Most robotic manipulation systems use the same design: a classic 6-DOF industrial arm with one or two wrist or environment-mounted cameras. This has been the standard playbook for decades–but what if we threw that playbook out the window?

What if we built robots that look nothing like before—and discover they can do things traditional robots never could? Our recent works explore this by asking: what happens when we give robots way more eyes, way more joints, or completely reimagine their shape from scratch?
RoboPanoptes: The All-Seeing, Snake-Like Robot 1
Meet RoboPanoptes—a robot that has eyes everywhere and the flexibility to use its entire body as a tool.

The design philosophy is simple: more cameras provide more information, and more joints enable more flexibility. So why not maximize both?
We start with a modular building block, with one servo motor (with one rotational degree of freedom) and two tiny USB cameras. Chain many of these modules together, add a hook-shaped head module at the end, and you get RoboPanoptes.
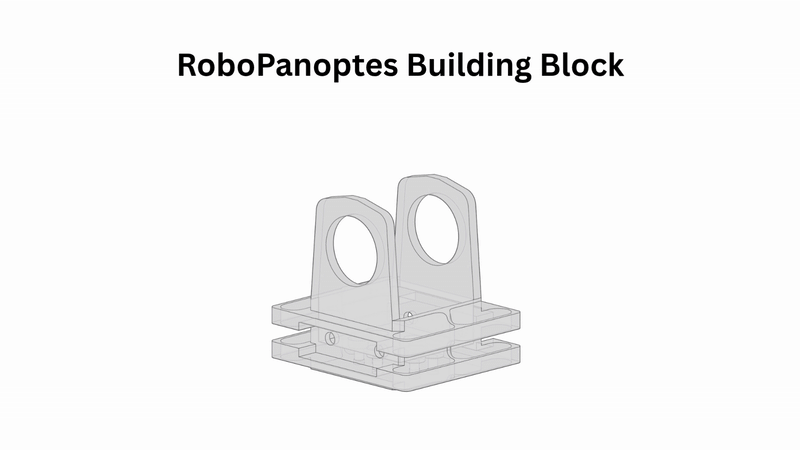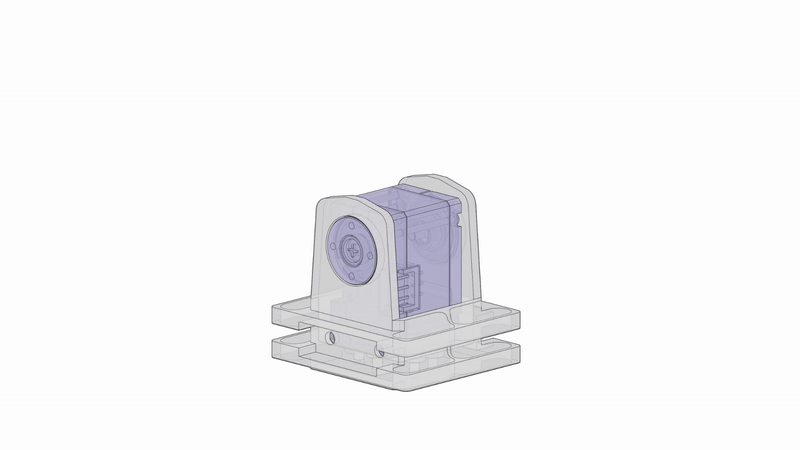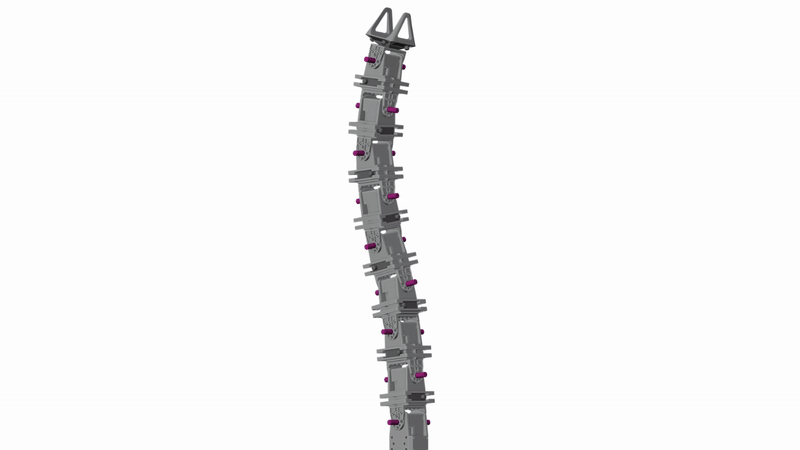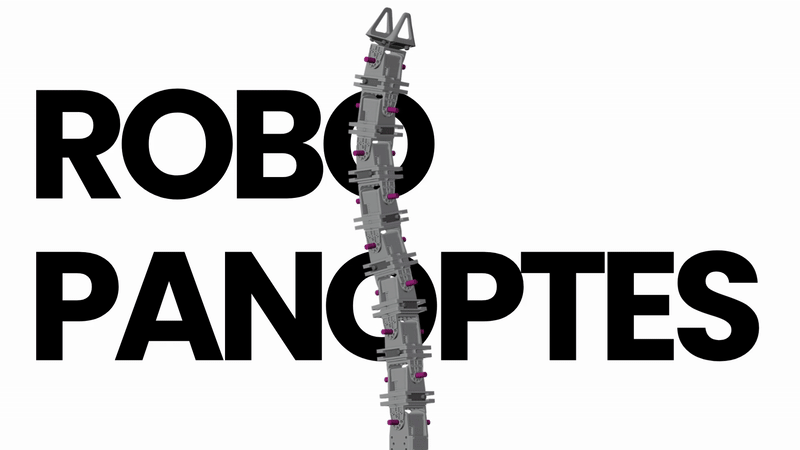
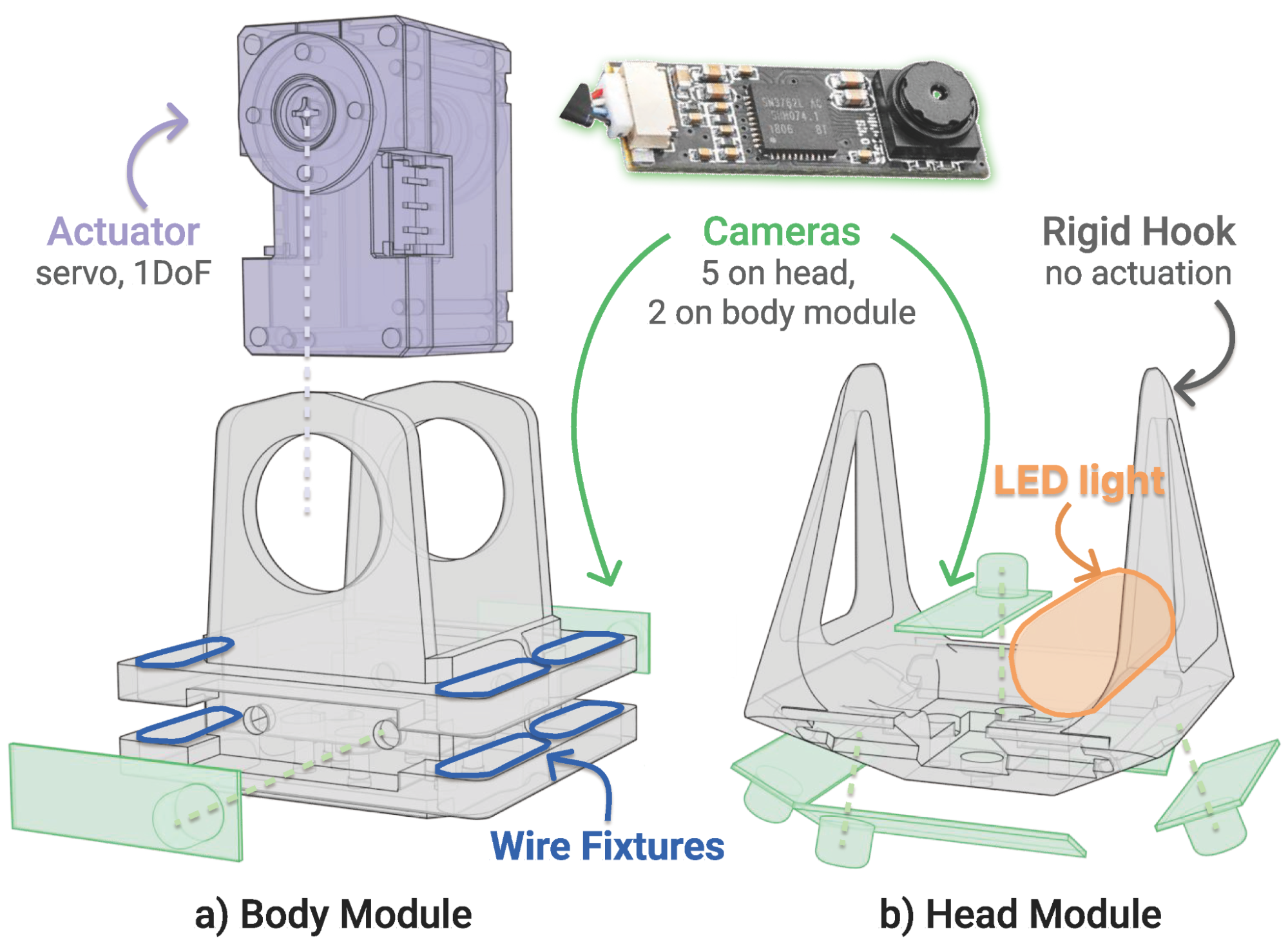
It has 9 degrees of freedom for snake-like flexibility, and 21 cameras sprinkled head-to-tail.

Whole-body Dexterity
With all that flexibility, RoboPanoptes becomes a natural sweeper. Watch it clear 10 cubes simultaneously with a single body wave—something no traditional 6-DOF arm could not achieve. We call this whole-body dexterity.

However, hardware potential is limited without proper control. Using a standard space mouse to teleoperate this robot would reduce it to poking cubes one by one.

Instead, we built a leader-follower teleoperation system. The operator uses both hands to control the leader robot, whose joint angles are sent to the follower robot in real-time as position targets.

This means we can sweep cubes much faster (9.3s/block -> 2s/block).

Whole-body Vision
RoboPanoptes' 21 cameras enable whole-body vision. Consider this unboxing task. The goal here is to enter a box through a small hole on its side, then poke the lid open.

A top-down camera captures the workspace but misses the hole's location. A head-mounted camera sees inside the box but loses track of the box's position. With cameras distributed along its entire body, RoboPanoptes doesn't have to choose where to look. The robot can see its surroundings, even peek inside a box to find the opening edge.

