Most video understanding models drown in data at inference time. Imagine watching a 60-minute security video just to answer: “Who entered the room after the clock rang?” Many models still scan frame by frame—processing thousands of irrelevant images to find a few useful moments. That is slow, expensive, and fundamentally inefficient. What if AI could search instead of see everything?
This question motivated us to rethink how vision-language models (VLMs) approach long-form video. In our paper “T*: Re-thinking Temporal Search for Long-Form Video Understanding” (CVPR 2025, arXiv:2504.02259), we introduce a simple yet powerful idea: before analyzing details, first find the few frames that matter.
The “Long Video Haystack” Problem

To formalize this challenge, we introduce the Long Video Haystack problem: given a long video and a question, locate the minimal set of frames, usually just one to five, that are sufficient to answer it. This mirrors how humans operate: we fast-forward, skim, and search for visual cues.
We develop LV-HAYSTACK, the first large-scale benchmark dataset for temporal search in long videos. Spanning 480 hours of egocentric and allocentric video, the dataset contains 15,092 human-annotated QA pairs. Each instance includes a real-world video, a question, and a small set of human-annotated keyframes that answer it.
Introducing T*: Lightweight, Visual, Efficient
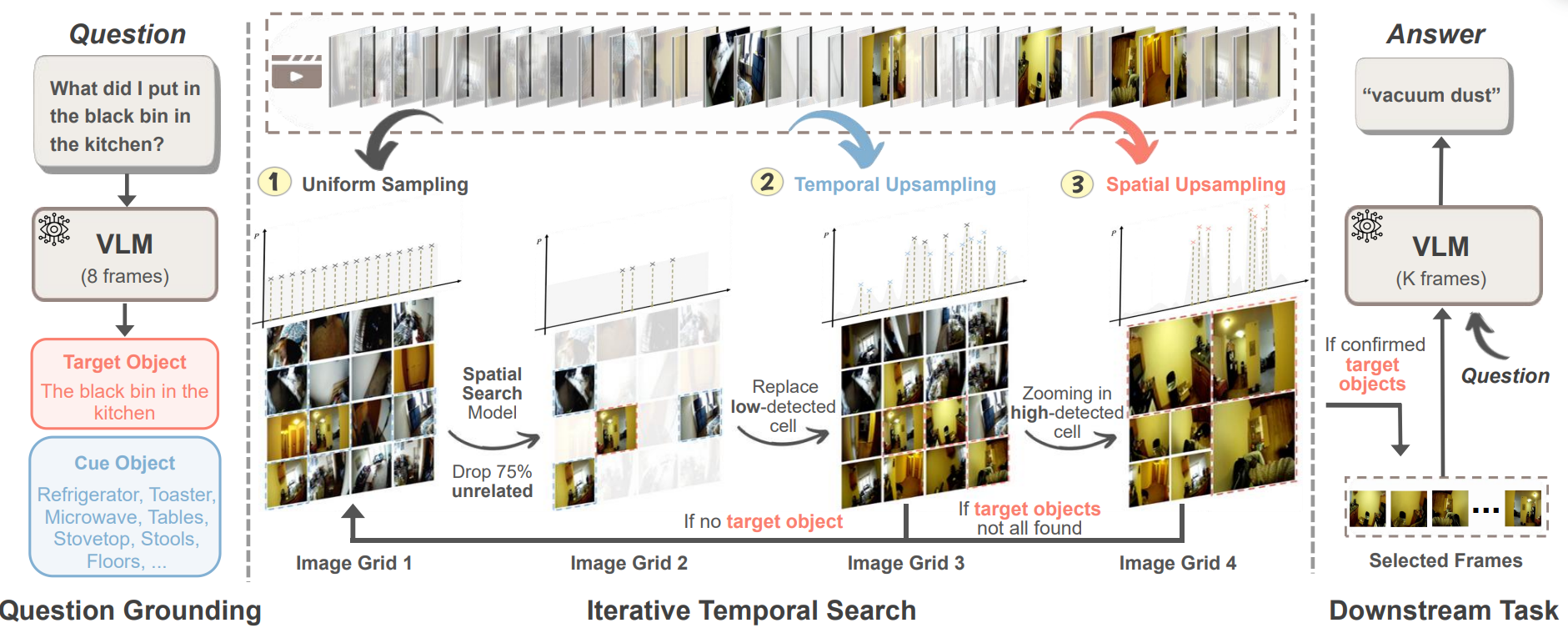
To tackle the Long Video Haystack problem, we developed T, a lightweight temporal search algorithm that reframes video understanding as spatial search. Instead of treating a video as a timeline to be processed sequentially, T composes sampled frames into grids and applies object detectors and visual grounding to guide an iterative zoom-in process. It treats a long video like a big image you can zoom through:
-
Ground the question. We first sample a handful of frames uniformly. A VLM reads the question and lists (a) the target we must find (e.g., “the black bin in the kitchen”) and (b) useful cues (e.g., “fridge, counter, stools”). These become anchors for search.
-
Turn time into a grid. We arrange sampled frames into an image grid and run a lightweight spatial search model (detector/grounder/attention). It scores each cell for the target and cues. Cells with little signal are dropped—typically most of them—so we don’t waste budget.
-
Zoom in, iteratively. We replace low-score cells with frames near the promising timestamps (temporal upsampling), and we densify around the highest-score cells (spatial upsampling). Each round keeps the good regions and throws away the rest. We repeat a few rounds until we’ve either found the target or used the small frame budget.
-
Answer with a few key frames. Finally, we send only the top-K frames to the VLM to answer the question. T* is a front-end: it works with many VLMs and many simple spatial search back-ends (e.g., YOLO-style detectors or attention heatmaps).
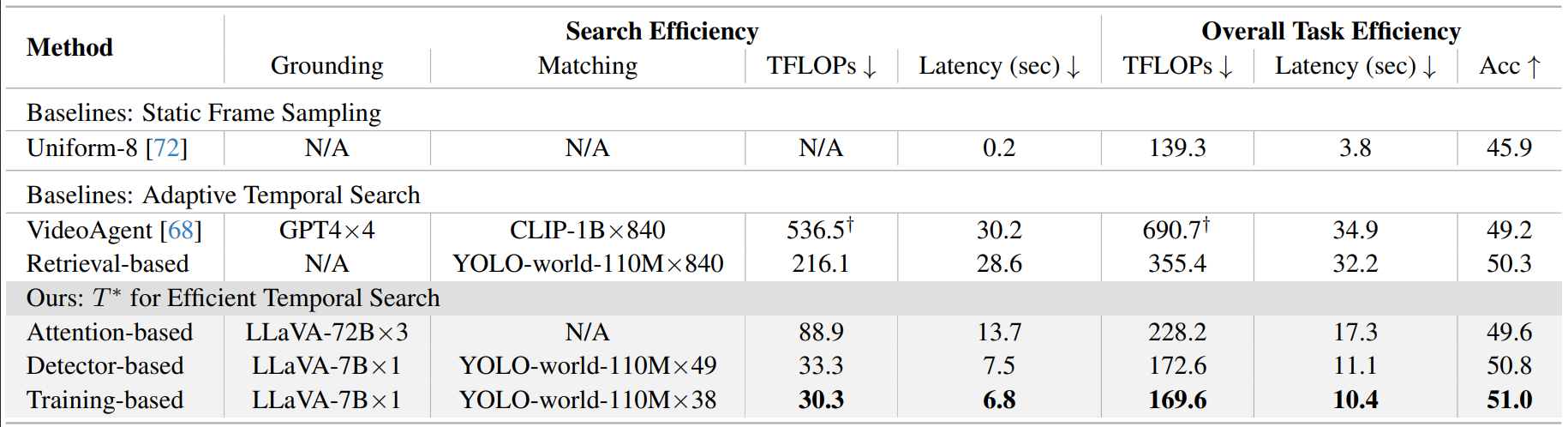
Why it’s efficient. Instead of scanning every frame, T* quickly narrows down when to look by scoring a grid, dropping most cells, and zooming into just a few short segments. You get targeted reasoning with very few frames and minimal compute—as low as 30 TFLOPs for temporal search compared to baseline’s 90–200 TFLOPs. Furthermore, T* leverages efficient, off-the-shelf detectors for temporal-spatial search, making it training-free.

