Humans are good at collaborating with each other — e.g., playing team sports — in part because we adapt to our teammates over multiple repeated interactions. Through these interactions, teammates build a shared understanding of the collaboration strategy, which we refer to as conventions. For example, when playing basketball, teams formulate conventions for signaling when to pass the ball, which offensive formation to take, which players on the opposing team to guard, and more. This ability to build conventions is critical to a team’s success.
The notion of conventions as applied to collaborative tasks has been well-studied, especially in the linguistics literature 12, where people have been shown to reduce their speech length when referring to the same objects with the same partners over repeated interactions. Even outside of linguistics, there are many cultural conventions (e.g., in the U.S., driving on the right side of an unmarked road) or personal conventions (e.g., personalized handshakes with friends) that we use.
It would be nice if we could apply the idea of conventions to human-AI collaboration, for example through assistive robotics. But before deploying robots and artificial agents into people’s homes (for cooking, cleaning, assembling furniture), we must be sure they can identify and learn such conventions in order to collaborate seamlessly with human partners.
In particular, collaboration in multi-agent tasks (e.g., team basketball) often involves two types of skills:
- Task-specific: fundamental skills relevant to the task (e.g., dribbling/shooting basketball)
- Partner-specific: shared strategy developed with the partner (e.g., when to pass the ball)
Task-specific skills are useful no matter who the partner is, such as learning the rules of the game. Partner-specific skills, on the other hand, refer to the shared strategy developed with the partner, i.e. conventions.
Breaking Symmetry
A challenge in collaborating with others is that of symmetry. When there is only one optimal strategy, players can unambiguously go for that strategy. However, when there exist many strategies that are optimal, players might go for different ones, resulting in a combined joint action that is suboptimal. Breaking symmetry, thus, is when players develop conventions as a mechanism to break ties between a set of equally optimal strategies.

For example, in the image above, Toronto Raptors point guard Kyle Lowry is giving a signal to coordinate an offensive play. To us, this signal could refer to almost anything, and there’s no way a priori to break symmetry between any of its possible meanings (e.g., does he want pick-and-roll, isolation, or something else?). Fortunately, his teammates can understand these signals based on conventions they’ve built through practice. As we can see, conventions are important in multi-agent collaboration since they solve the problem of breaking symmetry.
More concretely, consider a game of friendly Rock\((R)\)-Paper\((P)\)-Scissors\((S)\), where the goal is for two friends to throw the same hand. The joint action space of the two friends is \(\{R,P,S\} \times \{R,P,S\}\), and the joint actions \((R,R), (P,P), (S,S)\) are all optimal.
This problem seems trivial, but the two friends must make their actions independently without communicating, and without prior knowledge of the other person’s strategy. That is, their joint policy is factored: \(p(a_1, a_2) = p(a_1) p(a_2)\). Even though any of the 3 optimal joint actions are good, on their first attempt there is no way to know which of the 3 to pick! This is the symmetry breaking problem — there may be many optimal joint actions, but the players must still collectively decide on the same one.
Fortunately, by trial-and-error and building a history of repeated interactions, we can eventually converge on a convention (always pick Rock) with our partners and break symmetry with this shared strategy.
Generalizing to New Partners and New Tasks
So far, we’ve described task-specific skills as important for learning about the fundamentals of the task, and partner-specific skills (i.e. conventions) as important for breaking symmetry. Why make this distinction between the two types of skills? The point is that if we can learn separate representations for tasks and partners, then we can perhaps transfer our knowledge over to new partners and new tasks!