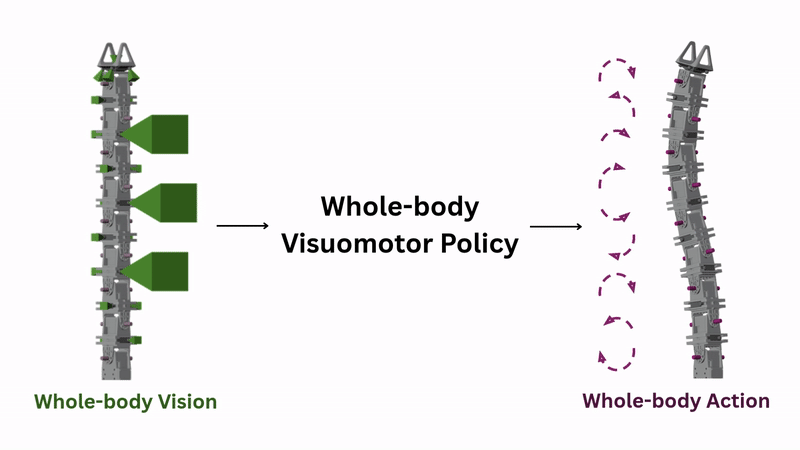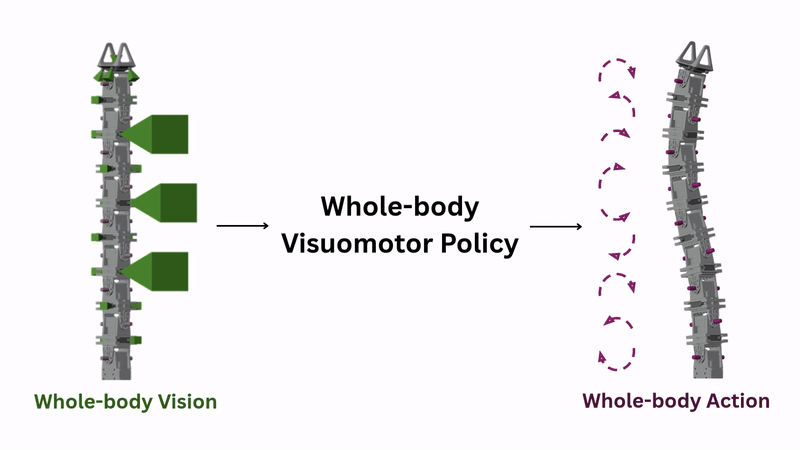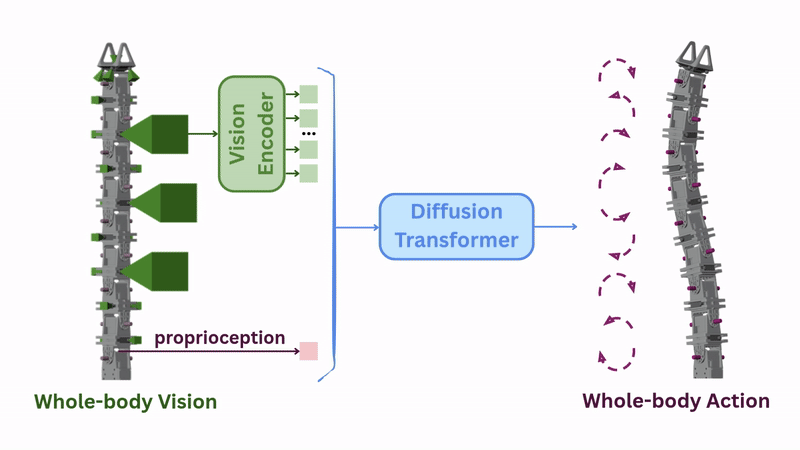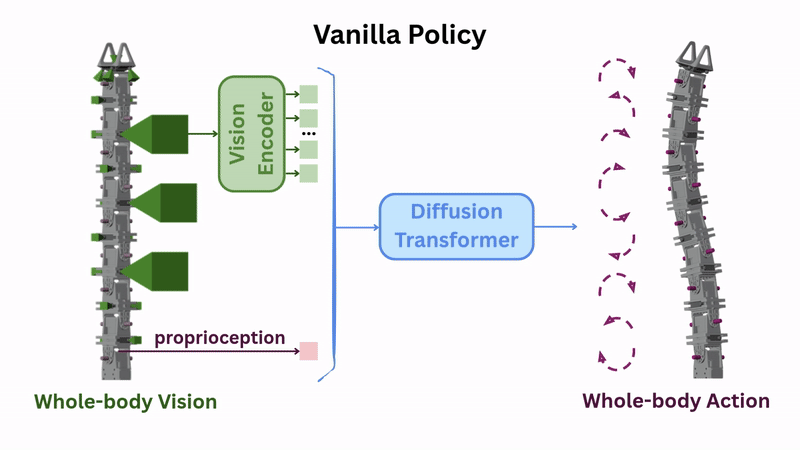
Whole-body Visuomotor Policy
To automatically infer whole-body actions from whole-body vision, we can train a visuomotor policy using demonstrations collected with the teleoperation setup. The pretrained image features and proprioception are passed to a diffusion transformer policy to predict robot actions. We call this the [vanilla policy] architecture.
