![]()
The International Conference on Learning Representations (ICLR) 2023 is being hosted in Kigali, Rwanda from May 1st - May 5th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
A Control-Centric Benchmark for Video Prediction
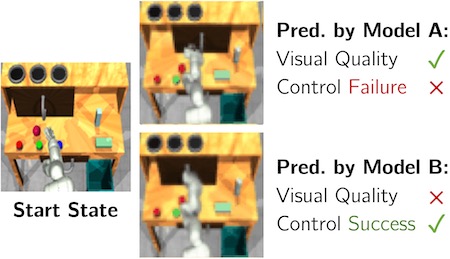
Contact: tians@stanford.edu
Links: Paper | Website
Keywords: benchmarking, video prediction, visual mpc, manipulation
Ask Me Anything: A simple strategy for prompting language models

Contact: avanikan@stanford.edu
Award nominations: Spotlight, top 25% of acceptances
Links: Paper | Website
Keywords: prompting, foundation models
Asymptotic Instance-Optimal Algorithms for Interactive Decision Making
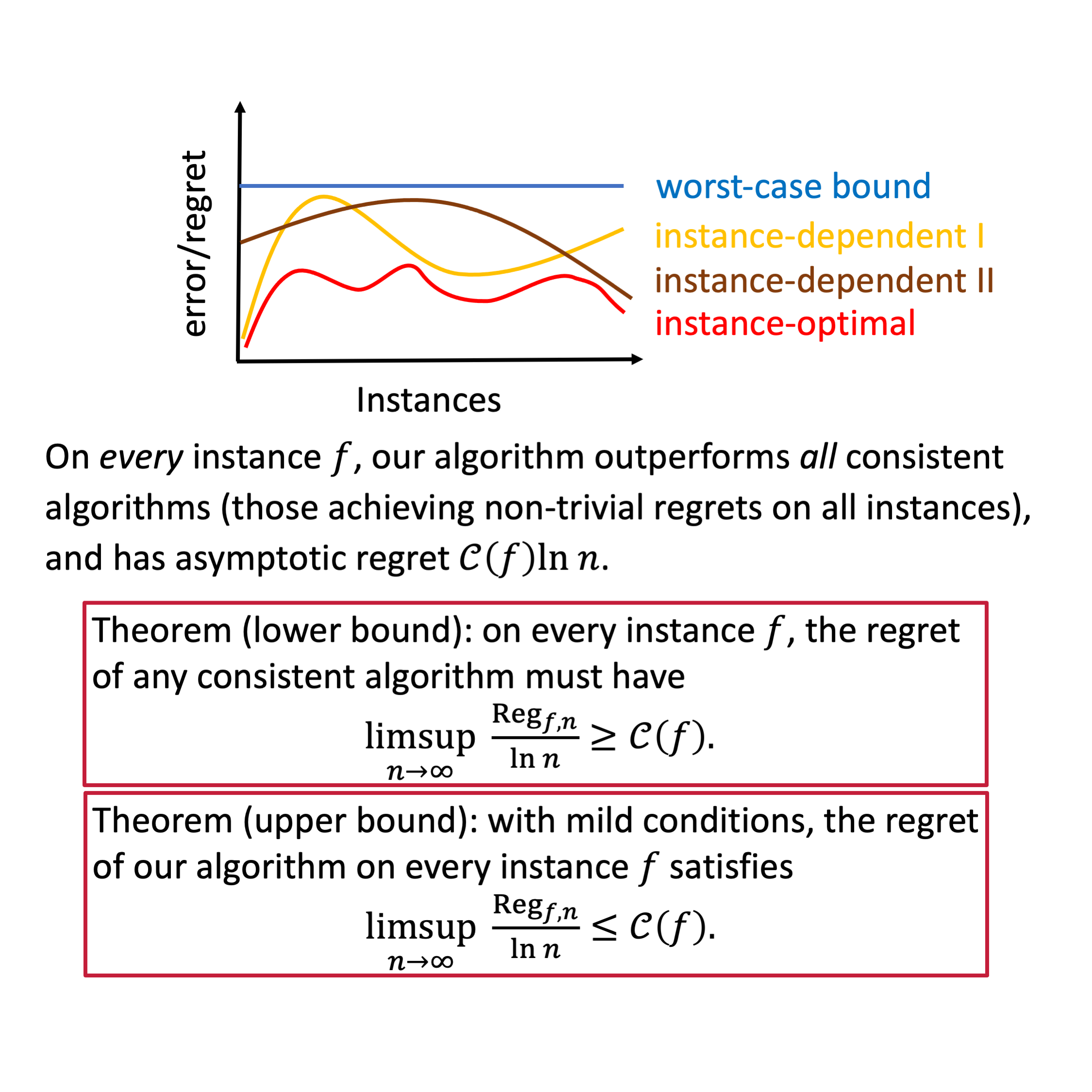
Contact: kefandong@stanford.edu
