TL;DR
We introduce VAGEN, a reinforcement learning framework that trains vision-language model (VLM) agents to build internal world models through explicit visual state reasoning. By encouraging agents to actively estimate the current state and predict future transitions, our 3B parameter model achieves state-of-the-art results across diverse visual tasks.
Introduction
Vision-Language Models (VLMs) have shown remarkable capabilities in understanding images and following instructions. Increasingly, these models are being deployed as visual agents — systems that interact with environments over multiple steps by perceiving visual observations, reasoning about state, and taking actions. Examples include web-browsing assistants that navigate interfaces, household robots that manipulate objects, and game agents that explore virtual worlds.
Visual agents are important because many real-world tasks are inherently interactive and sequential. Solving them requires not just understanding a single image, but maintaining context, planning ahead, and adapting as new observations arrive.
However, when VLMs are used as multi-turn agents, their performance often degrades significantly. Why?
A key reason is partial and noisy visual observations. At each turn, the agent only sees a screenshot or camera view which is a limited snapshot of the environment. The true state requires integrating information across multiple interactions. This is fundamentally different from single-turn visual QA, where all necessary information is present in one image, and from text-based agents, where the environment state is comprehensive and clean in text.
In this blog post, we introduce VAGEN (VLM Agent Training with World Model Reasoning), a framework that explicitly teaches VLM agents to build and maintain internal world models through reinforcement learning.
The Problem: VLM Agents and Partial Observability
Framing as a POMDP
We formulate multi-turn VLM agent tasks as a Partially Observable Markov Decision Process (POMDP), illustrated in the image below.
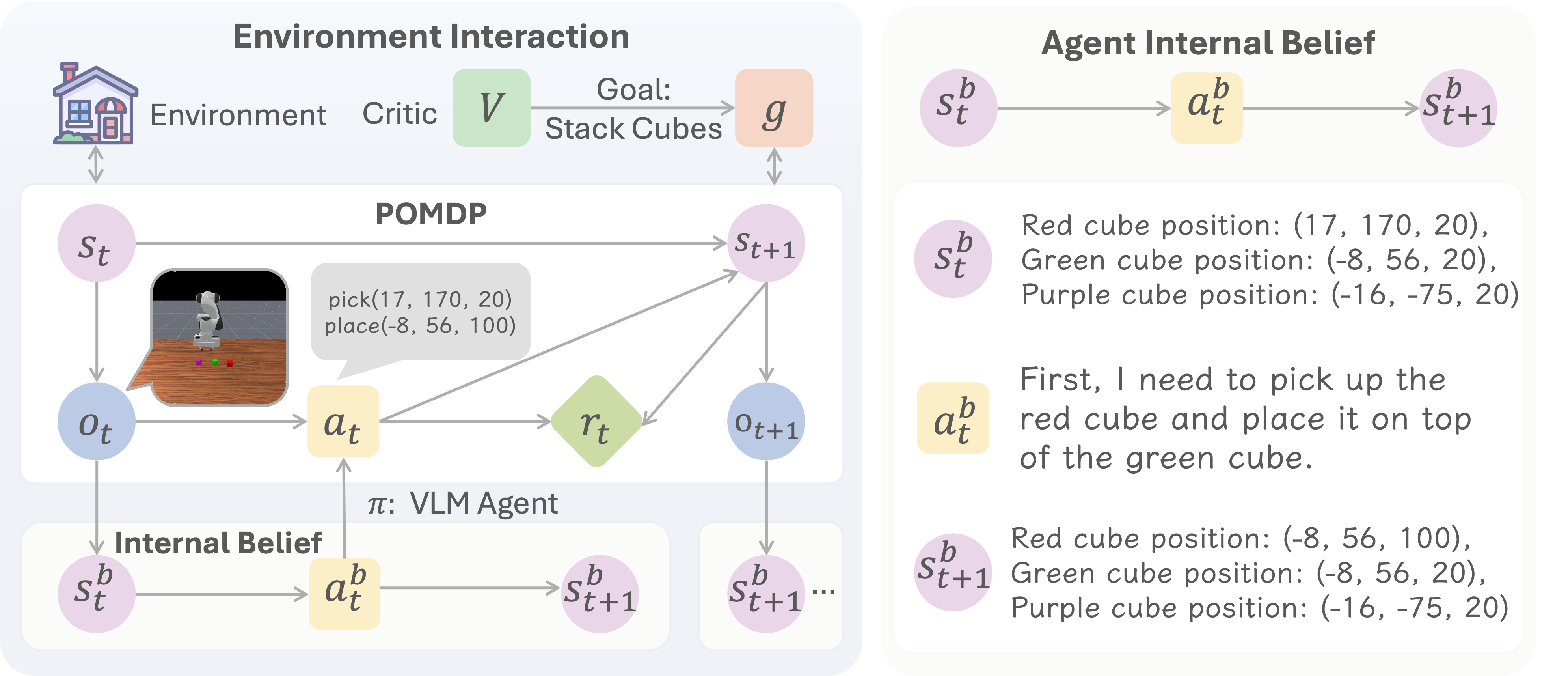
In a POMDP:
- The agent receives observations (images + text prompts) rather than the full environment state
- The true state contains information the agent cannot directly see
- The agent must infer the underlying state from its observation history
Our Approach: World Modeling with Structured Reasoning
We propose training VLM agents to perform explicit world modeling through two complementary reasoning processes:
1. State Estimation (Grounding)
“What is the current state?”
The agent learns to ground its visual observation into a structured state representation. For example:
- In a grid world: “The player is at position (2,3), there’s a wall to the north”
- In navigation: “I’m in a bedroom, facing the door, the target is a couch”
- In robot manipulation: “The gripper is above the red cube, which is on the table”
2. Transition Modeling (Prediction)
“What will happen next?”
The agent learns to predict how its actions will change the environment state:
- “If I move right, I’ll be at position (3,3)”
- “If I go through the door, I’ll enter the living room”
- “If I close the gripper, I’ll be holding the red cube”
The Combined World Modeling Strategy
We structure the agent’s output as:
<think>
<observation>
[State estimation: what is the current state?]
</observation>
[General reasoning...]
<prediction>
[Transition modeling: what will happen after my action?]
</prediction>
</think>
<answer>[executable action]</answer>
This structured format serves two purposes:
- During training: We can extract and evaluate the reasoning to provide targeted rewards
- During execution: The explicit reasoning improves action quality by forcing the model to think systematically
Five Reasoning Strategies
We compare five strategies for incorporating reasoning into VLM agents:
| Strategy | Description | Output Format |
|---|---|---|
| NoThink | Direct action output, no reasoning | <answer>action</answer> |
| FreeThink | Unconstrained chain-of-thought | <think>...</think><answer>action</answer> |
| StateEstimation | Only estimate current state | <think><observation>...</observation></think><answer>action</answer> |
| TransitionModeling | Only predict transitions | <think><prediction>...</prediction></think><answer>action</answer> |
| WorldModeling | Both estimation + prediction | <think><observation>...</observation>...<prediction>...</prediction></think><answer>action</answer> |
Training Algorithm: WorldModeling RL
On-Policy Agentic Training
Following the common agentic RL training paradigm, VAGEN employs an iterative on-policy training loop that alternates between rollout and policy update:

Rollout Phase: The VLM agent interacts with diverse visual environments through multi-turn episodes. At each turn, the agent receives a visual observation, generates structured reasoning and actions, and receives environment feedback. Complete trajectories are collected in a trajectory buffer.
Training Phase: The policy is updated using RL algorithms (PPO, GRPO, etc.) with collected trajectories.