3D Spatial Awareness Through Camera Pose Encoding
When we first tested RoboPanoptes on a stowing task—where it needed to open a drawer, reach inside, organize shoes, and close the drawer—the [vanilla policy] moved in the right direction but frequently missed by centimeters, achieving only 28% success.

The problem? Lack of 3D spatial awareness.
The solution was simple: concatenate each camera's 6D pose (position and orientation) as additional positional encoding to the image features. These poses are easily computed through forward kinematics.
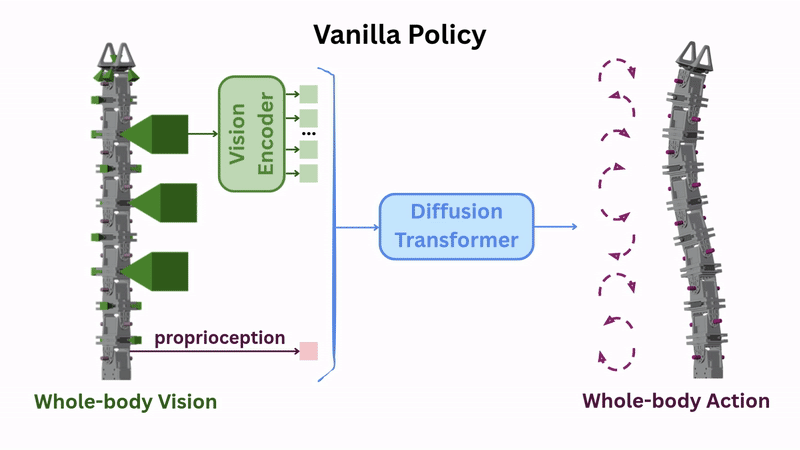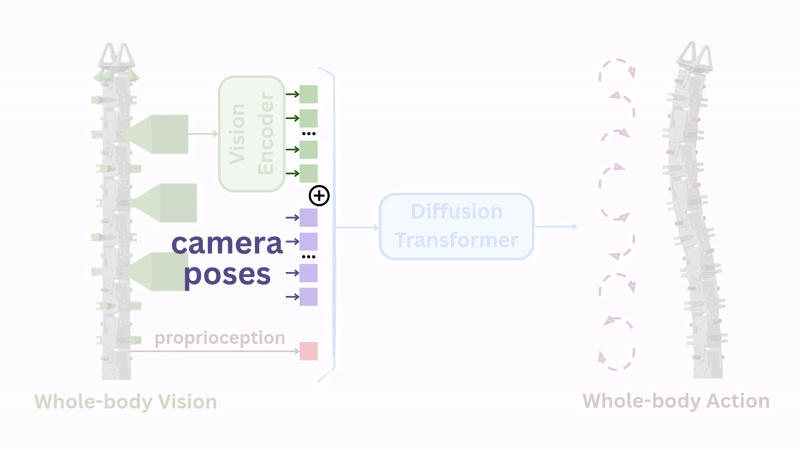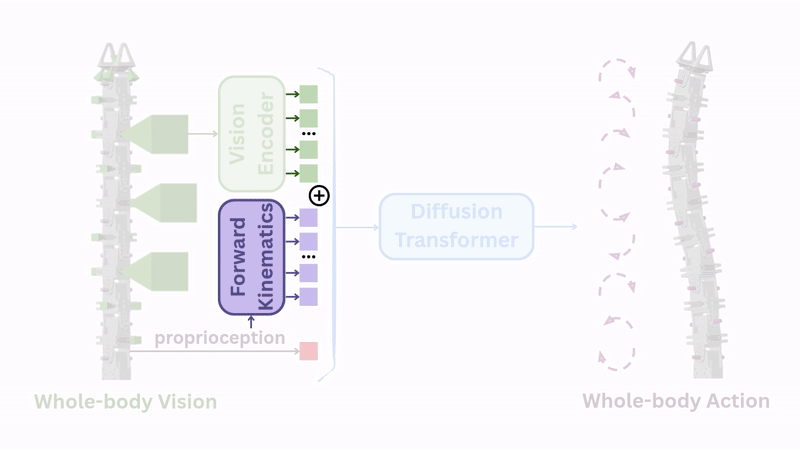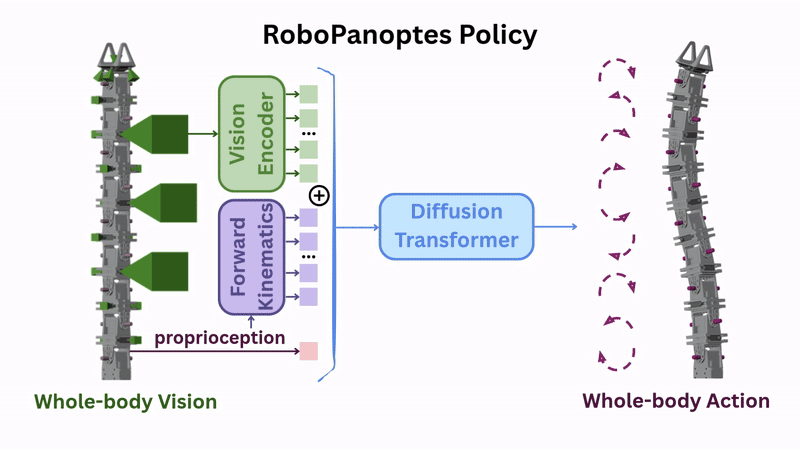
