![]()
The International Conference on Machine Learning (ICML) 2020 is being hosted virtually from July 13th - July 18th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Active World Model Learning in Agent-rich Environments with Progress Curiosity
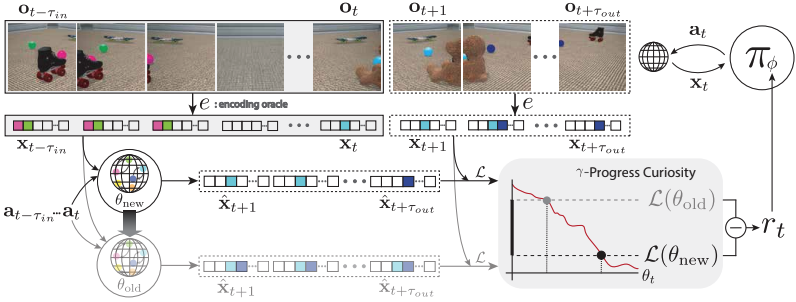
Contact: khkim@cs.stanford.edu
Links: Video
Keywords: curiosity, active learning, world models, animacy, attention
Graph Structure of Neural Networks
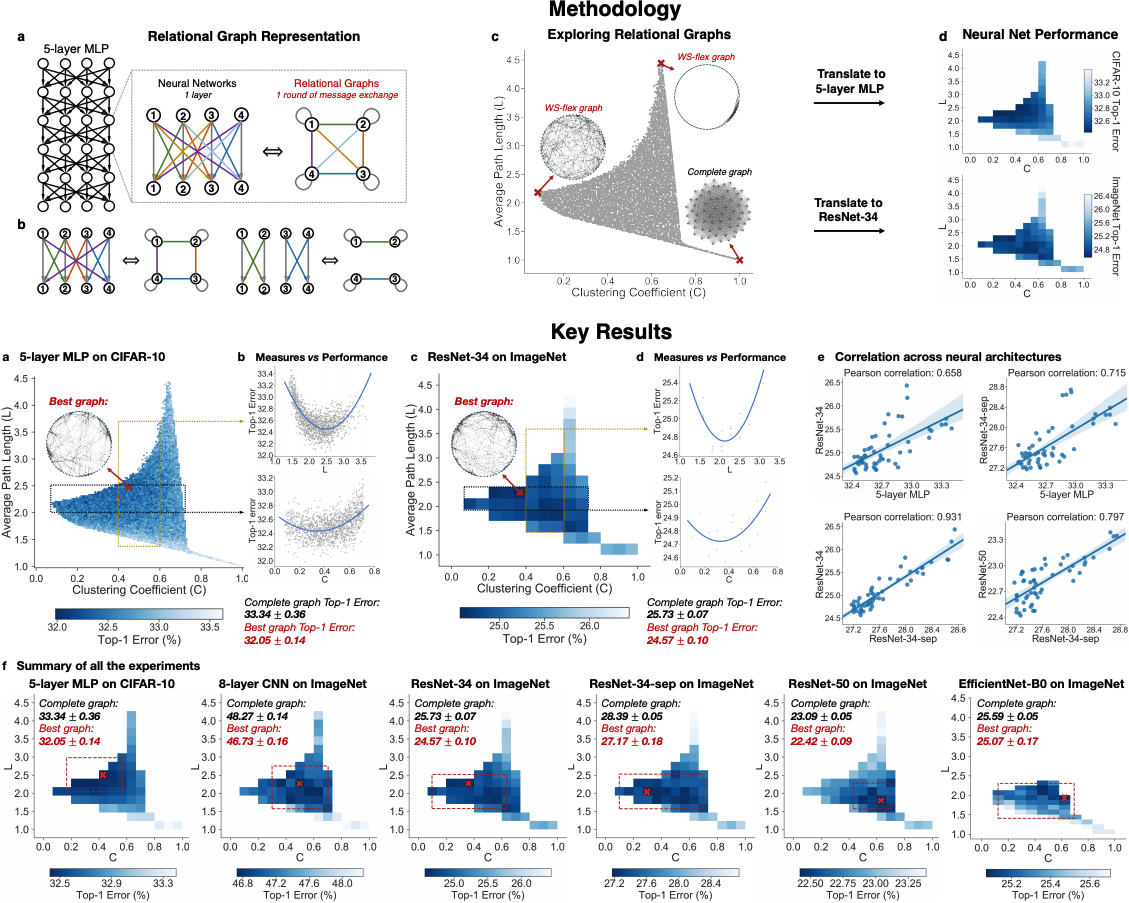
Contact: jiaxuan@stanford.edu
Links: Paper
Keywords: neural network design, network science, deep learning
A Distributional Framework For Data Valuation
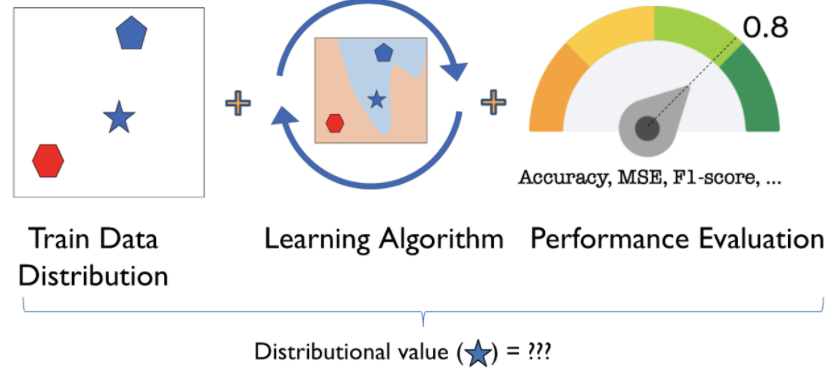
Contact: jamesz@stanford.edu
Links: Paper
Keywords: shapley value, data valuation, machine learning, data markets
A General Recurrent State Space Framework for Modeling Neural Dynamics During Decision-Making
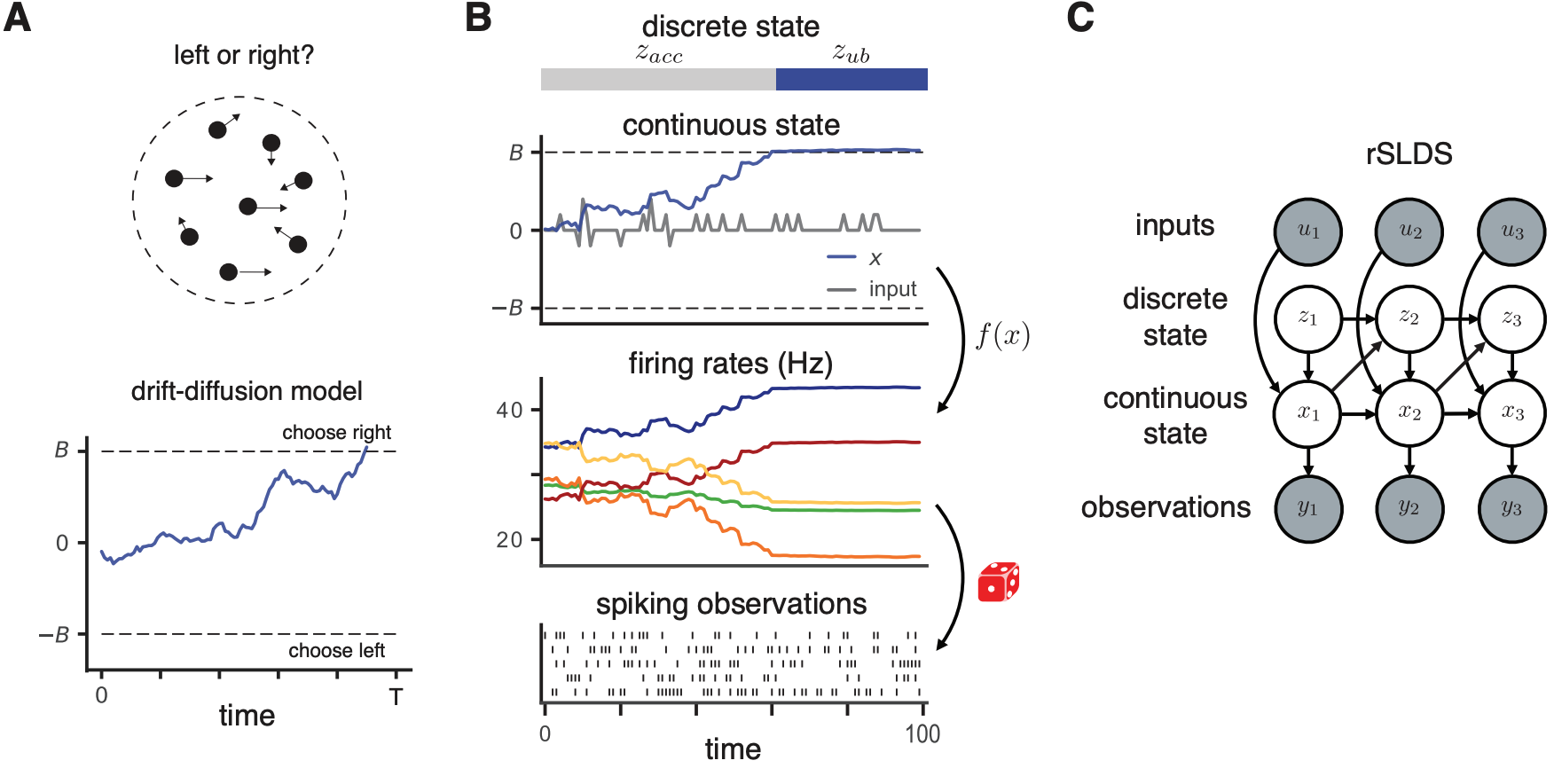
Contact: scott.linderman@stanford.edu
Links: Paper
Keywords: computational neuroscience, dynamical systems, variational inference
An Imitation Learning Approach for Cache Replacement
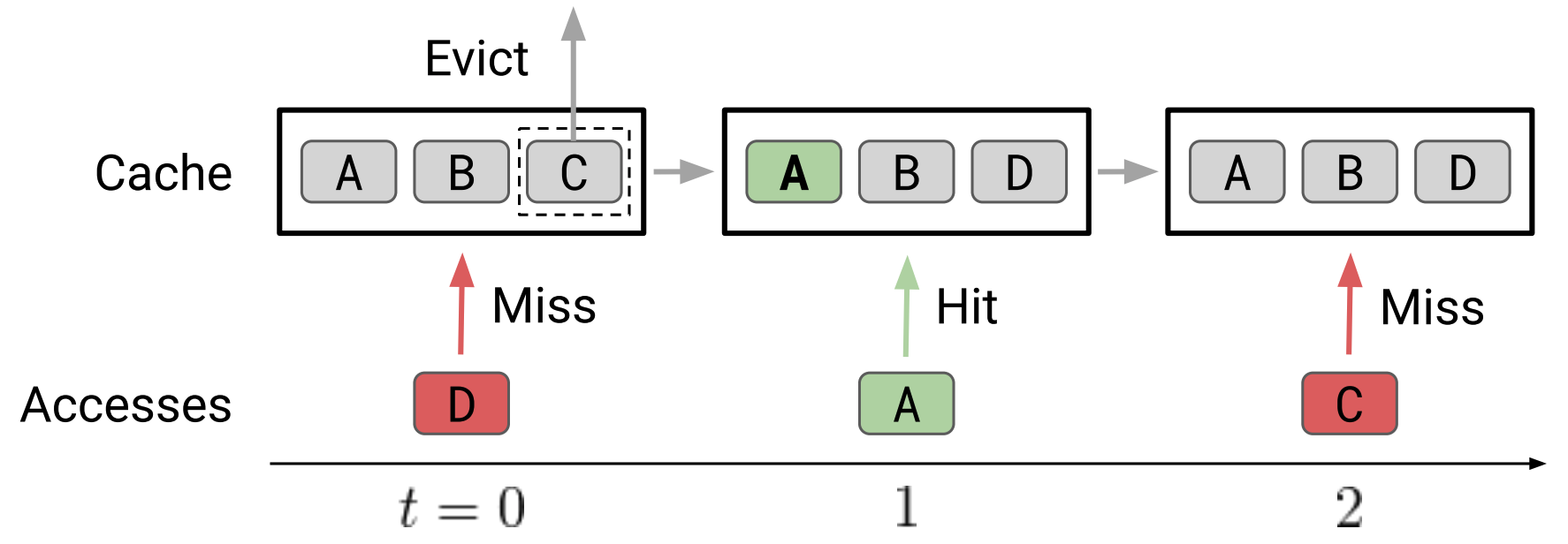
Contact: evanliu@cs.stanford.edu
Links: Paper
Keywords: imitation learning, cache replacement, benchmark
An Investigation of Why Overparameterization Exacerbates Spurious Correlations
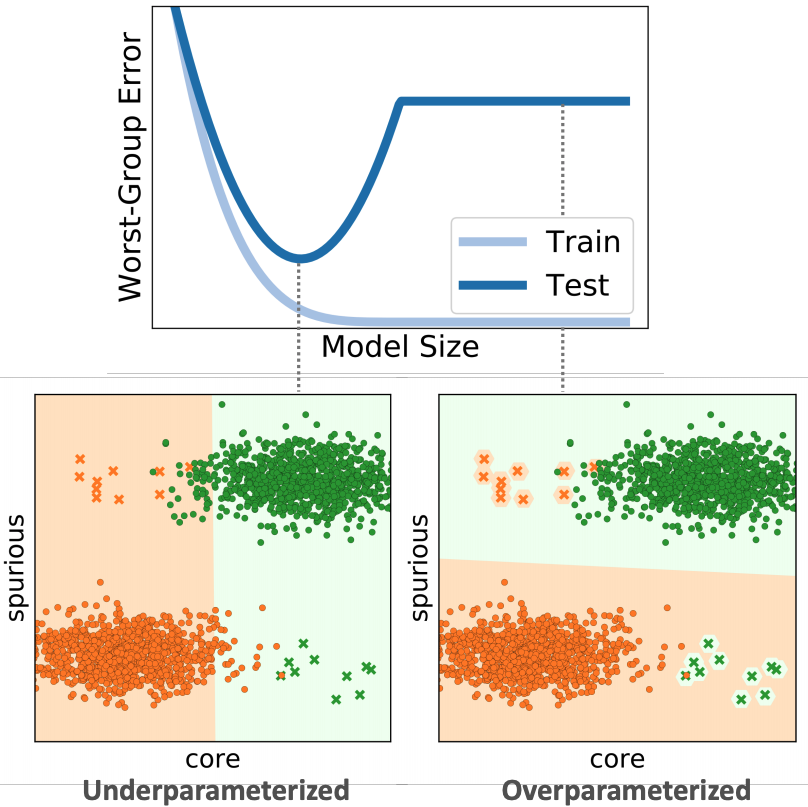
Contact: ssagawa@cs.stanford.edu
Links: Paper
Keywords: robustness, spurious correlations, overparameterization
Better Depth-Width Trade-offs for Neural Networks through the Lens of Dynamical Systems.
