![]()
Join us at the Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS) 2024, taking place in Vancouver from December 10th - December 15th. Stanford Artificial Intelligence Laboratory (SAIL) researchers will be presenting at the main conference, at the Datasets and Benchmarks track and the various workshops. Here’s some of the SAIL work you may run into at the conference!
Interested in learning more about Stanford Artificial Intelligence Laboratory’s latest innovations? Our researchers welcome your questions - don’t hesitate to connect with the contact authors listed for each paper.
List of Accepted Papers
Main Conference
Are More LLM Calls All You Need? Towards the Scaling Properties of Compound AI Systems

Contact: lingjiao@stanford.edu
Links: Paper | Blog Post | Website
Keywords: scaling laws; compound ai systems; language models
BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
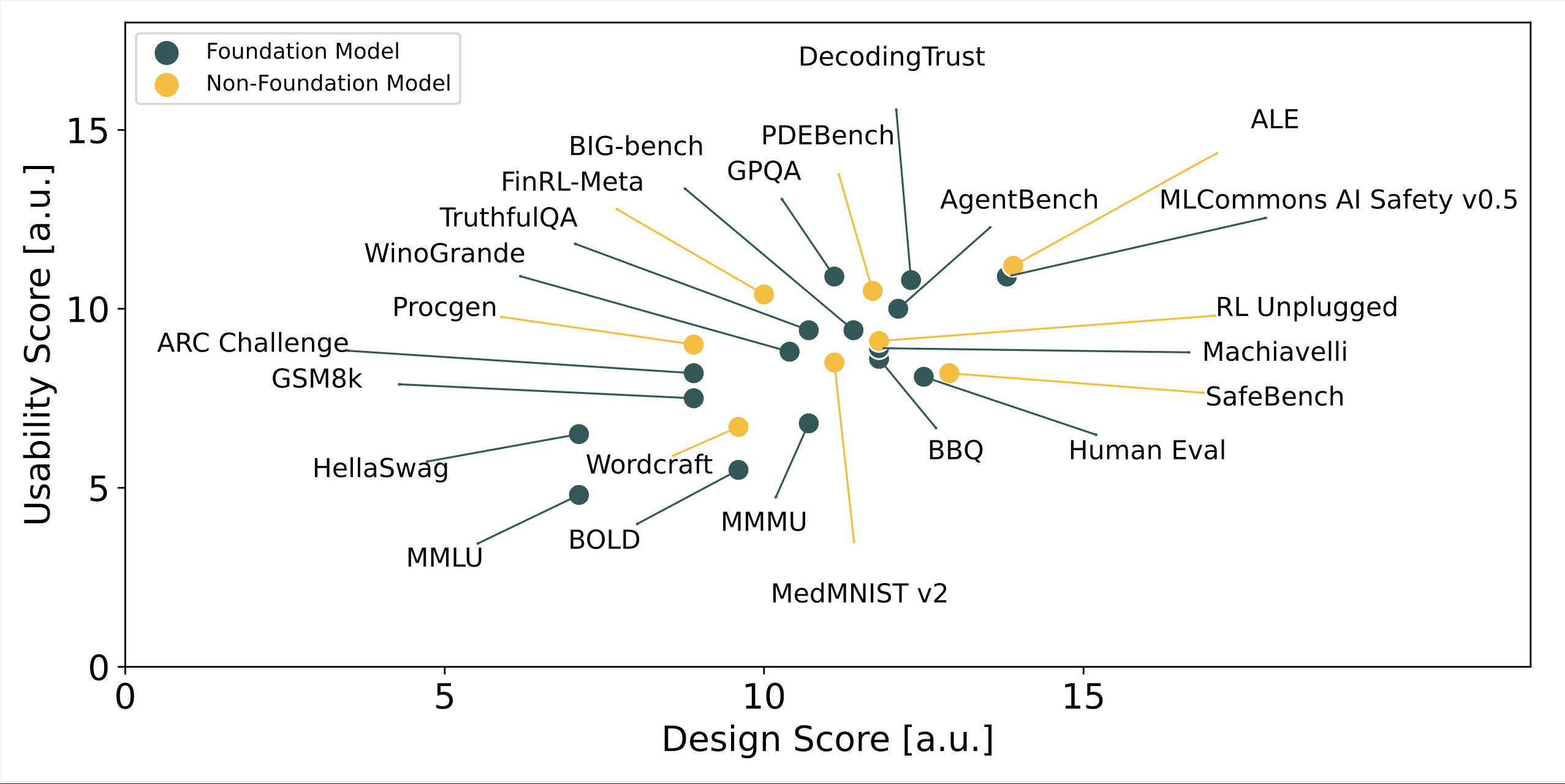
Contact: anka.reuel@stanford.edu, ahardy@stanford.edu
Award nominations: Spotlight (Datasets and Benchmarks Track)
Links: Paper | Website
Keywords: benchmarking, assessment, best practices, evaluation, benchmark
Consent in Crisis: The Rapid Decline of the AI Data Commons
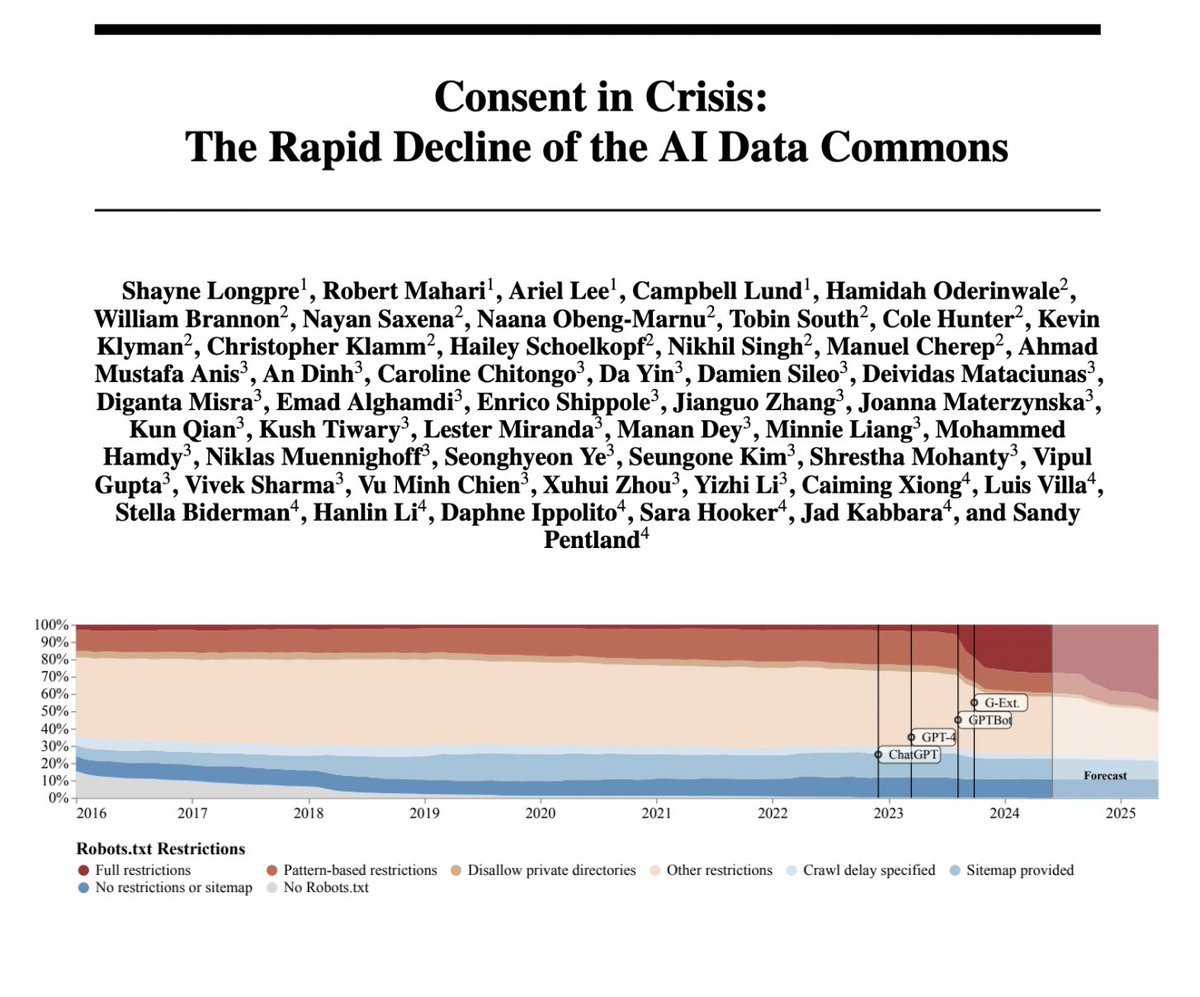
Contact: data.provenance.init@gmail.com
Links: Paper | Website
Keywords: training data, audits, text
