We introduce a new benchmark to test whether AI agents can actively explore physical spaces and build mental maps, just like humans do.
What happens when an AI needs to navigate a new building? Unlike humans who intuitively explore and build mental maps, most foundation models struggle when they must actively acquire spatial information rather than passively receive it. In the passive setting, a model simply analyzes a fixed log of pre-collected observations. Active acquisition is fundamentally harder: the AI must autonomously decide where to move, which direction to look, and when it has gathered enough information.
Current benchmarks fall short: passive benchmarks simply ask models to reason over observations handed to them, while task-driven benchmarks test goal completion without probing whether models truly internalize spatial structure. We propose Theory of Space as an explicit test of whether models can construct, revise, and exploit an internal spatial belief through active exploration.
Introducing Theory of Space: A Spatial Counterpart to Theory of Mind

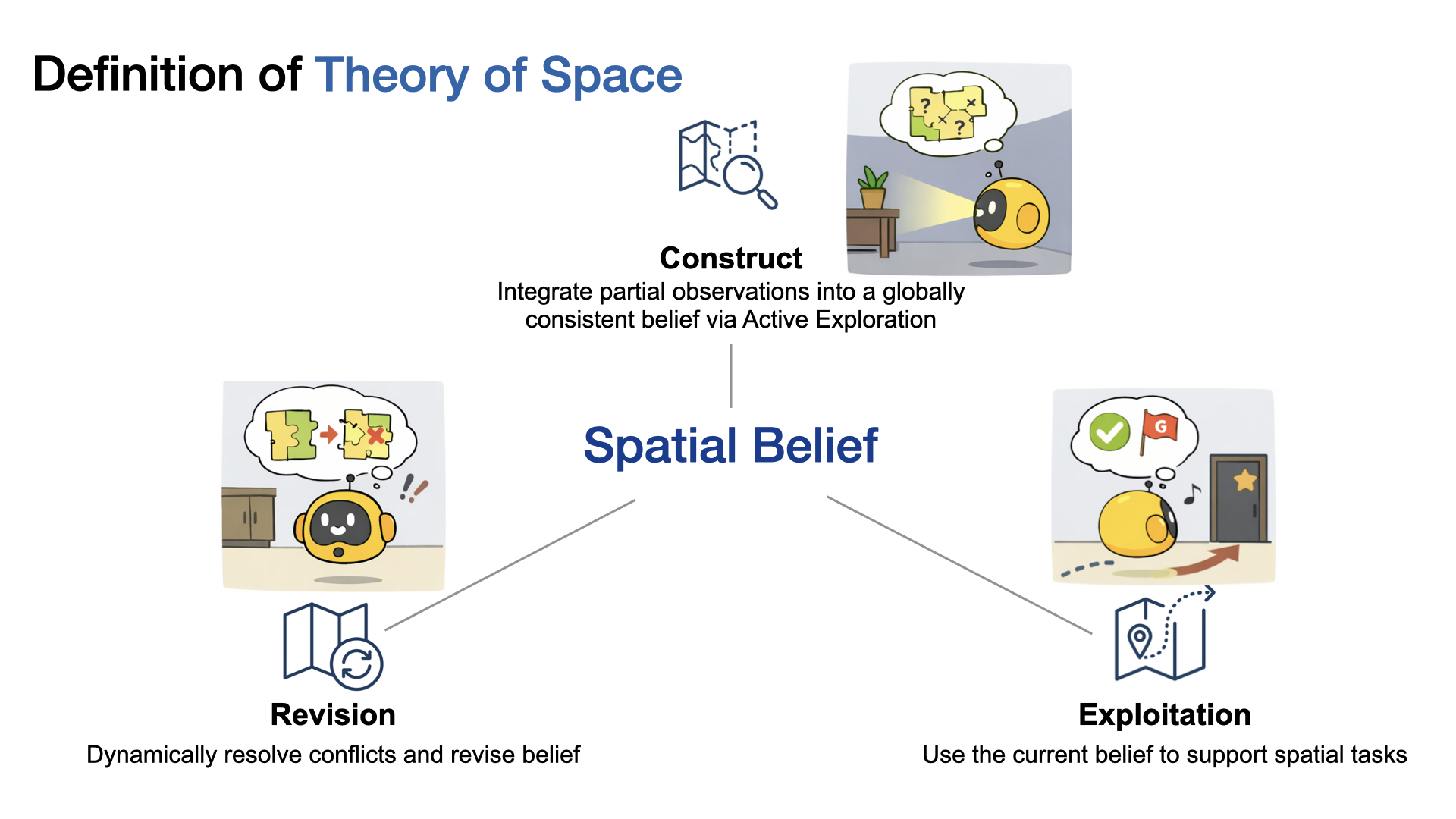
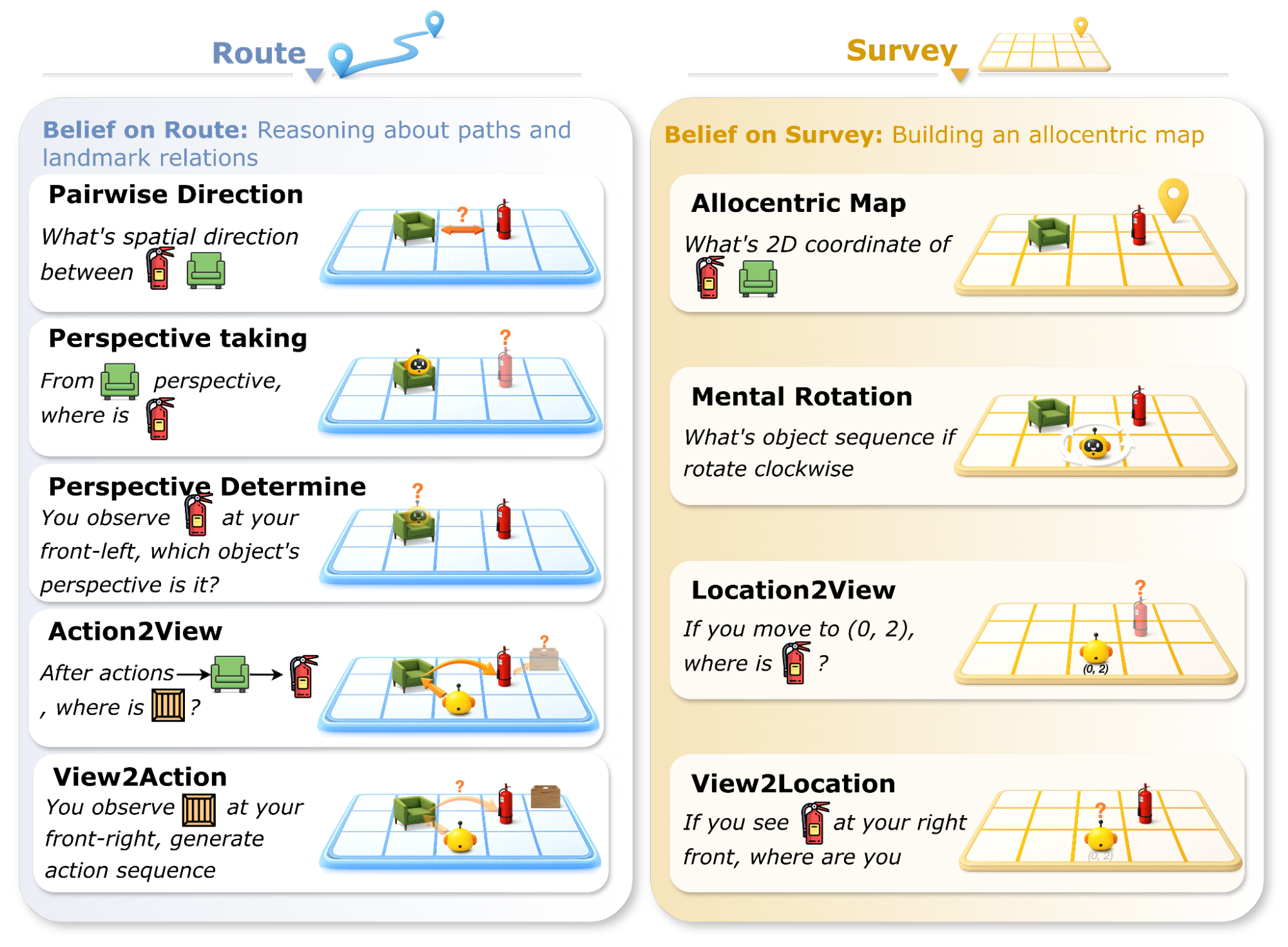
Theory of Mind is a well established concept from cognitive science that refers to the capacity to attribute beliefs, intentions, and knowledge to other agents, essentially reasoning about what someone else thinks or knows even when it differs from reality1. We draw an analogy to this familiar idea to define Theory of Space: just as Theory of Mind measures how agents model the hidden mental states of others, Theory of Space assesses an agent’s ability to model the hidden physical structure of the world. Specifically, we define it as the ability to construct spatial beliefs through exploration, exploit them for downstream spatial tasks, and revise them as environments change.
