![]()
The Conference on Computer Vision and Pattern Recognition (CVPR) 2025 is being hosted from June 11th - June 15st. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Apollo: An Exploration of Video Understanding in Large Multimodal Models

Contact: orrzohar@stanford.edu
Links: Paper | Website
Keywords: lmms, video understanding
Automated Generation of Challenging Multiple-Choice Questions for Vision Language Model Evaluation

Contact: yuhuiz@stanford.edu
Links: Paper | Video | Website
Keywords: vision language models, evaluation, multiple choice questions
Birth and Death of a Rose

Contact: gengchen@cs.stanford.edu
Links: Paper | Website
Keywords: 4d vision, computer graphics, computer vision
Category-Agnostic Neural Object Rigging
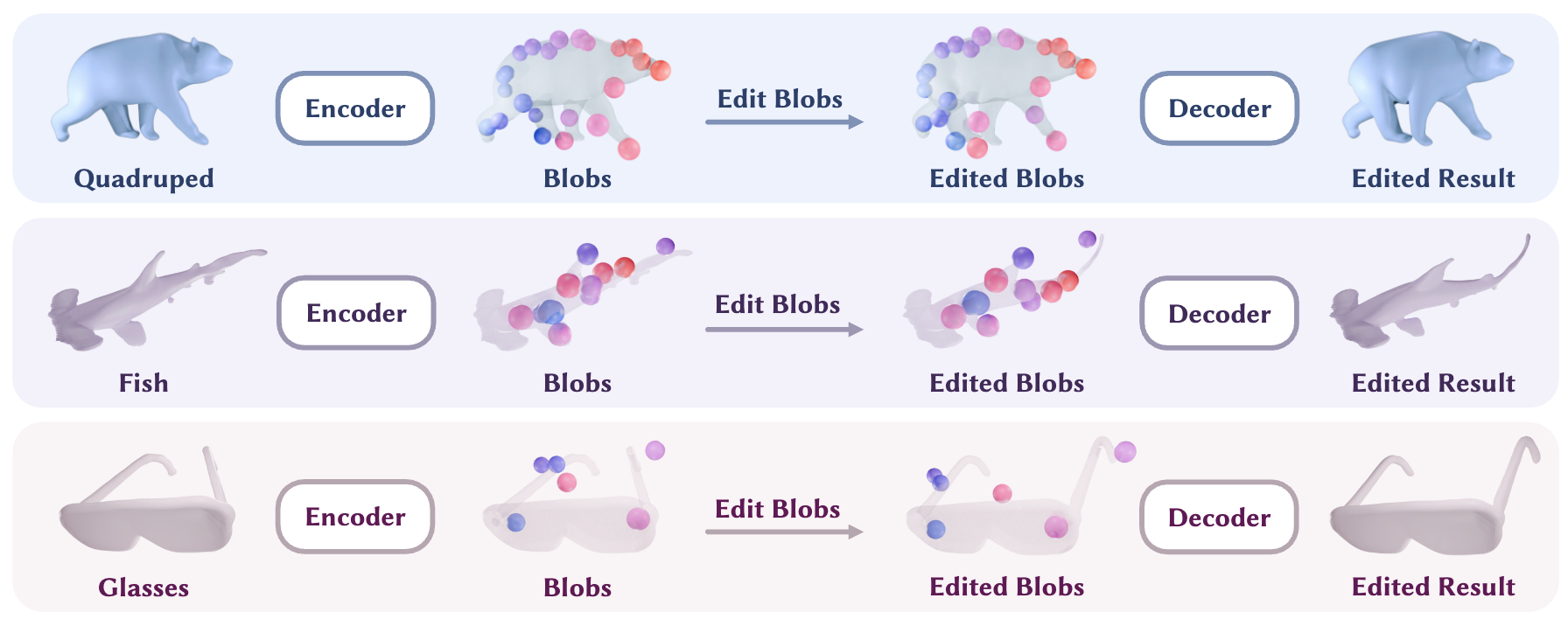
Contact: gengchen@cs.stanford.edu
Links: Paper | Website
Keywords: 4d vision, computer vision, computer graphics
FirePlace: Geometric Refinements of LLM Common Sense Reasoning for 3D Object Placement

Contact: ianhuang@stanford.edu
Links: Paper | Video | Website
Keywords: multimodal large language models, 3d object placement, scene generation
Latent Drifting in Diffusion Models for Counterfactual Medical Image Synthesis

Contact: azade.farshad@tum.de
Award nominations: CVPR Highlight
Links: Paper | Website
Keywords: medical image generation, counterfactual image generation, diffusion models
MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research

Contact: jmhb@stanford.edu
Links: Paper | Blog Post | Website
Keywords: reasoning, benchmark, science, microscopy, biomedical, vqa
The Scene Language: Representing Scenes with Programs, Words, and Embeddings

Contact: yzzhang@cs.stanford.edu
Links: Paper | Website
Keywords: visual representation, visual generation
We look forward to seeing you at CVPR 2025!