

Sources: Oculus First Contact, Boston Dynamics.
Tremendous progress has been made in the last few years in developing advanced virtual reality (VR) and robotics platforms. As the examples above show, these platforms now allow us to experience more immersive virtual worlds, or allow robots to perform challenging locomotion tasks like walking in snow. So, can we soon expect to have robots that can set the dinner table or do our dishes?
Unfortunately, we are not yet there.

Examples of human–object interactions in everyday life. Sources: Visit Jordan, EPIC Kitchens.
To understand why, consider the diversity of interactions in daily human life. We spend almost all of our waking hours performing activities—simple actions like picking up a fruit or more complex ones like cooking a meal. These physical interactions, called human–object interactions, are multi-stepped and governed by physics as well as human goals, customs, and biomechanics. In order to develop more dynamic virtual worlds, and smarter robots, we need to teach machines to capture, understand, and replicate these interactions. The information we need to learn these interactions is already widely available in the form of large video collections (e.g., YouTube, Netflix, Facebook).
In this post, I will describe some first steps we have taken towards learning multi-step human–object interactions from videos. I will discuss two applications of our method: (1) generating plausible and novel human-object interaction animations suitable for VR/AR, (2) enabling robots to react smartly to user behavior and interactions.
Problem and Challenges
We focus our investigation on a subset of the diverse interactions that humans experience — common tabletop home or office interactions where the hand manipulates objects on a desk or table. Tabletop interactions such as the ones shown below constitute a large proportion of our daily actions and yet are hard to capture because of the large space of hand-object configurations.

Some example tabletop interactions from our video collection. We gathered 75 videos (20 validation) similar to the ones shown above.
Our goal is to recognize, represent and generate these physical interactions by learning from large video collections. Any such approach must solve challenging vision-based recognition tasks and generate multi-step interactions that are consistent, temporally and spatially, with present and past states of the environment. It should also obey basic physical laws (e.g., objects cannot interpenetrate), human customs (e.g., hold a coffee mug with its handle), and limitations of human biomechanics (e.g., not reach too far).

We focus on human–object interactions in typical tabletop settings. We can capture interactions from video collections (top inset) and synthesize animations of these interactions.
1. Represent as Action Plots
Human activity spaces and the interactions that they can support span a large space of possibilities. Interacting with objects results in continuous spatio-temporal transformations, making them difficult to formalize. However, these complex interactions can be modeled sequentially, i.e., through transition probabilities from a given state to subsequent states.
To parametrize interactions in this sequential model, we introduce a representation called action plot. An action plot is a sequence of actions performed by a hand causing a state change in the scene. Each action defines a unique phase in the interaction and is represented as an action tuple consisting of an action label, duration, and participating objects with their end states and positions. This discretization allows us to focus on the combinatorial nature of interactions, while abstracting away the complexity of spatio-temporal transformations.

For instance, a simple interaction such as pouring water into a cup, can be described by an action plot containing the following atomic actions: (1) move hand (to grasp cup), (2) move cup, (3) move hand (to grasp bottle) (4) move bottle, (5) pour water from bottle to cup, (6) move bottle.
Formally, an action tuple is defined for a single time step as \(T = (a, d, o, s, p)\), where \(a\) is the action label, \(d\) is the action duration, \(o\) is the set of active objects participating, \(s\) is the end state of \(o\), \(p\) is the end position of \(o\). The duration and end positions are continuous variables in time units and 2D coordinates, respectively. The action labels, participating objects, and object end states are one-hot vectors denoting discrete variables. We decouple the time-varying and the time-invariant parameters in the action, which allows us to use appropriate statistical models for each.
2. Recognize from Video Collections
Our goal then is to learn to generate action plots containing plausible multi-step interactions that capture the physical constraints and causal dependencies in the real world. We aim to automatically learn this from video collections of humans interacting in a scene, since this is a quick, inexpensive and versatile setup. To fully characterize action plots, we need: (1) involved object instances, categories and positions, (2) hand positions, (3) action detection and segmentation, all of which are highly challenging to extract from video. Our automatic pipeline builds upon the most recent advances in computer vision and achieves state-of-the-art accuracy on tasks such as action segmentation. To learn interactions, we acquired a large video collection of 75 interaction videos at different locations and users. The videos show hand–object and object–object interactions with complex interactions on up to 10 objects.
Object and Instance Tracking: An important component of action plots are object categories, instances, locations, and states. We use state-of-the-art object detectors based on the Faster R-CNN architecture to find candidate bounding boxes and labels and object positions (2D and approximate 3D) in each frame, and subsequent temporal filtering to reduce detection jitter. To infer the object state, we train a classifier on the content of each bounding box.

