![]()
The thirty-sixth Conference on Neural Information Processing Systems (NeurIPS) 2022 is being hosted this week. We’re excited to share all the work from SAIL that’s being presented at the main conference, at the Datasets and Benchmarks track and the various workshops, and you’ll find links to papers, videos and blogs below.
Feel free to reach out to the contact authors and the workshop organizers directly to learn more about the work that’s happening at Stanford!
Main Conference
Learning Options via Compression
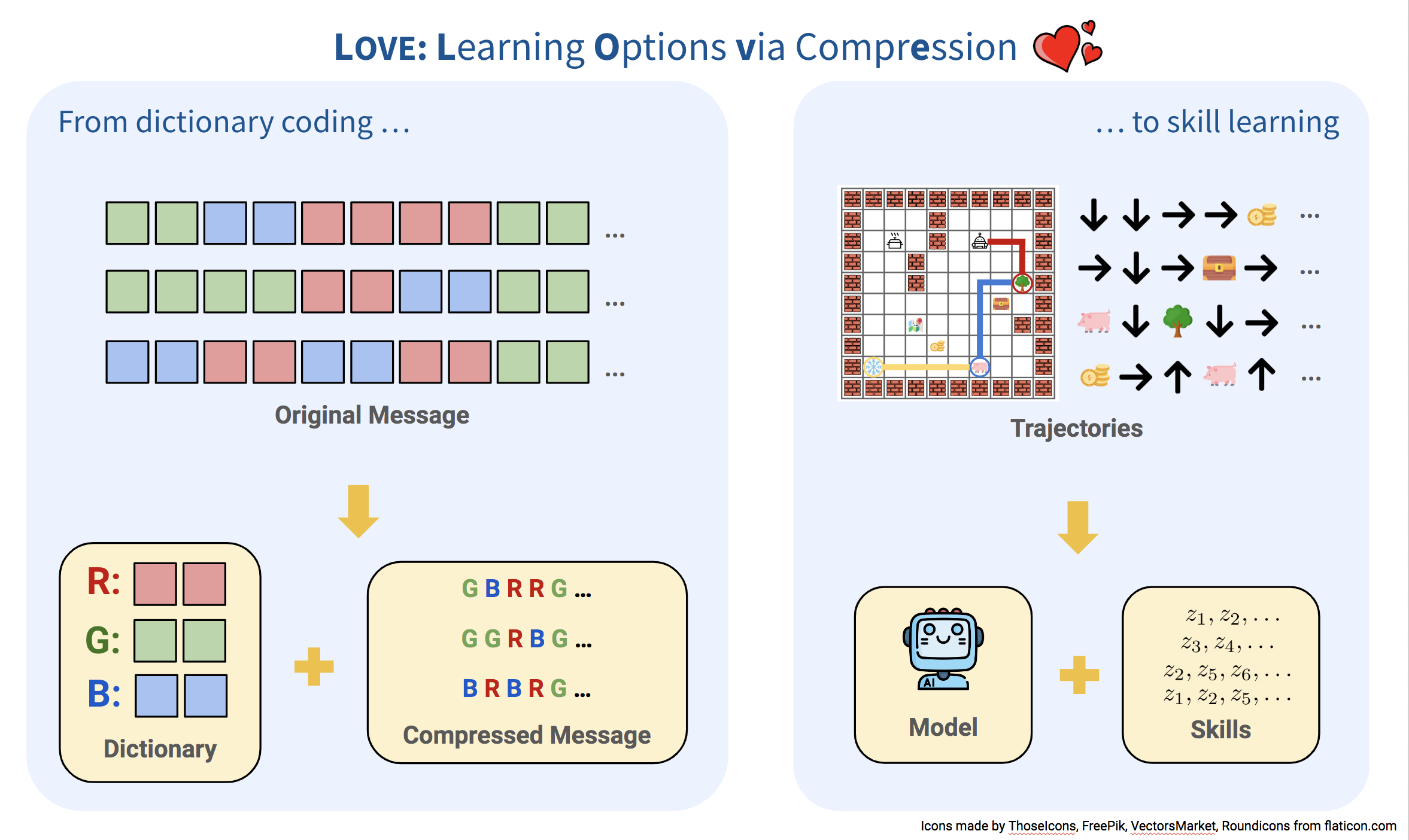
Contact: evanliu@cs.stanford.edu
Keywords: hierarchical reinforcement learning, skill learning
MABSplit: Faster Forest Training Using Multi-Armed Bandits
Contact: Motiwari@stanford.edu
Keywords: multi-armed bandits, random forests
Off-Policy Evaluation for Action-Dependent Non-stationary Environments
Contact: ychandak@stanford.edu
Keywords: non-stationarity, off-policy, reinforcement learning, counterfactual
A Fourier Approach to Mixture Learning
Contact: mqiao@stanford.edu
Links: Paper
Keywords: mixture learning, gaussian mixture models
A Nonconvex Framework for Structured Dynamic Covariance Recovery
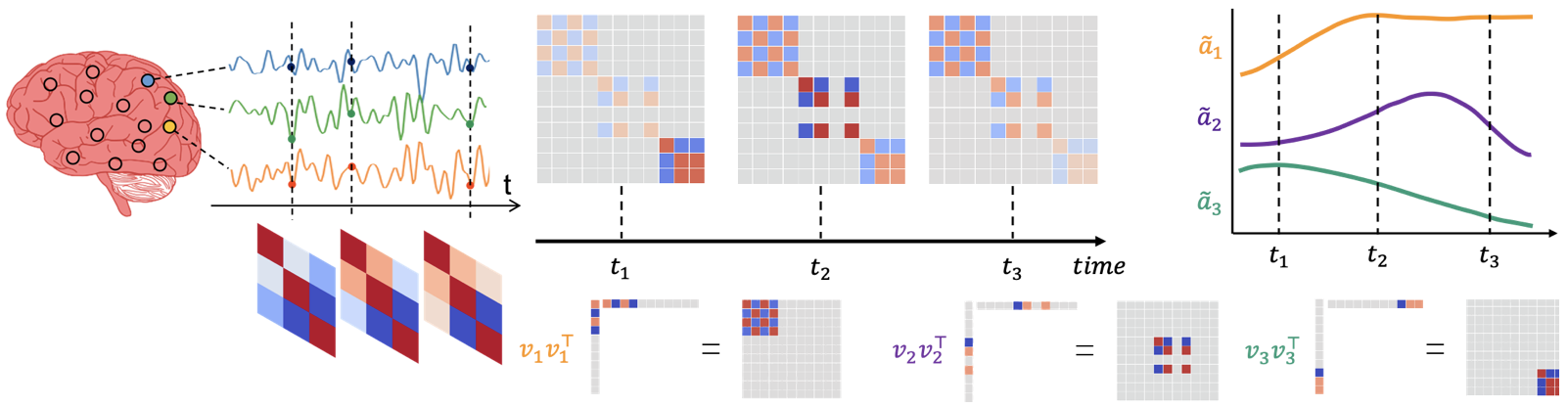
Contact: tsaikl@stanford.edu
Links: Paper
Keywords: dynamic covariance, structured factor model, alternating projected gradient descent, time series data, functional connectivity
Active Learning Helps Pretrained Models Learn the Intended Task
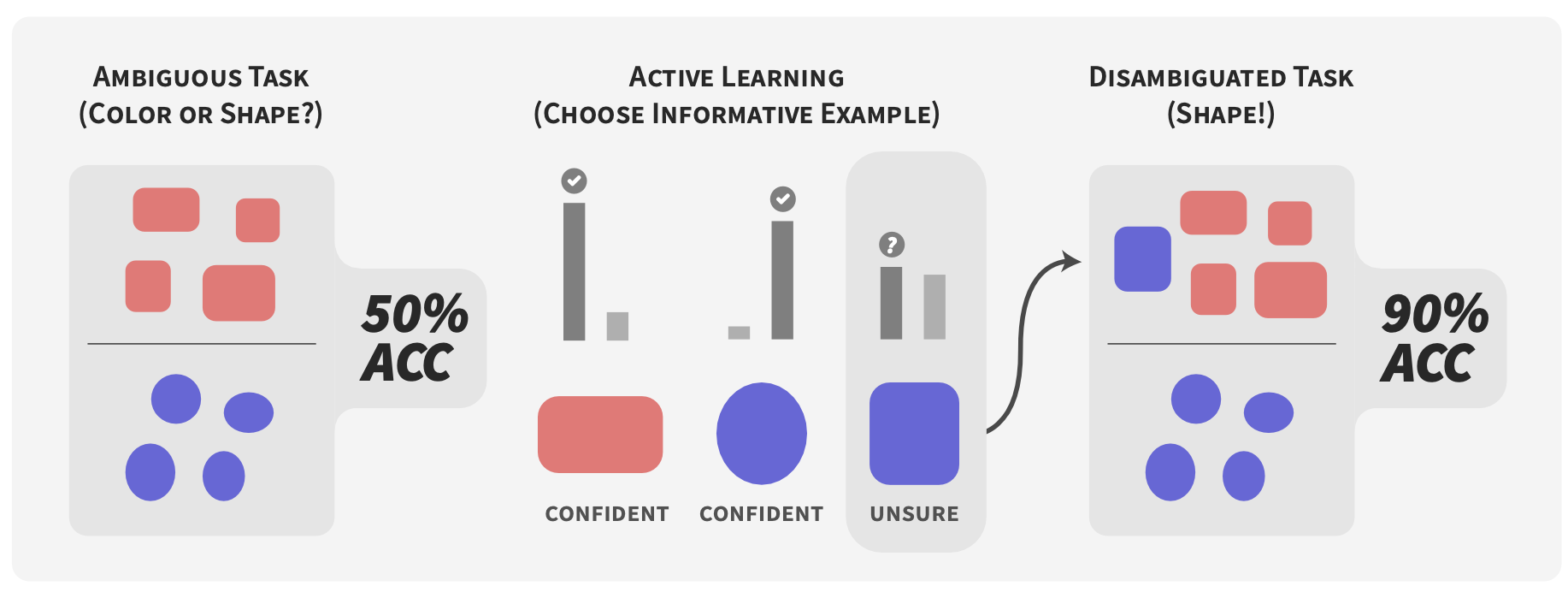
Contact: atamkin@stanford.edu
Links: Paper
Keywords: pretrained models, robustness, active learning, few shot learning
An Information-Theoretic Framework for Deep Learning
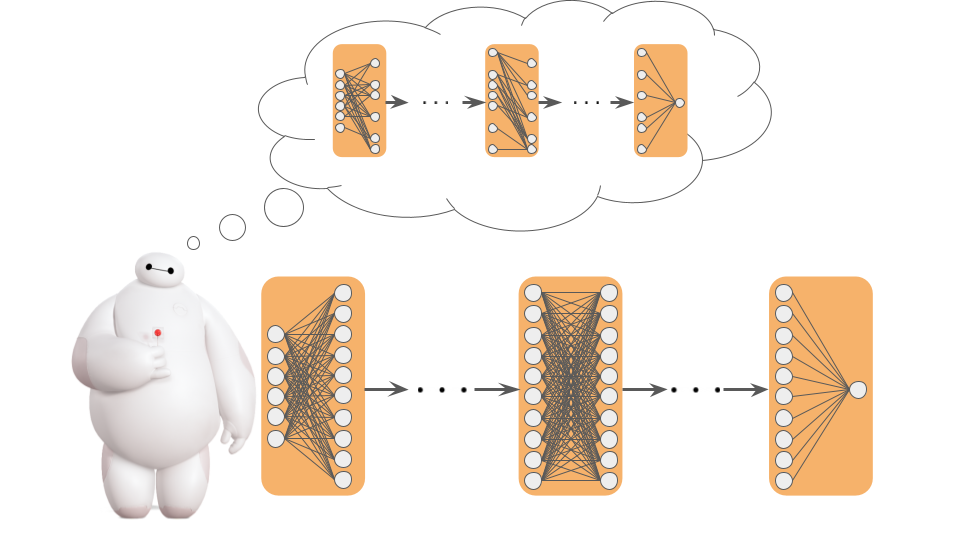
Contact: hjjeon@stanford.edu
Links: Paper
Keywords: information theory, deep learning, neural network theory
Assistive Teaching of Motor Control Tasks to Humans

Contact: meghas@stanford.edu
Links: Paper | Website
Keywords: human-ai interaction, education, reinforcement learning
Beyond Separability: Analyzing the Linear Transferability of Contrastive Representations to Related Subpopulations
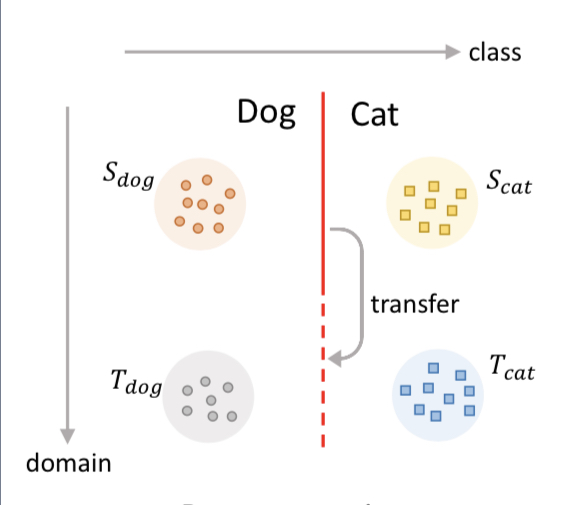
