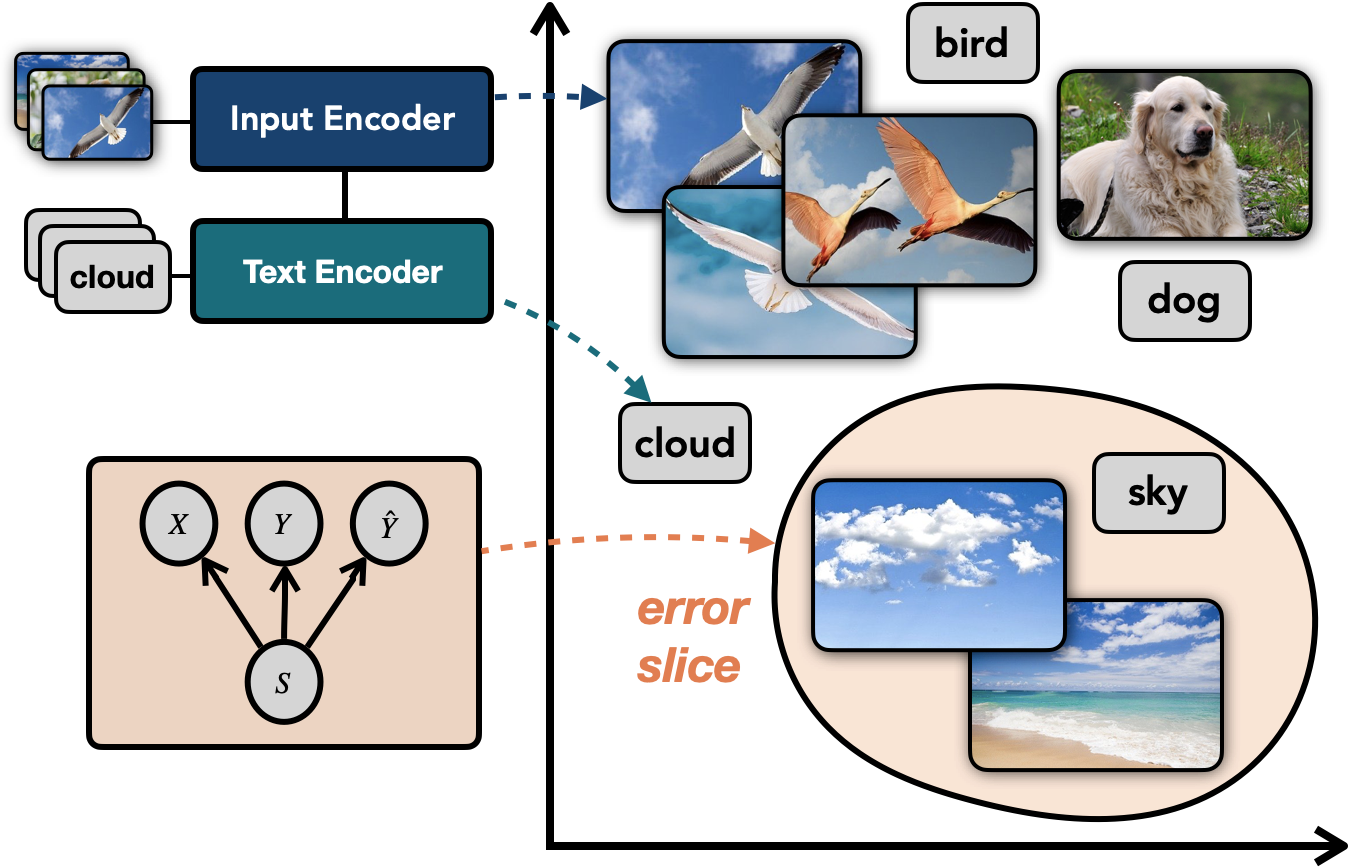
Machine learning models that achieve high overall accuracy often make systematic errors on coherent slices of validation data. Can we develop methods to automatically identify these systematic errors?
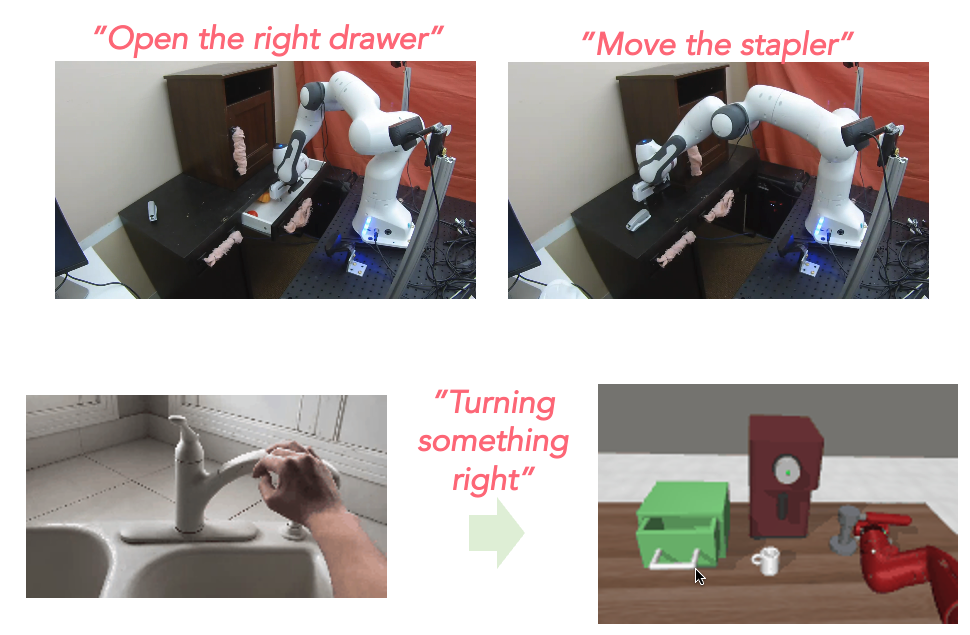
Where do the rewards for robotic reinforcement learning come from? In this blog post we study how using crowdsourced language annotations and videos of humans, we can learn reward functions in a scalable way and enable them to generalize more broadly.
We present an almost-linear time algorithm for the k-medoids problem that matches prior SOTA in clustering quality. Our solution has almost the same complexity as k-means and several advantages.