|
Prateek Verma - Research Samples
Here, I have given a list with a short description of my papers and research articles. Most of these papers were written under the constraint of working on a project or the requirements/deliverables.
While I am not on academic twitter/linkedin, I'm happy to connect via email! Drop me a line at “id@stanford.edu” where id is prateekv
Journal Papers
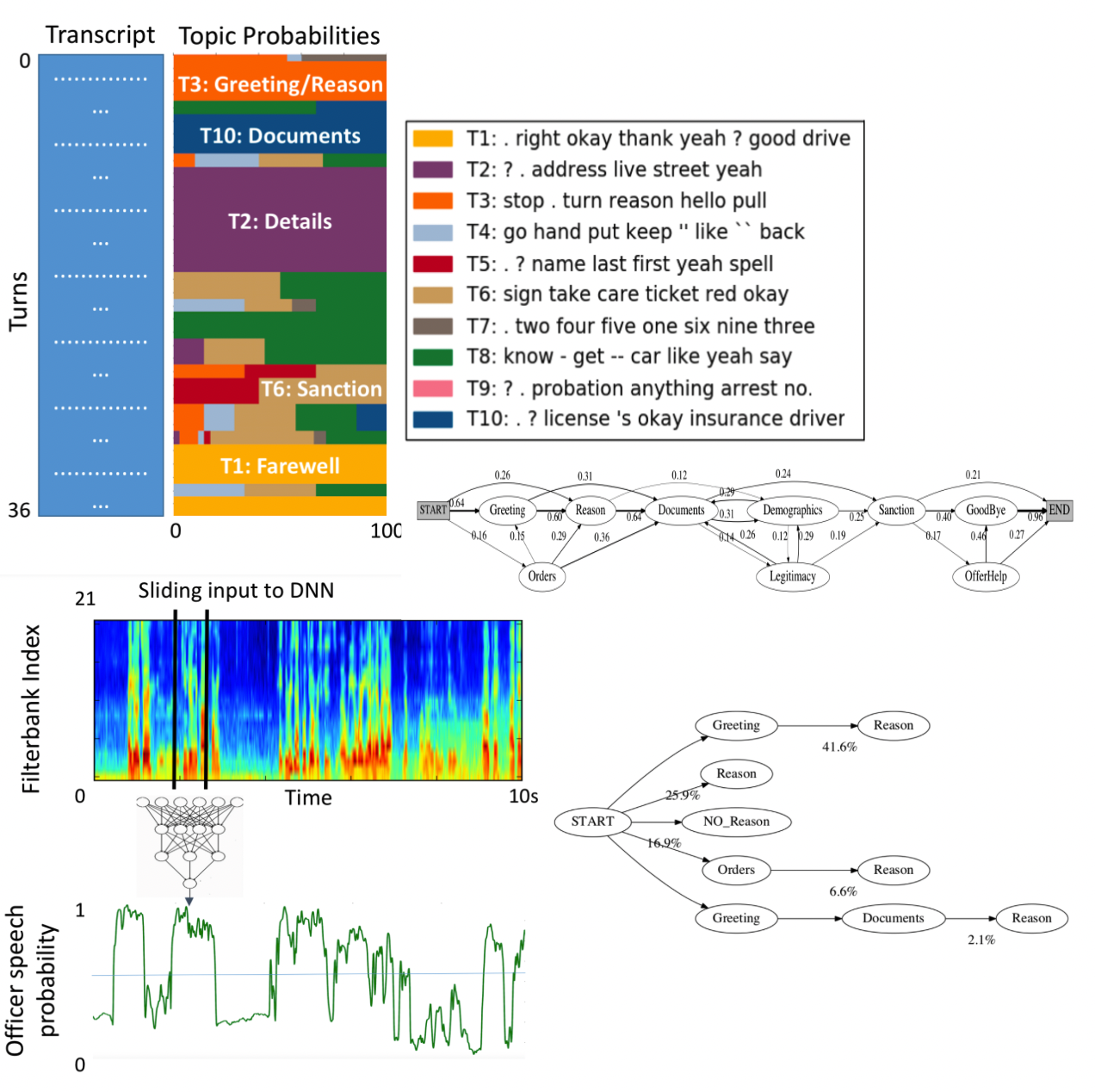 |
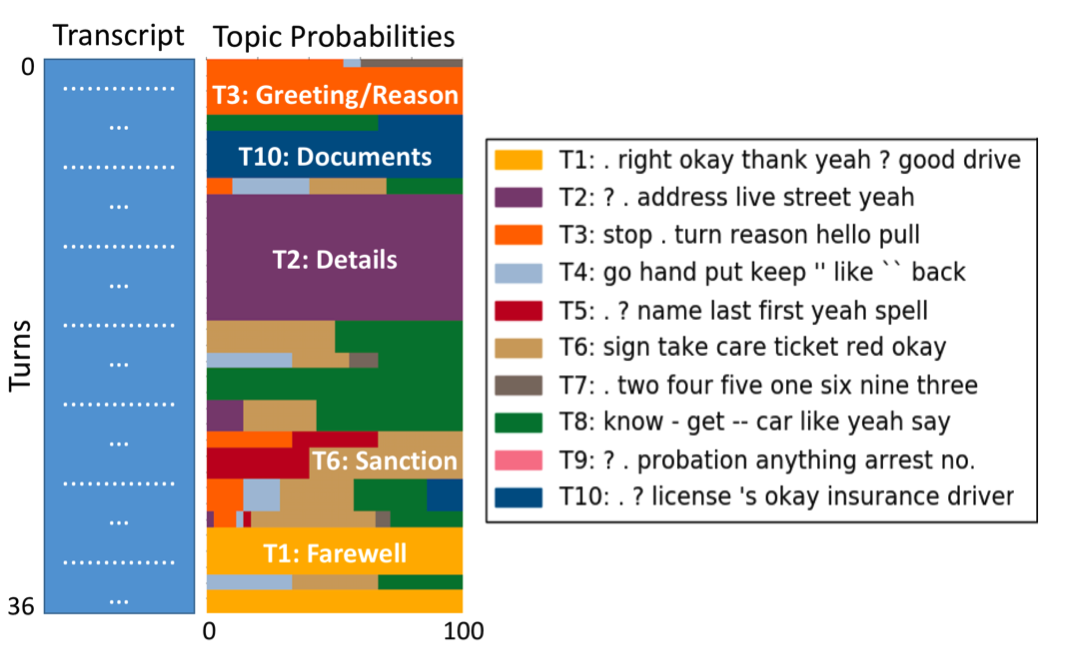
Vinodkumar Prabhakaran, Camilla Griffiths, Hang Su, Prateek Verma, Nelson Morgan, Jennifer Eberhardt, Dan Jurafsky, “Detecting Institutional Dialog Acts in Police Traffic Stops” Transactions of the Association for Computational Linguistics, MIT Press, 2018. (Also presented at ACL ’18 Melbourne)
Using AI and Speech algorithms to better understand officer behavior in actual world body cam recordings of Oakland Police Department. We demonstrate that the dialog structures produced by our tagger could reveal whether officers follow law enforcement norms, like introducing themselves, explaining the reason for the stop, and asking permission for searches. This work may, therefore, inform and aid efforts to ensure the procedural justice of police-community interactions.
|
Conference and Workshop Papers (with preprints)
2024
2023
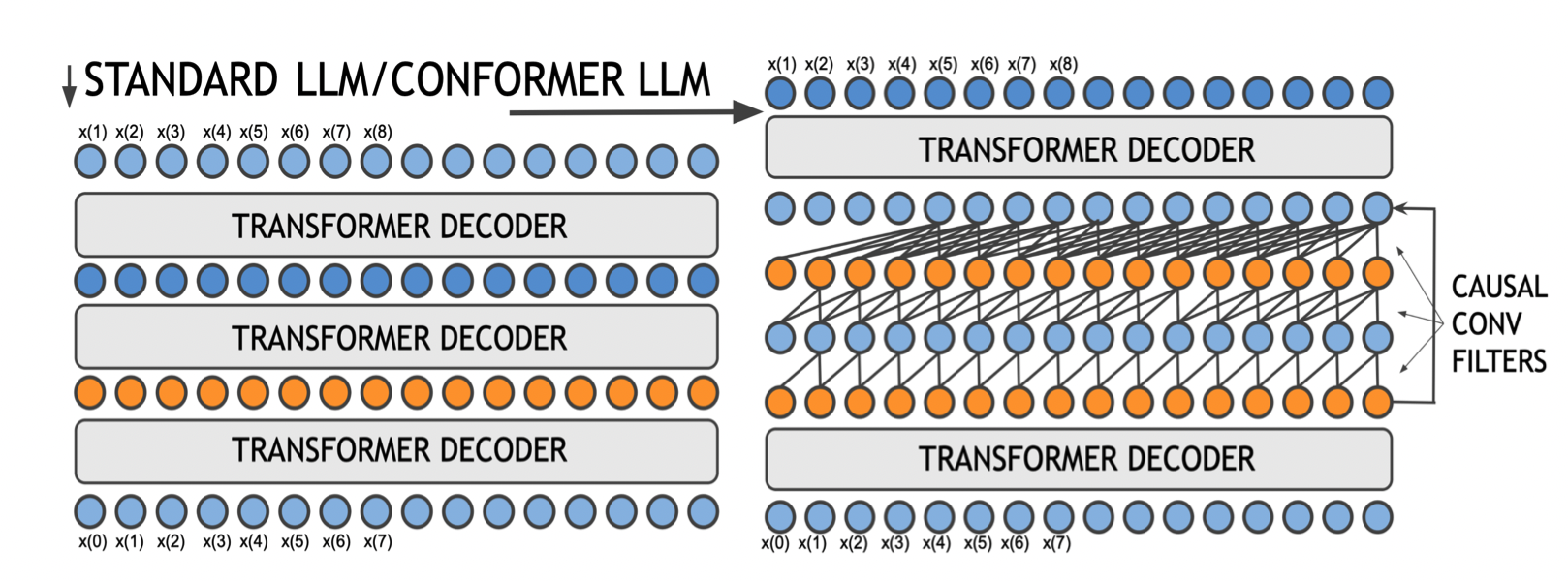 |
Prateek Verma, “Conformer LLMs - Convolution Augmented Large Language Models” under review
This work builds together two popular blocks of neural architecture, namely convolutional layers and Transformers, for large language models (LLMs). In this paper, by combining local and global dependencies over latent representations using causal convolutional filters and Transformers, we achieve significant gains in performance. This work showcases a robust speech architecture that can be integrated and adapted in a causal setup beyond speech applications for large-scale language modeling. With less than 1% of the parameters, we gain the addition of the order of tens of extra decoder layers. (jump from 12-64 layer)
|
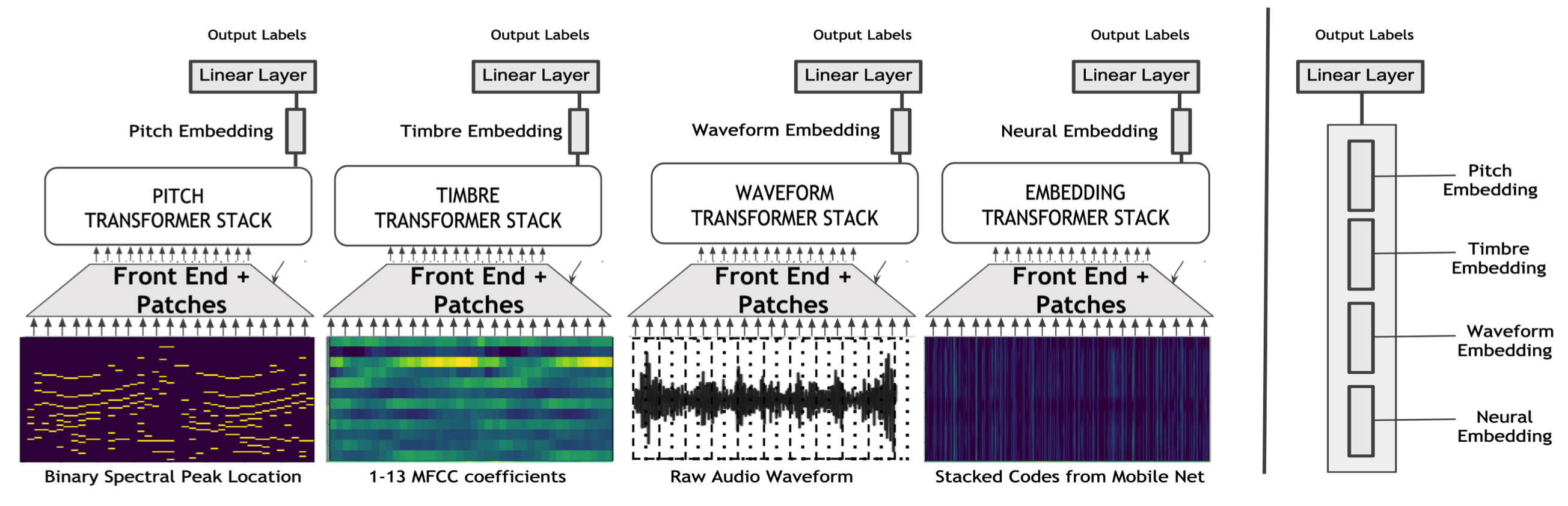 |
Prateek Verma, “Diverse Neural Audio Embeddings: Bringing Features Back” under review
Prior to deep learning era, decades of research was carried out on devising hand-crafted features. This was completely forgotten with the advent of deep learning. Can we have the best of both worlds in some fashion? For the case of audio understanding, we can surpass end-to-end architectures by learning separate architectures on the interpretable features of interest. By combining them after training, we find that we get a significant bump in performance, and the learned embeddings are robust and interpretable.