Contact: jhaochen@stanford.edu
Links: Paper
Keywords: self-supervised learning theory, deep learning theory
Beyond neural scaling laws: beating power law scaling via data pruning
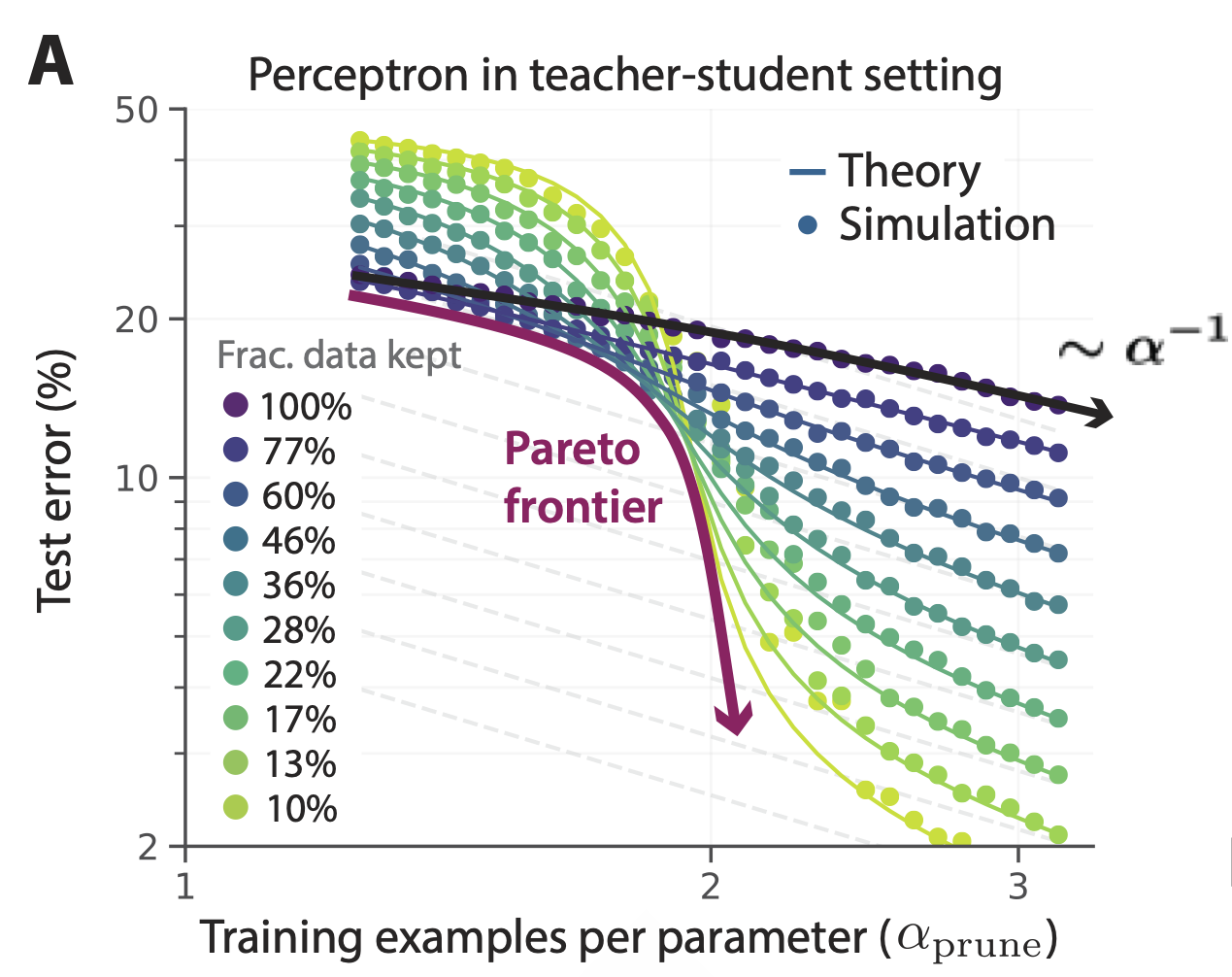
Contact: bsorsch@gmail.com
Award nominations: Best paper award
Links: Paper
Keywords: scaling laws, deep learning theory, data pruning, replica theory, active learning, data structure
CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior
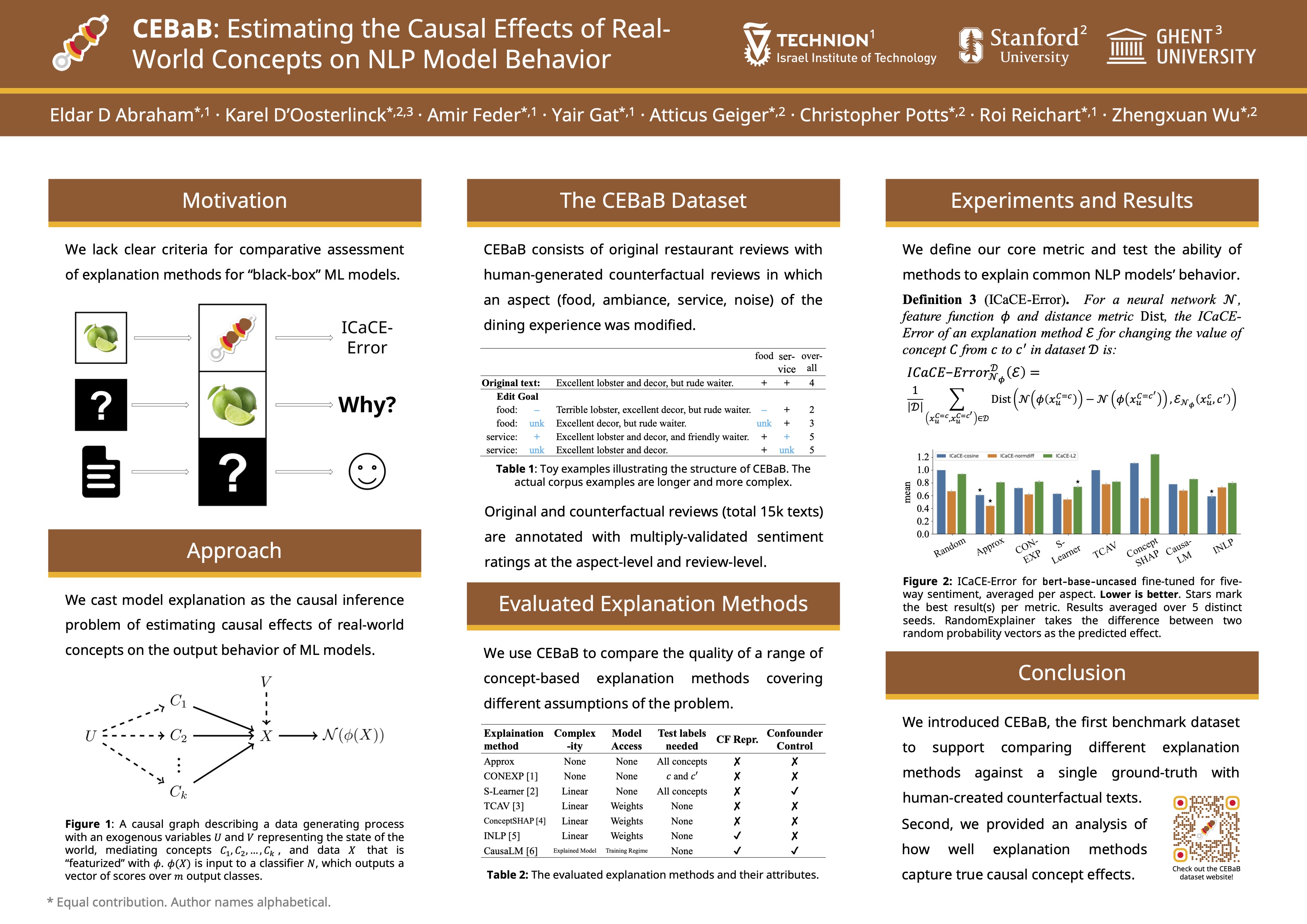
Contact: karel.doosterlinck@ugent.be
Links: Paper | Video | Website
Collaborative Decision Making Using Action Suggestions

Contact: asmar@stanford.edu
Links: Paper | Website
Keywords: collaboration, decision making, human-ai collaboration, pomdp, state estimation
Concrete Score Matching: Generalized Score Matching for Discrete Data
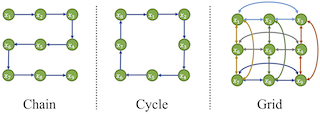
Contact: chenlin@stanford.edu
Links: Paper
Keywords: generative models, score matching, discrete data
Contrastive Adapters for Foundation Model Group Robustness
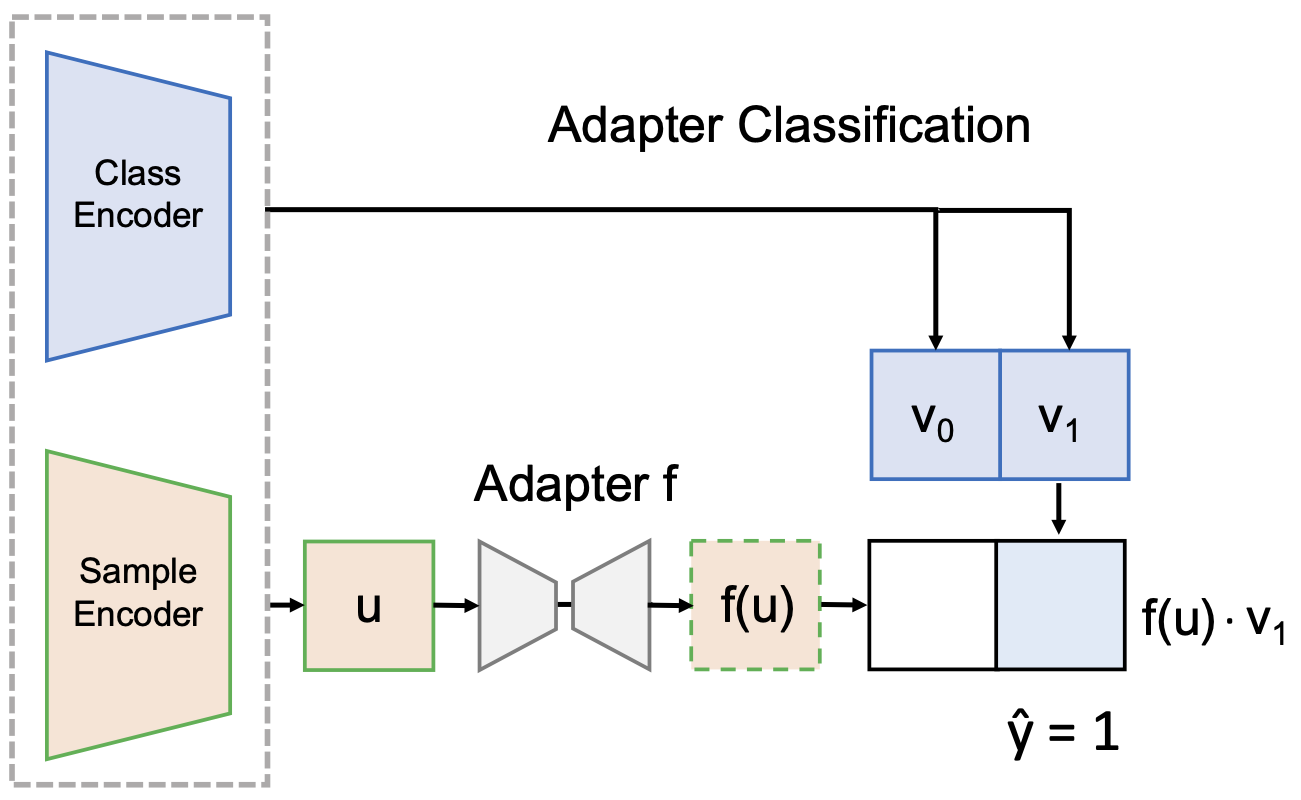
Contact: mzhang@cs.stanford.edu
Links: Paper
Keywords: foundation models, robustness, adaption, efficient
DRAGON: Deep Bidirectional Language-Knowledge Graph Pretraining
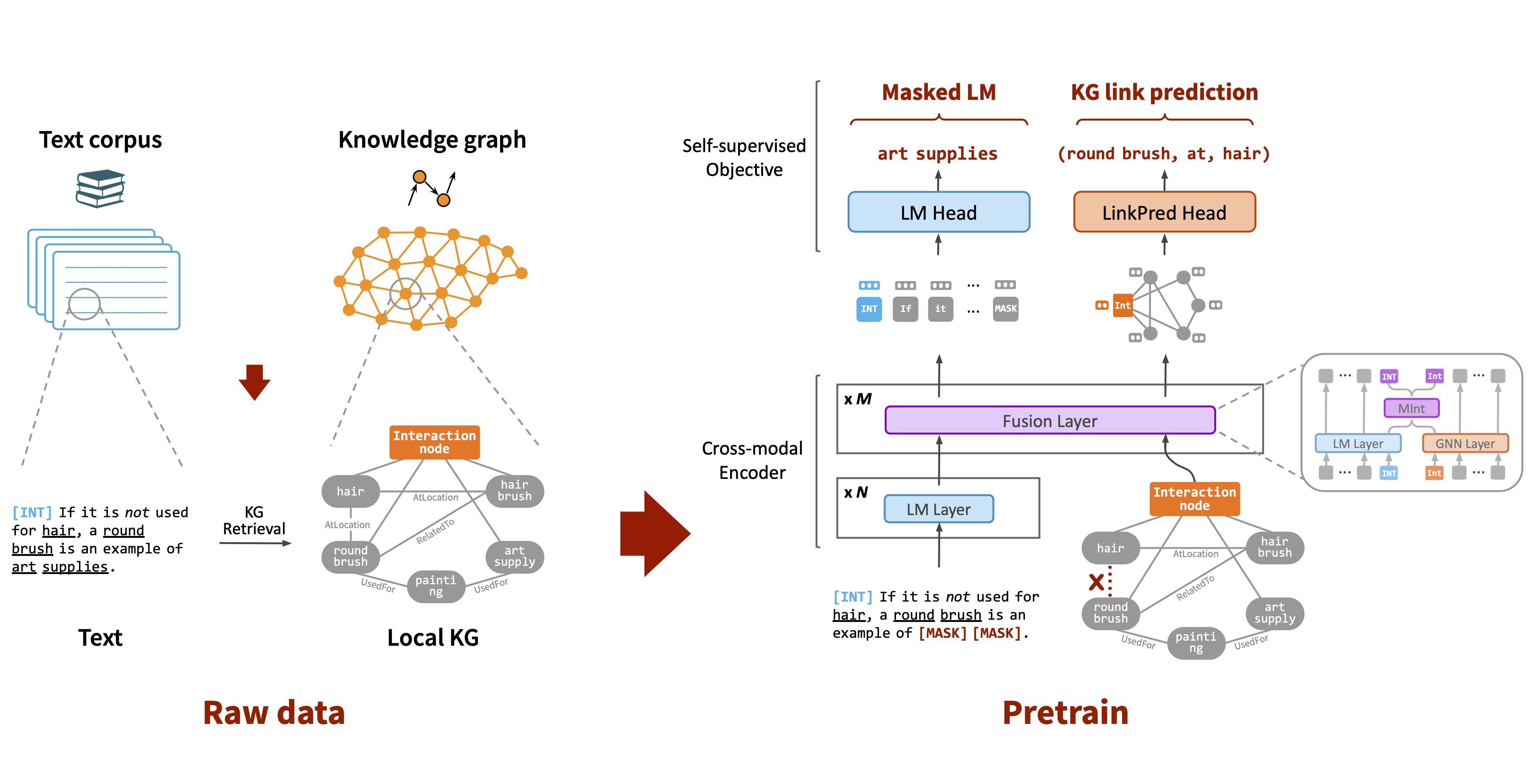
Contact: myasu@cs.stanford.edu
Links: Paper | Blog Post | Website
Keywords: pretraining, language model, knowledge graph, question answering, commonsense, reasoning, foundation model, self-supervised learning, biomedical
Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data
Contact: anie@stanford.edu
Links: Paper | Website
Keywords: offline rl, hyperparameter selection, data efficient, small data
Deciding What to Model: Value-Equivalent Sampling for Reinforcement Learning
Contact: dilip@cs.stanford.edu
Links: Paper
Keywords: reinforcement learning, efficient exploration, information theory, bayesian reinforcement learning, value equivalence
Denoising Diffusion Restoration Models
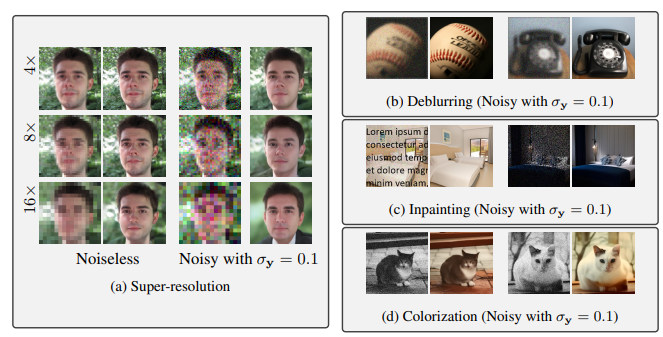
Contact: jiaming.tsong@gmail.com
Links: Paper | Website
Keywords: diffusion problems, inverse problems