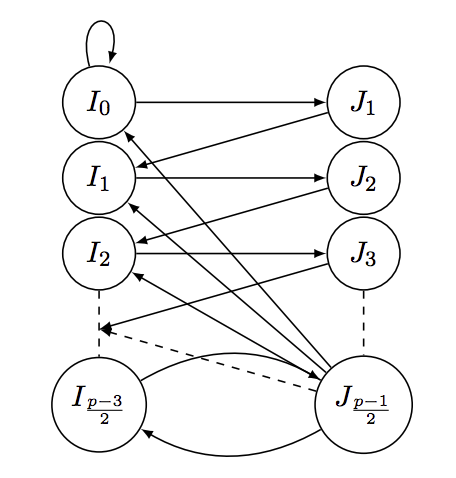
Contact: vaggos@cs.stanford.edu
Links: Paper
Keywords: expressivity, depth, width, dynamical systems
Bridging the Gap Between f-GANs and Wasserstein GANs
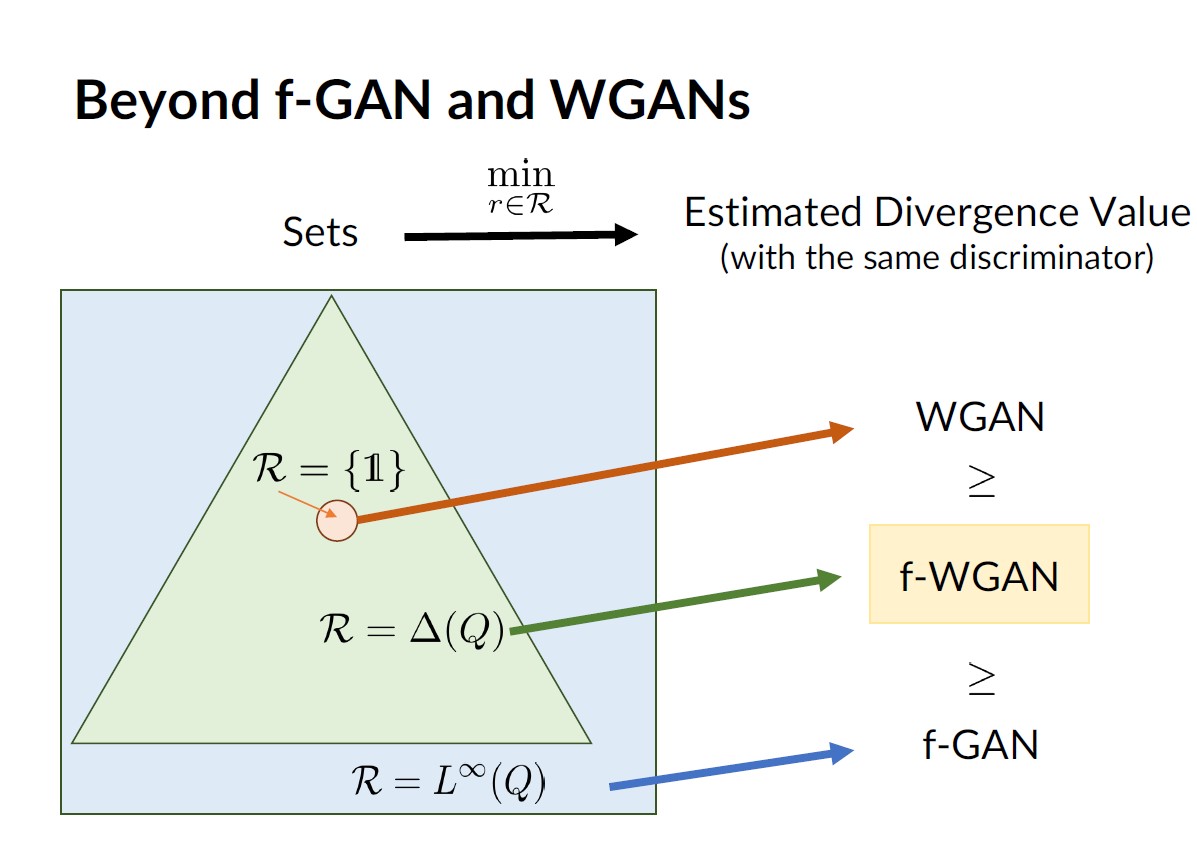
Contact: jiaming.tsong@gmail.com
Links: Paper
Keywords: gans, generative models, f-divergence, wasserstein distance
Concept Bottleneck Models
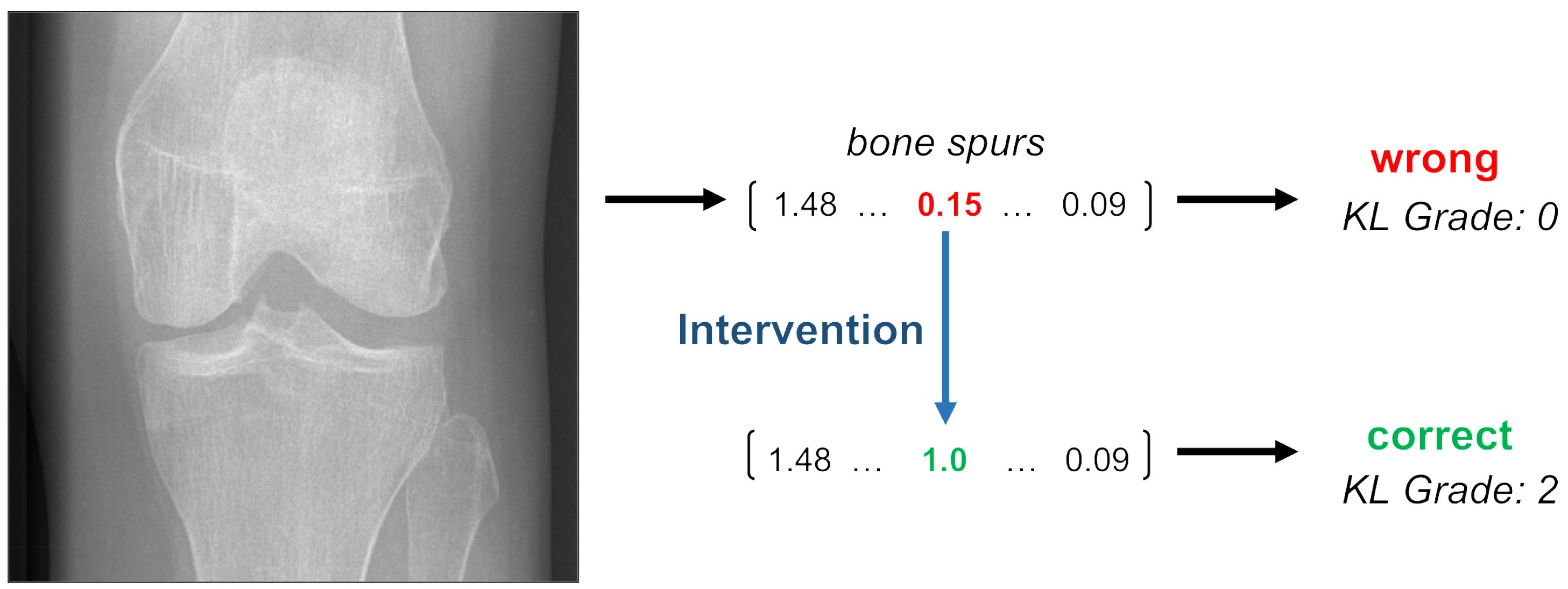
Contact: pangwei@cs.stanford.edu
Links: Paper
Keywords: concepts, intervention, interpretability
Domain Adaptive Imitation Learning
Contact: khkim@cs.stanford.edu
Links: Paper
Keywords: imitation learning, domain adaptation, reinforcement learning, generative adversarial networks, cycle consistency
Encoding Musical Style with Transformer Autoencoders
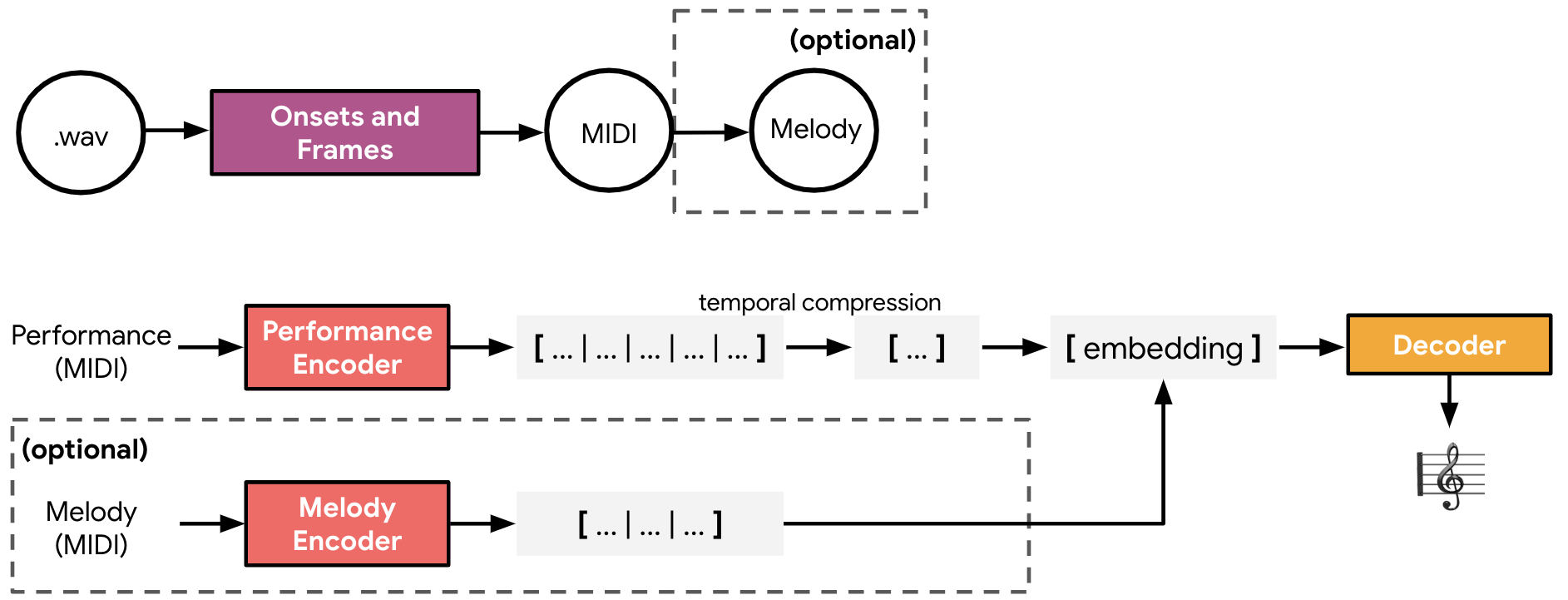
Contact: kechoi@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: sequential, network, and time-series modeling; applications - music
Fair Generative Modeling via Weak Supervision

Contact: kechoi@cs.stanford.edu
Links: Paper | Video