At its heart, Theory of Space tests three coupled capabilities:
1) Construct: Can the agent actively explore to build a globally consistent spatial belief from partial observations?
2) Revise: When the environment changes, can the agent update its mental map, overwriting obsolete information with new evidence?
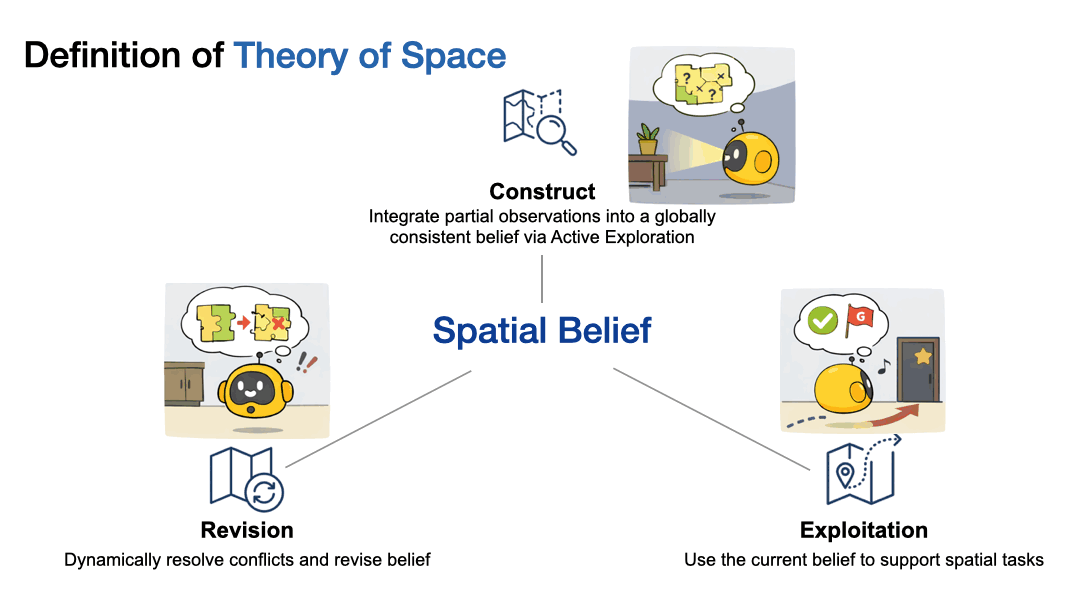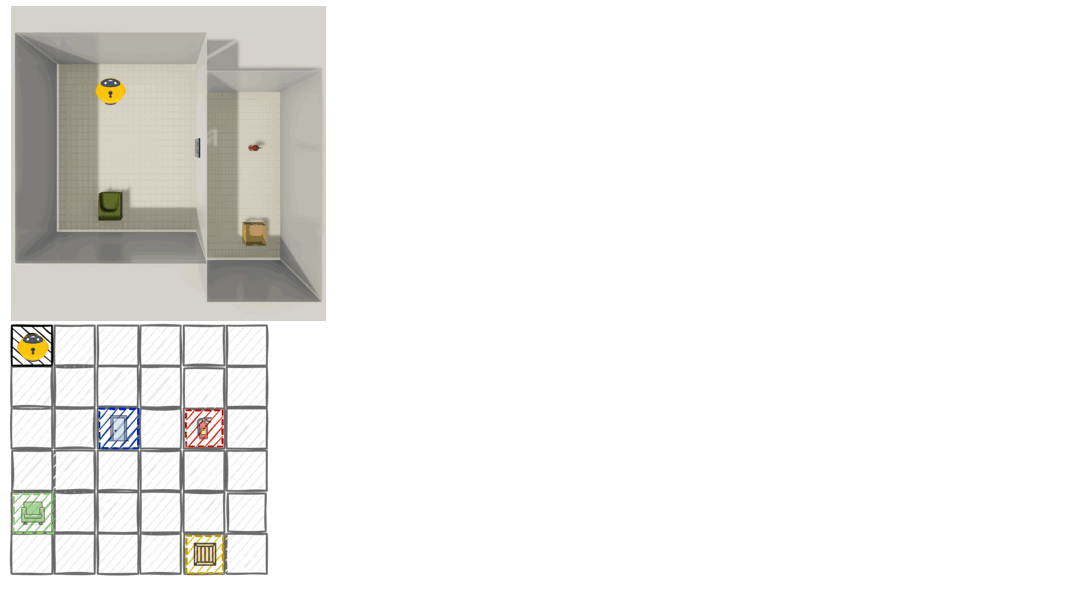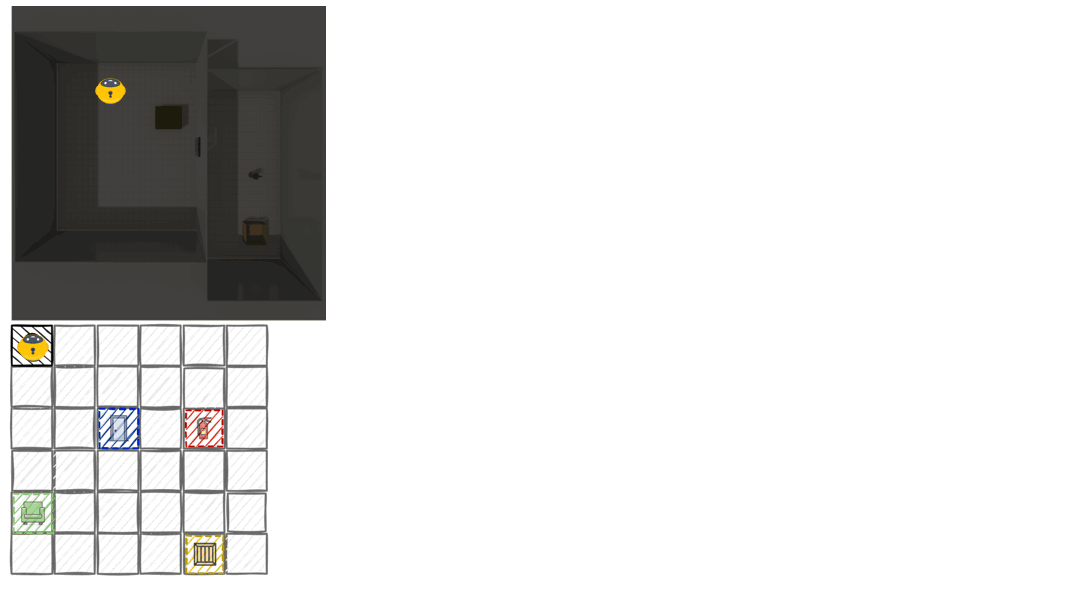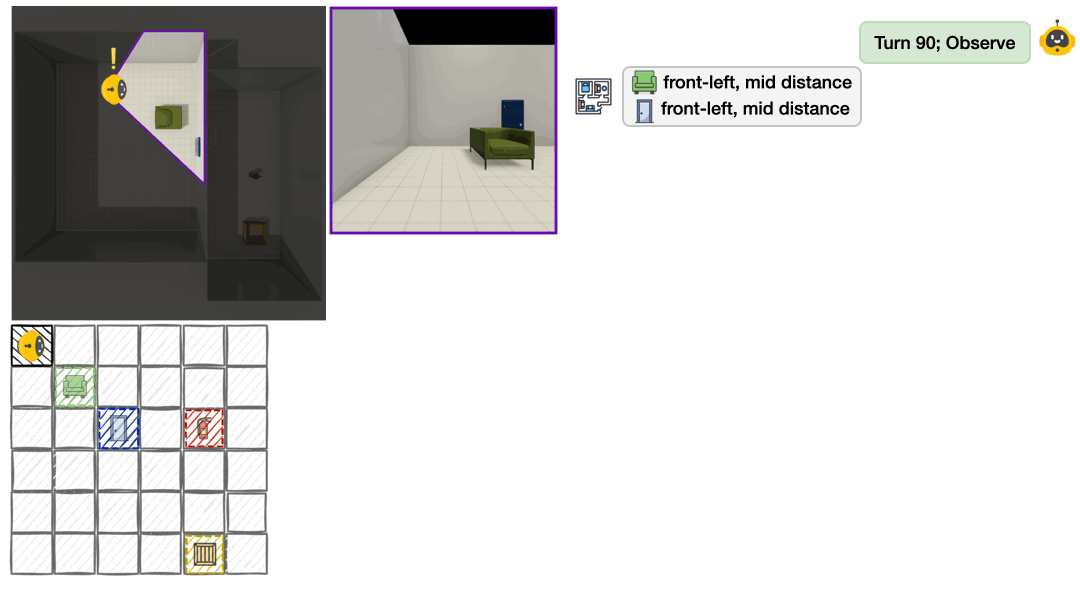
3) Exploit: Can the agent use its spatial belief to answer spatial reasoning questions about directions, locations, and perspectives?