Links: Paper
Keywords: instance optimality, reinforcement learning theory
Beyond Confidence: Reliable Models Should Also Quantify Atypicality
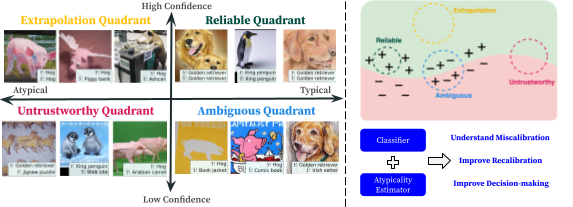
Contact: merty@stanford.edu
Award nominations: Oral Presentation
Links: Paper
Keywords: trustworthy machine learning, reliable machine learning, uncertainty, calibration
Characterizing Intrinsic compositionality in Transformers with Tree Projections
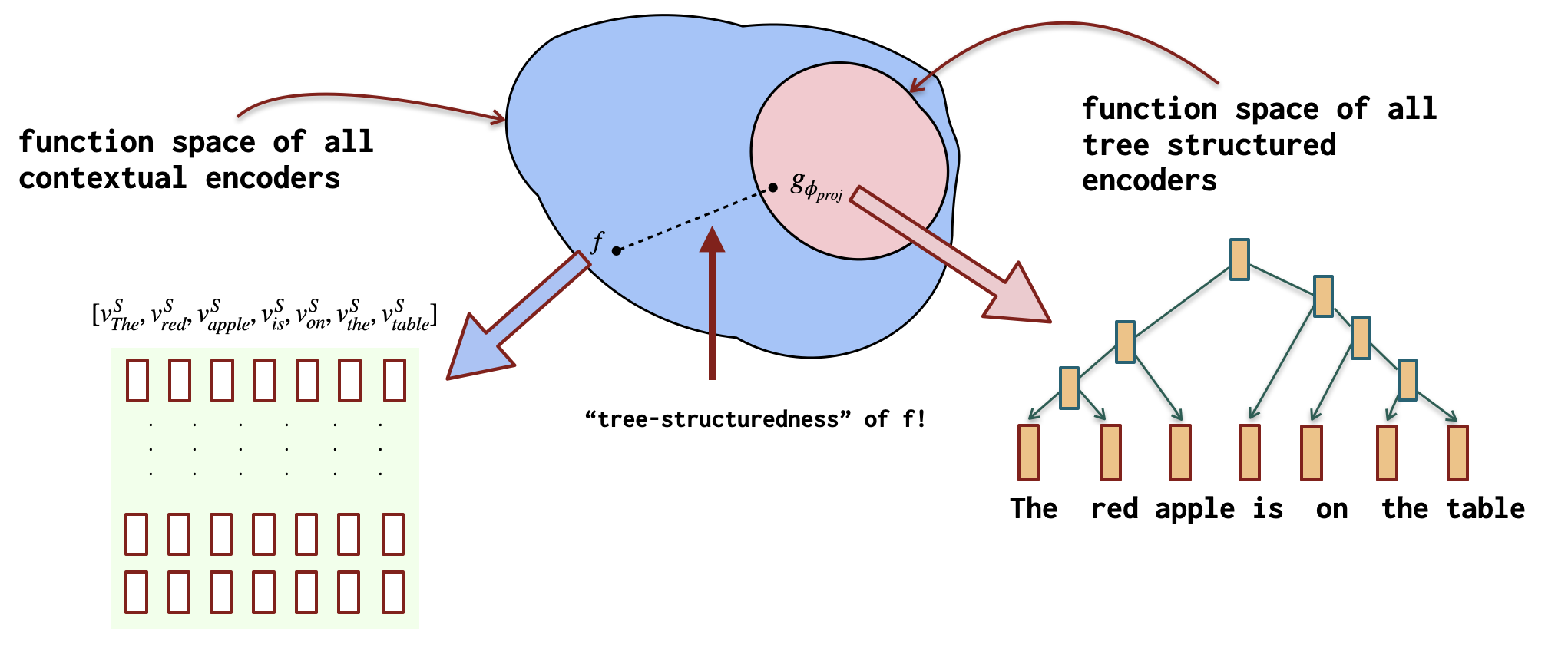
Contact: smurty@cs.stanford.edu
Links: Paper
Keywords: compositionality, emergent syntax, generalization
Diagnosing and Rectifying Vision Models using Language

Contact: yuhuiz@stanford.edu
Links: Paper | Video | Website
Keywords: model diagnosis, multi-modal contrastive learning, vision and language
