![]()
The International Conference on Learning Representations (ICLR) 2022 is being hosted virtually from April 25th - April 29th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Autonomous Reinforcement Learning: Formalism and Benchmarking
 Authors: Archit Sharma*, Kelvin Xu*, Nikhil Sardana, Abhishek Gupta, Karol Hausman, Sergey Levine, Chelsea Finn
Authors: Archit Sharma*, Kelvin Xu*, Nikhil Sardana, Abhishek Gupta, Karol Hausman, Sergey Levine, Chelsea Finn
Contact: architsh@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, continual learning, reset-free reinforcement learning
MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts
 Authors: Weixin Liang, James Zou
Authors: Weixin Liang, James Zou
Contact: wxliang@stanford.edu
Links: Paper | Video | Website
Keywords: benchmark dataset, distribution shift, out-of-domain generalization
An Explanation of In-context Learning as Implicit Bayesian Inference
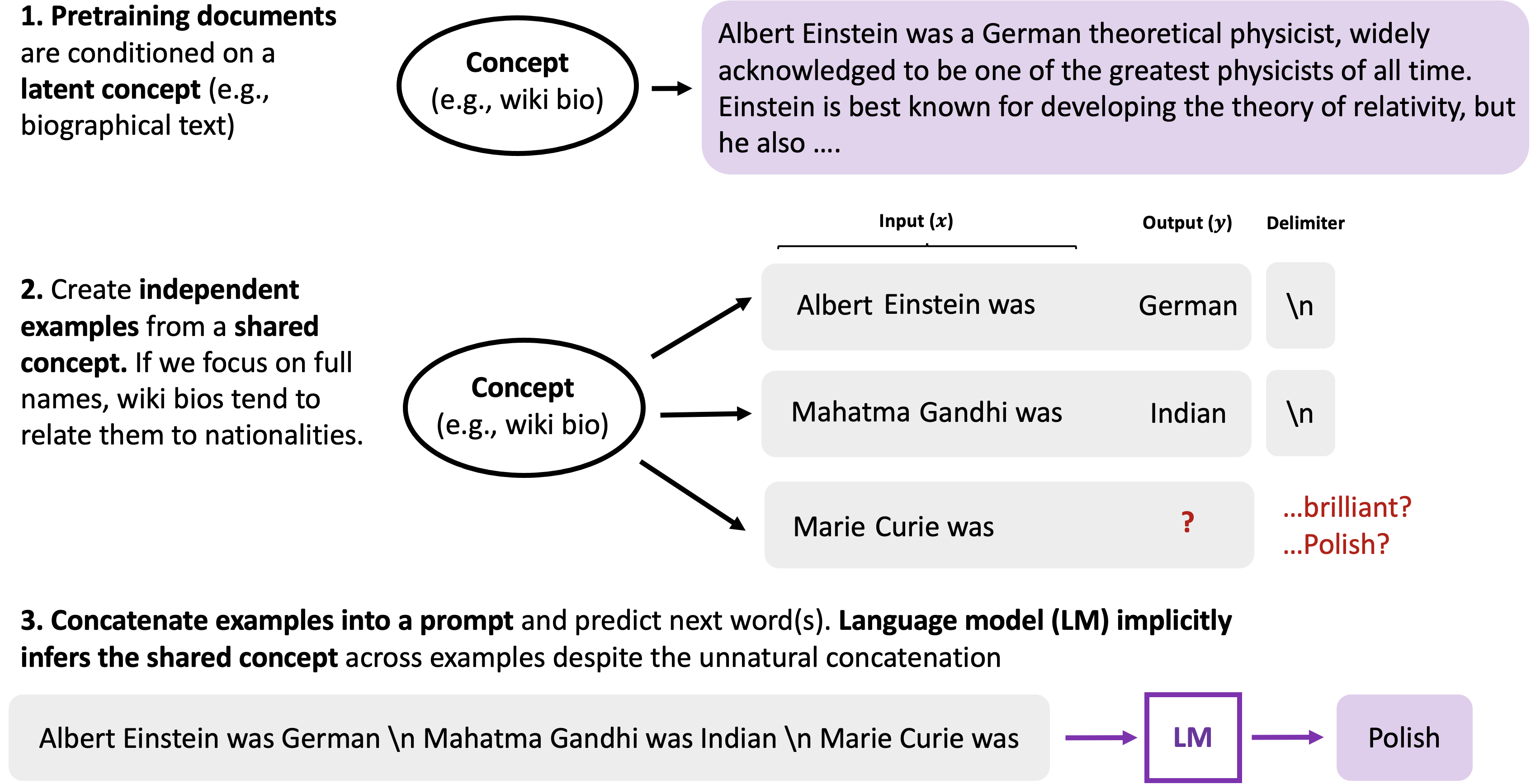 Authors: Sang Michael Xie, Aditi Raghunathan, Percy Liang, Tengyu Ma
Authors: Sang Michael Xie, Aditi Raghunathan, Percy Liang, Tengyu Ma
Contact: xie@cs.stanford.edu
Links: Paper | Video
Keywords: gpt-3, in-context learning, pretraining, few-shot learning
GreaseLM: Graph REASoning Enhanced Language Models for Question Answering
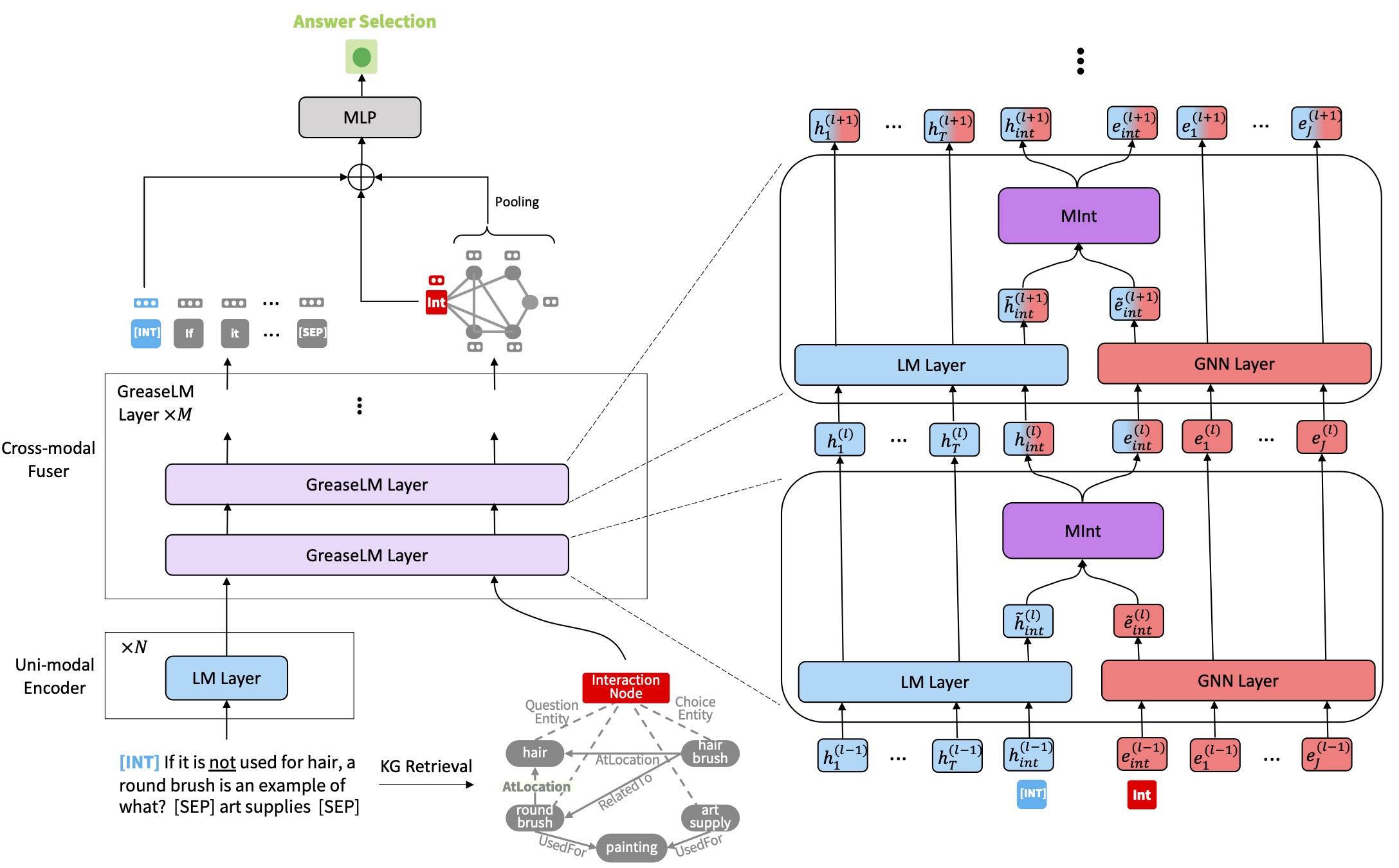 Authors: Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D. Manning, Jure Leskovec
Authors: Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D. Manning, Jure Leskovec
Contact: xikunz2@cs.stanford.edu
Award nominations: Spotlight
Links: Paper | Website
Keywords: knowledge graph, question answering, language model, commonsense reasoning, graph neural networks, biomedical qa
Fast Model Editing at Scale
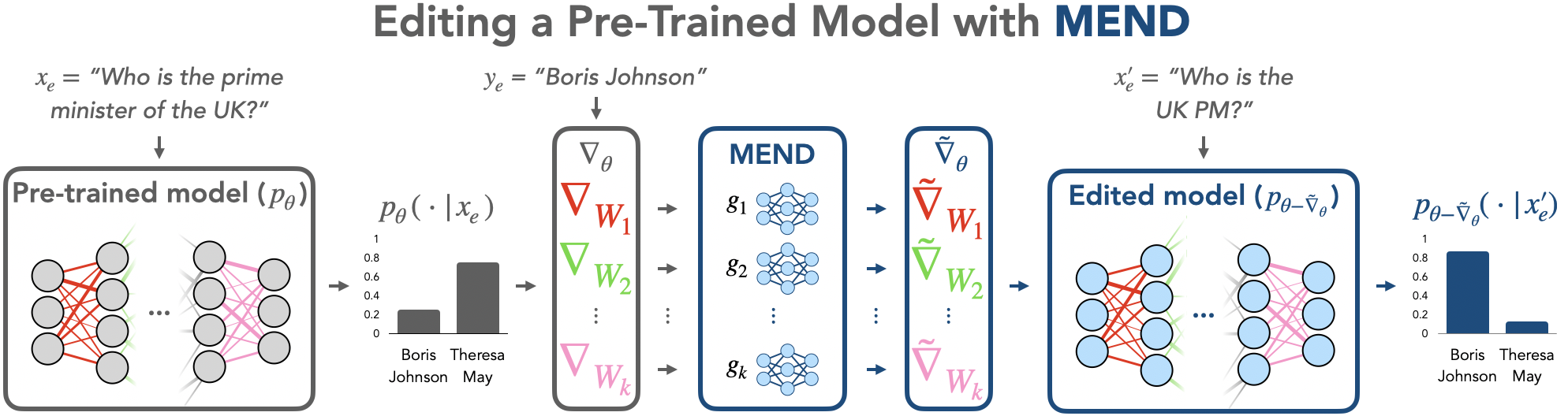 Authors: Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, Christopher D. Manning
