For the nearly one million American adults living with physical disabilities, taking a bite of food or pouring a glass of water presents a significant challenge. Assistive robots—such as wheelchair-mounted robotic arms—promise to solve this problem. Users control these robots by interacting with a joystick, guiding the robot arm to complete everyday tasks without relying on a human caregiver. Unfortunately, the very dexterity that makes these arms useful also renders them difficult for users to control. Our insight is that we can make assistive robots easier for humans to control by learning an intuitive and meaningful control mapping that translates simple joystick motions into complex robot behavior. In this blog post, we describe our self-supervised algorithm for learning the latent space, and summarize the results of user studies that test our approach on cooking and eating tasks. You can find a more in-depth description in this paper and the accompanying video.
Motivation. Almost 10% of all American adults living with physical disabilities need assistance when eating1. This percentage increases for going to the bathroom (14%), getting around the home (16%), or putting on clothes (23%). Wheelchair-mounted robotic arms can help users complete some of these everyday tasks.

Unfortunately, because robotic arms are hard for humans to control, even simple tasks remain challenging to complete. Consider the task shown in the video below:

The user is trying to control their assistive robot to grab some food. In the process, they must precisely position the robot’s gripper next to the container, and then carefully guide this container up and out of the shelf. The human’s input is—by necessity—low-dimensional. But the robot arm is high-dimensional: it has many degrees-of-freedom (or DoFs), and the user needs to coordinate all of these interconnected DoFs to complete the task.
In practice, controlling assistive robots can be quite difficult due to the unintuitive mapping from low-dimensional human inputs to high-dimensional robot actions. Look again at the joystick interface in the above video—do you notice how the person keeps tapping the side? They are doing this to toggle between control modes. Only after the person finds the right control mode are they able to make the robot take the action that they intended. And, as shown, often the person has to switch control modes multiple times to complete a simple task. A recent study2 found that able-bodied users spent 20% of their time changing the robot’s control mode! The goal of our research is to address this problem and enable seamless control of assistive robots.
Our Vision. We envision a setting where the assistive robot has access to task-related demonstrations. These demonstrations could be provided by a caregiver, the user, or even be collected on another robot. What’s important is that the demonstrations show the robot which high-dimensional actions it should take in relevant situations. For example, here we provide kinesthetic demonstrations of high-dimensional reaching and pouring motions:

Once the robot has access to these demonstrations, it will learn a low-dimensional embedding that interpolates between different demonstrated behaviors and enables the user to guide the arm along task-relevant motions. The end-user then leverages the learned embedding to make the robot perform their desired tasks without switching modes. Returning to our example, here the robot learns that one joystick DoF controls the arm’s reaching motion, and the other moves the arm along a pouring motion:


Typically, completing these motions would require multiple mode switches (e.g., intermittently changing the robot’s position and orientation). But now—since the robot has learned a task-related embedding—the user can complete reaching and pouring with just a single joystick (and no mode switching)! In practice, this embedding captures a continuous set of behaviors, and allows the person to control and interpolate between these robot motions by moving the joystick.
Insight and Contributions. Inspired by the difficulties that today’s users face when controlling assistive robotic arms, we propose an approach that learns teleoperation strategies directly from data. Our insight is that:
High-dimensional robot actions can often be embedded into intuitive, human-controllable, and low-dimensional latent spaces
You can think a latent space as a manifold that captures the most important aspects of your data (e.g., if your data is a matrix, then the latent space could be the first few eigenvectors of that matrix). In what follows, we first formalize a list of properties that intuitive and human-controllable latent spaces must satisfy, and evaluate how different autoencoder models capture these properties. Next, we perform two user studies where we compare our learning method to other state-of-the-art approaches, including shared autonomy and mode switching.
Learning User-Friendly Latent Spaces
Here we formalize the properties that user-friendly latent space should have, and then describe models that can capture these properties.
Notation. Let \(s\) be the robot’s current state. In our experiments, \(s\) contained the configuration of the robot’s arm and the position of objects in the workspace; but the state \(s\) can also consist of other types of observations, such as camera images. The robot takes high-dimensional actions \(a\), and these actions cause the robot to change states according to the transition function \(T(s, a)\). In practice, \(a\) often corresponds to the joint velocities of the robot arm.
We assume that the robot has access to a dataset of task-related demonstrations. Formally, this dataset \(D\) contains a set of state-action pairs: \(D = \{(s_0, a_0), (s_1, a_1), \ldots \}\). Using the dataset, the robot attempts to learn a latent action space \(Z\) that is of lower dimension than the original action space. In our experiments, \(Z\) was the same dimension as the joystick interface so that users could input latent action \(z\). The robot also learns a decoder \(\phi(z,s)\) that inputs the latent action \(z\) and the robot’s current state \(s\), and outputs the high-dimensional robot action \(a\).
User-Friendly Properties. Using this notation, we can formulate the properties that the learned latent space \(Z\) should have. We focus on three properties: controllability, consistency, and scaling.
- Controllability. Let \(s_i\) and \(s_j\) be a pair of states from the dataset \(D\), and let the robot start in state \(s_0 = s_i\). We say that a latent space \(Z\) is controllable if, for every such pair of states, there exists a sequence of latent actions \(\{z_1, z_2, \ldots, z_k\}\) such that \(s_k = s_j\). In other words, a latent space is controllable if it can move the robot between any start and goal states within the dataset.
- Consistency. Let \(d_m\) be a task-dependent metric that captures similarity. For instance, in a pouring task, \(d_m\) could measure the orientation of the robot’s gripper. We say that a latent space \(Z\) is consistent if, for two states \(s_1\) and \(s_2\) that are nearby, the change caused by the latent action \(z\) is similar: \(d_m\big(T(s_1, \phi(z, s_1)),~T(s_2, \phi(z, s_2))\big) < \epsilon\). Put another way, a latent space is consistent if the same latent action causes the robot to behave similarly in nearby states.
- Scaling. Let \(s'\) be the next state that the robot visits after taking latent action \(z\) in the current state \(s\), such that \(s' = T(s, \phi(z,s))\). We say that a latent space scales if the distance between \(s\) and \(s'\) increases to infinity as the magnitude of \(z\) increases to infinity. Intuitively, this means that larger latent actions should cause bigger changes in the robot’s state.
Models. Now that we have introduced the properties that a user-friendly latent space should have, we can explore how different embeddings capture these properties. It may be helpful for readers to think about principal component analysis as a simple way to find linear embeddings. Building on this idea, we utilize a more general class of autoencoders, which learn nonlinear low-dimensional embeddings in a self-supervised manner.3 Consider the model shown below:
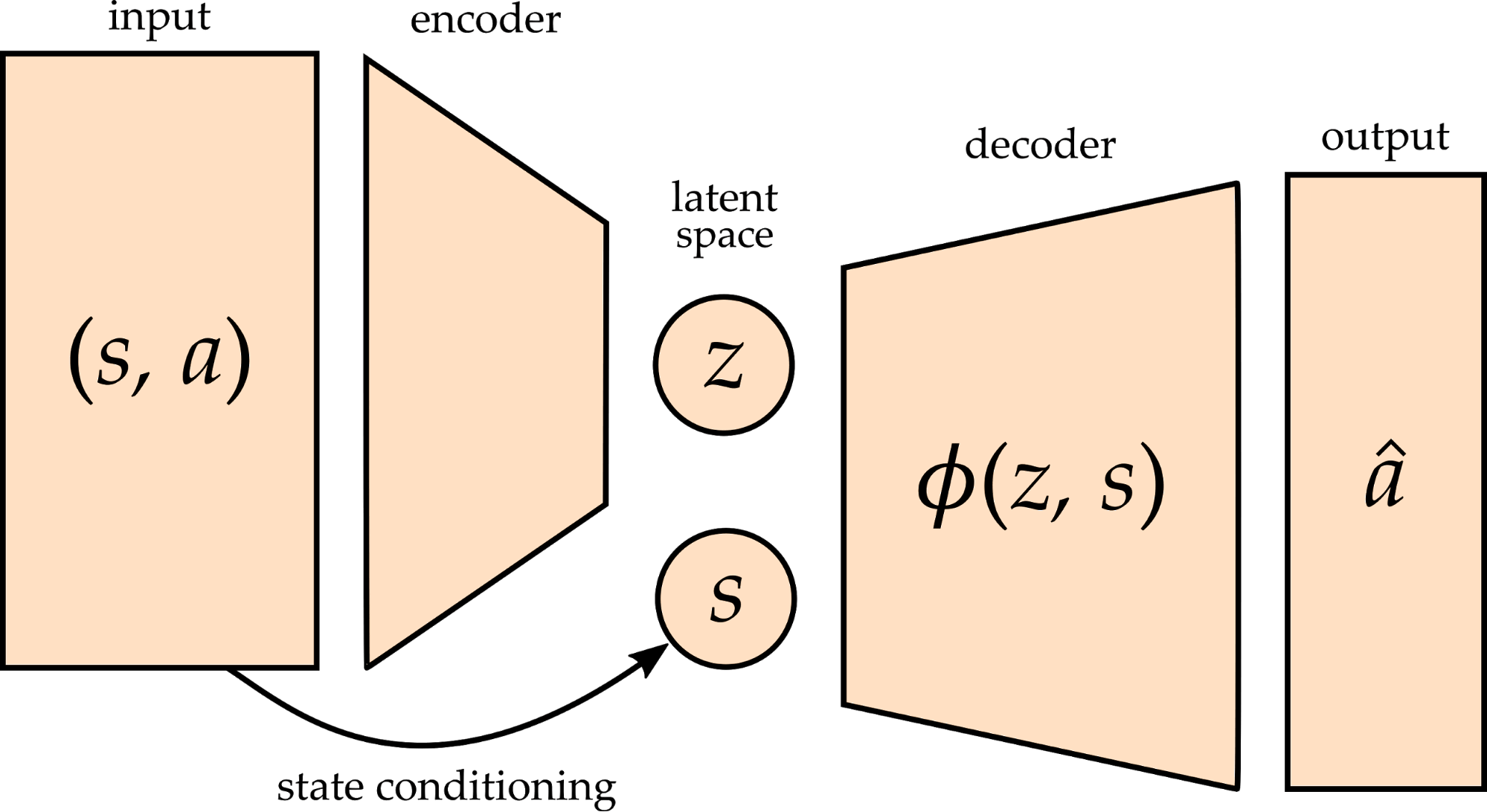
The robot learns the latent space using this model structure. Here \(s\) and \(a\) are state-action pairs sampled from the demonstration dataset \(D\), and the model encodes each state-action pair into a latent action \(z\). Then, using \(z\) and the current state \(s\), the robot decodes the latent action to reconstruct a high-dimensional action \(\hat{a}\). Ideally, \(\hat{a}\) will perfectly match \(a\), so that the robot correctly reconstructs the original action.