Extreme Q-Learning: MaxEnt RL Without Entropy
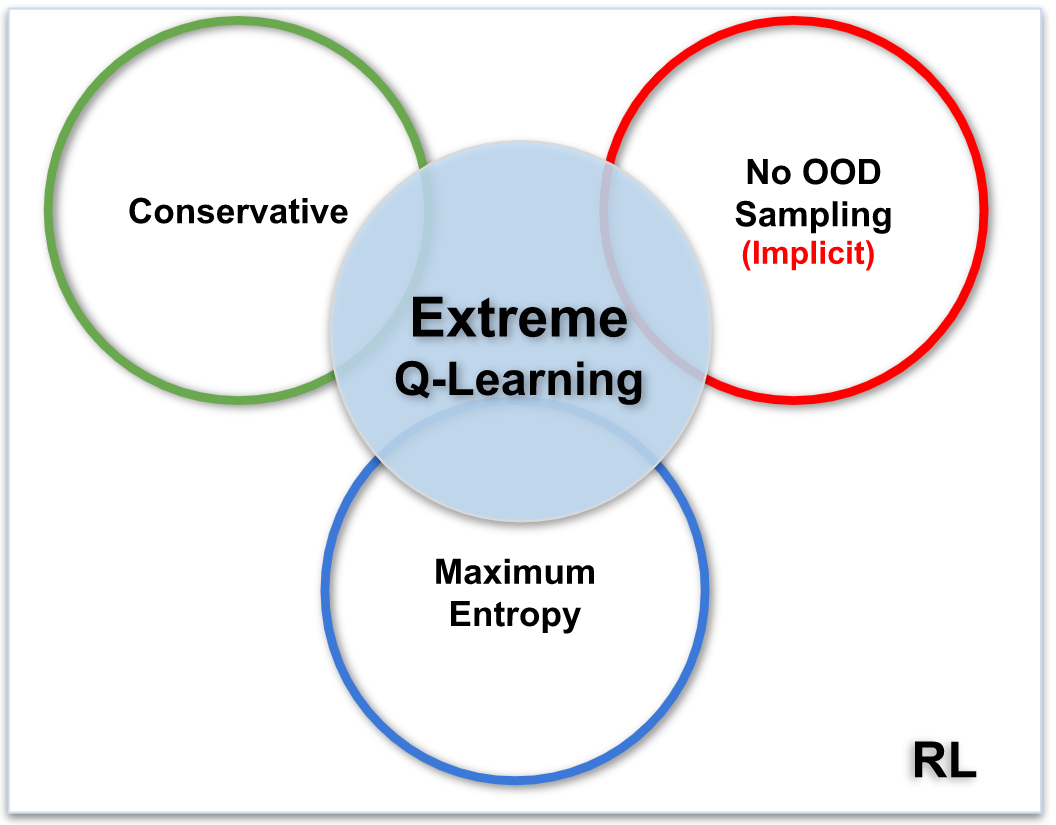
Contact: jhejna@cs.stanford.edu
Award nominations: notable top 5%
Links: Paper | Website
Keywords: reinforcement learning, offline reinforcement learning, statistical learning, extreme value analysis, maximum entropy rl, gumbel
First Steps Toward Understanding the Extrapolation of Nonlinear Models to Unseen Domains
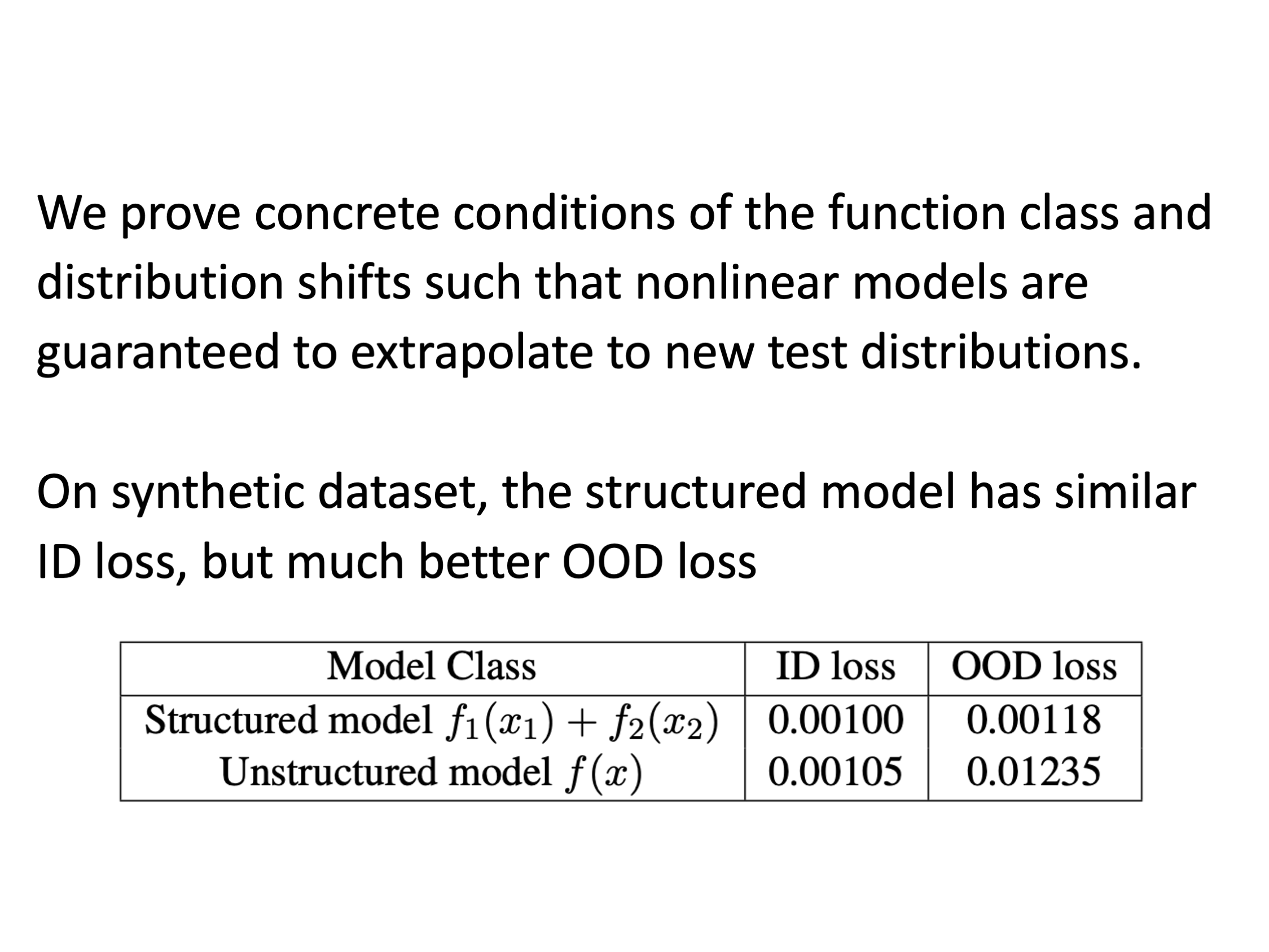
Contact: kefandong@stanford.edu
Links: Paper
Keywords: extrapolation of nonlinear models, theory, structured domain shift, gaussian kernel
FlexVDW: A machine learning approach to account for protein flexibility in ligand docking
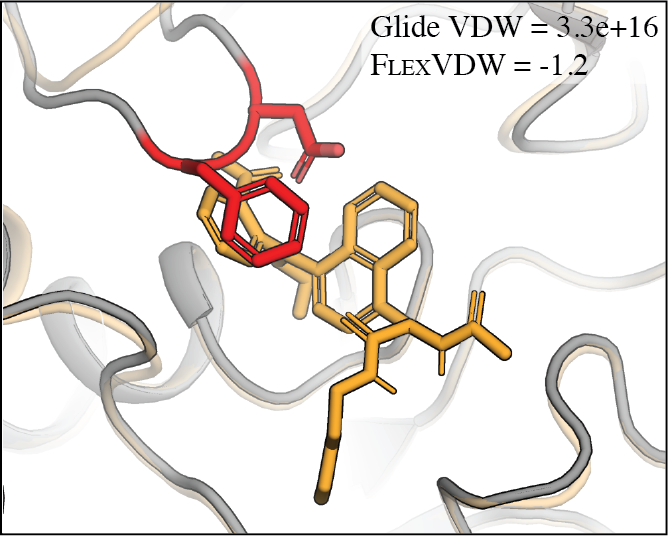
