Vision-Language-Action models (VLAs) are a popular recipe for generalist robot policies: take a vision-language model pretrained on internet-scale image-text data, then continue training it on (comparatively scarce) robot demonstrations. A growing trend pushes these models to reason before they act by training the model to emit an intermediate chain-of-thought (CoT) that bridges high-level intent and low-level control, much like step-by-step thinking for language models.
But what should a robot actually think about? Currently, reasoning VLAs usually have a fixed, hand-designed template: enumerate every visible object’s bounding box, create a high-level plan, describe affordances, identify the end-effector gripper position, and so on, at every single step. This reasoning trace is expensive to design as teams spend months writing annotation guidelines. More fundamentally, it may be the wrong thing to think about. Listing every object in a cluttered scene can drown out the one cue that matters. Re-planning at every timestep can be redundant. Verbose reasoning also slows the policy down at test time, where generating a few seconds of text per control step creates real lag.
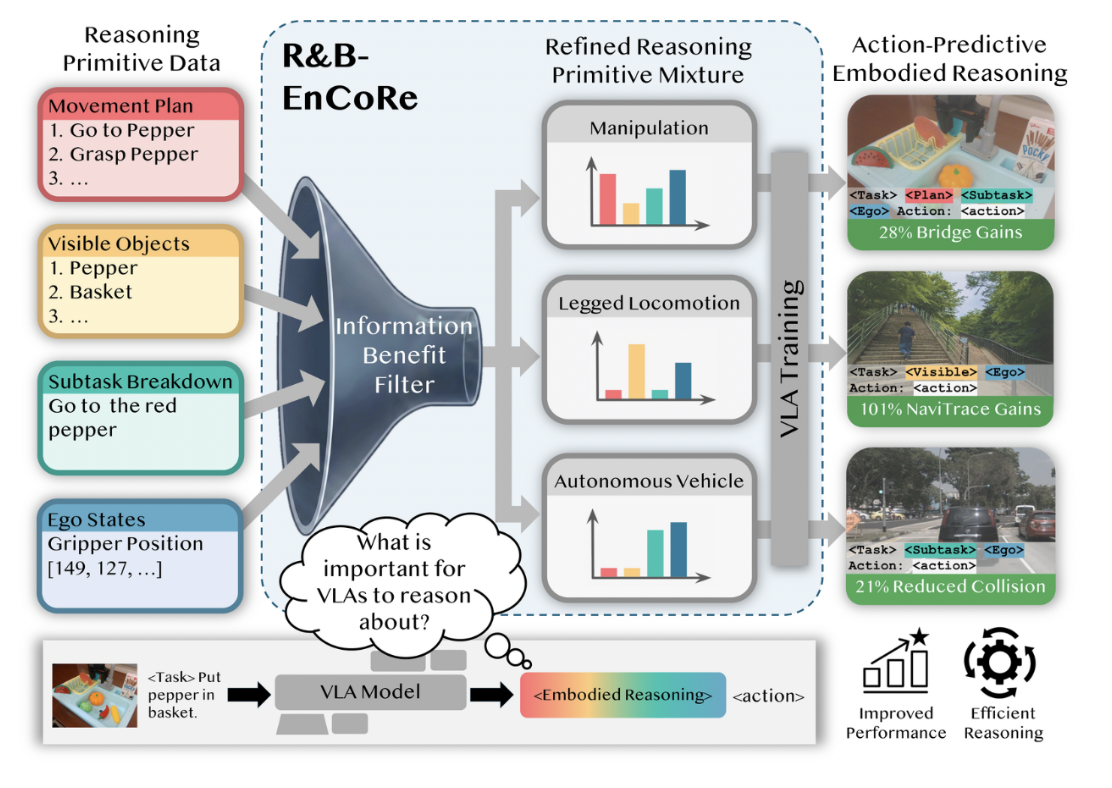
In our paper “Self-Supervised Bootstrapping of Action-Predictive Embodied Reasoning,” we introduce R&B-EnCoRe (short for Refine and Bootstrap Embodiment-specific Chain-of-Thought Reasoning), which is a self-improvement pretraining cycle for embodied reasoning VLAs. Instead of relying on a fixed reasoning template, the model generates its own candidate reasoning, refines it by measuring how much each piece of CoT reasoning actually helps predict the correct action, and bootstraps a stronger policy by retraining on the refined data. The whole cycle is self-supervised: no external rewards, no verifiers, no human annotation.
Why pretraining embodied reasoning has to be self-supervised
At the core of embodied reasoning, we face a circular dependency. Unlike language and vision domains where there is a massive amount of data in the form of documents and captions, robotics does not have internet-scale corpora that link reasoning to correct actions. So how do we know whether a particular thought actually helped the robot move correctly? To validate reasoning, we’d want a policy that already grounds reasoning in physical action. But to train that policy, we’d want validated reasoning data. Without quality reasoning we can’t build a robust policy; without a robust policy we can’t tell which reasoning was any good.
This chicken-and-egg problem is exactly why pretraining embodied reasoning has to be self-supervised. The policy and its reasoning data have to support and align with each other. Our key insight is to not treat reasoning as a fixed annotation and instead treat it as an unobserved latent variable Z that explains the relationship between the observed context C (the scene image and task) and the observed action A (the expert demonstration). Good reasoning is whatever best explains why the expert action was correct.
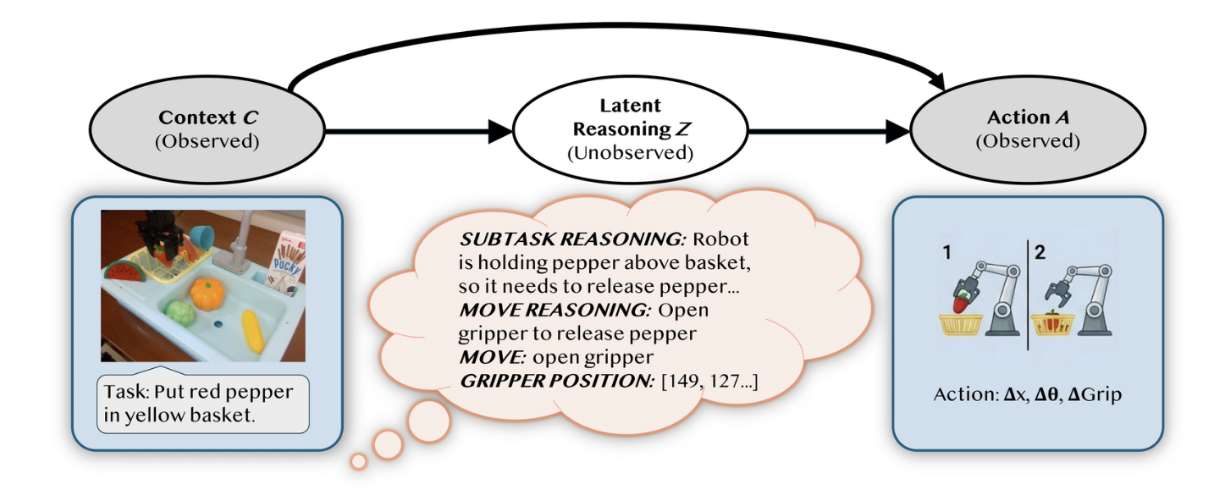
This framing enables us to bring in the well-developed machinery of variational inference. If reasoning is a latent variable, we can use importance-weighted sampling to estimate which reasoning traces make the expert’s action most probable and keep those. This estimate drives our self-improvement pretraining cycle.
The self-improvement cycle: generate → train → refine & bootstrap
R&B-EnCoRe runs as a loop with three stages. A pass through the loop turns the model’s own reasoning into better training data for the next policy.