DART-Eval: A Comprehensive DNA Language Model Evaluation Benchmark on Regulatory DNA

Contact: arpitas@stanford.edu
Links: Paper
Keywords: dna, language models, llms, biology, foundation models, benchmarks, gene regulation, healthcare
Geometric Trajectory Diffusion Models
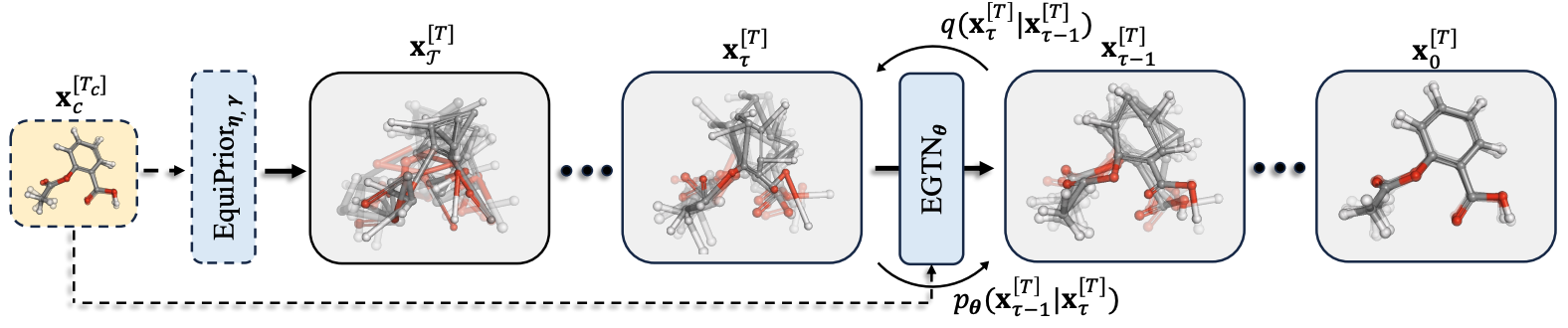
Contact: jiaqihan@stanford.edu
Links: Paper | Website
Keywords: diffusion models, trajectory generation
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
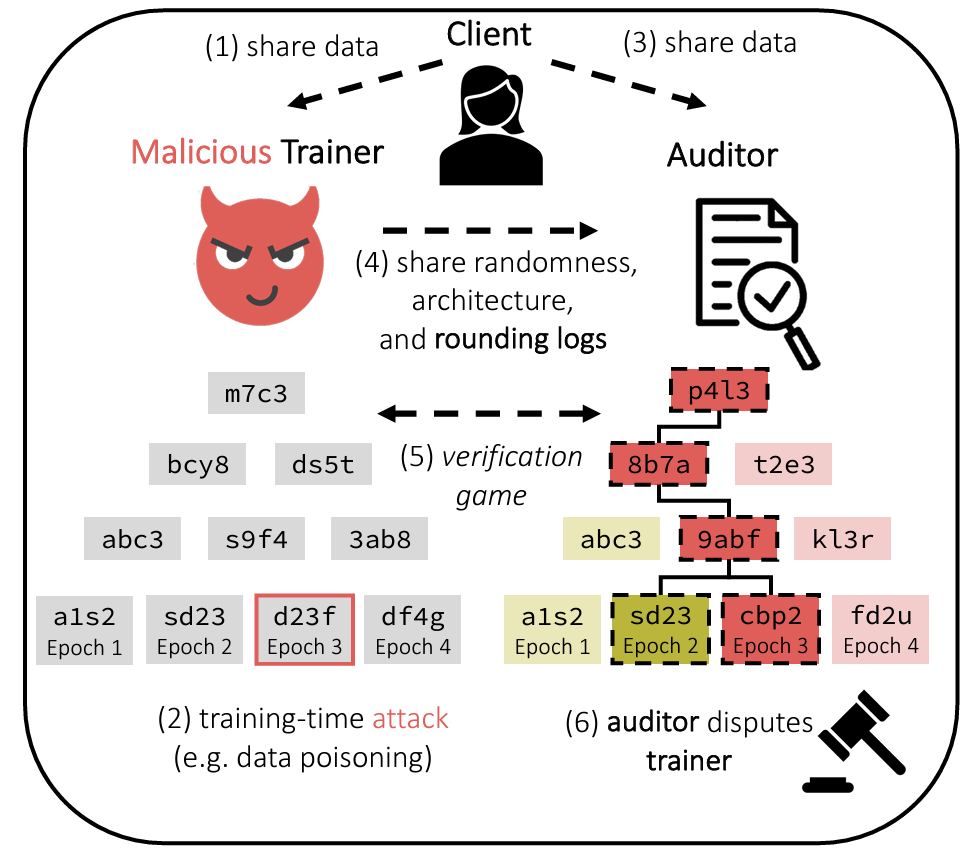
Contact: meghas@stanford.edu
Links: Paper | Website
Keywords: security, verification, robustness, reproducibility, systems
ReFT: Representation Finetuning for Language Models
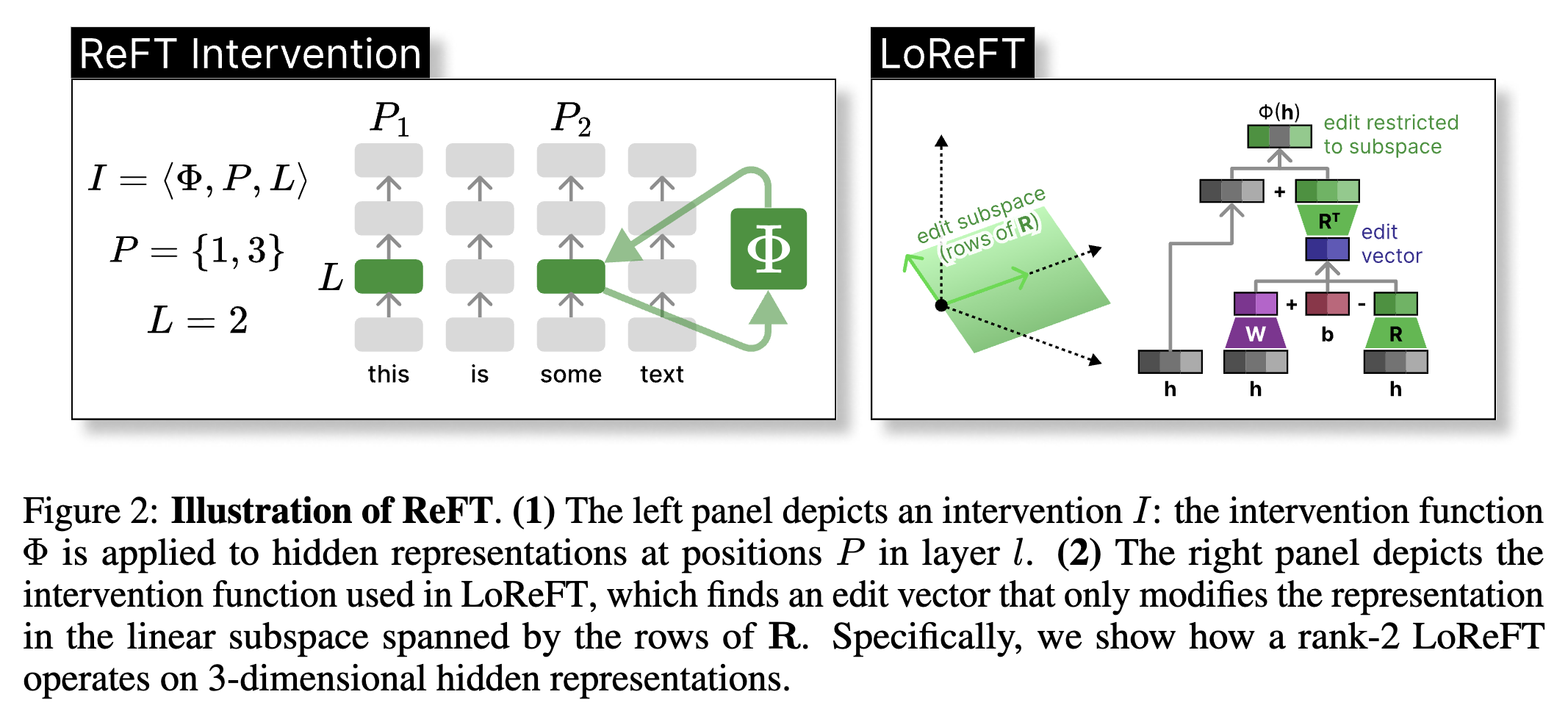
