Making Causal Inferences with Text
Identifying the linguistic features that cause people to act a certain way after reading a text, regardless of confounding variables, is something people do all the time without even realizing it. For example,
- Consider university course catalogues. Students peruse these each semester before signing up. What’s the magic 200-word blurb that jives with students enough to sign up? What kind of writing style recommendations could you give to any professor, regarding any subject?
- Consider crowdfunding campaigns [1]. We want to know which writing styles pull in the most money, but the effect of language is confounded by the subject of the campaign – a campaign for someone’s medical bills will be written differently than a campaign for building wells. We want to find writing styles that could help any campaign.
- Consider comments on reddit, where each post has a popularity score. Say that we’re interested in finding what writing styles will help posts become popular. Some authors list their genders on reddit, and a user’s gender may also affect popularity through tone, style, or topic choices [2]. How do you decide what kind of language to reccomend to any person, regardless of their gender.
Across three papers, we develop adversarial learning-based approaches for these kinds of tasks as well as a theory of causal inference to formalize the relationship between text and causality. Our method involves:
-
Training a model which predicts outcomes from text. We control for confounds with adversarial learning [3], [4] or residualization [5].
-
Interpreting the models’ learned parameters to identify the most important words and phrases for the outcome, regardless of confounders.
Compared to other feature selection methods, ours picks features that are more predictive of the outcome and less affected by confounding variables across four domains: e-commerce product descriptions (predictive of sales, regardless of brand), search advertisements (predictive of click-through rate, regardless of landing page), university course descriptions (predictive of enrollment, regardless of subject), and financial complaints (predictive of a short response time, regardless of topic).
Formalizing Textual Causality
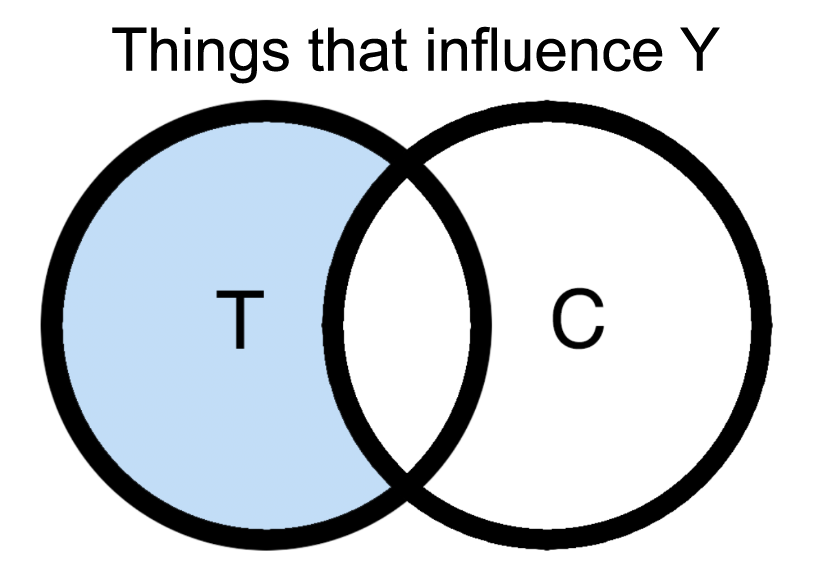
Our goal is to find features of text(s) T which are predictive of some desired target variable(s) Y but unrelated to confounding variable(s) C (i.e. the blue bit in the figure below). This is equivalent to picking a lexicon L such that when words in T belonging to L are selected, the resulting set L(T) can explain Y but not C.
In the paper, we formalize this intuitive goal into maximizing an informativeness coefficient
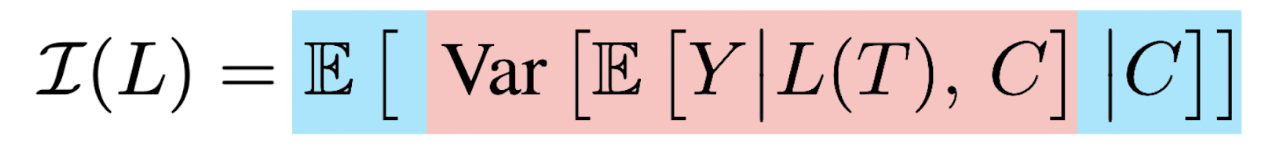
which measures the explanatory power of the lexicon L(T) beyond the information already contained in the confounders C. The red tells us how much variation in Y is explainable by both L(T) and C. The blue fixes C, letting us focus on L(T)’s unique effects. In our paper, we show that under some conditions this coefficient is equivalent to the strength of T’s causal effects on Y! [6]
In practice I(L) can be estimated by this sequence of steps:
- Training a classifier A that predicts Y from L(T) and C
- Training a classifier B that predicts Y from C.
