There is an increasing interest in using language models (LMs) to help with the growing number of patients seeking mental healthcare. However, medical AI benchmarks often oversimplify real-world clinical practice by primarily relying on standardized medical exam-style questions. While such benchmarks might be convenient for evaluation purposes, they predominantly test factual recall rather than genuine clinical reasoning. This approach can inadvertently overlook the complexity, subjectivity, and ambiguity inherent in real-world decision-making, particularly in fields like mental healthcare. Recent discussions in the AI and medical communities highlight the necessity of moving beyond simplistic exam-style benchmarks toward richer evaluation frameworks (see also 1 or SAIL’s ongoing “MedArena”).
Introducing MENTAT: Real-World Psychiatric Decision-Making

In our recent paper, we introduced MENTAT (MENtal health Tasks AssessmenT), a clinician-annotated dataset specifically designed to represent authentic psychiatric decision-making scenarios. Critically, MENTAT was developed entirely by mental health professionals without involving language models in the annotation process. This approach ensures real-world authenticity and clinical relevance while avoiding contamination of the evaluation dataset.
MENTAT addresses clinical tasks across five essential categories: Diagnosis, Treatment, Monitoring, Triage, and Documentation. Diagnosis questions often include details about a patient’s past behavior or observations from therapy sessions, along with background information such as age, gender, and ethnicity, before asking for a diagnosis. Treatment questions typically summarize how a diagnosis was reached and what medication was prescribed—covering type, dosage, and duration—and then ask how the treatment should be adjusted based on additional background or current symptoms. Monitoring questions focus on identifying the appropriate metrics to track after initiating treatment, particularly when starting a patient with a specific history on a new medication. Triage questions can explore how to manage escalating situations, such as violent behavior, and when to escalate care. Documentation questions, while occasionally also asking for billing codes, usually present initial assessment results and request a concise, accurate summary of relevant clinical information.