Generate (warmstart). We start by hypothesizing a set of candidate reasoning primitives, such as high-level plans, visible objects, subtask breakdowns, meta-action descriptions, gripper position, affordances, terrain, and so on. We obtain text for each by querying foundation models in a visual-question-answering style (or by reusing existing human annotations). Crucially, rather than always concatenating all primitives, we apply Reasoning Dropout. Each primitive is independently kept or dropped with some probability, generating traces that range from sparse to verbose. This seeds the cycle with many possible reasoning strategies instead of one rigid template.
Jointly train a prior and a posterior. On this warmstart data we train a single VLA to play two roles, mirroring the encoder–decoder structure of a variational autoencoder. The prior p(Z, A | C) conditions only on the context. This is the same structure as the online policy that will generate reasoning and then act. The posterior q(Z | C, A) additionally conditions on the ground-truth action as it learns to propose reasoning that explains why that action was right in hindsight. Together the posterior and prior distributions let the model “explain” and “critique” its own proposed actions through reasoning.
Refine and bootstrap by information benefit. For each demonstration we draw K candidate traces from the posterior and score each one with an importance weight w(Z) = p(Z, A | C) / q(Z | C, A). We then resample a single trace per demonstration in proportion to these weights. We prove that this ratio captures a quantity we call the information benefit of a reasoning strategy: how much a particular reasoning primitive reduces the divergence between the policy’s action distribution and the expert’s. Intuitively, primitives that make the correct action more predictable get amplified; distracting or redundant ones get suppressed. Finally we retrain the VLA on this refined, self-curated dataset of action-predictive traces. The resulting policy reasons about what actually matters for control.
What the cycle discovers
The most telling output of the self-improvement cycle isn’t just a higher score, but rather the reasoning distribution the model converges to for each embodiment. These distributions are interpretable, and they differ in sensible ways across different robot form factors.