Keywords: deep learning - generative models and autoencoders; fairness, equity, justice, and safety
Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
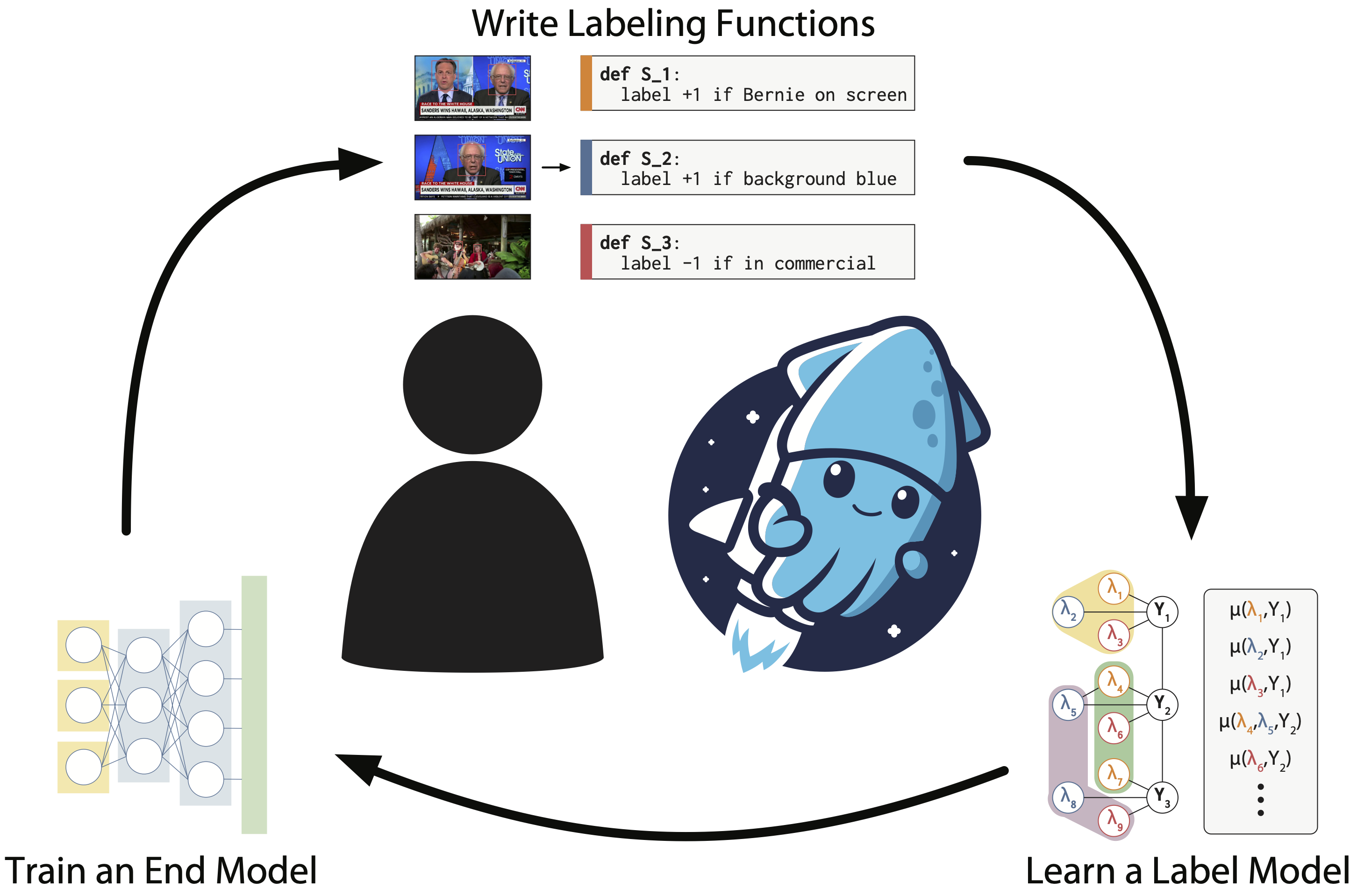
Contact: danfu@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: weak supervision, latent variable models
Flexible and Efficient Long-Range Planning Through Curious Exploration
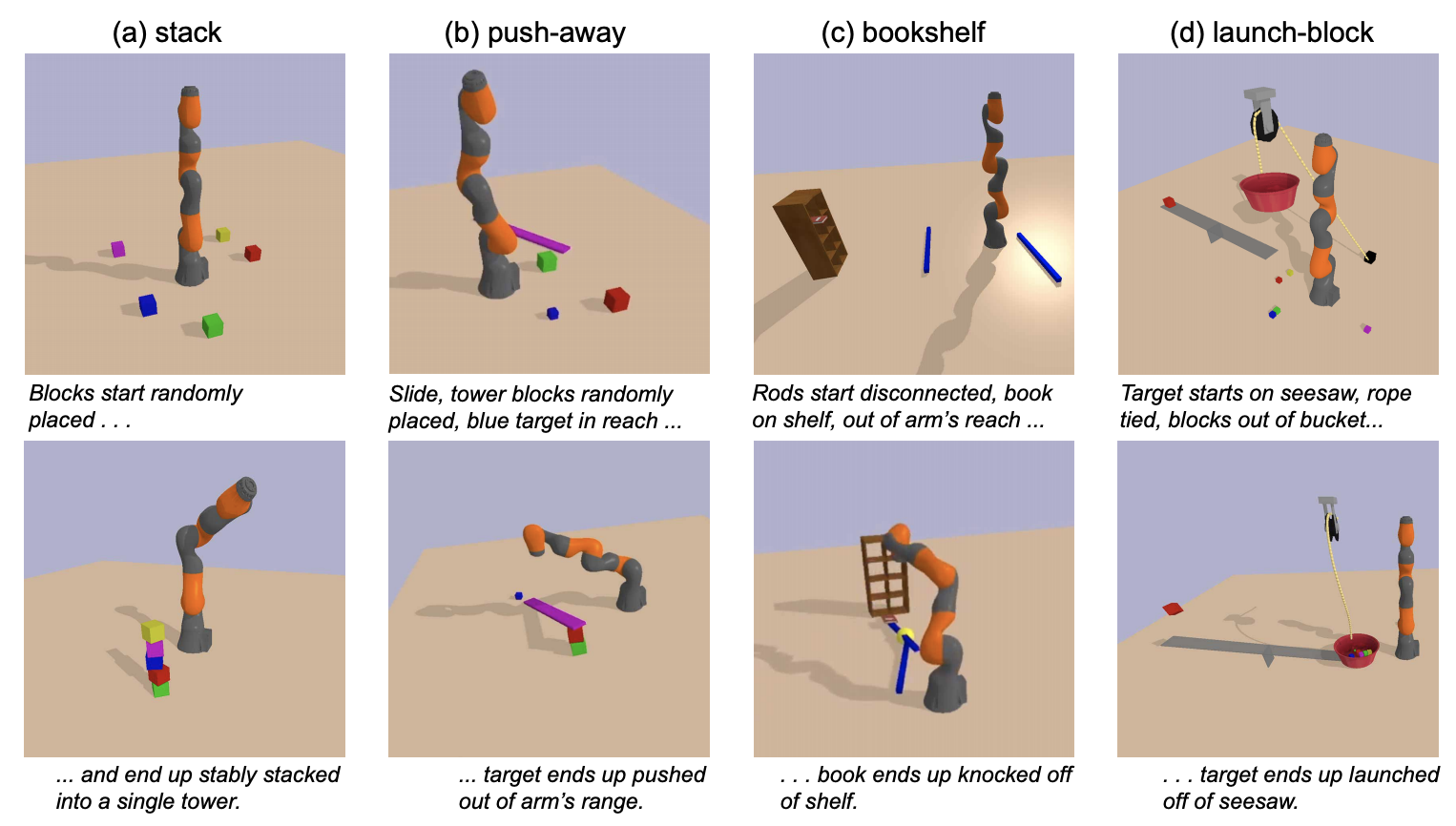
Contact: yamins@stanford.edu
Links: Paper | Blog Post | Video
Keywords: planning, deep learning, sparse reinforcement learning, curiosity
FormulaZero: Distributionally Robust Online Adaptation via Offline Population Synthesis
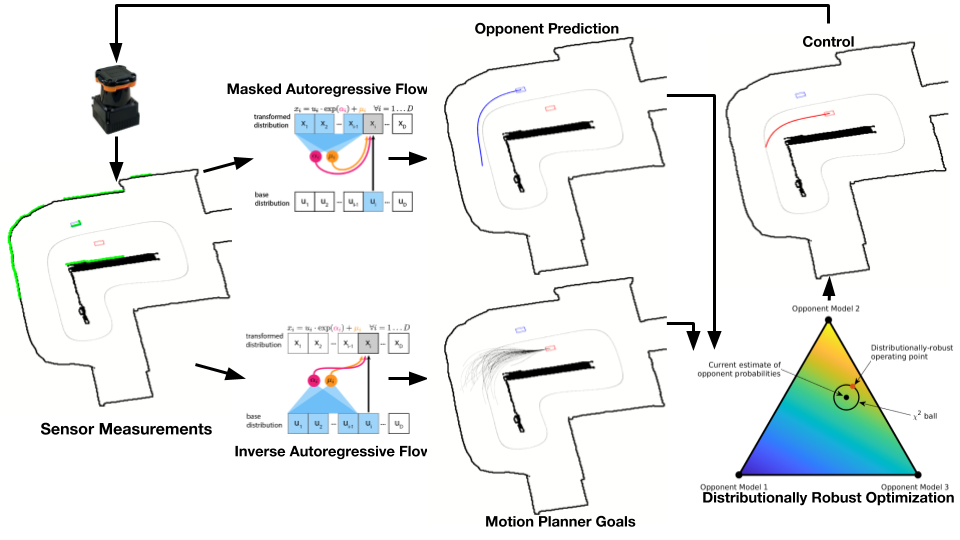
Contact: amans@stanford.edu, mokelly@seas.upenn.edu
Links: Paper | Video
Keywords: distributional robustness, online learning, autonomous driving, reinforcement learning, simulation, mcmc
Goal-Aware Prediction: Learning to Model what Matters
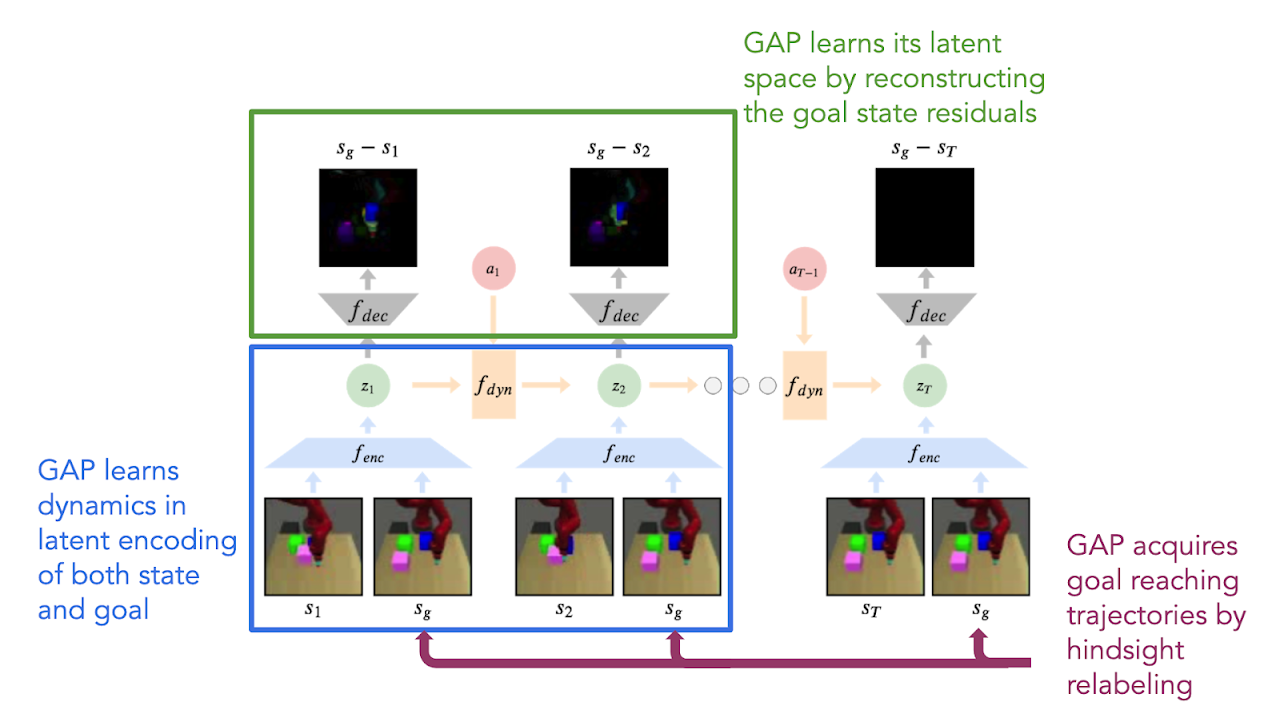
Contact: surajn@stanford.edu
Links: Paper
Keywords: reinforcement learning, visual planning, robotics