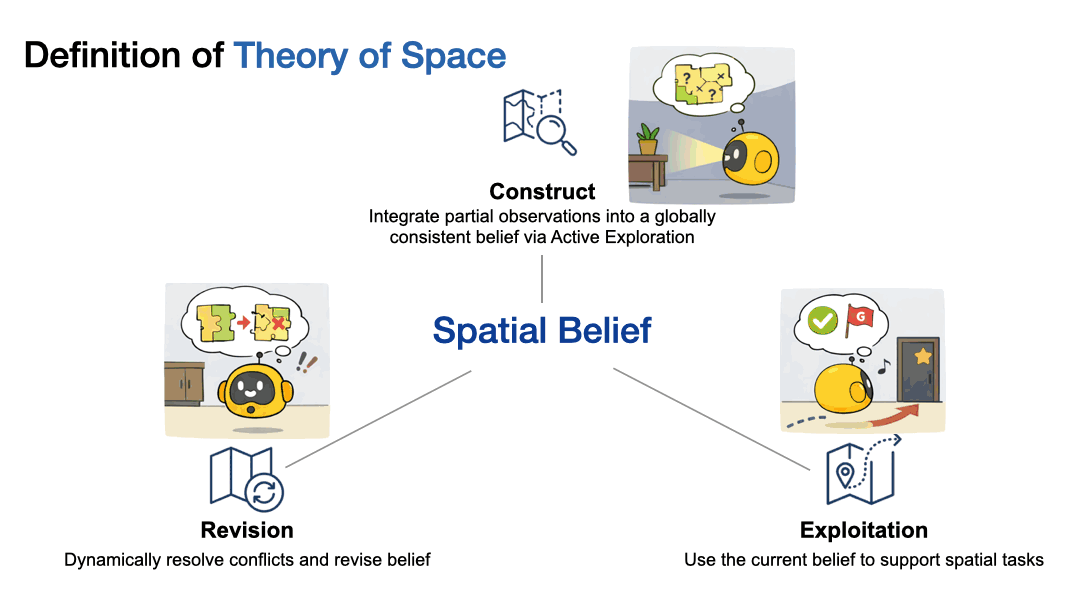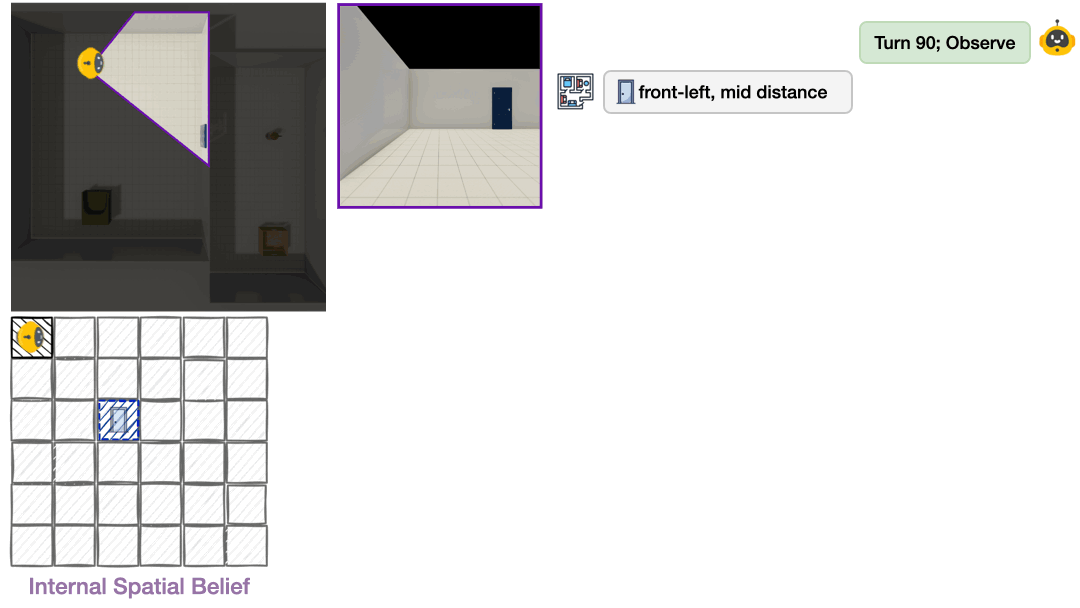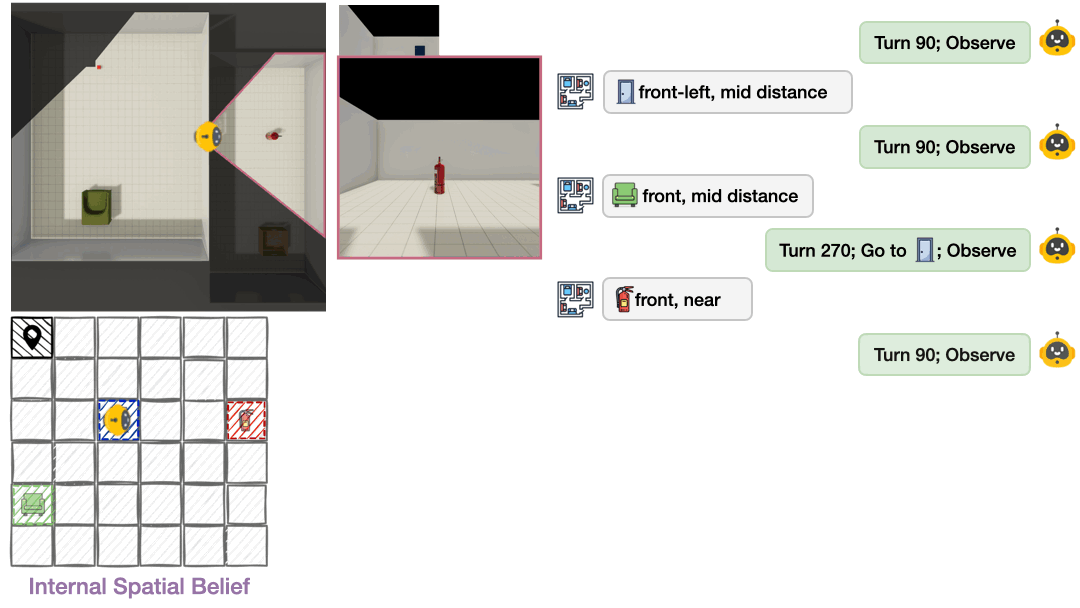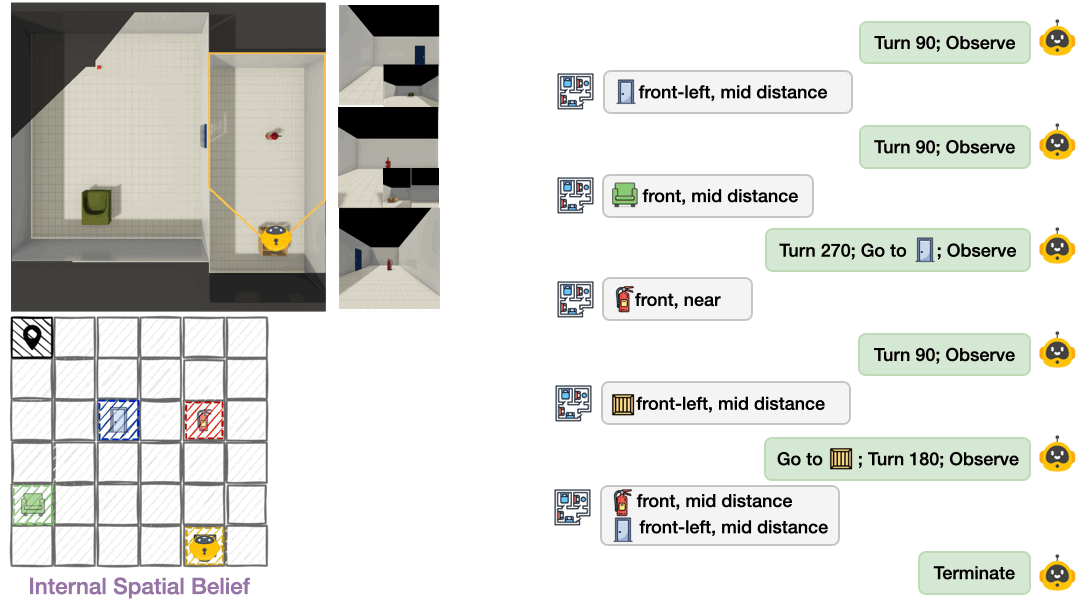
To operationalize this framework, we developed a benchmark with procedurally generated multi-room layouts. The agent starts in an unknown environment and must decide what to observe next, rotate, move between rooms, and build understanding one partial view at a time. We offer both text-based environments (symbolic observations like “chair is front-left and near”) and vision-based environments (egocentric RGB images rendered with ThreeDWorld2), enabling us to pinpoint whether failures stem from spatial reasoning deficits or visual perception errors.