This approach enables targeted reasoning using only a small number of frames. Unlike previous methods that rely on exhaustive scoring or full video modeling, T dynamically selects and refines which time regions to examine.*
The Results: Better Accuracy, Lower Cost
The T* framework was tested with leading vision-language models like GPT-4o and LLaVA-72B on long video QA tasks. The improvements were clear:
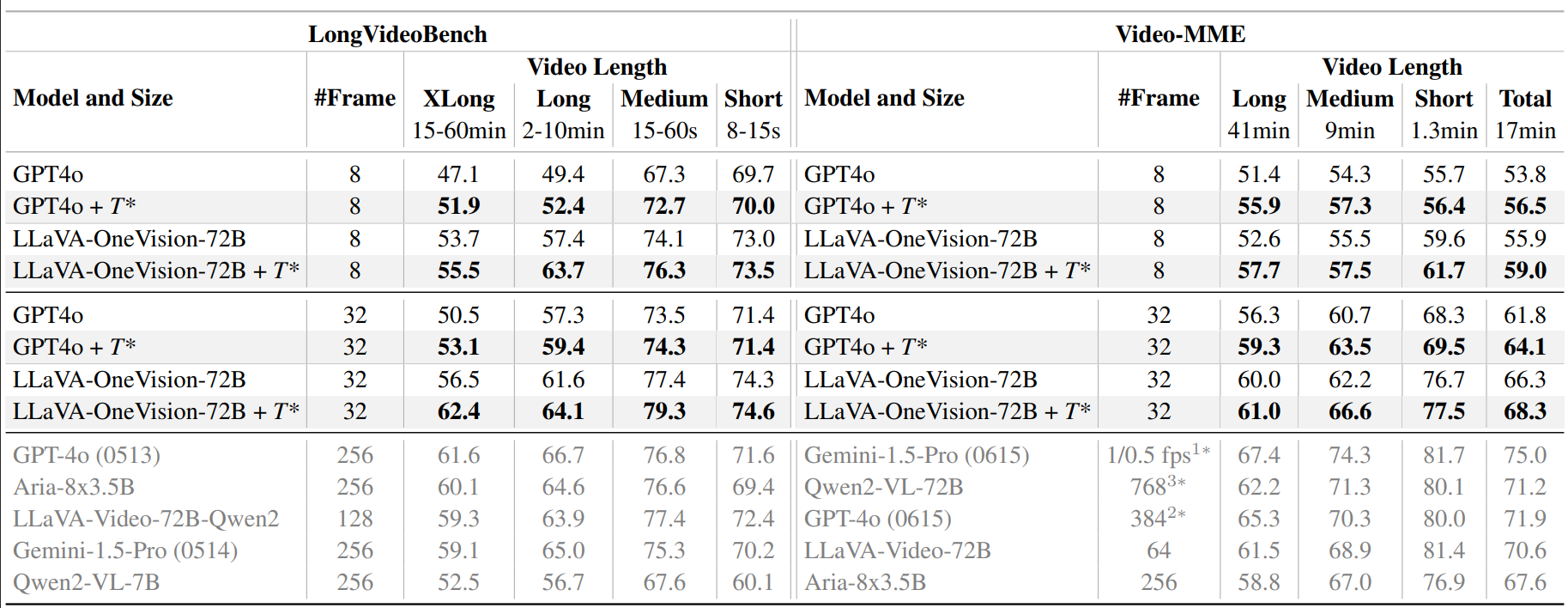
- LongVideoBench XL: T* improved GPT-4o’s accuracy from 47.1% → 51.9% using only 8 frames, beating uniform sampling baseline with 32 frames.
- Ego4D & VideoMME: T* consistently outperformed static and retrieval-based baselines.
- Efficiency: T* reduced compute costs to 30.3 TFLOPs, about 3–5× fewer FLOPs than VideoAgent and other adaptive methods, improving overall latency from 30+ s → 10.4 s.
Our paper, dataset, and code can be found at https://lvhaystackai.com/
Looking Ahead
We hope this work inspires more efficient, human-aligned approaches to long-form understanding. Future work includes incorporating multimodal cues like audio, subtitles, and gestures; expanding benchmarks; and refining evaluation metrics beyond accuracy.