With this addition, success rates jumped to 83%.

Robust Perception Through "Blink Training"
One final challenge remains: reliability. One inevitable problem with having so many USB cameras is that some of them may drop frames and have delays often. On average, the dropout rate (i.e., camera discount) observed for the used cameras is 4.4% and latency ranges from 15 ms to 100 ms. This makes testing performance suffer significantly.
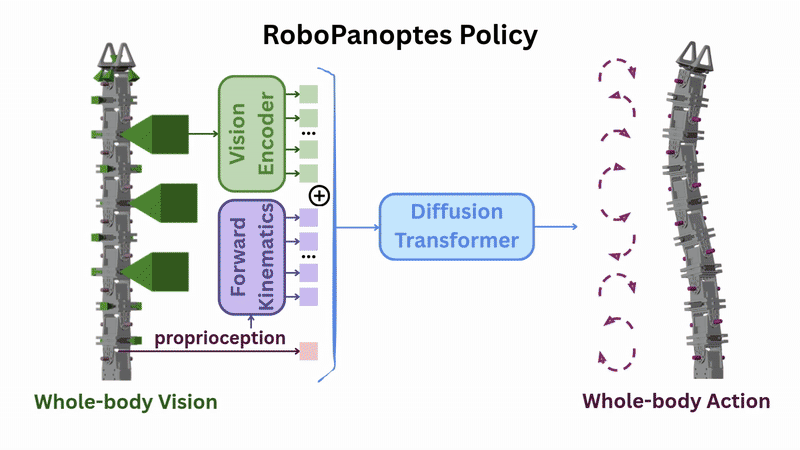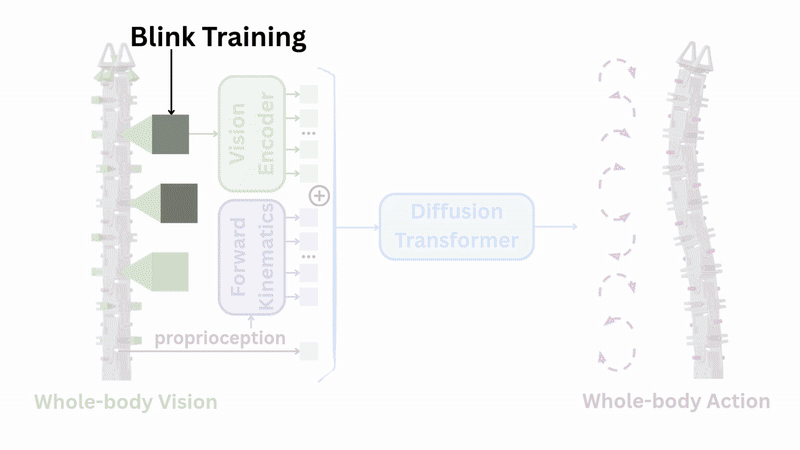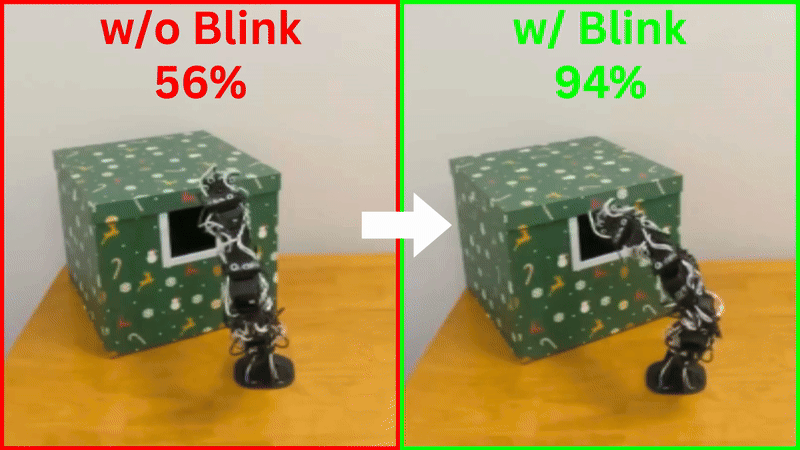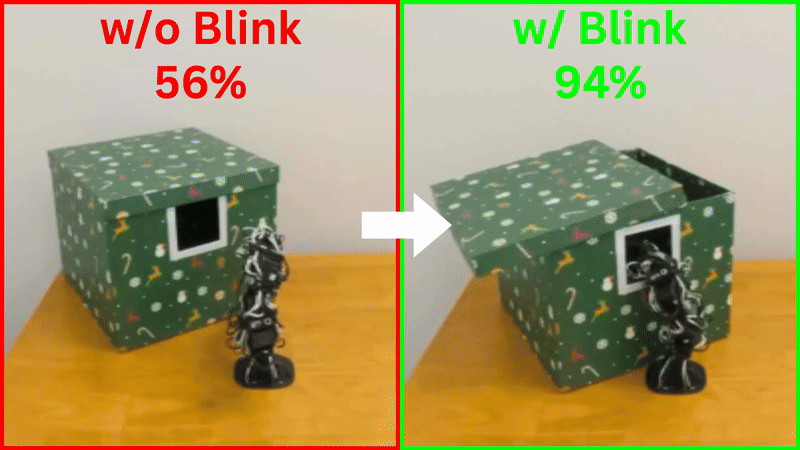
To build robustness, we introduced "blink training"—during training, we simulate the random frame dropping by masking out whole camera inputs, so the robot learns to continue functioning even when some eyes are temporarily "closed." This technique boosted success rates on the unboxing task from 56% to 94%.
DGDM: Designing Robots That Don't Need Sensors 2
While RoboPanoptes maximizes sensing, our Dynamics-Guided Diffusion Model (DGDM) takes the opposite direction: what if we designed robots that work perfectly without any sensors.
Imagine an assembly line where objects arrive in random orientations, but specialized gripper fingers automatically align them perfectly just by closing—no sensors, no feedback, no complex control systems required. It's mechanical intelligence baked directly into the robot's shape.

Designing Task-Specific Manipulators
Instead of building a robot and then figuring out how to control it, DGDM starts with the task and automatically generates the perfect robot shape to accomplish it. Need to rotate objects counterclockwise? DGDM designs finger shapes that naturally impart that rotation when closed. Want to align randomly oriented parts? It creates manipulators that funnel objects into the same final pose every time.

Generating Task-Specific Designs without Task-Specific Training
Our approach works by:
-
Representing tasks as interaction profiles that describe desired object motions.
-
Using geometric diffusion models to represent the design space.
-
Efficiently searching this space using gradients from a dynamics network trained on general interaction physics (no task-specific training needed).
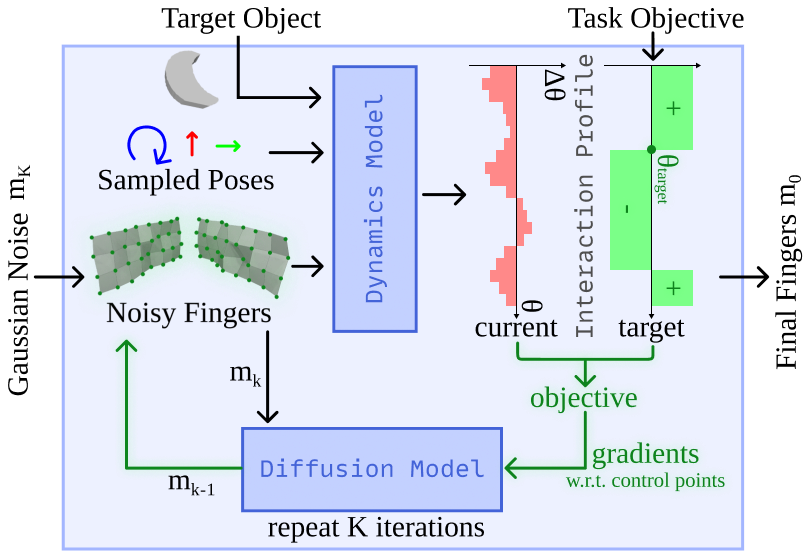
In other words, we learn the physics of how objects move when grippers close, then use that knowledge to sculpt robot shapes that create exactly the right motions. Both the geometric diffusion model and dynamics model are trained on randomly sampled manipulator designs and objects interacting in simulation, requiring no task-specific information.
Removing the dynamics guidance yields the [Unguided] baseline, which generates task-agnostic manipulators using our geometric diffusion model. Removing our diffusion model yields the [GD] baseline, which optimizes the manipulator control points using gradients of the design objective via gradient descent optimization. Our generated designs outperform [GD] and [Unguided] baselines by 31.5% and 45.3% respectively on average success rate. With the ability to generate a new design within 0.8s, DGDM facilitates rapid design iteration.
Two Paths, One Revolution
At first glance, RoboPanoptes and DGDM seem to be pulling in opposite directions. One maximizes sensing with 21 cameras; the other eliminates sensors entirely. One embraces complexity with 9 degrees of freedom; the other achieves goals through pure manipulator shape design.
But they're part of the same revolution: using machine learning to break free from conventional robot design assumptions. We've been constraining ourselves by following patterns that made sense for robots controlled with model-based methods, but don't necessarily apply in the robot learning era.
When you can learn from demonstrations instead of hand-coding behaviors, and use blink training to enhance perception robustness, suddenly it becomes feasible to build robots with many joints and many cameras. When you can use diffusion models to generate designs, you can explore robot morphologies inherently suited to their tasks within seconds, which might take human engineers days to figure out.
They're glimpses of a future where robots come in wildly different shapes and sizes. The age of unconventional robots is just beginning.
This blog post is based on the RSS 2025 paper RoboPanoptes: The All-Seeing Robot with Whole-body Dexterity by Xiaomeng Xu, Dominik Bauer, and Shuran Song, and the CoRL 2024 paper Dynamics-Guided Diffusion Model for Sensor-less Robot Manipulator Design by Xiaomeng Xu, Huy Ha, Shuran Song.