Probing the Black Box: Cognitive Map Externalization
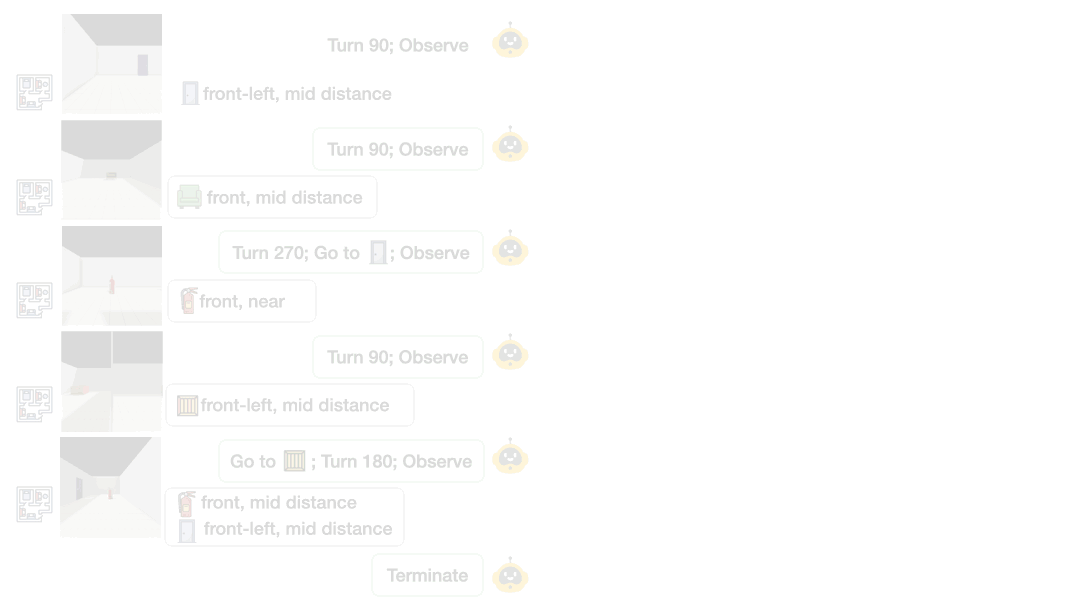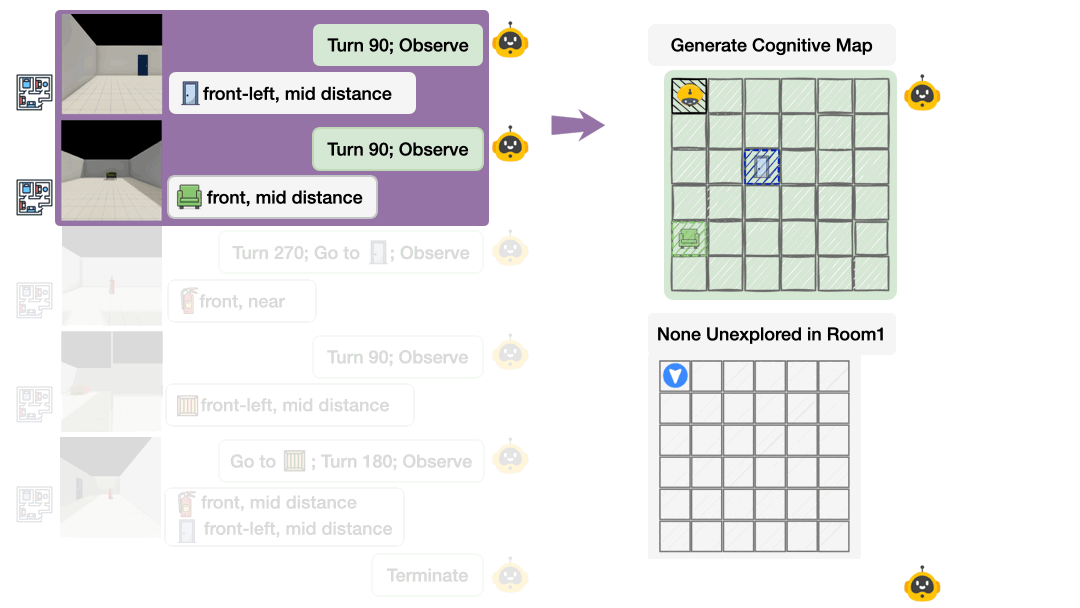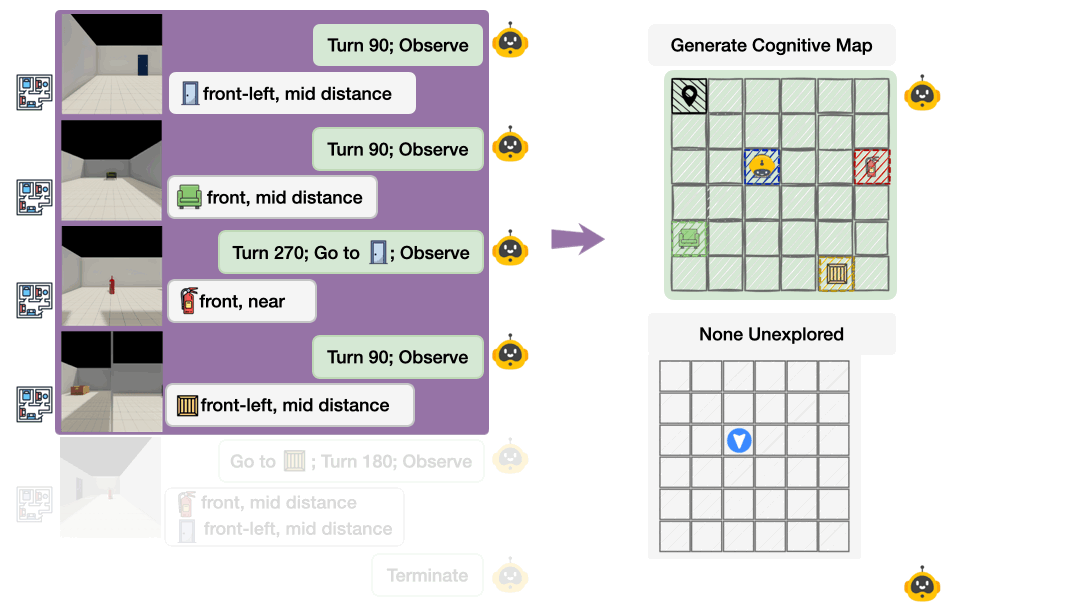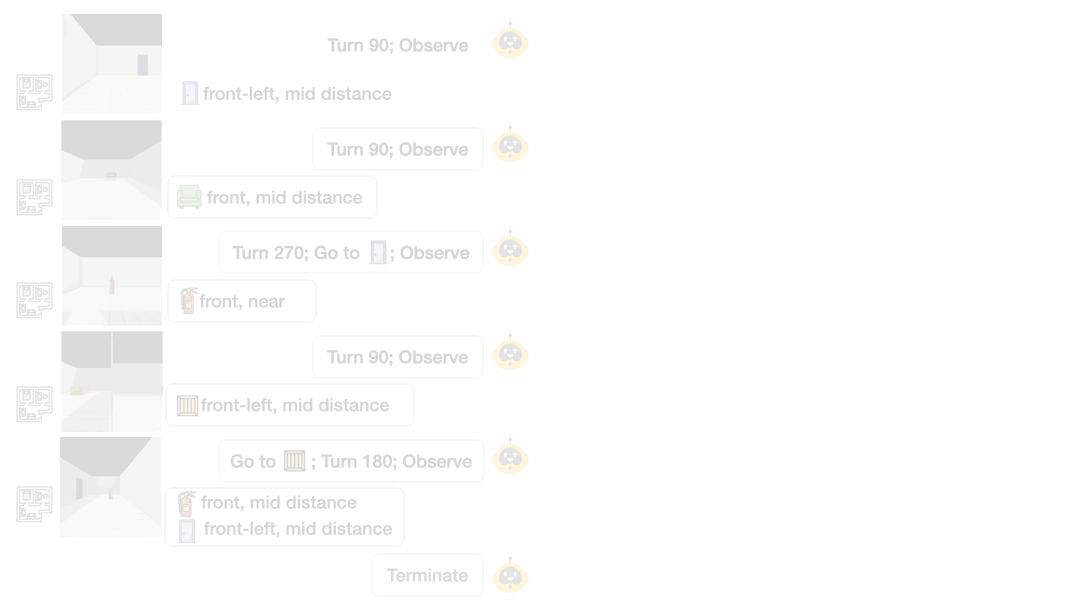
Most evaluations treat AI as a black box. We only see final answers, not internal representations. Theory of Space externalizes agents’ spatial beliefs as structured cognitive maps at each exploration step. Agents output a JSON-formatted map of observed object poses and select unobserved candidate points from a top-down map. This transforms evaluation from “did you get the right answer?” to “do you actually understand the space?”
We evaluate six state-of-the-art foundation models:
- Closed-source: GPT-5.2 (multimodal vision + tool use; 400K context); Gemini 3 Pro (native text/image/video/audio/PDF; 1M input tokens); Claude Sonnet 4.5 (multimodal + “computer use”; strong coding/agents).
- Open-source: GLM-4.6V (106B, 128K; native multimodal function/tool calling); Qwen3-VL-235B-A22B Thinking (open-weight MoE VLM; 256K context; strong visual/spatial/video understanding); InternVL 3.5-241B-A28B (open-source multimodal; Cascade RL + dynamic visual token routing)
Modality Gap: Text significantly outperforms vision across all metrics. A clear modality gap persists in both spatial belief construction and exploitation.
