Before being deployed for user-facing applications, developers align Large Language Models (LLMs) to user preferences through a variety of procedures, such as Reinforcement Learning From Human Feedback (RLHF) and Direct Preference Optimization (DPO). Current evaluations of these procedures focus on benchmarks of instruction following, reasoning, and truthfulness. However, human preferences are not universal, and aligning to specific preference sets may have unintended effects. We explore how alignment impacts performance along three axes of global representation: English dialects, multilingualism, and opinions from and about countries worldwide.
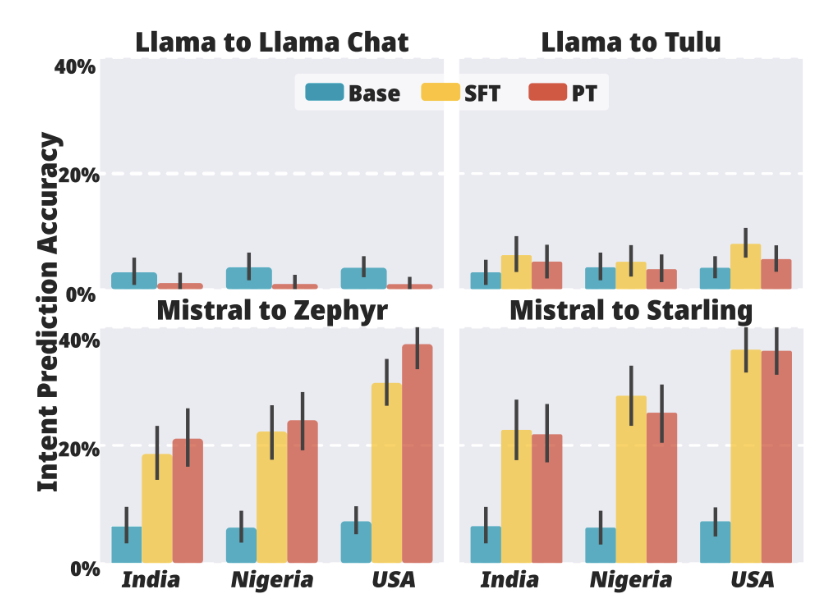
Dialects: First we notice that aligning an LLM with supervised finetuneing and preference tuning create a disparity in performance across various English Dialects. We show these results in Figure 2. We find all base models perform roughly equivalently at intent detection across dialects. However for Mistral to Mistral SFT, Indian English accuracy increased by 15.2%, Nigerian English accuracy increased by 20.3% and American English accuracy increased by 29.3%. The SFT process introduced a 14% gap in performance between Indian English and US English.
Language: We find that supervised fine-tuning (SFT) and preference tuning consistently improve the model’s multilingual capabilities for models such as Tulu and Starling. Interestingly, we noticed that 14.1% of Tulu’s training data is in a non-English language. Conversely, Zephyr, which decreases performance across most languages, was trained on 99.9% of the English data. Just a tiny amount of multilingual data can be highly beneficial. We include these results in Figure 3.

Opinions: Finally, we test how opinions of language models change based on supervised finetuning and preference tuning. In particular we explore how the LLM responses to survey questions change over various stages of alignment versus global respondents. We showcase these results in Figure 4.