Authors: Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, Christopher D. Manning
Contact: eric.mitchell@cs.stanford.edu
Links: Paper | Website
Keywords: model editing; meta-learning; language models; continual learning; temporal generalization
Vision-Based Manipulators Need to Also See from Their Hands
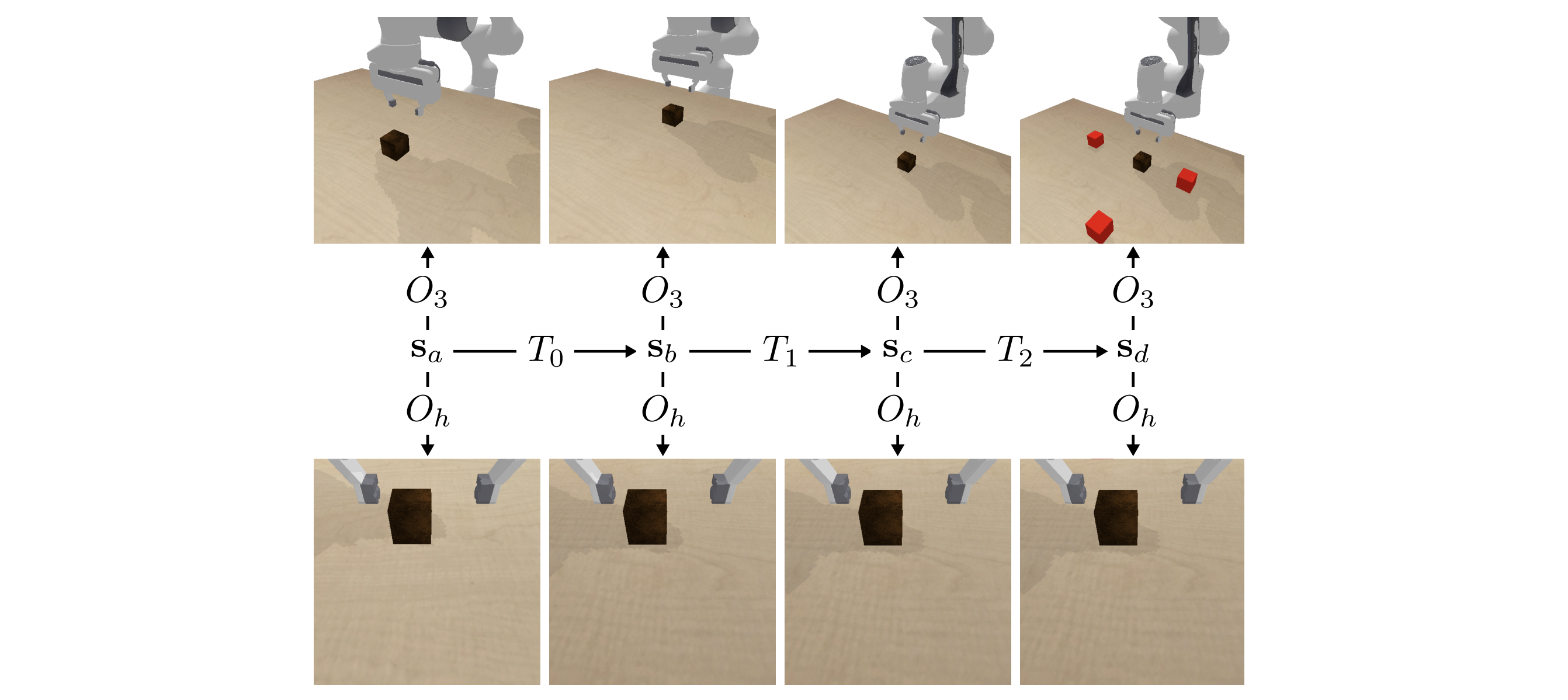 Authors: Kyle Hsu, Moo Jin Kim, Rafael Rafailov, Jiajun Wu, Chelsea Finn
Authors: Kyle Hsu, Moo Jin Kim, Rafael Rafailov, Jiajun Wu, Chelsea Finn
Contact: kylehsu@cs.stanford.edu
Award nominations: Oral Presentation
Links: Paper | Website
Keywords: reinforcement learning, observation space, out-of-distribution generalization, visuomotor control, robotics, manipulation
IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes
 Authors: Qi Li*, Kaichun Mo*, Yanchao Yang, Hang Zhao, Leonidas J. Guibas
Authors: Qi Li*, Kaichun Mo*, Yanchao Yang, Hang Zhao, Leonidas J. Guibas
Contact: kaichun@cs.stanford.edu
Links: Paper