Distinguishing discrete and continuous behavioral variability using warped autoregressive HMMs
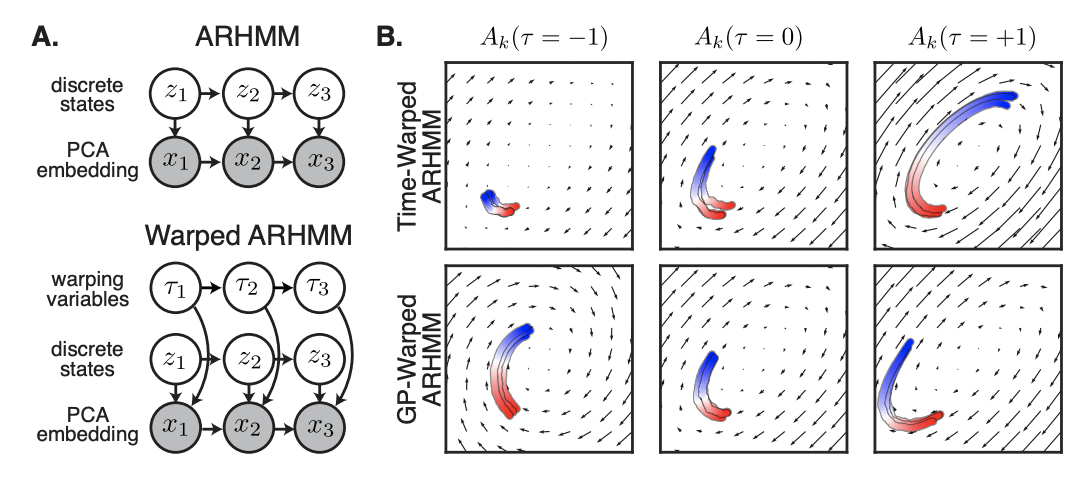
Contact: jcostac@stanford.edu
Links: Paper
Keywords: time series, markov models, naturalistic behavior, clustering
ELIGN: Expectation Alignment as a Multi-agent Intrinsic Reward
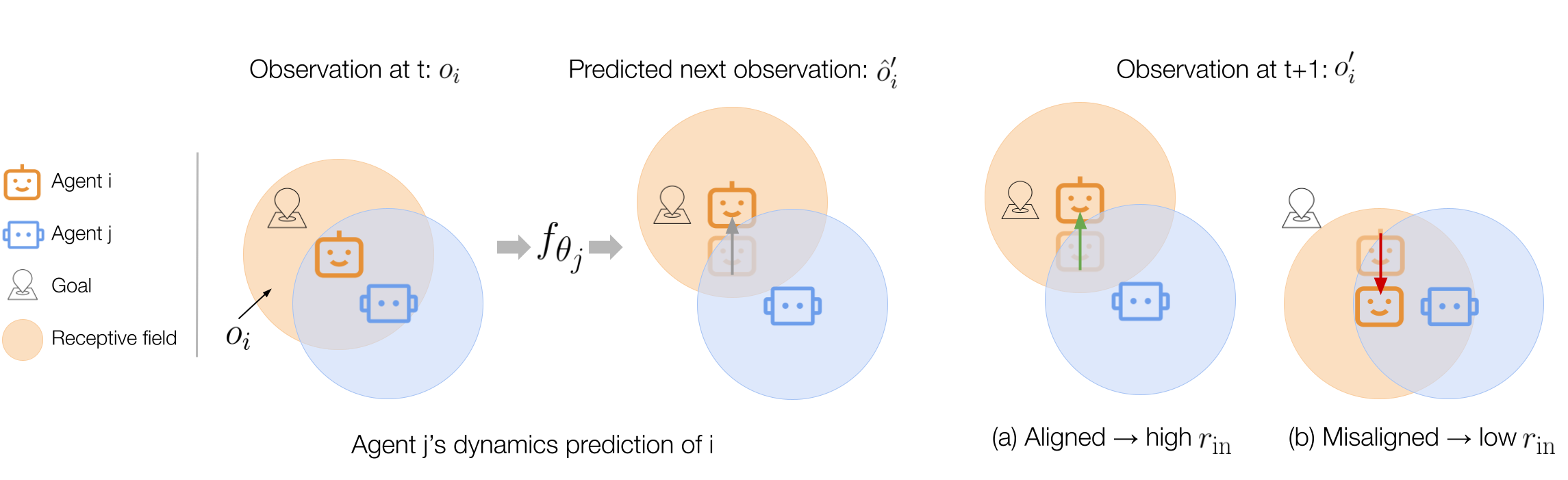
Contact: zixianma@cs.stanford.edu
Links: Paper
Keywords: multi-agent collaboration, intrinsic reward, reinforcement learning
Estimating and Explaining Model Performance When Both Covariates and Labels Shift

Contact: lingjiao@stanford.edu
Links: Paper | Website
Keywords: ml models, model deployment and monitoring, data distribution shift
Few-shot Relational Reasoning via Connection Subgraph Pretraining
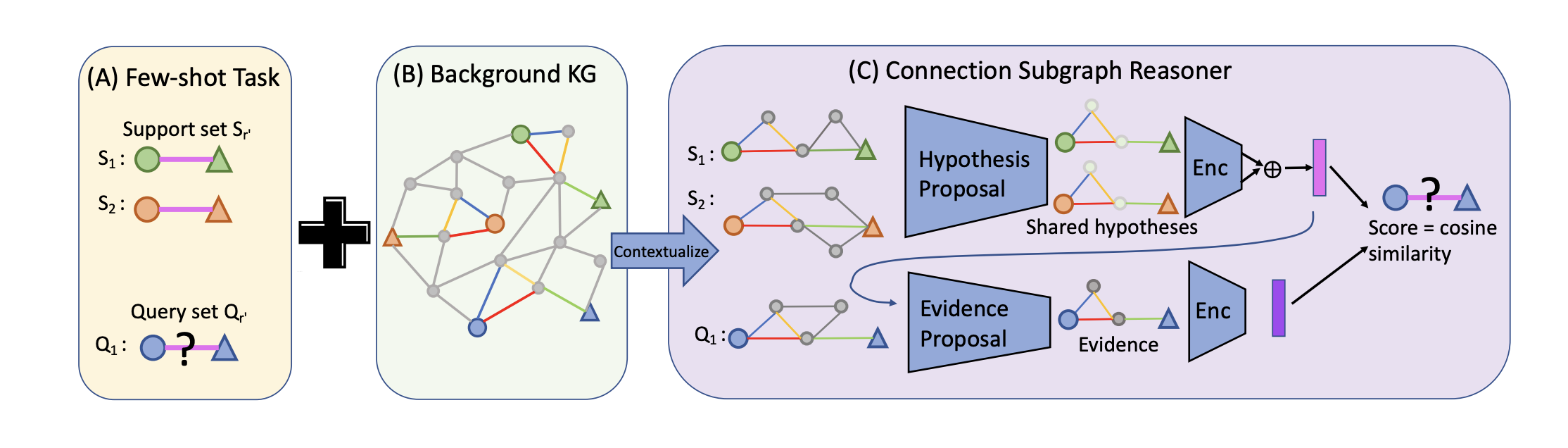
Contact: qhwang@cs.stanford.edu
Links: Paper
Keywords: few-shot learning, knowledge graphs, graph neural networks, self-supervised pretraining
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
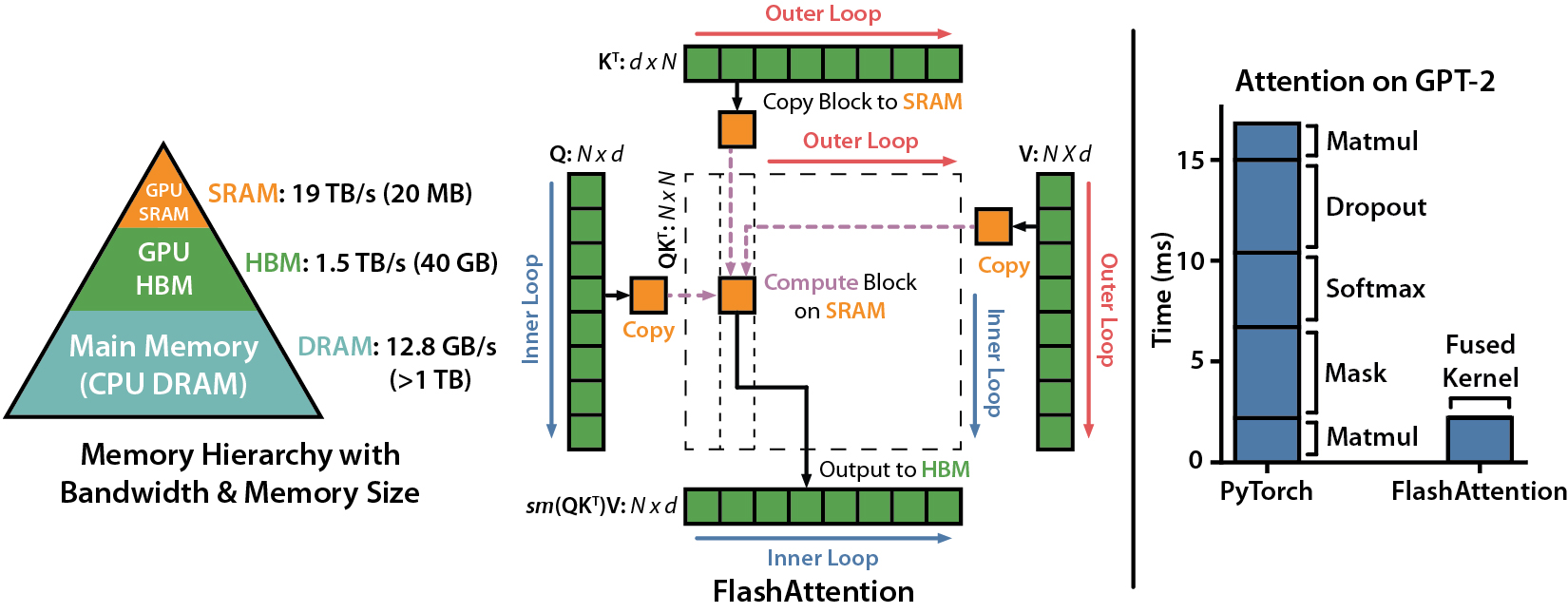
Contact: trid@stanford.edu
Links: Paper | Video | Website
Keywords: attention, long context, language modeling
Giving Feedback on Interactive Student Programs with Meta-Exploration
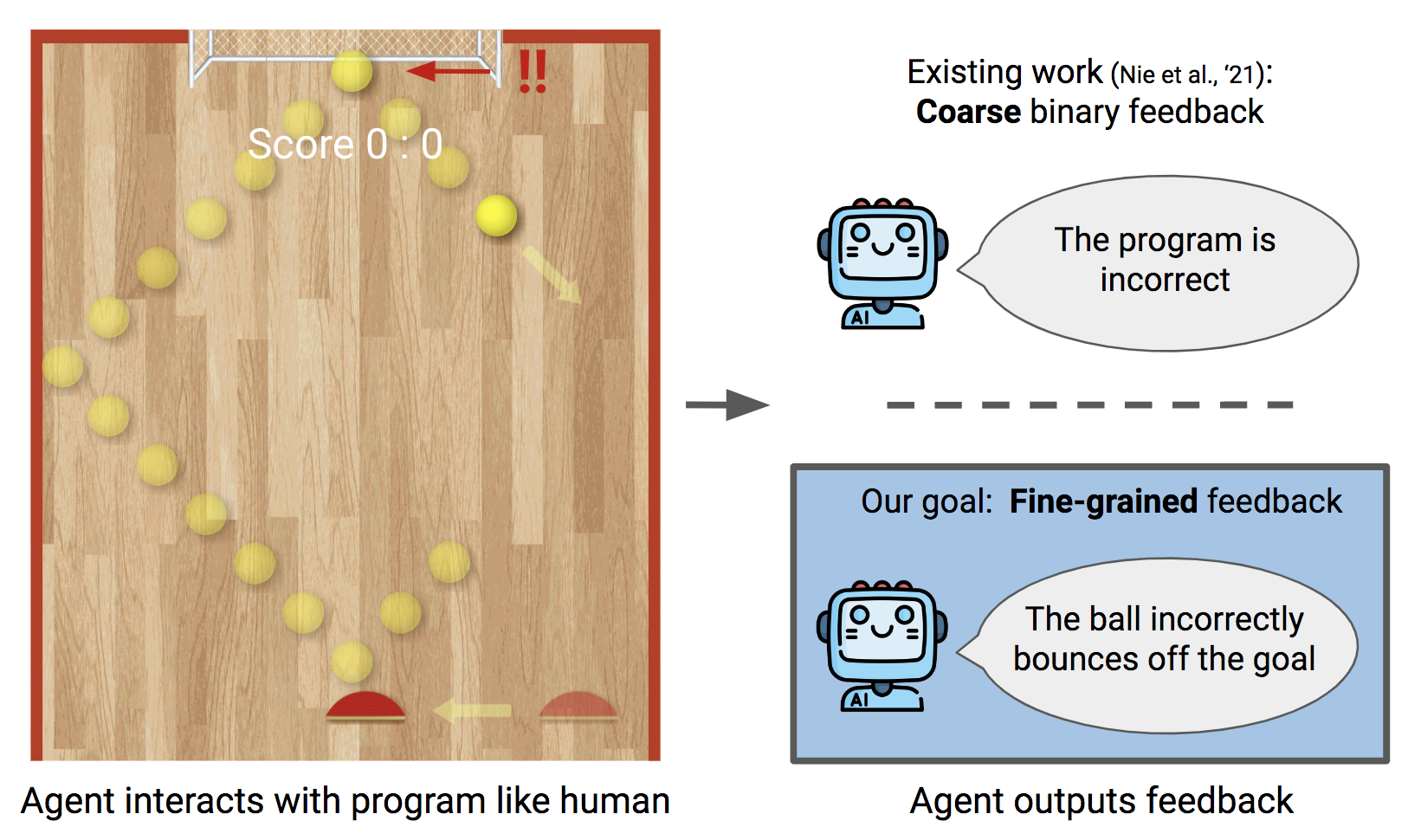
Contact: evanliu@cs.stanford.edu
Award nominations: Selected as oral
Links: Paper | Video | Website
Keywords: meta-reinforcement learning, reinforcement learning, exploration, education
Gradient Estimation with Discrete Stein Operators
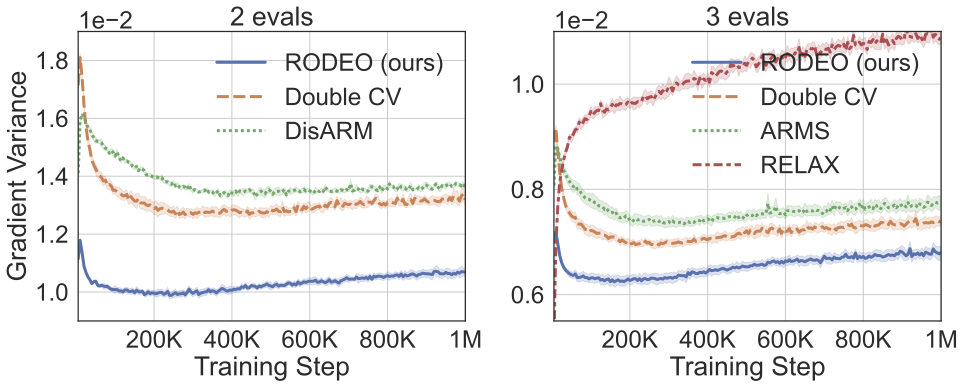
Contact: jiaxins@stanford.edu
Award nominations: Outstanding Paper Award
Links: Paper | Website
Keywords: gradient estimation, stein’s method, discrete latent variables, variance reduction
Improving Intrinsic Exploration with Language Abstractions
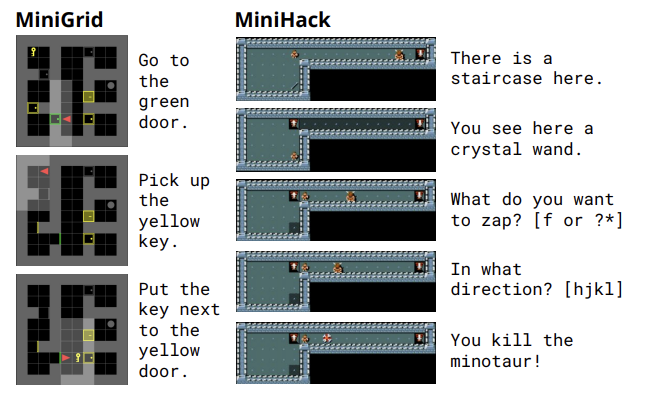
Contact: muj@stanford.edu
Links: Paper | Video
Keywords: reinforcement learning, intrinsic motivation, exploration, language, deep rl, language-guided rl
Improving Policy Learning via Language Dynamics Distillation
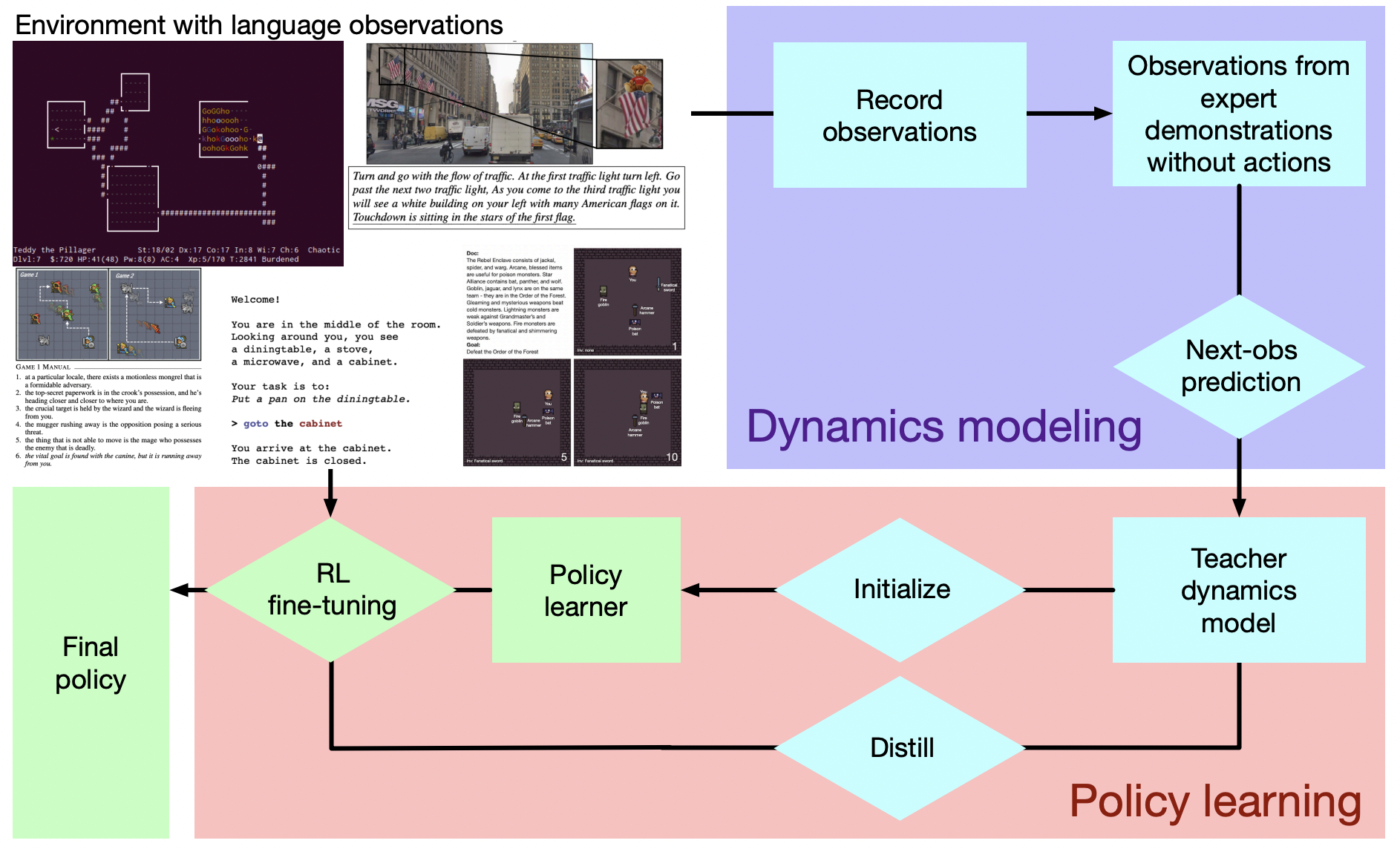
Contact: muj@stanford.edu
Links: Paper