Graph-based, Self-Supervised Program Repair from Diagnostic Feedback
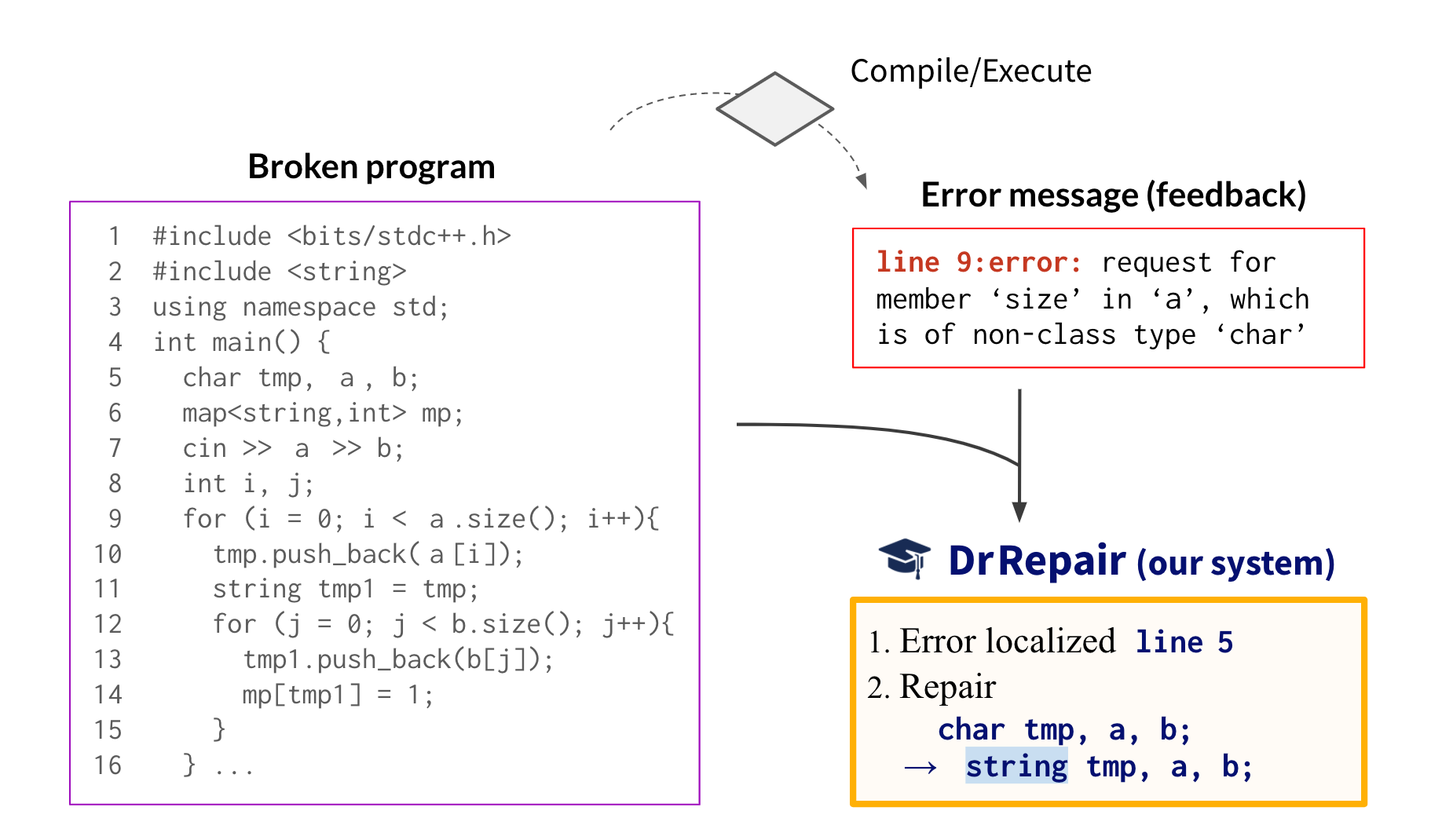
Contact: myasu@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: program repair, program synthesis, self-supervision, pre-training, graph
Interpretable Off-Policy Evaluation in Reinforcement Learning by Highlighting Influential Transitions
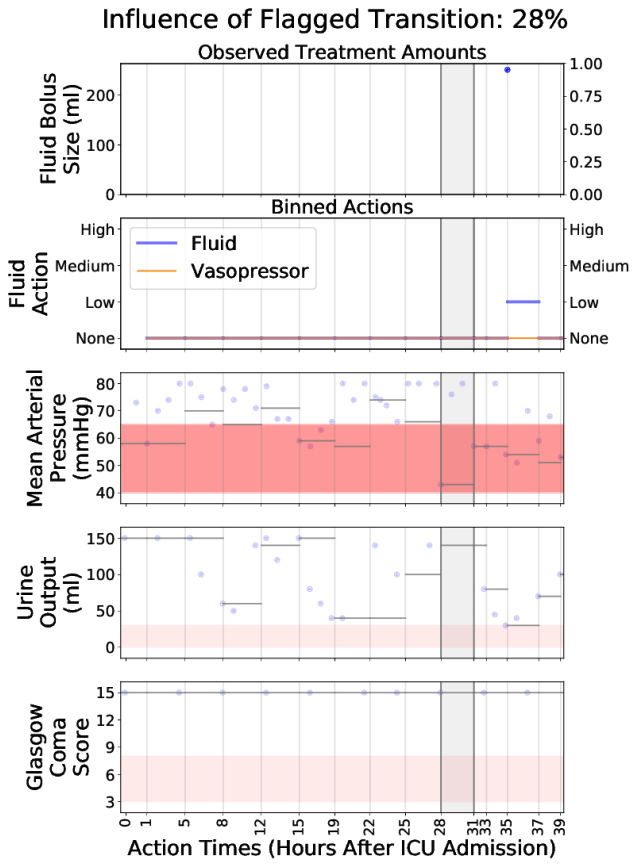
Contact: gottesman@fas.harvard.edu
Links: Paper
Keywords: reinforcement learning, off-policy evaluation, interpretability
Learning Near Optimal Policies with Low Inherent Bellman Error
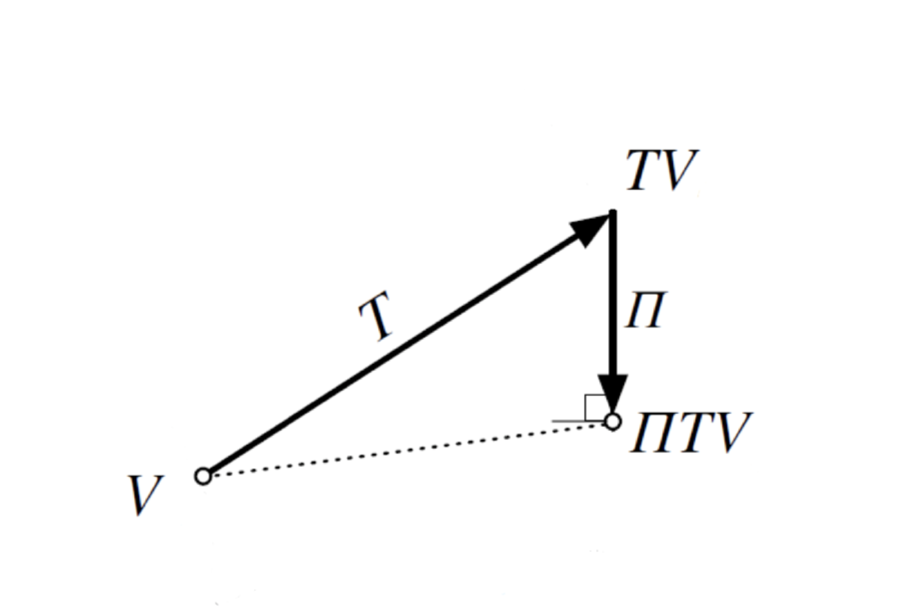
Contact: zanette@stanford.edu
Links: Paper
Keywords: reinforcement learning, exploration, function approximation
Maximum Likelihood With Bias-Corrected Calibration is Hard-To-Beat at Label Shift Domain Adaptation
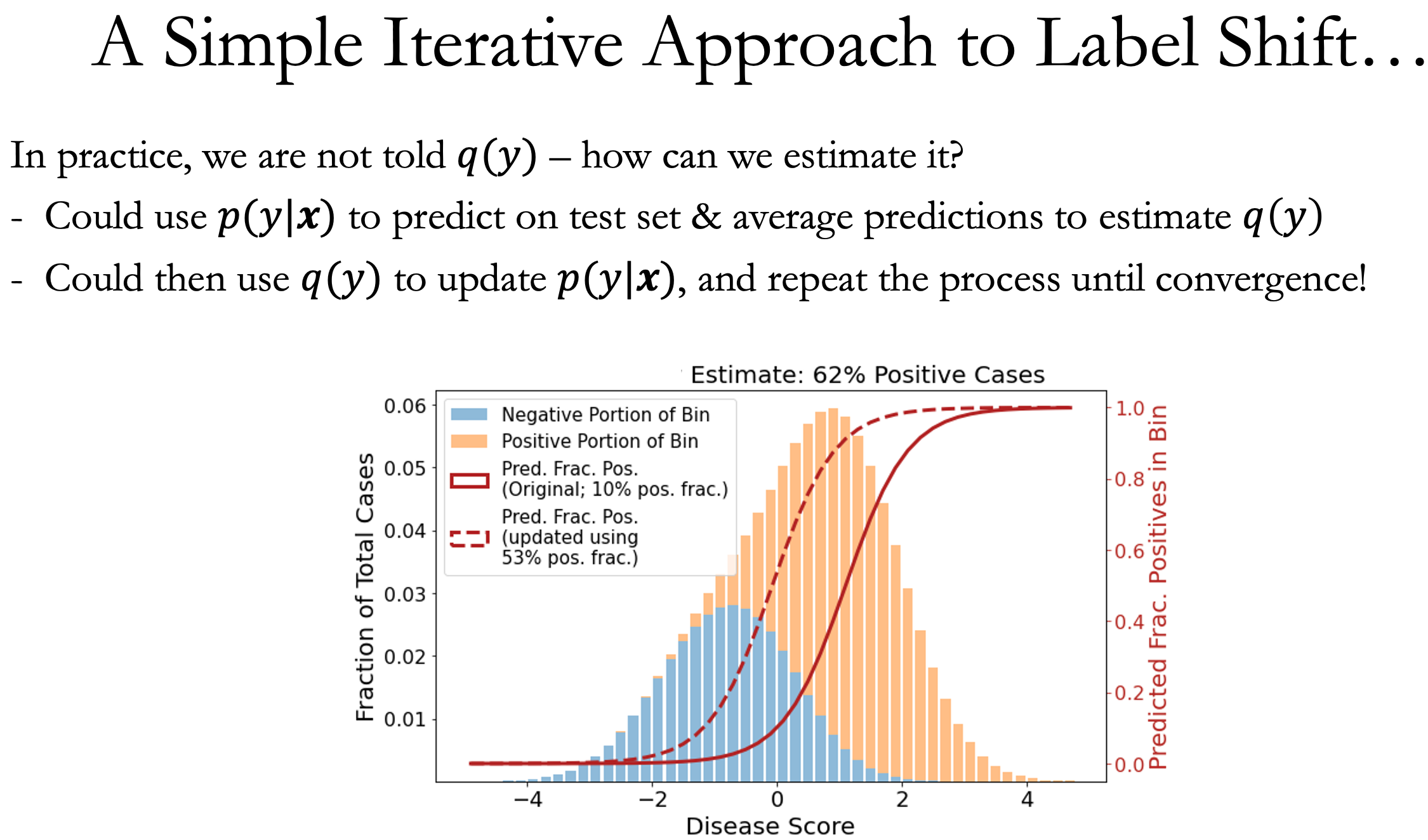
Contact: avanti@cs.stanford.edu, amr.alexandari@gmail.com, akundaje@stanford.edu
Links: Paper | Blog Post | Video
Keywords: domain adaptation, label shift, calibration, maximum likelihood
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