Of course, when the end-user controls their assistive robot, the robot no longer knows exactly what action \(a\) it should perform. Instead, the robot uses the latent space that it has learned to predict the human’s intention:
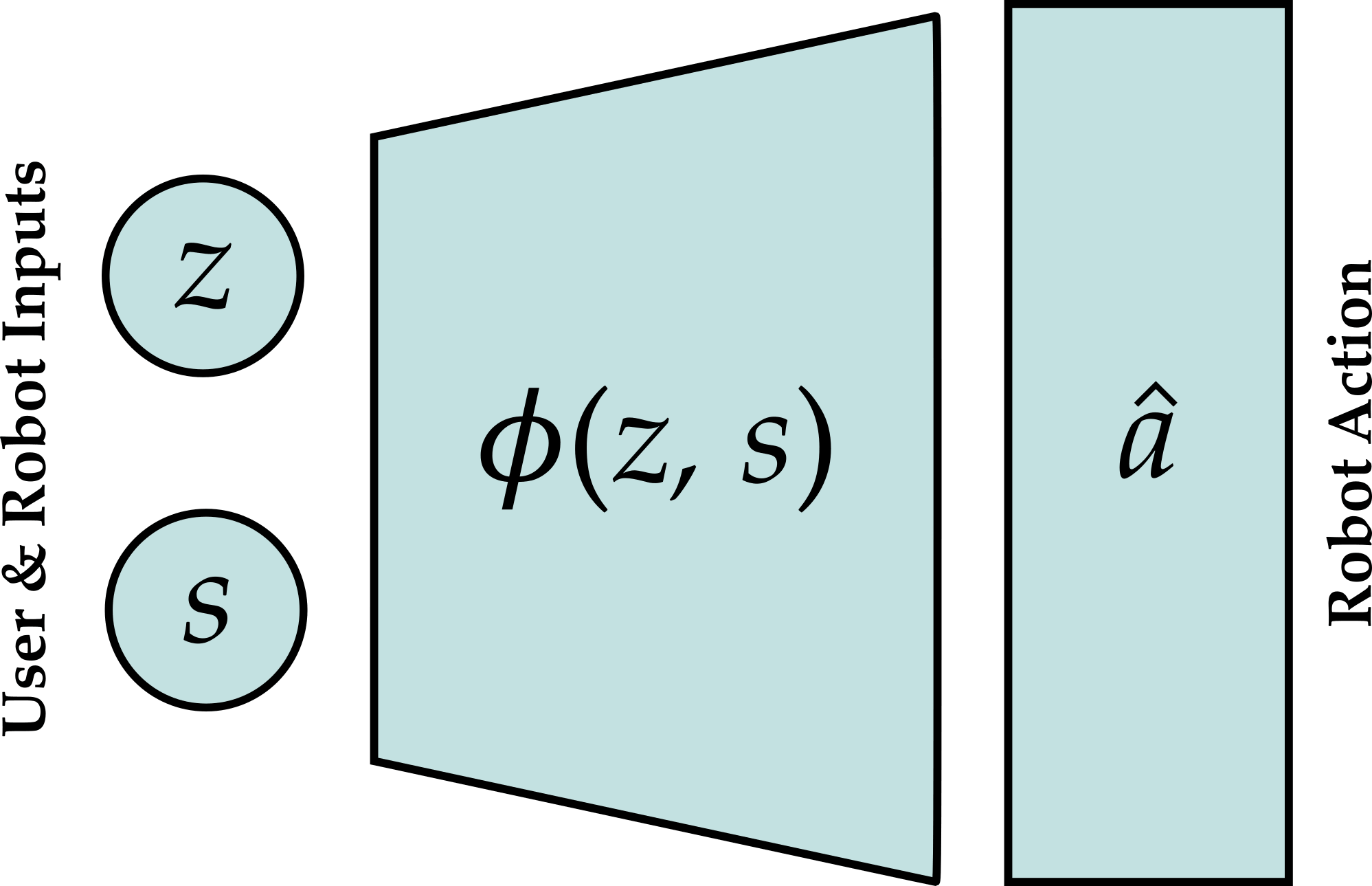
Here \(z\) is the person’s input on the joystick, and \(s\) is the state that the robot currently sees (e.g., its current configuration and the position of objects within the workspace). Using this information, the robot reconstructs a high-dimensional action \(\hat{a}\). The robot then uses this reconstructed action to move the assistive arm.
State Conditioning. We want to draw attention to one particularly important part of these models. Imagine that you are using a joystick to control your assistive robot, and the assistive robot is holding a glass of water. Within this context, you might expect for one joystick DoF to pour the water. But now imagine a different context: the robot is holding a fork to help you eat. Here it no longer makes sense for the joystick to pour—instead, the robot should use the fork to pick up morsels of food.
Hence, the meaning of the user’s joystick input (pouring, picking up) often depends on the current context (holding glass, using fork). So that the robot can associate meanings with latent actions, we condition the interpretation of the latent action on the robot’s current state. Look again at the models shown above: during both training and control, the robot reconstructs the high-dimensional action \(\hat{a}\) based on both \(z\) and \(s\).
Because recognizing the current context is crucial for correctly interpreting the human’s input, we train models that reconstruct the robot action based on both the latent input and the robot state. More specifically, we hypothesize that conditional variational autoencoders (cVAEs) will capture the meaning of the user’s input while also learning a consistent and scalable latent space. Conditional variational autoencoders are like typical autoencoders, but with two additional tricks: (1) the latent space is normalized into a consistent range, and (2) the decoder depends on both \(z\) and \(s\). The model we looked at above is actually an example of a cVAE! Putting controllability, consistency, and scaling together—while recognizing that meaning depends on context—we argue that conditional variational autoencoders are well suited to learn user-friendly latent spaces.
Algorithm. Our approach to learning and leveraging these embeddings is summarized below:

Using a dataset of state-action pairs that were collected offline, the robot trains an autoencoder (e.g., a cVAE) to best reconstruct the actions from that dataset. Next, the robot aligns its learned latent space with the joystick DoF (e.g., set up / down on the joystick to correspond to pouring / straightening the glass). In our experiments, we manually performed this alignment, but it is also possible for the robot to learn this alignment by querying the user. With these steps completed, the robot is ready for online control! At each timestep that the person interacts with the robot, their joystick inputs are treated as \(z\), and the robot uses the learned decoder \(\phi(z, s)\) to reconstruct high-dimensional actions.
Simulated Example. To demonstrate that the conditional variational autoencoder (cVAE) model we described does capture our desired properties, let’s look at a simulated example. In this example, a planar robotic arm with five joints is trying to move its end-effector along a sine wave. Although the robot’s action is 5-DoF, we embed it into a 1-DoF latent space. Ideally, pressing left on the joystick should cause the robot to move left along the sine wave, and pressing right on the joystick should cause the robot to move right along the sine wave. We train the latent space with a total of 1000 state-action pairs, where each state-action pair noisily moved the robot along the sine wave.