Contact: wuzhengx@stanford.edu, aryamana@stanford.edu
Links: Paper | Website
Keywords: interpretability, efficient training
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
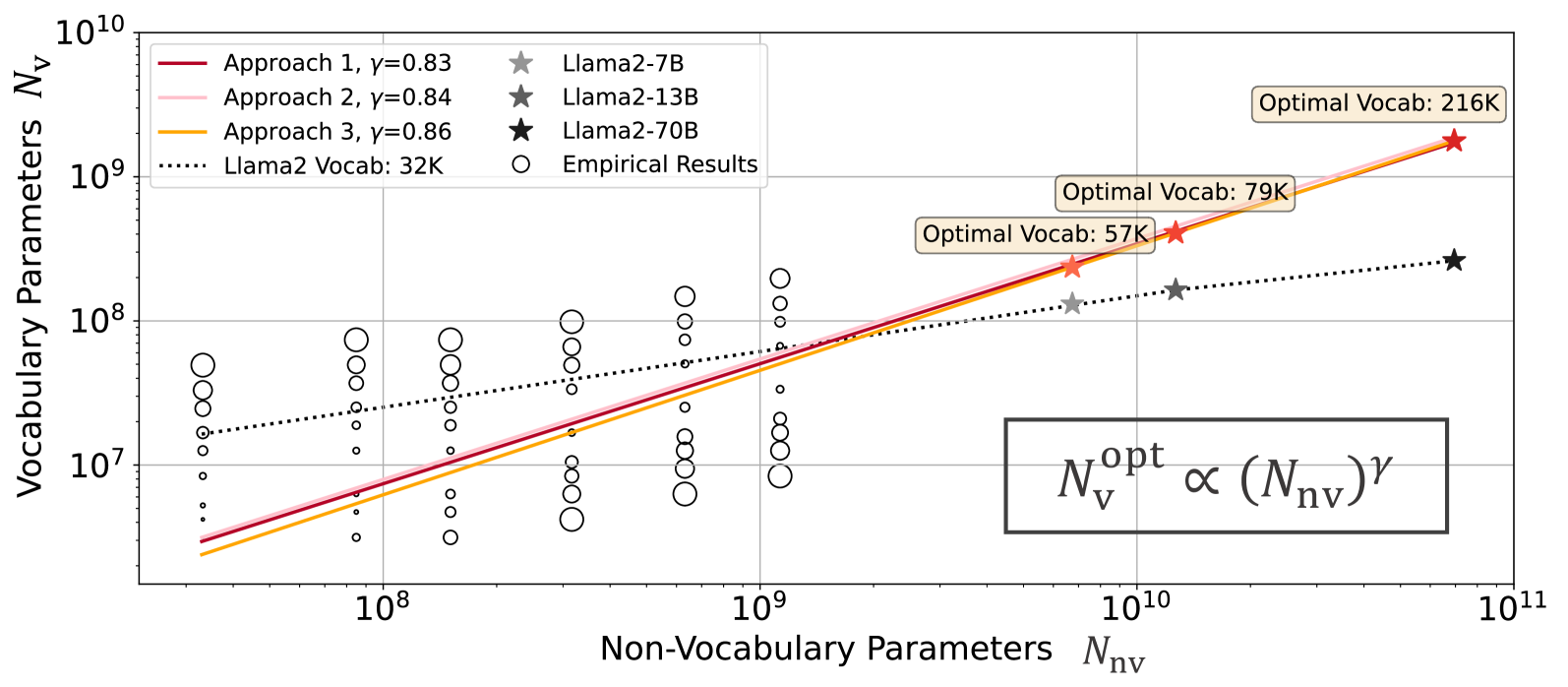
Contact: cftao@connect.hku.hk and liuqian.sea@gmail.com
Links: Paper | Website
Keywords: natural language processing, scaling laws, efficient neural networks, large language models
Smoothie: Label Free Language Model Routing

Contact: neelguha@gmail.com
Links: Paper
Keywords: routing, llms
Streaming Detection of Queried Event Start

Contact: ceyzagui@stanford.edu
Links: Paper | Website
Keywords: streaming,video,vlm,cv,online
Structured flexibility in recurrent neural networks via neuromodulation