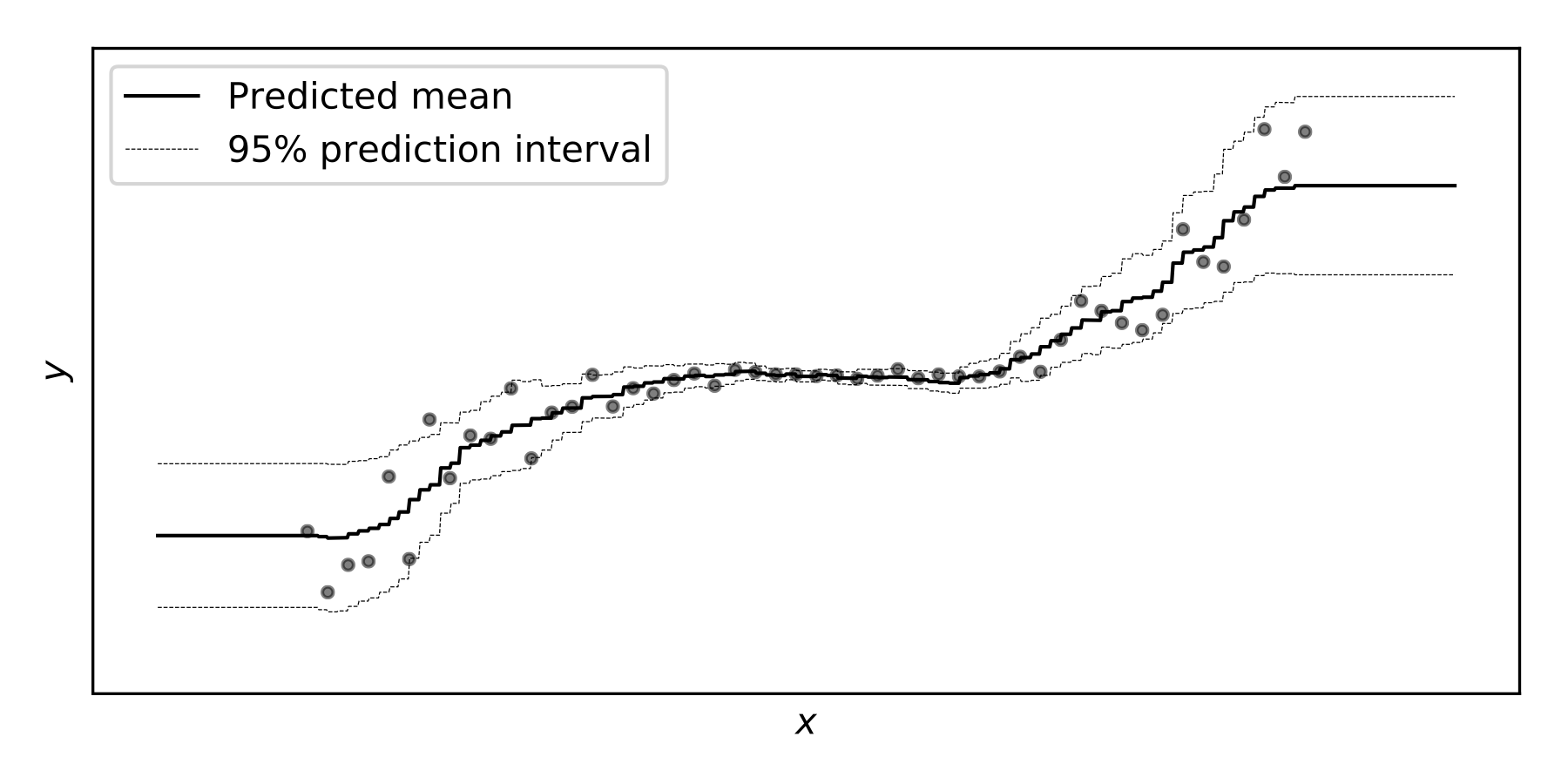
Contact: avati@cs.stanford.edu
Links: Paper
Keywords: gradient boosting, uncertainty estimation, natural gradient
On the Expressivity of Neural Networks for Deep Reinforcement Learning
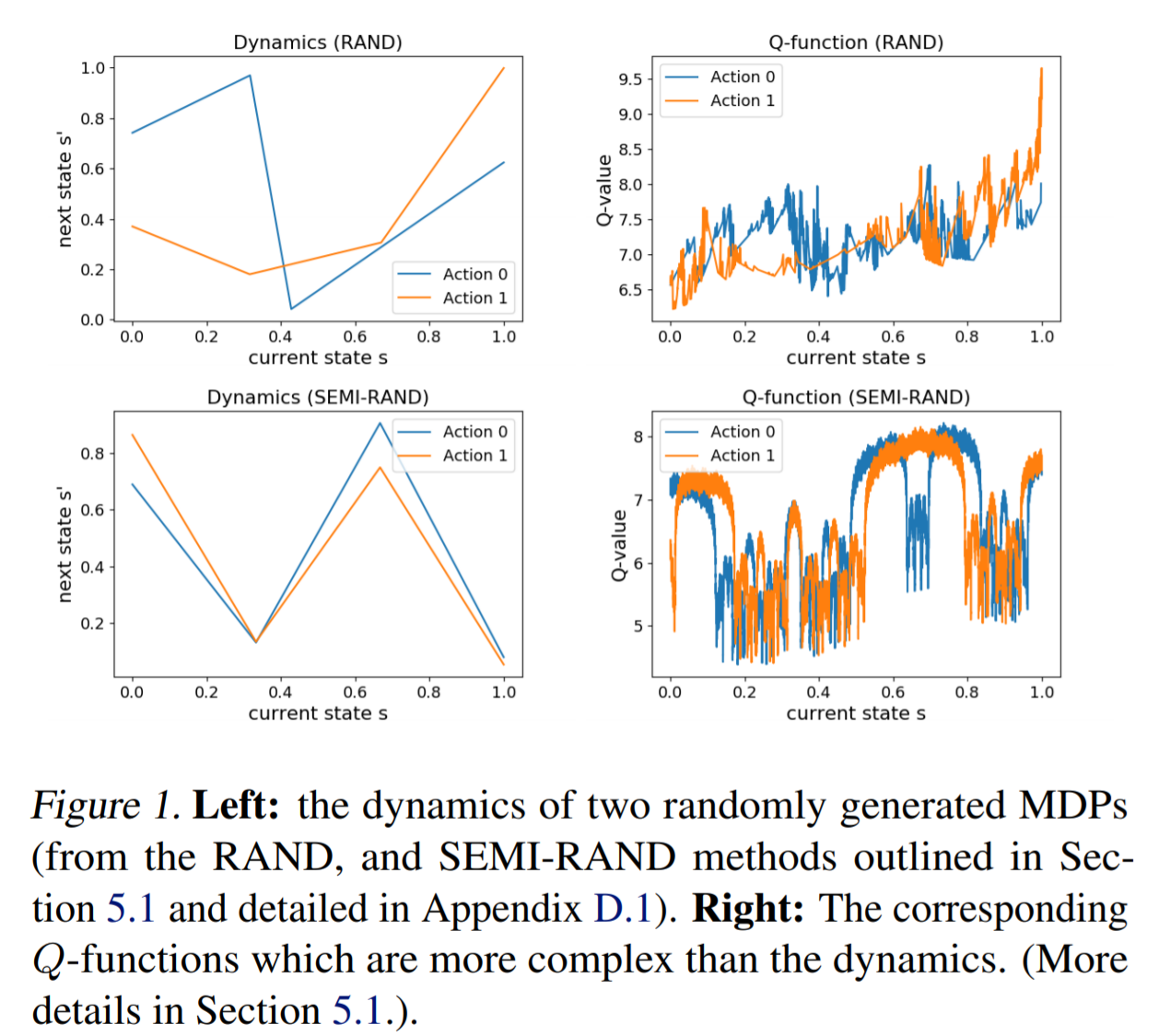
Contact: kefandong@gmail.com
Links: Paper
Keywords: reinforcement learning
On the Generalization Effects of Linear Transformations in Data Augmentation
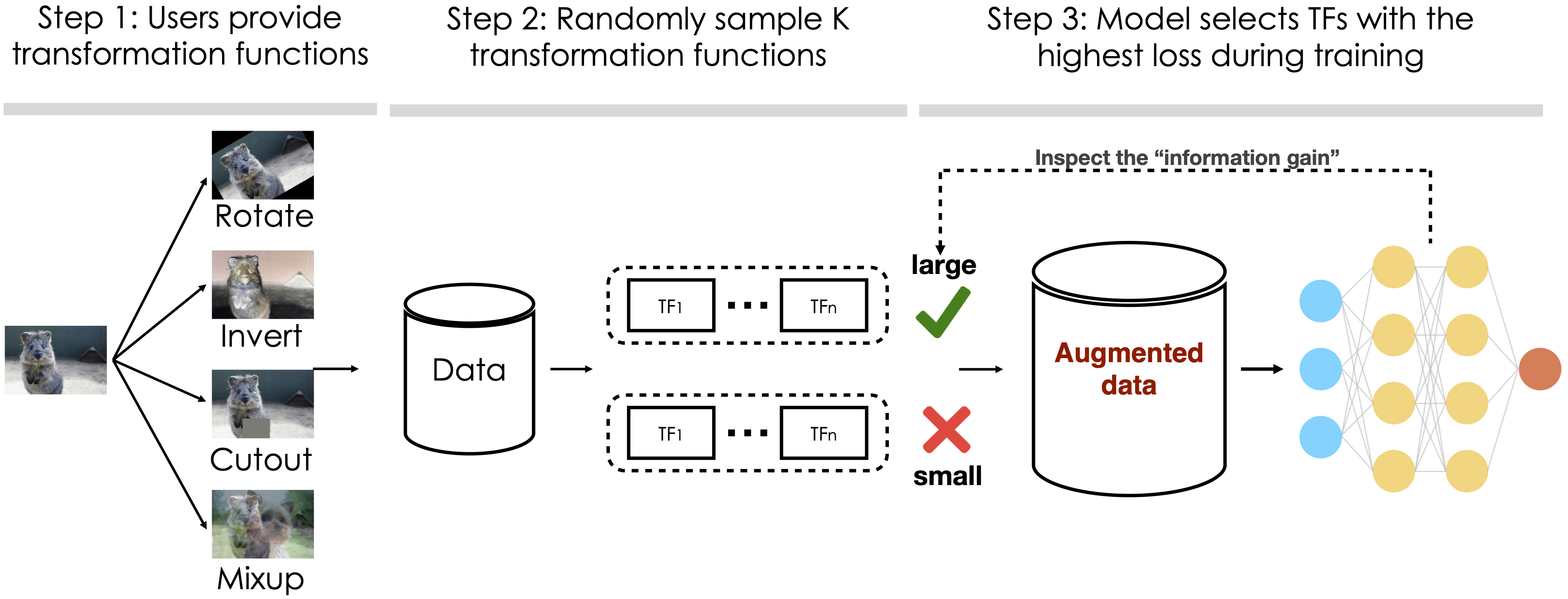
Contact: senwu@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: data augmentation, generalization
Predictive Coding for Locally-Linear Control

Contact: ruishu@stanford.edu
Links: Paper | Video
Keywords: representation learning, information theory, generative models, planning, control
Robustness to Spurious Correlations via Human Annotations
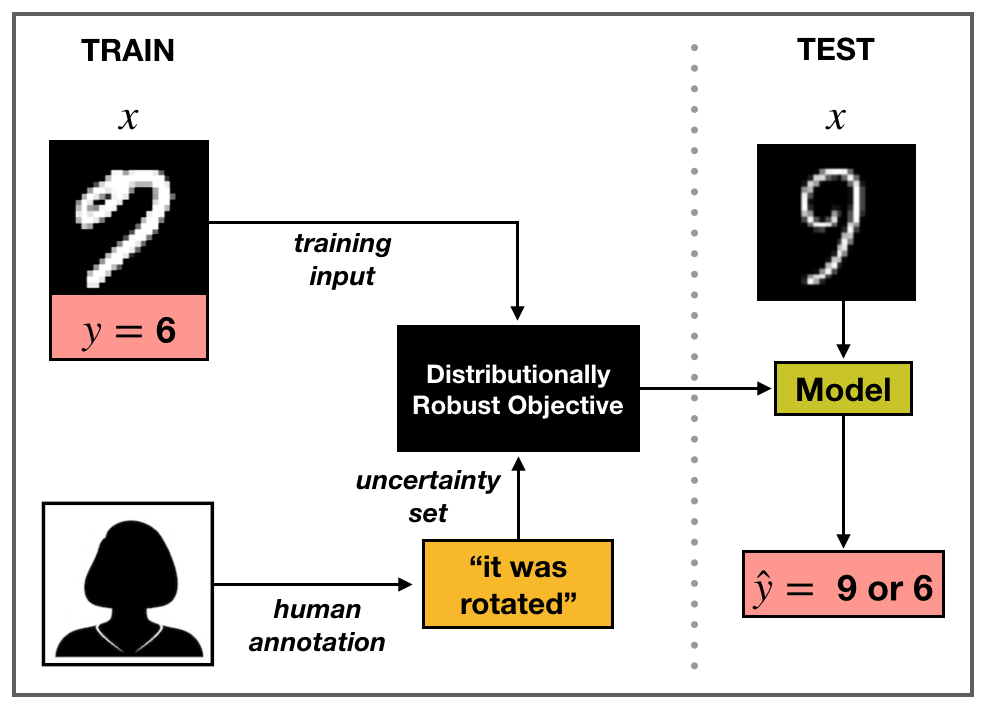
Contact: megha@cs.stanford.edu
Links: Paper
Keywords: robustness, distribution shift, crowdsourcing, human-in-the-loop
Sample Amplification: Increasing Dataset Size even when Learning is Impossible