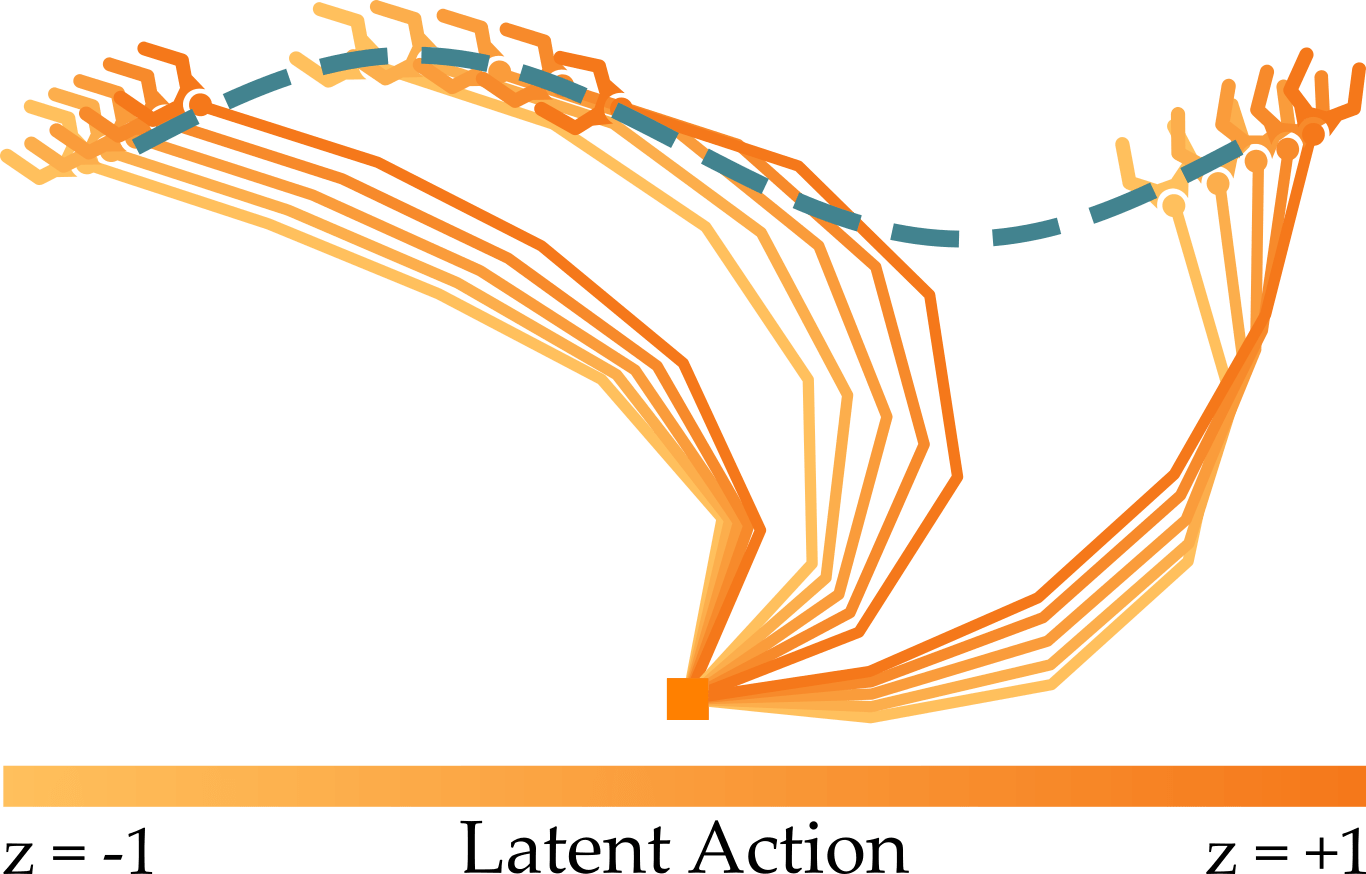
Above you can see how latent actions control the robot at three different states along the sine wave. At each state we apply five different latent actions: \(z = \{-1, -0.5, 0, 0.5, 1 \}\). What’s interesting is that the learned latent space is consistent: at each of the three states, applying negative latent actions causes the robot to move left along the sine wave, and applying positive latent actions cause the robot to move right along the sine wave. These actions also scale: larger inputs cause greater movement.
So the conditional variational autoencoder learns a consistent and scalable mapping—but it is also controllable? And do we actually need state conditioning to complete this simple task? Below we compare the cVAE (shown in orange) to a variational autoencoder (VAE, shown in gray). The only difference between these two models is that the variational autoencoder does not consider the robot’s current state when decoding the user’s latent input.
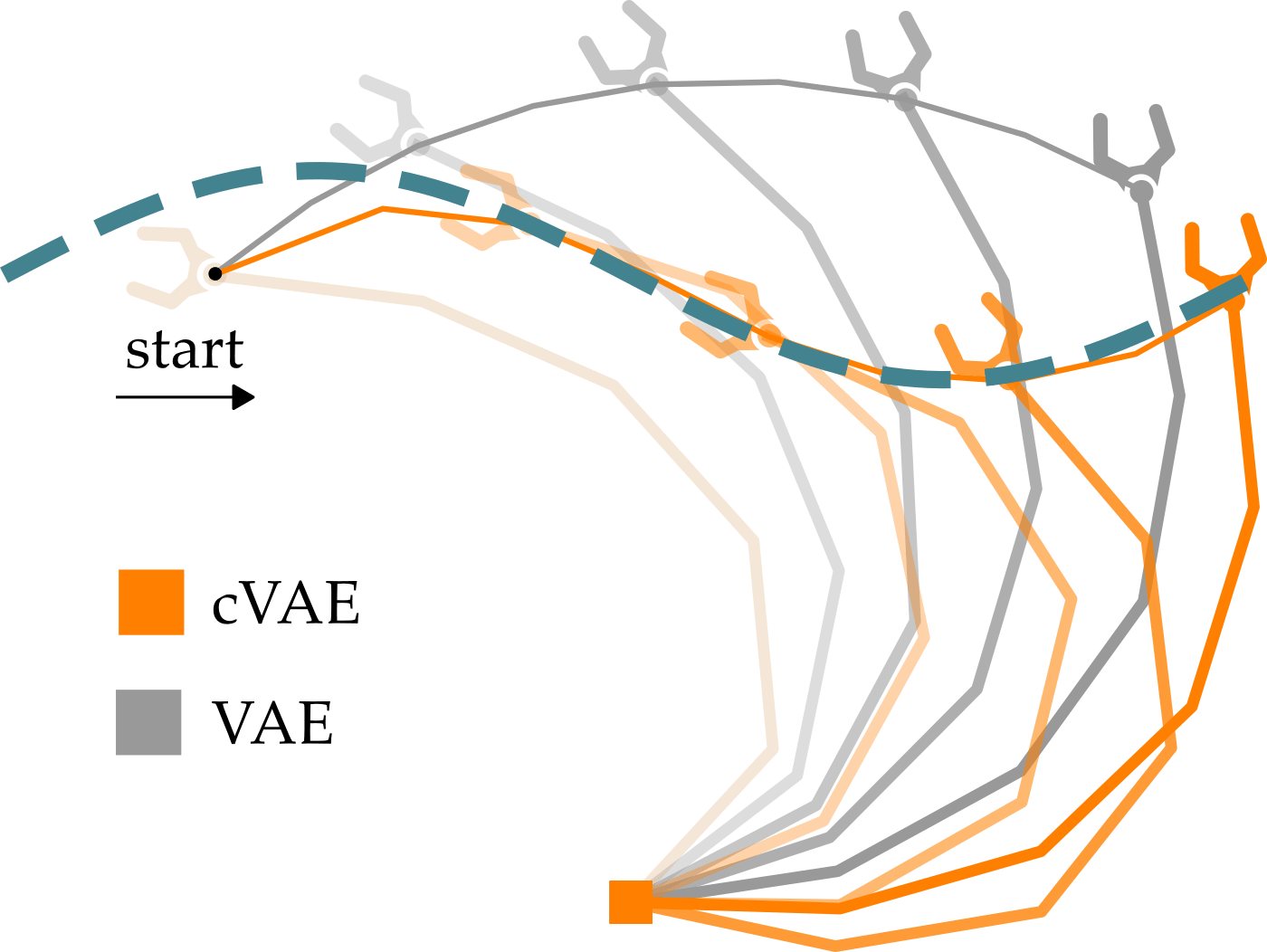
Both robots start on the left in a state slightly off of the sine wave, and at each timestep we apply the latent action \(z=+1\). As you can see, only the state conditioned model (the cVAE) correctly follows the sine wave! We similarly observe that the state conditioned model is more controllable when looking at 1000 other example simulations. In each, we randomly selected the start and goal states from the dataset \(D\). Across all of these simulations, the state conditioned cVAE has an average error of 0.1 units between its final state and the goal state. By contrast, the VAE is 0.95 units away from the goal—even worse than the principal component analysis baseline (which is 0.9 units from goal).
Viewed together, these simulated results suggest that model structure which we described above (a conditional variational autoencoder) produces a controllable, consistent, and scalable latent space. These properties are desirable in user-friendly latent spaces, since they enable the human to perform tasks easily and intuitively.
Leveraging Learned Latent Spaces