- Measuring error(B) - error(A)
We continue by introducing two methods for coming up with the best lexicon L(T).
Method 1: Adversarial Learning
First, we encode T into a vector e via an attentional bi-LSTM. We then feed e into a series of feedforward neural networks which are trained to predict each target and confounding variable using a cross-entropy loss function. As gradients back-propagate from the confound prediction heads to the encoder, we pass them through a gradient reversal layer. In other words, If the cumulative loss of the target variables is L_t and that of the confounds is L_c, then the loss which is implicitly used to train the encoder is L_e = L_t - L_c. The encoder is encouraged to learn representations of the text which are unrelated to the confounds.
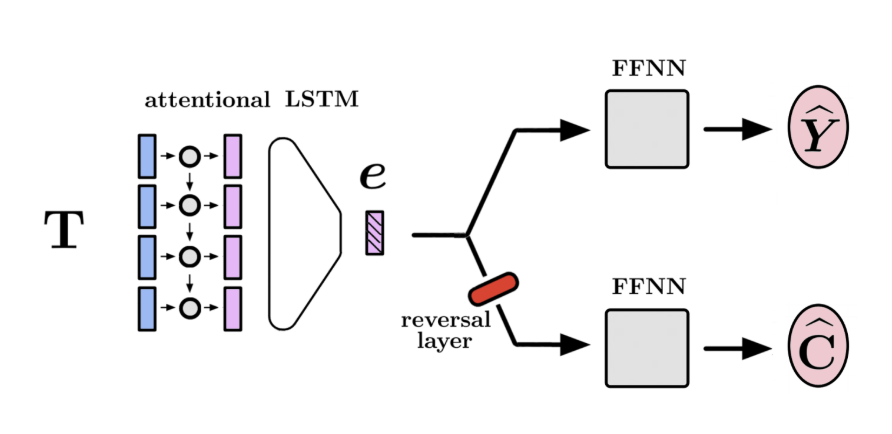
To get the “importance” of each feature, we simply look at the attention scores of the model, since ngrams the model focused on while making Y-predictions in a C-invariant way are themselves predictive of Y but not C!
Method 2: Deep Residualization
Recall that we can estimate I(L) by measuring the amount by which L can further improve predictions of Y compared to predictions of Y made from just C. Our Deep Residualization algorithm is directly motivated by this. It first predicts Y from C as well as possible, and then seeks to fine-tune those predictions using a bag-of-words representation of the text T. The parameters are then updated using the loss from both prediction steps. This two-stage prediction process implicitly controls for C because T is being used to explain the part of Y’s variance that the confounds can’t explain.
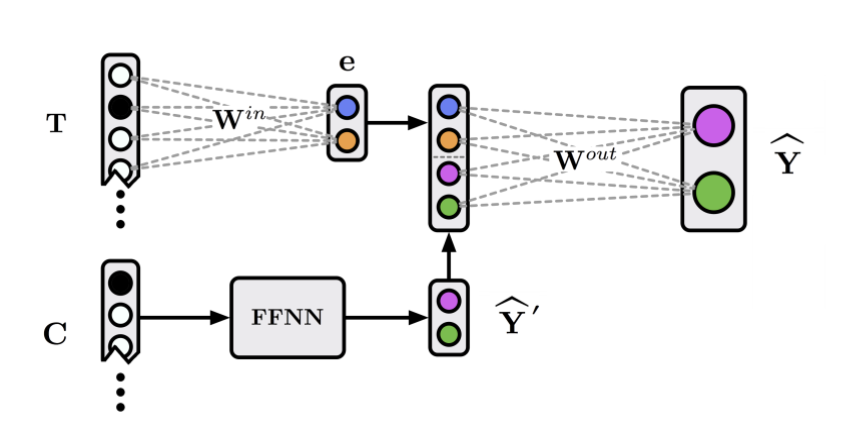
Then to get the “importance” of each feature, we trace all possible paths between the feature and output, multiply weights along these paths, then sum across paths.
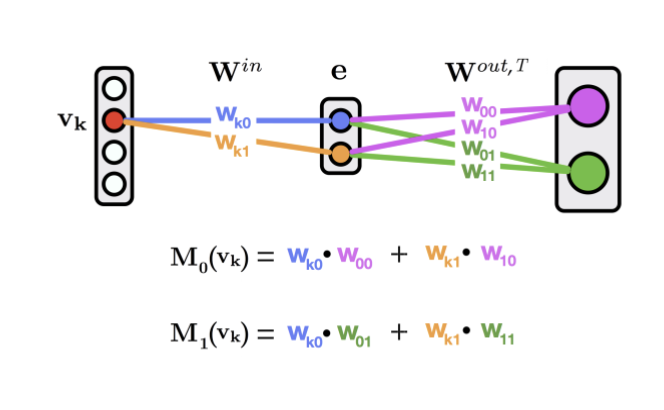
Social Science Applications
Armed with our theoretical framework and algorithms, we can now pick words and phrases that are strongly associated with arbitrary outcomes, regardless of confounding information. In our papers, we do this for four domains:
- Product descriptions for chocolate and health products on the Japanese e-commerce website Rakuten. We want to find language that explains sales, but not brand or price.
