
Links: Paper
Keywords: gpt-3, noun compounds, language comprehension
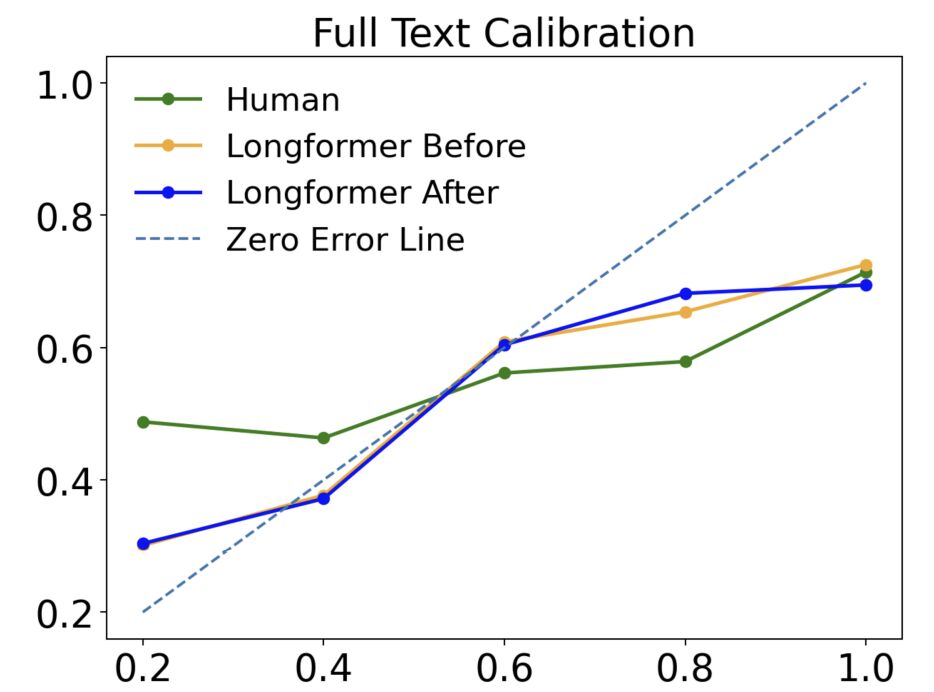
ClassActionPrediction: A Challenging Benchmark for Legal Judgment Prediction of Class Action Cases in the US
Contact: joel.niklaus@inf.unibe.ch
Links: Paper
Keywords: natural legal language processing, class actions, legal judgment prediction, legal nlp, transformers, calibration, integrated gradients
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning

Contact: smirchan@stanford.edu
Links: Paper
Keywords: vision-and-language learning, domain-specific pre-training, fashion