We conducted two user studies where participants teleoperated a robotic arm using a joystick. In the first study, we compared our proposed approach to shared autonomy when the robot has a discrete set of possible goals. In the second study, we compared our approach to mode switching when the robot has a continuous set of possible goals. We also asked participants for their subjective feedback about the learned latent space—was it actually user-friendly?
Discrete Goals: Latent Actions vs. Shared Autonomy
Imagine that you’re working with the assistive robot to grab food from your plate. Here we placed three marshmallows on a table in front of the user, and the person needs to make the robot grab one of these marshmallows using their joystick.

Importantly, the robot does not know which marshmellow the human wants! Ideally, the robot will make this task easier by learning a simple mapping between the person’s inputs and their desired marshmallow.
Shared Autonomy. As a baseline, we compared our method to shared autonomy. Within shared autonomy the robot maintains a belief (i.e., a probability distribution) over the possible goals, and updates this belief based on the user’s inputs4. As the robot becomes more confident about which discrete goal the human wants to reach, it provides increased assistance to move towards that goal; however, the robot does not directly learn an embedding between its actions and the human’s inputs.
Experimental Overview. We compared five different ways of controlling the robot. The first four come from the HARMONIC dataset developed by the HARP Lab at Carnegie Mellon University:
- No assist. The user directly controls the end-effector position and orientation by switching modes.
- Low Assist / High Assist / Full Assist. The robot interpolates between the human’s input and it’s shared autonomy action. Within the HARMONIC dataset the High Assist was most effective: here the shared autonomy action is weighted twice as important as the human’s input.
- cVAE. Our approach, where the robot learns a latent space that the human can control. We trained our model on demonstrations from the HARMONIC dataset.
Our participant pool consisted of ten Stanford University affiliates who provided informed consent. Participants followed the same protocol as used when collecting the HARMONIC dataset: they were given up to five minutes to practice, and then performed five recorded trials (e.g., picking up a marshmallow). Before each trial they indicated which marshmallow they wanted to pick up.
