This work was conducted as part of SAIL and CRFM.
Deep learning has enabled improvements in the capabilities of robots on a range of problems such as grasping 1 and locomotion 2 in recent years. However, building the quintessential home robot that can perform a range of interactive tasks, from cooking to cleaning, in novel environments has remained elusive. While a number of hardware and software challenges remain, a necessary component is robots that can generalize their prior knowledge to new environments, tasks, and objects in a zero or few shot manner. For example, a home robot tasked with setting the dining table cannot afford lengthy re-training for every new dish, piece of cutlery, or dining room it may need to interact with.
A natural way to enable such generalization in our robots is to train them on rich data sources that contain a wide range of different environments, tasks, and objects. Indeed, this recipe of massive, diverse datasets combined with scalable offline learning algorithms (e.g. self-supervised or cheaply supervised learning) has been the backbone of the many recent successes of foundation models 3 in NLP 456789 and vision 101112.
Replicating these impressive generalization and adaptation capabilities in robot learning algorithms would certainly be a step toward robots that can be used in unstructured, real world environments. However, directly extending this recipe to robotics is nontrivial, as we neither have sufficiently large and diverse datasets of robot interaction, nor is it obvious what type of supervision can enable us to scalably learn useful skills from these datasets. On one hand, the popular imitation learning approach relies on expert data which can be expensive to obtain at scale. On the other hand, offline reinforcement learning, which can be performed using non-expert and autonomously-collected data, requires us to define a suitable reward function. Hard-coded reward functions are often task-specific and difficult to design, particularly in high-dimensional observation spaces. Getting rewards annotated post-hoc by humans is one approach to tackling this, but even with flexible annotation interfaces 13, manually annotating scalar rewards for each timestep for all the possible tasks we might want a robot to complete is a daunting task. For example, for even a simple task like opening a cabinet, defining a hardcoded reward that balances the robot’s motion to the handle, grasping the handle, and gradually rewarding opening the cabinet is difficult, and even more so when it needs to be done in a way that is general across cabinets.
So how can we scalably supervise the reward learning process? In this blog post I’ll share some recent work that explores using data and supervision that can be easily collected through the web as a way of learning rewards for robots. Specifically, I’ll begin by discussing how we can leverage tools like crowdsourcing natural language descriptions of videos of robots as a scalable way to learn rewards for many tasks within a single environment. Then, I’ll explore how training rewards with a mix of robot data and diverse “in-the-wild” human videos (e.g. YouTube) can enable the learned reward functions to generalize zero-shot to unseen environments and tasks.
Reward Learning via Crowd-Sourced Natural Language
What if all we needed to learn a reward was a description of what is happening in a video? Such an approach could be easily applied to large datasets with many tasks using crowdsourcing. Note that this is much simpler than obtaining crowdsourced annotations of scalar rewards, which requires annotators to have some intuition for what actions deserve a high reward or follow a consistent labeling scheme.