Keywords: language grounding, reinforcement learning, reading to generalize
Improving Self-Supervised Learning by Characterizing Idealized Representations
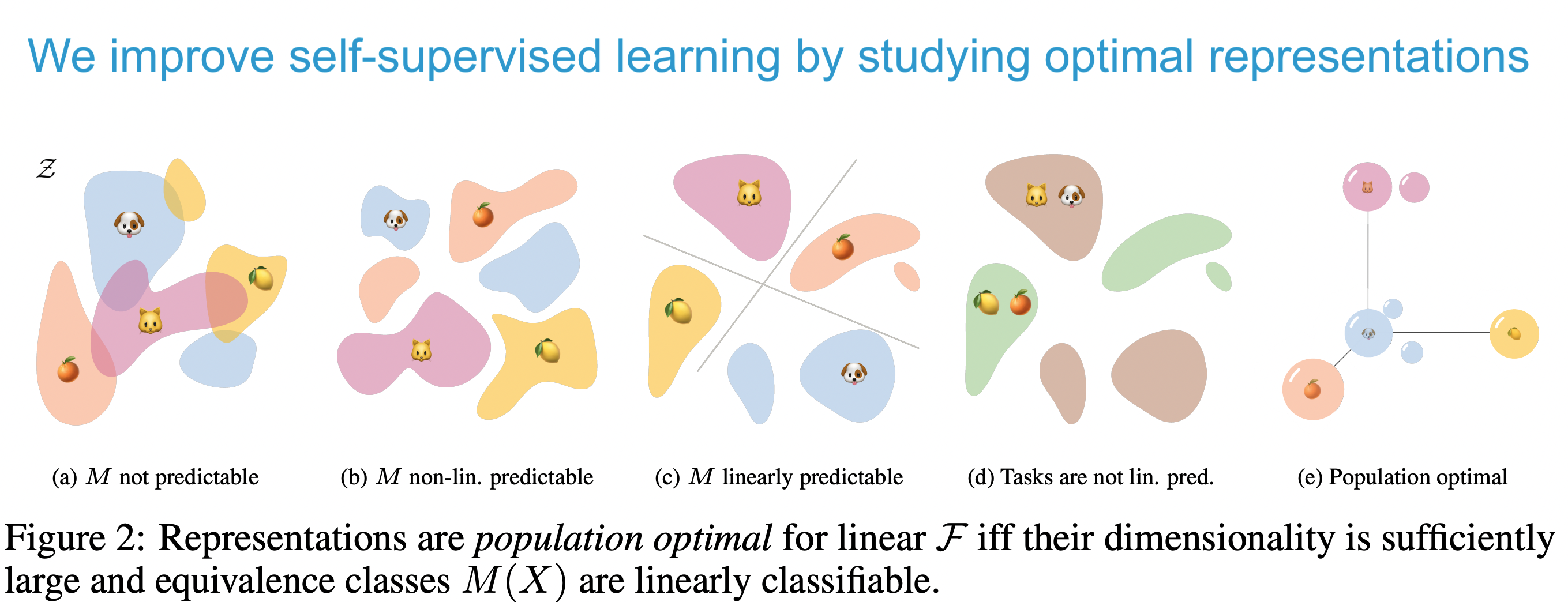
Contact: yanndubs@stanford.edu
Links: Paper | Video | Website
Keywords: self-supervised learning, invariances, contrastive learning, machine learning, representation learning
Increasing the Scope as You Learn: Adaptive Bayesian Optimization in Nested Subspaces
Contact: lnardi@stanford.edu
Award nominations: No
Links: Paper | Website
Keywords: high-dimensional global optimization, bayesian optimization, gaussian processes
Iterative Feature Matching: Toward Provable Domain Generalization with Logarithmic Environments
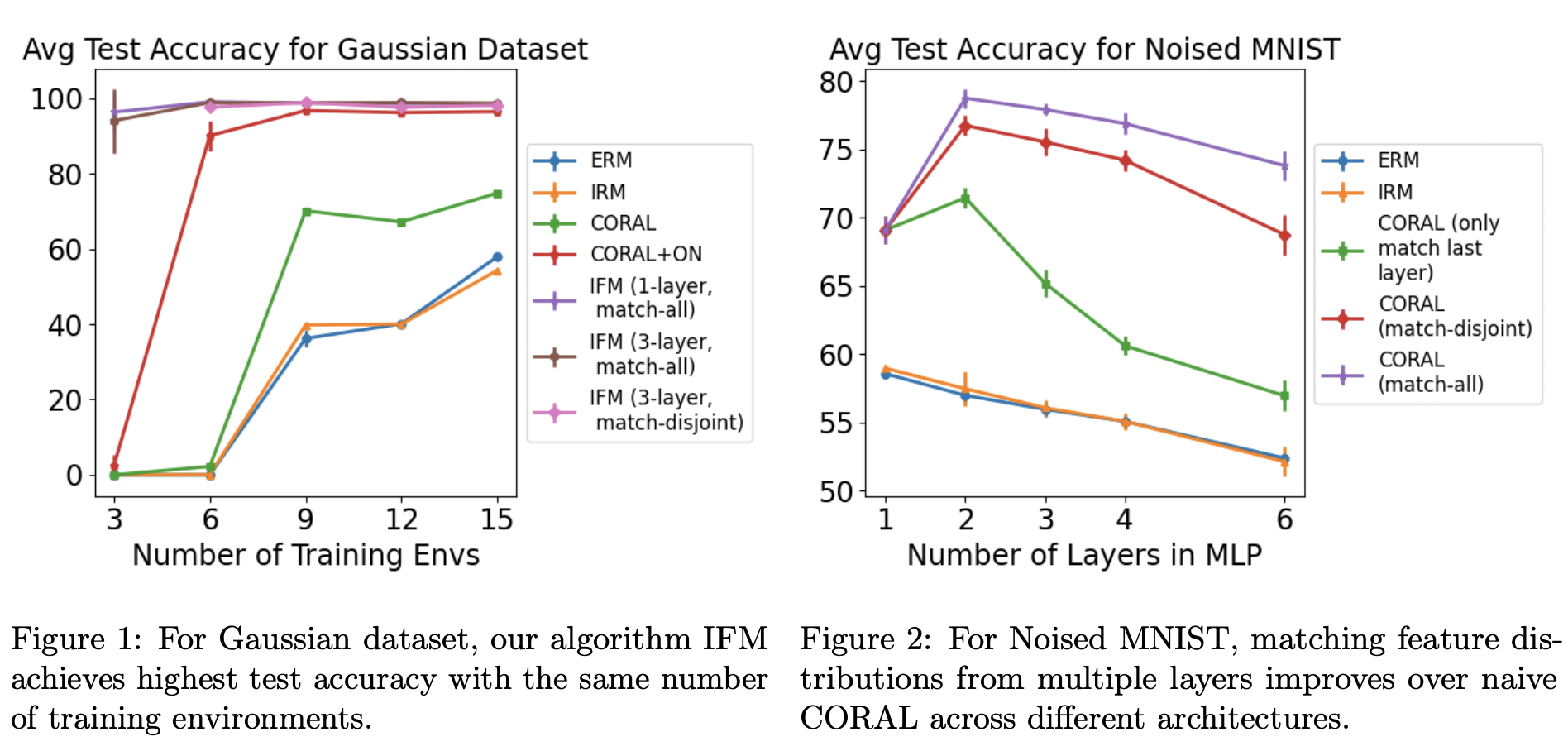
Contact: cynnjjs@stanford.edu
Links: Paper
Keywords: domain generalization, ood robustness
Joint Entropy Search for Maximally-Informed Bayesian Optimization
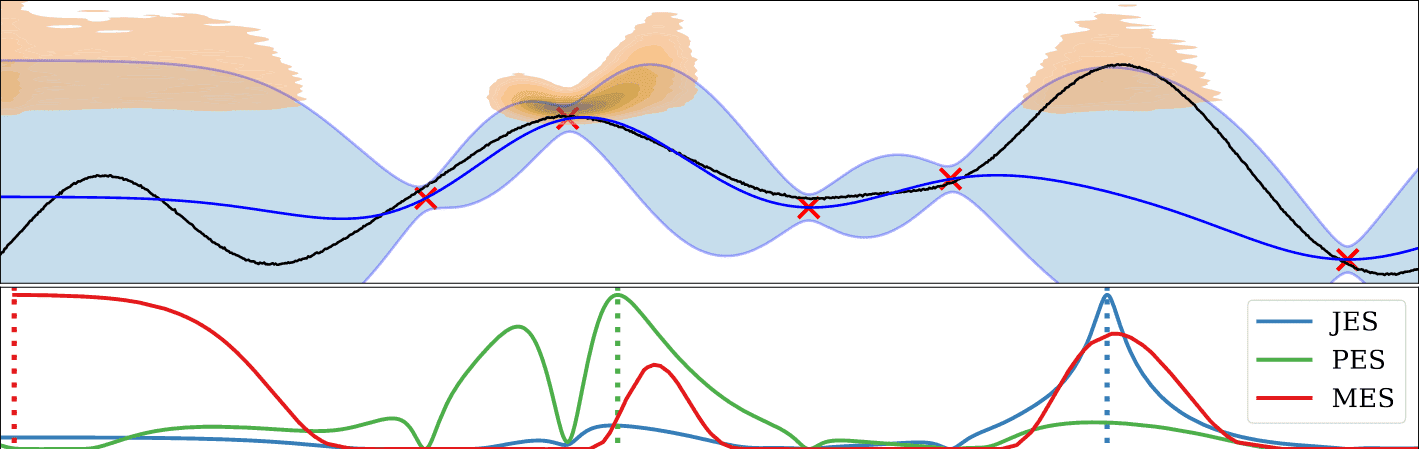
Contact: lnardi@stanford.edu
Award nominations: No
Links: Paper | Website
Keywords: bayesian optimization, entropy search, gaussian processes
Learning to Accelerate Partial Differential Equations via Latent Global Evolution
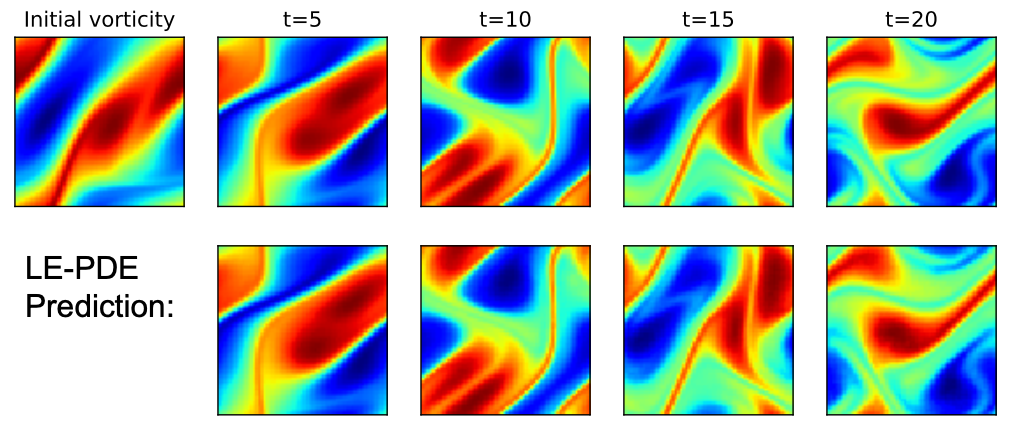
Contact: tailin@cs.stanford.edu
Links: Paper | Website
Keywords: accelerate, partial differential equation, latent global evolution, inverse optimization
Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
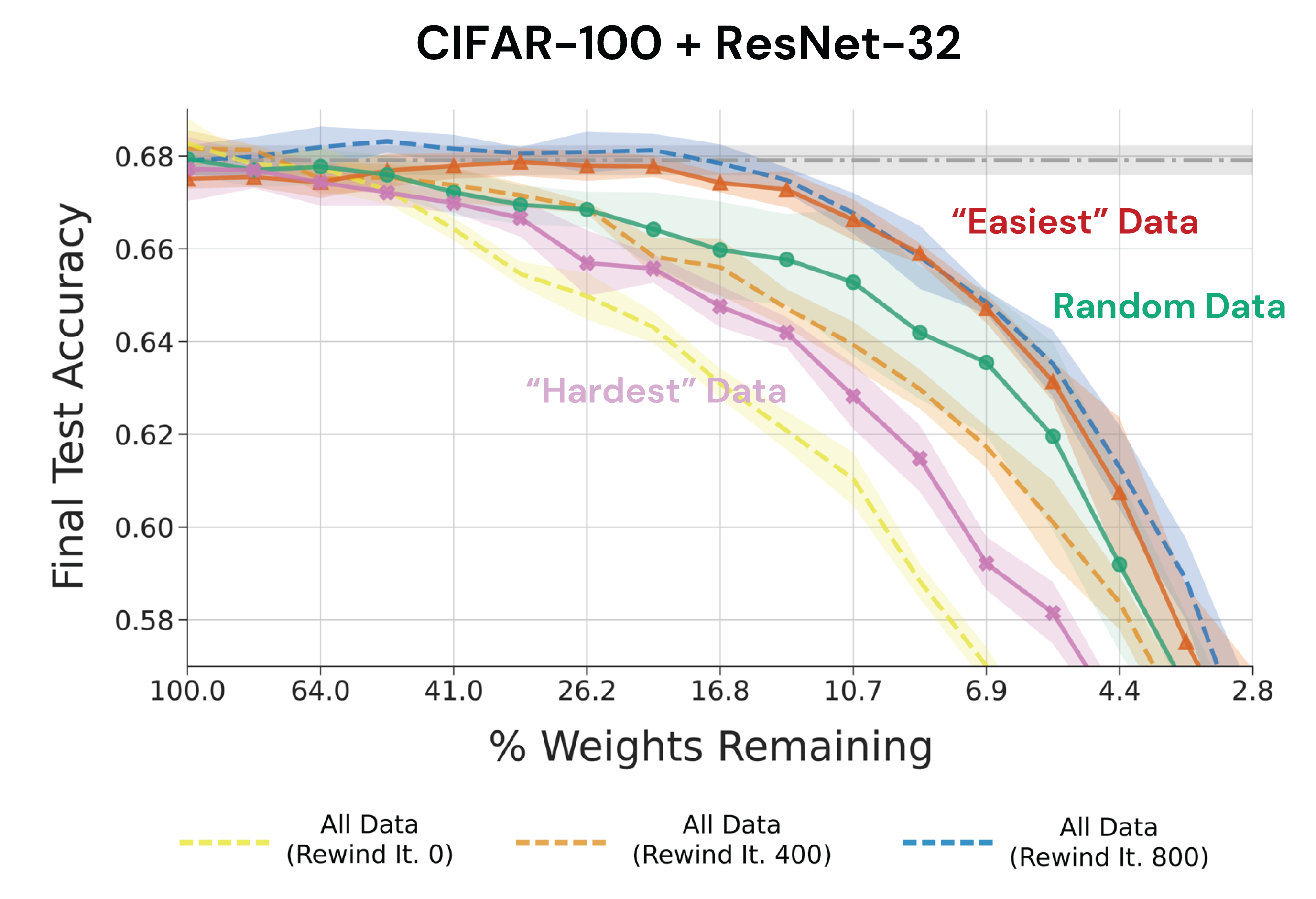
Contact: mansheej@stanford.edu
Links: Paper
Keywords: data pruning, linear mode connectivity, iterative magnitude pruning, loss landscape geometry, lottery ticket hypothesis, sparsity
Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning
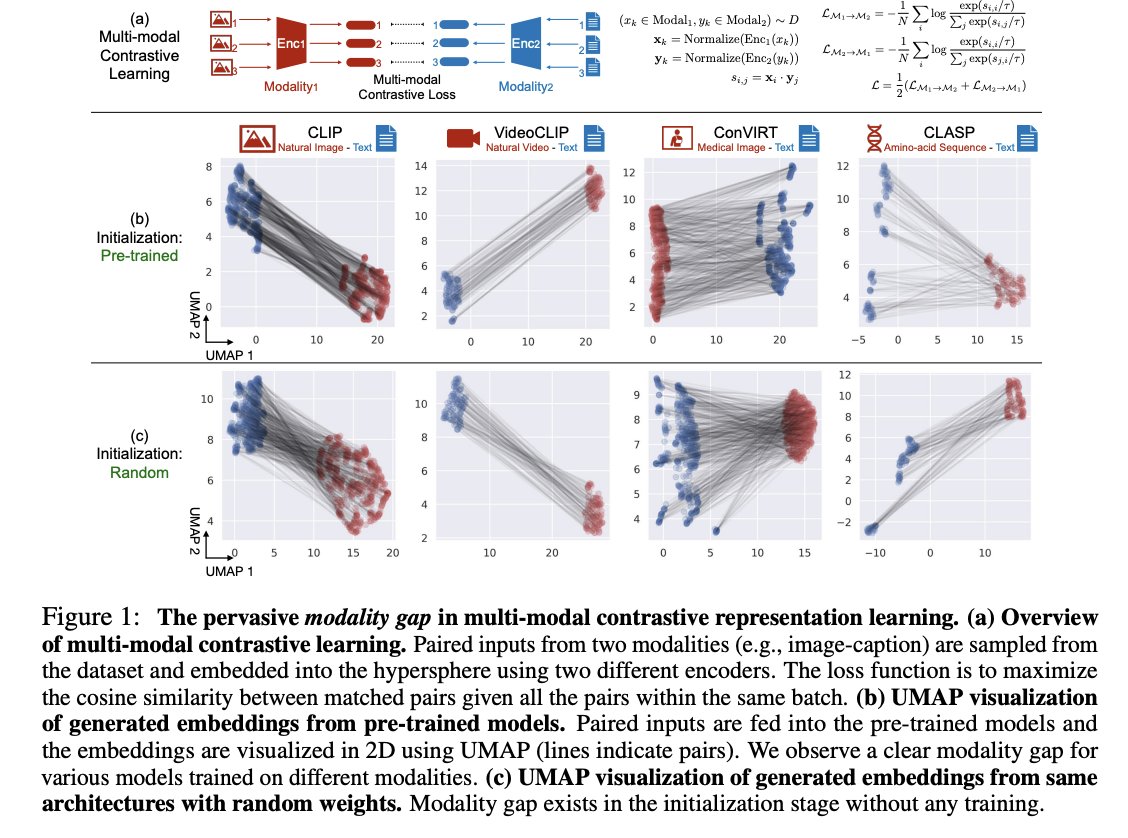
Contact: wxliang@stanford.edu
Links: Paper | Video | Website
Keywords: cone effect, modality gap, geometry of deep multi-model learning, contrastive representation learning, multi-modal representation learning
No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit
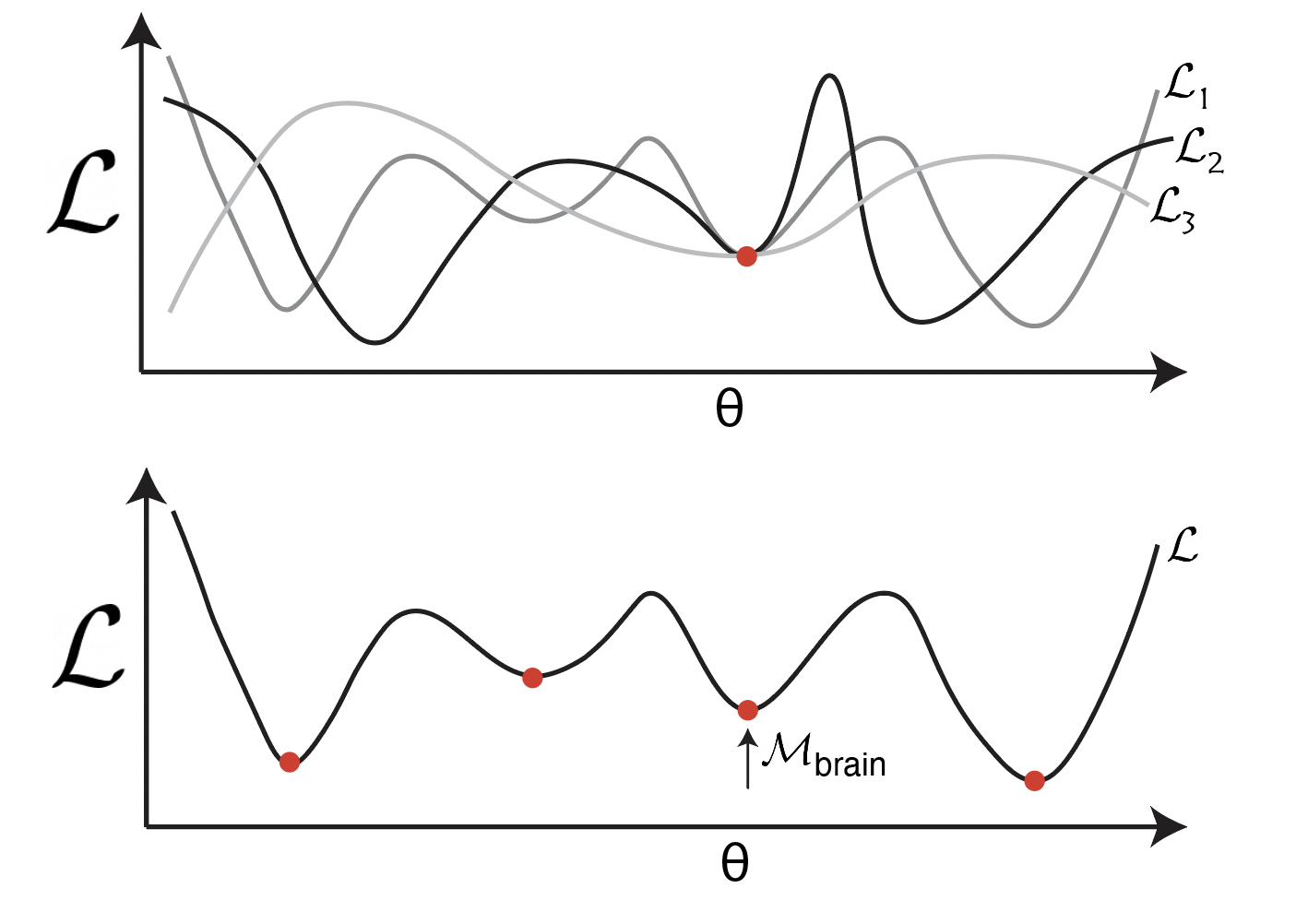
Contact: rylanschaeffer@gmail.com
Links: Paper | Blog Post