Contact: shivamgarg@stanford.edu
Links: Paper | Video
Keywords: learning theory, sample amplification, generative models
Scalable Identification of Partially Observed Systems with Certainty-Equivalent EM
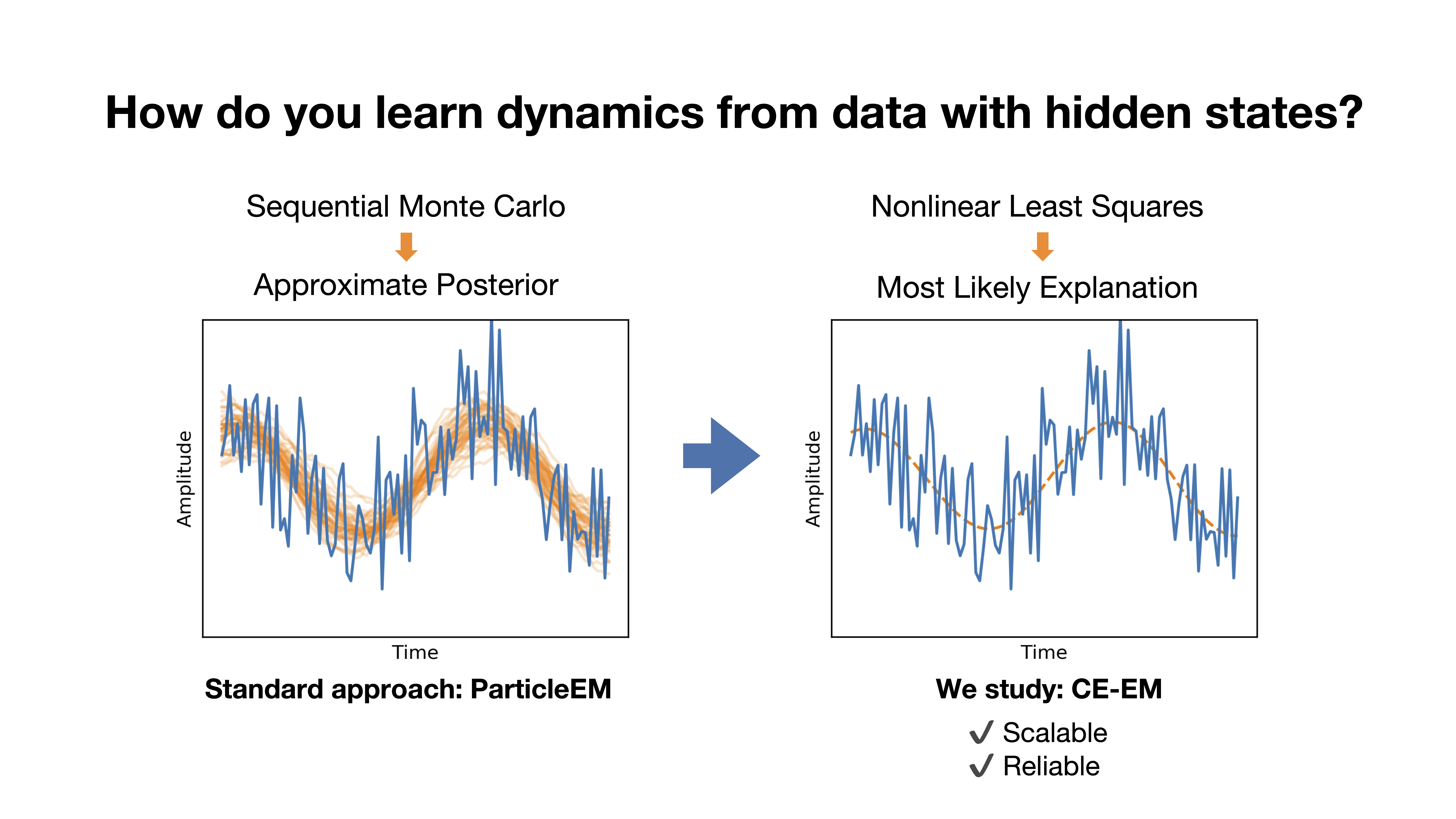
Contact: kmenda@stanford.edu
Links: Paper | Video
Keywords: system identification; time series and sequence models
The Implicit and Explicit Regularization Effects of Dropout
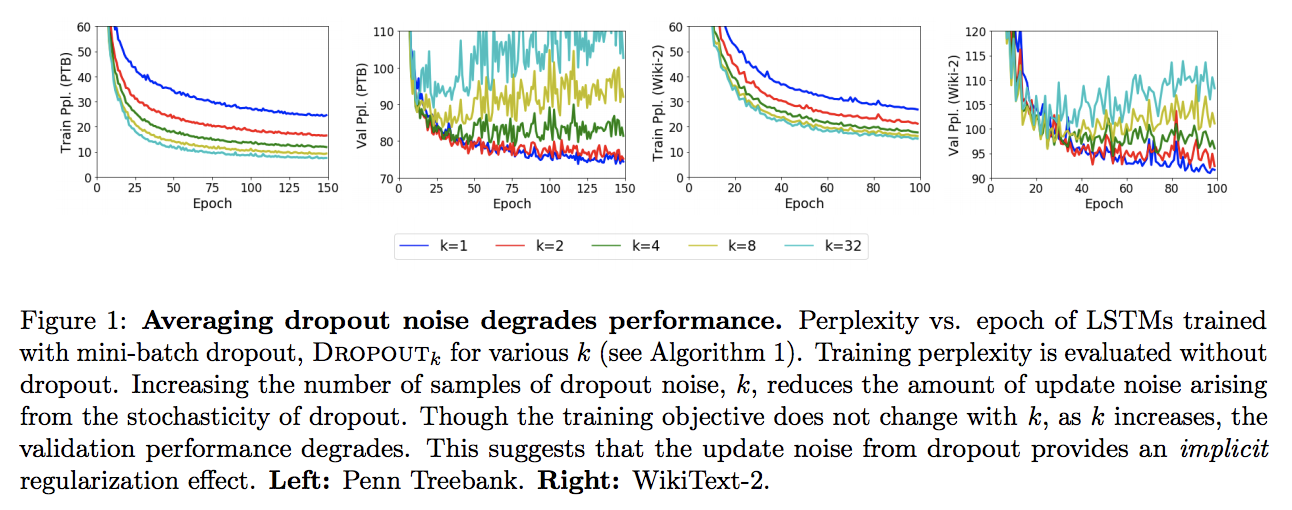
Contact: colinwei@stanford.edu
Links: Paper
Keywords: dropout, deep learning theory, implicit regularization
Training Deep Energy-Based Models with f-Divergence Minimization

Contact: lantaoyu@cs.stanford.edu
Links: Paper
Keywords: energy-based models; f-divergences; deep generative models
Two Routes to Scalable Credit Assignment without Weight Symmetry
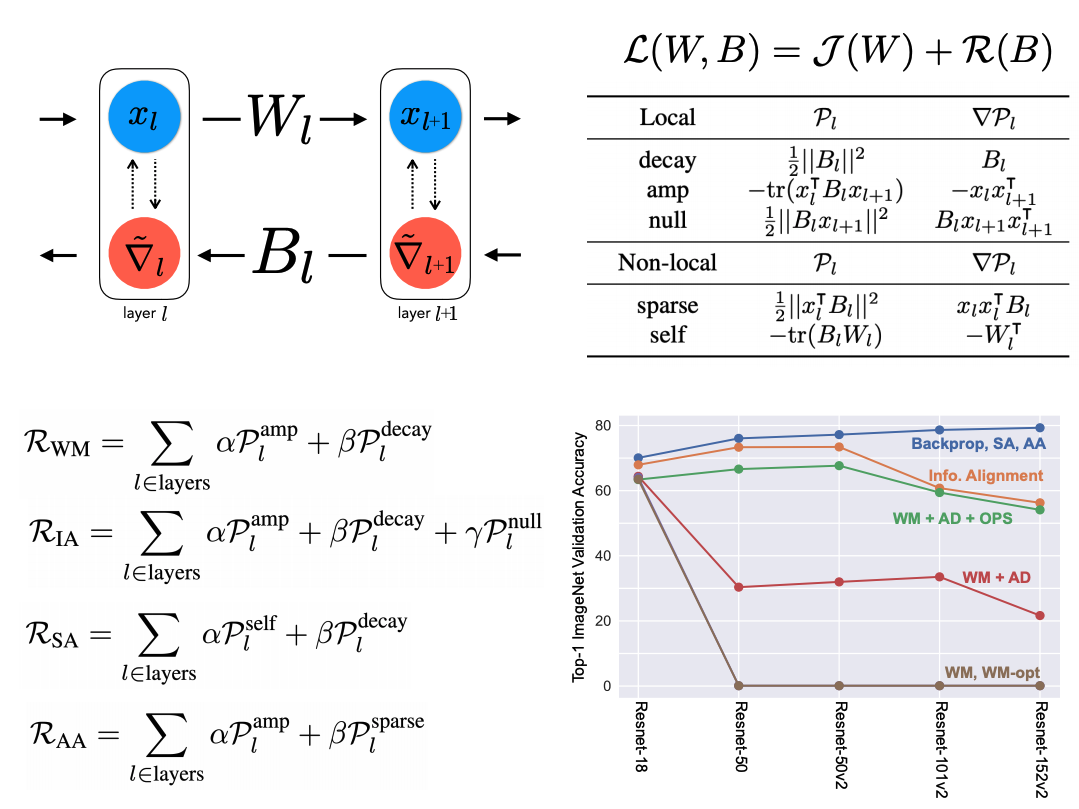
Contact: jvrsgsty@stanford.edu
Links: Paper | Video
Keywords: learning rules, computational neuroscience, machine learning
Understanding Self-Training for Gradual Domain Adaptation

Contact: ananya@cs.stanford.edu