|
 |
Anjalie Field, Prateek Verma, Nay San, Jennifer L. Eberhardt, Dan Jurafsky, “Developing Speech Processing Pipelines for Police Accountability” InterSpeech 2023, Dublin, United Kingdom
Police body-worn cameras can potentially improve countability and transparency in policing. Yet, in practice, they result in millions of hours of never-reviewed footage. We investigate the potential of large pre-trained speech models for facilitating reviews, focusing on ASR and officer speech detection in footage from traffic stops. Our proposed pipeline includes training data alignment and filtering, fine-tuning with resource constraints, and combining officer speech detection with ASR for a fully automated approach. Our work offers practical applications for reviewing body camera footage and general guidance for adapting pre-trained speech models to noisy multi-speaker domains.
|
 |
Prateek Verma and Chris Chafe, Adaptive Front-End For Audio Signal Processing” IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2023, Rhodes, Greece
Imagine being a penguin in Antarctica. They are highly social creatures, yet for millions of years, evolution has resulted in their hearing systems being optimized for only five kinds of sounds: wind, fellow penguins, breaking ice, high-pitched birds, and water. Can we build optimal machine ears for only a few categories, similar to a mixture of experts? We design a novel front end that only allows the front end to be adapted according to the type of input signal. In another way, the machine ears adapt according to the contents of the input signal and switch to optimal ears every 25ms. We show rich basis functions that are learned.
|
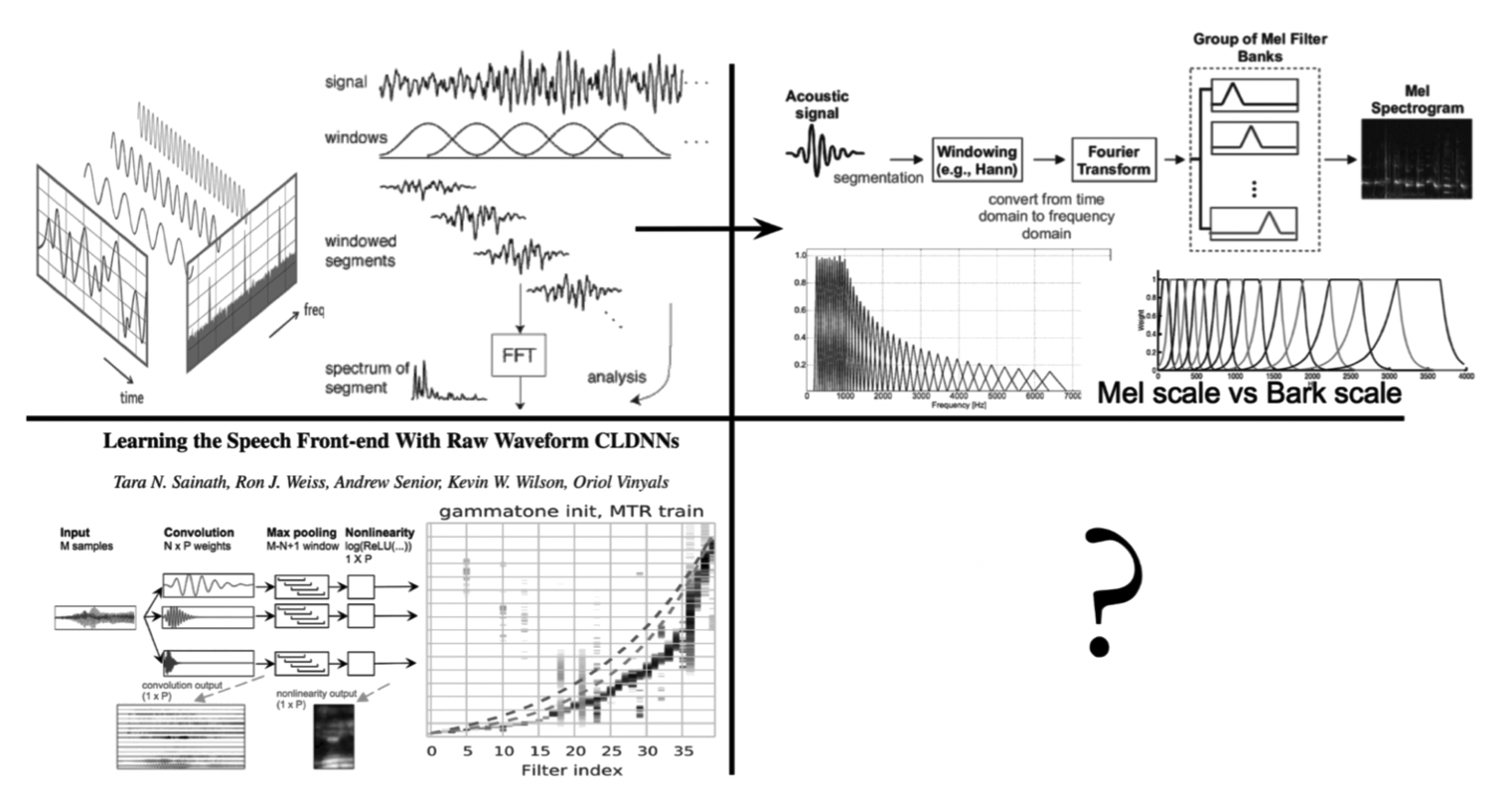 |
Prateek Verma, “Neural Architectures Learning Fourier Transforms, Signal Processing and Much More….” Technical Report, Stanford University, Aug 2023, Presented at NVIDIA Auditorium
One interpretation of the Fourier Transform is decomposing a signal into its constituent components by projecting them onto complex exponentials. Variants exist, such as discrete cosine transform that does not operate on the complex domain and projects an input signal to only cosine functions oscillating at different frequencies. However, the classical definition is suboptimal. The first one is that all kernels are sinusoidal. What if we could have some kernels adapted or learned according to the problem? What if we can use neural architectures for this? We show how to learn these kernels for audio signal processing applications from scratch. We find that the neural architecture not only learns sinusoidal kernel shapes but discovers all kinds of incredible signal-processing properties. E.g., windowing functions, onset detectors, high pass filters, low pass filters, modulations, etc. Further, we would also explore making the learned kernel’s content adaptive, i.e., learning different kernels for different inputs.
|
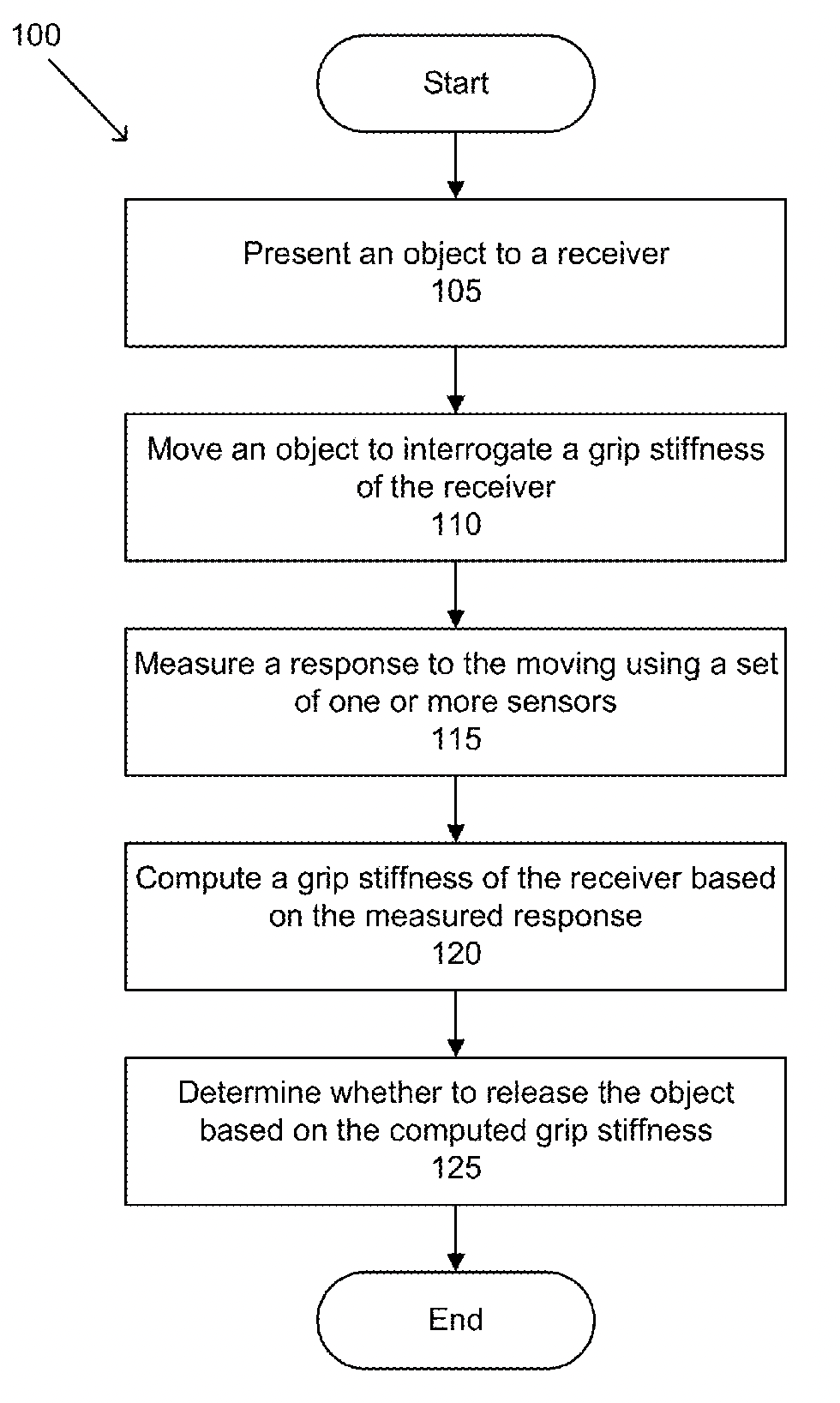 |
J. Kenneth Salisbury Jr., Prateek Verma, Elizabeth Bianchini, Etienne Chassaing, “Tactile Gesture Interpretation for Safe Human-Robot Handovers”, Office of Technology Licensing, Stanford University and United States Patent Application Publication 18/061,341 Filed by Stanford University.