- Written complaints to the Consumer Financial Protection Bureau (CFPB). We want to find language that predicts short response time, regardless of the financial product the complaint is about.
- Search advertisements for real estate, job listings, and apparel on the website Google.com. We want to find language that predicts a high click-through rate (CTR), regardless of the landing page the ad points to.
- Course descriptions and enrollment figures for 6 years of undergraduate offerings at Stanford University. We want to find language that boosts enrollment, regardless of subject and requirements.
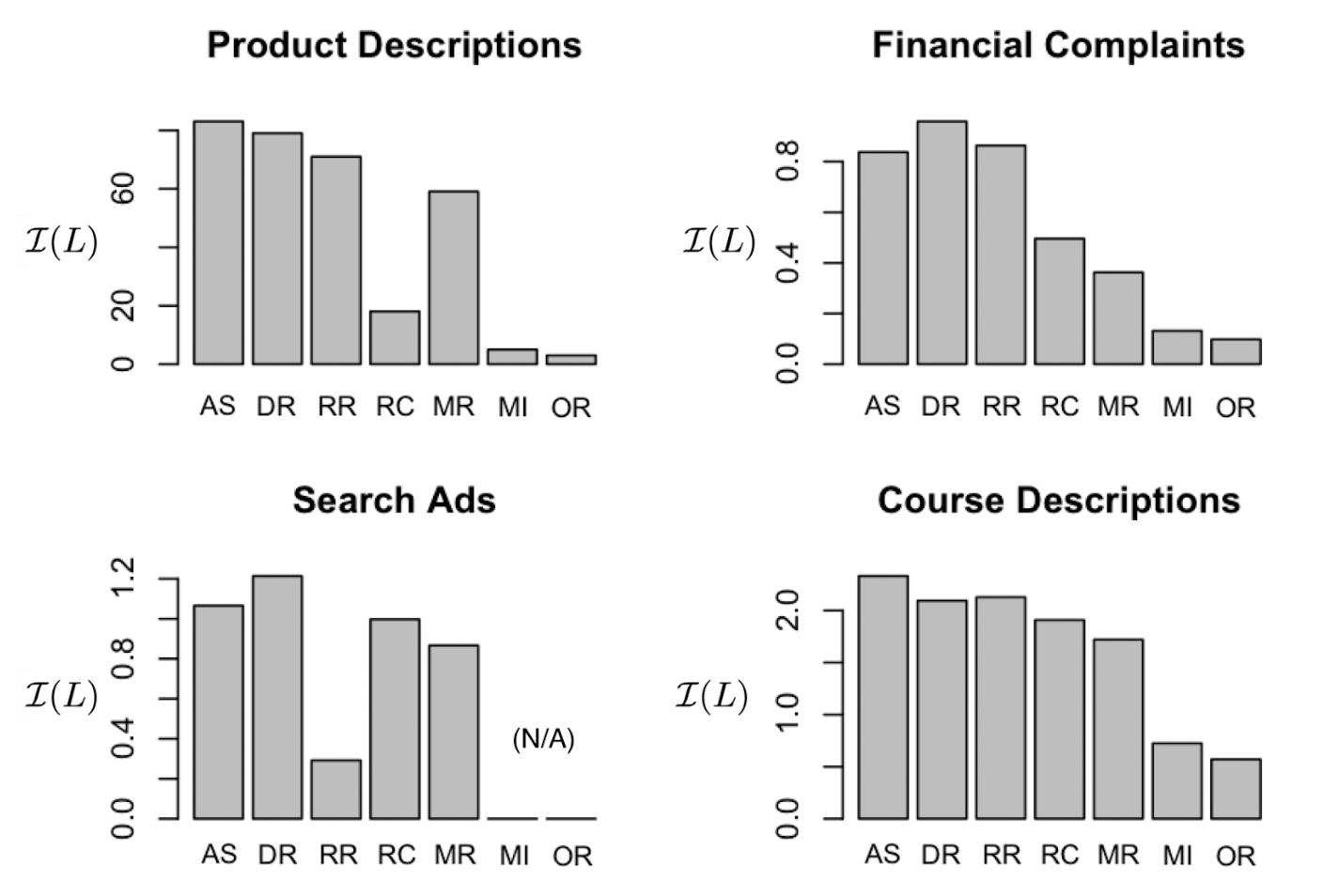
As we can see, in each setting one or both of our proposed methods outperform a number of existing feature selection algorithms: Residualized Regressions (RR), Regression with Confound features (RC), Mixed-effects Regression (MR), Mutual information (MI), and Log-Odds Ratio (OR).