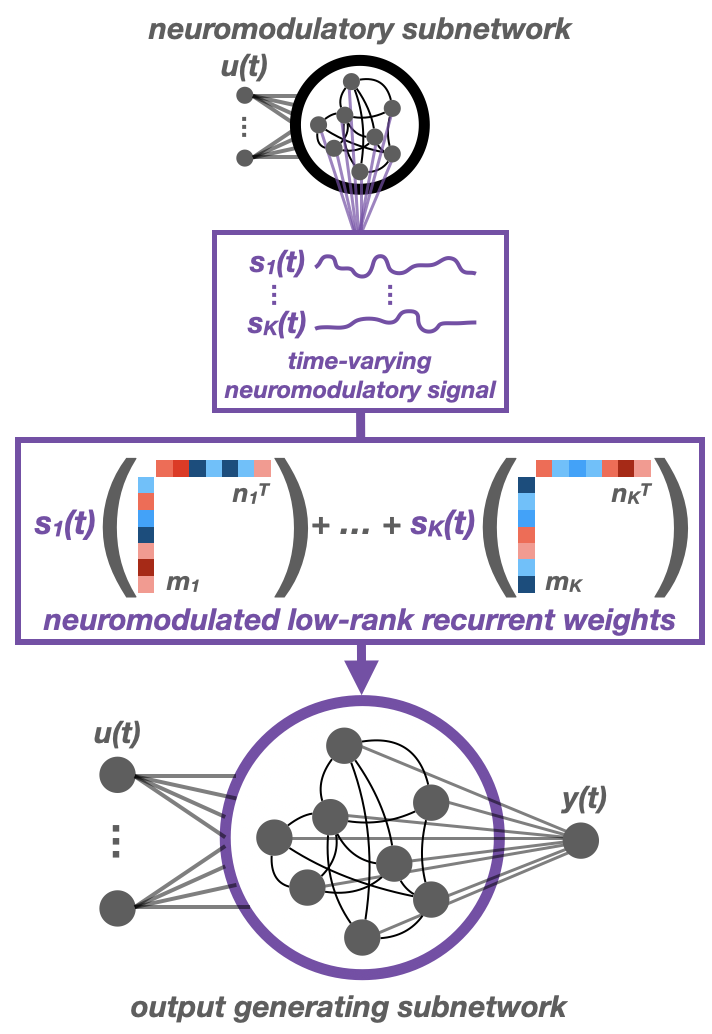
Contact: jcostac@stanford.edu
Links: Paper
Keywords: recurrent neural networks, neuroscience
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding

Contact: kenneth.enevoldsen@cas.au.dk
Links: Paper
Keywords: sentence embeddings, rag, low-resource nlp, danish, norwegian, swedish, scandinavian
Towards Scalable and Stable Parallelization of Nonlinear RNNs

Contact: xavier18@stanford.edu
Links: Paper | Blog Post | Video
Keywords: rnns, ssms, parallel algorithms, optimization
Why are Visually-Grounded Language Models Bad at Image Classification?

Contact: yuhuiz@stanford.edu
Links: Paper | Video | Website