What distinguishes VAGEN are two key components designed for visual agentic tasks:
Component 1: WorldModeling Reward (LLM-as-Judge)
A key innovation is our WorldModeling Reward. Instead of only rewarding task success (which is sparse and delayed), we also reward accurate world modeling at each turn:
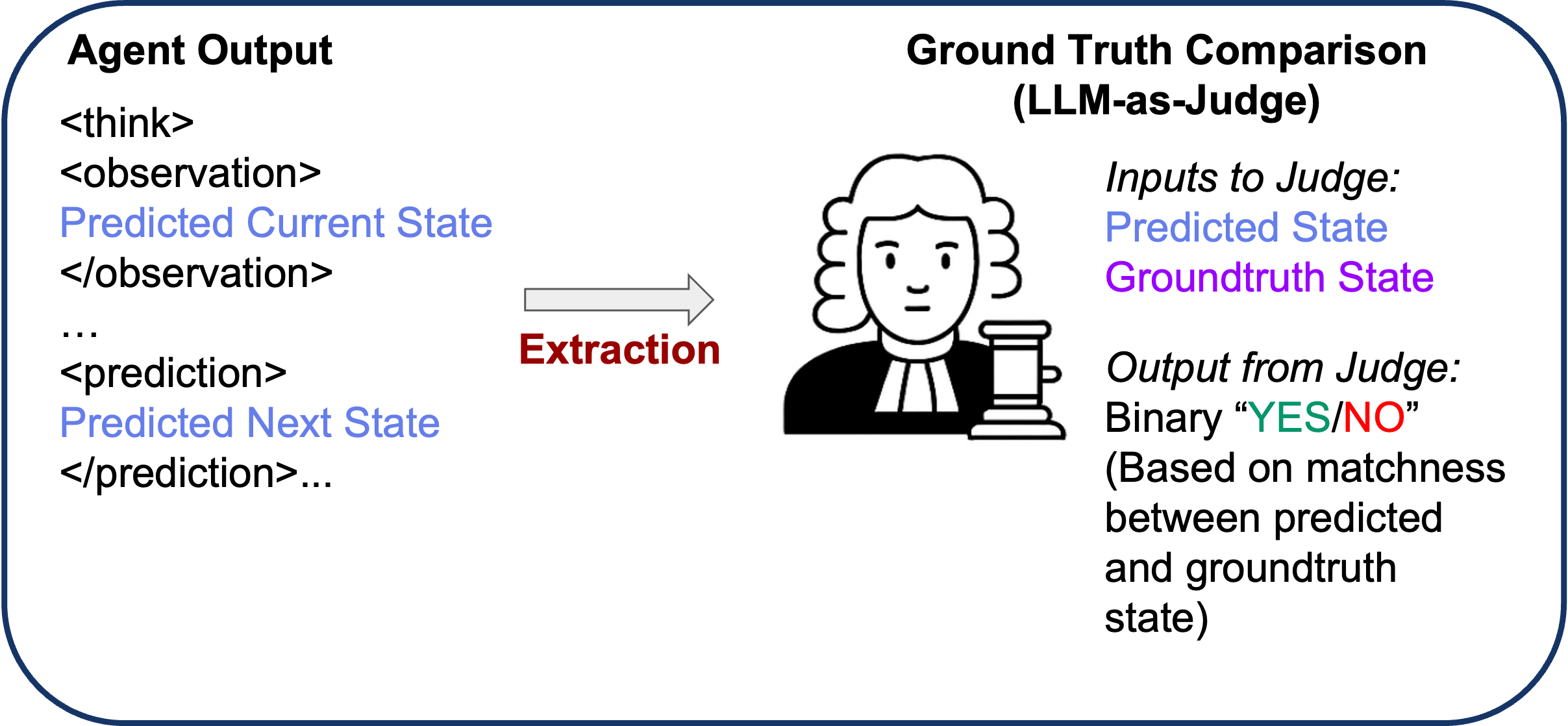
- Extract the agent’s state estimation and transition predictions from its output
- Compare against ground truth states from the simulator
- Score using an LLM judge that determines if the prediction matches ground truth
This provides dense, intermediate rewards that guide the agent to develop accurate internal representations, even when task rewards are sparse.
Component 2: Bi-Level GAE for Credit Assignment
Multi-turn agentic tasks introduce a credit assignment challenge: which parts of an interaction actually drove success or failure?
A common solution in policy gradient methods for RL is Generalized Advantage Estimation (GAE), which estimates how much each action improves outcomes relative to a baseline while balancing bias and variance. GAE is widely used in PPO to produce stable training signals.
In single-turn RL for VLMs, GAE is typically applied at the token-level, distributing trajectory-level rewards across generated tokens so the model can learn which parts of its reasoning or actions were helpful.
However, multi-turn agents operate across longer horizons and multiple temporal scales. This creates a mismatch, where we need to distinguish between:
- Turn-level credit: Which turns were pivotal for task success?