Stanford researchers have developed a technique to interpret contact events between a human and a device equipped with a force sensor. It can detect and classify distinct touch interactions such as tap, touch, grab, and slip. Application of this technology is practical, for example, when a human and a robot transfer an object from one to the other (known as “handovers”). As with current practice, the developed technique enables more subtle, robust, and safe handovers without relying on crude threshold detection or reliance on external sensing. The technique can be applied in other contexts. For example, the developed technique could turn a screen with a force sensor into a fully interactive touchscreen display, with no requirement for the additional sensors typical of a touch screen.
|
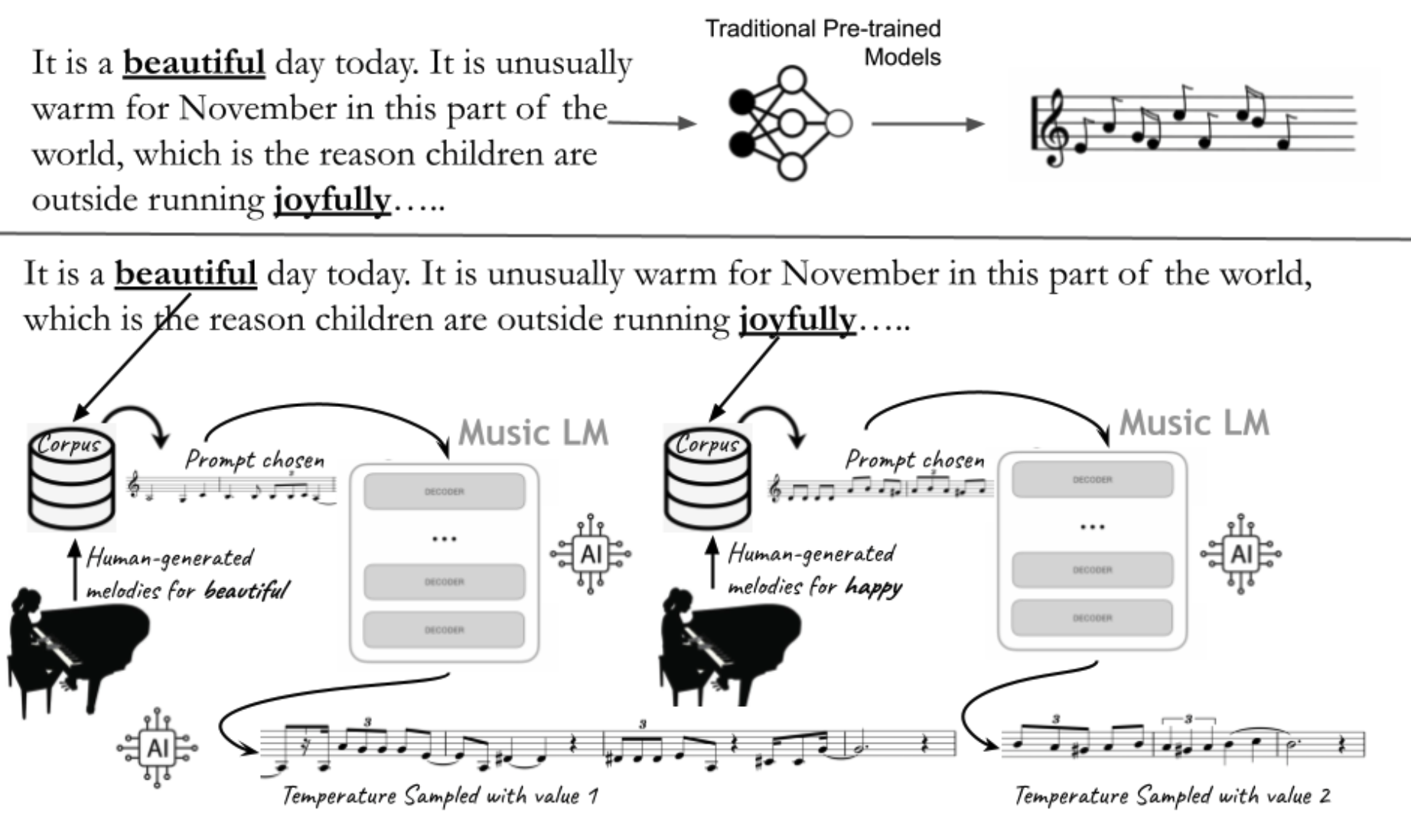 |
Constantin Basica, Prateek Verma, Patricia Alessandrini, and Alexandru Berceanu, “Accessible Co-Creativity with AI through Language and Voice Input”, The International Conference on AI and Musical Creativity, Sussex, UK. “Demo”
How can we use AI to make the creative process more inclusive and accessible? This project introduces tools for humans to co-create music with AI-based architectures. The aim is for human musicians or non-musicians to be able to augment their creative capabilities and guide neural architectures to understand language and musical nuances. This work is akin to learning a new instrument: the human learns how to co-create with the AI system for musical applications. One of the main goals of the project is accessibility. We want people with various abilities and disabilities to be empowered to explore music creation by interacting with machines and using language andor their voice. The proposed tools can be used for composition, improvisation, and/or performance. /
|
 |
Patricia Alessandrini, Constantin Basica,Prateek Verma “Creating an interactive and accessible remote performance system with the Piano Machine”, 16th Computer Music Multidisciplinary Research, Tokyo, Japan.
This demo shows a work-in-progress development of an intelligent interactive system for the Piano Machine. This physical computing system causes the strings of the piano to sound through mechanical excitation. While the first version of the Piano Machine, developed in 2017 by Patricia Alessandrini and Konstantin Leonenko, employed a simple midi-keyboard control using Aftertouch for continuous control, the Piano Machine was further developed in 2019-2020 with Machine Learning to allow for higher-level control, allowing the Piano Machine to respond interactively to inputs such as live sound and gesture. The current development will integrate the Piano Machine into AI-driven co-creative systems, such that performersimprovisers can use a variety of inputs in person or remotely./
|
2022
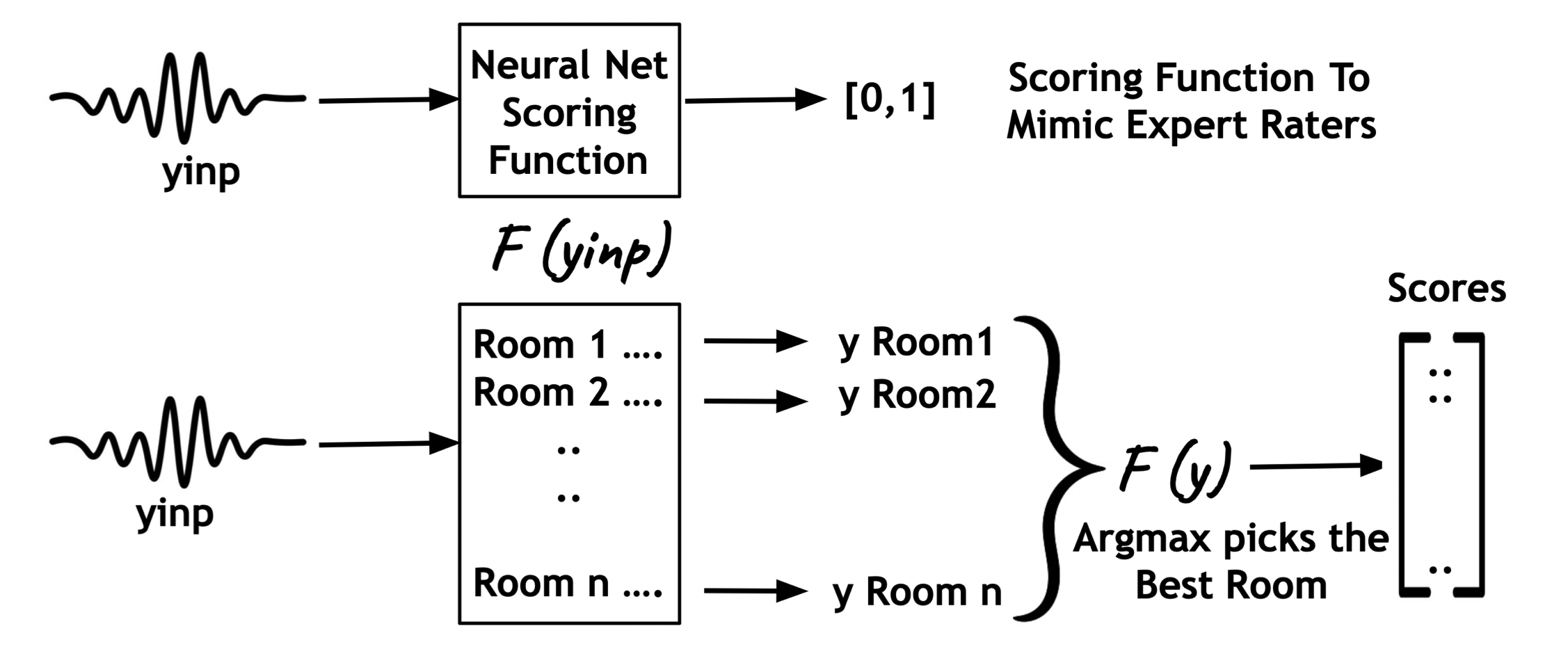 |
Prateek Verma and Jonathan Berger, “Enhancing Audio Perception of Music By AI Picked Room Acoustics”, 24th International Congress on Acoustics, Gyeongju, Korea, ICA 2022
Inspired by how room acoustics turns bad singing into a “good bathroom singer.” A neural network is used to score the outputs of simulated room impulse responses to find that room acoustics alone are sufficient to improve the perceptual qualities of music. We show how the optimal chosen acoustics turn bad-quality sounds into good sounds. Quite a generic idea that can be extrapolated to various problems.