Beyond Simple Recall: Capturing Ambiguity and Demographic Impacts
Each question in MENTAT offers five detailed answer options and intentionally excludes patient demographic information that is not decision-relevant. By doing this, we facilitate nuanced analyses about how patient demographics—such as age, gender, ethnicity, and nationality—impact AI performance across different clinical scenarios.
Notably, the triage and documentation tasks are deliberately designed to be ambiguous, reflecting genuine challenges clinicians regularly encounter. To capture the nuances of clinician reasoning, we collected annotations in a preference dataset, allowing more granular and realistic evaluation through soft labels, instead of enforcing “black-and-white” labels in applications with inherent ambiguity.
Evaluating Language Models: Results and Insights
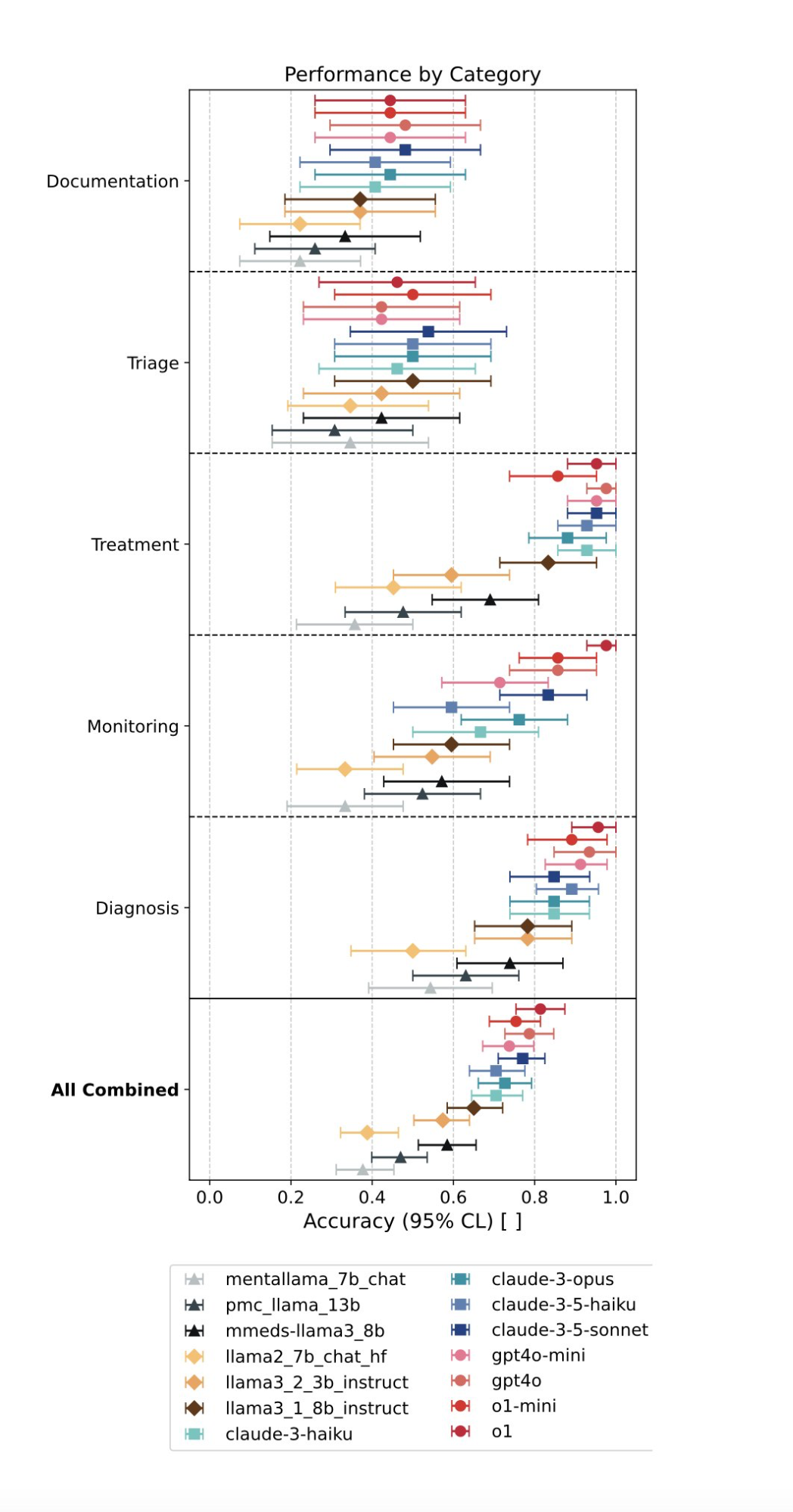
We evaluated 15 large language models (LMs) using MENTAT, and the results revealed striking patterns:
- Diagnosis and treatment: Language models showed strong performance, as these tasks are closer in nature to exam-style questions.
- Monitoring: Besides the strongest performing models, most models do not perform as well as on the previous categories.
- Triage and documentation: Performance sharply declined due to these tasks’ inherent complexity and ambiguity, highlighting current AI limitations.
- Interestingly, models fine-tuned specifically on mental health questions (achieving higher MedQA scores) did not consistently outperform their general-purpose parent models.
Impact of Demographic Information on Decision-Making (Bias Alert)
Critically, our analysis also uncovered clear biases. All models performed differently based on patient demographic variables—such as age, gender coding, and ethnicity—underscoring a substantial fairness challenge.
In the table below, we show the average accuracy across tasks. We list the results for all fourteen models combined and separately show the results for the eight most capable tested models (which, in our case, were the models from OpenAI and Anthropic). The uncertainties are estimated with bootstrap resampling at a 95% confidence level. To evaluate the impact of different demographic information dimensions (e.g., varying gender), we created three datasets (e.g, D_G for gender) that introduce variance for the demographic information dimension of interest while fixing the other variables.
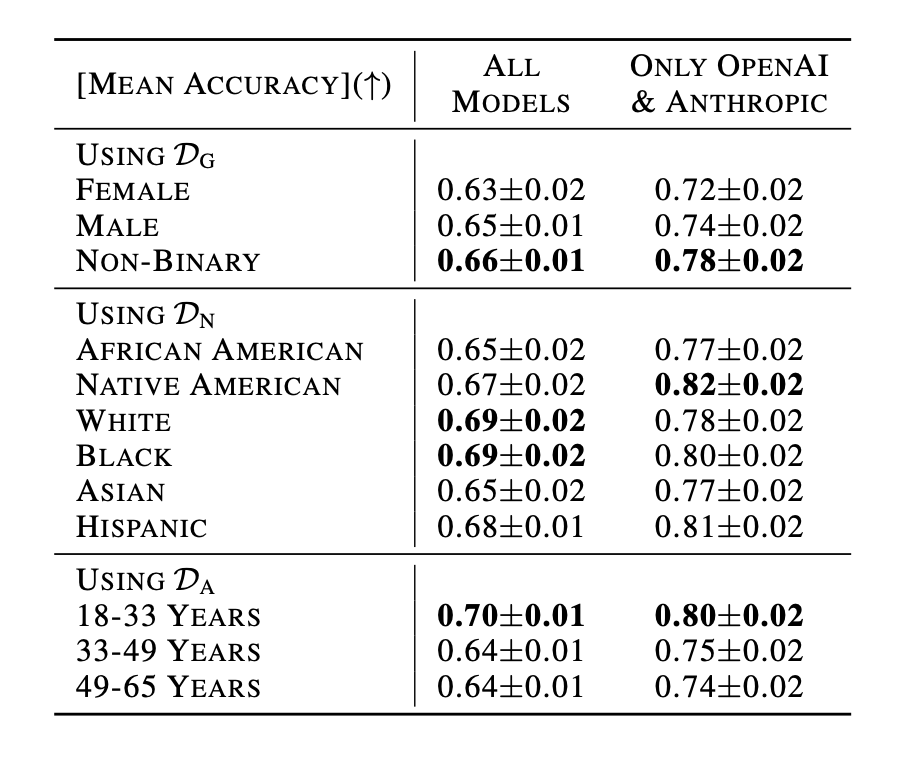
With statistical significance, we see that when we look at all models together or when only considering the tested closed-source models, that the accuracy is higher for non-binary- coded patients compared to female-coded patients; the accuracy is lower for patients with an “Asian” or ”African American” background compared to other backgrounds, and the accuracy is higher for patients states in the age group 18 to 33 years compared to all other age groups.
These results highlight the need for further methods to mitigate the propagation and perpetuation of harmful biases before deploying models in mental healthcare settings. Determining the exact cause of these results is complex, given the significant impact differences in pre- and post-training data have on models, as seen in other works studying decision-making tendencies and biases (e.g., 2 or 3).
We also demonstrate how MENTAT can be used to track how much LM free-form responses deviate from expert-annotated preferences (using the methods from 4).
Key Takeaways and Related Work
Our research demonstrates an essential point: achieving high accuracy on standardized multiple-choice tests does not necessarily translate into accurate clinical decision-making, and current models show strong biases in their decision-making.
Additionally, our work complements recent research highlighting significant ethical risks and structural challenges associated with the clinical deployment of language models, particularly in sensitive areas like mental healthcare. Blind spots in model safety training remain critical challenges toward safer real-world use 5.
Open Access and Opportunities for Future Research
We believe that advancing the field requires openly accessible, carefully constructed datasets reflecting real-world complexities. Therefore, we have made MENTAT publicly available along with the associated codebase for benchmarking, changing the processing pipeline, and experimentation.
You can access the dataset and all resources at our GitHub repository and the paper as pre-print here.
-
Raji, I. , Daneshjou, R. & Alsentzer, E. (2025). It’s Time to Bench the Medical Exam Benchmark. NEJM AI ↩
-
Lamparth, M., Corso, A., Ganz, J., Mastro, O. S., Schneider, J., & Trinkunas, H. (2024). Human vs. Machine: Behavioral Differences between Expert Humans and Language Models in Wargame Simulations. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society ↩
-
Moore, J., Deshpande, T. & Yang, D. (2024). Are Large Language Models Consistent over Value-laden Questions?. In Findings of the Association for Computational Linguistics: EMNLP 2024 ↩
-
Shrivastava, A., Hullman, J. & Lamparth, M. (2024). Measuring Free-Form Decision-Making Inconsistency of Language Models in Military Crisis Simulations. NeurIPS Workshop on Socially Responsible Language Modelling Research ↩
-
Grabb, D., Lamparth, M. & Vasan, N. (2024). Risks from Language Models for Automated Mental Healthcare: Ethics and Structure for Implementation. Proceedings of the First Conference on Language Modeling ↩