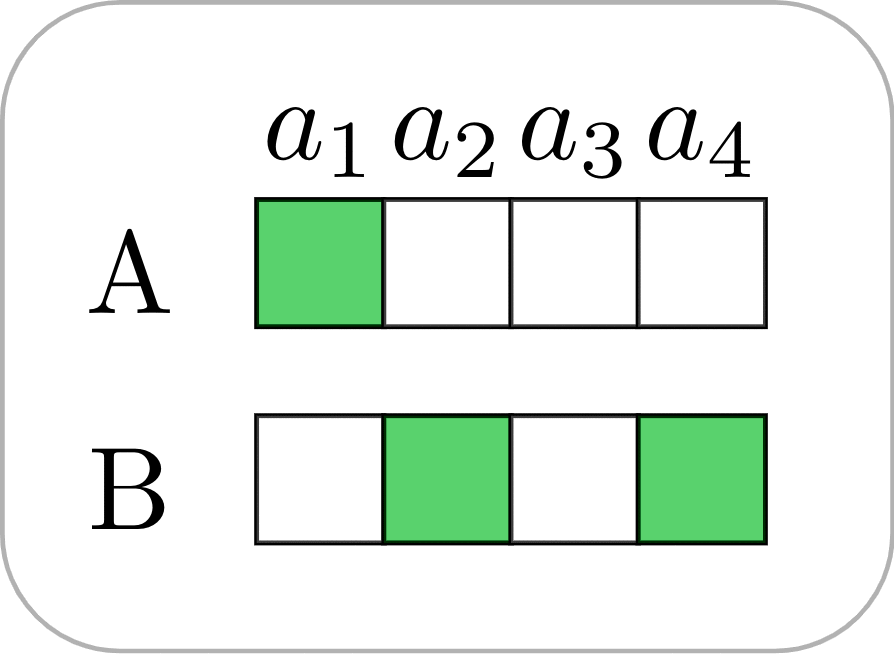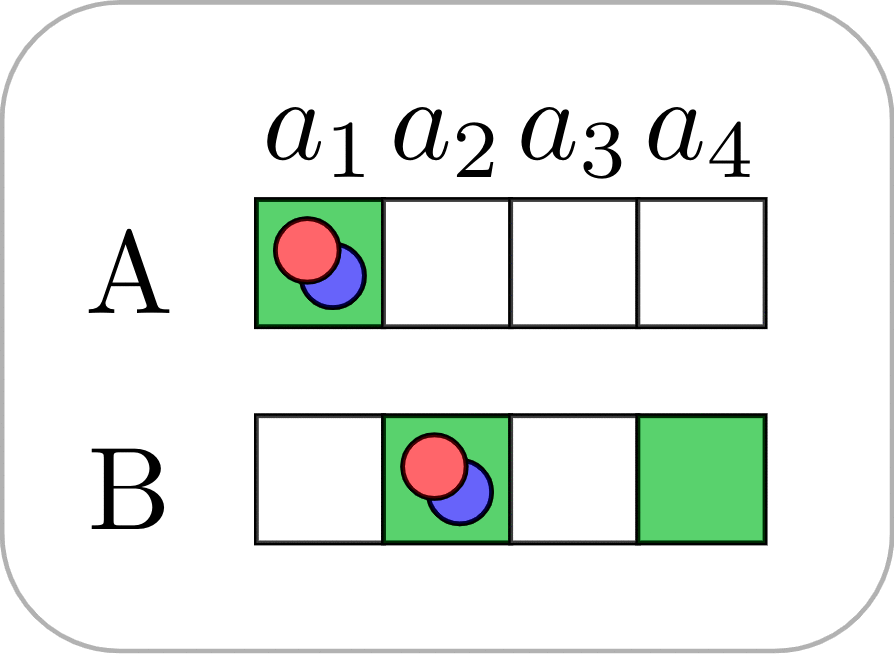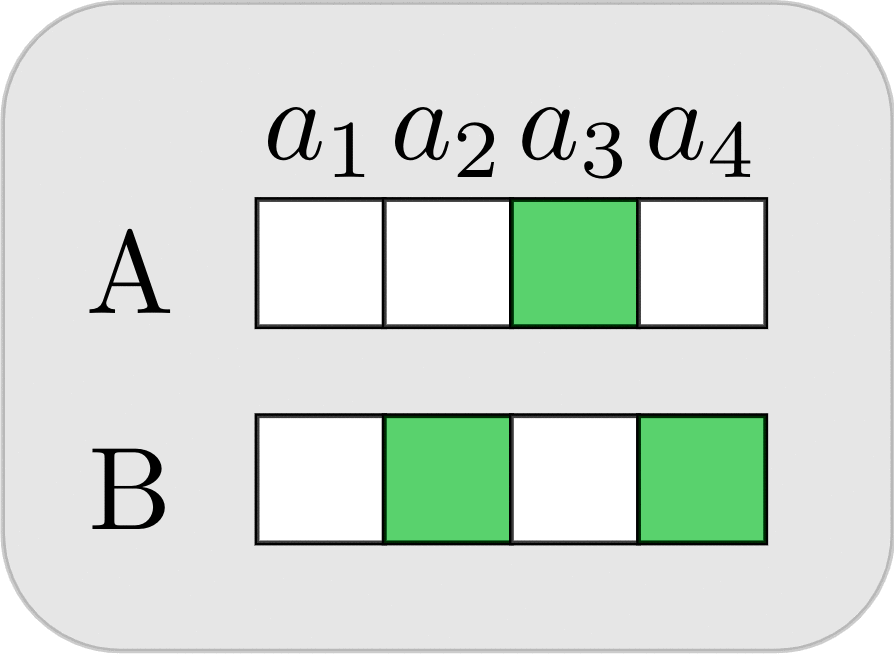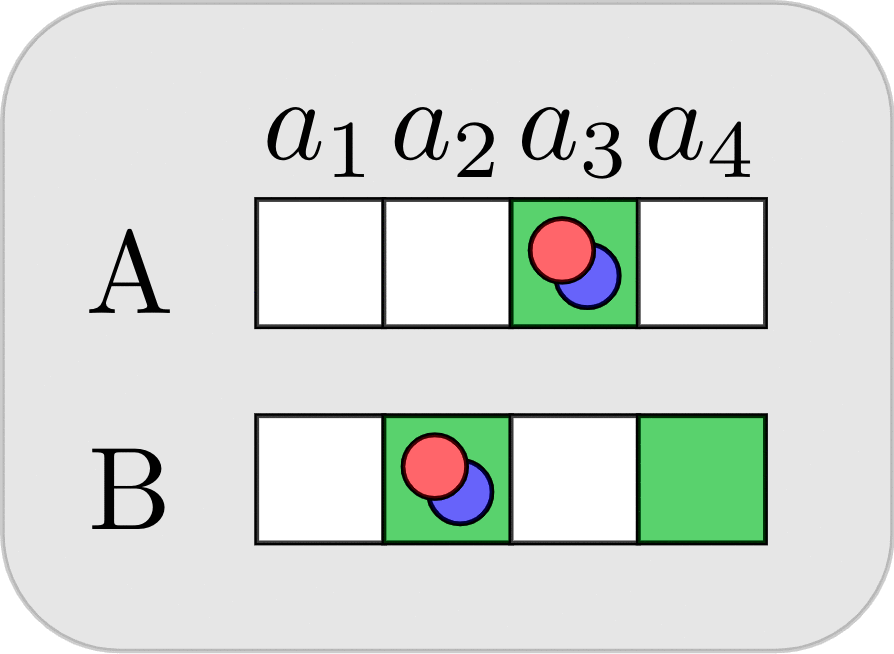
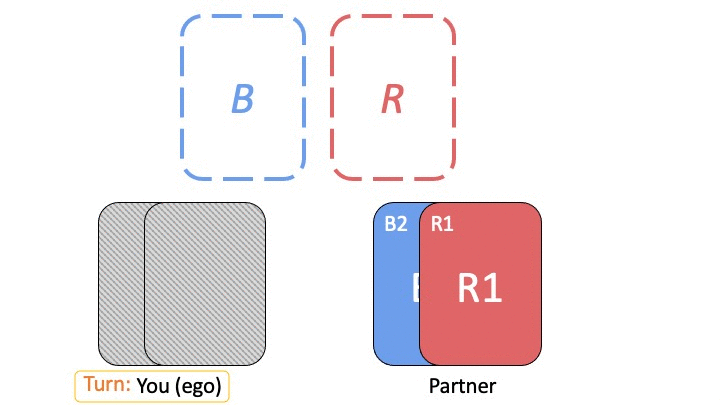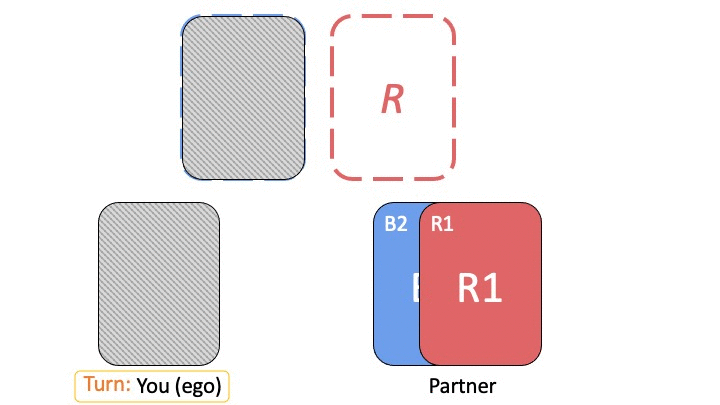