“It’s Not Just Hate”: A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Authors: Federico Bianchi, Stefanie Anja Hills, Patricia Rossini, Dirk Hovy, Rebekah Tromble and Nava Tintarev
Contact: fede@stanford.edu
Keywords: hate speech detection
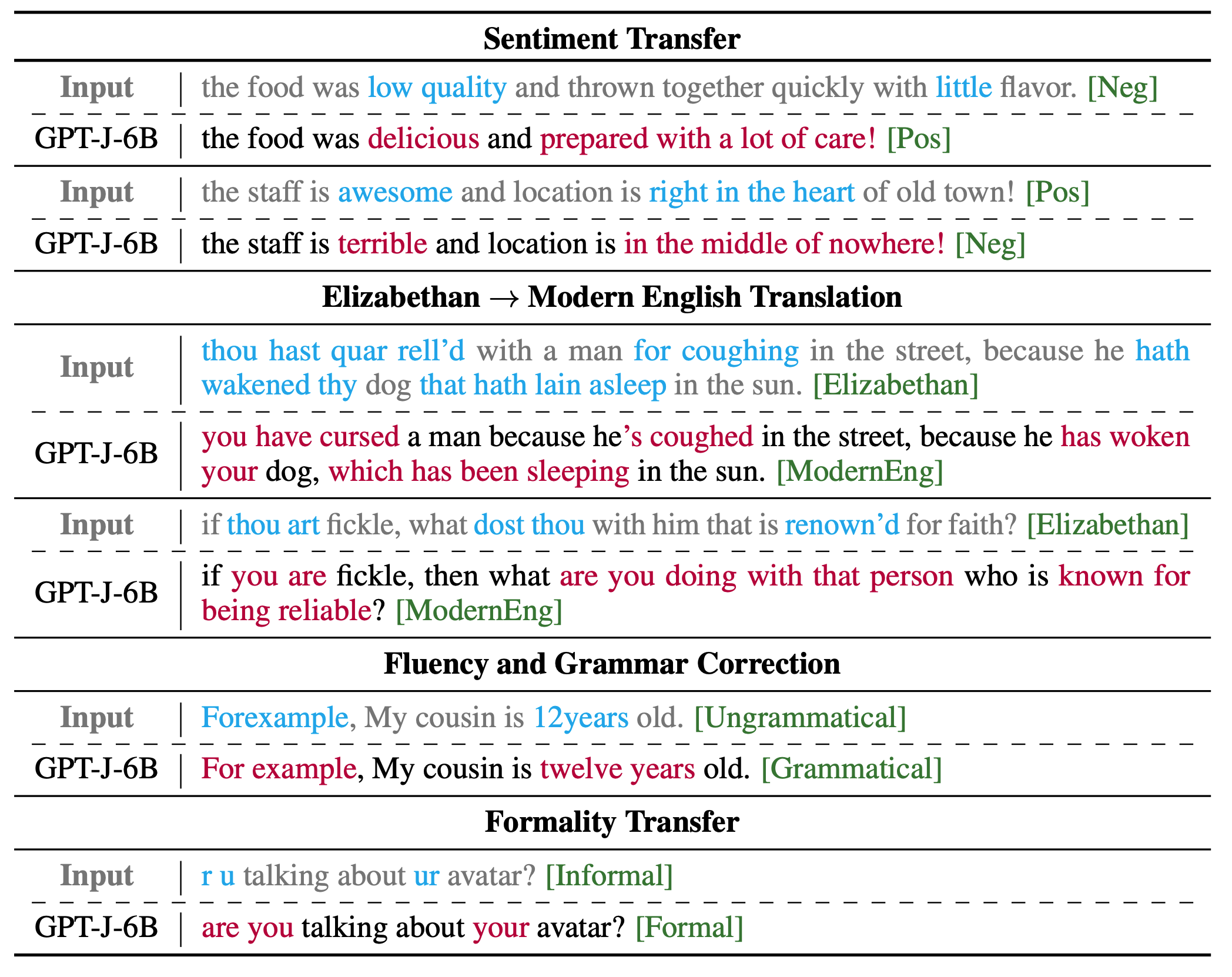
Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Models
Contact: msuzgun@cs.stanford.edu
Links: Paper | Video | Website
Keywords: style transfer, language models, prompting, sentiment transfer, grammar error correction, shakespeare, yelp, amazon
The Authenticity Gap in Human Evaluation