Results. We found that participants who controlled the robot using our learned embedding were able to successfully pick up their desired marshmallow almost 90% of the time:
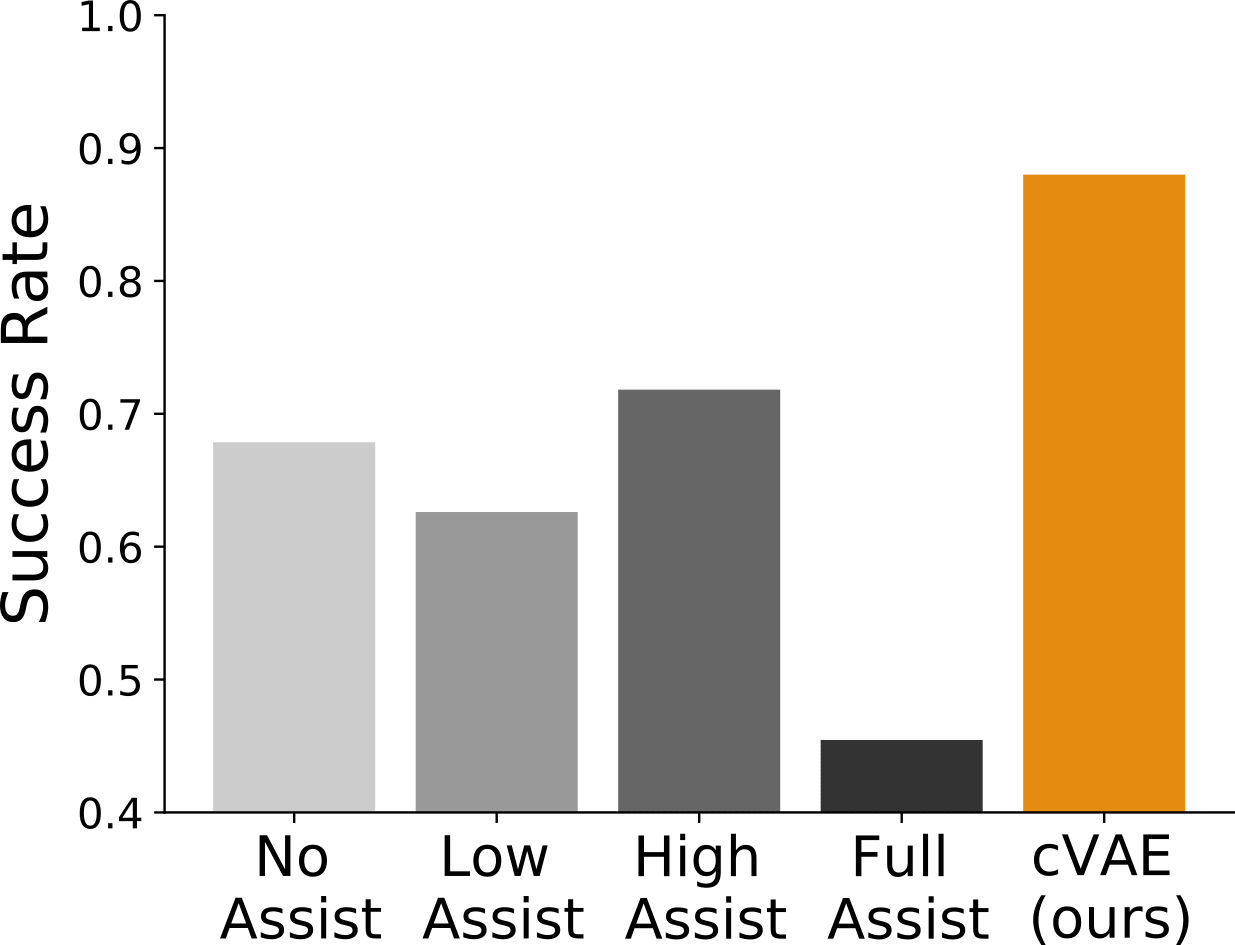
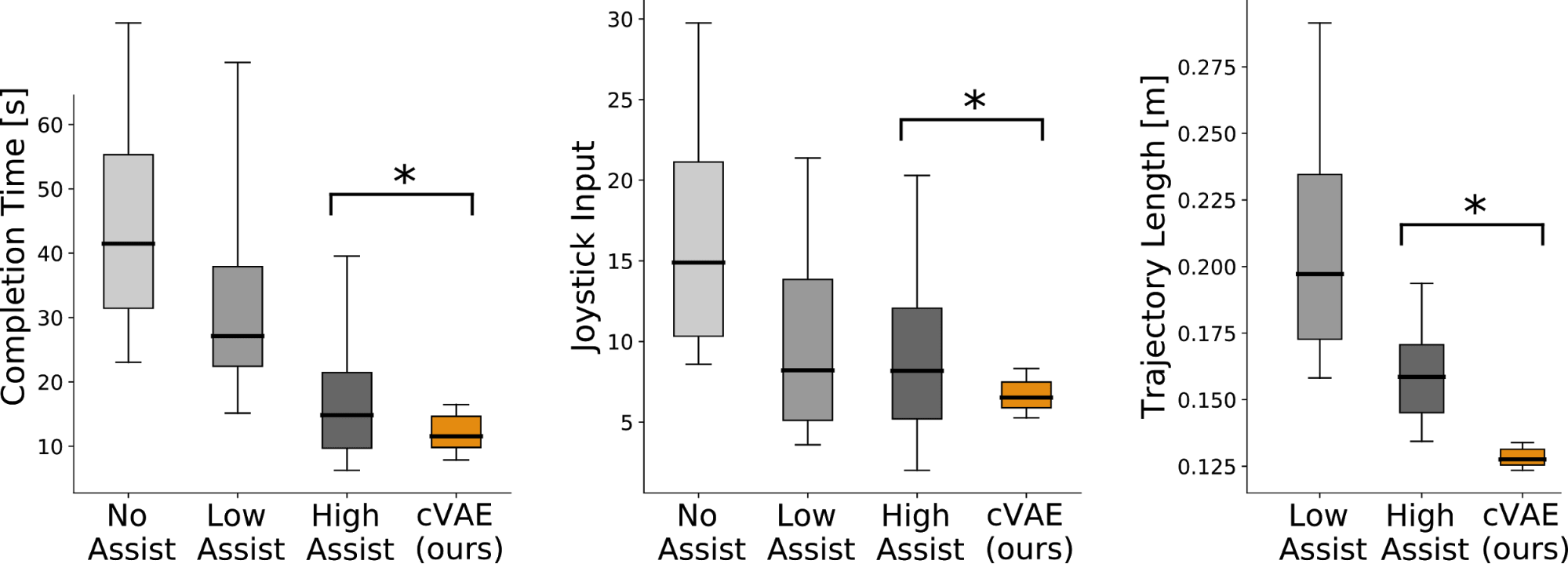
When breaking these results down, we also found that our approach led to completing the task (a) in less time, (b) with fewer inputs, and (c) with more direct robot motions. See the box-and-whisker plots below, where an asterisk denotes statistical significance:
Why did learning a latent space outperform the shared autonomy benchmarks? We think this improvement occurred because our approach constrained the robot’s motion into a useful region. More specifically, the robot learned to always move its end-effector into a planar manifold above the plate. The human could then control the robot’s state within this embedded manifold to easily position the fork above their desired marshmallow:
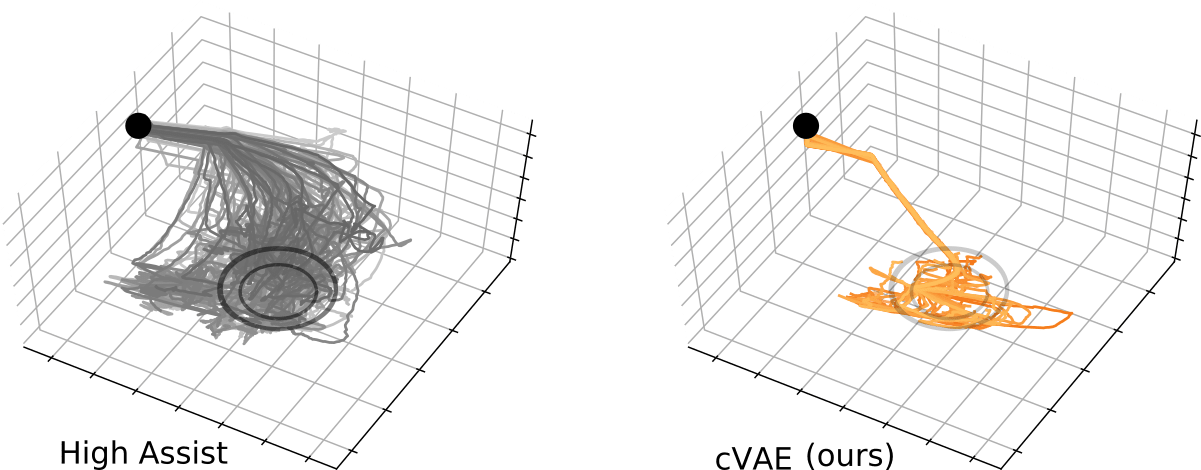
These plots show trajectories from the High Assist condition in the HARMONIC dataset (on left) and trajectories from participants leveraging our cVAE method (on right). Comparing the two plots, it is clear that learning a latent space reduced the movement variance, and guided the participants towards the goal region. Overall, our first user study suggests that learned latent spaces are effective in shared autonomy settings because they encode implicit, user-friendly constraints.
Continuous Goals: Latent Actions vs. Switching Modes
Once the robot knows that you are reaching for a goal, it can provide structured assistance. But what about open-ended scenarios where there could be an infinite number of goals? Imagine that you are trying to cook an apple pie with the help of your assistive robotic arm. You might need to get ingredients from the shelves, pour them into the bowl, recycle empty containers (or return filled containers to the shelves), and stir the mixture. Here shared autonomy does not really make sense—there aren’t a discrete set of goals we might be reaching for! Instead, the robot must assist you through a variety of continuous subtasks. Put another way, we need methods that enable the user to provide and control the robot towards continuous goals. Our approach offers one promising solution: equipped with latent actions, the user can control the robot through a continuous manifold.