Keywords: embodied ai, 3d scene graph, interactive perception
VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects
 Authors: Ruihai Wu*, Yan Zhao*, Kaichun Mo*, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas J. Guibas, Hao Dong
Authors: Ruihai Wu*, Yan Zhao*, Kaichun Mo*, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas J. Guibas, Hao Dong
Contact: kaichun@cs.stanford.edu
Links: Paper | Video | Website
Keywords: visual affordance learning, robotic manipulation, 3d perception, interactive perception
Language modeling via stochastic processes
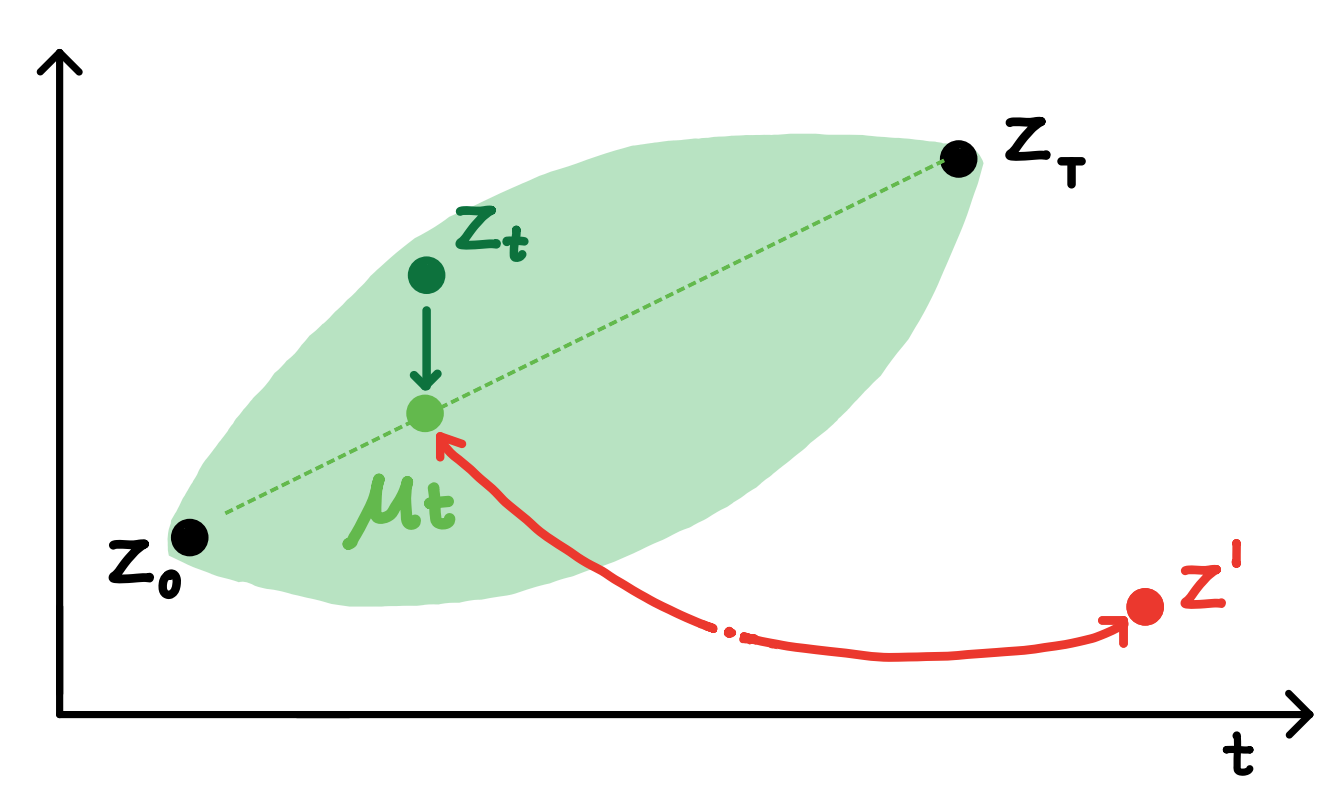 Authors: Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto
Authors: Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto
Contact: rewang@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Video | Website
Keywords: contrastive learning, language modeling, stochastic processes
MetaMorph: Learning Universal Controllers with Transformers