Links: Paper | Video
Keywords: domain adaptation, self-training, semi-supervised learning
Understanding and Mitigating the Tradeoff between Robustness and Accuracy
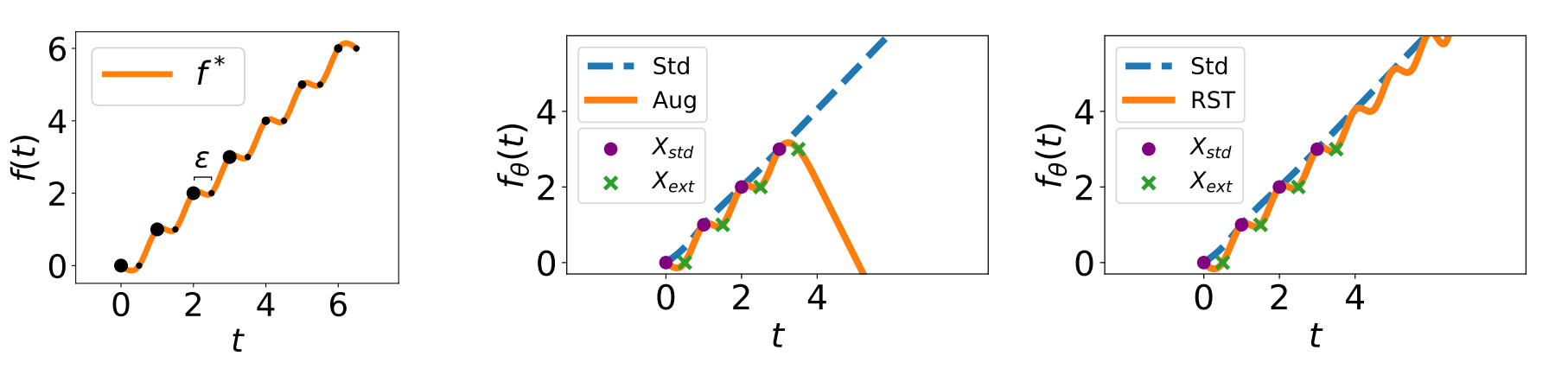
Contact: aditir@stanford.edu, xie@cs.stanford.edu
Links: Paper | Video
Keywords: adversarial examples, adversarial training, robustness, accuracy, tradeoff, robust self-training
Understanding the Curse of Horizon in Off-Policy Evaluation via Conditional Importance Sampling

Contact: yaoliu@stanford.edu
Links: Paper
Keywords: reinforcement learning, off-policy evaluation, importance sampling
Visual Grounding of Learned Physical Models
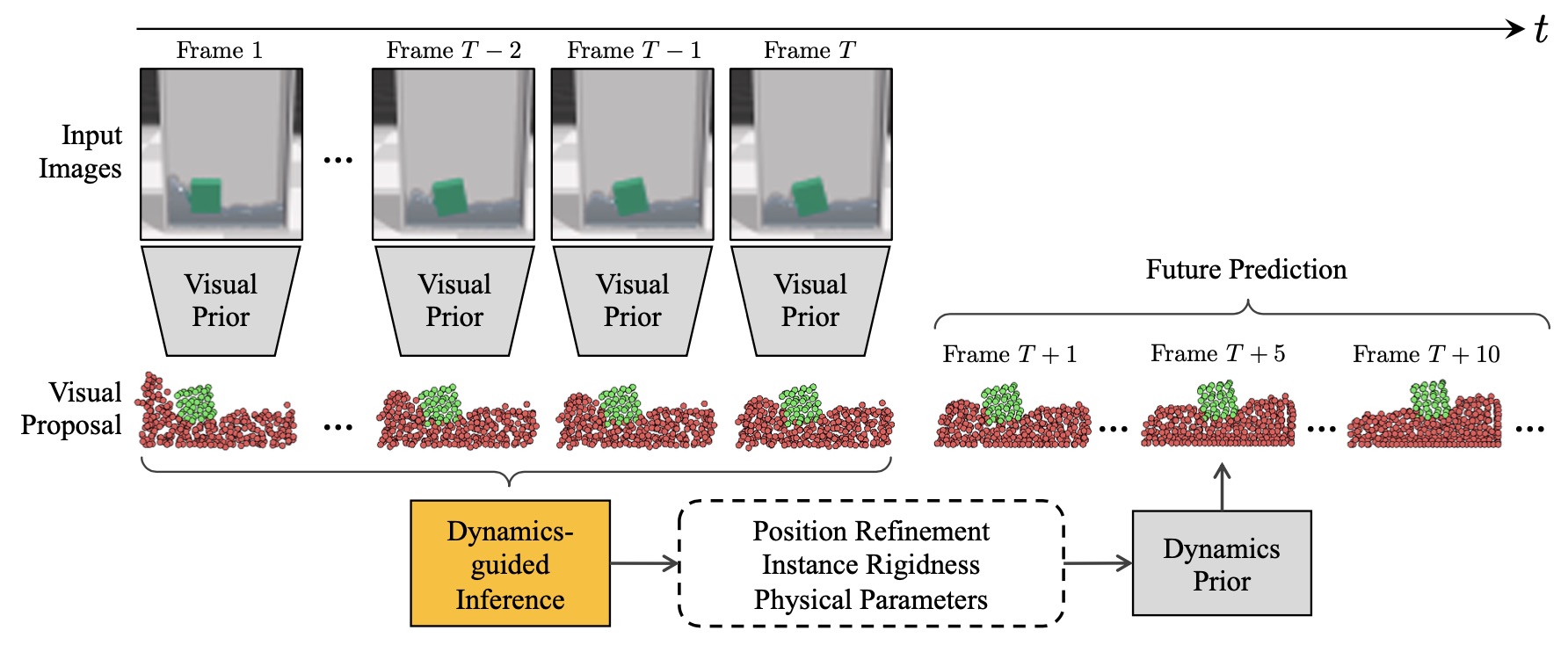
Contact: liyunzhu@mit.edu
Links: Paper | Video
Keywords: intuitive physics, visual grounding, physical reasoning
Learning to Simulate Complex Physics with Graph Networks
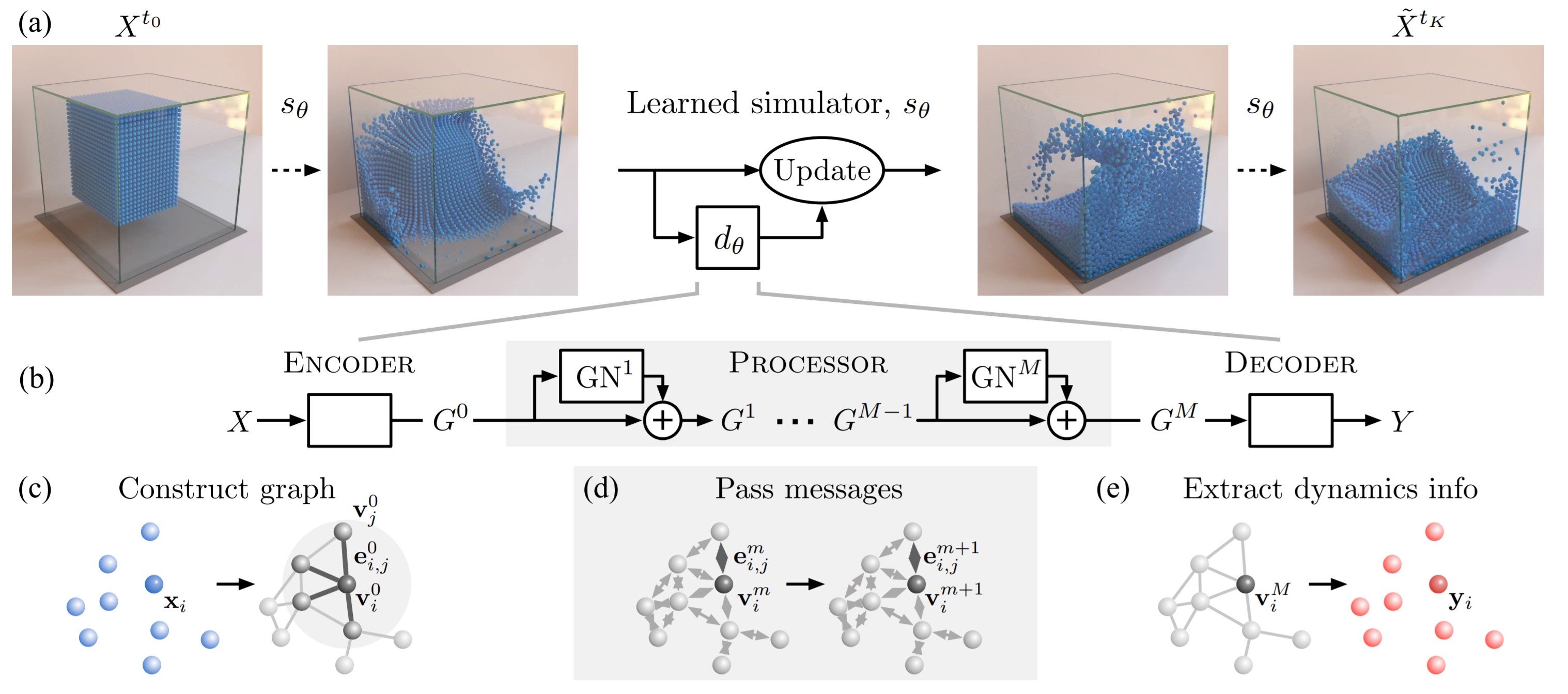
Contact: rexying@stanford.edu
Links: Paper
Keywords: simulation, graph neural networks
Coresets for Data-Efficient Training of Machine Learning Models
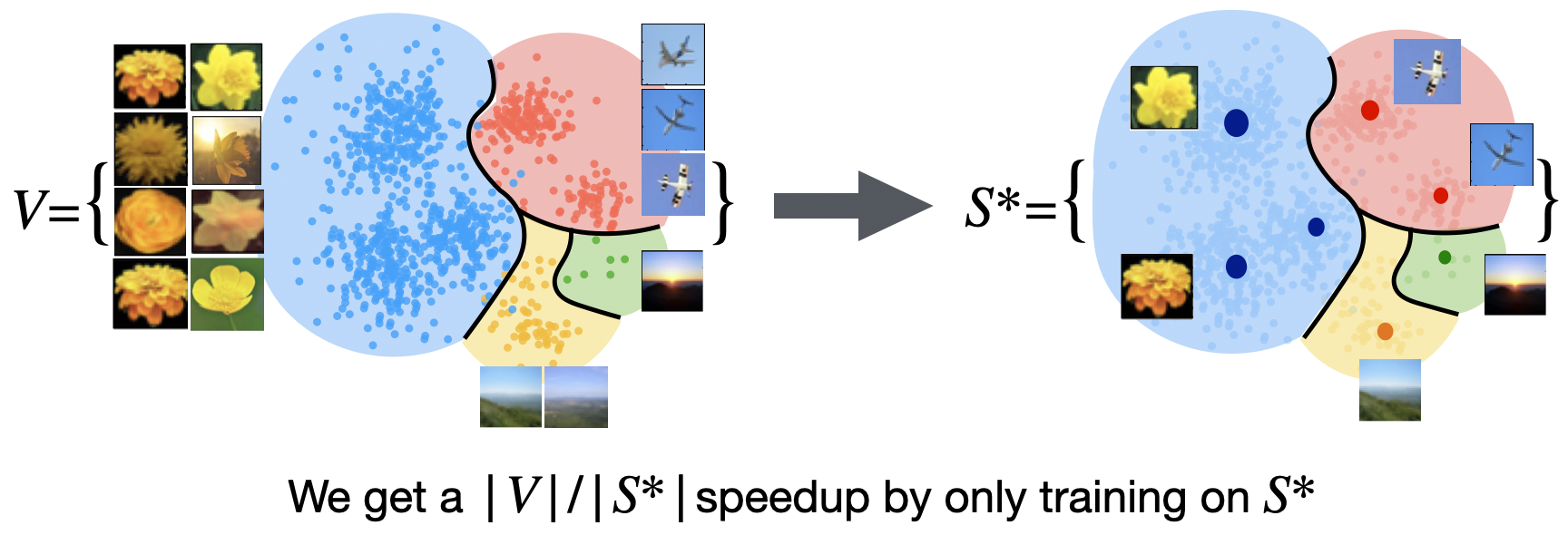