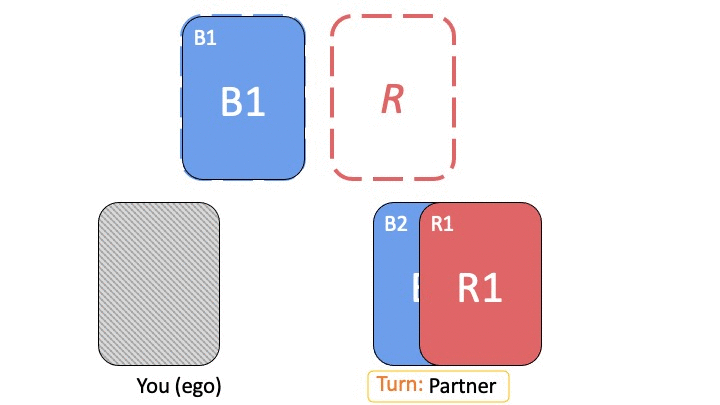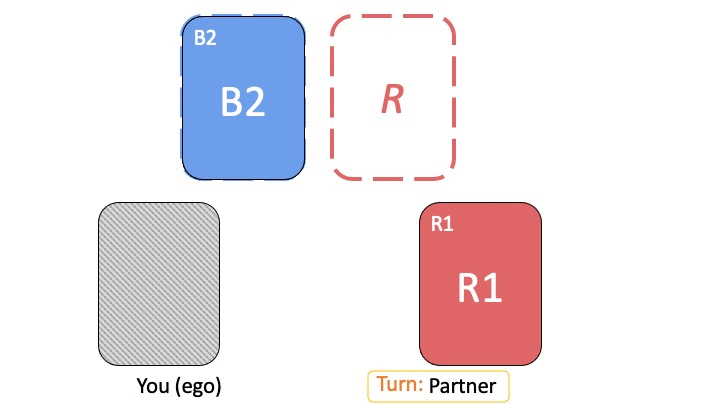
Let’s look at a block placing game that reveals the interplay between task-specific and partner-specific skills. There is a 2x2 grid with a target Goal configuration that a red player (Bob) and a blue player (Alice) have to construct together. Only the red player sees the Goal configuration. The players start with an empty grid, and take turns. On each turn, a player can choose to move/place a block of their own color.
