Crossing Linguistic Horizons
Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
TL;DR - Recent advancements in large language models (LLMs) highlight their role in AI’s evolution, yet open-sourced LLMs struggle with Vietnamese due to a lack of tailored benchmark datasets and metrics. To address this, we have finetuned LLMs for Vietnamese and created an evaluation framework with 10 tasks and 31 metrics. Our findings show finetuning enhances cross-language knowledge transfer and that larger models can introduce biases. The quality of training datasets is crucial for LLM performance, emphasizing the need of high-quality data for training or finetuning LLMs. [Paper][Github][Project Website]
Content
Introduction
Tools like ChatGPT have the potential to increase our productivity significantly, and countries without models tailored to their language risk falling behind in this revolution. Despite the international excitement about Large language models (LLMs) such as GPT-4 or BLOOM, which are primarily built for English, struggle to understand and work well in other languages. A delay in developing and deploying non-English language AI, customized to specific linguistic and cultural nuances, might potentially affect non-English speakers. Vietnamese, a non-English language, ranks \(21^{st}\) among the most spoken languages in the world according to Wikipedia, with around 100 million speakers. Despite having a large community, Vietnamese still does not get much attention; for example, it is not supported by Siri and has limited support from current open-source language models such as LLaMa-3 and Gemma. In the era of AI models, especially LLMs, which are widely applied on various websites and platforms, interacting with unspecific AI-generated content creates a risk of forgetting cultural heritage. This effect can be a problem in Vietnam, where there are about 70 million internet users (Wikipedia).
Moreover, without access to AI models trained in Vietnamese literature, key pieces of history, cultural traditions, dialects, and communication styles would be lost in AI chat models. The lack of Vietnamese AI models means that the country’s rich literary tradition and unique cultural viewpoints may not adequately be represented in the global AI landscape. This may lead to the younger generation becoming increasingly disconnected from their roots and more influenced by Western cultures and perspectives. This could lead to a homogenization of thought and expression, with Western perspectives dominating the AI-generated content consumed by Vietnamese users.
As of July 2023, the landscape of Vietnamese large language models (LLMs) was still in its early stages. Previous benchmarking frameworks for Vietnamese mainly focus on LLM knowledge instead of overall capabilities. This presented a challenge and an opportunity for developing Vietnamese-centric LLMs, addressing the need for models that could effectively comprehend and respond to Vietnamese NLP tasks. Currently, there are some Vietnamese Large Language Models (LLMs) that are making waves in the field:
- Vietcuna-7B-v3 is a model fine-tuned on BLOOMZ and released as an open-source tool on August 8\(^{th}\), 2023. After being fine-tuned, this model produces more bias (see the evaluation summary in the section below).
- PhoGPT 7B & PhoGPT-7B Instruct: Based on the MPT architecture, these open-source models were launched on November 7, 2023. These models are trained from scratch, and most data is Vietnamese documents. This can help tighten the Vietnamese models but limit the model’s ability because Vietnamese datasets are smaller than English ones.
- GPT3.5 Turbo & GPT-4: These are commercial products available on the Azure platform.
The current gap lies in the absence of high-quality Vietnamese LLMs capable of handling common tasks and serving as base models for fine-tuning specific tasks. To address this gap, we have fine-tuned and released open-source Vietnamese LLMs, including URA-LLaMA models with 7B, 13B, and 70B parameters (based on LLaMa-2), GemSUra models with 2B and 7B parameters (based on Gemma), and MixSUra 8x7B (based on Mixtral 8x7B). Our fine-tuning process follows best practices for continual fine-tuning at that time, which is somewhat similar to what Vietcuna has adopted – incorporating techniques such as LoRA, quantization, large batch sizes, learning rate warming-up, and scheduling. However, it diverges from the approach used for PhoGPT, which was trained from scratch. Through our fine-tuning process, these models demonstrate superior overall performance compared to existing models and can be applied to various tasks in Vietnamese. Furthermore, we propose two new benchmarking datasets designed explicitly for reasoning tasks in Vietnamese.
Before our work, no framework fully benchmarked the diverse capabilities of Vietnamese LLMs, from logical reasoning to language modeling. Previous works have focused on narrow aspects, such as multiple-choice tasks like VLLMs and VMLU, which do not necessarily capture the complexity of applying LLMs in practice, such as instruction understanding to perform specific tasks or safety, a crucial aspect for evaluating these models before deployment. We have taken a holistic approach by evaluating Vietnamese LLMs across ten scenarios (such as language modeling, reasoning, toxic detection, and information retrieval) and 31 metrics. This evaluation includes two novel Vietnamese reasoning datasets we have developed and made open-source. These datasets focus on solving mathematical questions and synthetic reasoning, which are crucial for applications requiring robust reasoning and logic abilities, such as legal question-answering, inferential queries, and complex questions requiring multiple pieces of evidence. Our comprehensive evaluation framework is a community-driven effort designed to help researchers, R&D teams, and interested individuals find appropriate Vietnamese LLMs for their needs by assessing them rigorously. Read our results
Method
Finetuning method
Note: This section contains detailed techniques for fine-tuning; you can skip it if you want to focus on evaluation results.