Contact: psuriana@stanford.edu
Links: Paper
Keywords: deep learning, structural biology, protein ligand docking, protein flexibility
Hungry Hungry Hippos: Towards Language Modeling with State Space Models
 Authors: Daniel Y. Fu*, Tri Dao*, Khaled K. Saab, Armin W. Thomas, Atri Rudra, Christopher Ré
Authors: Daniel Y. Fu*, Tri Dao*, Khaled K. Saab, Armin W. Thomas, Atri Rudra, Christopher Ré
Contact: danfu@cs.stanford.edu
Award nominations: Notable top-25% (spotlight)
Links: Paper | Blog Post | Website
Keywords: language modeling, state space models, convolution, fft, io-aware
Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning

Contact: rtaori@stanford.edu
Links: Paper
Keywords: clip, transfer learning, contrastive learning, multi-modal
Learning Controllable Adaptive Simulation for Multi-resolution Physics
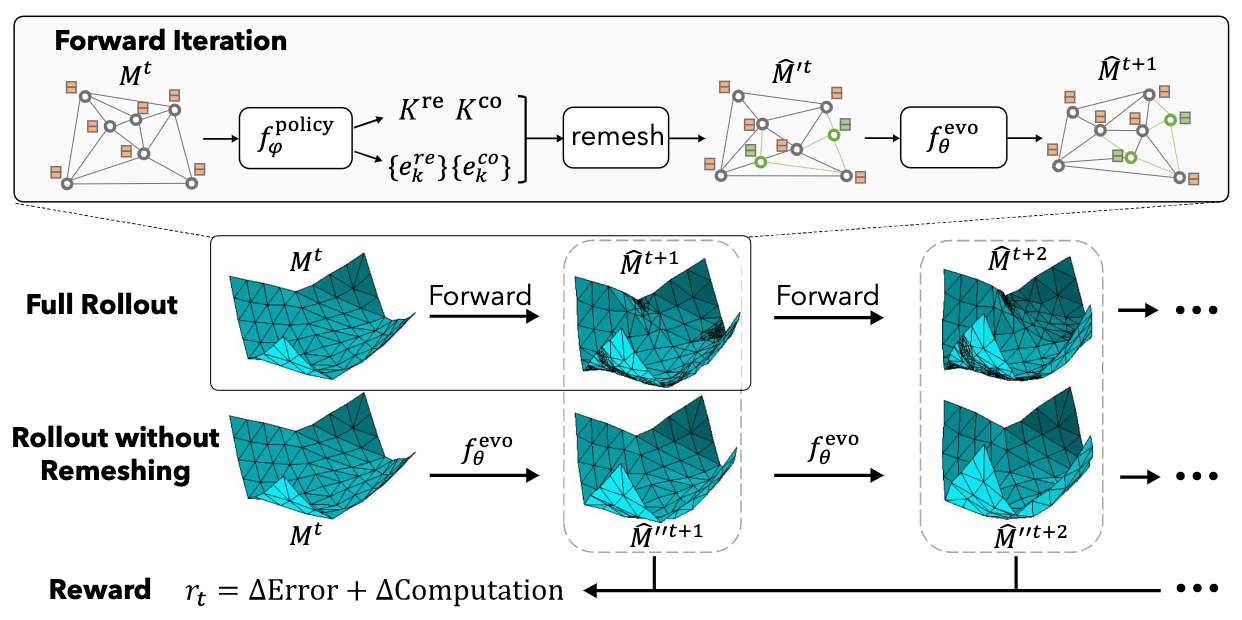
Contact: tailin@cs.stanford.edu
Award nominations: notable-top-25% (spotlight)
Links: Paper | Website
Keywords: learned simulation, adaptive, multi-scale, error vs. computation, controllable
Parameter-Efficient Fine-Tuning Design Spaces
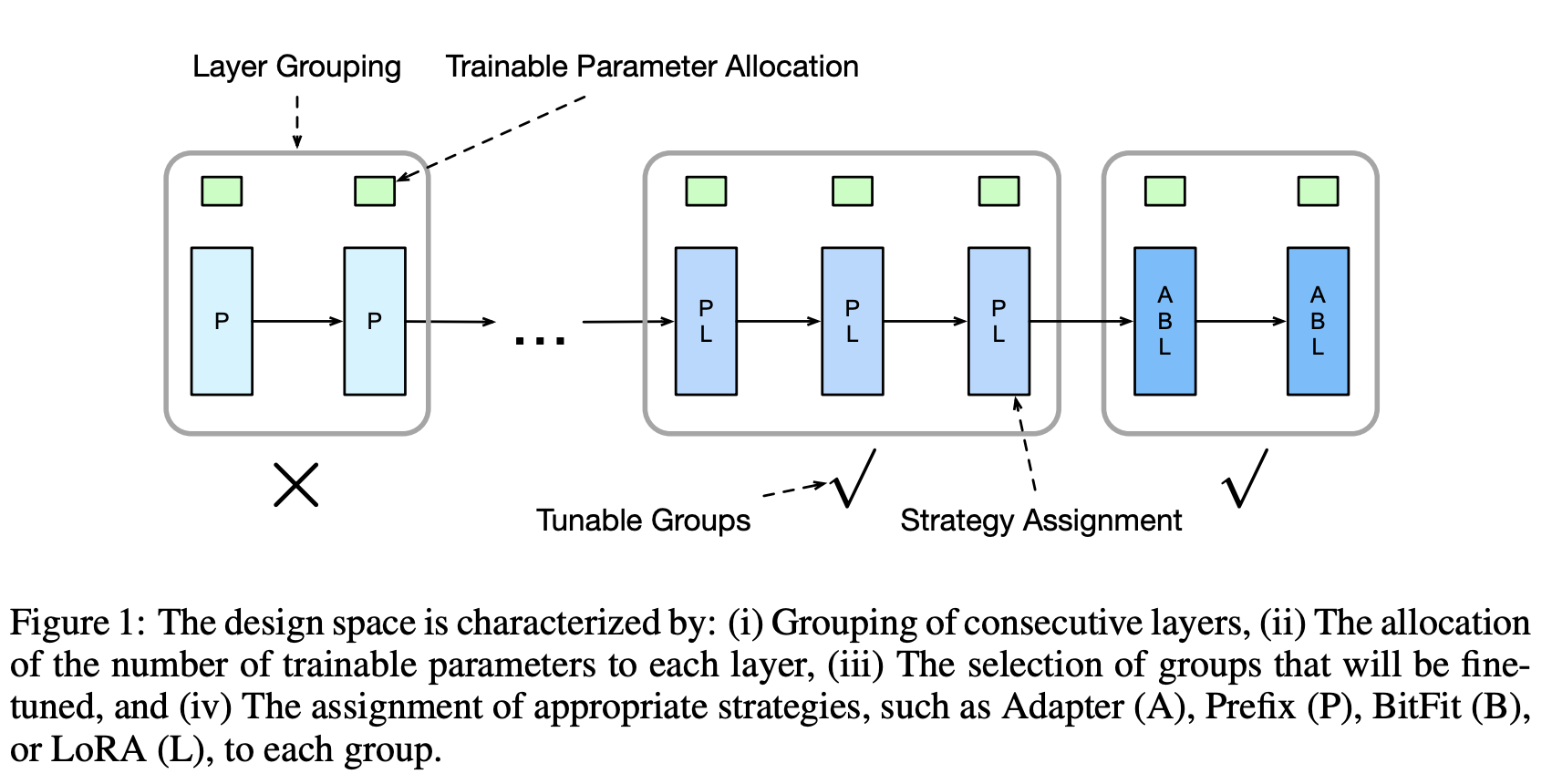
Contact: jchen896@gatech.edu
Links: Paper
Keywords: parameter-efficient fine-tuning, design spaces
Pitfalls of Gaussians as a noise distribution in NCE

Contact: cpabbara@stanford.edu
Links: Paper
Keywords: nce, noise contrastive estimation, generative models, statistical efficiency, theory
Post-hoc Concept Bottleneck Models
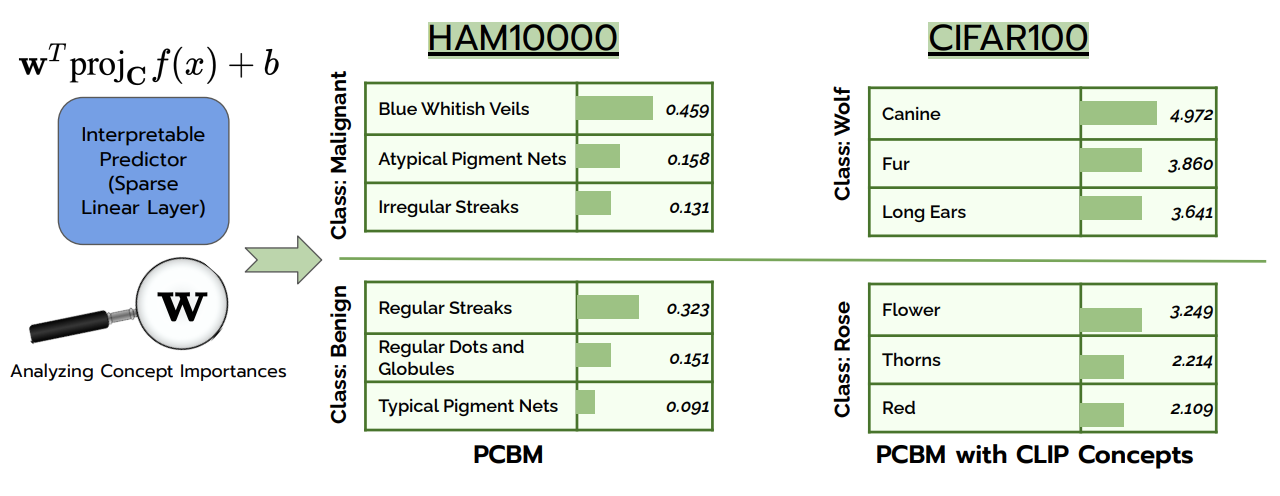