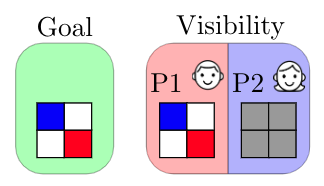
Suppose that Alice and Bob have been playing this game many times, and through trial-and-error have converged on a signaling strategy where on turn 1 Bob always places the red block horizontally opposite the blue block location. Below we see a possible progression of their game (with 4 turns, from left to right). On turn 1 Bob places the red block at the top-right corner. On turn 2 Alice does nothing. On turn 3 Bob places the red block in the correct bottom-right corner. On turn 4, based on signaling conventions that they’ve established, Alice correctly deduces that the blue block should be at the top-left corner.

From Bob’s perspective, the task-specific skill is moving the red block to the bottom-left to match the Goal configuration, whereas the partner-specific skill is signaling the correct blue block location to Alice using his action on turn 1. With this example, we can see how task-specific skills (placing the red block correctly) can be transferred to new partners, and how partner-specific signals can be transferred to tasks with similar symmetries (e.g., if the rules change such that the red block must end up at one of the positions that is empty in the Goal configuration, Bob can still re-use the same conventions to signal to Alice the location of the blue block).
Building Convention-Aware Agents
Given the importance of building conventions, how can we build convention-aware artificial agents? In this work, we design an artificial agent to work well with new tasks and new partners based on the above intuition of separating task-specific and partner-specific representations. We consider two-player collaborative tasks with no external communication, where our agent plays as one of the players, and knows the identity of the task and the partner (e.g., a cooking robot might know if it is working in the same kitchen or with the same person that it has worked with before).
Modular Policy