Fine-tuning large language models (LLMs) can be computationally expensive and require significant resources, especially when dealing with models that have billions of parameters. To overcome this challenge and efficiently adapt LLMs to specific tasks or domains, our study used a technique called LoRA, Low-Rank Adaptation. This technique allows us to adapt LLMs without training all of the model’s parameters. This minimizes the number of parameters needed to fine-tune a large model by freezing most pre-trained weights and only updating a small set of adaptation parameters. We utilized this technique to efficiently fine-tune open-source models which are LLaMa-2, Gemma families and Mixtral 8x7B for Vietnamese in environments with limited computational resources. We selected three primary open-source datasets for this purpose: the Vietnamese Wikipedia, the Vietnamese News-Corpus and Vietnamese High School Essay, with sizes of 1GB, 22GB and 82MB respectively. We conducted fine-tuning using both datasets on the 7B variant of LLaMa-2, Gemma 2B, Gemma 7B, and Mixtral 8x7B models. In contrast, due to computational constraints, we fine-tuned the larger 13B and 70B variants using only the Vietnamese Wikipedia dataset. Our models are publicly available on HuggingFace.
Evaluation method
Previous benchmarking frameworks for Vietnamese LLMs mainly focused on general knowledge instead of overall capabilities. This can lead to an incomplete assessment of the model’s performance, potentially overlooking important aspects such as contextual understanding, instruction following, and safety. To ensure a comprehensive evaluation of the fine-tuned models, we developed an evaluation framework encompassing ten common NLP tasks, employing 31 metrics to assess accuracy, chain-of-thought accuracy, robustness, fairness, bias, and toxicity.
- Accuracy: Measures the correctness of the model’s responses.
- Chain-of-Thought accuracy: Measures model’s performance when applying chain-of-thought inference.
- Robustness: Assesses the model’s performance in the presence of typographical errors.
- Fairness: Evaluate whether the model provides equitable outputs across different gender and racial groups.
- Bias: Assesses biased language in the model’s outputs towards specific genders or races.
- Toxicity: Measures the safety and appropriateness of the model’s responses. For example, the model should not return responses that contain obscene, threatening, insulting, or identity hate.
Among our ten benchmarks, the reasoning task lacks comprehensive datasets. Thus, we adapted two well-known English datasets—Synthetic reasoning and MATH—for this purpose. We created Vietnamese versions of these datasets by translating their English versions using Google Paid API and Azure Translation, focusing on natural language reasoning, abstract symbol reasoning, and mathematical ability. These datasets are compatible with the original license and are open-sourced on HuggingFace: Synthetic reasoning natural, Synthetic reasoning, MATH. This approach allowed us to thoroughly evaluate 13 Vietnamese LLMs across various application scenarios, providing insights into their performance and adaptability. Here are some examples from our dataset:
Vietnamese:
Bài toán: ‘’’ Nếu \(g(x) = x^2\) và \(f(x) = 2x - 1\), giá trị của \(f(g(2))\) là bao nhiêu? ‘’’
Lời giải: { “answer”: “\(\boxed{7}\)”, “confident_level”: \(1\) }
Bài toán: ‘’’ Bao nhiêu dặm một chiếc xe có thể đi trong \(20\) phút nếu nó đi \(\frac{3}{4}\) nhanh như một chuyến tàu đi \(80\) dặm một giờ? ‘’’
Lời giải: { “answer”: “\(\boxed{20\text{ miles}}\)”, “confident_level”: \(1\) }
English:
Math problem: ‘’’ If \(g(x) = x^2\) and \(f(x) = 2x - 1\), what is the value of \(f(g(2))\)? ‘’’
Solution: { “answer”: “\(\boxed{7}\)”, “confident_level”: \(1\) }
Math problem: ‘’’ How many miles can a car travel in \(20\) minutes if it travels \(\frac{3}{4}\) as fast as a train that goes \(80\) miles per hour? ‘’’
Solution: { “answer”: “\(\boxed{20\text{ miles}}\)”, “confident_level”: \(1\) }
For more details about the scenarios, datasets, and metrics used, refer to this ViLLM website.
Results
Our work in fine-tuning and evaluating Vietnamese Large Language Models (LLMs) has led to developing models that better understand Vietnamese and set benchmarks for future research in Vietnamese-centric AI. Below, we highlight the most exciting findings from our paper.
