![]()
The Forty-Second International Conference on Machine Learning (ICML) 2025 is being hosted in Vancouver from July 13 to July 19. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts
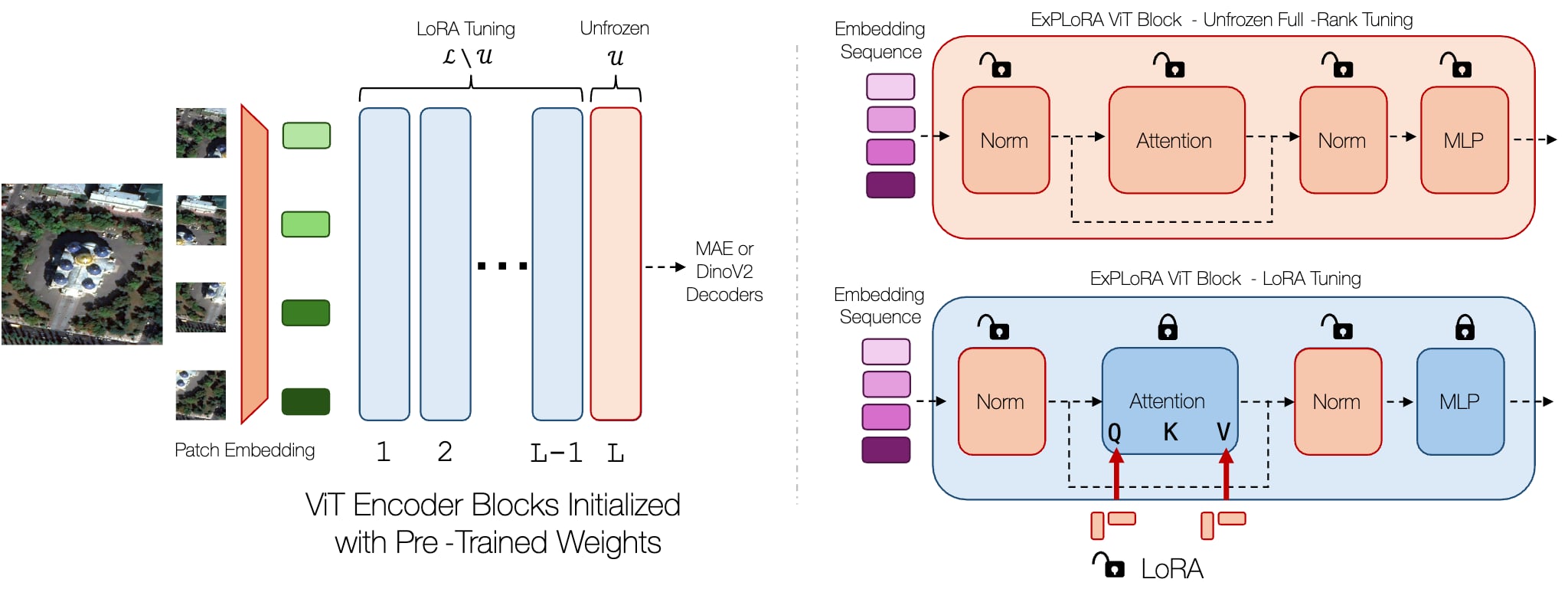 Authors: Samar Khanna, Medhanie Irgau, David Lobell, Stefano Ermon
Authors: Samar Khanna, Medhanie Irgau, David Lobell, Stefano Ermon
Contact: samarkhanna@cs.stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: parameter-efficient pre-training, continual learning, PEFT, unsupervised learning
An analytic theory of creativity in convolutional diffusion models

Contact: kambm@stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: diffusion models, creativity, combinatorial generalization, theory
What can large language models do for sustainable food?
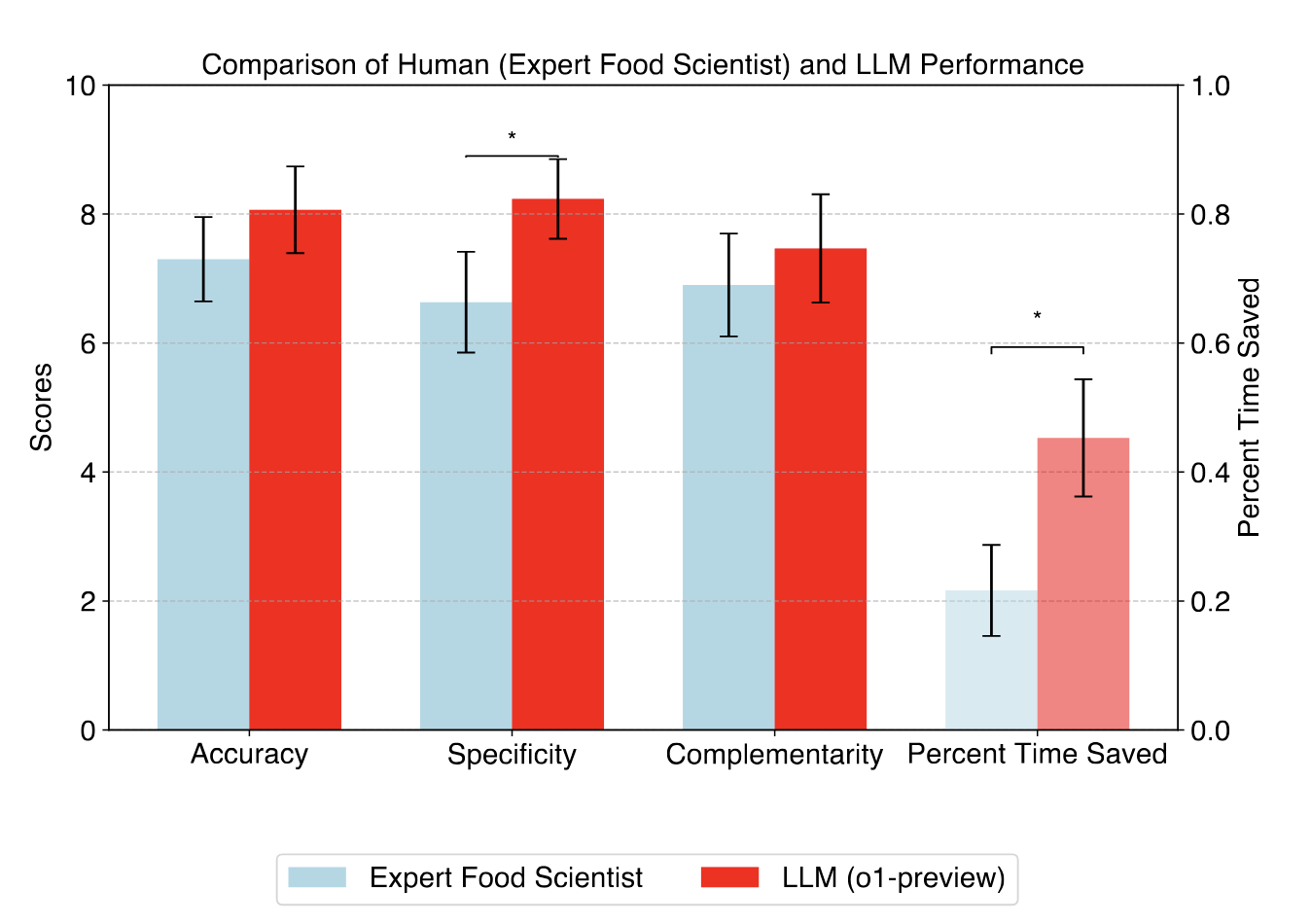