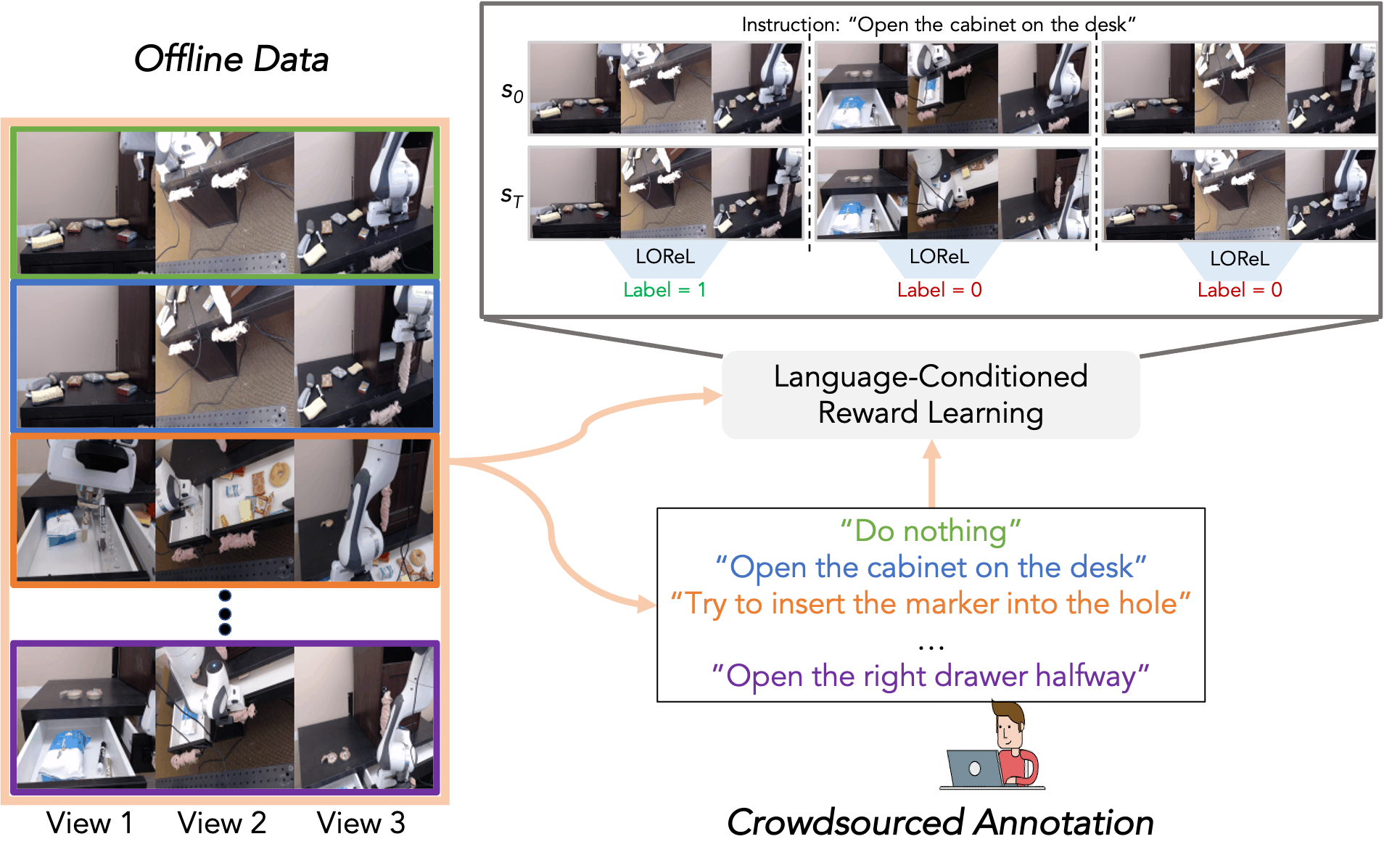
In our recent paper, we studied this problem by reusing a non-expert dataset of robot interaction, and crowdsourcing language descriptions of the behavior happening in each video. Specifically, each video is annotated with a single natural language description describing what task (if any) the robot completes. For our experiments we used Amazon Mechanical Turk (AMT) to crowdsource natural language descriptions of each episode in a replay buffer of a Franka Emika Panda robot operating over a desk 14 (See Figure 1). The dataset consisted of a mix of successful and unsuccessful attempts at many tasks like picking up objects and opening or closing the drawers.

We then used these annotations to train a model (starting with a pre-trained DistilBert 15 model) to predict if the robot’s behavior completes a language-specified command (See Figure 2). Specifically, our method, Language-conditioned Offline Reward Learning (LOReL), simply learns a classifier which takes as input text, and a pair of states (images), and predicts if transitioning between the states completes the text instruction. We can easily generate positives for training this classifier by taking state transitions in our annotated data, and can generate negatives by randomly permuting the human provided annotations.