Keywords: vision language model, image classification
Datasets and Benchmarks Track
UniTox: Leveraging LLMs to Curate a Unified Dataset of Drug-Induced Toxicity from FDA Labels
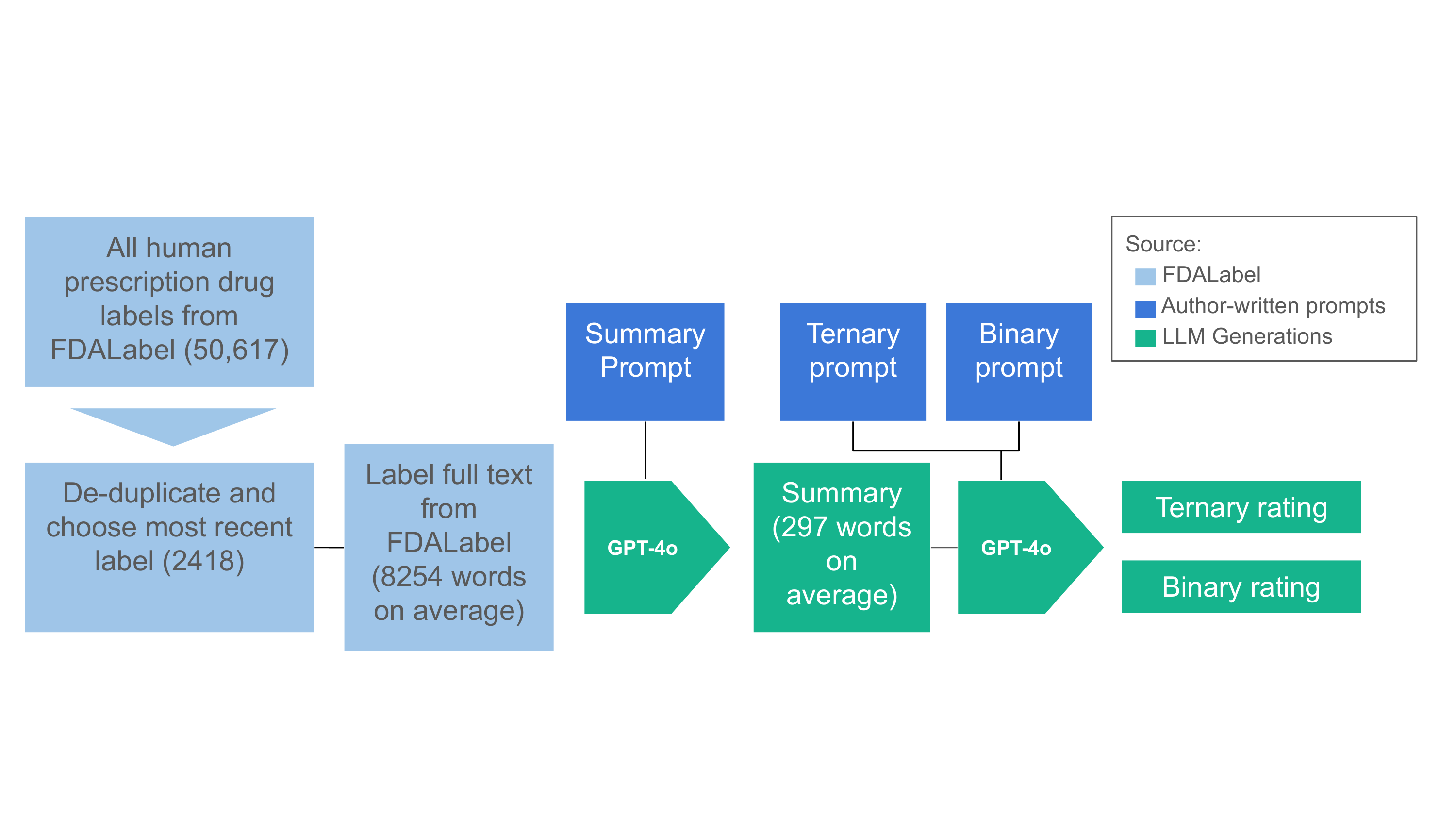
Contact: jsilberg@stanford.edu
Award nominations: Spotlight
Links: Paper | Blog Post | Website
Keywords: large language model, gpt, biomedicine, drug discovery, drug toxicity, drug safety
Workshop Papers
AI Governance and the Developmental Immaturity of the Science of AI Safety

Contact: reich@stanford.edu
Workshop: Regulatable ML Workshop
Keywords: ai governance, ai safety
On Short Textual Value Column Representation Using Symbol Level Language Models
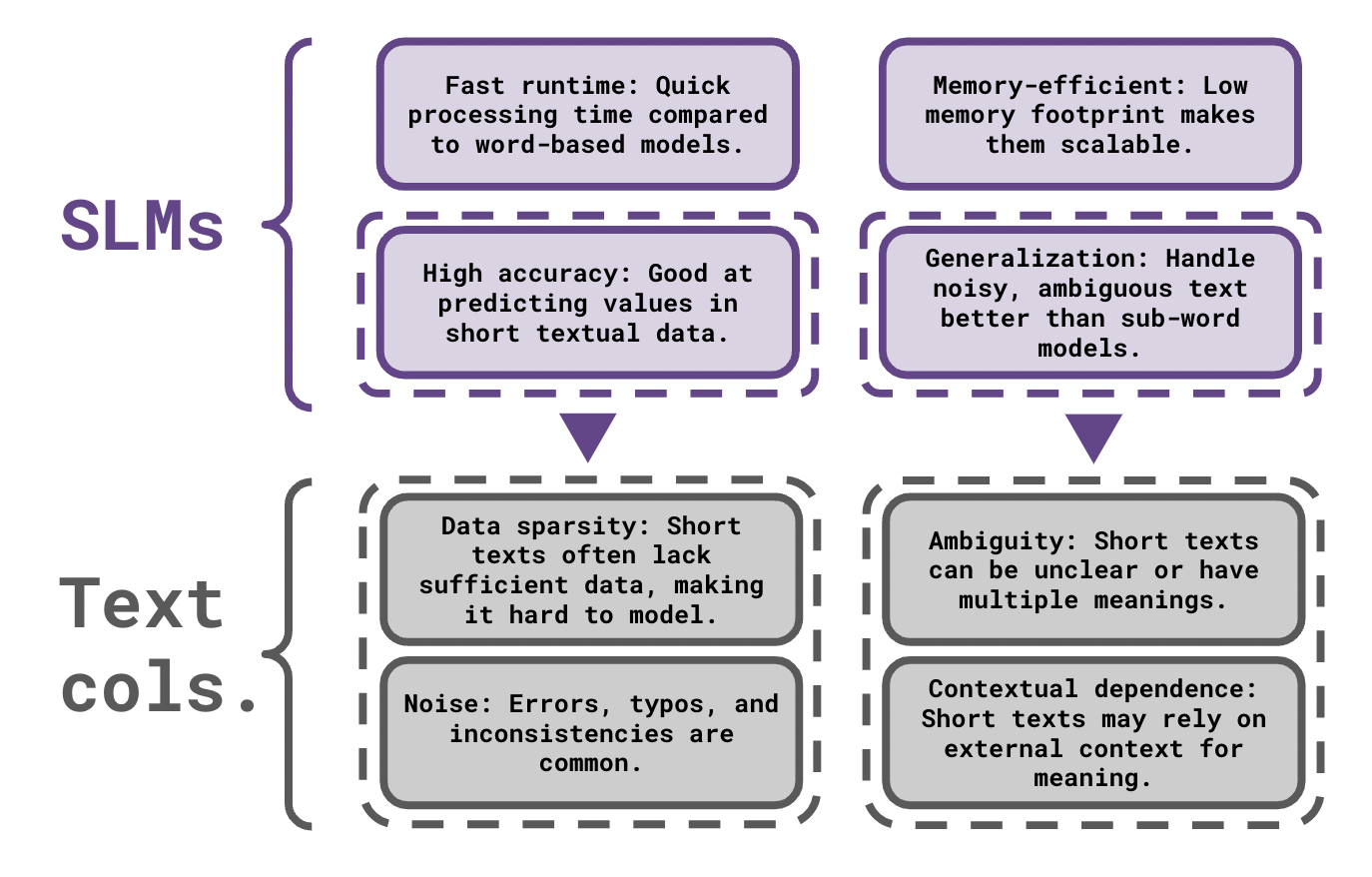