|
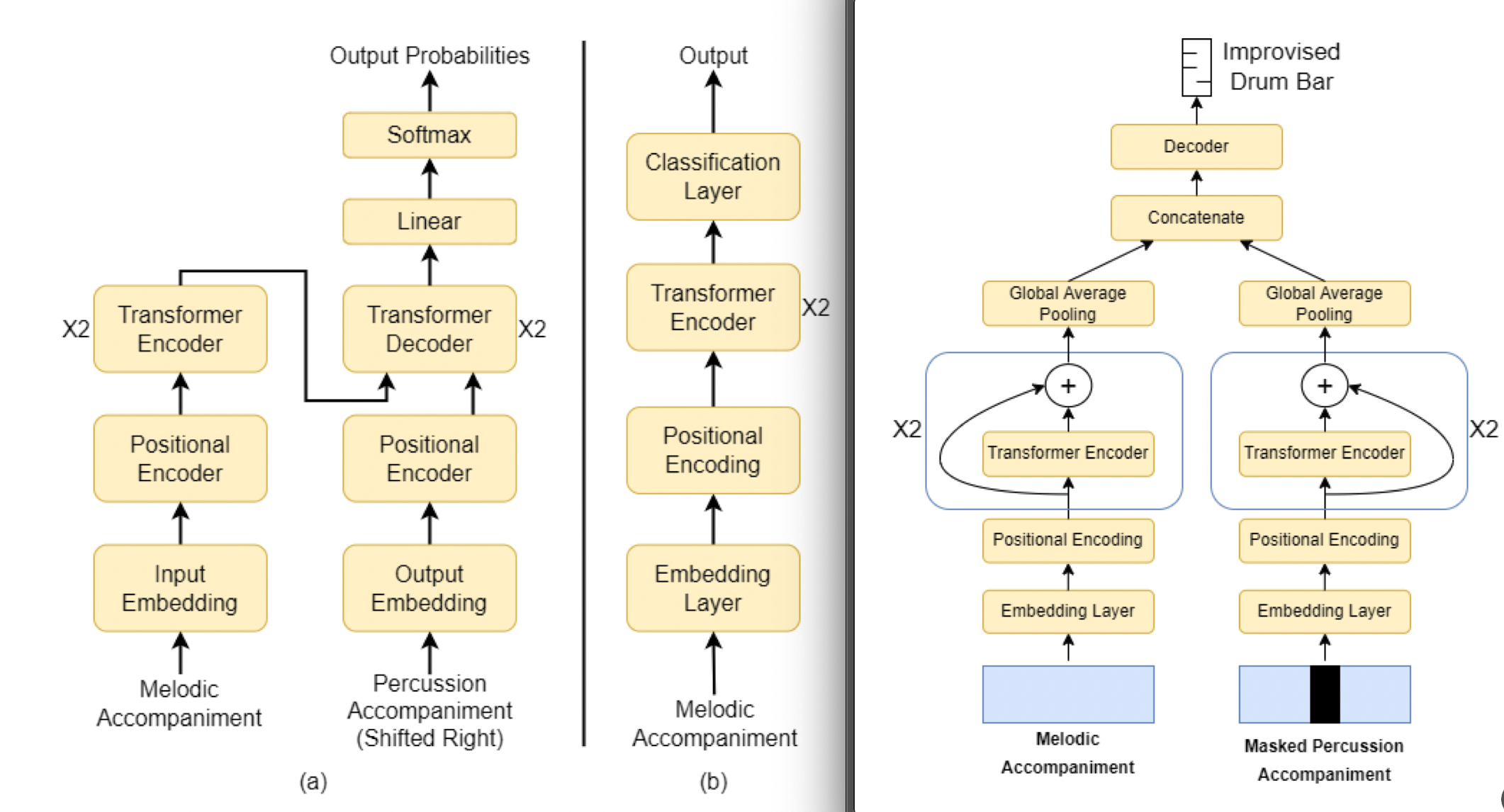 |
Rishabh Dahale, Vaibhav Talwadker, Preeti Rao, Prateek Verma, “Generating Coherent Drum Accompaniment With Fills And Improvisations”, 23rd International Society for Music Information Retrieval Conference (ISMIR 2022), Bengaluru, India
Training LLMs on Drums, we find a peculiar phenomenon – Increasing model size does not incorporate improvisations due to the highly repetitive data structure, having implicit data imbalances. We present a framework for the model to figure out when and how to improvise. This idea merges popular seq-to-seq models with BERT style in-filling.
|
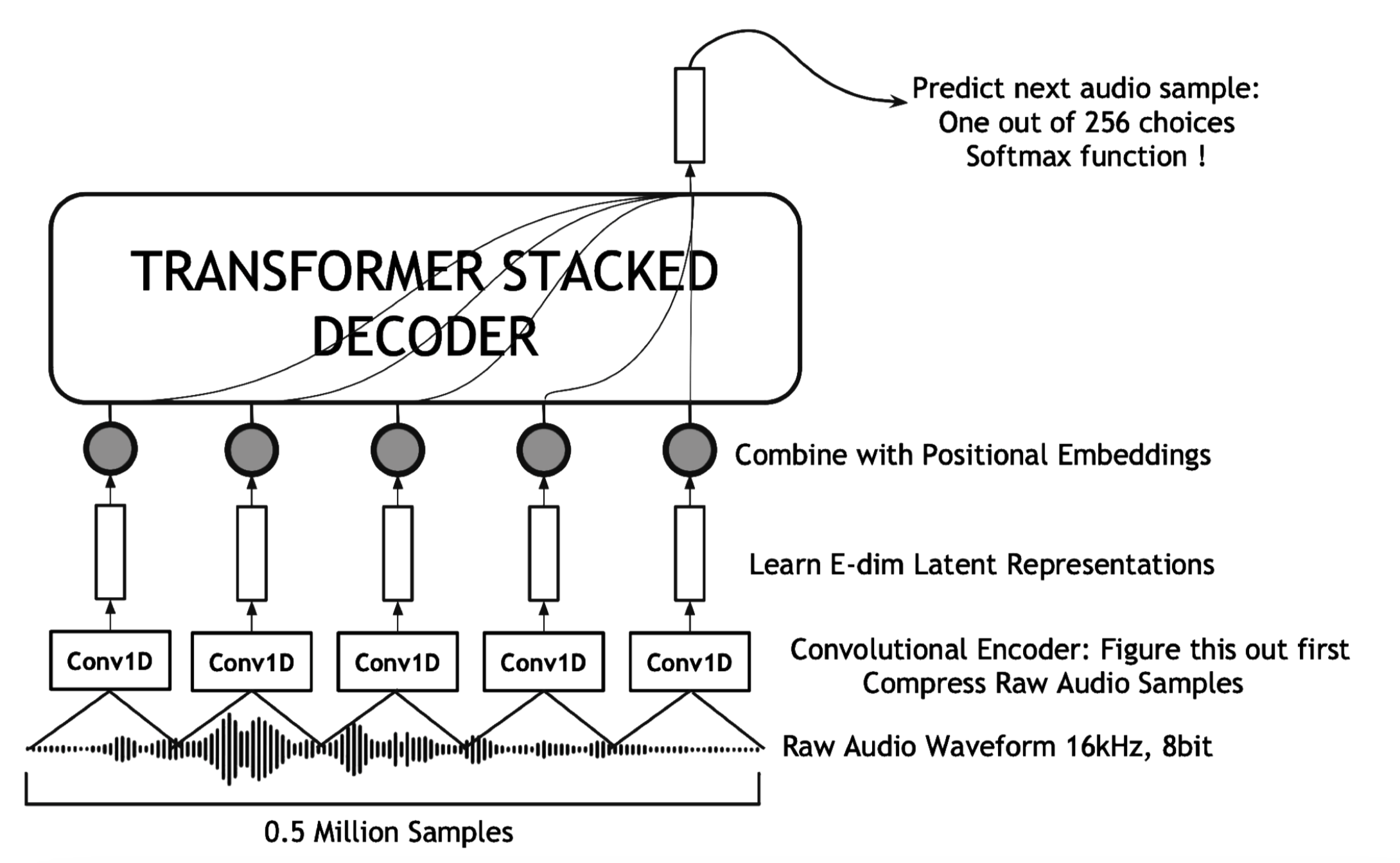 |
Prateek Verma, “A Language Model for Raw Audio with Context of 1/2 Million Samples”, arXiv
In academic settings, with industry throwing massive computing power into making generative models bigger and bigger, I explored how we can improve the perplexity of a model by chasing context length instead. On a standard benchmark of raw audio, we surpassed other state space models coming out of Chris Re’s group, along with Wavenet and other transformer-based models. We are also excited to have shown significant improvements with a minuscule number of parameters. Further competing on modeling long context (greater than 500k samples) is an interesting research direction instead of chasing model size and parameters, and we expect this work to be a stepping stone in that direction. Meta adapted this work after a year without citing.
|
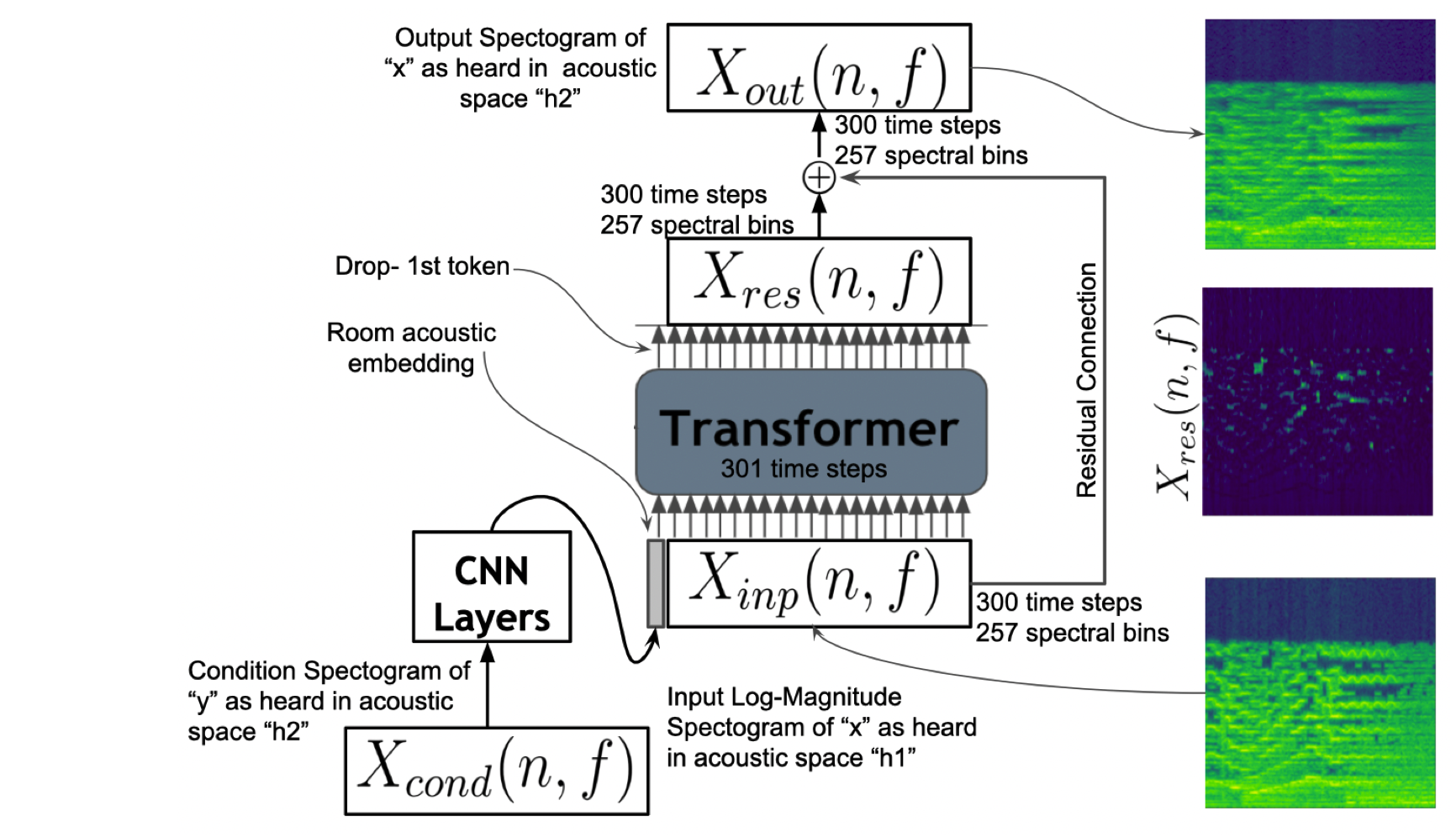 |
Prateek Verma, Chris Chafe, Jonathan Berger, “One shot acoustic transfer: Learning to hear music in any concert hall/room”, arxiv 2210.15750
Given any sound, our work allows us to learn the acoustic properties of that sound w.r.t the environment played in and transforms any signal to that space as if it was played in that space. We propose conditional Transformers that can map signals to another of interest by conditioning on a third signal. We show, through listening experiments and empirical formulations, the validity of our method. We can now hear our favorite music in fancy concert halls in Europe or even a lecture hall during inference.