Contact: merty@stanford.edu
Award nominations: Spotlight (Top 25%)
Links: Paper
Keywords: concepts, interpretability, concept bottleneck models, model editing
Reward Design with Language Models
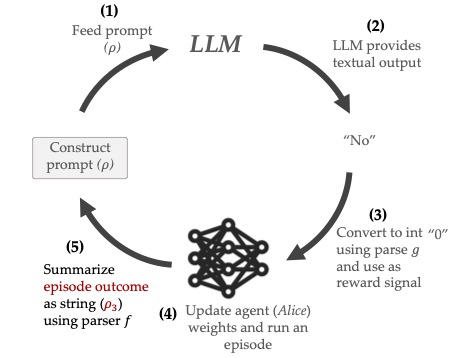
Contact: minae@cs.stanford.edu
Links: Paper | Video
Keywords: alignment, reinforcement learning, foundation models, reward design
Simplified State Space Layers for Sequence Modeling
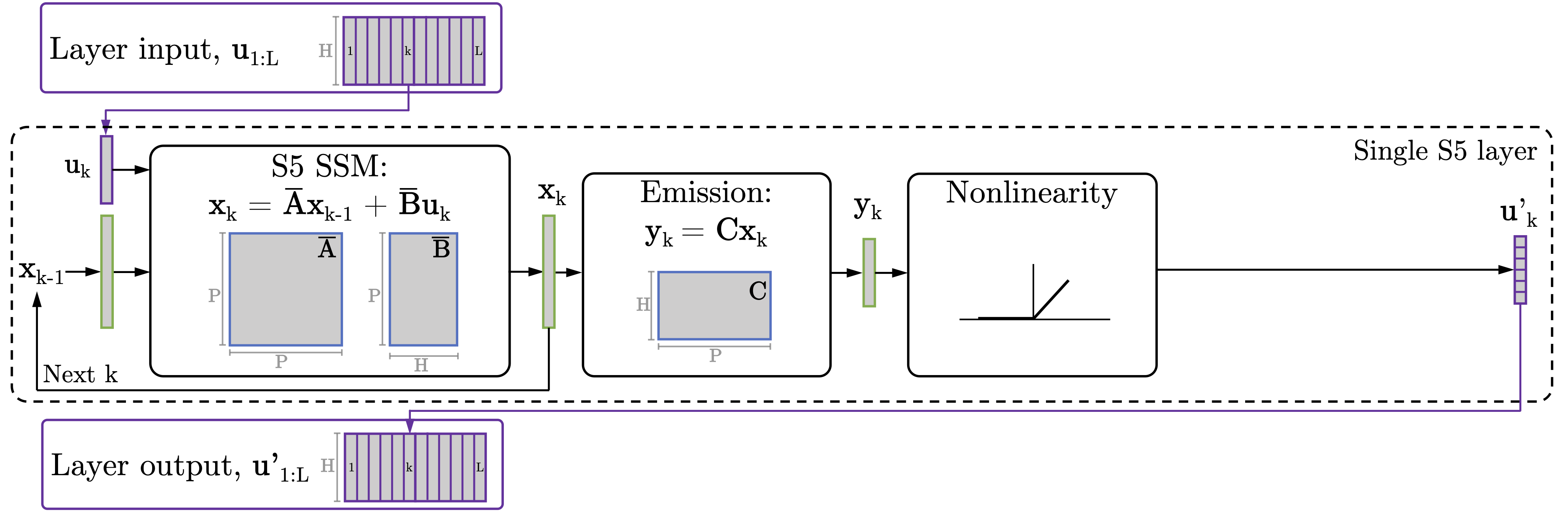
Contact: jsmith14@stanford.edu
Award nominations: Notable-top-5% (In-person Oral Presentation)
Links: Paper | Website
Keywords: deep learning, sequence model, state space model, s4
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
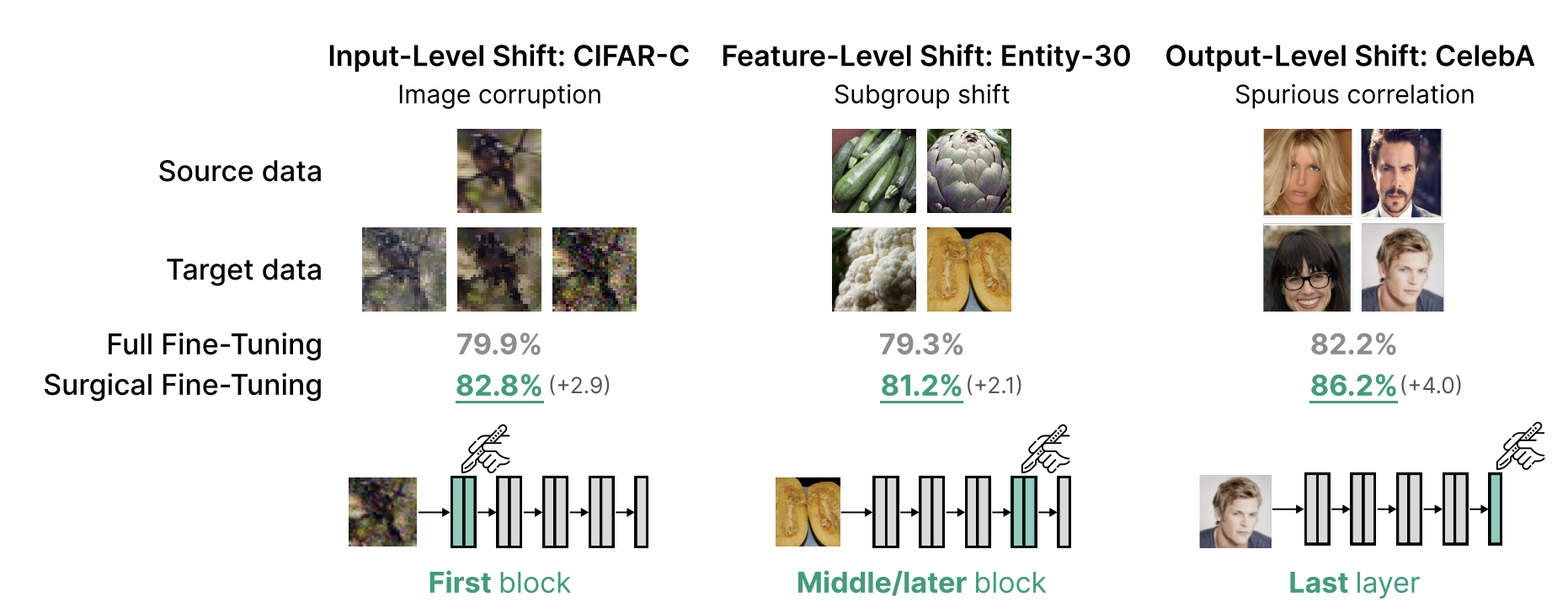