Keywords: neuroscience, deep learning, grid cells, representation learning
Oracle Inequalities for Model Selection in Offline Reinforcement Learning
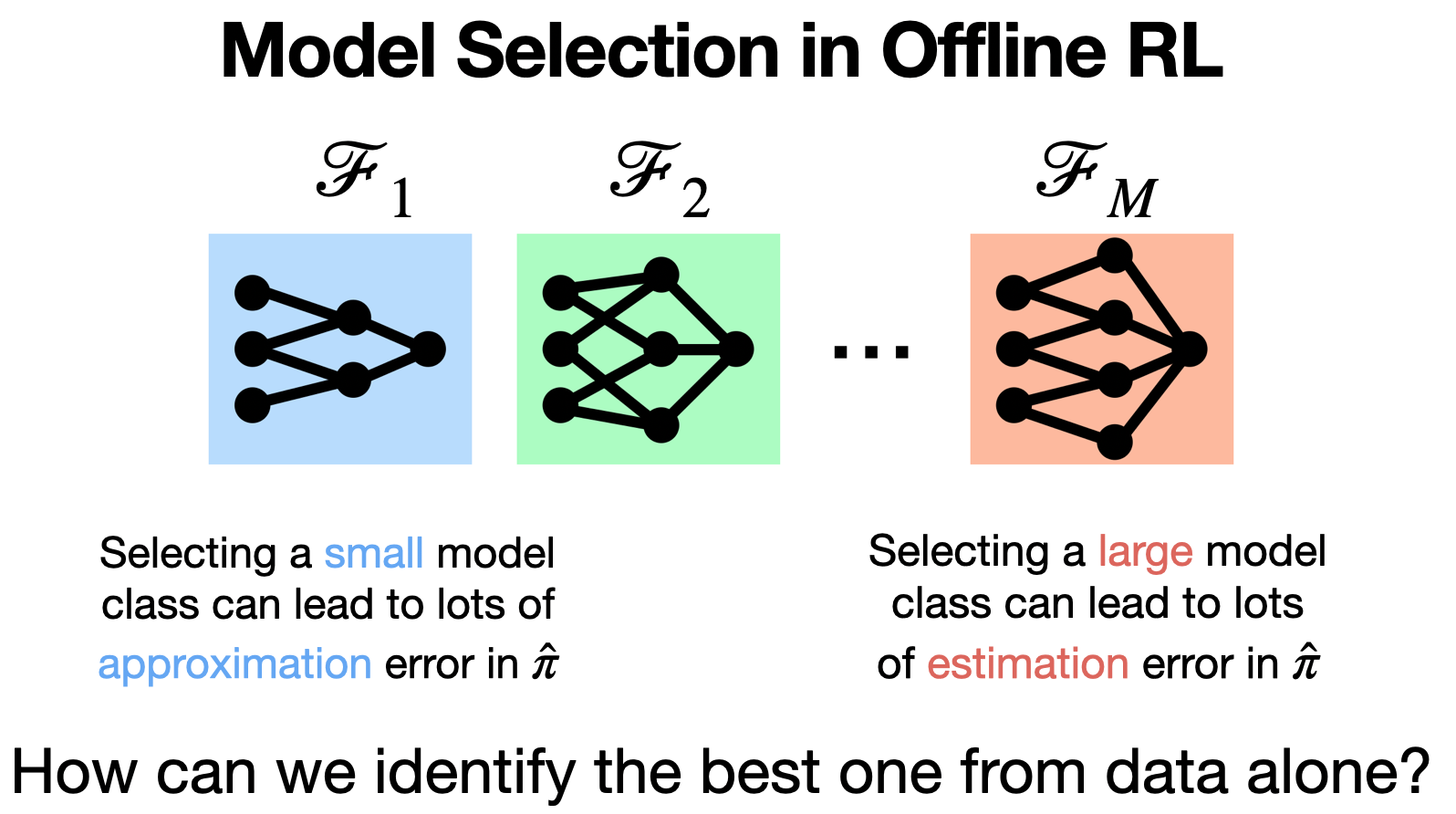
Contact: jnl@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, offline reinforcement learning, model selection, hyperparameter tuning, offline policy evaluation
Planning to the Information Horizon of BAMDPs via Epistemic State Abstraction
Contact: dilip@cs.stanford.edu
Links: Paper
Keywords: bayes-adaptive markov decision process, bayesian reinforcement learning, exploration, planning
S4ND: Modeling Images and Videos as Multidimensional Signals Using State Spaces
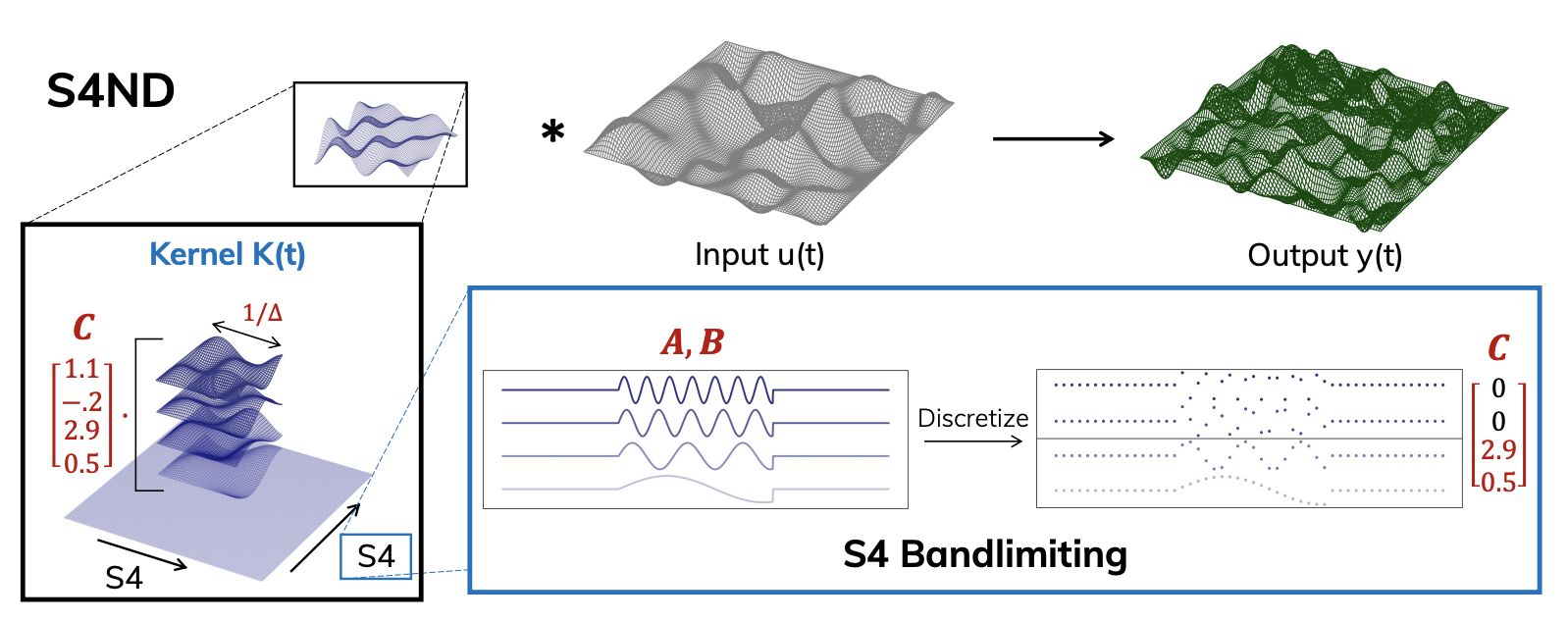
Contact: etnguyen@stanford.edu
Links: Paper | Video | Website
Keywords: state space models, s4, computer vision, deep learning
SIXO: Smoothing Inference with Twisted Objectives
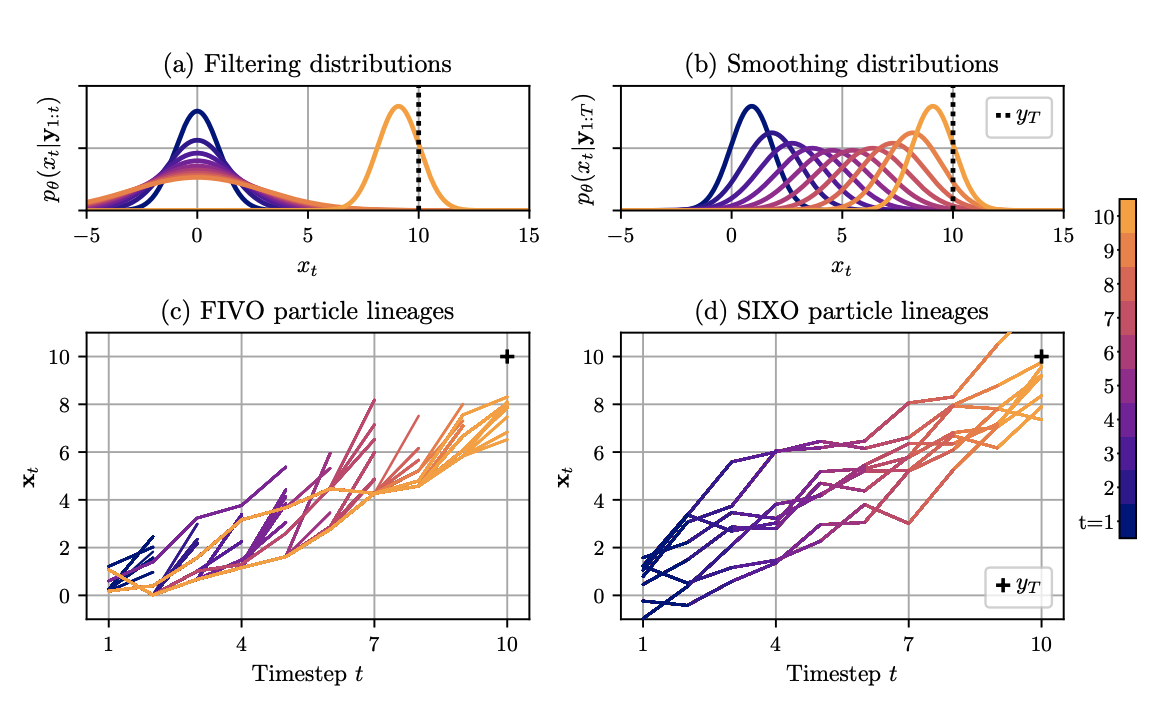
Contact: jdlawson@stanford.edu
Award nominations: Oral
Links: Paper
Keywords: smoothing, variational, objectives, fivo, sequential monte carlo, inference, twisted, time series
STaR: Bootstrapping Reasoning With Reasoning
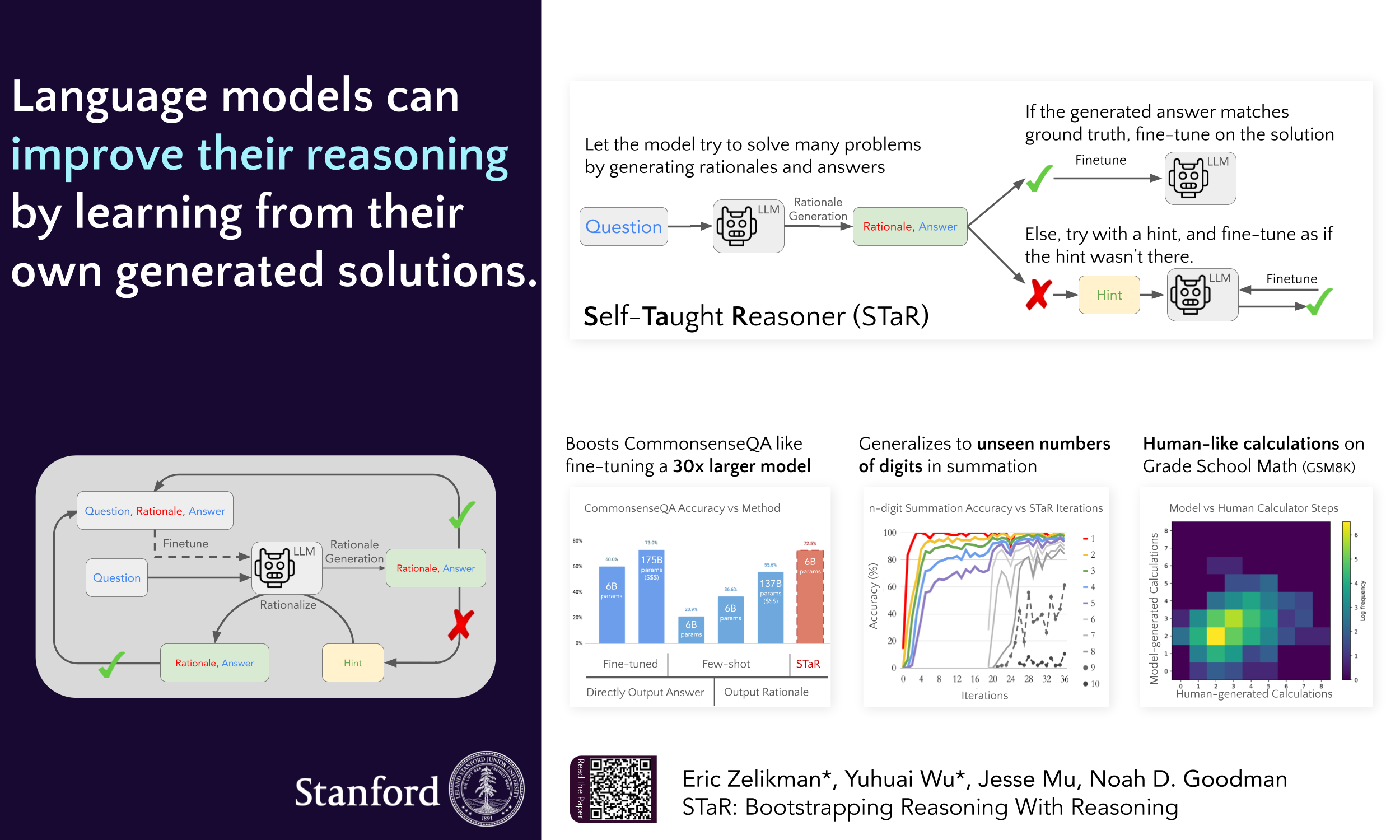
Contact: ezelikman@cs.stanford.edu
Links: Paper
Keywords: chain-of-thought, reasoning, language model, bootstrapping
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
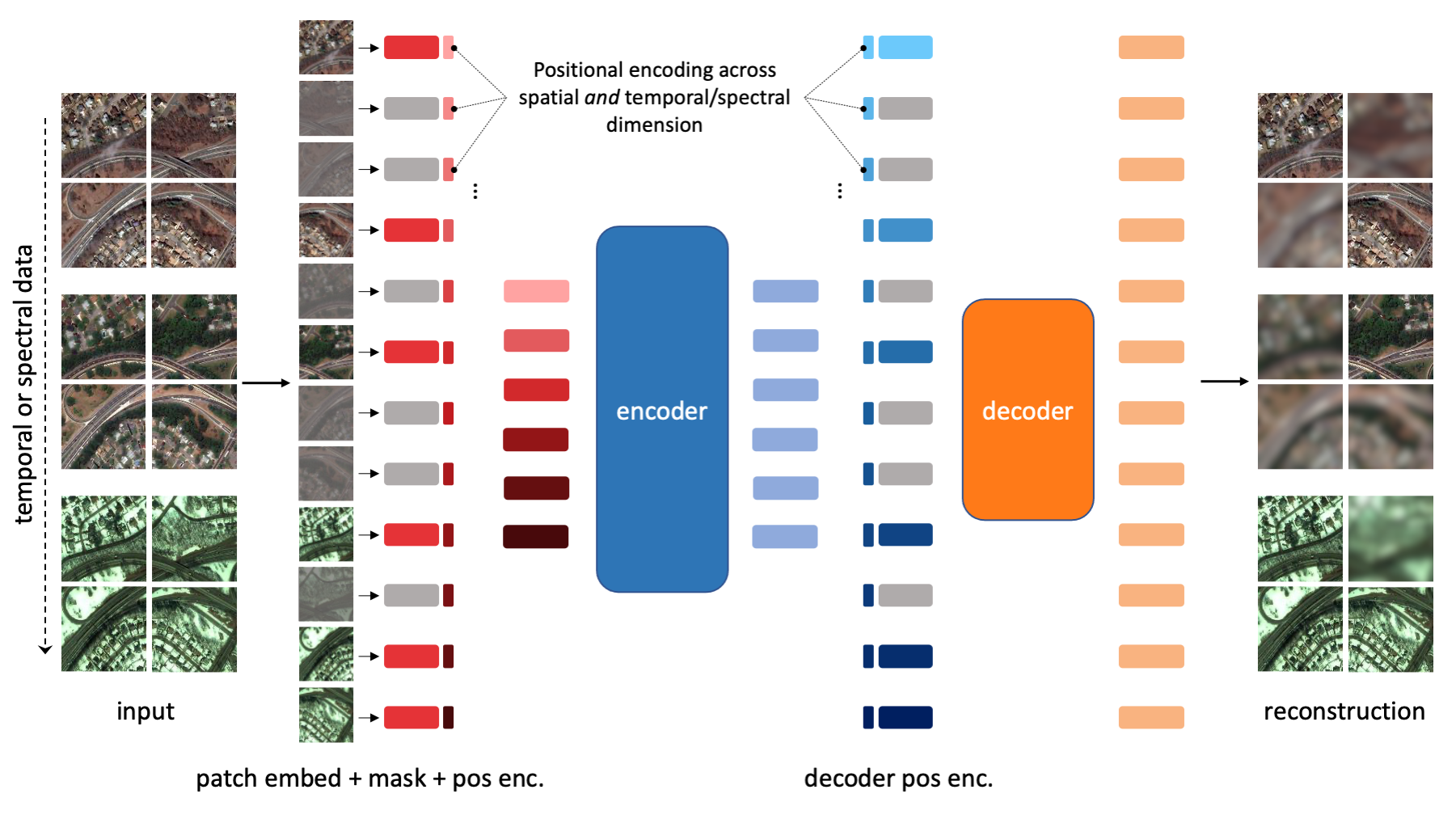
Contact: samar.khanna@stanford.edu
Links: Paper | Video | Website
Keywords: self-supervised learning, transformers, pretraining, satellite images, temporal, multi-spectral
Self-Similarity Priors: Neural Collages as Differentiable Fractal Representations
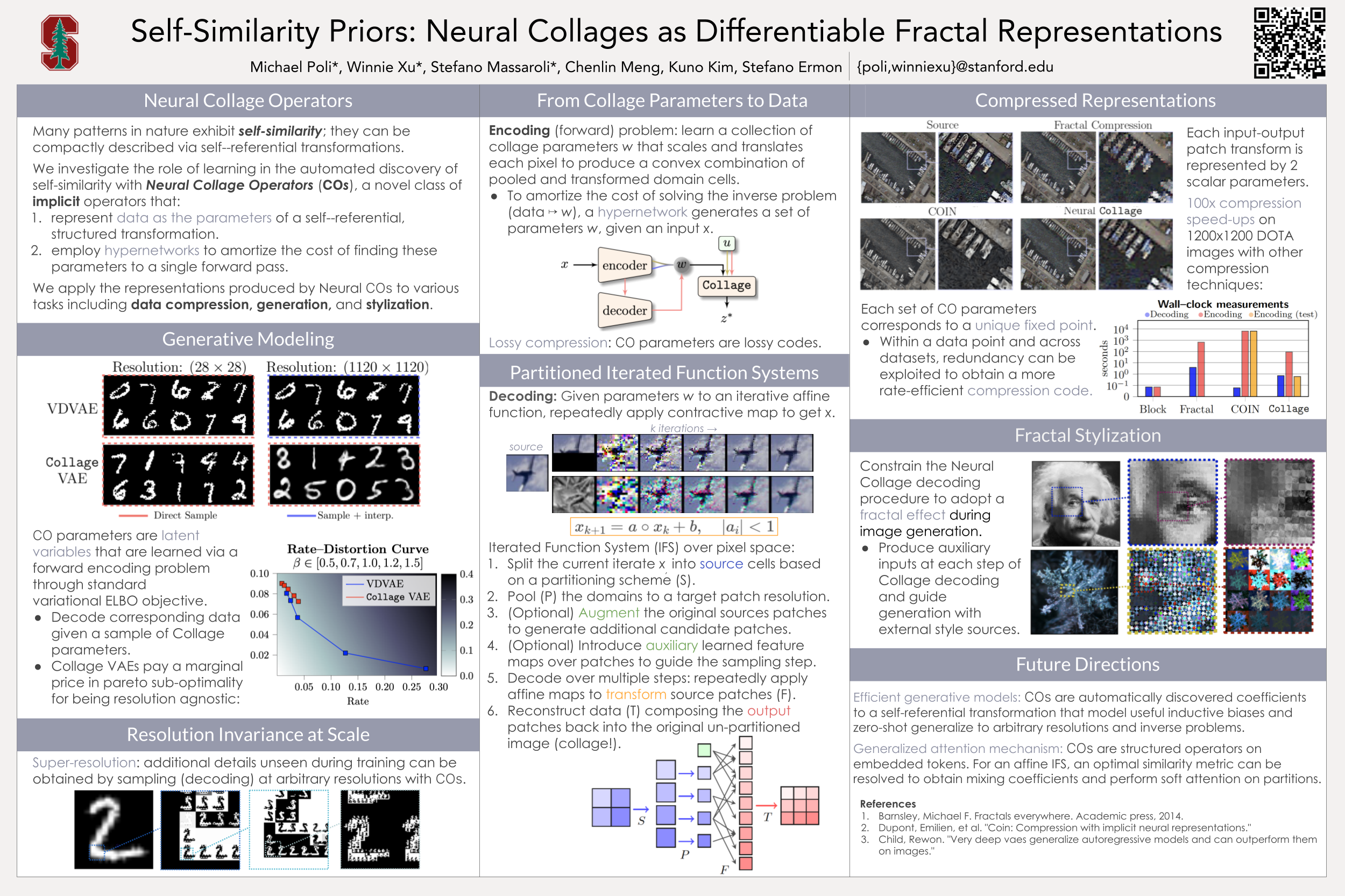
Contact: poli@stanford.edu
Links: Paper | Website
Keywords: implicit representations, compression, deep equilibrium models, generative models, fractal, fixed-point
Self-Supervised Learning of Brain Dynamics from Broad Neuroimaging Data
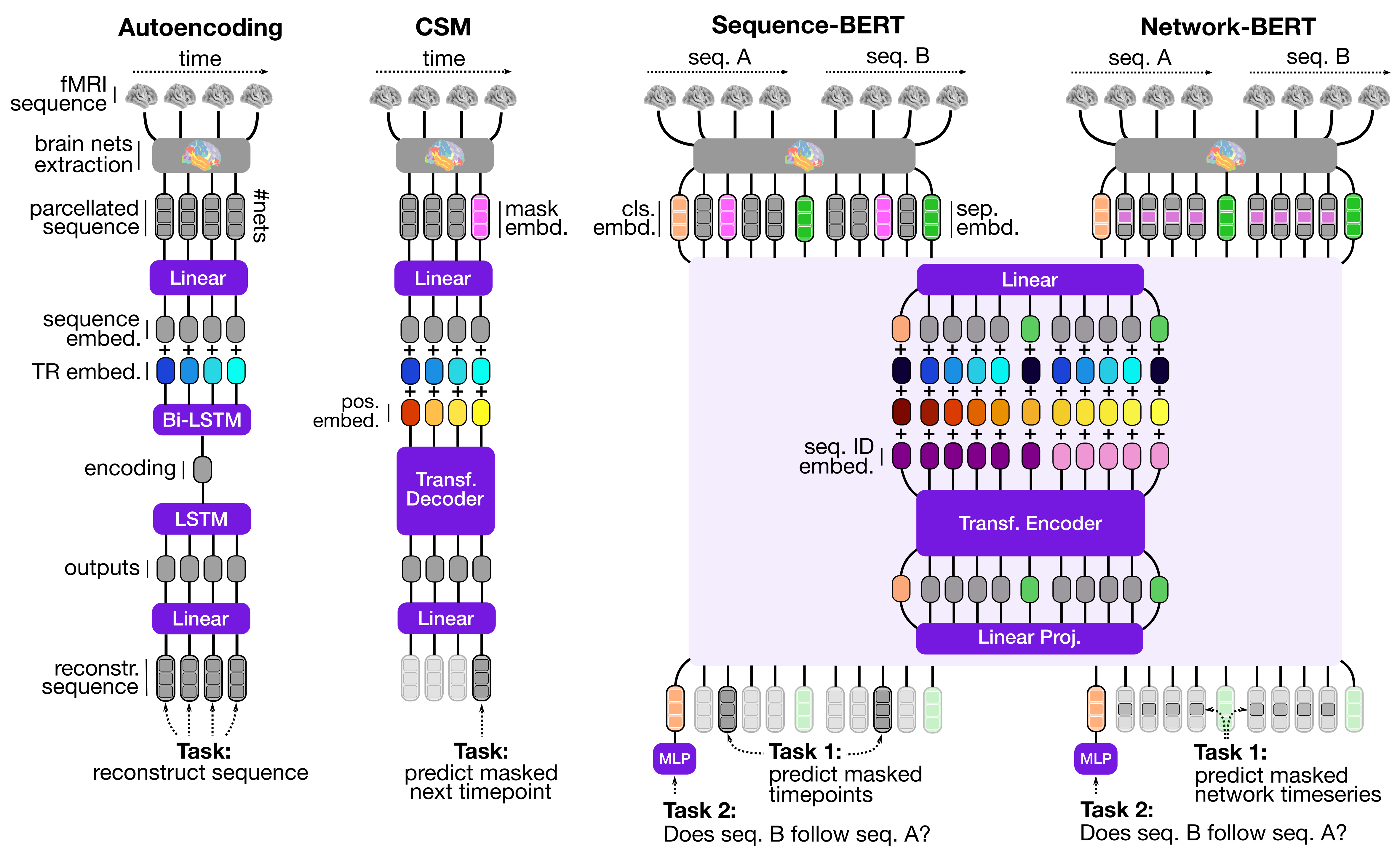
Contact: athms@stanford.edu
Links: Paper
Keywords: self-supervised learning, neuroimaging, deep learning, natural language processing, brain decoding