|
2021
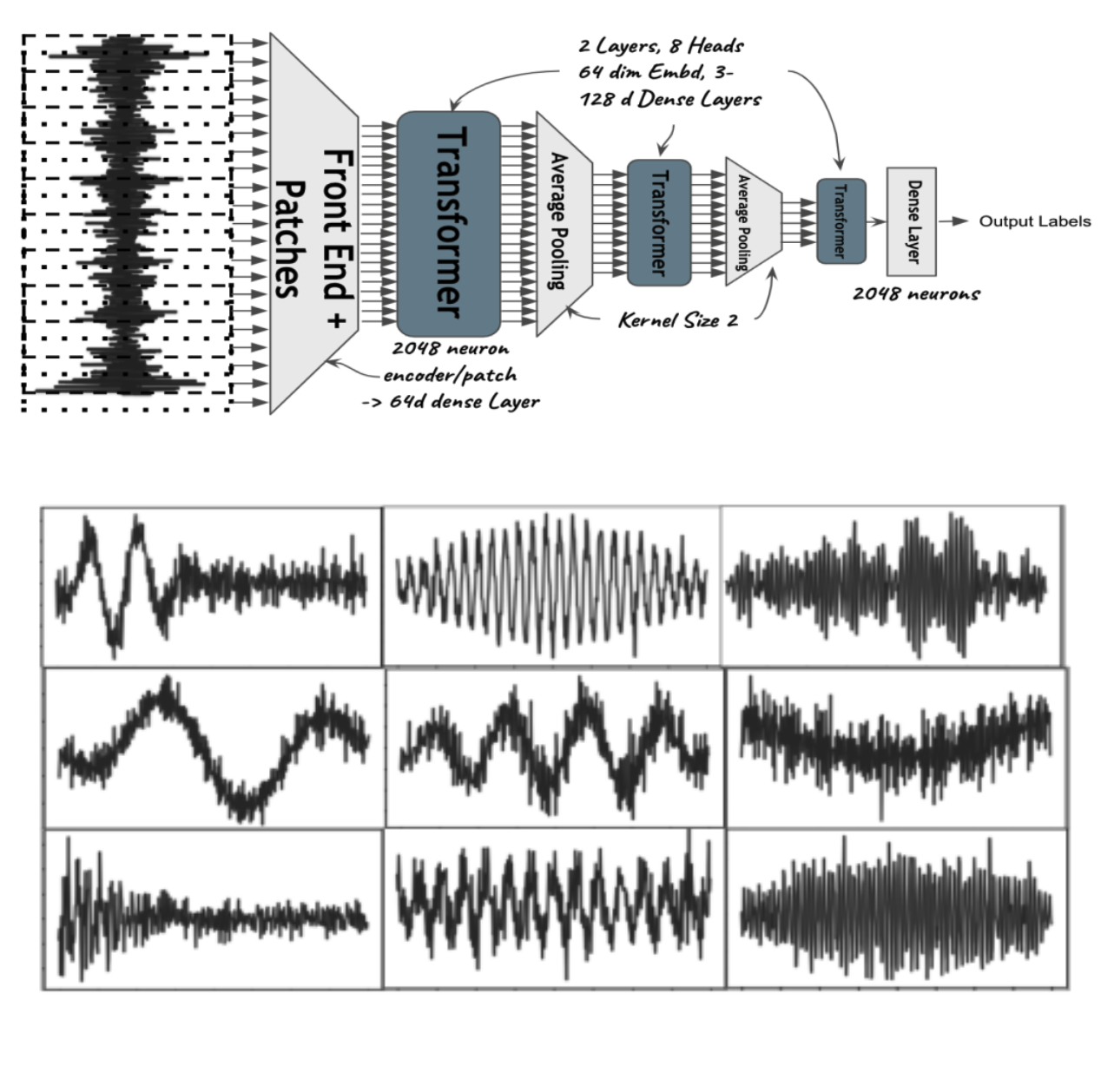 |
Prateek Verma and Jonathan Berger, “Audio Transformers: Transformer Architectures For Large Scale Audio Understanding. Adieu Convolutions.", Featured on CS 25 Transformers United Seminar, 47 citations, arxiv.org/abs/2105.00335
The very first Transformer model for audio understanding directly operating on raw waveforms. By learning a structure on intermediate embeddings inspired by classic signal processing ideas like wavelet, we find that adding no extra parameter can increase the absolute accuracy by 5%. This is, again, a generic idea that can help us with any Transformer model. We discover that the model surpasses the state-of-the-art models without convolutional filters in our architecture. Further, we see beautiful traditional signal-processing properties emerging!
|
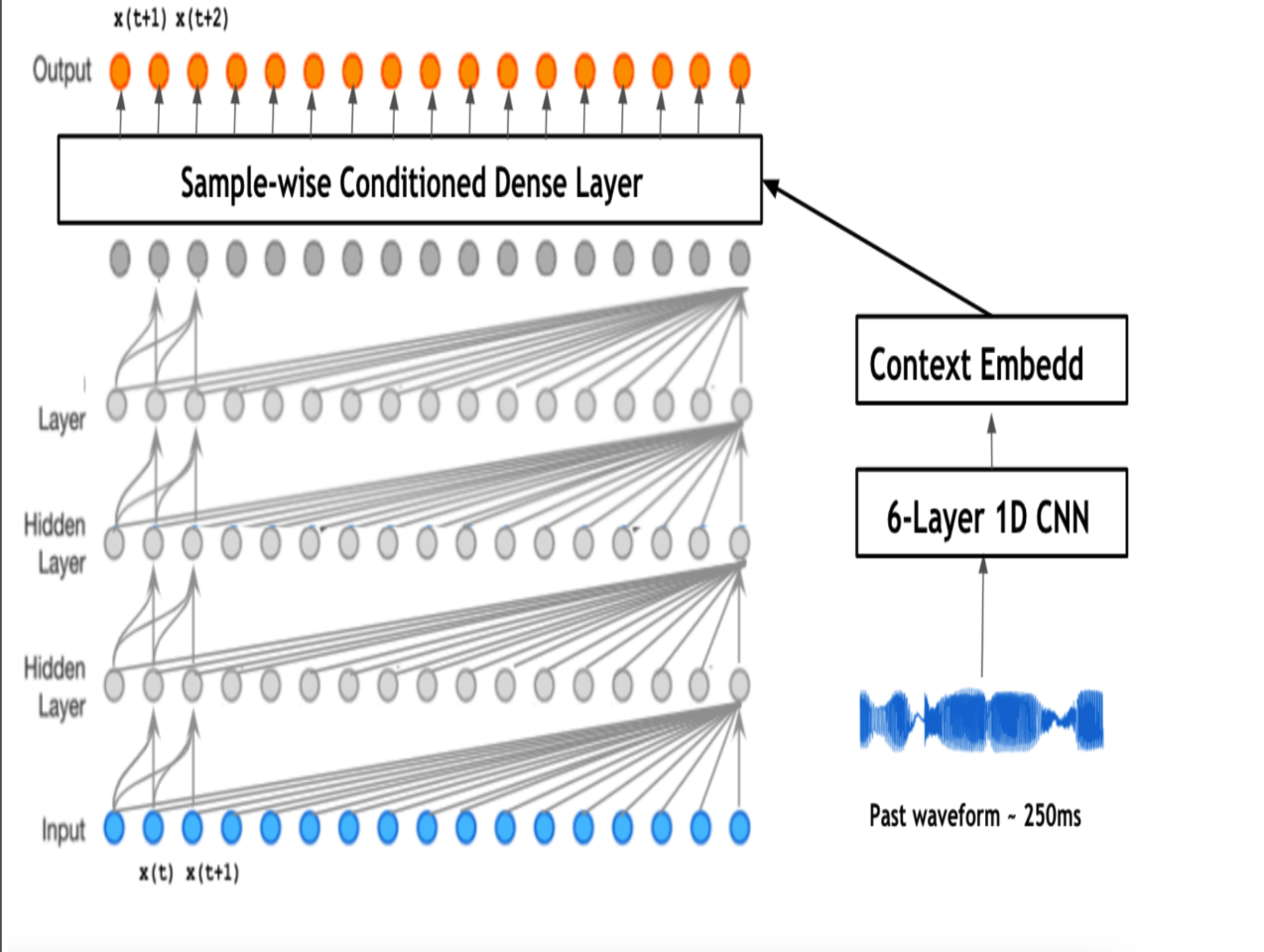 |
Prateek Verma and Chris Chafe, “A Generative Model For Raw Audio Using Transformer Architectures”, Proceedings of 43rd International Conference on Digital Audio Effects(DAFx20in2021), Vienna, Austria, 2021.
We explored how a transformer-based Large Language Model can surpass wavenet, a state-of-the-art paper for generative modeling for raw waveform, keeping the same number of parameters, training corpus, and context length. In order to surpass the quadratic constraint of the model, we condition the context itself utilizing the quasi-stationary property of raw signals, showing further improvement in long-context modeling.
|
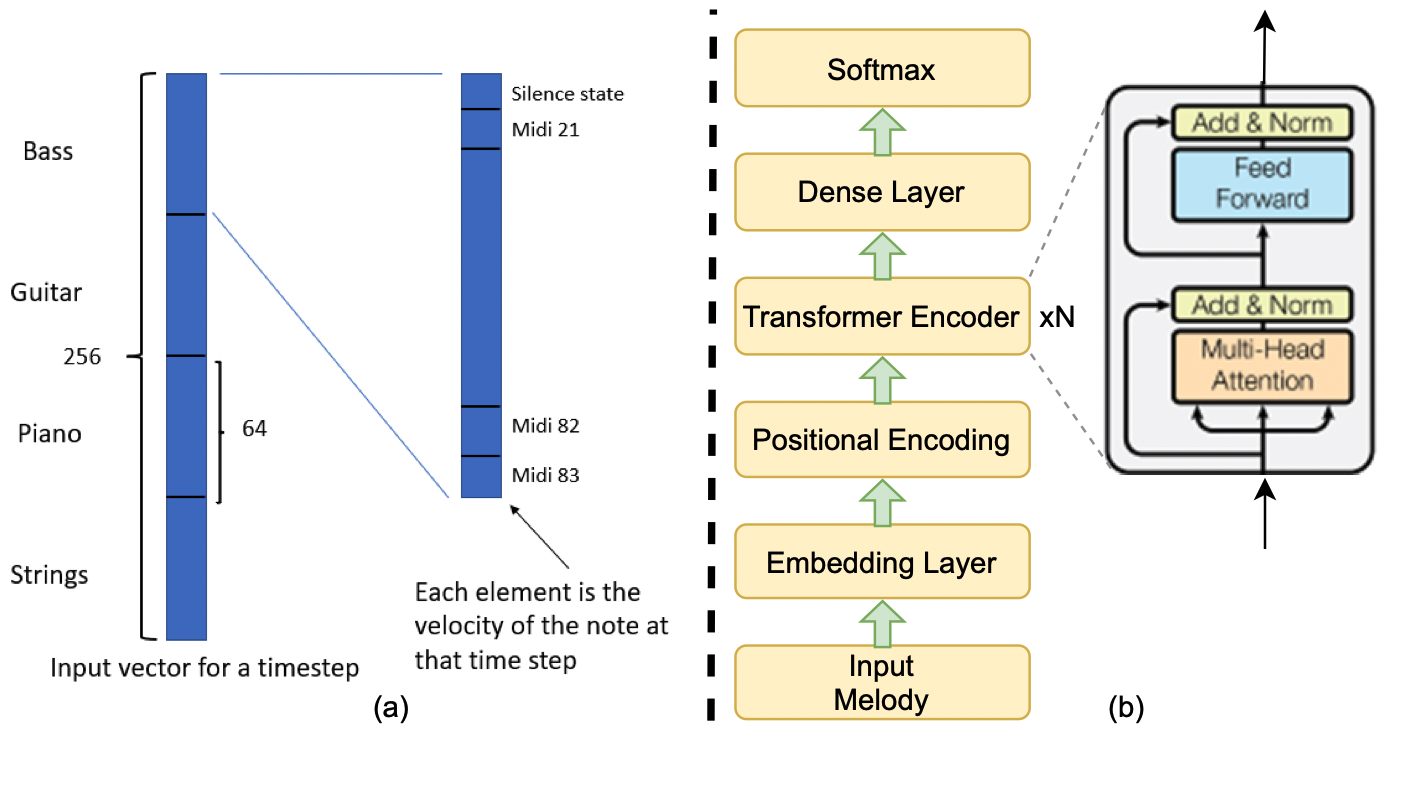 |
Rishabh Dahale, Vaibhav Talwadker, Prateek Verma, Preeti Rao “Neural Drum Accompaniment Generation”, Late Breaking Demo, 22nd International Society for Music Information Retrieval Conference (ISMIR 2021), Virtual.