End-Effector. As a baseline, we asked participants to complete these cooking tasks while using the mode switching strategy that is currently employed by assistive robotic arms. We refer to this strategy as End-Effector. To get a better idea of how it works, look at the gamepads shown below:
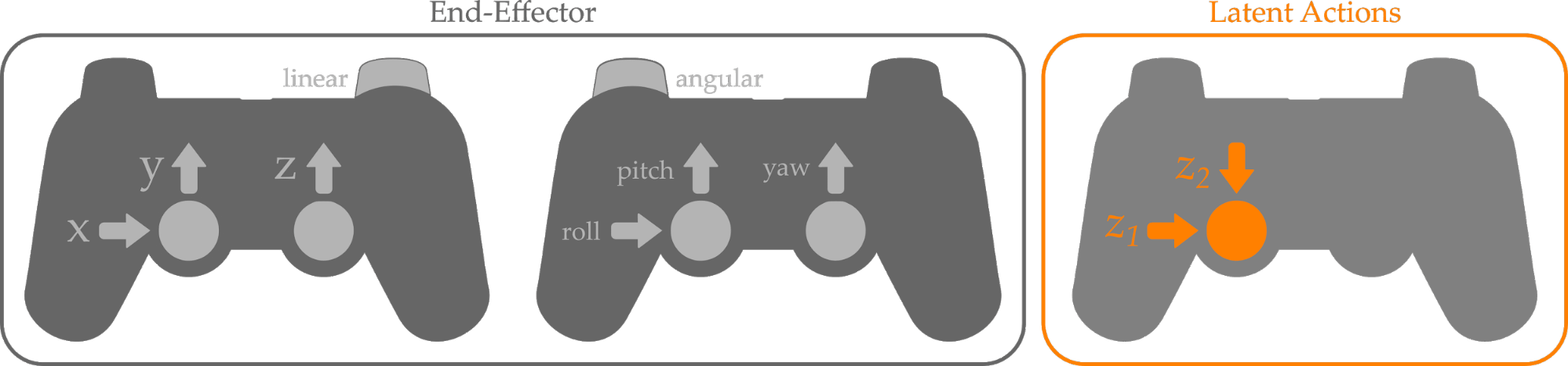
Within End-Effector, participants used two joysticks to control either the position or rotation of the robot’s gripper. To change between linear and angular control they needed to switch between modes. By contrast, our Latent Actions approach only used a single 2-DoF joystick. Here there was no mode switching; instead, the robot leveraged its current state to interpret the meaning behind the human’s input, and then reconstructed the intended action.
Experimental Overview. We designed a cooking task where eleven participants made a simplified apple pie. Each participant completed the experiment twice: once with the End-Effector control mode and once with our proposed Latent Action approach. We alternated the order in which participants used each control mode.
Training and Data Efficiency. In total, we trained the latent action approach with less than 7 minutes of kinesthetic demonstrations. These demonstrations were task-related, and consisted of things like moving between shelves, picking up ingredients, pouring into a bowl, and stirring the bowl. The robot then learned the latent space using its onboard computer in less than 2 minutes. We are particularly excited about this data efficiency, which we attribute in part to the simplicity of our models.
Results. We show some video examples from our user studies below. In each, the End-Effector condition is displayed on the left, and the Latent Action approach is provided on the right. At the top, we label the part of the task that the participant is currently completing. Notice that each of the videos is sped up (3x or 4x speed): this can cause the robot’s motion to seem “jerky,” when actually the user is just making incremental inputs.