Contact: kawin@stanford.edu
Links: Paper
Keywords: evaluation, nlp, nlg, generation
LADIS: Language Disentanglement for 3D Shape Editing
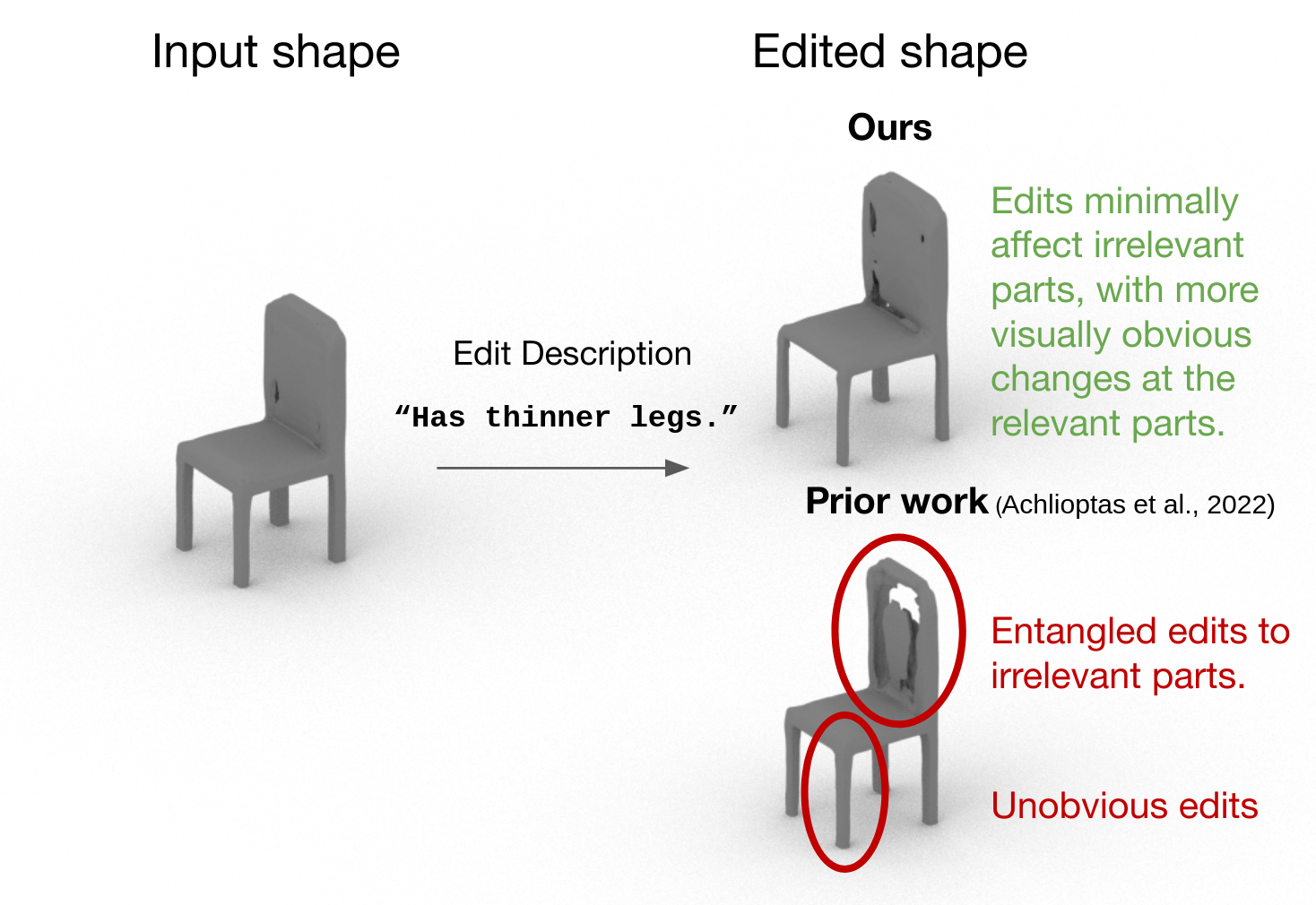
Contact: ianhuang@cs.stanford.edu
Links: Paper
Keywords: speech, vision, robotics, multimodal grounding
SocioProbe: What, When, and Where Language Models Learn about Sociodemographics
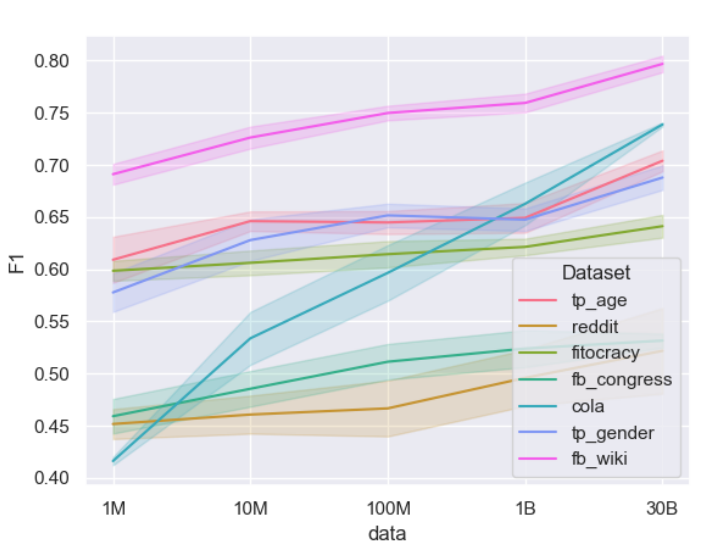
Contact: fede@stanford.edu
Keywords: sociodemographic, language models
Data-Efficient Strategies for Expanding Hate Speech Detection into Under-Resourced Languages
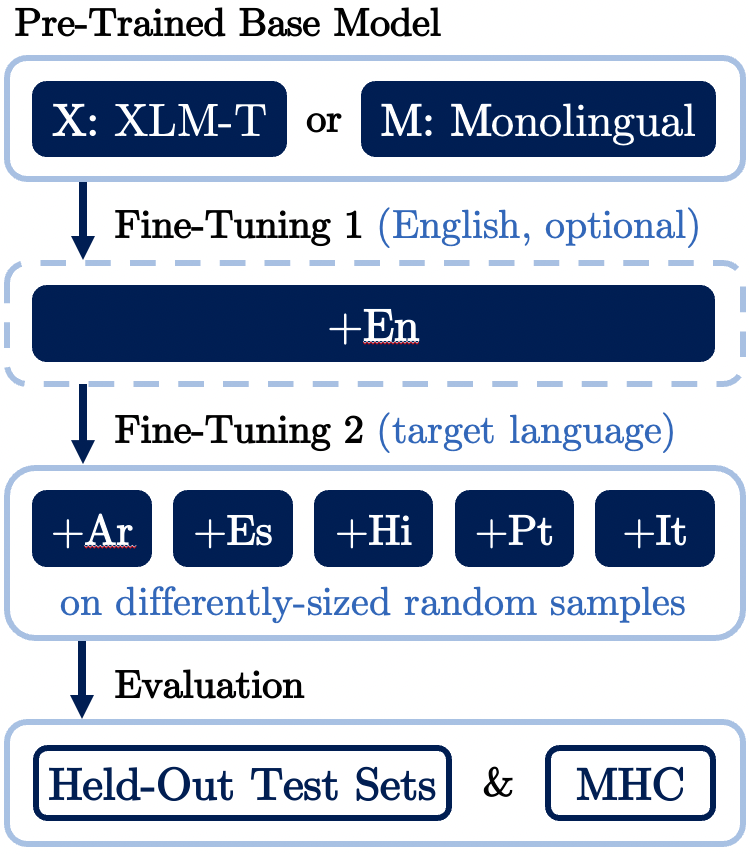