Statistically Meaningful Approximation: a Case Study on Approximating Turing Machines with Transformers

Contact: colin.y.wei@gmail.com
Links: Paper
Keywords: approximation theory, generalization bounds, sample complexity bounds, learning theory
Structural Analysis of Branch-and-Cut and the Learnability of Gomory Mixed Integer Cuts
Contact: vitercik@stanford.edu
Links: Paper
Keywords: gomory mixed integer cuts, automated algorithm configuration, integer programming, tree search, branch-and-bound, branch-and-cut, cutting planes, sample complexity, generalization guarantees, data-driven algorithm design
Training and Inference on Any-Order Autoregressive Models the Right Way
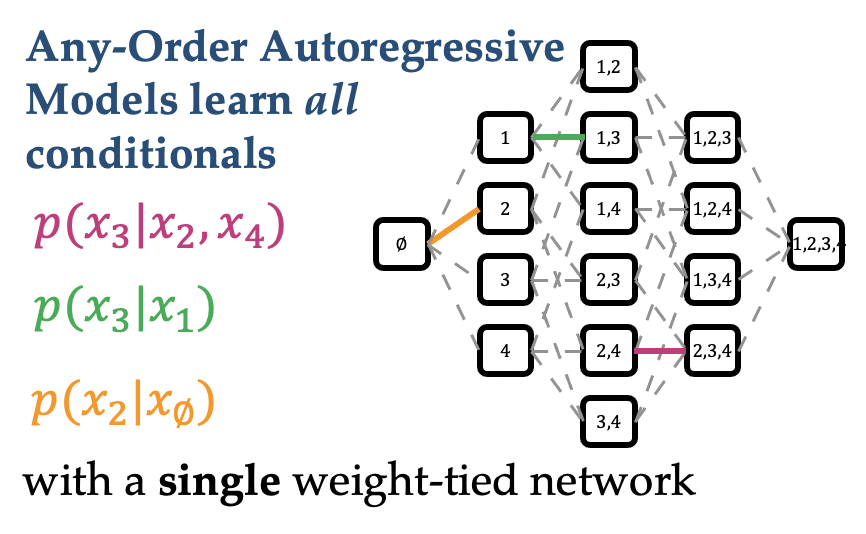
Contact: andyshih@stanford.edu
Award nominations: Selected as Oral
Links: Paper | Video | Website
Keywords: any-order autoregressive models, tractable generative models, arbitrary marginal and conditional
Transform Once: Efficient Operator Learning in Frequency Domain

Contact: poli@stanford.edu
Links: Paper
Keywords: convolutions, long range dependencies, neural operators, high-resolution, frequency, transform, differential equation, dynamics, turbulence, fluid flows, pde
Uncalibrated Models Can Improve Human-AI Collaboration
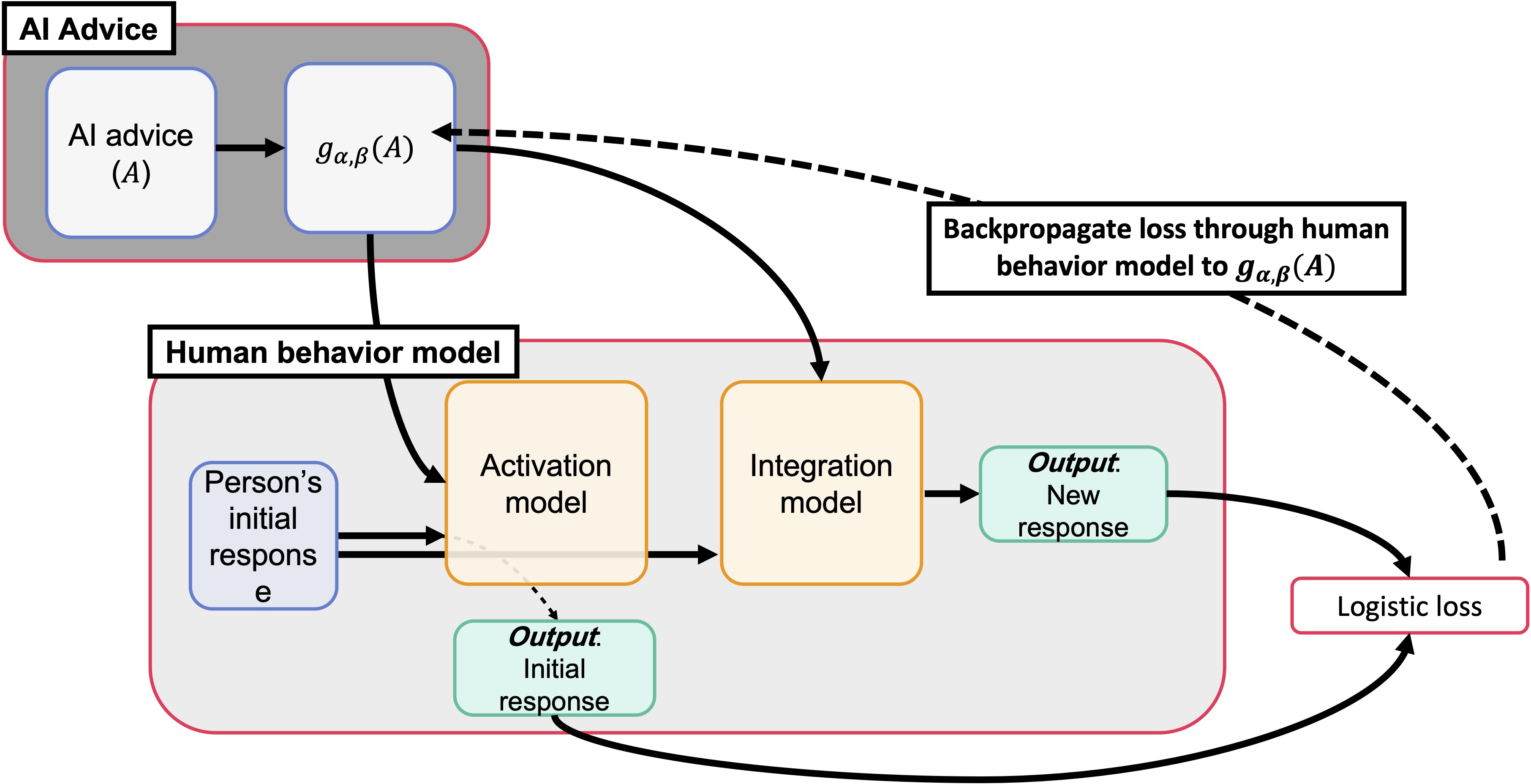
Contact: kailasv@stanford.edu
Links: Paper
Keywords: human-in-the-loop ai, human-calibrated ai
WeightedSHAP: analyzing and improving Shapley based feature attributions
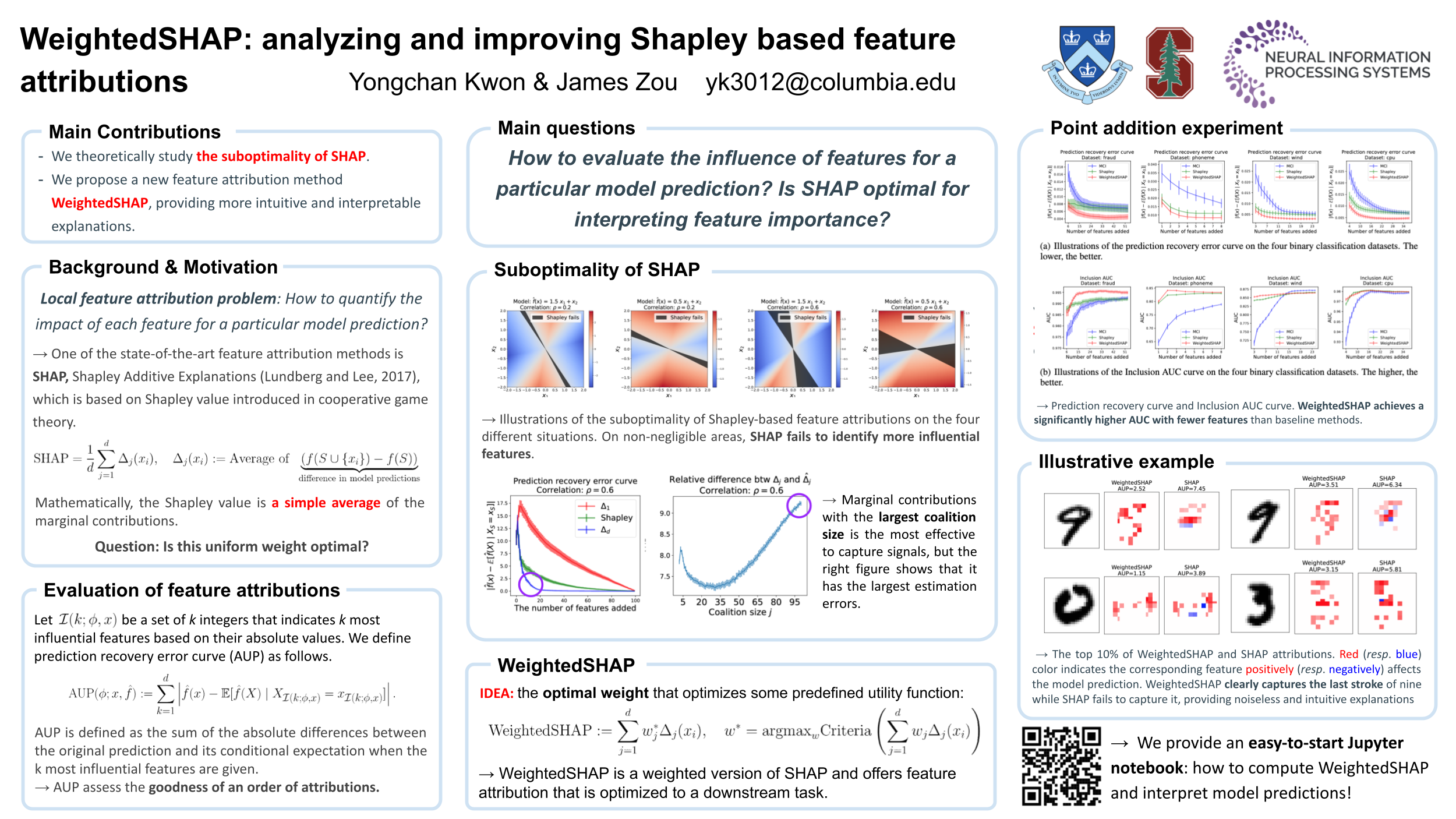
Contact: yckwon@stanford.edu
Links: Paper | Website
Keywords: shapley value, model interpretation, attribution problem
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes
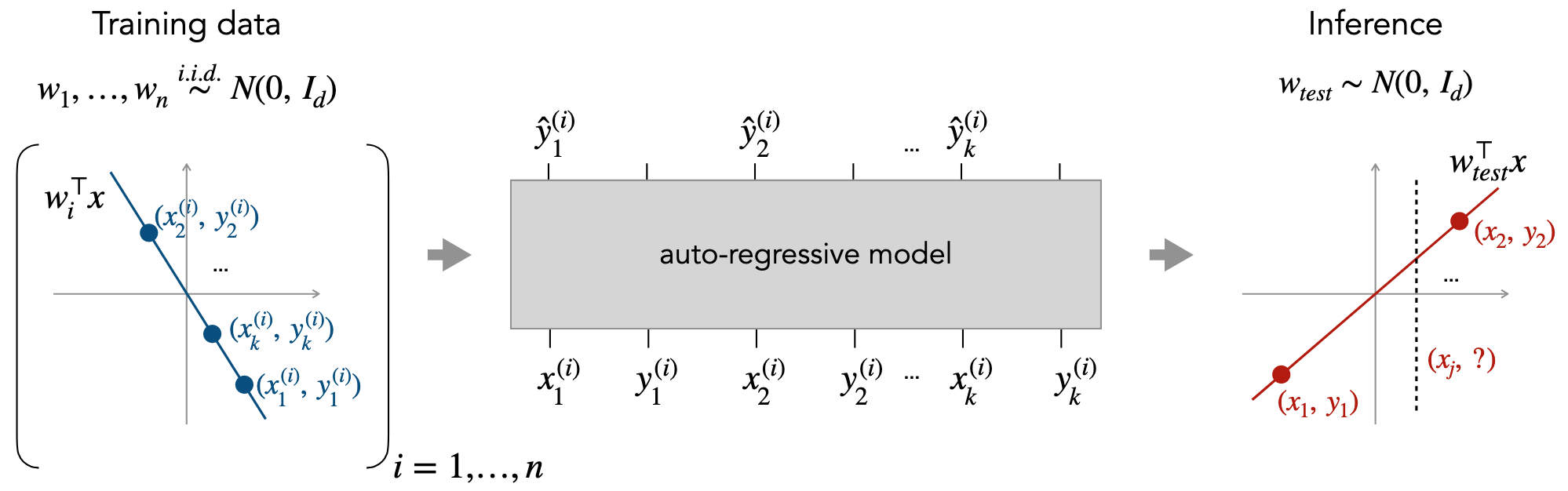
Contact: shivamg@cs.stanford.edu; tsipras@stanford.edu
Links: Paper
Keywords: in-context learning, transformers, meta-learning
When Does Differentially Private Learning Not Suffer in High Dimensions?
Contact: lxuechen@cs.stanford.edu
Links: Paper
Keywords: differential privacy, fine-tuning, dp convex optimization, pretrained models
You Only Live Once: Single Life Reinforcement Learning
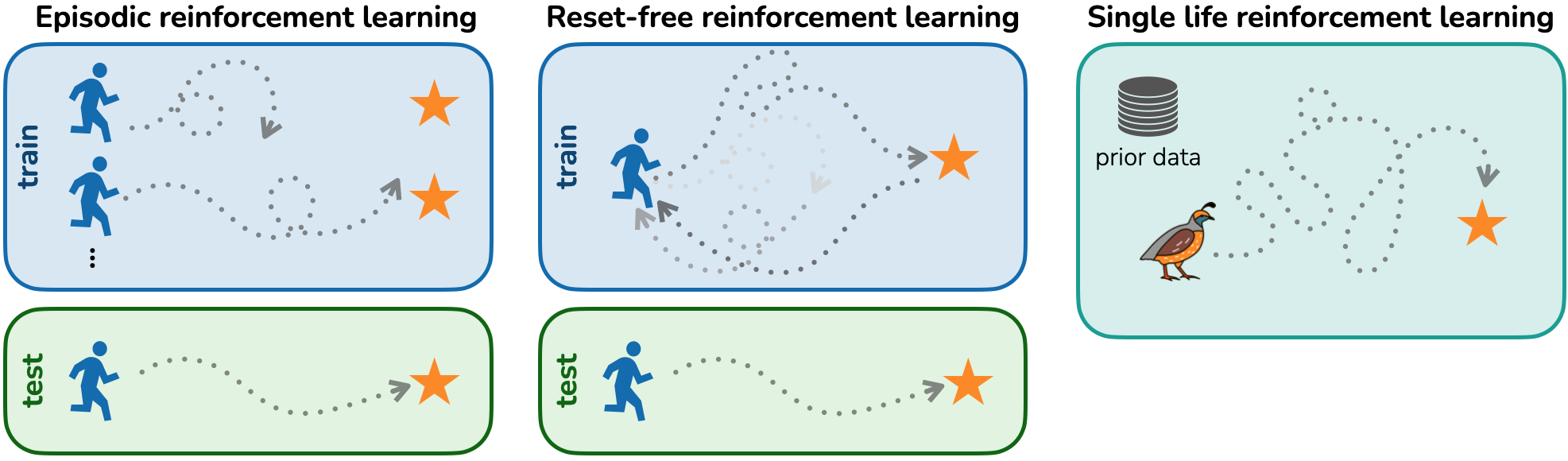