 Authors: Agrim Gupta, Linxi Fan, Surya Ganguli, Li Fei-Fei
Authors: Agrim Gupta, Linxi Fan, Surya Ganguli, Li Fei-Fei
Contact: agrim@stanford.edu
Links: Paper | Video | Website
Keywords: rl, modular robots, transformers
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
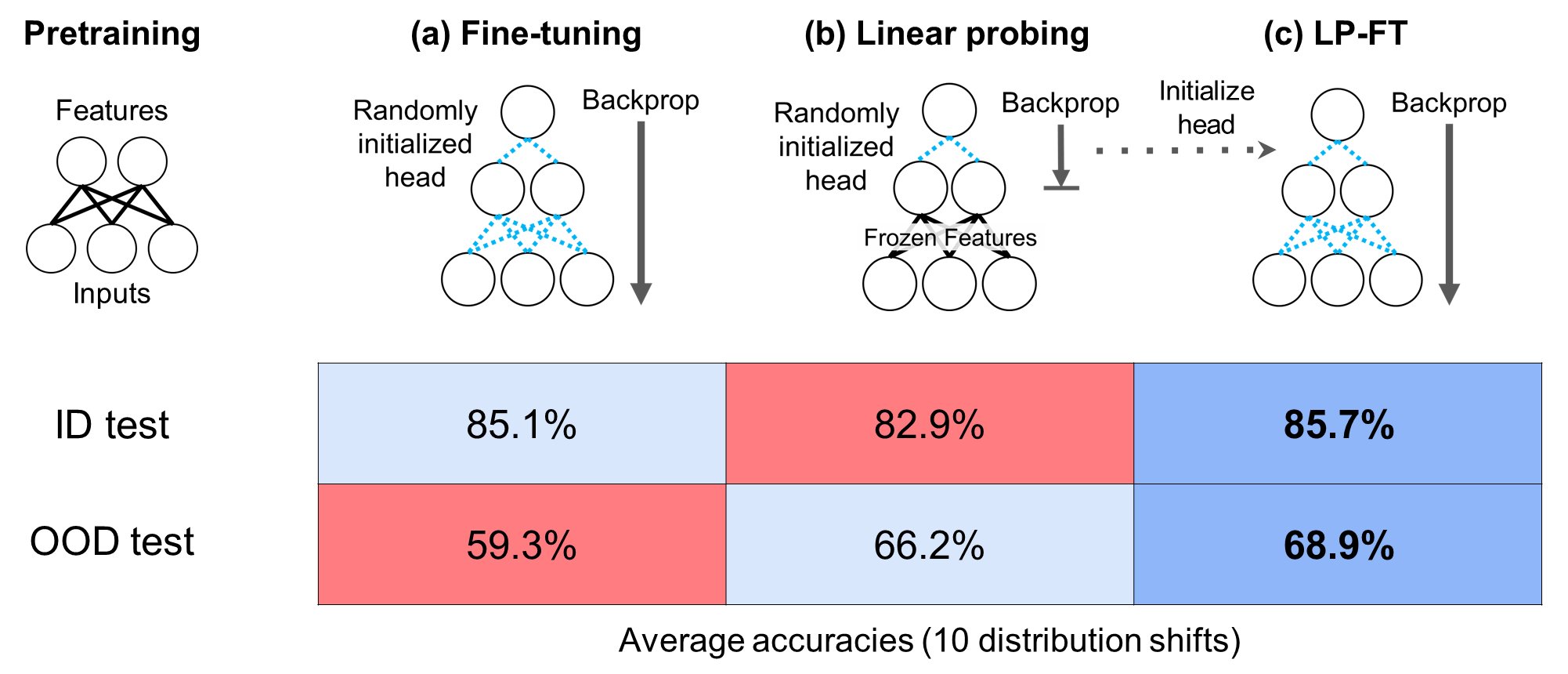 Authors: Ananya Kumar
Authors: Ananya Kumar
Contact: ananya@cs.stanford.edu
Award nominations: Oral Presentation
Links: Paper
Keywords: fine-tuning theory, transfer learning theory, fine-tuning, distribution shift, implicit regularization
An Experimental Design Perspective on Model-Based Reinforcement Learning
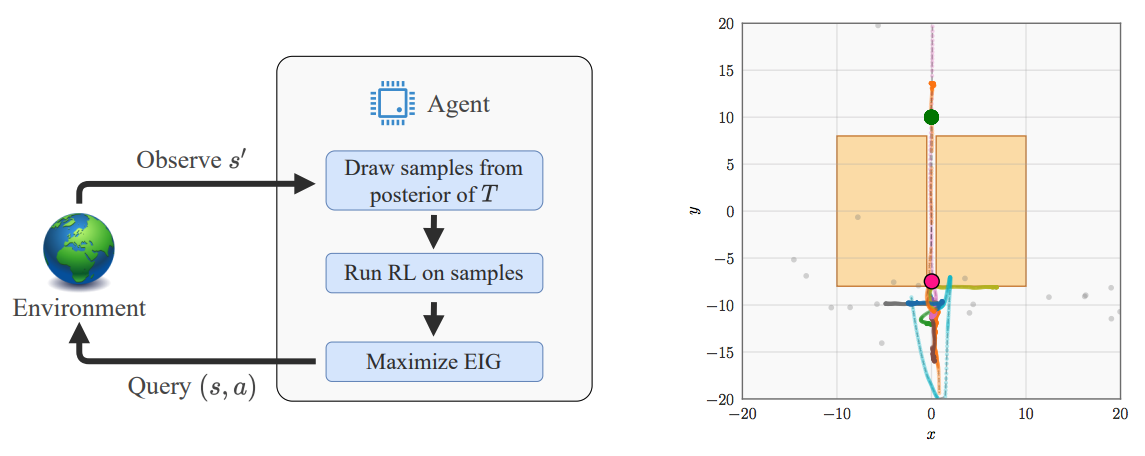 Authors: Viraj Mehta, Biswajit Paria, Jeff Schneider, Stefano Ermon, Willie Neiswanger
Authors: Viraj Mehta, Biswajit Paria, Jeff Schneider, Stefano Ermon, Willie Neiswanger
Contact: virajm@cs.cmu.edu, neiswanger@cs.stanford.edu
Links: Paper