We use a modular architecture that learns a task module for each task and a partner module for each partner. Given the task and the partner we are playing with, we use the corresponding modules to parameterize our policy. In our design, the task module first processes the input (the state observations of the task), and outputs a 1) latent representation \(z\) and 2) an action distribution \(g^t\). Then the partner modules takes \(z\) as input and predicts another action distribution \(g^p\), and the final policy is given by the multiple of the two actions distributions \(\pi(a \vert s) = g^t(a \vert s) g^p(a \vert z)\).
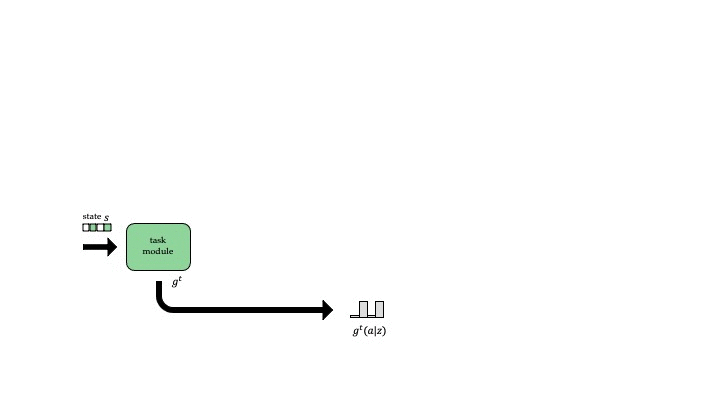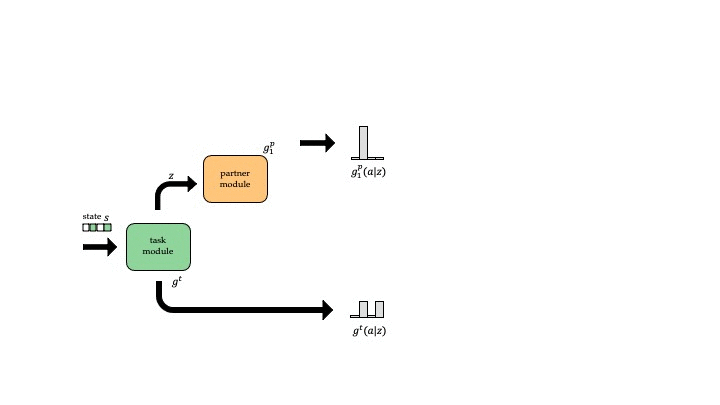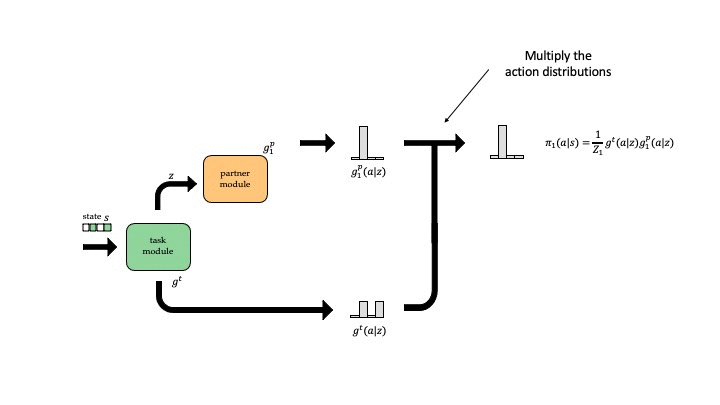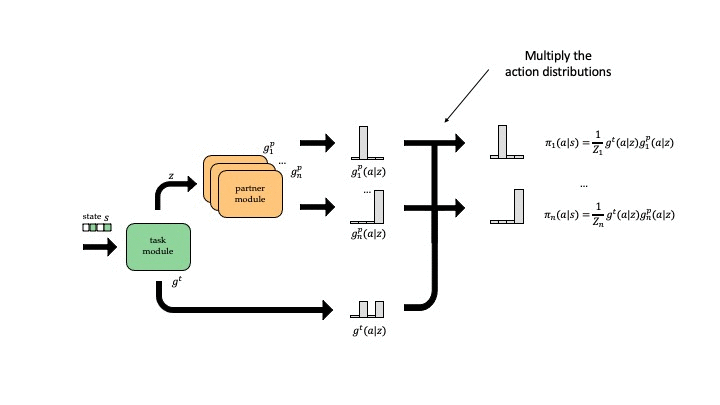
The intuition behind this sequential setup is that the task module action distribution \(g^t\) assigns high probability to all the actions that are potentially good (roughly speaking, there exists a complementary partner action \(a'\) such that \(Q(a, a')\) is good). If there is only one such action, then \(g^t\) may be very sharp; if all actions are good then \(g^t\) may be uniform. Then, the partner module action distribution \(g^p\) outputs how to break the tie between the equally good actions, which we can interpret as the convention built with this partner.
Finally, to prevent the task module from being uninformative and pushing all the hard work to the partner module, we add a regularization term (Eq 1) so that the task module output distribution should match the marginal of the different partner module output distributions (that is, what we should do if we don’t know which partner we’re playing with).
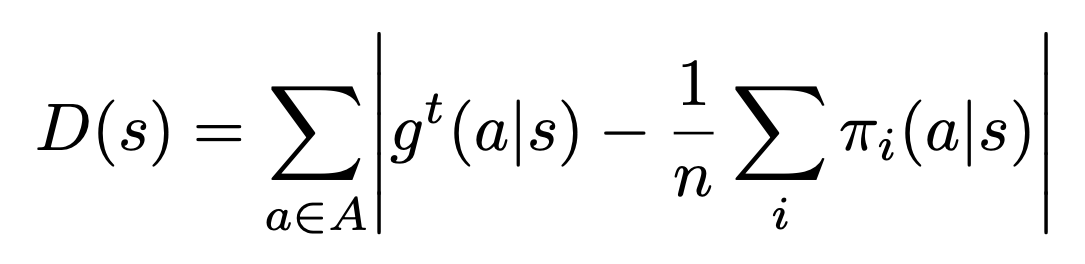 |
(1) |
When given a new partner, we train a new partner module with the same task module — this enables us to transfer over the marginal distribution of the good actions to make, and only worry about learning the tie-breaking preferences of the new partner.