Contact: thomasat@stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: large language models, sustainability, climate, food, health, optimization
Archon: An Architecture Search Framework for Inference-Time Techniques
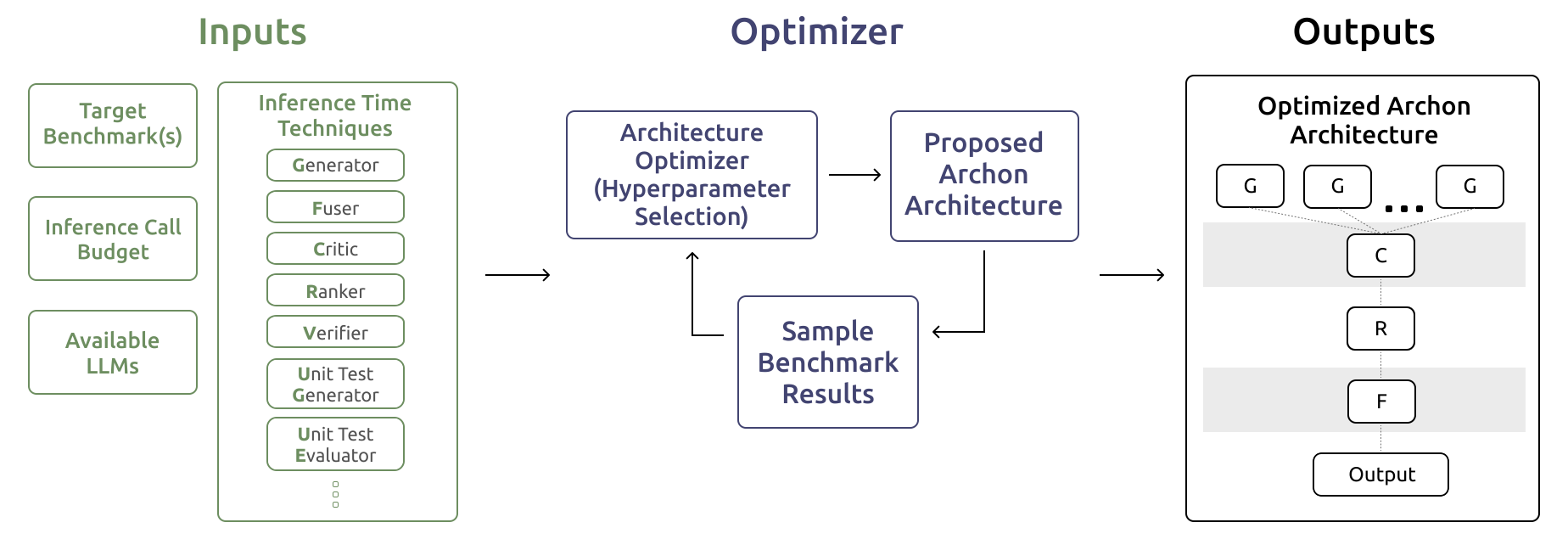
Contact: jonsaadfalcon@gmail.com
Workshop: Main Conference
Award nominations: ICLR 2025: SSM FM Workshop, Oral Presentation
Links: Paper | Website
Keywords: inference-time techniques, test-time scaling, machine learning, natural language processing
Auditing Prompt Caching in Language Model APIs
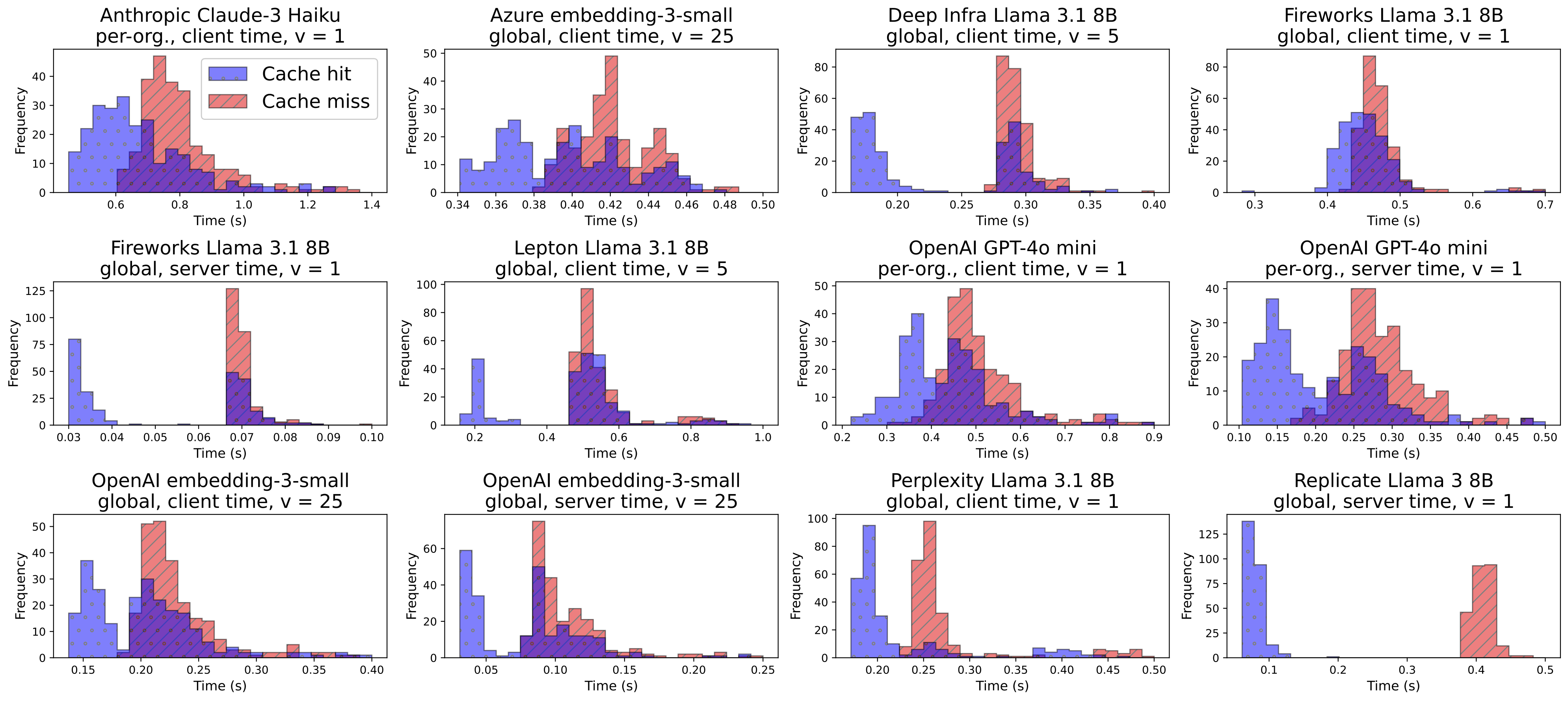
Contact: cygu@cs.stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: large language models, statistical hypothesis testing, timing attack, privacy
AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders
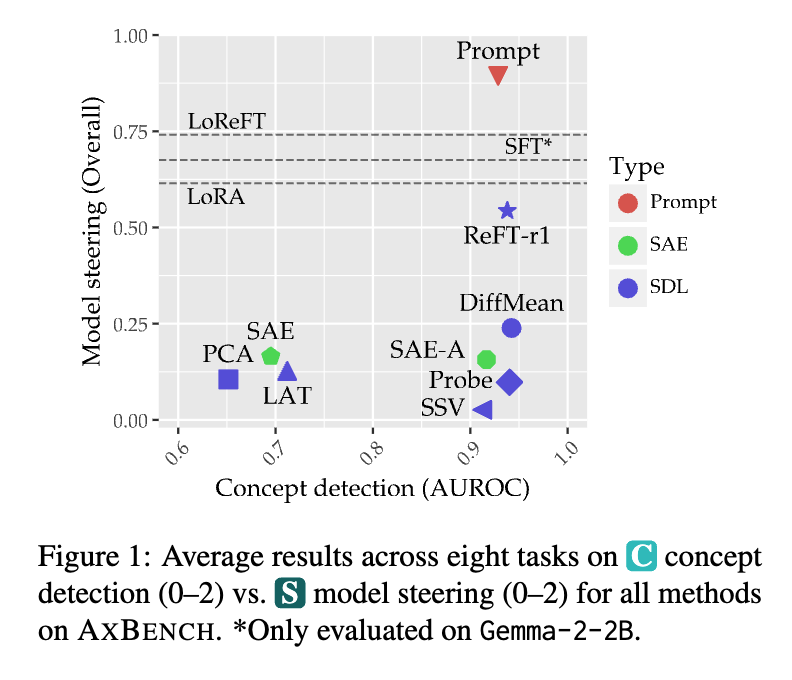