We explored how to create a background accompaniment of playing drums given a melody input. Additionally, our work explored that instead of treating drum generation as a sequential task, we can learn which notes/events occur given a melody line (sequential input) parallelly.
|
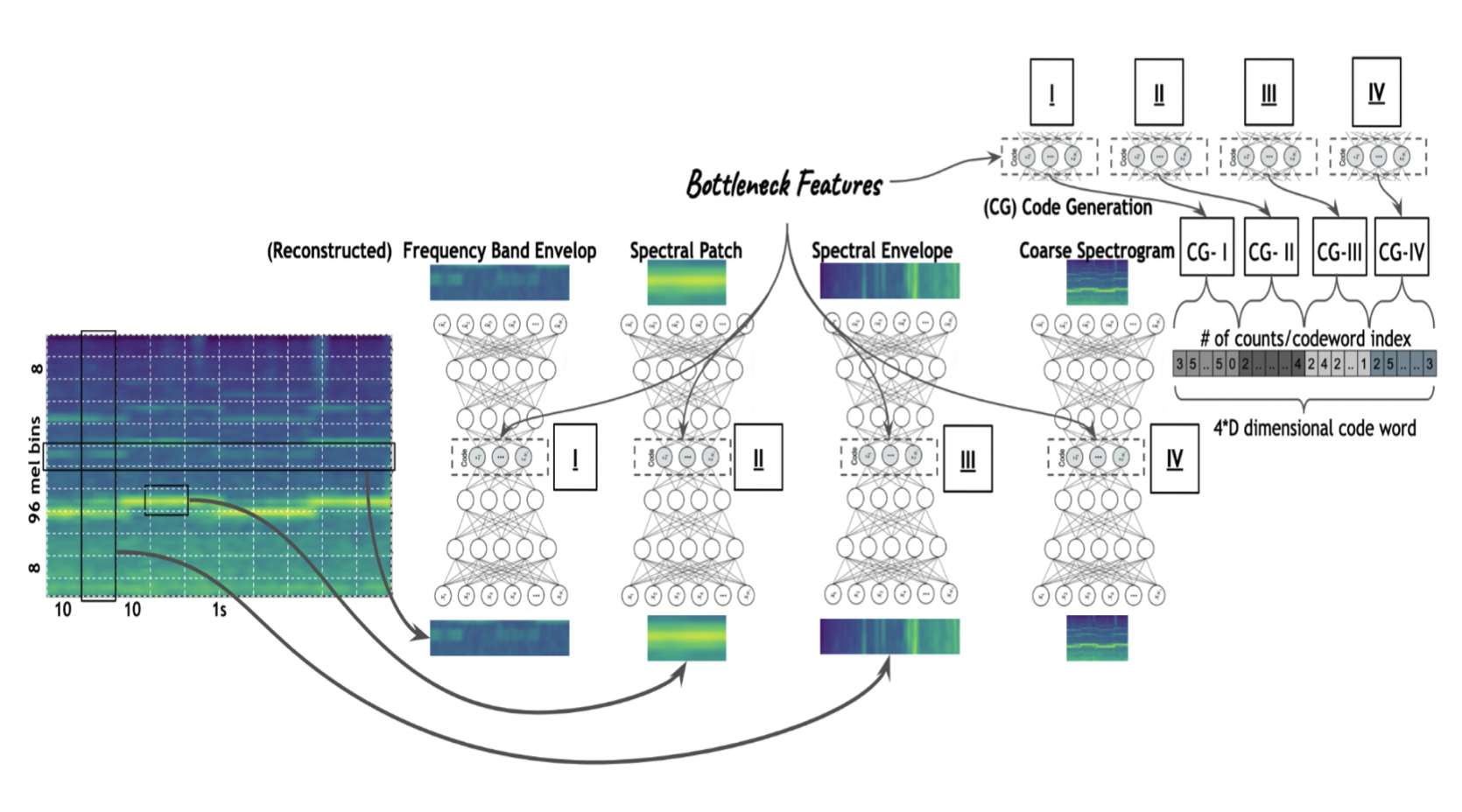 |
Prateek Verma, "Large Scale Audio Understanding without Transformers/ Convolutions/ BERTs/ Mixers/
Attention/ RNNs or ….”, arxiv preprint
What if one could go back in time and we had all of the computing resources but did not have any of the advancements like Transformers, Convolution, Attention, and so on :) If we are only given the classic Science paper by Hinton in 06, neural networks can compress the feature of interest better than PCA via bottleneck autoencoders. We explored this for a classification task via simply clustering over latent representations and counting the different types of tokens. We find that we outperform resnet, densenets, and lstm+cnn models that were state of the art till 2019 and come strikingly close to outperforming Transformers with the same number of trainable parameters :)
|
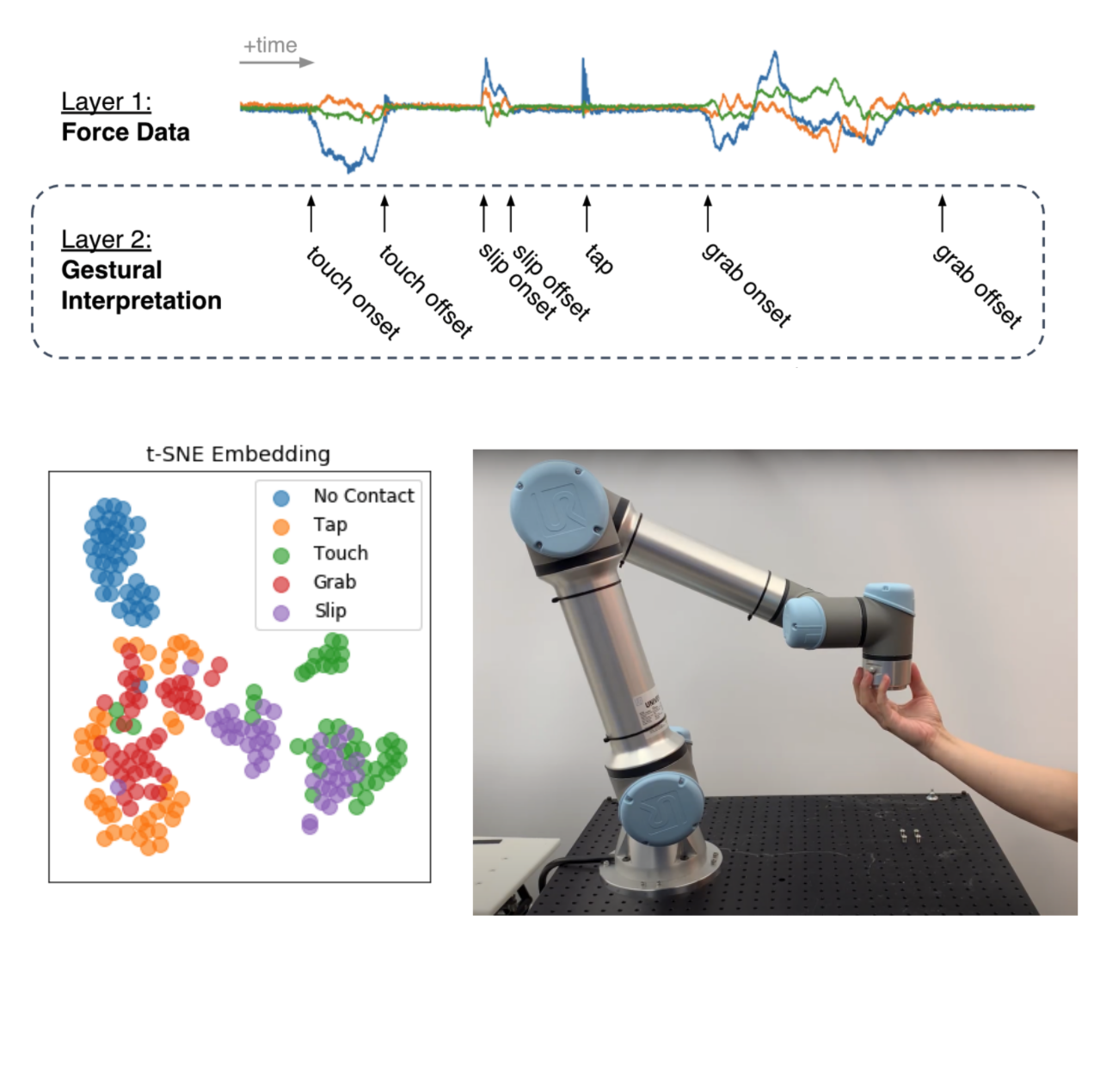 |
Elizabeth Bianchini, Ken Salisbury, Prateek Verma, “Human Tactile Gesture Interpretation For Robotic Systems” IEEE International Conference on Intelligent Robots and Systems, IROS, 2021, Prague, Czech Republic
Physical human-robot interactions (pHRI) are less efficient and communicative than human-human interactions, and a key reason is a lack of informative sense of touch in robotic systems. Interpreting human touch gestures is a nuanced, challenging task with extreme gaps between human and robot capability. We explored classic signal processing ideas to achieve this task and lightweight, simple neural architectures to understand 1-D signals.