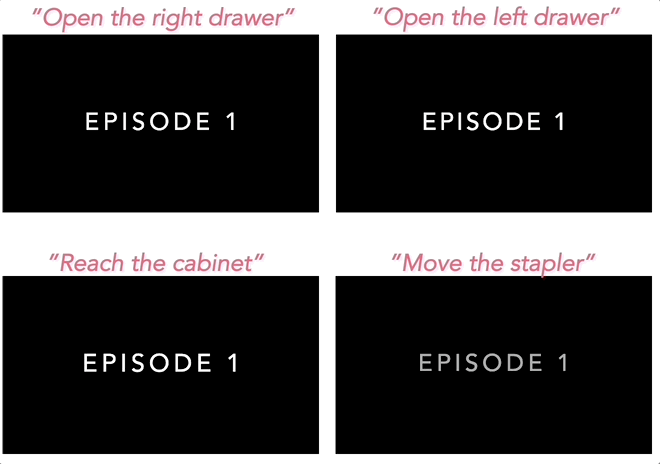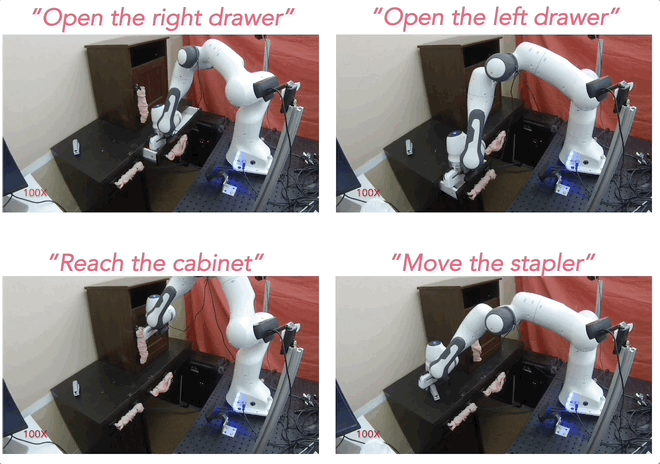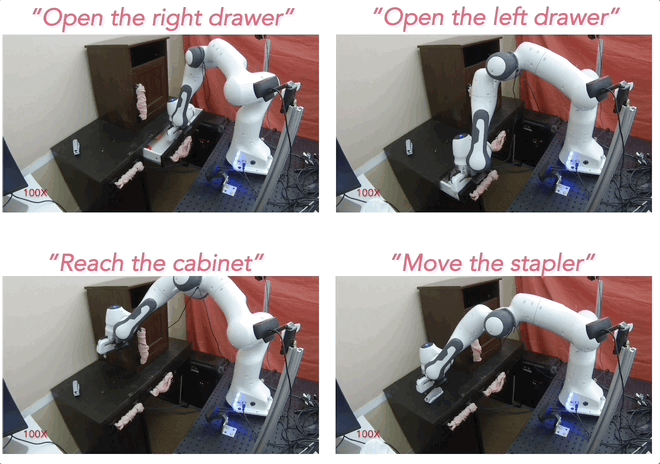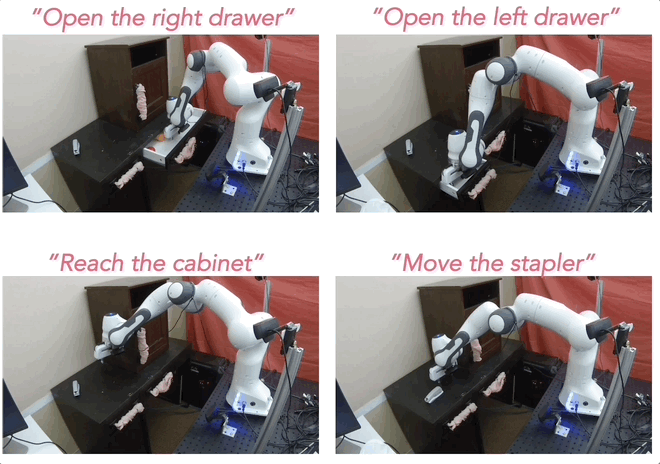
Given this procedure for generating rewards, policies can be learned using any off-the-shelf reinforcement learning algorithm. In our case, we use Visual Model-Predictive Control (VMPC) 16, which learns a task-agnostic visual dynamics model, and performs model-predictive control with it to maximize the LOReL reward (see Figure 3).