Contact: fede@stanford.edu
Keywords: hate speech detection, low resource
Twitter-Demographer: A Flow-based Tool to Enrich Twitter Data
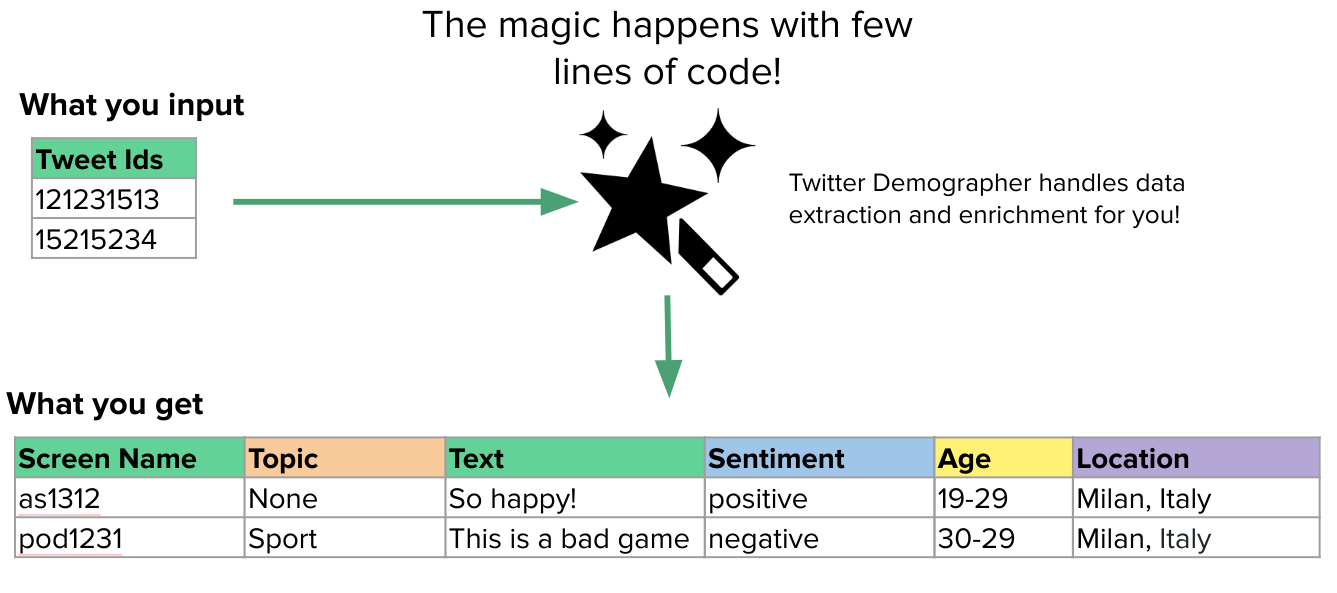
Contact: fede@stanford.edu
Links: | Video | Website
Keywords: demographer, social science, data enrichment twitter
Improving the Factual Correctness of Radiology Report Generation with Semantic Rewards
Authors: Jean-Benoit Delbrouck, Pierre Chambon, Christian Bluethgen, Emily Tsai, Omar Almusa and Curtis Langlotz
Keywords: natural language generation
We look forward to seeing you at EMNLP 2022!