For manipulation, the model gravitates toward short meta-action descriptions (“Move”), gripper position, and subtasks, while pruning exhaustive object enumeration; it also prefers the concise “Subtask”/”Move” primitives over their verbose “Explain” counterparts, cutting average token count roughly in half. For legged navigation, all four robots (bipedal, wheeled, bicycle, quadruped) converge on affordances (the actionable capabilities of the terrain) and proposed movements, while counterfactual reasoning drops sharply. For autonomous driving, the cycle retains goal and object-related cues while down-weighting hallucinated “experience.”
The cycle improves policies across embodiments and scales
The self-improvement cycle helps consistently, across very different embodiments and model sizes (1B, 4B, 7B, and 30B parameters).
Manipulation (LIBERO-90, 1B MiniVLA; Bridge WidowX hardware, 7B OpenVLA). R&B-EnCoRe improves manipulation success by 28% over reasoning on all primitives, while halving reasoning length. On the perception side in the LIBERO-90 simulator, the cycle learns to attend to task-salient objects rather than every object in the scene.
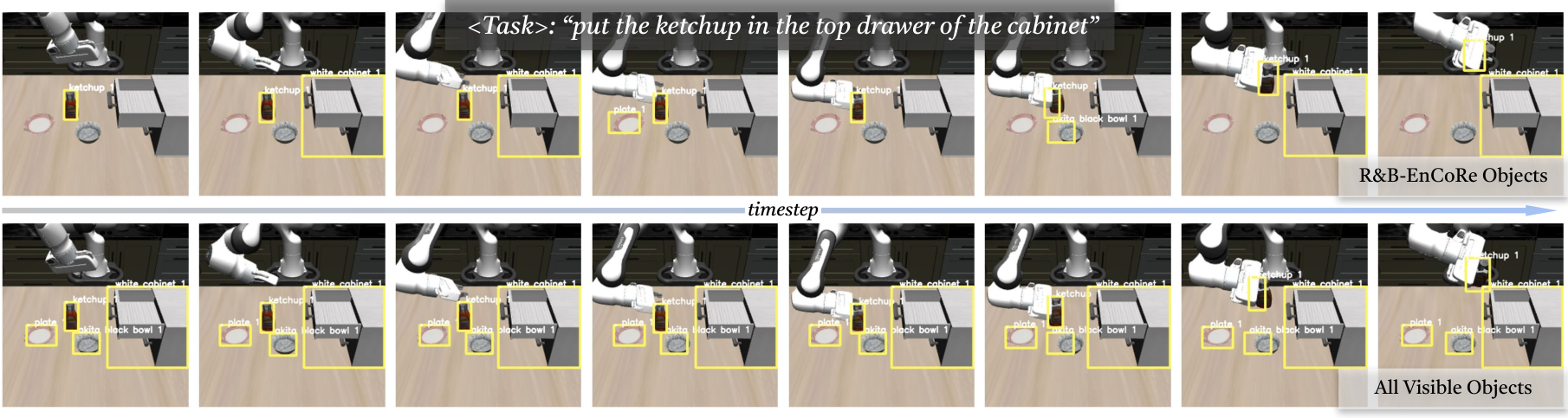
On real WidowX hardware, when reasoning is generated at test time, R&B-EnCoRe holds up far better on out-of-distribution scenes with distractor objects (where the all-primitives baseline degrades by 31%) and cuts inference from over 5 seconds to about 3 seconds per step by producing concise traces.


Legged navigation (NaviTrace, 30B Qwen3-VL MoE). Here the cycle refines the model’s own self-generated VQA traces. This is a fully self-improving loop where the VLM both writes and curates its reasoning, improving the downstream navigation score by 101%.

Autonomous driving (nuScenes, 4B Qwen3-VL). Refining human-crafted reasoning traces yields a 21% reduction in the collision-rate metric, with concise reasoning that is more informative than not reasoning at all. We also observed that performance improves with the number of posterior samples K, exactly the behavior the importance-weighting theory predicts.

A consistent theme across all of these: selective reasoning beats exhaustive reasoning. Through R&B-EnCoRe, a VLA can discover which reasoning to keep by improving on its own.
Takeaways
R&B-EnCoRe turns the chicken-and-egg problem of embodied reasoning into a self-improvement pretraining cycle. By treating reasoning as a latent variable and refining it through importance-weighted variational inference, a VLA can distill internet-scale priors into concise, embodiment-specific reasoning that is predictive of successful control—without rewards, verifiers, or human annotation. Notably, the cycle’s strength comes from the diversity of candidate primitives rather than their individual quality: informative ones are automatically up-weighted and vice versa.
We validated this across manipulation, legged locomotion, and autonomous driving on 1B, 4B, 7B, and 30B parameter models. Our work points toward self-improving policies that learn not just to act, but to ask the right questions before acting.
Paper and code
This work is by Milan Ganai, Katie Luo, Jonas Frey, Clark Barrett, and Marco Pavone (Stanford, UC Berkeley, and NVIDIA).
- Website: https://milanganai.github.io/rnb-encore/
- Paper: Self-Supervised Bootstrapping of Action-Predictive Embodied Reasoning
- Code: https://github.com/rnb-encore
- Models: https://huggingface.co/collections/stanfordasl/rnb-encore
Citation:
@INPROCEEDINGS{GanaiLuoEtAl-2026RnB-EnCoRe,
AUTHOR = {Milan Ganai AND Katie Luo AND Jonas Frey AND Clark Barrett AND Marco Pavone},
TITLE = ,
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2026},
ADDRESS = {Sydney, Australia},
MONTH = {July}
}