Keywords: reinforcement learning, model-based reinforcement learning, mbrl, bayesian optimal experimental design, boed, bax
Domino: Discovering Systematic Errors with Cross-Modal Embeddings
 Authors: Sabri Eyuboglu*, Maya Varma*, Khaled Saab*, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, Christopher Ré
Authors: Sabri Eyuboglu*, Maya Varma*, Khaled Saab*, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, Christopher Ré
Contact: {eyuboglu,mvarma2,ksaab}@stanford.edu
Award nominations: Oral Presentation
Links: Paper | Blog Post | Website
Keywords: robustness, subgroup analysis, error analysis, multimodal, slice discovery
Pixelated Butterfly: Simple and Efficient Sparse training for Neural Network Models
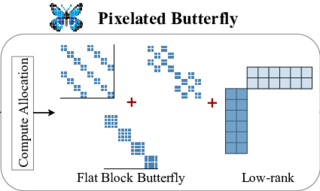 Authors: Tri Dao, Beidi Chen, Kaizhao Liang, Jiaming Yang, Zhao Song, Atri Rudra, Christopher Ré
Authors: Tri Dao, Beidi Chen, Kaizhao Liang, Jiaming Yang, Zhao Song, Atri Rudra, Christopher Ré
Contact: trid@stanford.edu
Award nominations: Spotlight