Contact: asc8@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, autonomous reinforcement learning, adversarial imitation learning
ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
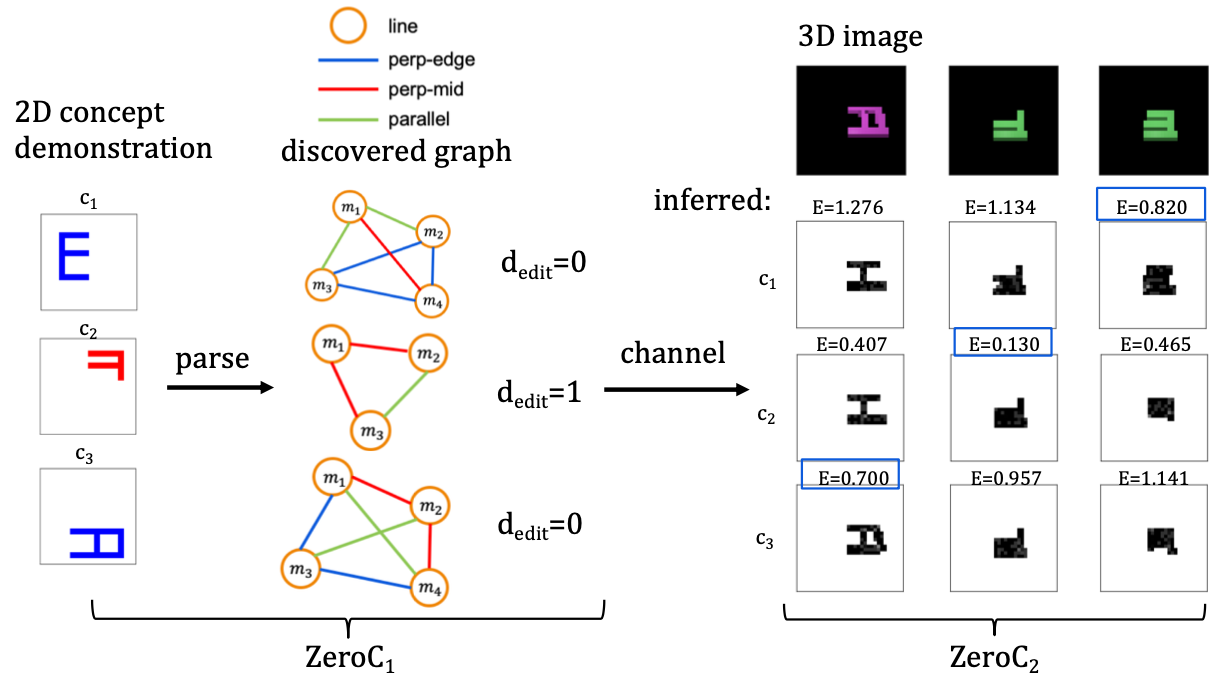
Contact: tailin@cs.stanford.edu
Links: Paper | Website
Keywords: zero-shot concept recognition, zero-shot concept acquisition, neuro-symbolic, inference time
5th Robot Learning Workshop: Trustworthy Robotics
Authors: Ransalu Senanayake
Contact: ransalu@stanford.edu
Links: Paper | Website
Keywords: trustworthy ai, robotics
Datasets and Benchmarks Track
- CLEVRER-Humans: Describing Physical and Causal Events the Human Way | Website by Jiayuan Mao*, Xuelin Yang*, Xikun Zhang, Noah Goodman, Jiajun Wu.
- DABS 2.0: Improved Datasets and Algorithms for Universal Self-Supervision | Website by Alex Tamkin, Gaurab Banerjee, Mohamed Owda, Vincent Liu, Shashank Rammoorthy, Noah Goodman.
- Geoclidean: Few-Shot Generalization in Euclidean Geometry | Website by Joy Hsu, Jiajun Wu, Noah Goodman.
- HAPI: A Large-scale Longitudinal Dataset of Commercial ML API Predictions | Website by Lingjiao Chen, Matei Zaharia, James Zou.
- How Well Do Unsupervised Learning Algorithms Model Human Real-time and Life-long Learning? | Website by Chengxu Zhuang, Violet Xiang, Yoon Bai, Xiaoxuan Jia, Nick Turk-Browne, Kenneth Norman, James J. DiCarlo, Daniel LK Yamins.
- IKEA-Manual: Seeing Shape Assembly Step by Step by Ruocheng Wang, Yunzhi Zhang, Jiayuan Mao, Ran Zhang, Chin-Yi Cheng, Jiajun Wu.
- Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset | Website by Peter Henderson*, Mark S. Krass*, Lucia Zheng, Neel Guha, Christopher D. Manning, Dan Jurafsky, Daniel E. Ho.
Workshop Papers
- Generation Probabilities are Not Enough: Improving Error Highlighting for AI Code Suggestions by Helena Vasconcelos, Gagan Bansal, Adam Fourney, Q.Vera Liao, Jennifer Wortman Vaughan.
- Learning Absorption Rates in Glucose-Insulin Dynamics from Meal Covariates by Ke Alexander Wang, Matthew E. Levine, Jiaxin Shi, Emily Fox.
- The Solution Path of the Group Lasso by Aaron Mishkin, Mert Pilanci.