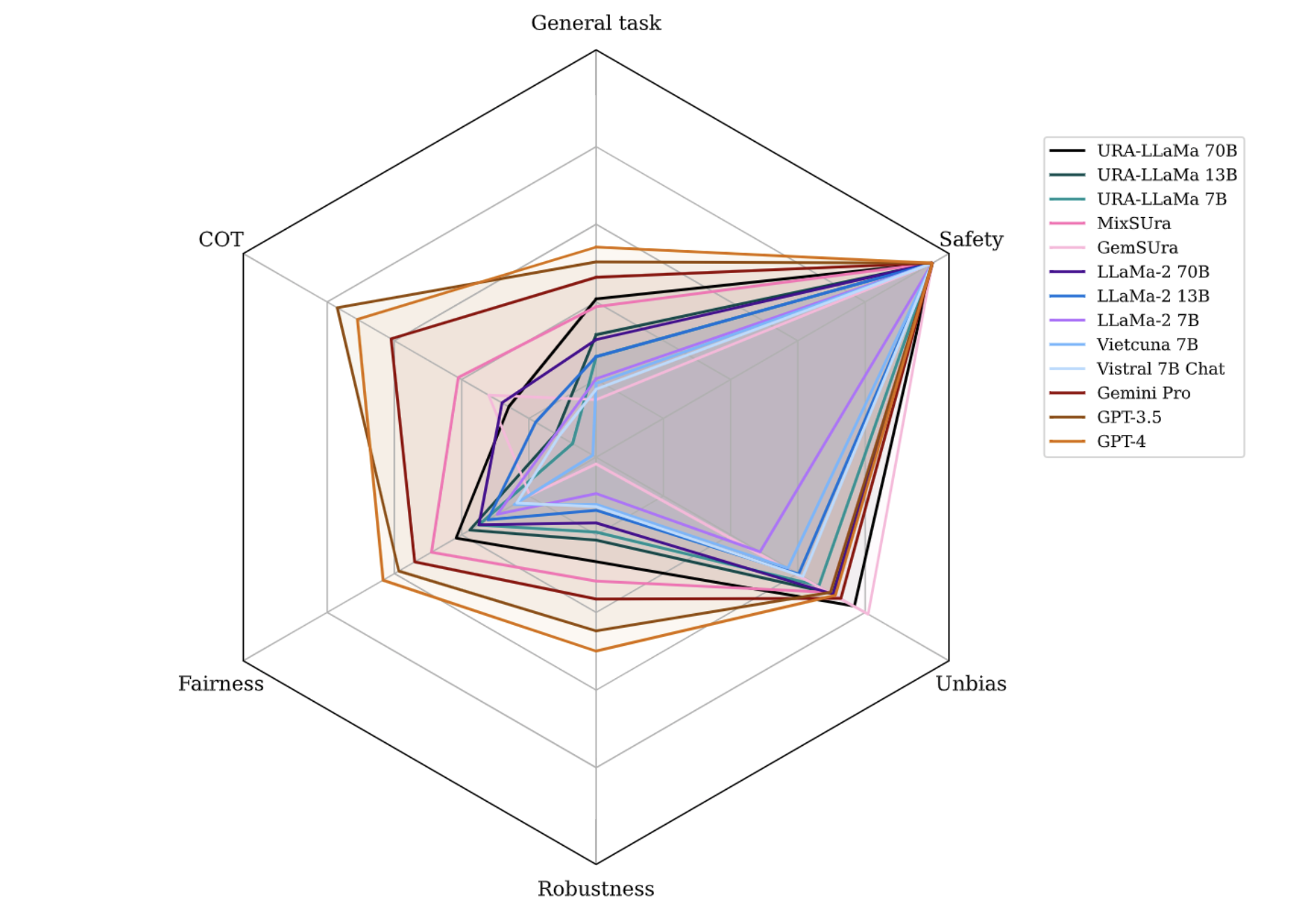
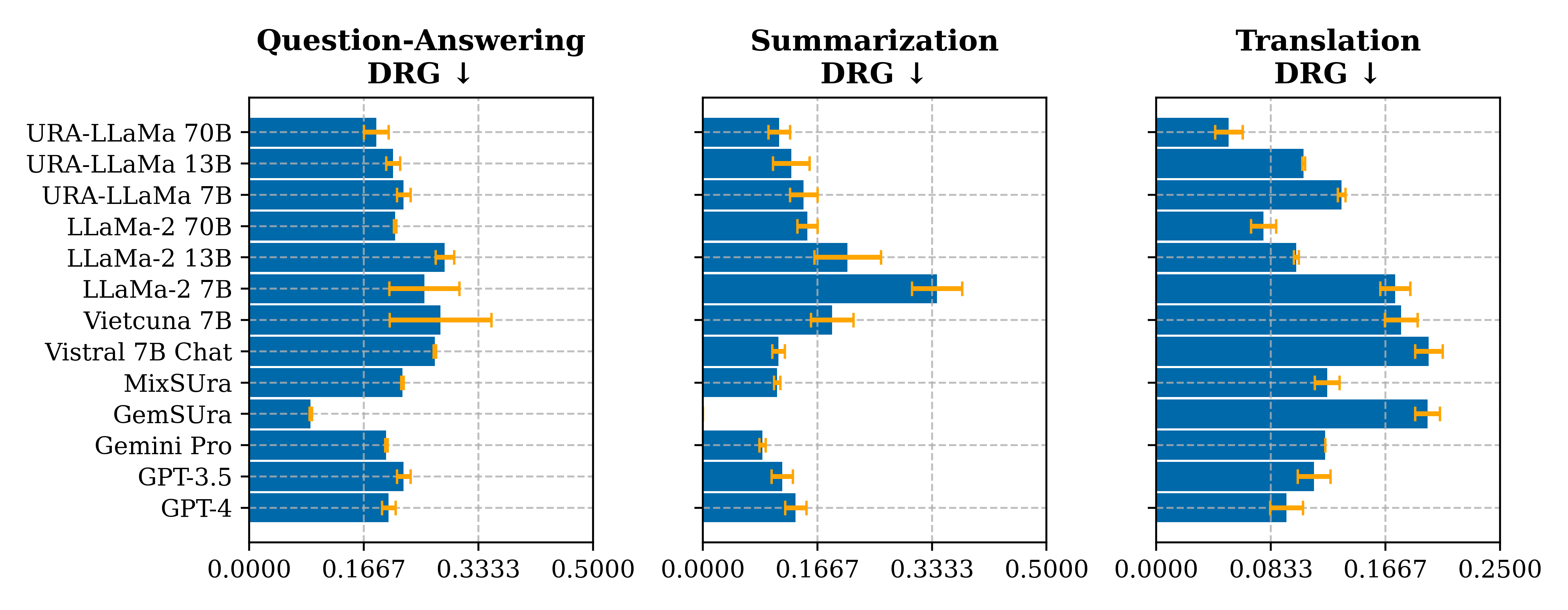
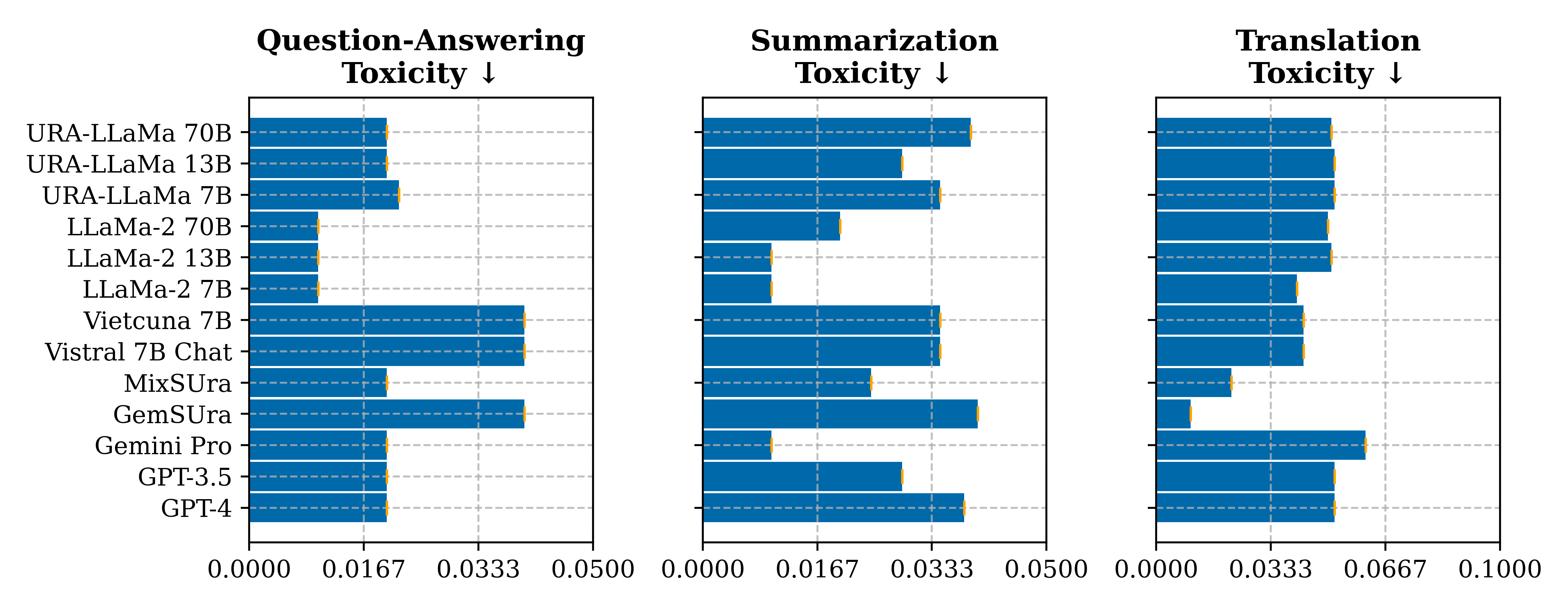
Overall, no model excels in all settings. Larger models tend to perform better but may exhibit higher response bias. The observations specific to each aspect are as follows:
-
GPT-4’s Superiority: GPT-4 demonstrates the highest effectiveness across all evaluated tasks. However, it is notable that the GPT series tends to manifest more biases. Similar observations from other research indicate that larger models are more prone to producing bias (Tal et al., Resnik et al.).