Contact: asc8@stanford.edu
Links: Paper
Keywords: transfer learning, fine-tuning, parameter freezing, distortion of pre-trained models
The Asymmetric Maximum Margin Bias of Quasi-Homogeneous Neural Networks
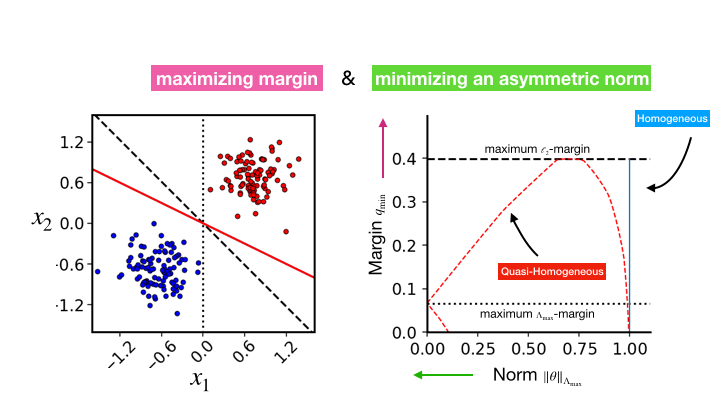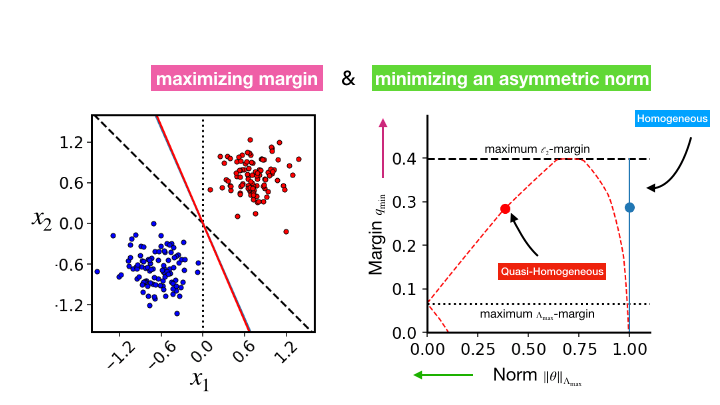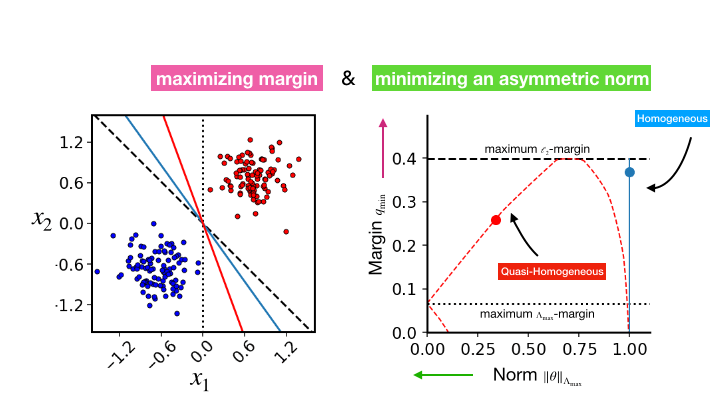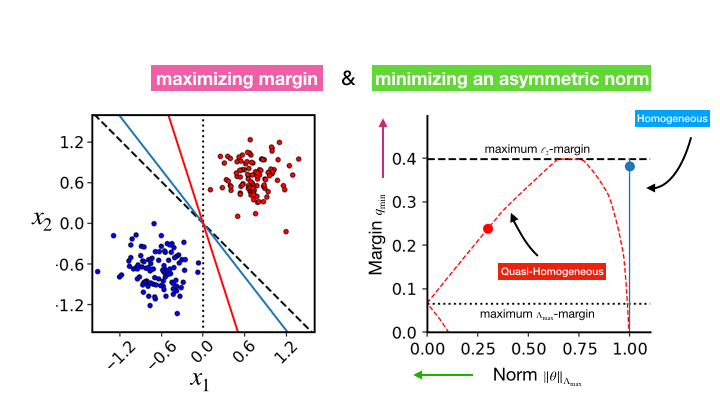
Contact: kunin@stanford.edu, atsushi3@stanford.edu
Award nominations: ICLR 2023 notable top 25%
Links: Paper
Keywords: margin, maximum-margin, implicit regularization, neural networks, neural collapse, gradient flow, implicit bias, robustness, homogeneous, symmetry, classification
When and why vision-language models behave like bags-of-words, and what to do about it?