Contact: wuzhengx@stanford.edu
Workshop: Main Conference
Award nominations: Spotlight poster
Links: Paper | Website
Keywords: mechanistic interpretability
Causal-PIK: Causality-based Physical Reasoning with a Physics-Informed Kernel
Contact: cpares@stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: active exploration, physical reasoning, causality, bayesian optimization
CollabLLM: From Passive Responders to Active Collaborators

Contact: shirwu@cs.stanford.edu
Workshop: Main Conference
Award nominations: Oral, Outstanding Paper (6 out of all oral papers, but the organizers said in the email that “This information is under embargo until we announce it officially during the Opening Remarks on the first day of ICML, so please do not share it publicly before then.” so not sure if this is ok to share)
Links: Paper | Blog Post | Website
Keywords: human-centered large language model, multiturn interaction, collaborative problem-solving, reinforcement learning
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World

Contact: rschaef@cs.stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: model collapse, synthetic data, model-data feedback loops, data-model feedback loops, generative models, generative modeling, kernel density estimation, supervised finetuning, machine learning, icml
Confounder-Free Continual Learning via Recursive Feature Normalization
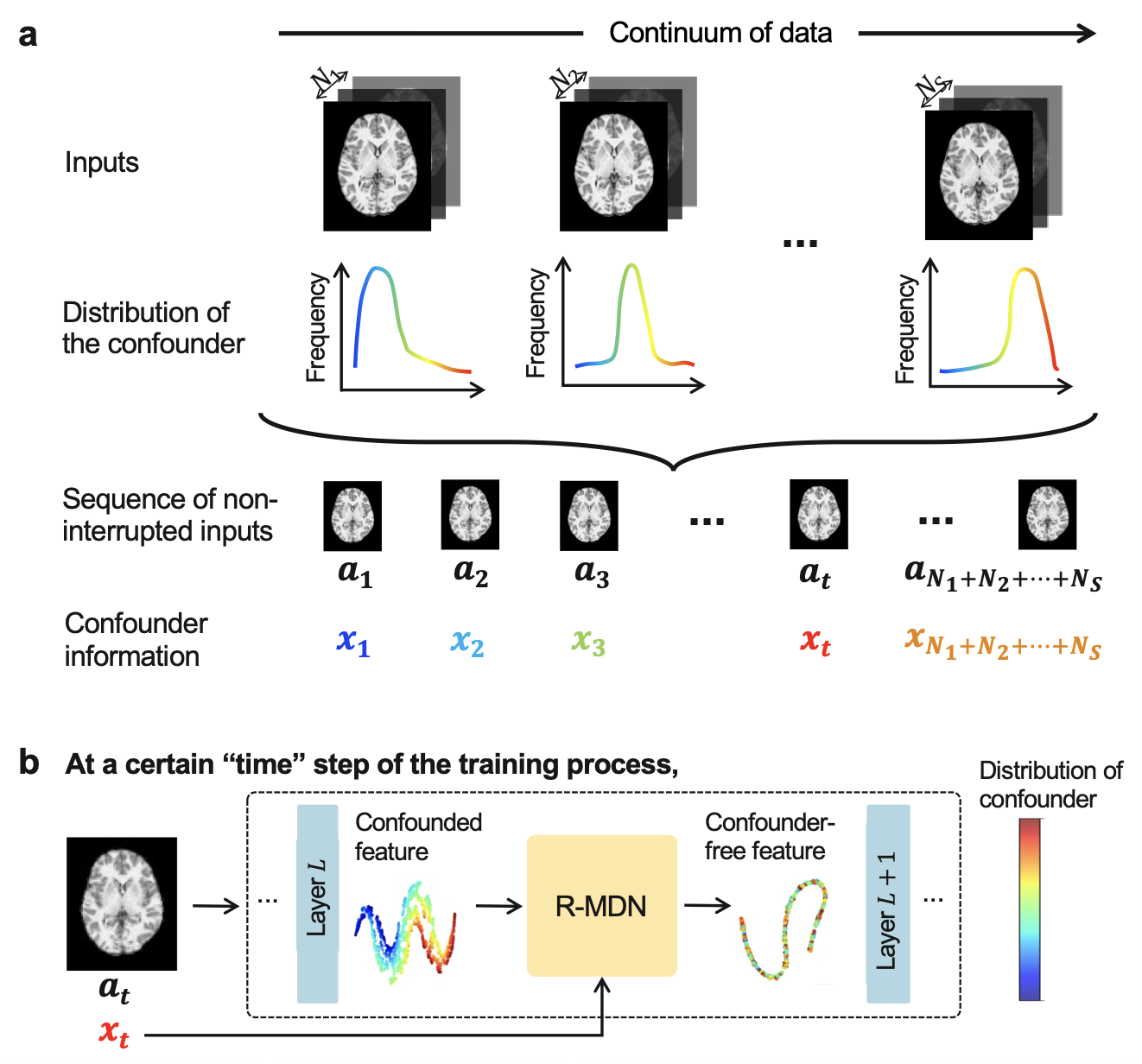
Contact: {ynshah,eadeli}@stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: deep neural networks, confounders, continual learning, invariant representations, statistical regression
Cost-efficient Collaboration between On-device and Cloud Language Models
Contact: avanikan@stanford.edu