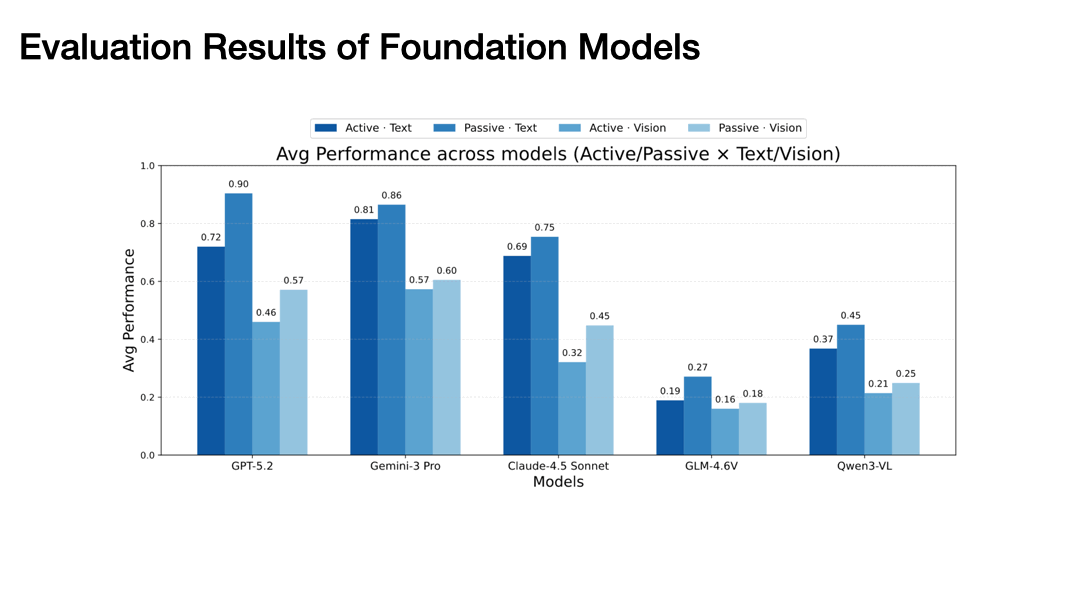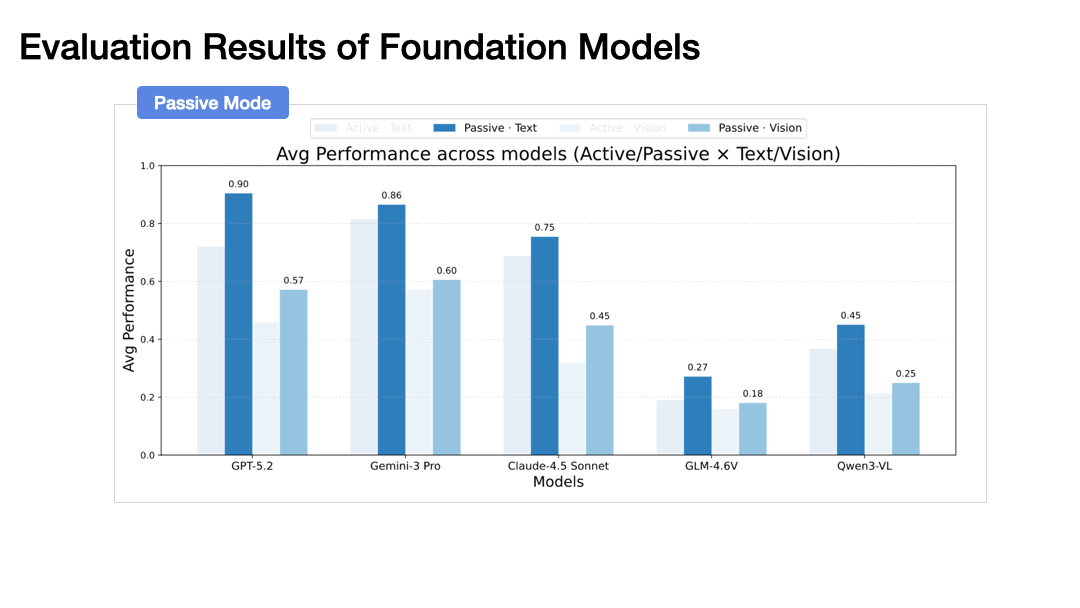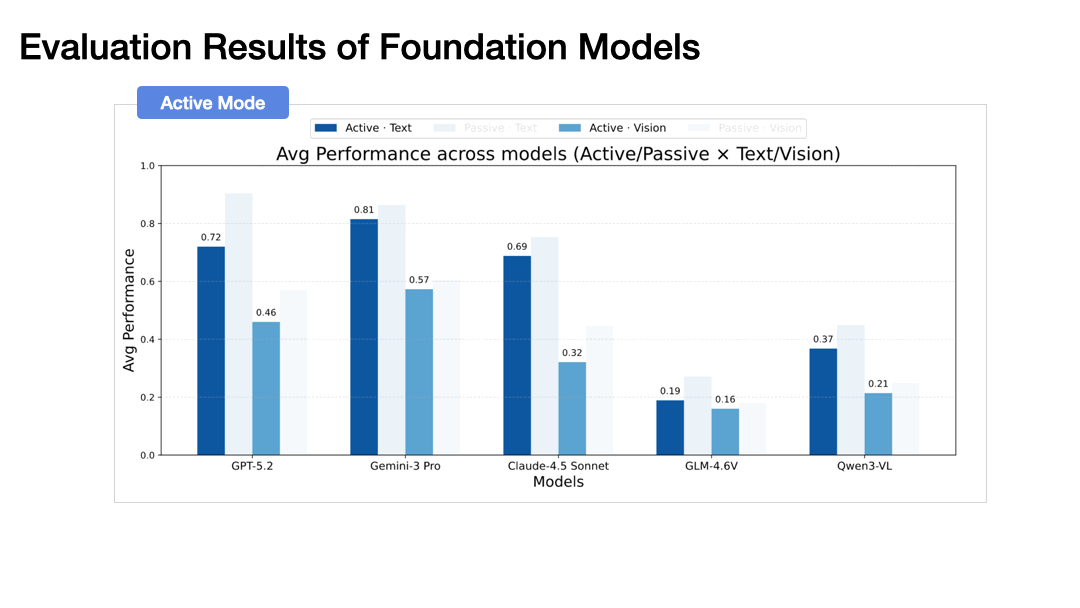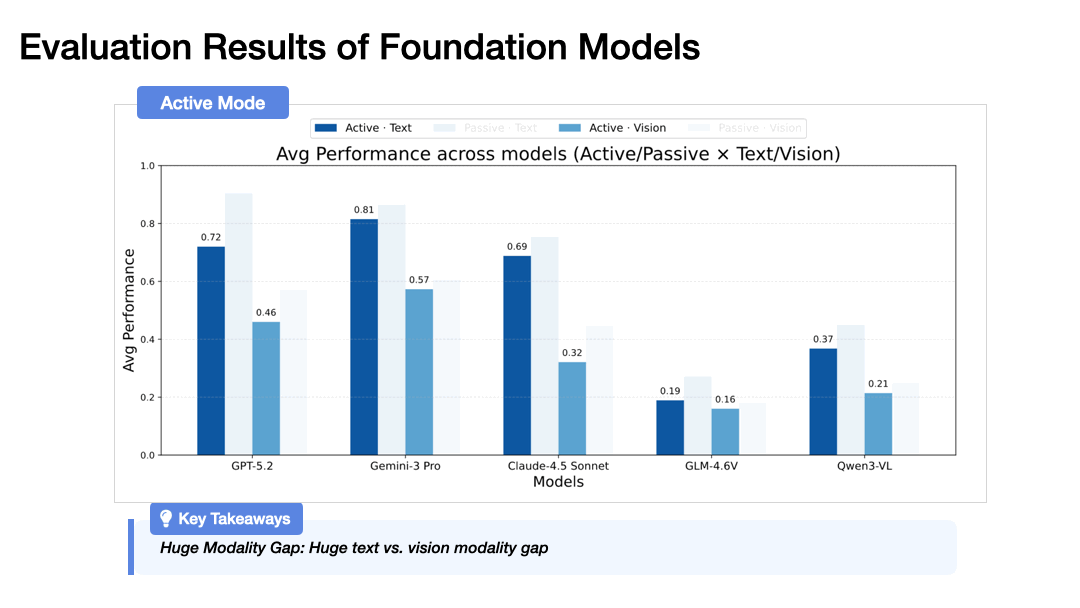
Active Exploration Bottleneck
Our experiments with state-of-the-art models (GPT-5.2, Gemini-3 Pro, Claude-4.5 Sonnet) reveal the striking finding:
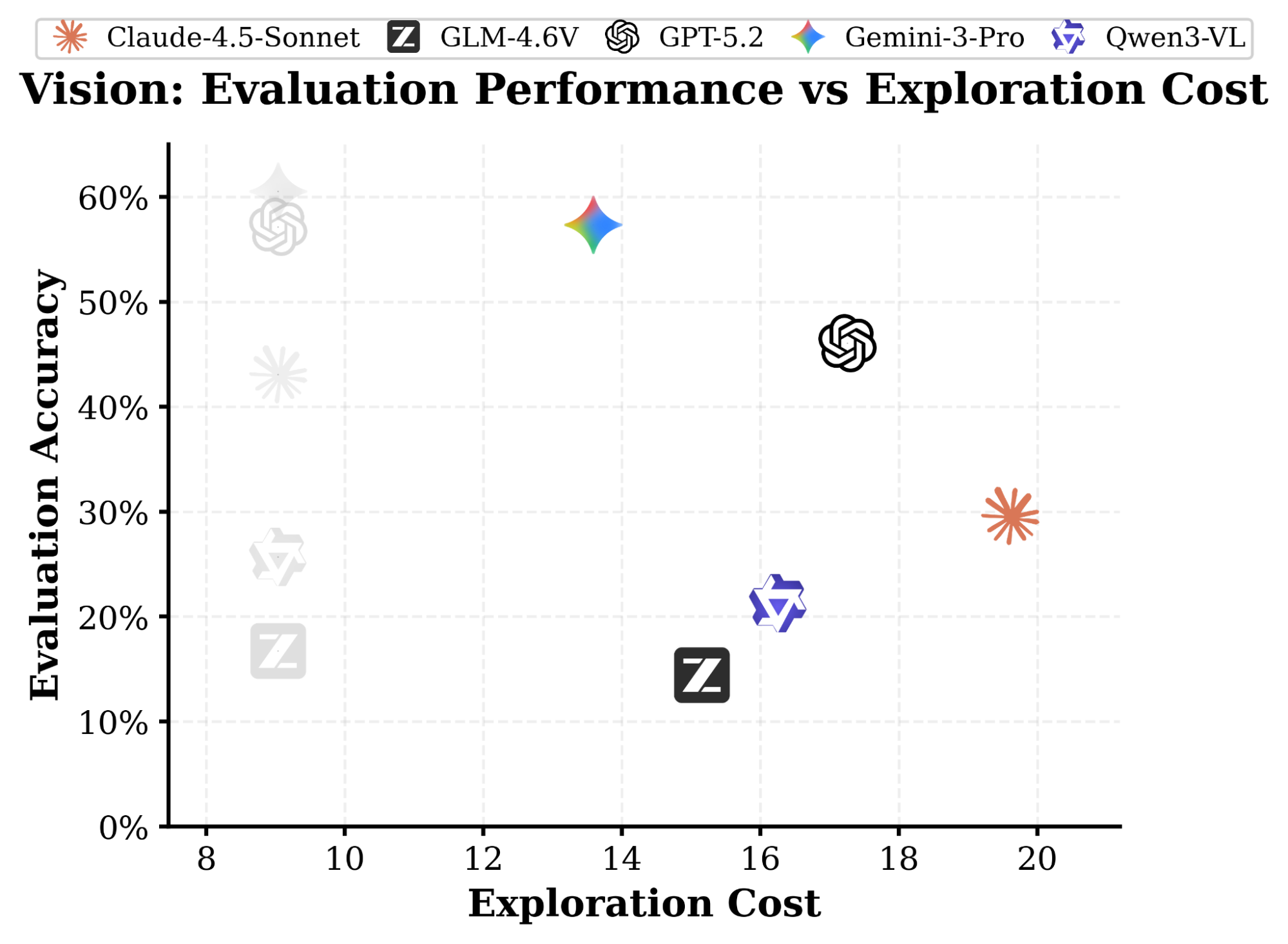
The chart shows evaluation accuracy (how well models exploit their beliefs to answer downstream spatial tasks like pairwise directions, perspective taking, and localization) versus exploration cost, where the exploration cost is evaluated as the number of exploration steps.
Faded icons mark passive settings; solid icons show active exploration.
Active Exploration is the Bottleneck:
-
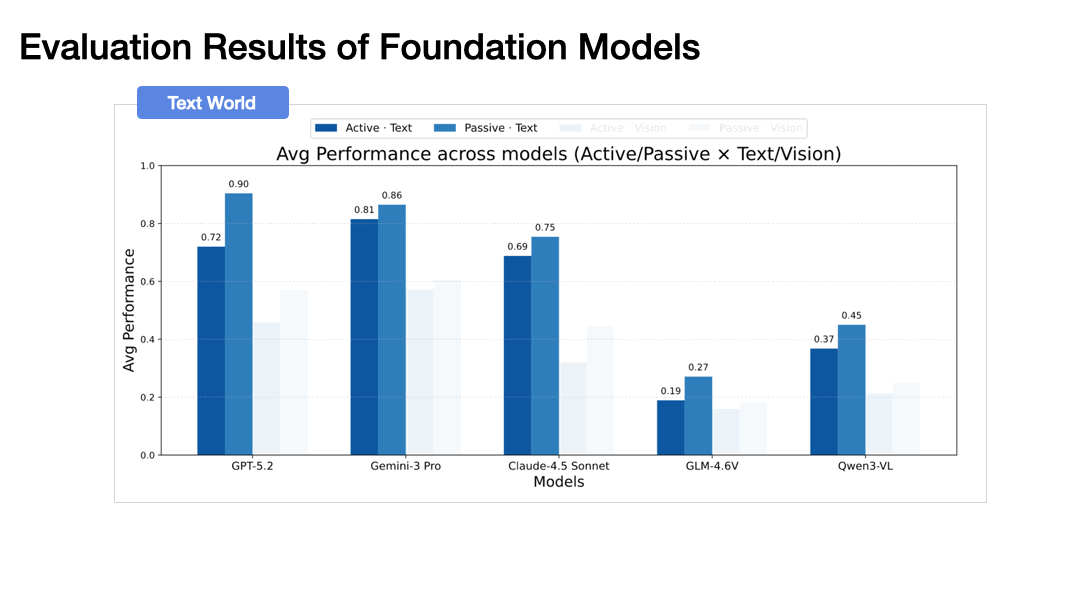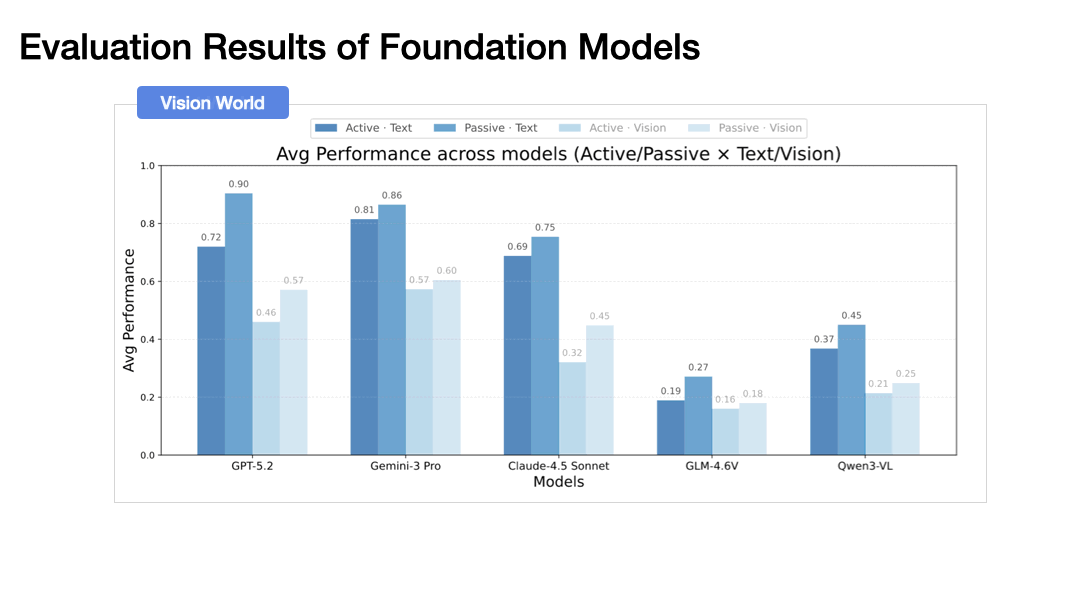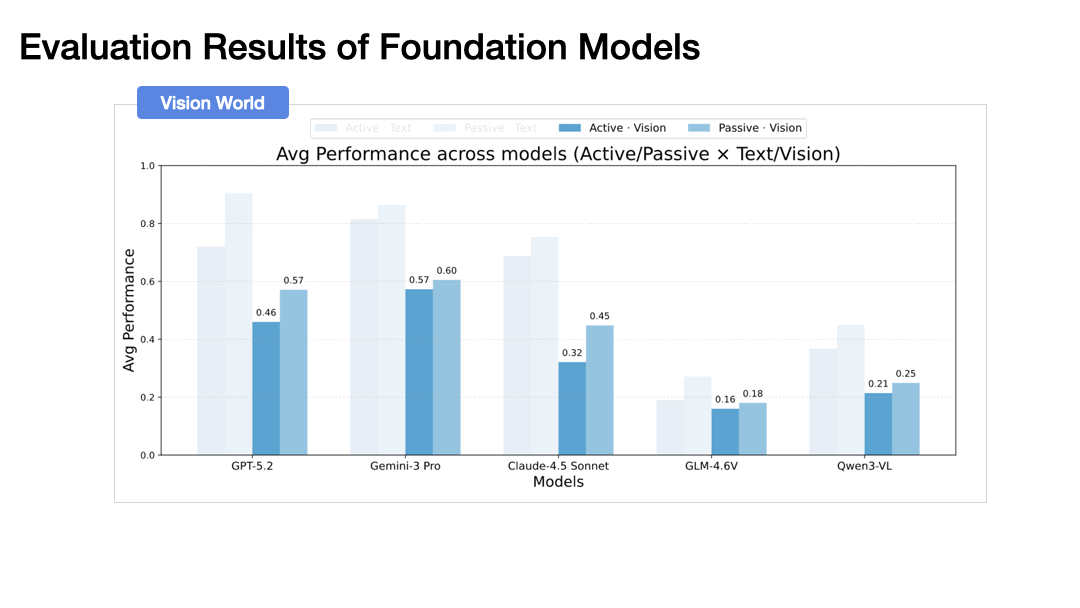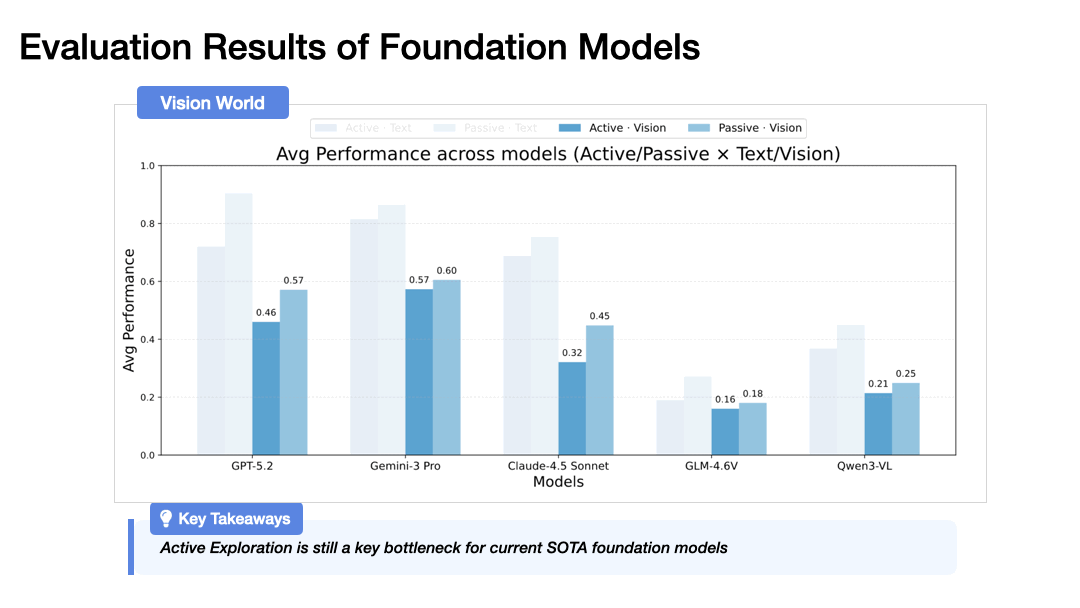
Performance drops dramatically when agents must actively explore rather than passively receive observations. In the vision-based world, GPT-5.2 drops from 57.1% to 46.0%, and Gemini-3 Pro from 60.5% to 57.3%. This gap widens with environment complexity.
-