|
2020
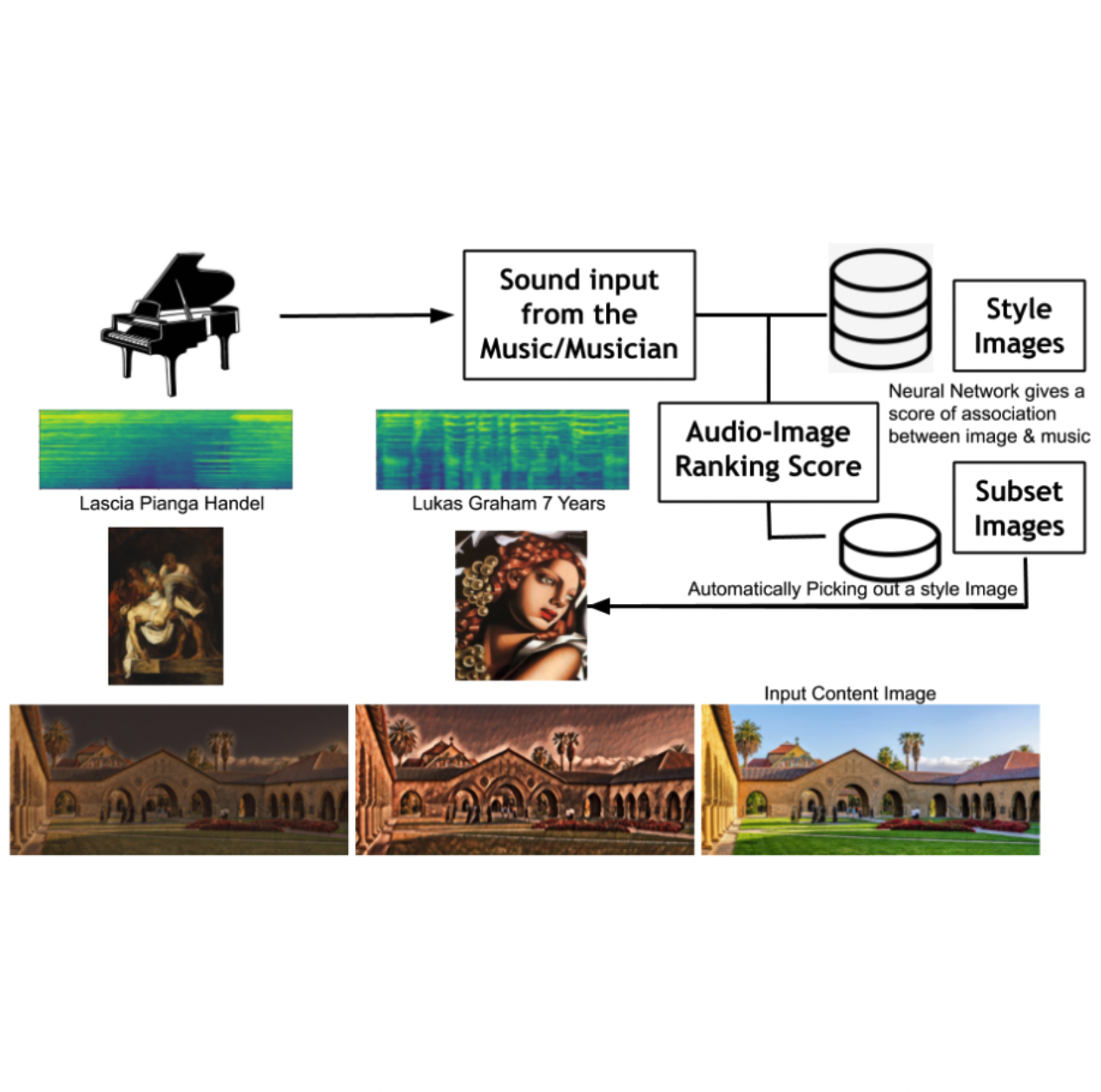 |
Prateek Verma, Ingrid Olden, Constantin Basica, Pam Keivelson, “Painting from Music using Neural Visual Style Transfer”, 34th Neural Information Processing Systems, workshop on Machine Learning for Creativity and Design
What if a musician can sketch a painting by playing music? This work enables artists to surpass their skill set to augment their creativity via AI. We first learn a common latent space by learning the scoring function determining the distance between music and paintings. Given a library of textures and images, we first play any piece on a musical instrument and the corresponding texture that matches best with the played music via the learned scoring function. This is then used for real-time style transfer on any input image given.
|
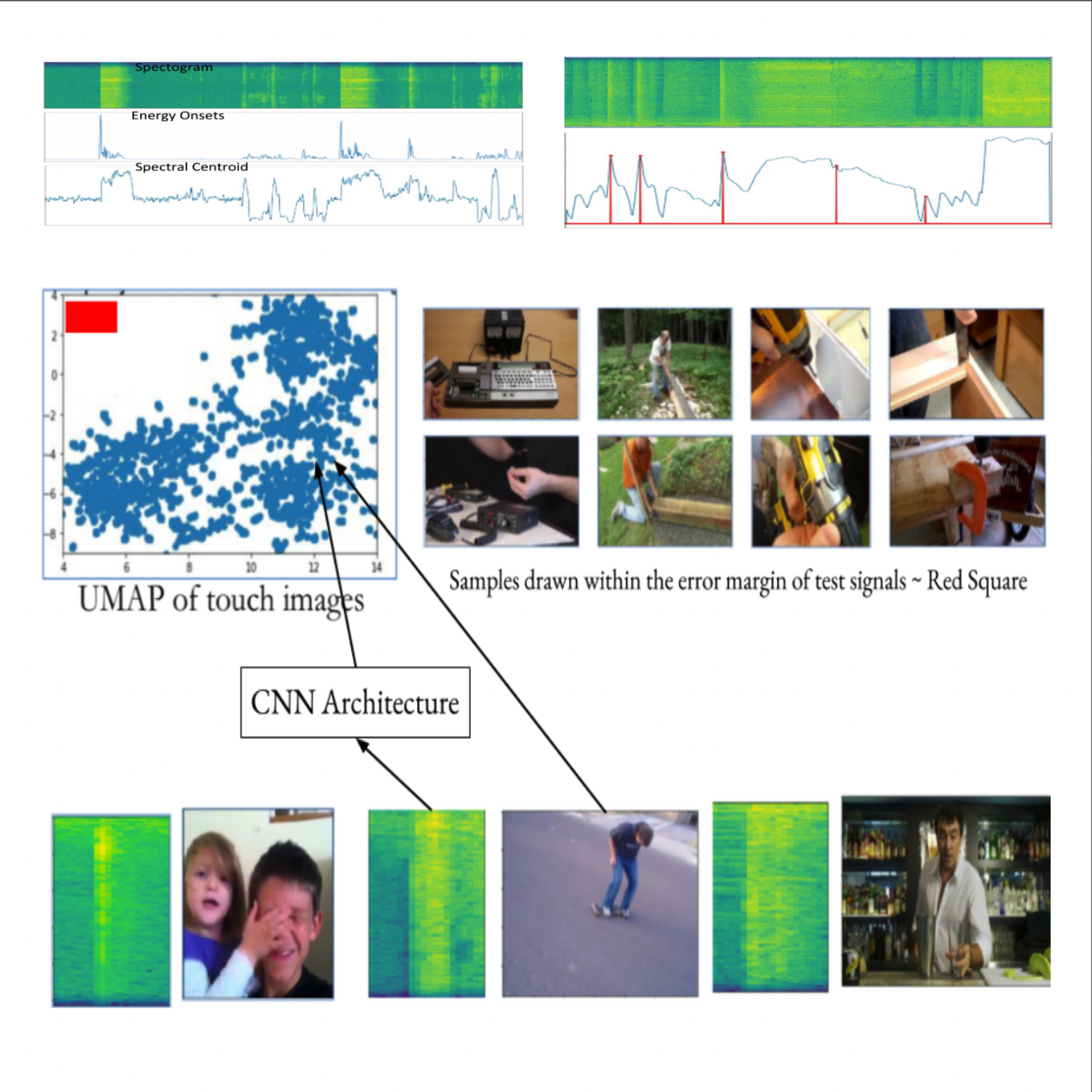 |
Prateek Verma and Kenneth Salisbury “Unsupervised Learning of Audio Perception of Touch Sounds: Learning to Map to UMAP Space”, MIT-CSAIL, Stanford, Toyota Research Institute Annual Showcase Presentation, Stanford University, Feb 2020
Enabling robotic arm to aid in perception and probing using sounds. Given a scene with objects like an opaque water bottle filled with liquid. From vision alone, we cannot gauge whether it is filled or not, yet we can find that via sound. How can we understand impact sounds at scale by watching YouTube videos to develop super-human capabilities to develop perception of touch sounds? This paper builds upon key ideas to build the perception of touch sounds without access to ground-truth data. We show how we can leverage ideas from classical signal processing to get large amounts of data of any sound of interest with high precision. The model trained to map sounds to this clustered representation gives reasonable performance as opposed to expensive methods collecting a lot of human-annotated data. Such approaches can be used to build a state-of-the-art perceptual model for any sound of interest described using a few signal processing features. Using signal processing combined with neural architectures and high dimensional clustering of unlabelled data by daisy chaining high-precision sound event detectors is a vastly powerful idea. She can be explored in a variety of ways in the future.
|
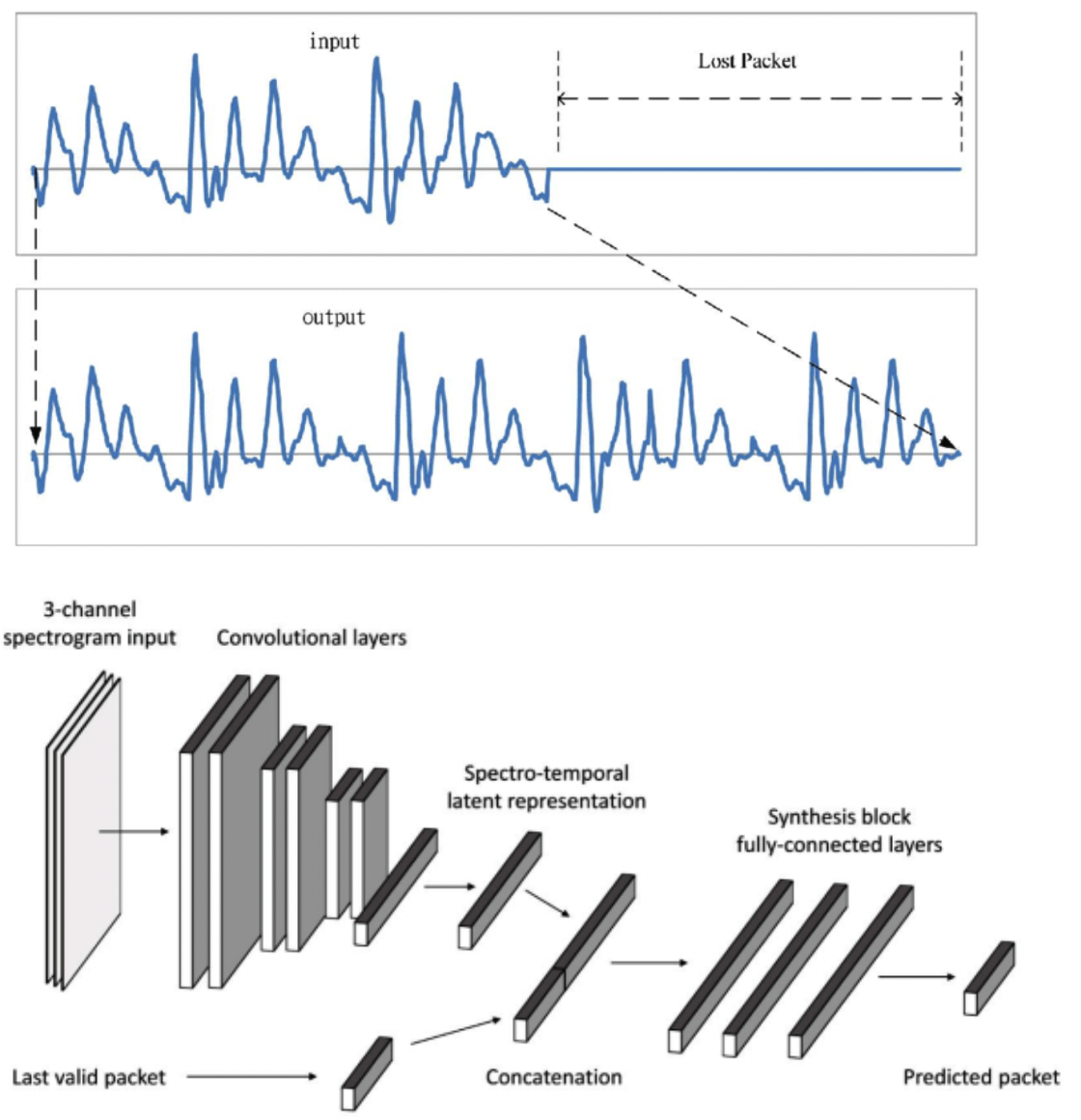 |
Prateek Verma, Alessandro Ilic Mezza, Chris Chafe, Cristina Rottondi,“A Deep Learning Approach for Low-Latency Packet Loss Concealment of Audio Signals in Networked Music Performance Applications” 27th Conference on Finnish-Russian University Cooperation in Telecommunications (FRUCT)
Networked Music Performance (NMP) is envisioned as a potential game-changer among Internet applications: it aims at revolutionizing the traditional concept of musical interaction by enabling remote musicians to interact and perform together through a telecommunication network. Ensuring realistic conditions for music performance, however, constitutes a significant engineering challenge due to extremely strict requirements in terms of audio quality and, most importantly, network delay. This article describes a technique for predicting lost packet content in real-time using a deep learning approach. The ability to conceal errors in real-time can help mitigate audio impairments caused by packet losses, thus improving the quality of audio playouts in real-world scenarios.