When given a new task (with the same states/actions/dynamics, but different rewards), we train a new task module with the same partner module. This enables us to learn the complexities of the new task, while also recalling the preferences of the partner in terms of breaking ties between equally optimal actions.
Experiments
We ran experiments on multi-armed bandits, the block placing task described above, and a simplified 2-player version of Hanabi.
| Multi-armed Bandit | Block Placing | Hanabi |
|---|---|---|
 |
|
 |
We won’t go into details about the Multi-armed Bandit and the Hanabi tasks in this blogpost, but check out our paper for more details and results!
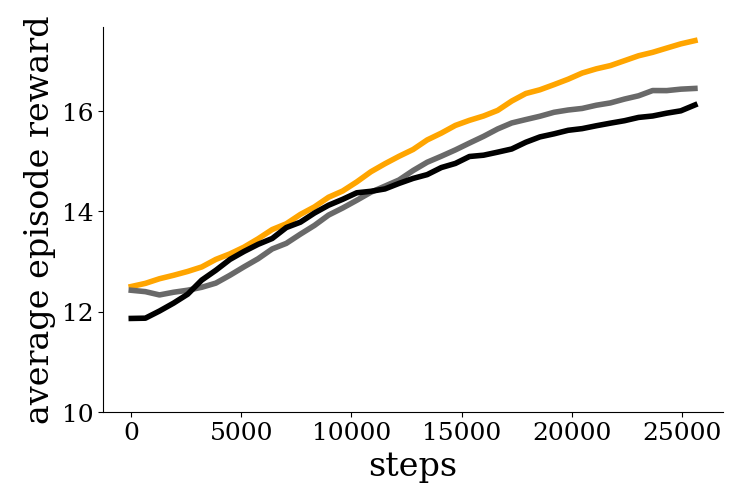
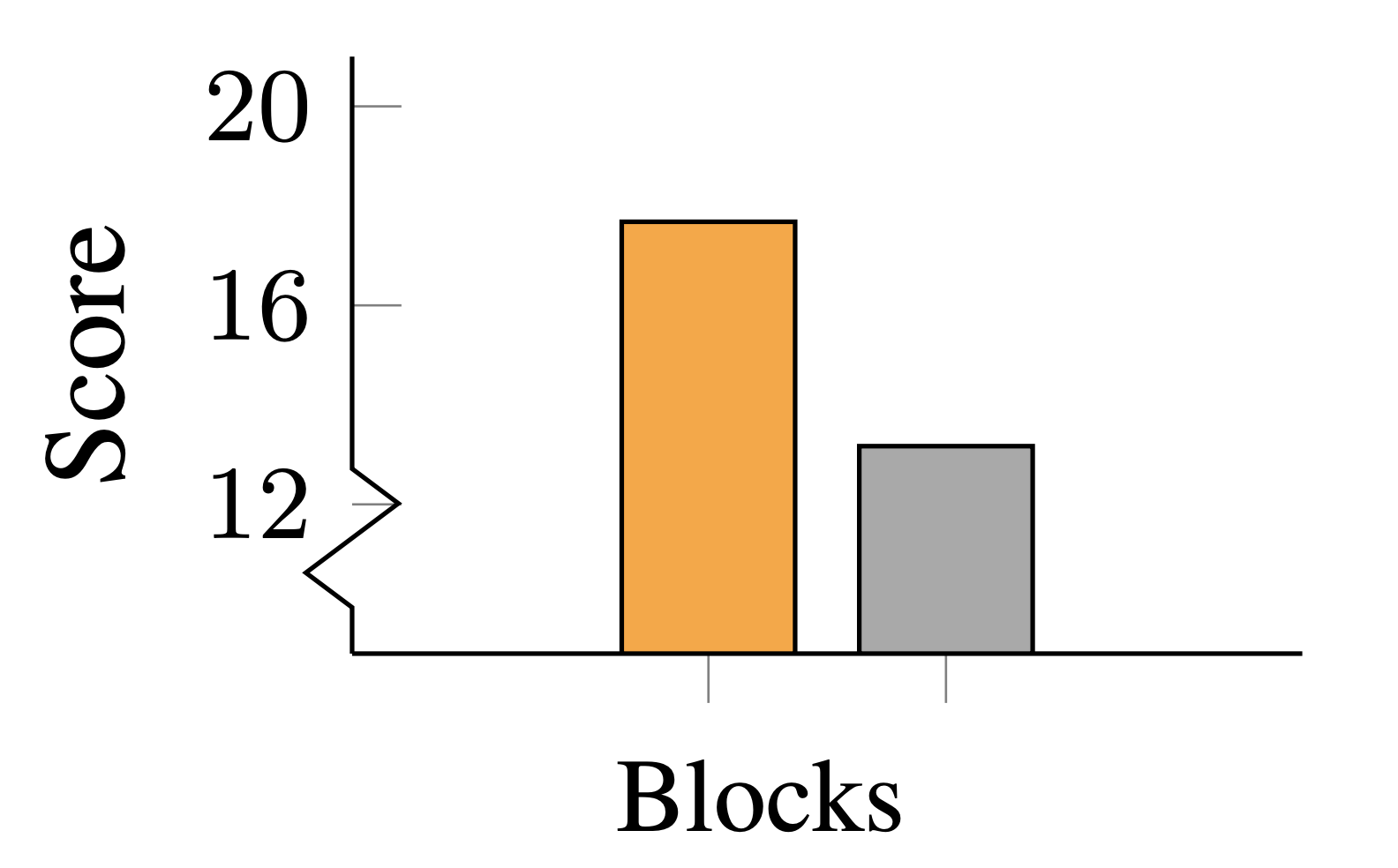
Here we show some plots from the block placing task for both transferring to new partners and new tasks. The max reward for the block placing task is 20. For transferring to new partners, we first train a single task module by playing with a pool of 6 partners, and then test with 6 new partners. Throughout, we use the same task module but use a different partner module for each partner. We compare with baselines BaselineAgg, which aggregates the gradients from all the training partners during training, and First-Order Model-Agnostic Meta-Learning (FOMAML). In contrast to these baselines, our modular setup allows us to reinitialize only the partner-specific representations while re-using the task-specific representations, and we see that this enables faster adaptation to new partners.