Workshop: Main Conference
Links: Paper | Blog Post | Video | Website
Keywords: local-remote collaboration, edge ai, on-device ai, edge-cloud hybrid systems
Gaussian Mixture Flow Matching Models
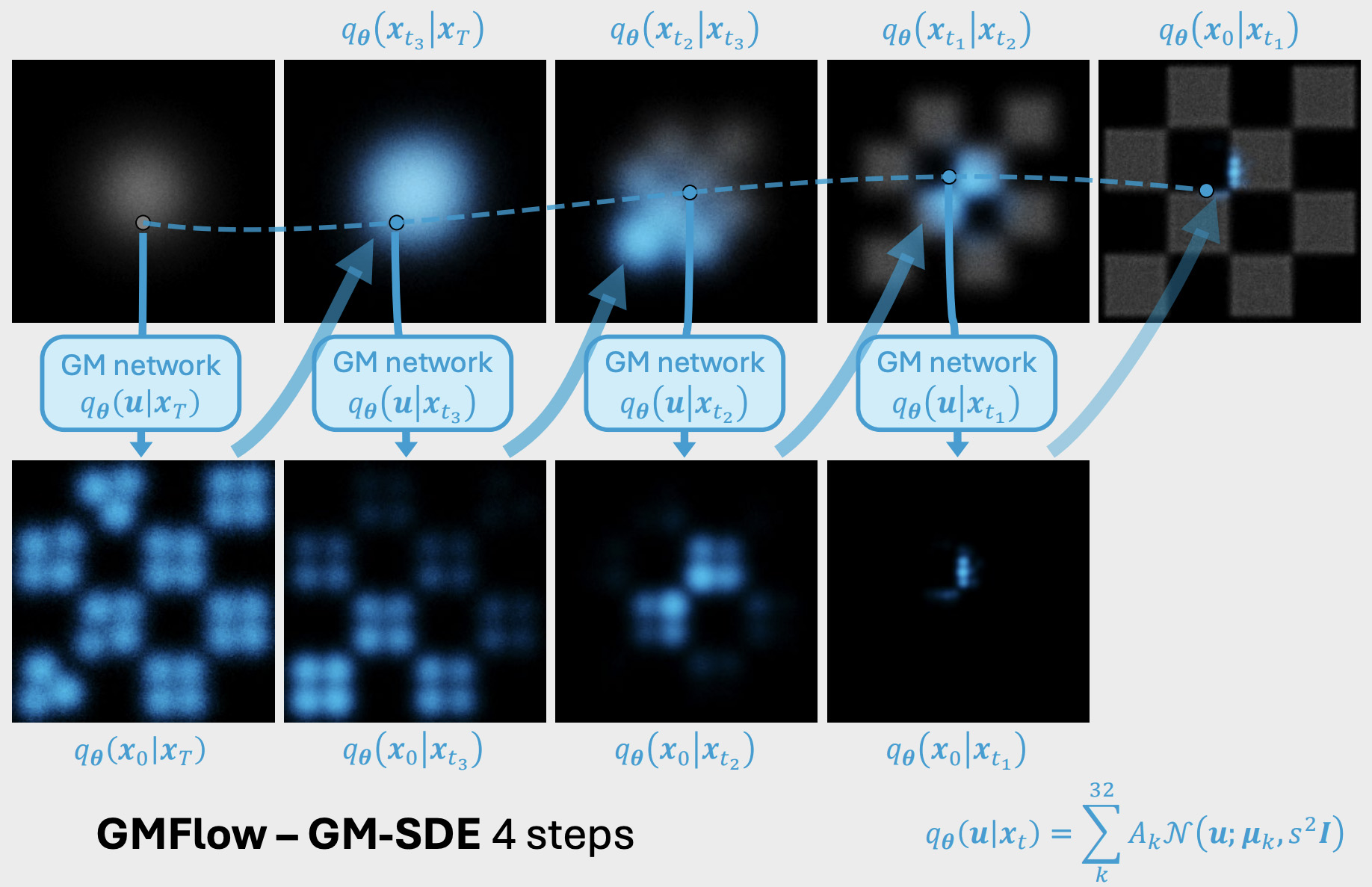
Contact: hanshengchen@stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: diffusion models
Geometric Algebra Planes: Convex Implicit Neural Volumes
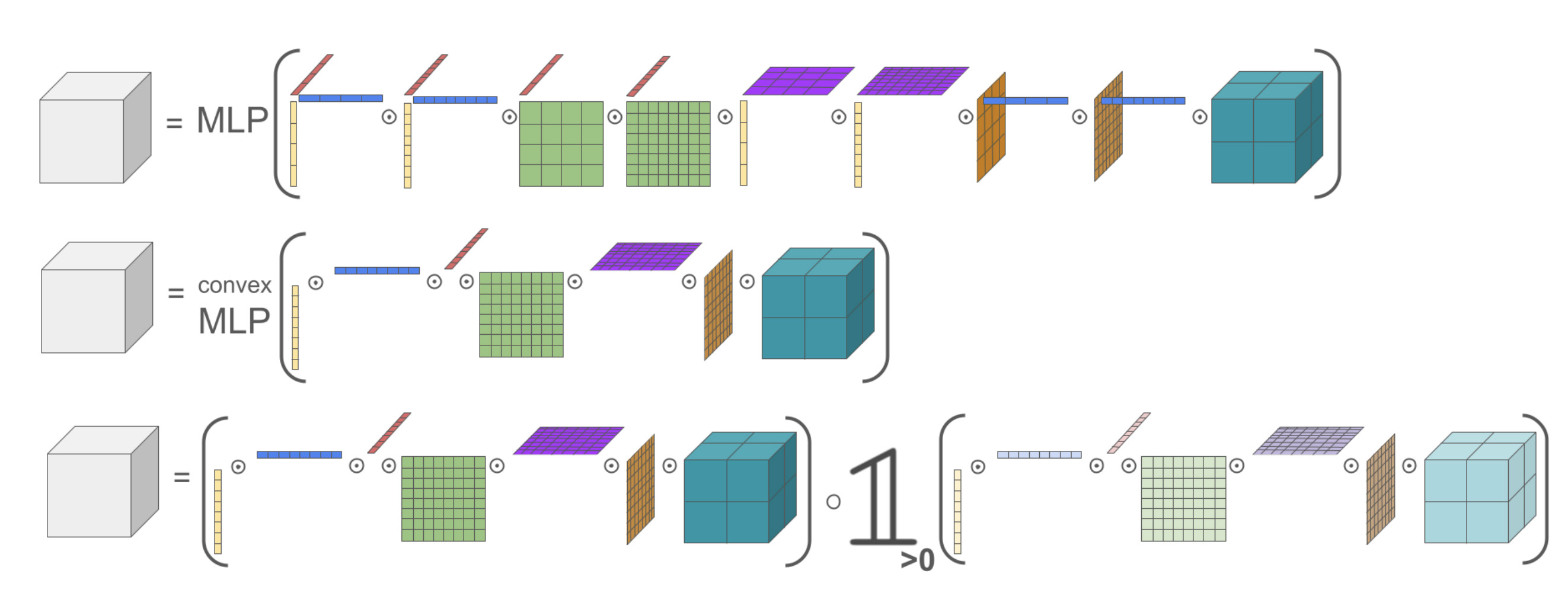
Contact: gordon.wetzstein@stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: representation learning
Geometric Generative Modeling with Noise-Conditioned Graph Networks
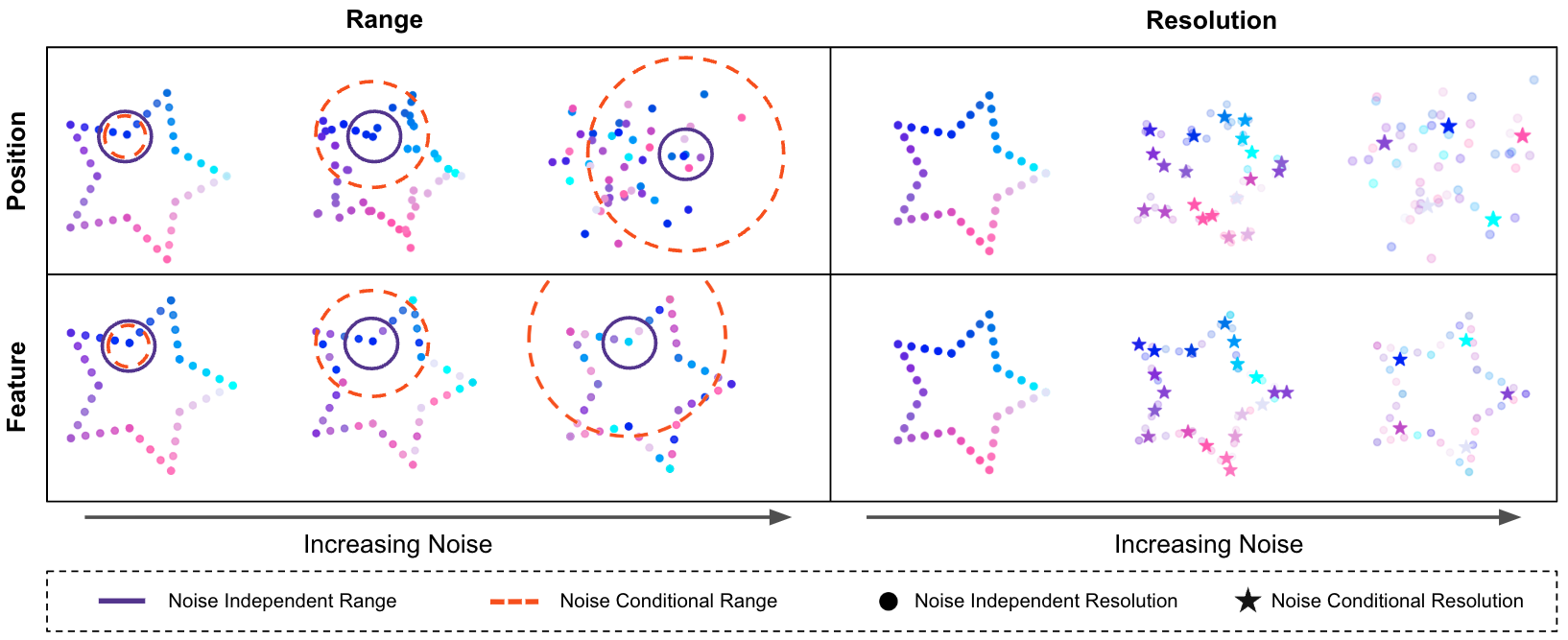
Contact: peterph@cs.stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: graph neural networks,generative models,diffusion models,flow-matching
How Do Large Language Monkeys Get Their Power (Laws)?