Results from our method for object instance detection and tracking, and hand detection. We build upon the state-of-the-art computer vision methods.
Hand Detection: Since most interactions involve the hand, we aim to infer which objects are manipulated by the hand as well as the object position when it is occluded by the hand. We use a fully convolutional neural network (FCN) architecture to detect hands. This network is trained using data from the hand masks in the GTEA dataset and fine-tuned on a subset of our video collection. Hand detection and object motions allow us to infer hand state (empty, occupied), which is an important piece of information.
Action Segmentation: To generate action labels for each video frame, we need to identify the involved actions as well as their start and end times (i.e., action segmentation). We adopt a two phased approach: (1) extract meaningful image features for each frame, (2) use the extracted features to classify action labels for each frame and segment the actions. For added robustness to over-segmentation resulting from frame-based action classification, we use a Long Short-Term Memory (LSTM) network to aggregate information temporally. Please see our paper for more details.
3. Generate using Recurrent Neural Nets
The action plot representation described in part 1 allows us to compactly encode complex spatio-temporal interactions, and the recognition system in part 2 allows us to create action plots from videos. The goal now is to use extracted action plots from video collections to learn to generate novel interactions. To make the problem tractable, we decouple the time-varying and the time-invariant parameters in the action tuple \(T=L \bigcup p\) where \(L=(a,d,o,s)\). More specifically, we use a many-to-many RNN to model \(L\) and a time-independent Gaussian mixture model for \(p\).
Time-Dependent Action Plot RNN: Taking inspiration from similar sequential problems in natural language processing, we use a state-preserving recurrent neural network (RNN) to model the time-dependent parameters of interaction. At each timestep, the network takes the time-dependent variables \(L_t\) as input and predicts \(L_{t+1}\) for next timestep. Specifically, we use a Gated Recurrent Unit (GRU) which has a latent state that captures the information about the history of past interactions. We train the RNN using action plots extracted from a video collection with a combination of the cross entropy and \(L^2\) losses.
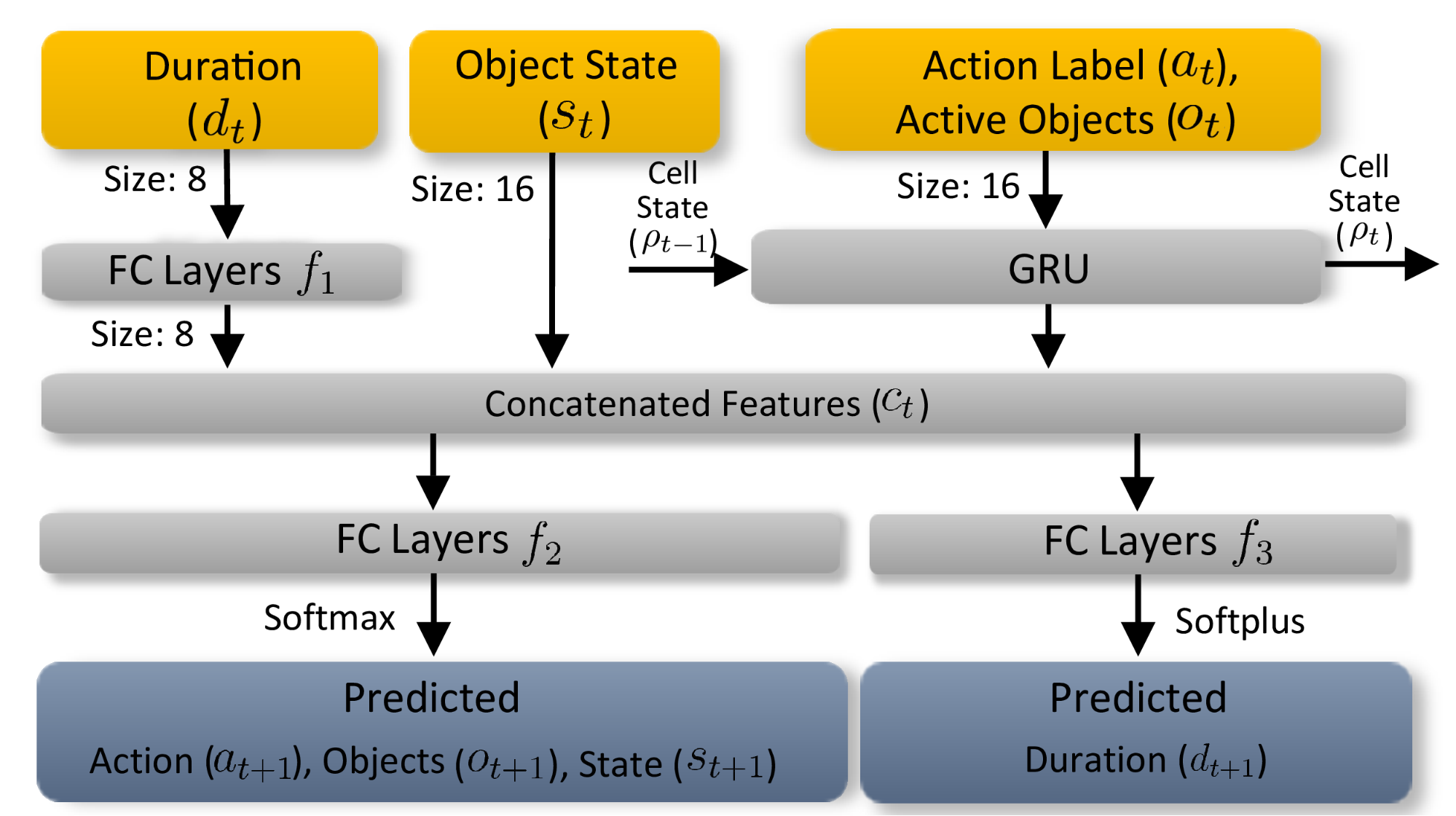
The Action Plot RNN learns to predict the next state consisting of action labels, active objects, object state, and duration. The inputs at each timestep are first embedded into vectors with the sizes specified. FC indicates fully connected networks (FC) networks composed of three consecutive FC, ReLU, FC layers.
Time-Independent Object Position Model: Many interactions involve object motions that need to be modeled to generate new plausible motions. There are strong physical and co-occurrence priors in object distribution. It is common to find open bottles around cups, but uncommon around laptops. Since these are not strongly time-dependent, we model them with a Gaussian mixture model (GMM) learned from video collections.