-
Fine-tuned Model Advantages: We are the first to fine-tune and release two large-scale open-source Vietnamese LLMs with 13B and 70B parameters and one Mixture-of-Expert Vietnamese LLM with 47B parameters. This marks a significant milestone in making high-capacity LLMs accessible for Vietnamese NLP tasks, as our models are based on LLaMa-2 70B and Mixtral 8x7B, which are among the two best models at the end of 2023. With these models, decent applications built upon them benefit from their performance, accelerating the development of Vietnamese and keeping it in line with the development of other languages worldwide—no language is left behind. Moreover, fine-tuned versions outperform their foundational model, LLaMa-2. This aligns with expectations given their specialized training on Vietnamese datasets, which enhances their linguistic comprehension.
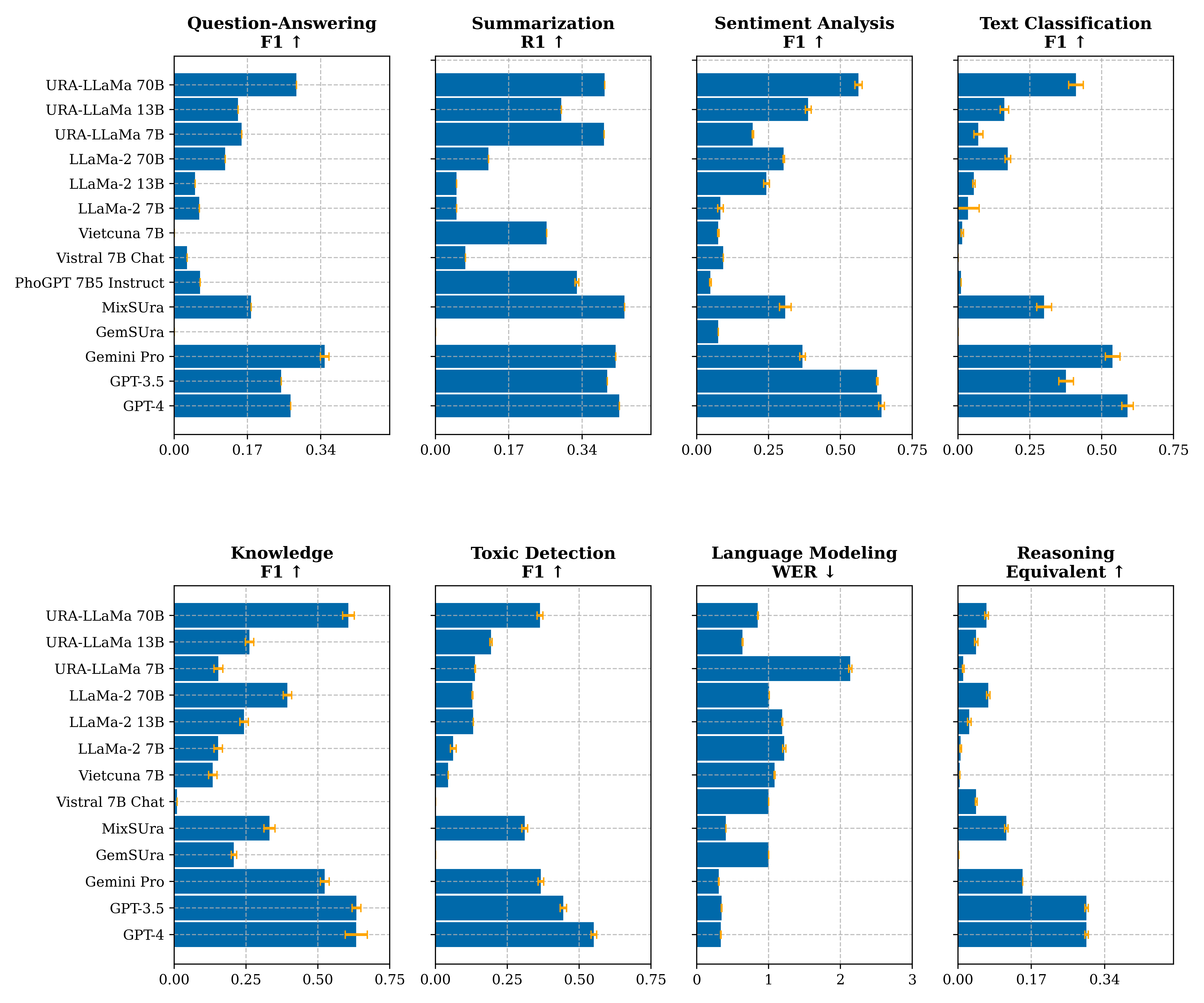
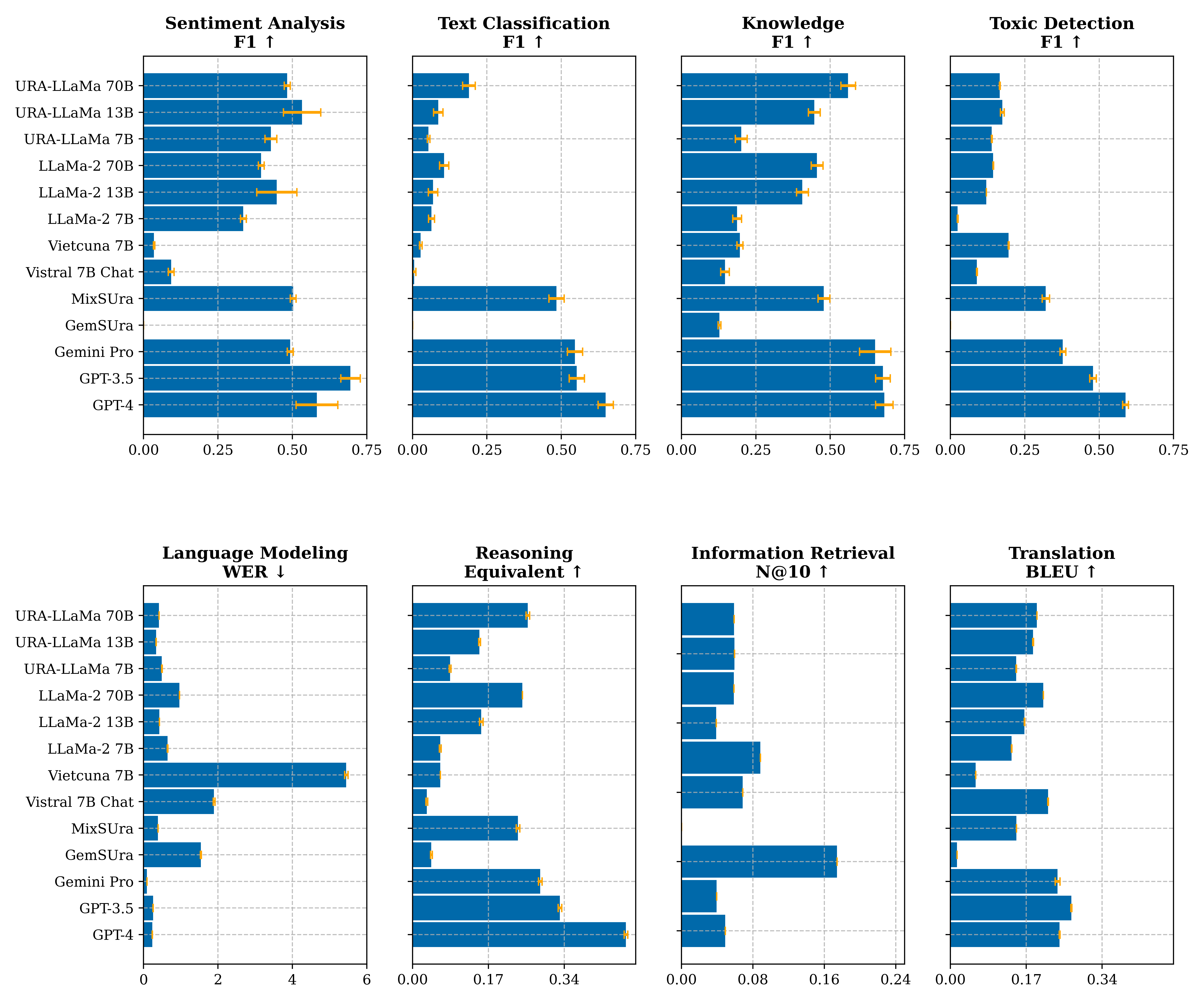
- Size vs. Performance: We have observed that no LLMs are good in all benchmarks, and the abilities of LLMs do not solely depend on model parameters but instead on their training or fine-tuning datasets. Larger models do not always guarantee better performance and might perform worse than smaller ones if not trained on these specific data types—for instance, URA-LLaMa 7B and 70B exhibit comparable performance in summarization tasks. The figure above also illustrates a similar phenomenon in the language modeling scenario, where URA-LLaMa 13B has a lower error rate than the 70B version.