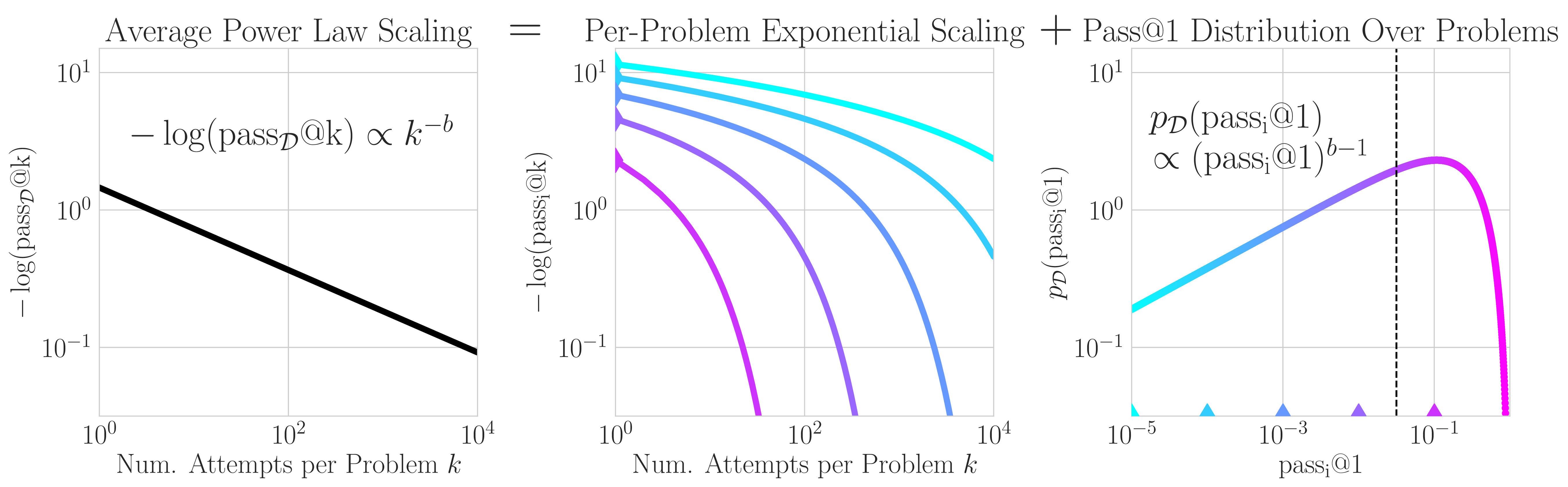
Contact: rschaef@cs.stanford.edu
Workshop: Main Conference
Award nominations: Oral
Links: Paper
Keywords: scaling laws, inference compute, scaling inference compute, test-time compute, scaling test-time compute, language models, evaluations, scaling-predictable evaluations,machine learning, icml
Independence Tests for Language Models
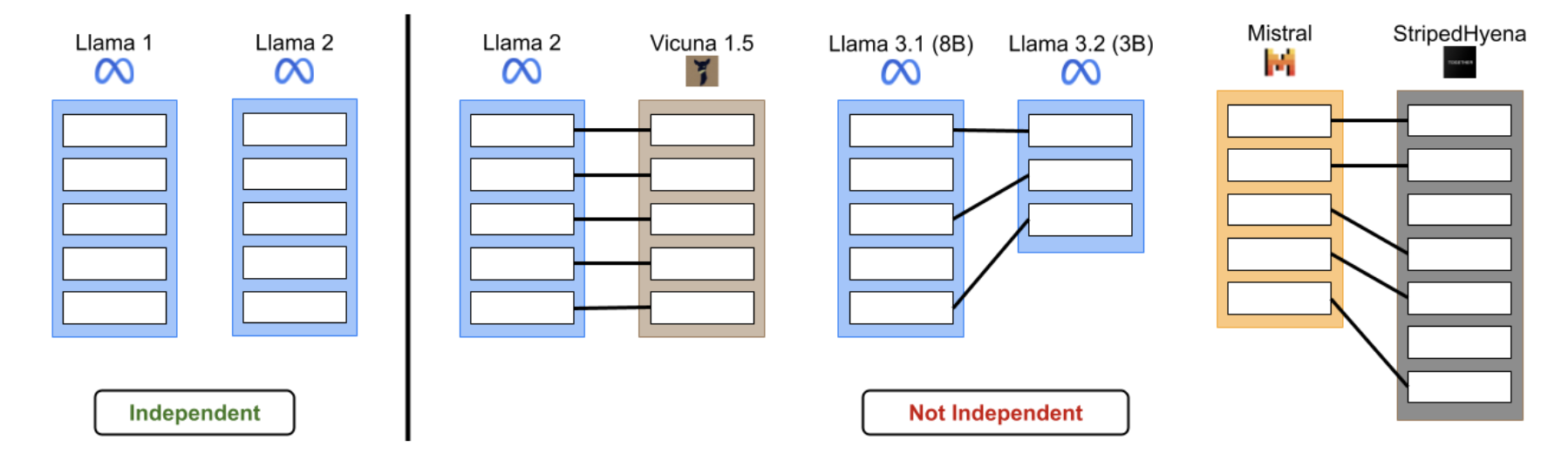
Contact: salzhu@stanford.edu
Workshop: Main Conference
Award nominations: Spotlight
Links: Paper
Keywords: model provenance, language models
Internal Causal Mechanisms Robustly Predict Language Model Out-of-Distribution Behaviors
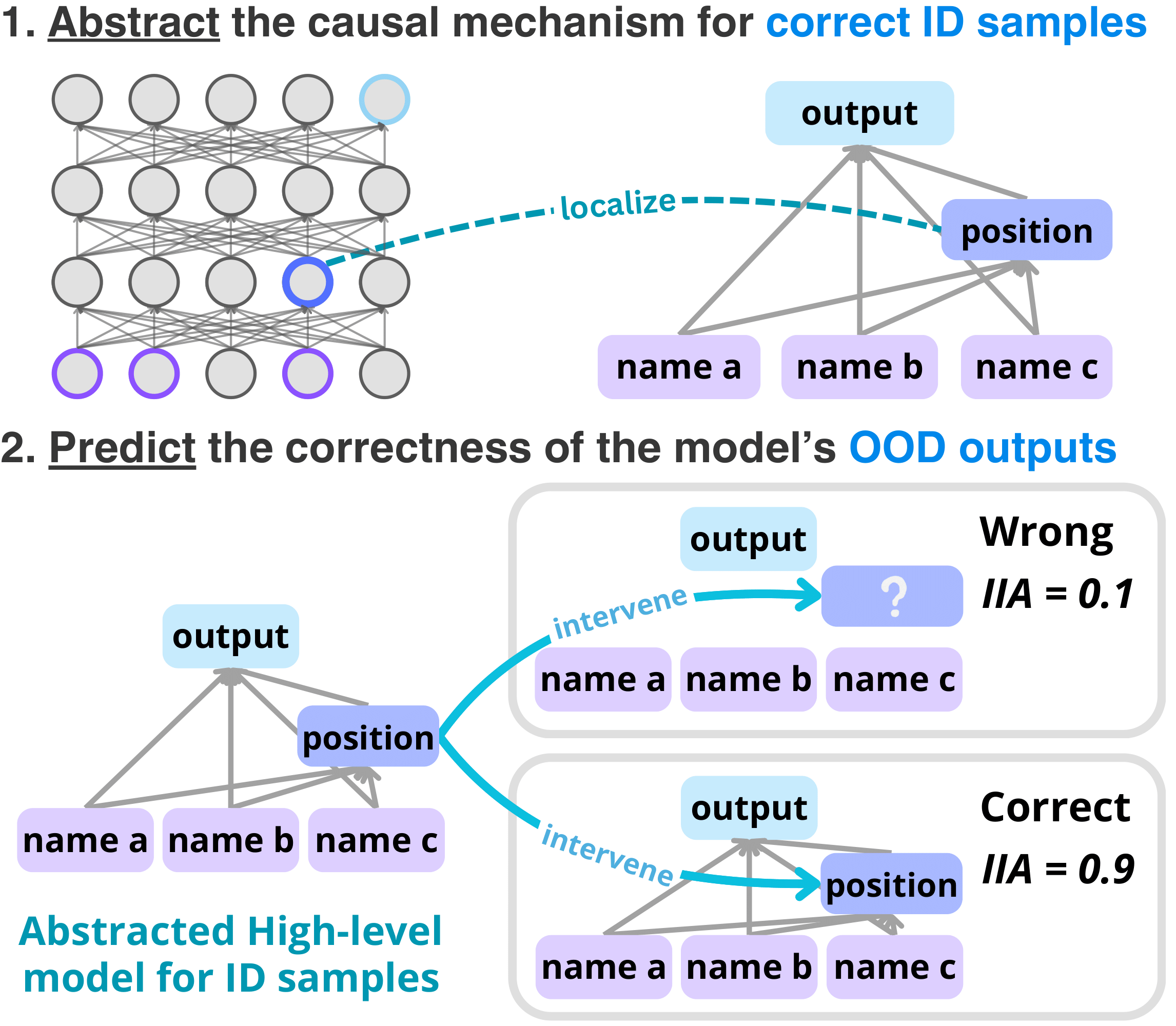
Contact: hij@stanford.edu
Workshop: Main Conference, Workshop
Links: Paper
Keywords: causal abstraction, causal interpretability, ood, correctness prediction
KernelBench: Can LLMs Write Efficient GPU Kernels?