Exploration Inefficiency: Our scripted proxy agents reach target coverage in approximately 9 steps. Foundation models take 14+ steps and still produce less accurate beliefs, often chasing every new door immediately and leaving rooms partially explored.
Spatial Belief Probing Results
We evaluate the probed cognitive maps along four dimensions:
-
Correctness: Does the map match ground truth for object positions, directions, and orientations?
-
Perception: Are newly observed objects encoded accurately?
-
Stability: Do beliefs about previously seen objects degrade over time?
-
Self-tracking: Does the agent know where it is?
Cognitive Map Failures: Vision perception is a bottleneck, especially for object orientation. In vision settings, orientation correctness drops to 20-32% compared to 91-92% in text. Stability scores reveal that beliefs about previously observed objects degrade over time (56-62% in vision), and new updates corrupt earlier correct perceptions.
Belief Revision Failures
Using a false belief paradigm, we secretly relocate objects after initial exploration. The agent must re-explore and update its mental map. Two critical failures emerge:
Vision-based Revision Failures: Vision agents suffer from excessive exploration redundancy (6.2 redundant steps for GPT-5.2) and poor accuracy in identifying object shifts.
-
GPT-5.2 orientation identification: 97.9% (text) vs 14.3% (vision)
-
Gemini-3 Pro orientation identification: 98.7% (text) vs 23.9% (vision)
Belief Inertia: Agents persist in obsolete spatial coordinates despite new observations. In vision settings, orientation inertia reaches 68.9% for GPT-5.2, meaning agents frequently fail to overwrite their initial spatial memory despite directly observing objects in new locations.
Looking Ahead
Theory of Space reframes spatial evaluation from “can the model answer?” to “can the model build and maintain a coherent, revisable spatial world model through efficient information gathering?”
We hope this benchmark provides a foundation for developing AI systems with uncertainty-aware exploration policies, robust belief maintenance over long horizons, and reliable mechanisms for revising beliefs when environments change.
Our paper, code, and benchmark are available at: https://theory-of-space.github.io/
-
Premack, David, and Guy Woodruff. “Does the chimpanzee have a theory of mind?.” Behavioral and brain sciences 1.4 (1978): 515-526. ↩
-
Gan, C., Schwartz, J., Alter, S., Mrowca, D., Schrimpf, M., Traer, J., … Yamins, D. L. K. (2020). ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation. arXiv:2007.04954. https://arxiv.org/abs/2007.04954 ↩