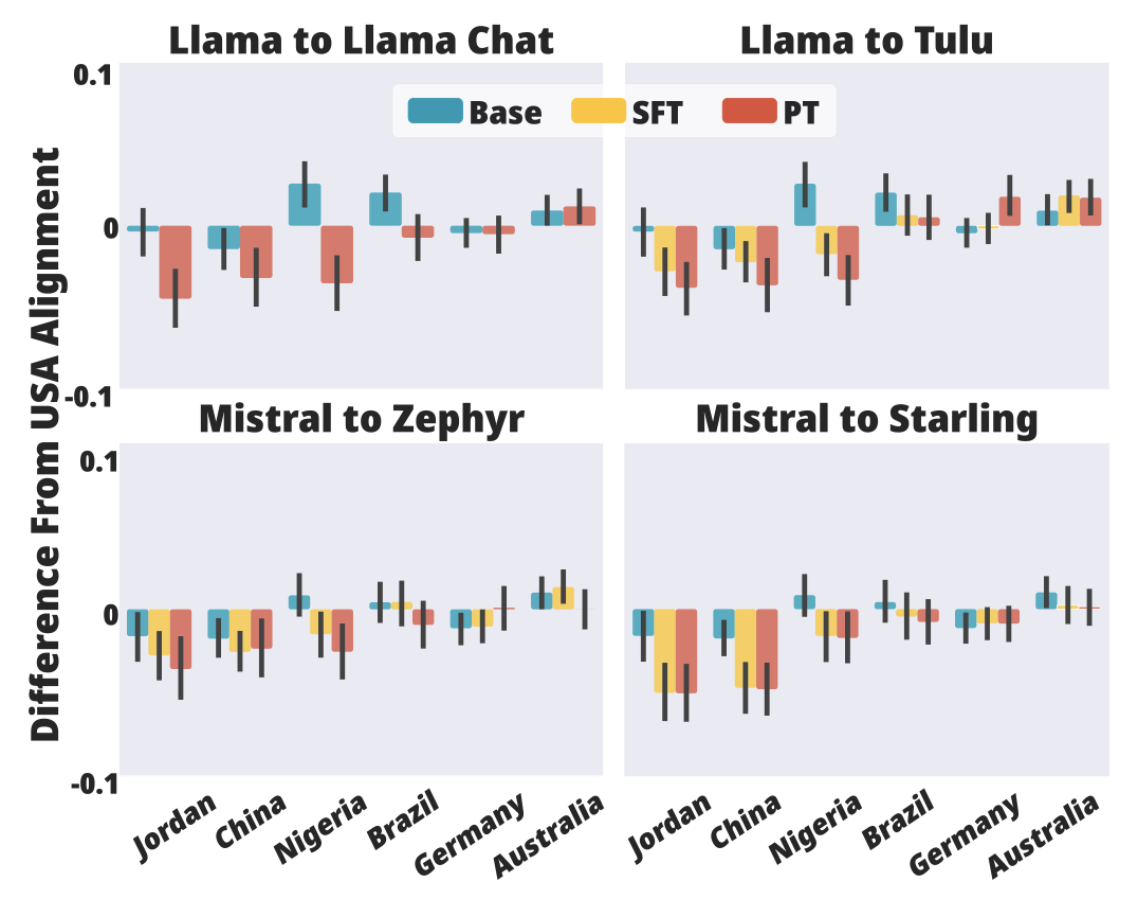
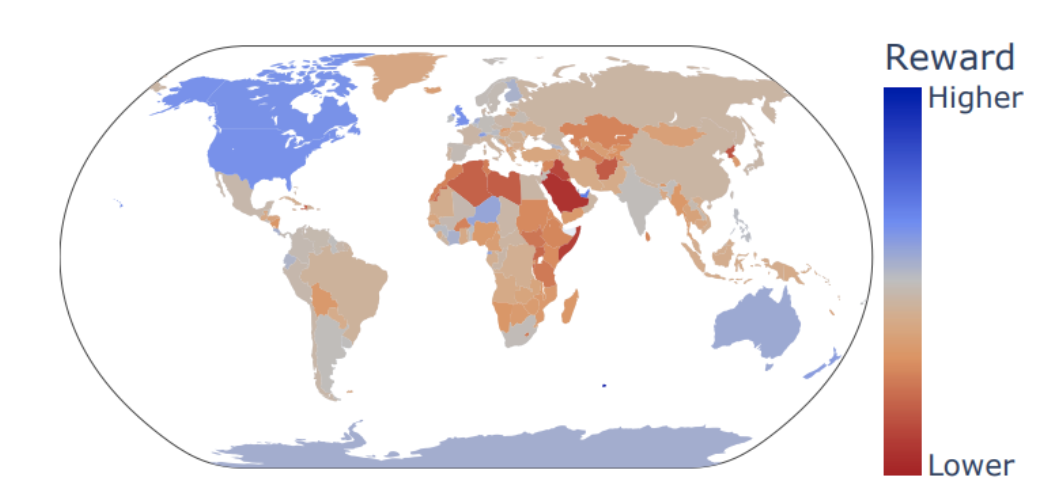
We find that both supervised finetuning and preference tuning tend to steer models towards US preferences and opinions rather than other countries such as Jordan, China, or Nigeria. In fact the base version of Llama 2 is more aligned with Nigeria than the USA, whereas Llama 2 chat is more aligned with the USA than Nigeria. We also explore how reward models express opinions about countries and find 0.849 spearman correlation with US opinions about countries. Details of this experiment are included in the paper.
Overall we find that the procedures used to convert base LLMs into Chatbot assistants have several unintended global impacts that make them less useful for global users. Specifically we identify dialects, languages, and opinions as downstream areas to monitor impact. We hope our work encourages model developers to audit their LLMs for appropriateness and effectiveness to the global audiences they intend to serve.
Project repository: https://github.com/SALT-NLP/unintended-impacts-of-alignment