Contact: simonguo@stanford.edu
Workshop: Main Conference
Links: Paper | Blog Post | Website
Keywords: benchmark, gpu kernel design, code generation
PhD Student

Contact: amberxie@stasnford.edu
Workshop: Main Conference
Award nominations: Spotlight Poster
Links: Paper | Website
Keywords: imitation learning, diffusion, planning, robotics
RBench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
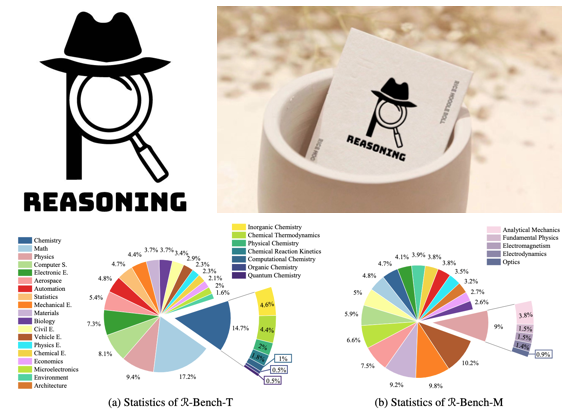
Contact: gordon.wetzstein@stanford.edu
Workshop: Main Conference
Links: Paper | Website
Keywords: benchmark
Recommendations and Reporting Checklist for Rigorous & Transparent Human Baselines in Model Evaluations
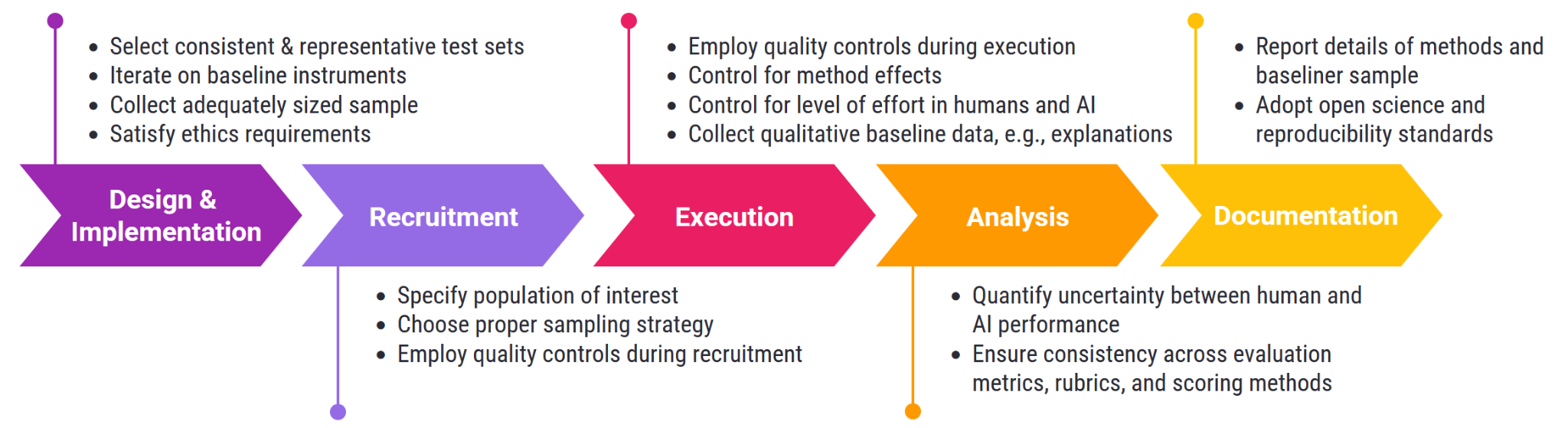
Contact: kevinwei@acm.org, anka.reuel@stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: human baselines, evaluation, ai, governance
RelGNN: Composite Message Passing for Relational Deep Learning