Links: Paper | Blog Post
Keywords: sparse training, butterfly matrices
Hindsight: Posterior-guided training of retrievers for improved open-ended generation
 Authors: Ashwin Paranjape, Omar Khattab, Christopher Potts, Matei Zaharia, Christopher D Manning
Authors: Ashwin Paranjape, Omar Khattab, Christopher Potts, Matei Zaharia, Christopher D Manning
Contact: ashwinp@cs.stanford.edu
Links: Paper
Keywords: retrieval, generation, retrieval-augmented generation, open-ended generation, informative conversations, free-form qa, posterior distribution, elbo
Unsupervised Discovery of Object Radiance Fields
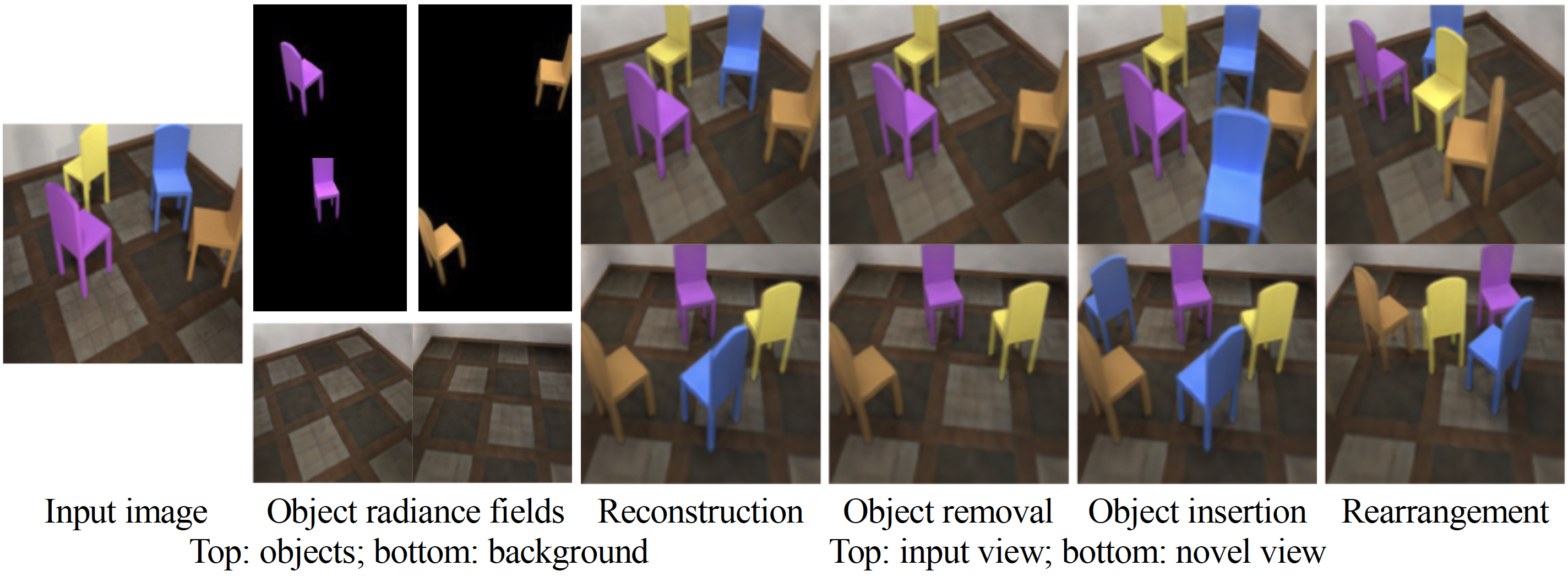 Authors: Hong-Xing Yu, Leonidas J. Guibas, Jiajun Wu
Authors: Hong-Xing Yu, Leonidas J. Guibas, Jiajun Wu
Contact: koven@cs.stanford.edu
Links: Paper | Video | Website
Keywords: object-centric representation, unsupervised, 3d object discovery
Efficiently Modeling Long Sequences with Structured State Spaces