- A Finite-Particle Convergence Rate for Stein Variational Gradient Descent by Jiaxin Shi, Lester Mackey.
- BudgetLongformer: Can we Cheaply Pretrain a SotA Legal Language Model From Scratch? by Joel Niklaus, Daniele Giofre.
- ColRel: Collaborative Relaying for Federated Learning over Intermittently Connected Networks by Rajarshi Saha, Michal Yemini, Emre Ozfatura, Deniz Gunduz, Andrea Goldsmith.
- Data Feedback Loops: Model-driven Amplification of Dataset Biases | Website by Rohan Taori, Tatsu Hashimoto.
- DrML: Diagnosing and Rectifying Vision Models using Language by Yuhui Zhang, Jeff Z. HaoChen, Shih-Cheng Huang, Kuan-Chieh Wang, James Zou, Serena Yeung.
- Federated Learning on Patient Data for Privacy-Protecting Polycystic Ovary Syndrome Treatment by Lucia Morris*, Tori Qiu*, Nikhil Raghuraman*.
- Kernel Density Bayesian Inverse Reinforcement Learning by Aishwarya Mandyam, Didong Li, Diana Cai, Andrew Jones, Barbara Engelhardt.
- Learning Controllable Adaptive Simulation for Multi-scale Physics by Tailin Wu, Takashi Maruyama, Qingqing Zhao, Gordon Wetzstein, Jure Leskovec.
- Learning Efficient Hybrid Particle-continuum Representations of Non-equilibrium N-body Systems by Tailin Wu, Michael Sun, H.G. Jason Chou, Pranay Reddy Samala, Sithipont Cholsaipant, Sophia Kivelson, Jacqueline Yau, Zhitao Ying, E. Paulo Alves, Jure Leskovec, Frederico Fiuza.
- On Rate-Distortion Theory in Capacity-Limited Cognition & Reinforcement Learning by Dilip Arumugam, Mark K. Ho, Noah D. Goodman, Benjamin Van Roy.
- PriorBand: Hyperband + Human Expert Knowledge | Website by Neeratyoy Mallik*, Carl Hvarfner*, Danny Stoll, Maciej Janowski, Edward Bergman, Mairus Lindauer, Luigi Nardi, Frank Hutter.
- The Curse of Low Task Diversity: On the Failure of Transfer Learning to Outperform MAML and Their Empirical Equivalence | Video by Brando Miranda, Patrick Yu, Yu-Xiong Wang, Sanmi Koyejo.
- Unmasking the Lottery Ticket Hypothesis: Efficient Adaptive Pruning for Finding Winning Tickets by Mansheej Paul*, Feng Chen*, Brett W. Larsen*, Jonathan Frankle, Surya Ganguli, Gintare Karolina Dziugaite.
We look forward to seeing you at NeurIPS 2022!