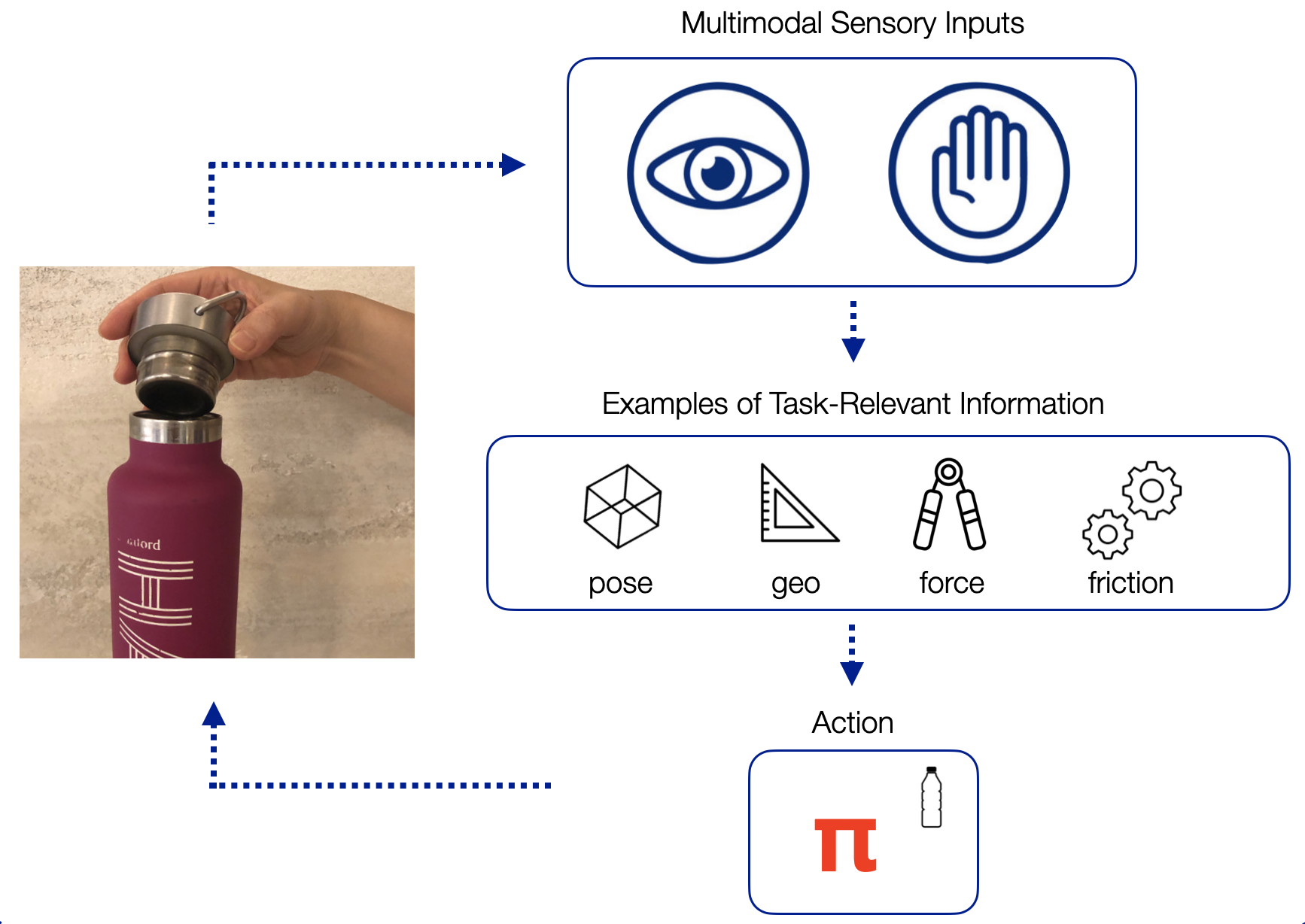
Contact-rich manipulation tasks in unstructured environments often require both tactile and visual feedback. In this blog post, we introduce how to use self-supervision to learn a compact and multimodal representation of vision and touch.
Human–object interactions are multi-stepped and governed by physics as well human goals, customs, and biomechanics -- how can we teach machines to capture, understand, and replicate these interactions?