Task 1: Adding Eggs. The user controls the robot to pick up a container of eggs, pour the eggs into the bowls, and then dispose of the container:

Task 2: Adding Flour. The user teleoperates the robot to pick up some flour, pour the flour into the bowls, and then return the flour to the shelf:

Task 3: Add Apple & Stir. The user guides the robot to pick up the apple, place it into the bowl, and then stir the mixture. You’ll notice that in the End-Effector condition this person got stuck at the limits of the robot’s workspace, and had to find a different orientation for grasping the apple.

Task 4: Making an Apple Pie. After the participant completed the first three tasks, we changed the setup. We moved the recycling container, the bowl, and the shelf, and then instructed participants to redo all three subtasks without any reset. This was more challenging than the previous tasks, since the robot had to understand a wider variety of human intentions.

Across each of these tasks, participants were able to cook more quickly using the Latent Action approach. We also found that our approach reduced the amount of joystick input; hence, using an embedding reduced both user time and effort.
Subjective Responses. After participants completed all of the tasks shown above, we asked them for their opinions about the robot’s teleoperation strategy. Could you predict what action the robot would take? Was it hard to adapt to the robot’s decoding of your inputs? Could you control the robot to reach your desired state? For each of these questions, participants provided their assessment on a 7-point scale. Here a 7 means agreement (it was predictable, adaptable, controllable, etc.), and a 1 means that the user did not like that strategy.
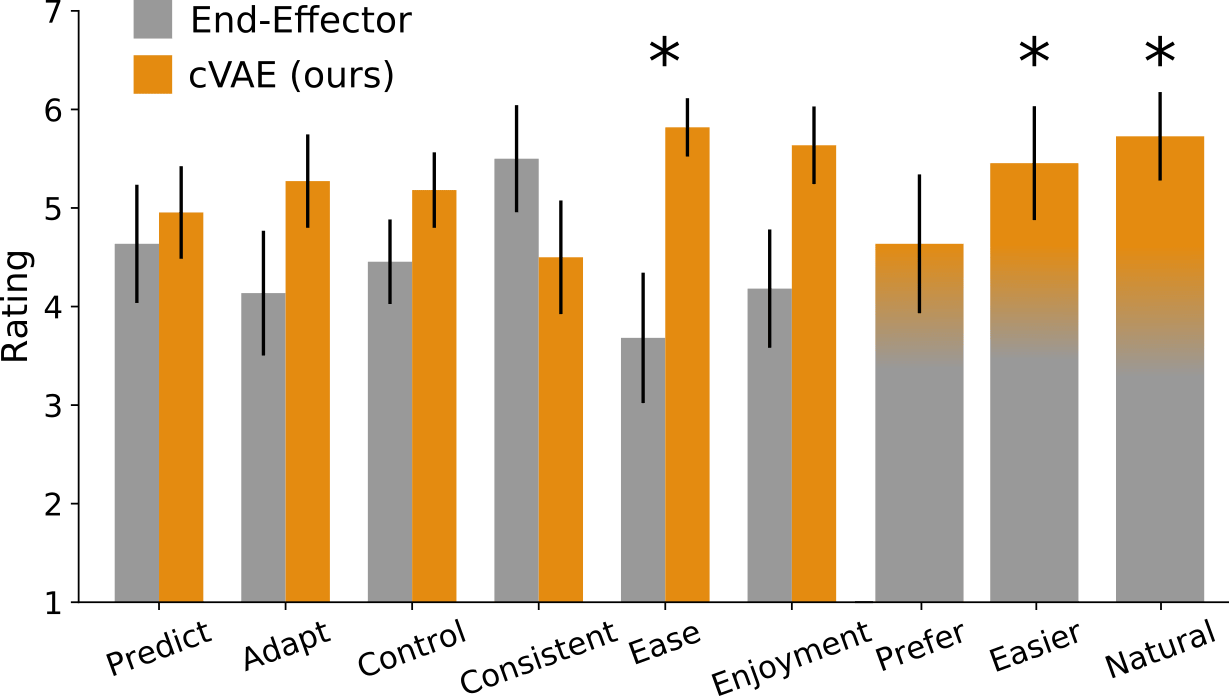
Summarizing these results, participants thought that our approach required less effort (ease), made it easier to complete the task (easier), and produced more natural robot motion (natural). For the other questions, any differences were not statistically significant.
Key Takeaways
We explored how we can leverage latent representations to make it easier for users to control assistive robotic arms. Our main insight is that we can embed the robot’s high-dimensional actions into a low-dimensional latent space. This latent action space can be learned directly from task-related data:
- In order to be useful for human operators, the learned latent space should be controllable, consistent and scalable.
- Based on our simulations and experiments, state conditioned autoencoders appear to satisfy these properties.
- We can leverage these learned embeddings during tasks with either discrete or continuous goals (such as cooking and eating).
- These models are data efficient: in our cooking experiments, the robot used its onboard computer to train on data from less than 7 minutes of kinesthetic demonstrations.
Overall, this work is a step towards assistive robots that can seamlessly collaborate with and understand their human users.
If you have any questions, please contact Dylan Losey at: dlosey@stanford.edu
Our team of collaborators is shown below!

This blog post is based on the 2019 paper Controlling Assistive Robots with Learned Latent Actions by Dylan P. Losey, Krishnan Srinivasan, Ajay Mandlekar, Animesh Garg, and Dorsa Sadigh.
For further details on this work, check out the paper on Arxiv.
-
D. M. Taylor, Americans With Disabilities: 2014. US Census Bureau, 2018. ↩
-
L. V. Herlant, R. M. Holladay, and S. S. Srinivasa, “Assistive teleoperation of robot arms via automatic time-optimal mode switching,” in ACM/IEEE International Conference on Human Robot Interaction (HRI), 2016, pp. 35–42. ↩
-
C. Doersch, “Tutorial on variational autoencoders,” arXiv preprint arXiv:1606.05908, 2016. ↩
-
S. Javdani, H. Admoni, S. Pellegrinelli, S. S. Srinivasa, and J. A. Bagnell, “Shared autonomy via hindsight optimization for teleoperation and teaming,” The International Journal of Robotics Research, vol. 37, no. 7, pp. 717–742, 2018. ↩