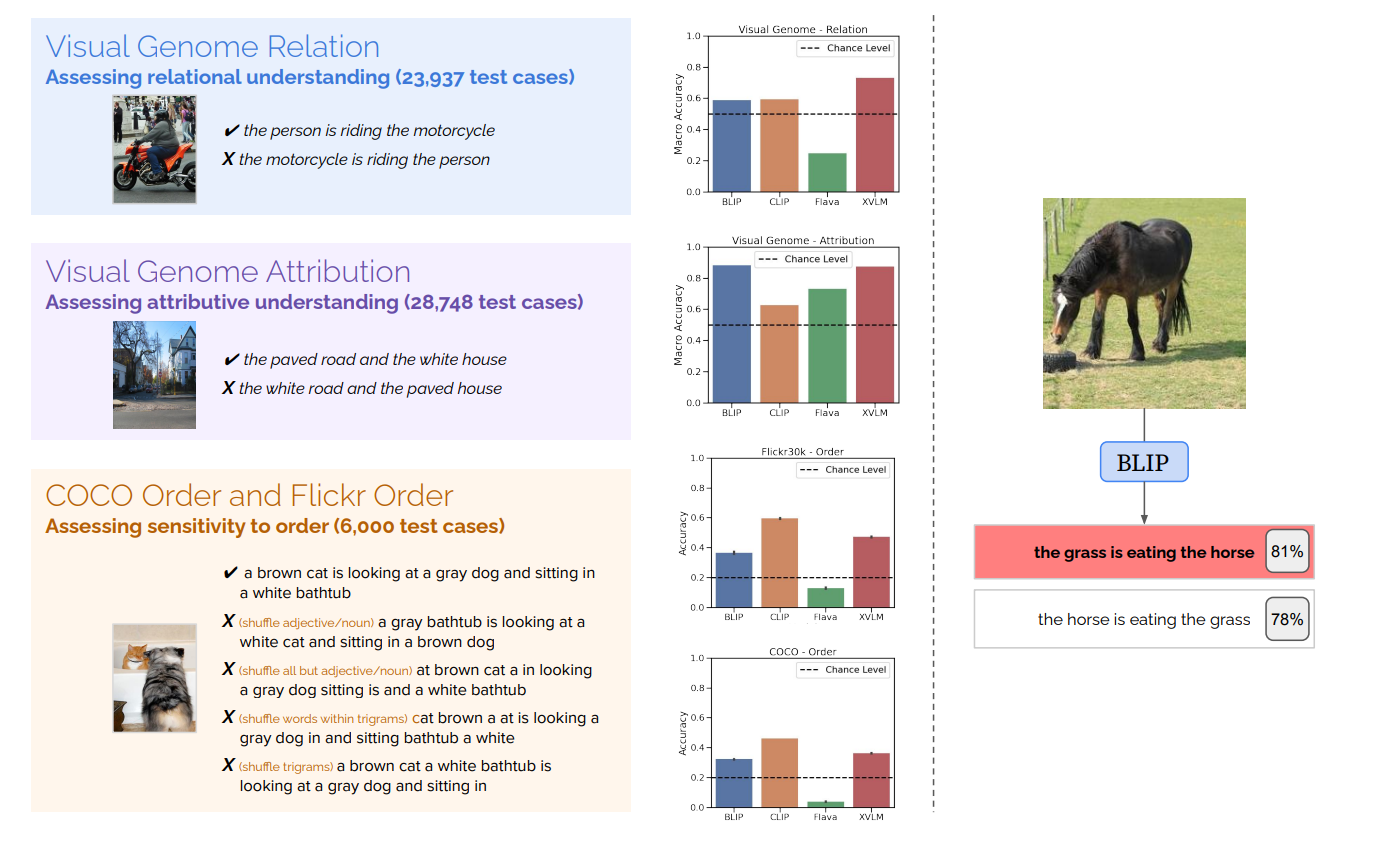
Contact: merty@stanford.edu
Award nominations: Oral (Top 5%)
Links: Paper | Blog Post
Keywords: vision-language models, clip, contrastive learning, retrieval, vision-language pretraining, multimodal representation learning
We look forward to seeing you at ICLR!