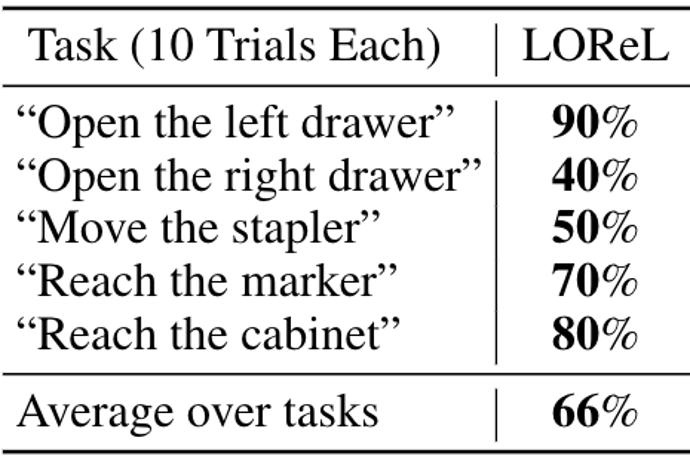
Thus, we were able to supervise reward learning in robots with simple crowdsourcing of natural language descriptions. However much is left to be desired. Although we found that LOReL enabled robots to successfully complete tasks seen in the training set with some robustness to rephrasing, it did not yet generalize well to instructions for tasks that were not in the training set. Thinking back to our original goals, we’d like our learned rewards to generalize broadly to new tasks and environments.
How might we learn a reward that can generalize across tasks and environments instead of just different formulations of the same command? We hypothesized that an important step in achieving this goal was to leverage data with scale and diversity. Unfortunately, even using methods that can learn from non-expert, autonomously-collected data, we still have limited physical robot datasets with diversity across behaviors and environments. Until we have robot datasets of sufficient diversity, how can we learn to generalize across environments and tasks?
Boosting Generalization with Diverse Human Videos
Sticking with the theme of supervision that exists on the web, “in-the-wild” human videos like those that exist on YouTube are diverse, plentiful, and require little effort to collect. Of course there are numerous challenges in working with such data, from the visual domain shift to the robots environment, to the lack of a shared action space. But if we could learn from a massive number of “in-the-wild” videos, could we generalize better akin to large language and vision models?
We investigate this question in another recent work, where we examine the extent to which “in-the-wild” human videos can enable learned reward functions to better generalize to unseen tasks and environments. Specifically, we consider the setting where during training the agent learns from a small amount of robot data of a few tasks in one environment and a large amount of diverse human video data, and at test time tries to use the reward on unseen robot tasks and environments (See Figure 4).