Time-independent object position model allows us capture physical and co-occurrence priors. The above animation shows a heat map of possible object locations learned from video collections in a time-independent manner.
Results & Applications
Animation Synthesis: Because our approach learns the causal dependencies of individual actions, it can be used to generate novel plausible action plots that were never observed during training. These action plots can then be rendered into realistic animations as shown below. This can enable novel applications in virtual/augmented reality settings, for instance, to teach new skills to people (e.g., make coffee).

Our approach allows animation synthesis. We can generate new interactions unseen in training data (bottom left). Please view a longer example on YouTube (link).
Simulation and Motion Planning for Robots: We can also enable applications in smart and reactive environments to improve the lives of the elderly and people with disabilities. We developed a robotic cup with a differential drive. The actions of the cup are driven by a real-time version of our recognition, representation, and generation pipeline. Interactions are captured in real-time and encoded to action plots which are then used to predict plausible future states. These predictions are used by the robot to react appropriately.

“Summon Cup” is an example where our method predicts a possible grasp of the cup by the hand. The smart cup moves in the direction of the hand to prevent users from needing to overreach. However, if our method detects that the hand is previously holding a book, the smart cup does not move since the physical constraint of holding only one object at a time is implicitly learned by our method.

“Summon Cup to Pour” shows examples where the hand, smart cup, and a bottle interact in more complex ways. When a filled bottle is moved, the smart cup automatically positions itself for easier pouring. However, when we detect that the bottle is empty, the smart cup does not react. This level of semantic planning is only possible with an understanding of complex human–object interactions.
Discussion
This work is a first step towards recognizing, representing, and generating plausible dynamic multi-step human–object interactions. We presented a method to automatically learn interactions from video collections by recognizing interactions from videos, representing them compactly using action plots, and generating novel and plausible interactions. While we take a first step forward, there are important limitations that need to be overcome, particularly with long time horizon activities which our Action Plot RNN cannot yet capture. We are also currently limited to tabletop interaction tasks. In the future, we plan to consider longer-term interactions and improving the physical plausibility of the interactions we generate.
We believe that methods that take a sequential view of interactions provide a strong foundation for learning to generate human–object interactions. Our method provides one possible solution, but extensive research is needed before we can create more immersive and dynamic virtual realities, or build robots that can make dinner and wash dishes.
This blog post is based on the following paper that will appear at Eurographics 2019. For more details on this work, datasets, and code, please visit the project webpage.
Learning a Generative Model for Multi-Step Human-Object Interactions from Videos. He Wang*, Soeren Pirk*, Ersin Yumer, Vladimir Kim, Ozan Sener, Srinath Sridhar, Leonidas J. Guibas. Eurographics 2019 [Honorable Mention]. Project Webpage, PDF
* joint first authors
Thanks to Michelle Lee, Andrey Kurenkov, Davis Rempe, Supriya Krishnan, and Vladimir Kim for feedback on this post. This research was supported by a grant from Toyota-Stanford Center for AI Research, NSF grant CCF-1514305, a Vannevar Bush Faculty Fellowship, and a Google Focused Research Award.