For transferring to a new task, we tweak the rule of the game such that the red player (Bob) must place the red block at one of the positions that is empty (white) in the Goal configuration. We train a task module for this tweaked task, and test if our modular architecture can directly generalize to the new task rules while remembering signalling conventions with old partners in a zero-shot manner. We compare with a baseline method that is similarly modular, but does not use a marginal regularization (see Equation 1 above) to push the task module to learn the right representations. Our results suggest that the marginal regularization term is important for transferring to new tasks.

Takeaways
We studied the role of task-specific skills and partner-specific skills (i.e., conventions) in multi-agent collaborative tasks. We explored the use of a modular architecture to train agents that can separate task-specific and partner-specific representations. With the modular setup, we are able to piece together new combinations of modules to adapt more quickly to novel combinations of tasks and partners!
For more details check out our ICLR 2021 paper “On the Critical Role of Conventions in Adaptive Human-AI Collaboration”.
Acknowledgments
Thanks to Sidd Karamcheti and Jacob Schreiber for their helpful comments on this blogpost!
-
Robert D Hawkins, Mike Frank, and Noah D Goodman. Convention-formation in iterated reference games. In Proceedings of the 39th Annual Meeting of the Cognitive Science Society, 2017. ↩
-
Robert D. Hawkins, Michael Franke, Michael C. Frank, Kenny Smith, Thomas L. Griffiths, Noah D. Goodman. From partners to populations: A hierarchical Bayesian account of coordination and convention. 2021. ↩