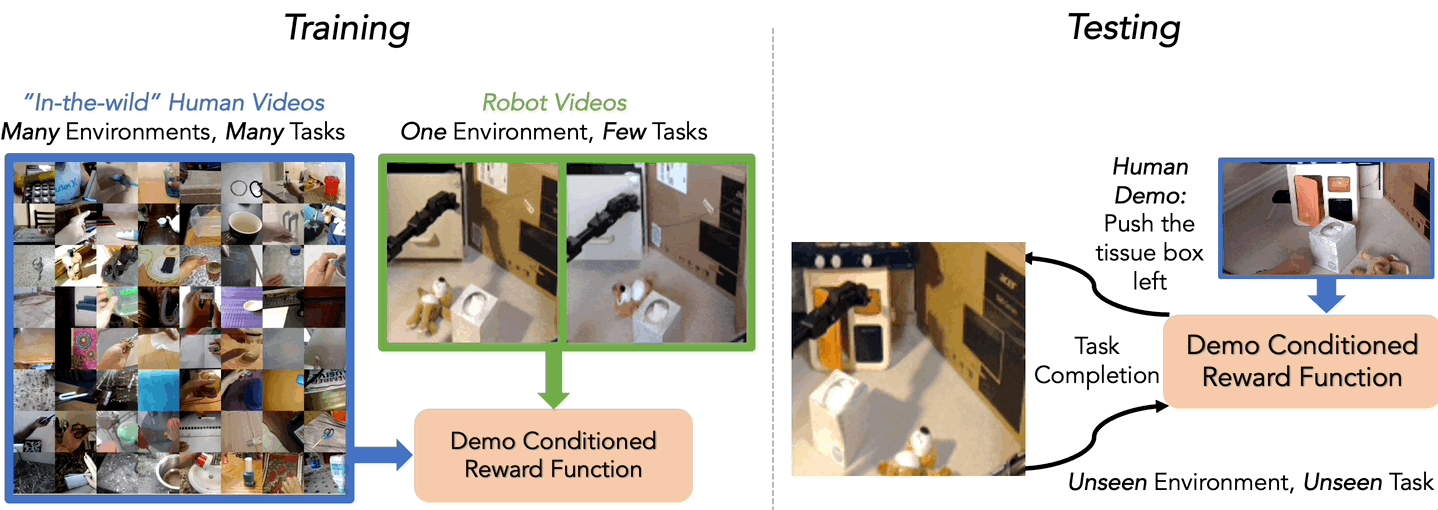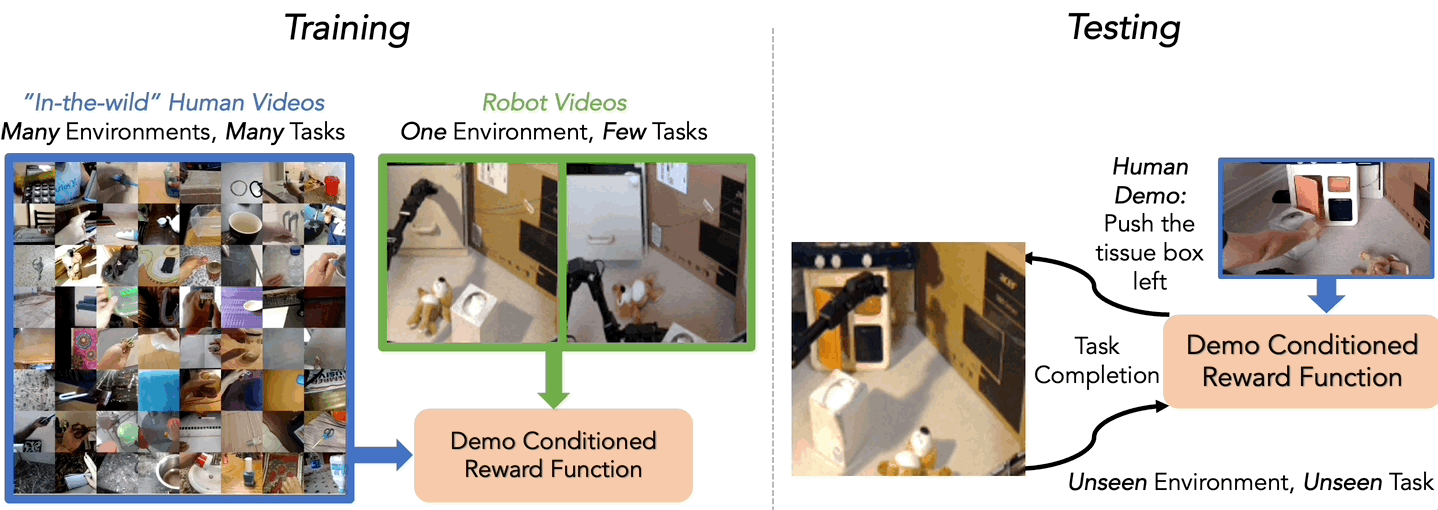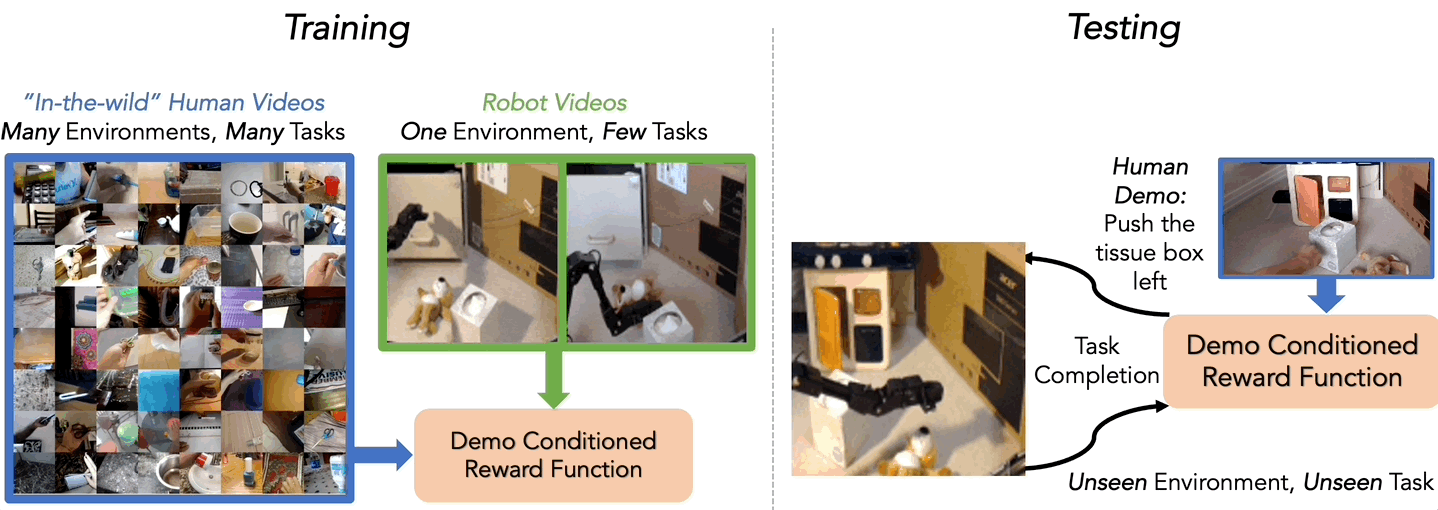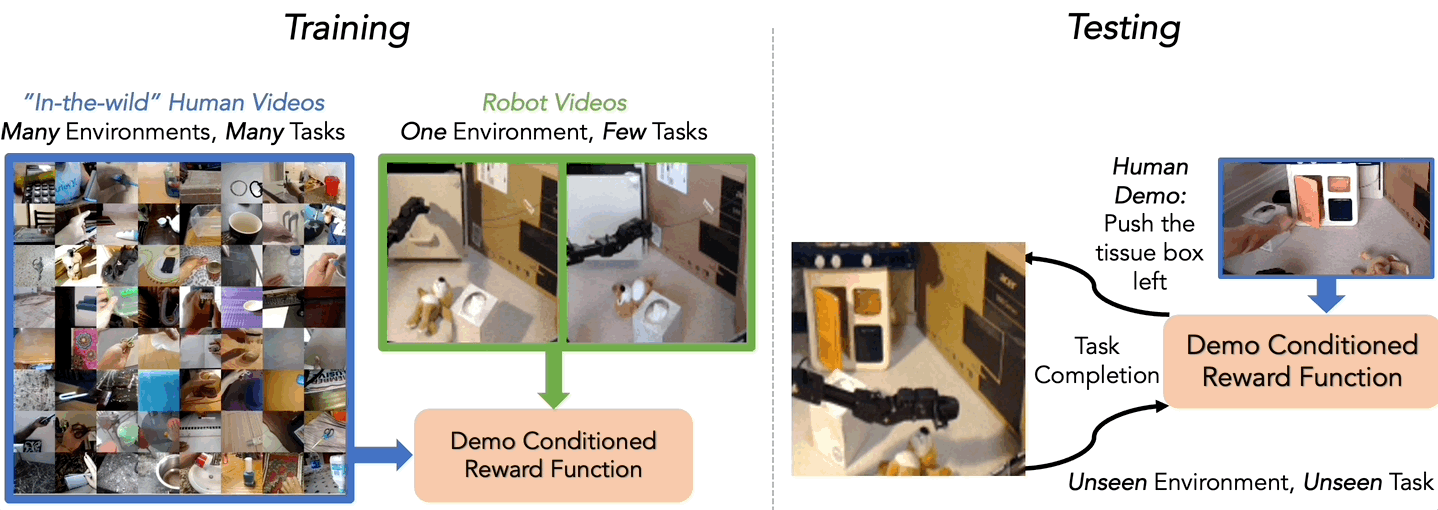
Our approach to learning from these human videos (in this case the Something-Something 17 dataset) is simple. We train a classifier, which we call Domain-Agnostic Video Discriminator (DVD), from scratch on a mix of robot and human videos to predict if two videos are completing the same task or not (See Figure 5).

Conditioned on a task specification (human video of a task) as one video, and the robot behavior as the