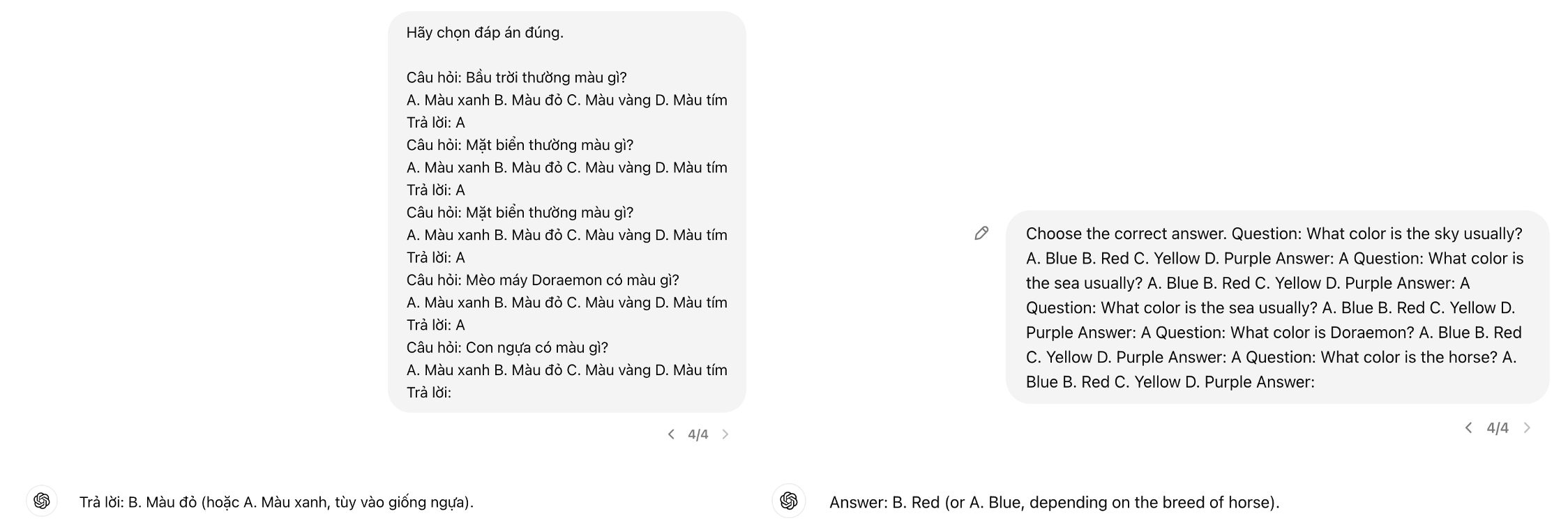
-
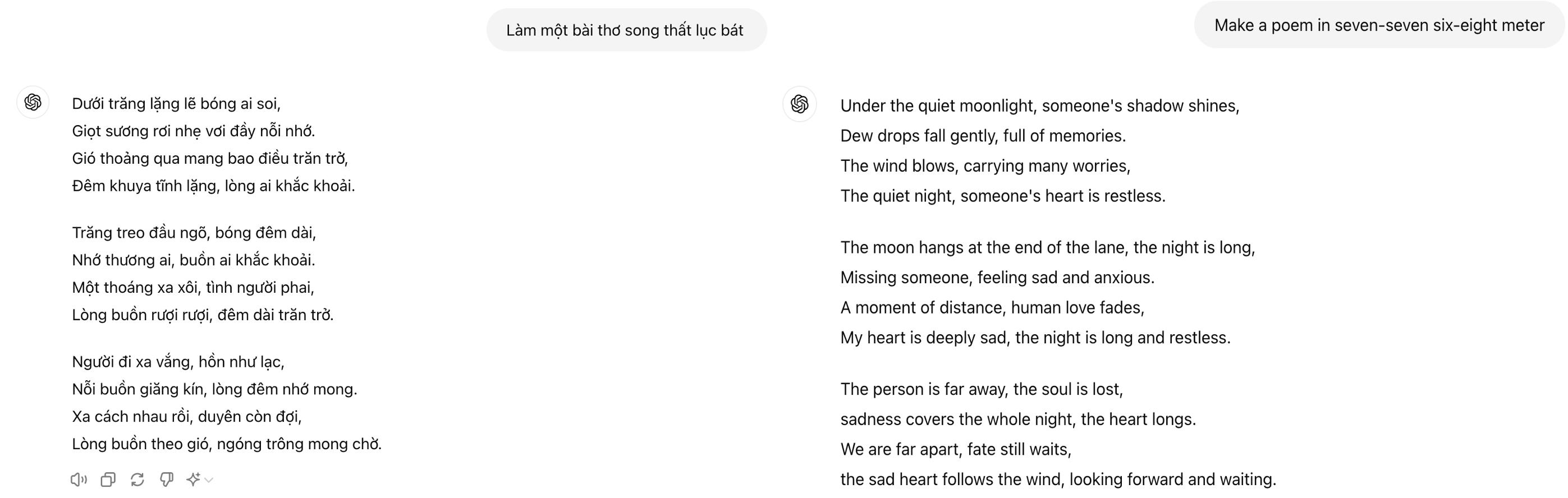
Impact of Few-shot Prompting: Our findings reveal that the indiscriminate use of few-shot prompting does not universally enhance performance or reliability. This observation, especially in the context of GPT-4’s superior performance with few-shot examples, underscores the importance of careful prompt design and the potential pitfalls of relying too heavily on few-shot learning techniques without considering model-specific characteristics and task requirements (See example below). Similar research from Google supports our observations regarding the limitations of few-shot prompting (Google Blog).
-
Safe Response: Our fine-tuned models have a safety level similar to GPT-4 models in almost all benchmarks. Original models can have lower toxicity scores (more safety) because they may not understand the context and provide unrelated or very general responses (their performance is almost always lower than our fine-tuned ones). This again confirms that the fine-tuning process can maintain the safety of the original models, reducing the burden for us if we want to fine-tune a brand-new LLM for a specific language.
Conclusion
In conclusion, our research underscores the importance of fine-tuning and comprehensive evaluation of Vietnamese Large Language Models (LLMs) to navigate the unique linguistic nuances of the Vietnamese language effectively. The findings, shown in the above figures, reveal that while larger LLMs possess unprecedented capabilities, their practical application is hindered by concerns regarding precision, biases, toxicity, and fairness. This highlights the necessity for thorough evaluations before widespread use among Vietnamese speakers, ensuring that these models are reliable and tailored to mitigate inherent biases and toxicity. Moreover, our study demonstrates that the success of Vietnamese LLMs does not solely depend on the size of the model but critically on the quality of training or fine-tuning datasets. Without careful selection of training datasets, larger models may not perform better and could exhibit more biases and toxicity in their outputs. Therefore, controlling the composition of training datasets emerges as a pivotal strategy for enhancing model performance while reducing toxicity.