Contact: chentl@stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: gnn, relational deep learning
Shrinking the Generation-Verification Gap with Weak Verifiers
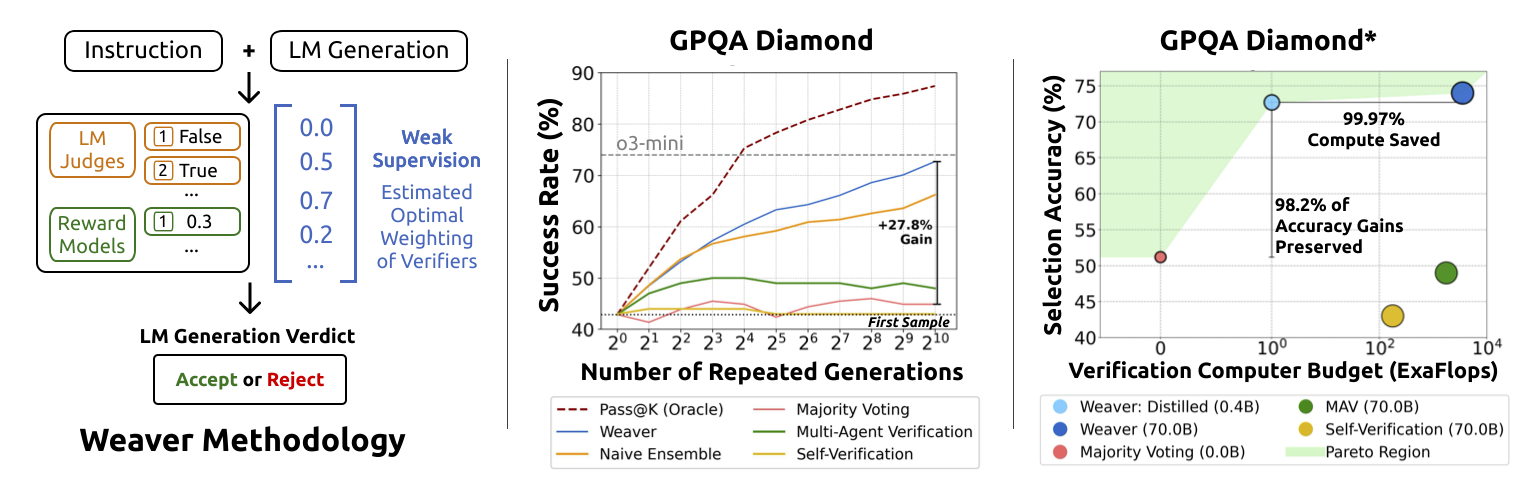
Contact: jonsaadfalcon@gmail.com
Workshop: Workshop
Links: Paper | Blog Post | Website
Keywords: test-time compute, repeated sampling, weak supervision, weak verification
TAROT: Targeted Data Selection via Optimal Transport
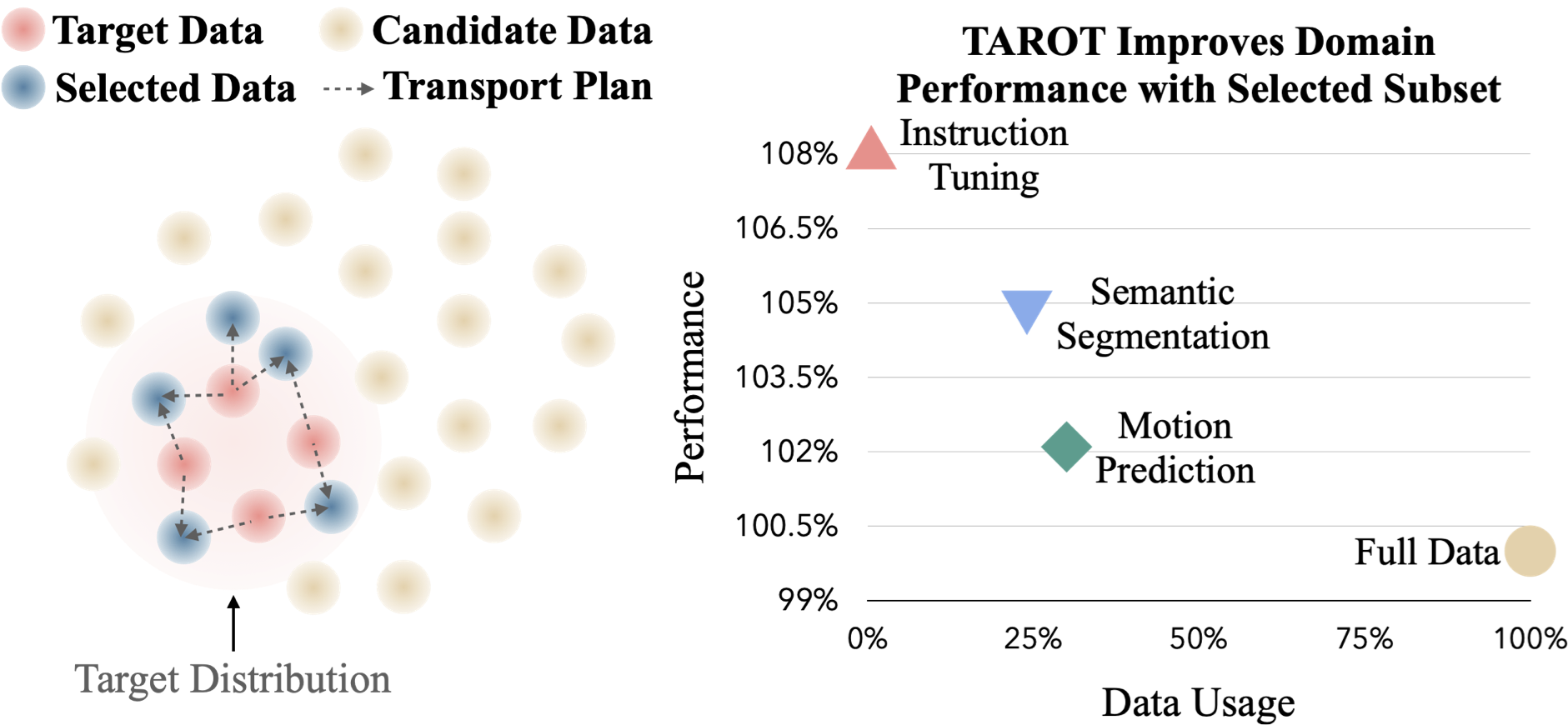
Contact: yuejiang.liu@stanford.edu
Workshop: Main Conference
Links: Paper | Blog Post
Keywords: data selection, optimal transport, data attribution
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?

Contact: rschaef@cs.stanford.edu
Workshop: Main Conference
Links: Paper
Keywords: evaluations, benchmarks, scaling laws, emergent abilities, capabilities, frontier models, foundation models, machine learning, icml
We look forward to seeing you at ICML 2025!