other video, the DVD score acts as a reward function that can be used for reinforcement learning. Like in LOReL, we combined the DVD reward with visual model predictive control (VMPC) to learn human video conditioned behavior (See Figure 6).

Now, we would like to understand - does training with diverse human videos enable improved generalization? To test this, we designed a number of held out environments, with different viewpoints, colors, and object arrangement (See Figure 7).

We then measured the learned DVD success rate on these unseen environments (See Figure 8 (left)) as well as unseen tasks (See Figure 8 (right)) when training with and without human videos. We found that using human videos enabled over a 20+% improvement in success rate in the unseen environments and on unseen tasks over using only robot data.
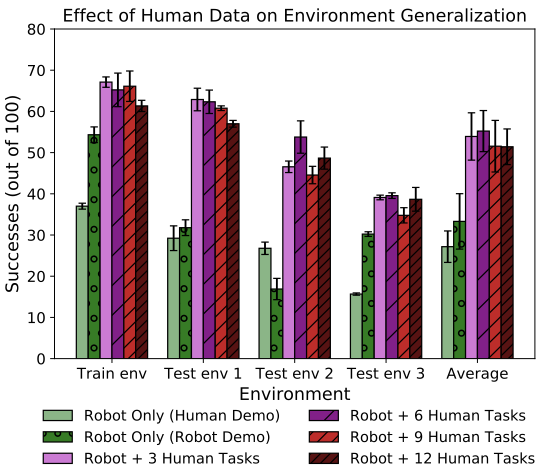
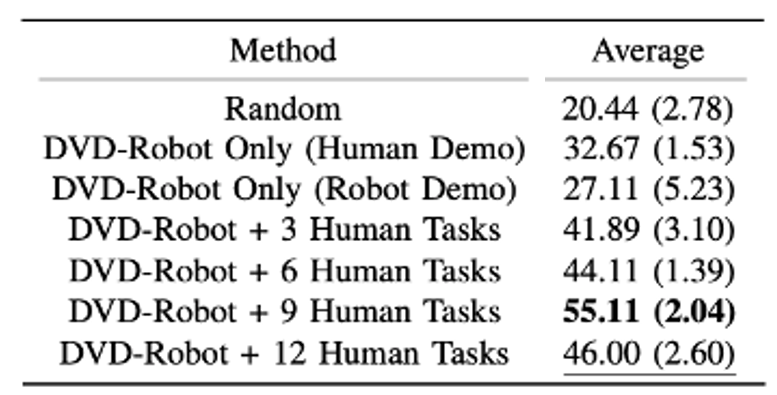
Despite the massive domain shift between the human videos and robot domain, our results suggest that training with diverse, “in-the-wild” human videos can enable learned reward functions to generalize more effectively across tasks and environments.