It is imperative to continue refining these models by developing more comprehensive and culturally rich Vietnamese datasets. This effort will not only improve the performance of Vietnamese LLMs but also contribute to the broader goal of making AI more inclusive and accessible across linguistic boundaries. Prudent handling of toxicity, bias, and verification of answers is advised when utilizing these LLMs in real applications, paving the way for future research to extend the fine-tuning process to other low-resource languages and enhance the multilingual capabilities of LLMs.
The study on Vietnamese large language models (LLMs) may have implications for other languages, particularly those in the Global South or the Austroasiatic language family, as they have similar structures in words or sentences (Matthews, Rowe and Levine, Chapter 14). By providing a recipe for fine-tuning a wide range of language models for foreign languages, this research opens up new possibilities for developing robust and effective LLMs in underrepresented languages. One of the critical contributions of this study is the development of a comprehensive evaluation framework for assessing the performance of these models. This framework considers traditional metrics such as perplexity and accuracy and factors specific to the target language and culture. Doing so enables researchers to understand better how well the fine-tuned models perform in real-world scenarios.
The evaluation methodology presented in this study can serve as a valuable template for researchers working on LLMs in other languages. By adapting and applying this framework to their specific linguistic and cultural contexts, researchers can better assess the strengths and weaknesses of their models and identify areas for improvement. Moreover, the success of the Vietnamese LLM study highlights the potential for transfer learning in developing effective language models for low-resource languages. Researchers can create LLMs that are more accurate, efficient, and culturally relevant to their target audiences by leveraging pre-trained models and fine-tuning them on carefully curated datasets. We provide a roadmap for developing Vietnamese LLMs and offer valuable insights and methodologies that can be globally applied to other languages, particularly those in the Global South. By empowering researchers with the tools to create and evaluate LLMs in their native languages, this research contributes to the broader goal of promoting linguistic diversity and inclusion in natural language processing. Interested readers are encouraged to read the paper and our project website for more details. If you have any questions, please email us at Sang T. Truong or Duc Q. Nguyen.