Contact: nroll@stanford.edu
Workshop: Table Representation Learning Workshop
Links: Paper
Keywords: symbol level language models, column matching
OLMoE: Open Mixture-of-Experts Language Models

Contact: niklasm@stanford.edu
Workshop: Efficient Natural Language and Speech Processing Workshop
Award nominations: Oral (Spotlight)
Links: Paper | Blog Post | Website
Keywords: large language models, mixture-of-experts, foundation models
Measuring Free-Form Decision-Making Inconsistency of Language Models in Military Crisis Simulations

Contact: lamparth@stanford.edu
Workshop: Socially Responsible Language Modelling Research Workshop
Links: Paper
Keywords: language models, ai safety, natural language processing, military, inconsistency, transparency
DivShift: Exploring Domain-Specific Distribution Shift in Large-Scale, Volunteer-Collected Biodiversity Datasets
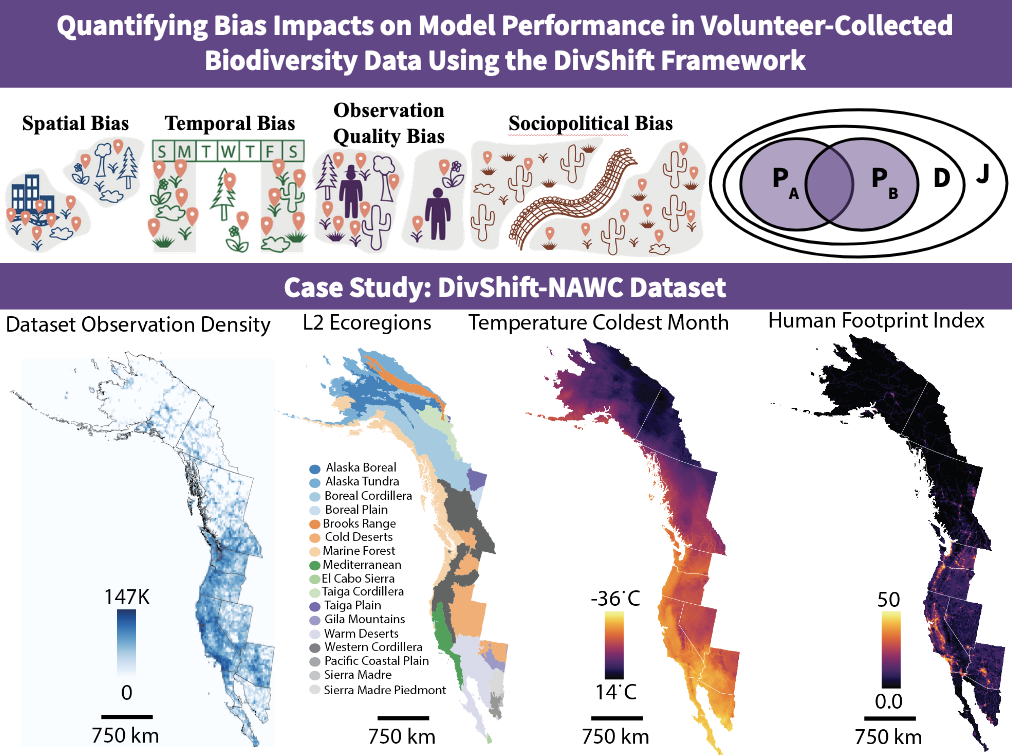
Contact: esierra@stanford.edu
Workshop: Tackling Climate Change with Machine Learning Workshop
Links: Paper | Video
Keywords: biodiversity, data bias
Intuitions of Compromise: Utilitarianism vs. Conctractualism

Contact: jlcmoore@stanford.edu
Workshop: Pluralistic Alignment Workshop
Links: Paper | Website
Keywords: value aggregation, nash product, expected utility, compromise, moral decision making, social welfare
We look forward to seeing you at NeurIPS this year!