Contact: baharanm@cs.stanford.edu
Links: Paper | Video
Keywords: Coresets, Data-efficient training, Submodular optimization, Incremental gradient methods
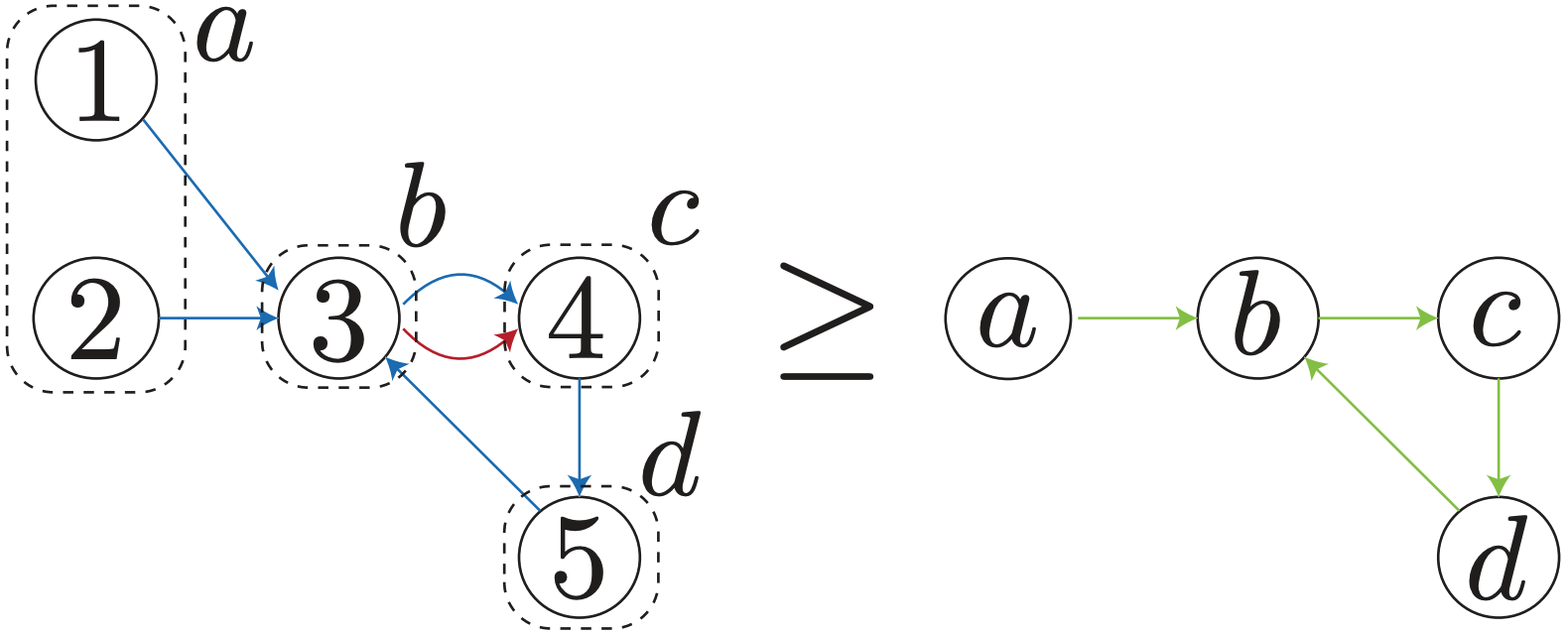
Which Tasks Should be Learned Together in Multi-Task Learning
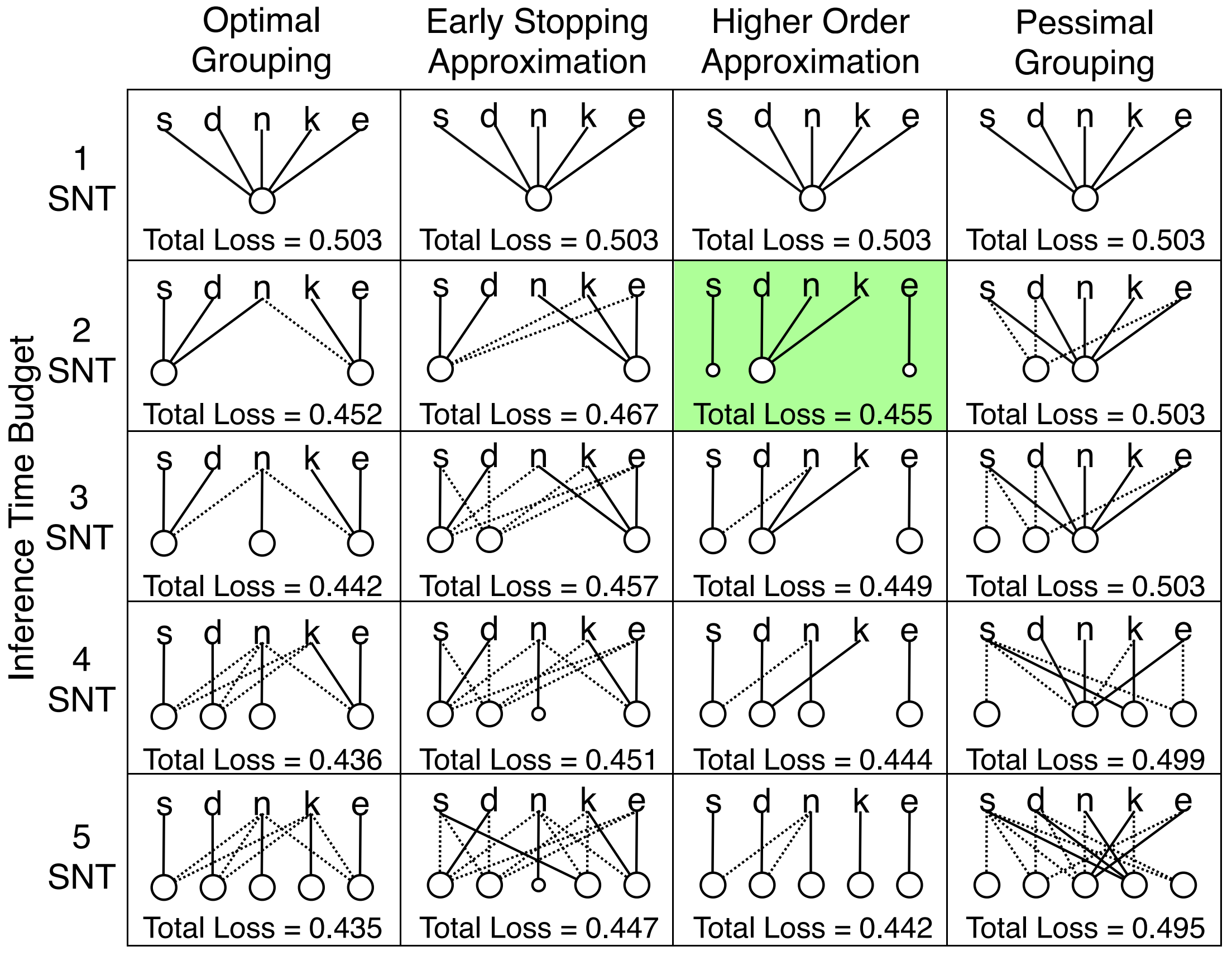
Contact: tstand@cs.stanford.edu
Links: Paper | Video
Keywords: machine learning, multi-task learning, computer vision
Accelerated Message Passing for Entropy-Regularized MAP Inference
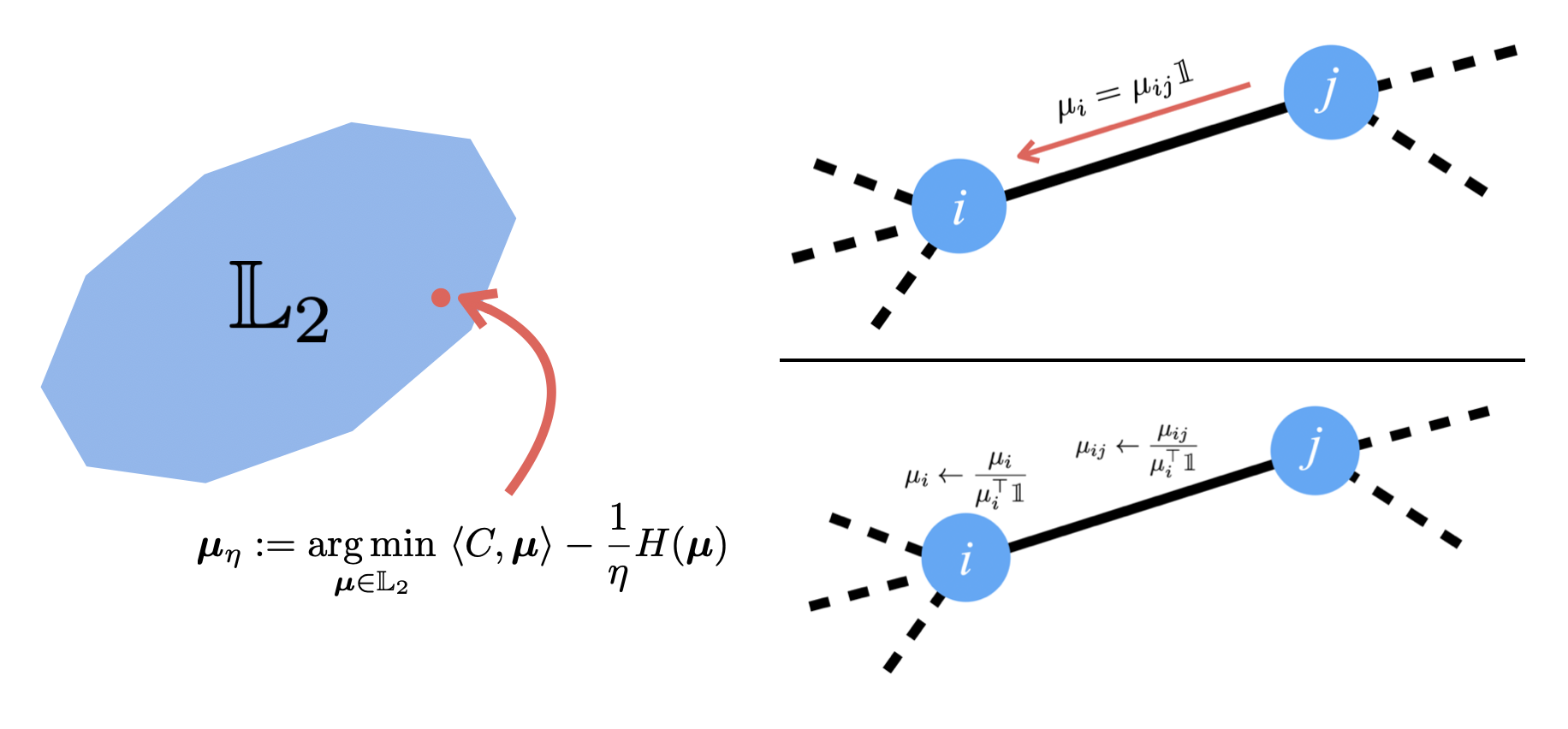
Contact: jnl@stanford.edu
Links: Paper
Keywords: graphical models, map inference, message passing, optimization
On Learning Sets of Symmetric Elements
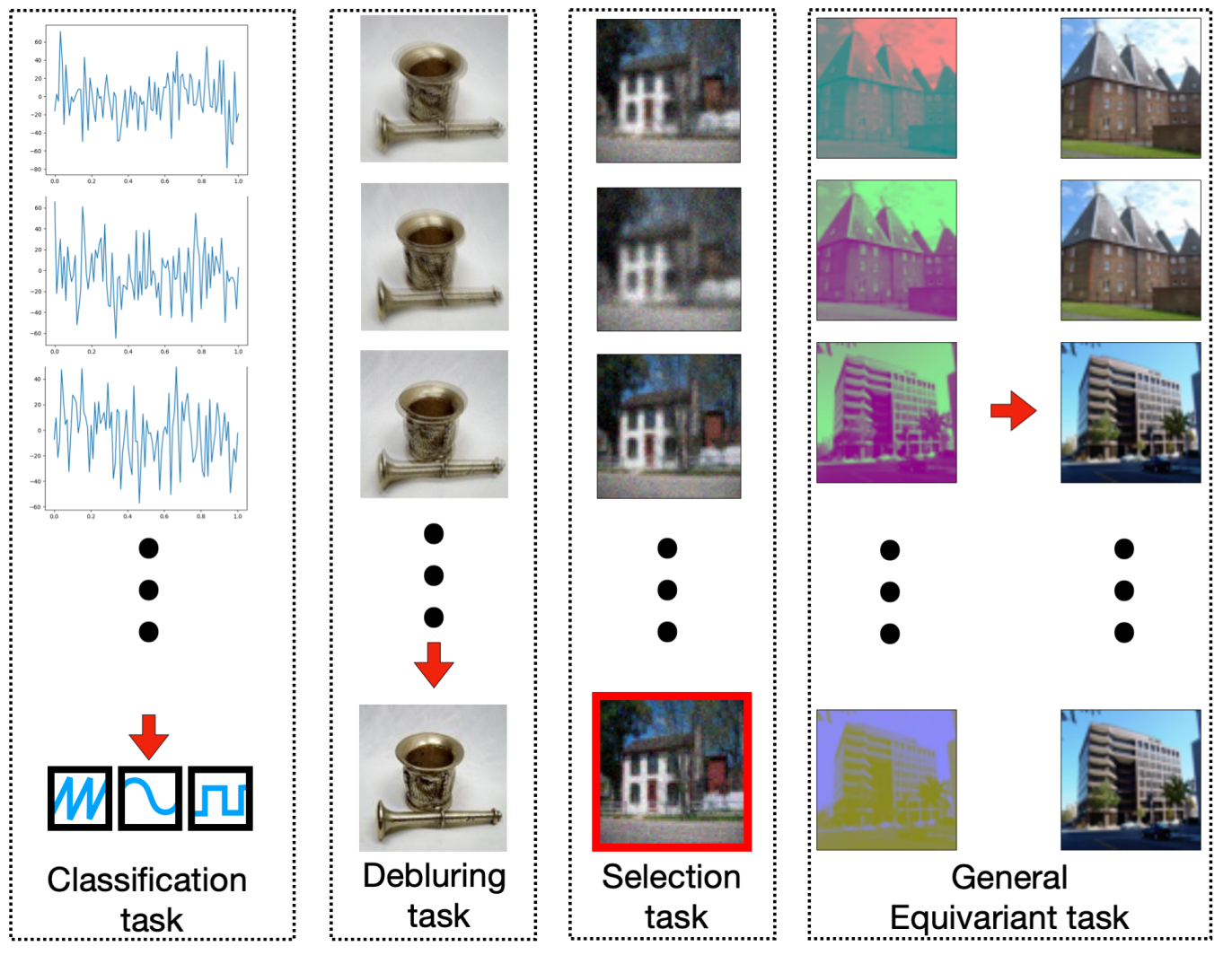
Contact: or.litany@gmail.com
Links: Paper
Keywords: equivariance, sets, pointclouds, graphs
Outstanding Paper Award
Individual Calibration with Randomized Forecasting
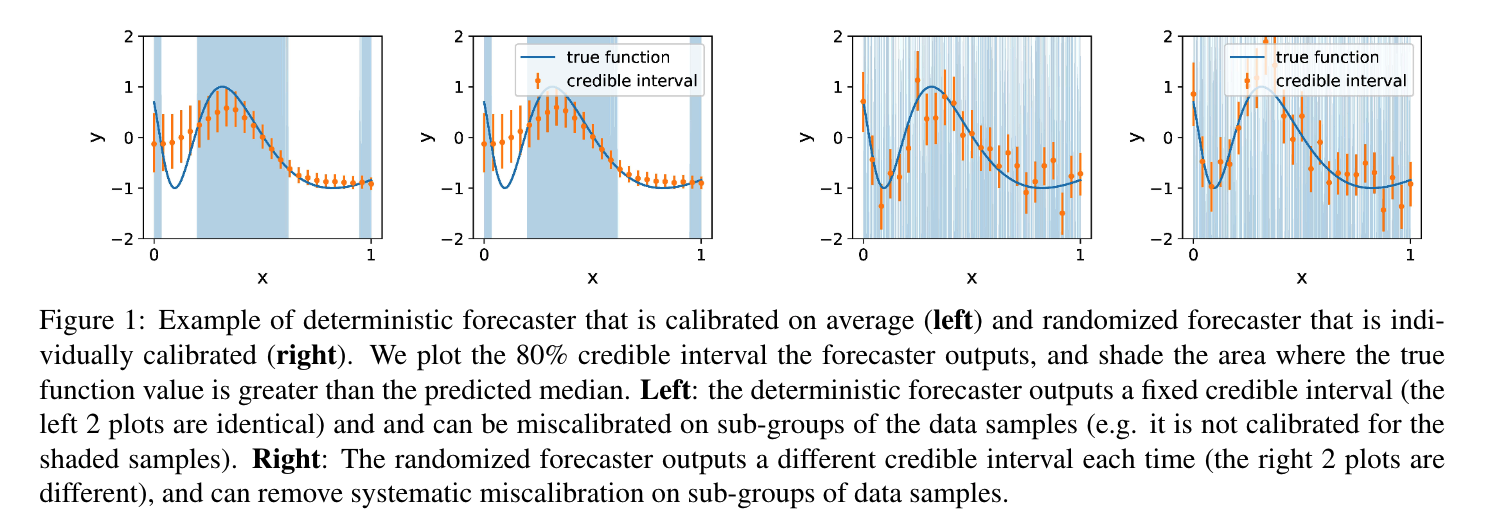
Contact: sjzhao@stanford.edu
Links: Paper
Keywords: calibration, uncertainty estimation
We look forward to seeing you at ICML 2020!