Conclusion
In order to move towards broad generalization in robotics, we need to be able to learn from scalable sources of supervision and diverse data. While most current robot learning methods depend on costly sources of supervision, such as expert demonstrations or manually engineered reward functions, this can be a limiting factor in scaling to the amount of data we need to achieve broad generalization.
I’ve discussed two works that use supervision that is easily acquired through the web, specifically (1) crowd-sourced natural language descriptions of robot behavior, and (2) “in-the-wild” human video datasets. Our results suggest these approaches can be an effective way of supervising reward learning and boosting generalization to unseen environments and tasks at low cost. To learn more about these projects check out the LOReL and DVD project pages which include videos and links to the code.
This blog post is based on the following papers:
-
“Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation” Suraj Nair, Eric Mitchell, Kevin Chen, Brian Ichter, Silvio Savarese, Chelsea Finn. CoRL 2021.
-
“Learning Generalizable Robotic Reward Functions from “In-The-Wild” Human Videos” Annie S. Chen, Suraj Nair, Chelsea Finn. RSS 2021.
Finally, I would like to thank Ashwin Balakrishna, Annie Chen, as well as the SAIL editors Jacob Schreiber and Sidd Karamcheti and CRFM editor Shibani Santurkar for their helpful feedback on this post.
-
Kalashnikov, D., Irpan, A., Pastor, P., Ibarz, J., Herzog, A., Jang, E., Quillen, D., Holly, E., Kalakrishnan, M., Vanhoucke, V., Levine, S. (2018). QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. Conference on Robot Learning. ↩
-
Kumar, A., Fu, Z., Pathak, D., Malik, J. (2021). RMA: Rapid Motor Adaptation for Legged Robots. Robotics Science and Systems. ↩
-
Bommasanimi, R. et al. (2021). On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258. ↩
-
Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., Zettlemoyer, L. (2018). Deep contextualized word representations. Conference of the North American Chapter of the Association for Computational Linguistics. ↩
-
Devlin, J., Chang, M., Lee, K., Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805. ↩
-
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692. ↩
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K, Narang, S, Matena, M., Zhou, Y., Li, W, Liu, P. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research. ↩
-
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., Stoyanov, V. (2020). Unsupervised Cross-lingual Representation Learning at Scale. Annual Meeting of the Association for Computational Linguistics. ↩
-
Brown et al. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165 ↩
-
Deng, J., Dong, W., Socher, R., Li, L., Li, K, Fei-Fei, L. (2009). ImageNet: A large-scale hierarchical image database. IEEE International Conference on Computer Vision and Pattern Recognition. ↩
-
Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020. ↩
-
Yuan, L. et al. (2021). Florence: A New Foundation Model for Computer Vision. arXiv preprint arXiv:2111.11432. ↩
-
Cabi, S. et al. (2020). Scaling data-driven robotics with reward sketching and batch reinforcement learning. Robotics Science and Systems. ↩
-
Wu, B., Nair, S., Fei-Fei, L., Finn, C. (2021). Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks. Conference on Robot Learning. ↩
-
Sanh, V., Debut, L., Chaumond, J., Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. Neural Information Processing Systems. ↩
-
Finn, C., Levine, S. (2017). Deep Visual Foresight for Planning Robot Motion. IEEE International Conference on Robotics and Automation. ↩
-
Goyal, R. et al. (2017). The “something something” video database for learning and evaluating visual common sense. International Conference on Computer Vision. ↩