- Token-level credit: Within each turn, which tokens (reasoning vs. action) mattered most?
Bi-Level GAE addresses this by:
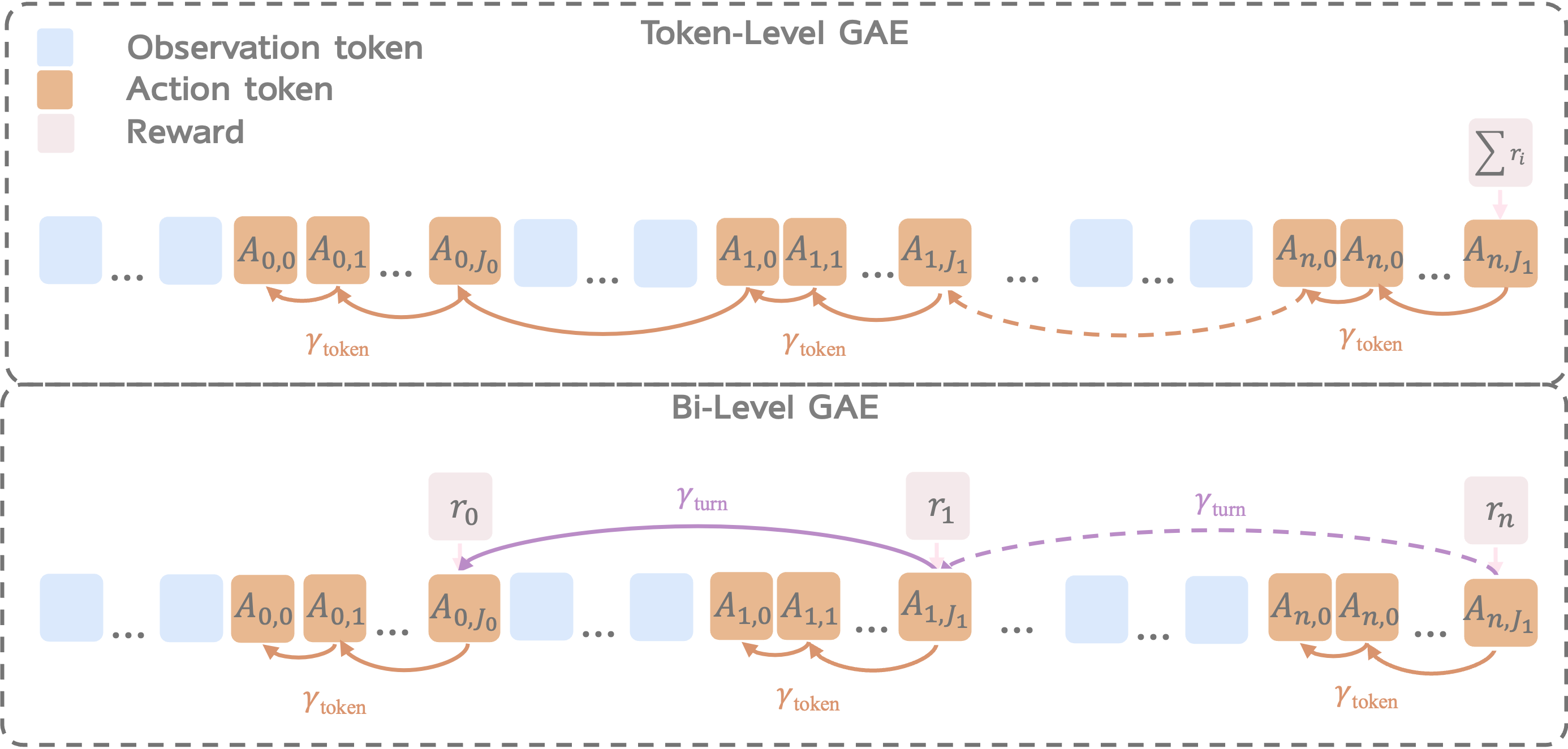
- First computing turn-level advantages using rewards at turn boundaries
- Then computing token-level advantages within each turn and using separate discount factors for each level
This hierarchical structure provides more precise learning signals for multi-turn reasoning tasks.
Evaluation: Five Diverse Visual Tasks
We evaluate VAGEN across five tasks that require different types of visual reasoning:
Task Overview





Task Details
-
FrozenLake: Navigate a 4x4 frozen lake grid. The agent must reach the goal while avoiding holes. Requires understanding position and planning safe paths.
-
Sokoban: Classic box-pushing puzzle. The agent must push all boxes onto target locations. Requires spatial reasoning and planning multiple moves ahead.
-
Visual Navigation: Navigate through realistic 3D indoor environments (AI2-THOR) to find target objects. Requires visual understanding and exploration strategy.
-
ManiSkill (Robot Manipulation): Control a robot arm to pick and place objects. Requires understanding 3D spatial relationships and precise action sequences.
-
SVG Construction: Generate SVG code that reconstructs a target image. A unique visual-to-code task requiring iterative refinement across multiple turns.
Results
The main results comparing VAGEN with proprietary VLMs across all five tasks (average scores) are given below:
| Model | Sokoban | FrozenLake | Navigation | PrimitiveSkill | SVG | Overall |
|---|---|---|---|---|---|---|
| Open-Source Models | ||||||
| Qwen2.5-VL-72B | 0.18 | 0.44 | 0.73 | 0.44 | 0.76 | 0.51 |
| Qwen2.5-VL-7B | 0.13 | 0.14 | 0.34 | 0.19 | 0.55 | 0.27 |
| Qwen2.5-VL-3B | 0.14 | 0.14 | 0.24 | 0.00 | 0.54 | 0.21 |
| VLM-R1-3B | 0.13 | 0.13 | 0.33 | 0.00 | 0.55 | 0.23 |
| VAGEN (Ours, Backbone: Qwen2.5-VL-3B) | ||||||
| FreeThink | 0.57 | 0.68 | 0.67 | 0.66 | 0.78 | 0.67 |
| NoThink | 0.57 | 0.09 | 0.00 | 0.00 | 0.76 | 0.28 |
| StateEstimation | 0.56 | 0.68 | 0.74 | 0.00 | 0.78 | 0.56 |
| TransitionModeling | 0.41 | 0.76 | 0.62 | 0.82 | 0.77 | 0.68 |
| WorldModeling (VAGEN-Base) | 0.61 | 0.71 | 0.79 | 0.91 | 0.78 | 0.76 |
| VAGEN-Full | 0.79 | 0.74 | 0.81 | 0.97 | 0.79 | 0.82 |
| RL Baselines | ||||||
| Vanilla-PPO | 0.18 | 0.21 | 0.29 | 0.00 | 0.64 | 0.26 |
| GRPO w/ Mask | 0.20 | 0.57 | 0.85 | 0.25 | 0.79 | 0.54 |
| Turn-PPO w/ Mask | 0.38 | 0.70 | 0.81 | 0.25 | 0.77 | 0.55 |
| Proprietary Models | ||||||
| GPT-5 | 0.70 | 0.77 | 0.78 | 0.66 | 0.85 | 0.75 |
| o3 | 0.60 | 0.78 | 0.78 | 0.66 | 0.82 | 0.73 |
| o4-mini | 0.44 | 0.82 | 0.75 | 0.56 | 0.78 | 0.67 |
| GPT-4o | 0.43 | 0.54 | 0.72 | 0.50 | 0.80 | 0.60 |
| Gemini 2.5 Pro | 0.58 | 0.78 | 0.63 | 0.50 | 0.86 | 0.67 |
| Gemini 2.0 | 0.28 | 0.61 | 0.56 | 0.28 | 0.84 | 0.51 |
| Claude 4.5 Sonnet | 0.31 | 0.80 | 0.67 | 0.53 | 0.88 | 0.64 |
| Claude 3.7 Sonnet | 0.25 | 0.69 | 0.47 | 0.44 | 0.85 | 0.54 |
Key Findings
1. VAGEN significantly outperforms proprietary models
Our 3B parameter model trained with VAGEN achieves 0.82 overall score, compared to:
- GPT-5: 0.75
- Gemini 2.5 Pro: 0.67
- Claude 4.5: 0.62
This demonstrates that explicit world modeling training is more effective than simply scaling model size.