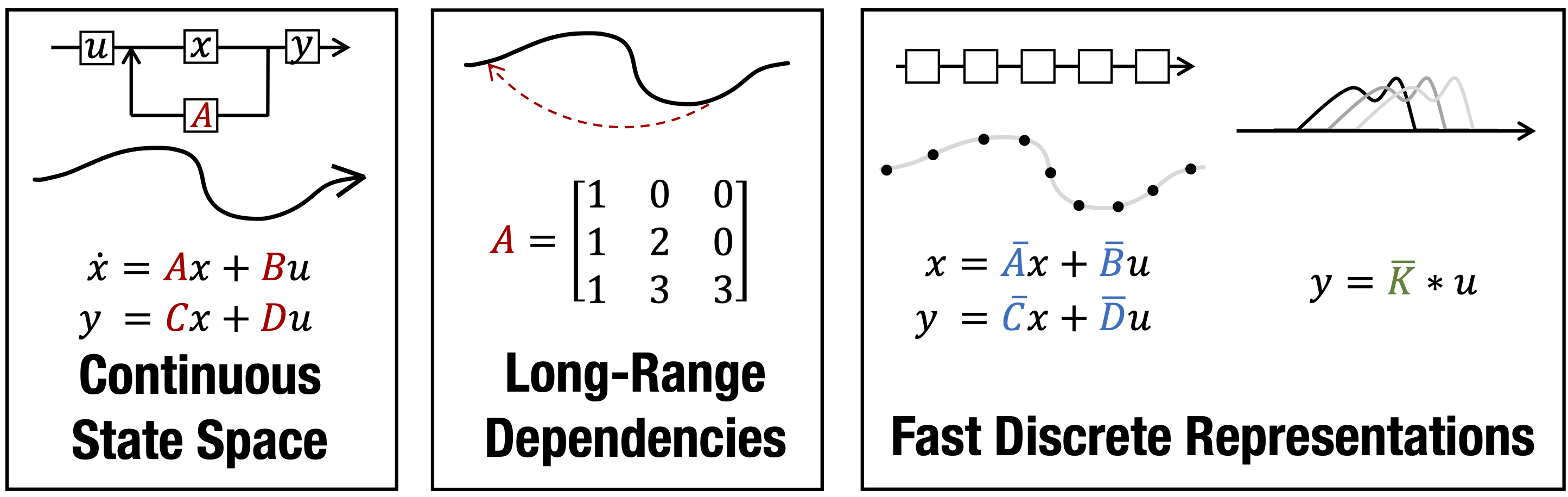 Authors: Albert Gu, Karan Goel, Christopher Ré
Authors: Albert Gu, Karan Goel, Christopher Ré
Contact: albertgu@stanford.edu
Award nominations: Outstanding Paper Honorable Mention
Links: Paper | Blog Post | Video
Keywords: hippo
How many degrees of freedom do we need to train deep networks: a loss landscape perspective
 Authors: Brett W. Larsen, Stanislav Fort, Nic Becker, Surya Ganguli
Authors: Brett W. Larsen, Stanislav Fort, Nic Becker, Surya Ganguli
Contact: bwlarsen@stanford.edu
Links: Paper
Keywords: loss landscape, high-dimensional geometry, random hyperplanes, optimization
How did the Model Change? Efficiently Assessing Machine Learning API Shifts
 Authors: Lingjiao Chen, Matei Zaharia, James Zou
Authors: Lingjiao Chen, Matei Zaharia, James Zou
Contact: lingjiao@stanford.edu
Links: Paper | Website
Keywords: mlaas, performance shifts, ml systems
We look forward to seeing you at ICLR 2022!