3D Shape Scanning with a Time-of-Flight Camera
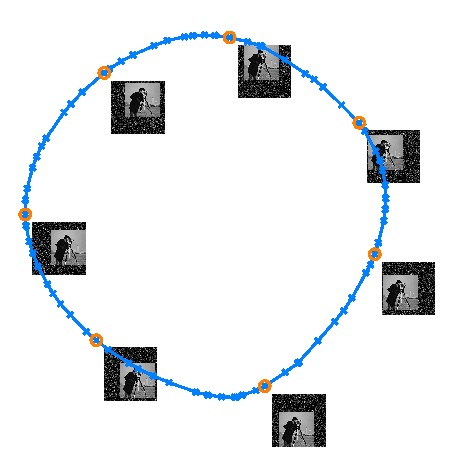
We recently developed a technique that allows to digitalize 3D objects using a Time-of-Flight camera. One has to move the camera simply around the object. Then the scans are automatically aggregated and fused into a single 3D model.
Cite as:
(This was joint work with Yan Cui, Derek Chan, Sebastian Thrun and Christian Theobalt)
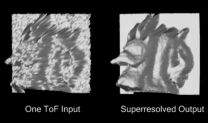
To our best knowledge, this is the first time a Time-of-Flight camera has been used to scan an objects (previously only environments have been scanned). Initially object scanning using a ToF camera seems to be out of range, due to severe noise, nonlinear measurement errors and low resolution. We overcome these obstacles with Lidarboost, our previous resolution enhancement algorithm. Here we aggregate some ten consecutive frames into a higher resolution one. The superresolved scans are then aligned using a novel algorithm, that takes into account the systematic bias of Time-of-Flight camera.
We demonstrate our algorithm on five scenes, four of them recorded by rotating the object on a turntable. The fifth scene has been recorded by free-hand motion around the objects and yields similar results as the turn-table setups, thus proving the robustness of our algorithm. We will present the results at CVPR 2010, for which we have the pre-print and the additional material already available. We plan to release the results of our method soon here.
Cite as:
@ARTICLE{schuon_scanning10,
title={3D Shape Scanning with a Time-of-Flight Camera}, author={Cui, Yan, and Schuon, Sebastian and Derek, Chan and Thrun, Sebastian and Theobalt, Christian},
journal={In Proc. of IEEE CVPR 2010}, year={2010}}(This was joint work with Yan Cui, Derek Chan, Sebastian Thrun and Christian Theobalt)
posted by Sebastian Schuon at
12:42 PM
0 Comments
![]()
 The previous work mon motion deblurring, namely comparing several methods with real captures images with well known properties has recently been accepted as a journal paper. Even though significant progress has been made since the paper was written in the field, the paper contains some good reference data, others might be interested to work with. They are available on the
The previous work mon motion deblurring, namely comparing several methods with real captures images with well known properties has recently been accepted as a journal paper. Even though significant progress has been made since the paper was written in the field, the paper contains some good reference data, others might be interested to work with. They are available on the 




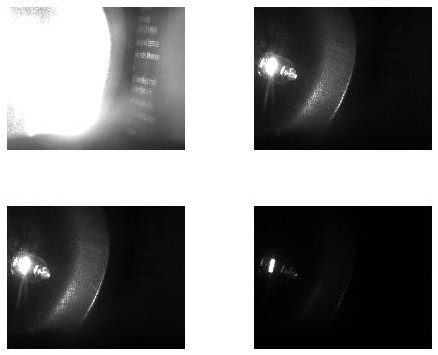
 A way to illustrate the magnetic field on surfeces, the Magneto-Optic Kerr Effect can be used. During my time at the
A way to illustrate the magnetic field on surfeces, the Magneto-Optic Kerr Effect can be used. During my time at the