2. WorldModeling strategy is consistently best
Across all tasks, the full WorldModeling strategy (combining state estimation and transition modeling) outperforms other reasoning approaches:
| Strategy | Overall Performance |
|---|---|
| NoThink | Baseline |
| FreeThink | +12% |
| StateEstimation | +18% |
| TransitionModeling | +20% |
| WorldModeling | +25% |
3. Both components of WorldModeling RL help
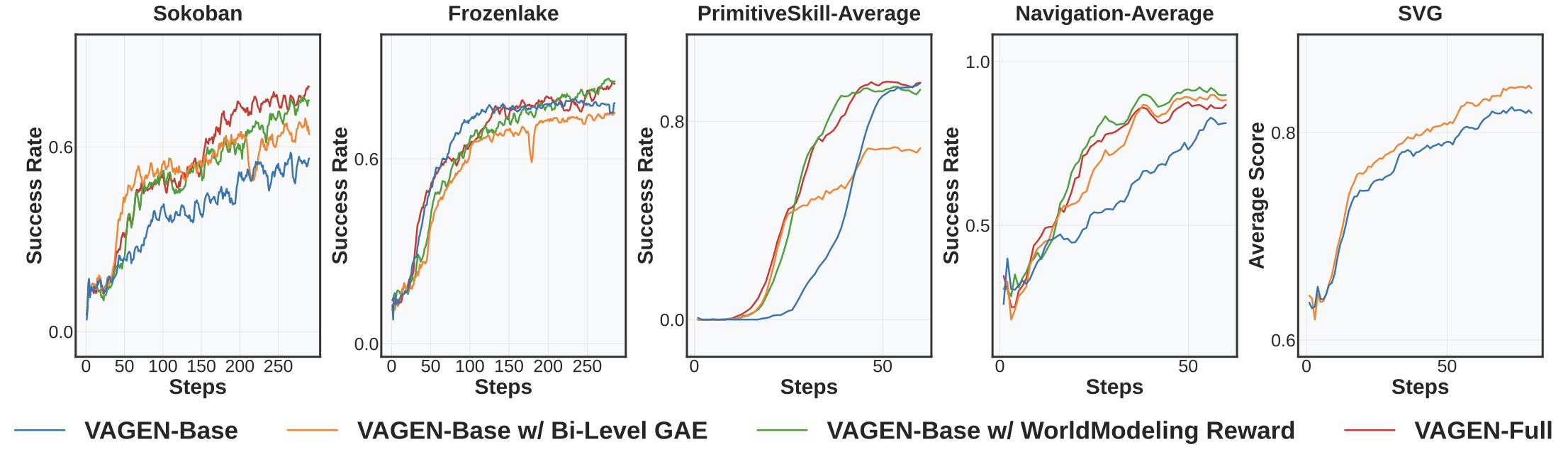
We did ablation study to show the contribution of each component.
- WorldModeling Reward alone: Consistently improves performance by providing visual learning signals, but limited by coarse credit assignment
- Bi-Level GAE alone: Notable but unstable improvements, sensitive to reward sparsity
- VAGEN-Full (both): Most robust, achieving strong and stable results across all tasks
Conclusion and Limitations
We introduce a multi-turn reinforcement learning framework that rewards the reasoning process to build an internal world model through explicit visual state reasoning over StateEstimation (grounding) and TransitionModeling (prediction). In this way, the VLM agent learns to explore the environment to understand its causal/transition dynamics, and update internal beliefs as multi-turn interactions unfold.
To optimize an agent’s world model reasoning, we propose WorldModeling Reward for dense turn-level feedback that evaluates the accuracy of the agent’s internal state simulation against ground-truth. To solve the critical challenge of long-horizon credit assignment, we propose Bi-Level GAE that first computes the value of an entire turn’s reasoning before propagating that credit precisely to individual tokens.
Our VAGEN framework significantly enhances task performance and visual reasoning quality for VLMs in agentic tasks. Limitations include restricted model architecture and evaluation environments. Future work will explore additional VLM families and unified multi-modal models for image-based world modeling.
Resources
- Paper: arXiv
- Code: GitHub
- Project Page: https://vagen-ai.github.io/