Furthermore, we can interpret features these algorithms are selecting to learn about the linguistic dynamics of the associated domains!
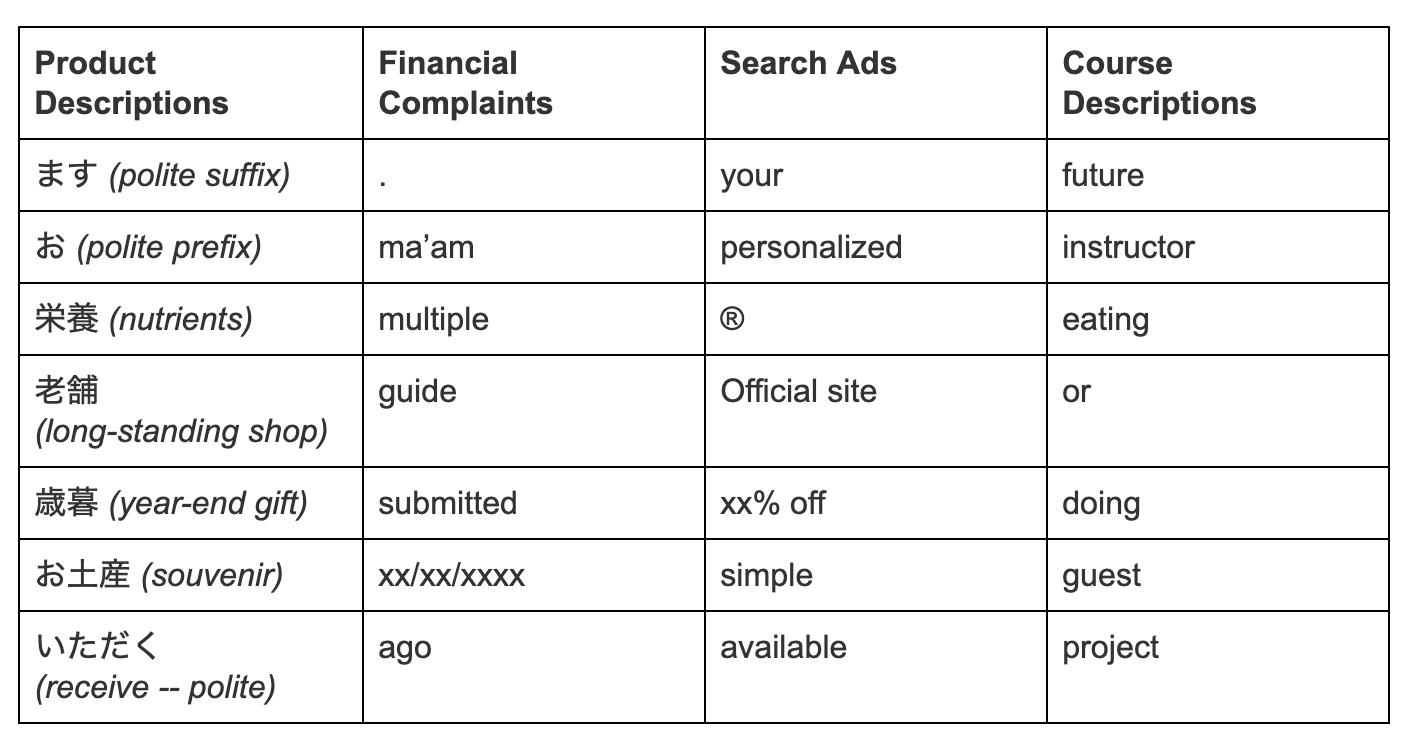
- Appeals to politeness and seasonality appear to help make for successful Japanese product descriptions – an interesting intersection of language and culture.
- Concrete details (“multiple”, “xx/xx/xxxx”) and already having taken some steps (“submitted”, “ago”) appears important for writing a complaint that will get handled quickly.
- Appeals to authority (“®“, “Official site”) and personalization (“your” “personalized”) are helpful for search advertising creatives.
- Student choice (“or”) and dynamic activities (“eating”, “doing”, “guest”, “project”) make for successful course descriptions.
Conclusion
This work presented two methods for identifying text features which best explain an outcome, controlling for confounding variables we are not interested in. This method is generally applicable to a variety of data science and social science applications. In the future, we hope to strengthen the method’s theoretical guarantees in a causal inference framework.
The algorithms in this blog post have been open-sourced! Install via pip:
pip3 install causal-selection
This post was based on the following papers: