Recently Vision-Language-Action (VLA) models have seen widespread adoption in the field of robotics. OpenVLA1 is currently the best open-source model, but its 7 billion parameter count makes both training and inference very slow. Furthermore, the OpenVLA input (image) and output (action) spaces could benefit from advancements we’ve seen in smaller policy classes.
In this post, we introduce MiniVLA, which reduces the footprint of OpenVLA from 7B to just 1B parameters. We also introduce several improvements to the input and output representations of the model that help boost performance on a popular simulation benchmark, Libero-90, from 62% to 82% even with a 7x smaller model.
TLDR; Our main improvements:
- MiniVLA: 7x smaller model!
- Action chunking using Vector Quantization
- Multi-image support (wrist and image history)
Our full codebase and instructions can be found here.
All models discussed in this post can be found here.
Background on OpenVLA
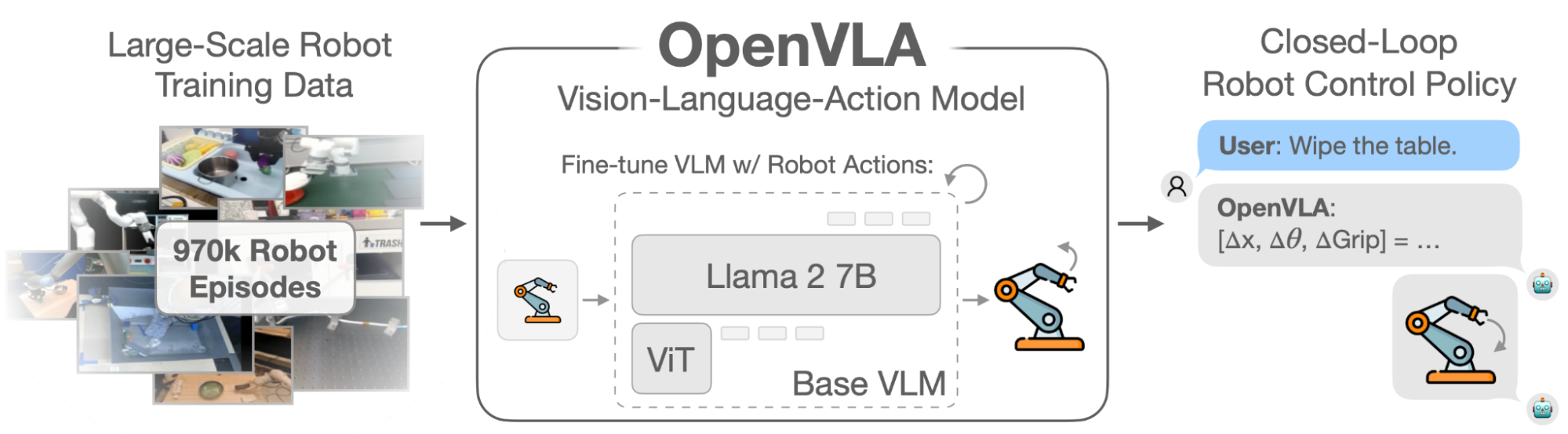
OpenVLA is built on top of Prismatic Vision Language Models (VLMs)2, specifically using a fused Vision Transformer (ViT) encoder to generate image tokens, along with a Llama 2 7B backbone for processing the image tokens and language task input. OpenVLA trains this model to predict actions as outputs, given an image of the scene and an instruction described in language as inputs. An action is a command provided to the robot at each time step (e.g., how much to move the robot arm). These models operate in a closed loop, meaning after each action is executed on the robot, we pass the new image and original language task to the model to get a brand new action, and so on until the task is complete.
MiniVLA: Leveraging a smaller LLM backbone
MiniVLA uses a Qwen 2.5 0.5B backbone while retaining the same ViT as OpenVLA for visual encoding. This leads to a total parameter count of around 1B. Our model is similar in architecture to EVLA3, but we offer more thorough benchmarking and other improvements like action chunking and multi-image support. We train this transformer backbone using the Llava-1.5-Instruct Visual Question Answering (VQA) dataset, the same dataset used for training the base Prismatic VLM in OpenVLA. Below we can see that validation accuracy (higher is better) drops minorly for these VQA datasets:
| VQAv2 | GQA | VizWiz | TextVQA+OCR | TextVQA | VSR | POPE | |
|---|---|---|---|---|---|---|---|
| Prism 224px Llama 7B | 78.11 | 62.5 | 49.82 | 54.70 | 42.70 | 55.2 | 87.6 |
| Prism 224px Qwen25-0.5B | 71.73 | 56.64 | 49.39 | 39.8 | 33.8 | 48.5 | 87.6 |
Both VizWiz and VQAv2 assess general visual reasoning. VizWiz also contains a series of unanswerable questions. GQA and VSR evaluate spatial reasoning, while TextVQA assesses reasoning around text. POPE tests the hallucinations in our model. We do notice a drop for the TextVQA tasks, but overall performance is still good for our base VLM.
This Qwen-based Prismatic VLM can be found here.
Next we train MiniVLA based on this Prism base VLM on LIBERO-90. We report rollout task success rates in simulation (higher is better) averaged across the 90 tasks below:
| Trained to 95% Action Accuracy | Libero 90 |
|---|---|
| OpenVLA | 62% |
| MiniVLA | 61.4% |
We see that when trained on Libero-904, there is no significant difference in performance between each model.
Importantly, we also find that on a single NVIDIA L40s, MiniVLA inference is 2.5x faster than OpenVLA (12.5Hz vs 5Hz). Next, we will outline some of the other major changes we make for the OpenVLA and MiniVLA models in their output and input spaces.
Using Vector Quantized Action Chunking for outputs
One major design choice for VLAs is how we turn continuous actions into discrete action tokens. OpenVLA and other works use a simple binning scheme, where each dimension of the action (usually 7 total dimensions) is binned within some minimum and maximum value into N bins (usually 256 bins). Then, we can convert these bin indices into tokens for the LLM to output. The simplest version used in OpenVLA overwrites the least frequently used N tokens of the vocabulary to represent these N bins.
Many recent works in Imitation Learning like Diffusion Policy (DP) and Action Chunking Transformer (ACT) have benefited from predicting chunks of actions instead of just single actions. But predicting a full action sequence makes inference even slower, which we want to avoid!
There we introduce Vector Quantized Action Chunking for VLAs:
1) We utilize the VQ-BeT5 implementation of Residual VQ networks to encode a chunk of actions into a series of M codeword indices.
2) We include the option to add extra tokens to the vocabulary to represent these codewords.
Code for training these VQ’s can be found in our codebase as well, and it works with both OpenVLA and MiniVLA. We see a big difference with VQ action chunking on Libero-90, once again comparing success rates of rolling out each model in simulation:
| Model (Final Action Accuracy) | Libero 90 |
|---|---|
| OpenVLA (95%) | 62% |
| MiniVLA (95%) | 61.4% |
| + VQ h8 (action chunks) (85%) | 77% |
| + VQ h1 (single action) (95%) | 62.4% |
Interestingly, using a VQ trained on just a single time step (VQ h1 single action in the table) has barely any effect over the base MiniVLA or OpenVLA, providing even more evidence for the importance of action chunking.
We also train MiniVLA with VQ action chunking on the Bridge V2 Dataset6, a much larger dataset consisting of real world demonstration data. We evaluate this model on a few Simpler Env7 tasks, which are simulated tasks designed to be close to the real world tasks. Below we show the success rates for rolling out MiniVLA in Simpler Env:
| Model (Final Action Accuracy) | Place carrot | Place spoon | Block stack | Pick eggplant |
|---|---|---|---|---|
| OpenVLA (95%) | 46% | 44% | 62% | 66% |
| MiniVLA + VQ h8 (action chunks) (80%) | 44% | 68% | 70% | 14% |
We find that MiniVLA with VQ action chunking matches or surpasses OpenVLA in success rates in 3 / 4 tasks, but performs worse in 1 / 4 tasks, despite being 7x smaller.
Adding multi-image support to inputs
A key limitation of OpenVLA is that it is trained on a single image. However, in many prior works, we have seen large gains from using image history or incorporating wrist images8.
Thus we add support for both history and wrist images into OpenVLA. We see that on top of the VQ action chunking above, adding either wrist images or history=2 yields a 5% improvement in task success rates:
| Model | Libero 90 |
|---|---|
| OpenVLA | 62% |
| MiniVLA VQ h8 | 77% |
| + VQ h8 + history=2 | 82% |
| + VQ h8 + wrist images | 82.1% |
These results are quite close to the state-of-the-art performance on Libero 90, from Baku9.
Summary
We introduce MiniVLA, a lightweight version of OpenVLA with 7x fewer parameters but equal performance on Libero-90. We also introduce VQ action chunking and multi-image support to both OpenVLA and MiniVLA, noting substantial improvement over the base action tokenization scheme and single-image paradigm.
We are excited for the community to make use of these advancements in their own research!
Contact: belkhale@stanford.edu
BibTeX Citation
@misc{belkhale2024minivla,
title={MiniVLA: A Better VLA with a Smaller Footprint},
author={Suneel Belkhale and Dorsa Sadigh},
url={https://github.com/Stanford-ILIAD/openvla-mini},
year={2024},
}
-
Kim, Moo Jin, et al. “OpenVLA: An Open-Source Vision-Language-Action Model.” arXiv preprint arXiv:2406.09246 (2024). ↩
-
Karamcheti, Siddharth, et al. “Prismatic vlms: Investigating the design space of visually-conditioned language models.” arXiv preprint arXiv:2402.07865 (2024). ↩
-
Budzianowski, Paweł, et al. “EdgeVLA: Efficient Vision-Language-Action Models.” ↩
-
Liu, Bo, et al. “Libero: Benchmarking knowledge transfer for lifelong robot learning.” Advances in Neural Information Processing Systems 36 (2024). ↩
-
Lee, Seungjae, et al. “Behavior generation with latent actions.” arXiv preprint arXiv:2403.03181 (2024). ↩
-
Walke, Homer Rich, et al. “Bridgedata v2: A dataset for robot learning at scale.” Conference on Robot Learning. PMLR, 2023. ↩
-
Li, Xuanlin, et al. “Evaluating Real-World Robot Manipulation Policies in Simulation.” arXiv preprint arXiv:2405.05941 (2024). ↩
-
Team, Octo Model, et al. “Octo: An open-source generalist robot policy.” arXiv preprint arXiv:2405.12213 (2024). ↩
-
Haldar, Siddhant, Zhuoran Peng, and Lerrel Pinto. “BAKU: An Efficient Transformer for Multi-Task Policy Learning.” arXiv preprint arXiv:2406.07539 (2024). ↩