|
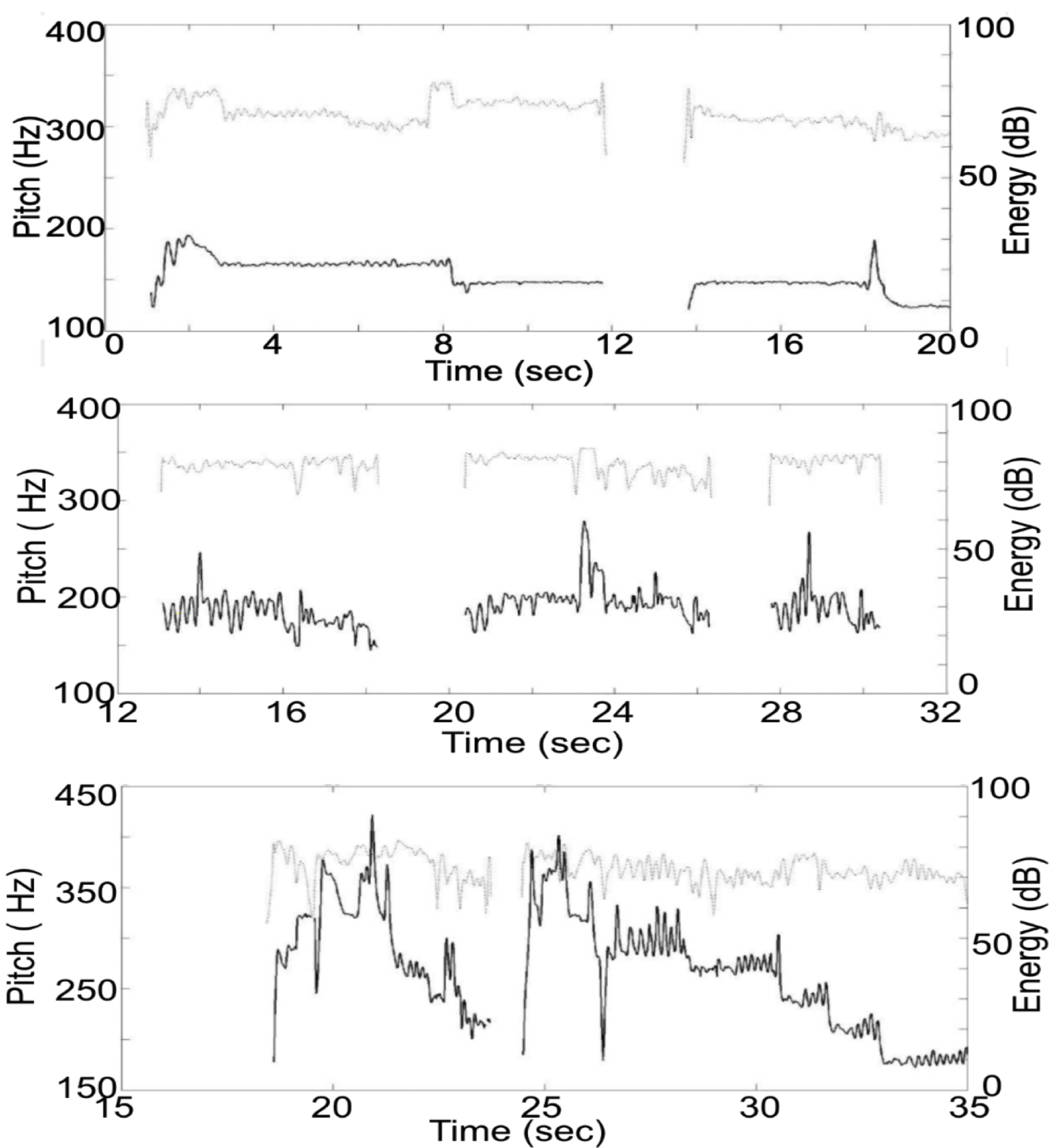 |
Amruta Vidwans, Prateek Verma and Preeti Rao, “Classifying Cultural Music Using Melodic Features” 15th International Conference on Signal Processing and Communication (SPCOM 2020), IISc Bangalore, India
A classic signal processing paper. We present a melody-based classification of musical styles by exploiting pitch and energy-based characteristics on the audio signal. Three prominent musical styles were chosen, with improvisation as an integral part with similar melodic principles, themes, and structure of concerts, namely, Hindustani, Carnatic, and Turkish music. Our automatic method is based on finding a set of highly discriminatory features, motivated by musicological knowledge, to capture distinct characteristics of the melodic contour. The nature of transitions in the pitch contour, the presence of microtonal notes, and the dynamic variations in the vocal energy are exploited.
|
2019
 |
Prateek Verma & Jonathan Berger, “Neural Content-Based Collaborative Filtering” 20th International Society for Music Information Retrieval, Late Breaking Demo, Delft, The Netherlands, 2019
In this paper, we propose to combine these two approaches. The paper's main contribution is an algorithm that proposes a content-based collaborative filtering approach in which the user-item matrix is replaced by a user-filter matrix based on activations of a deep neural network. This allows us to build recommendation engines based on collaborative filtering purely based on a perception system
|
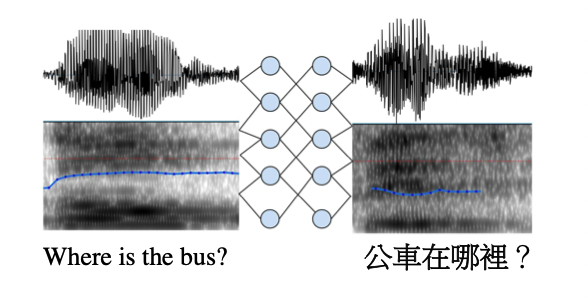 |
Albert Haque, Michelle Guo, Prateek Verma, “End-to-End Spoken Language Translation”, Technical Report, Department of Computer Science, Stanford University, 2017, Published in 2019
(Done 2 years prior to 19 person Google Brain and Google Research team citing and scaling it)
First fully differentiable pipeline for mapping spectrogram to spectrogram with application to speech-to-speech translation. With conditioning to the speaker, we enabled the translation of Chinese to English speech and vice-versa while retaining the speaker's voice. Google cited our paper, replicated the same architecture, threw in massive amounts of data, and scaled it to a much bigger model, achieving the same!
|
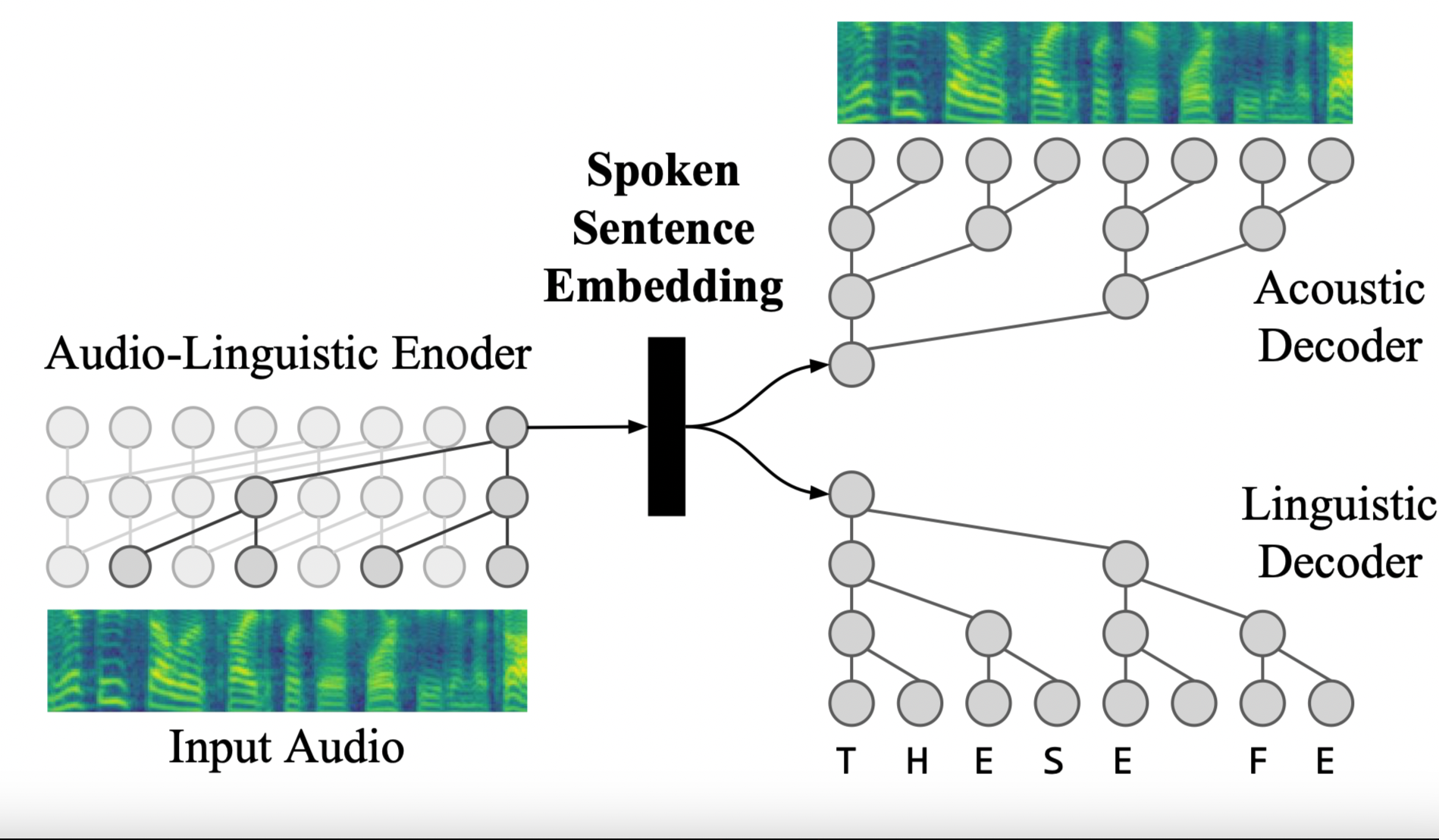 |
Albert Haque, Michelle Guo, Prateek Verma, Li-Fei Fei, “Spoken Sentence Embeddings”, ICASSP 2019, Brighton, UK.
We propose spoken sentence embeddings that capture acoustic and linguistic content. While existing works operate at the character, phoneme, or word level, our method learns long-term dependencies by modeling speech at the sentence level. Formulated as an audio-linguistic multitask learning problem, our encoder-decoder model simultaneously re-constructs acoustic and natural language features from audio. Our results show that spoken sentence embeddings outperform phoneme and word-level baselines on speech and emotion recognition tasks.
|
2018
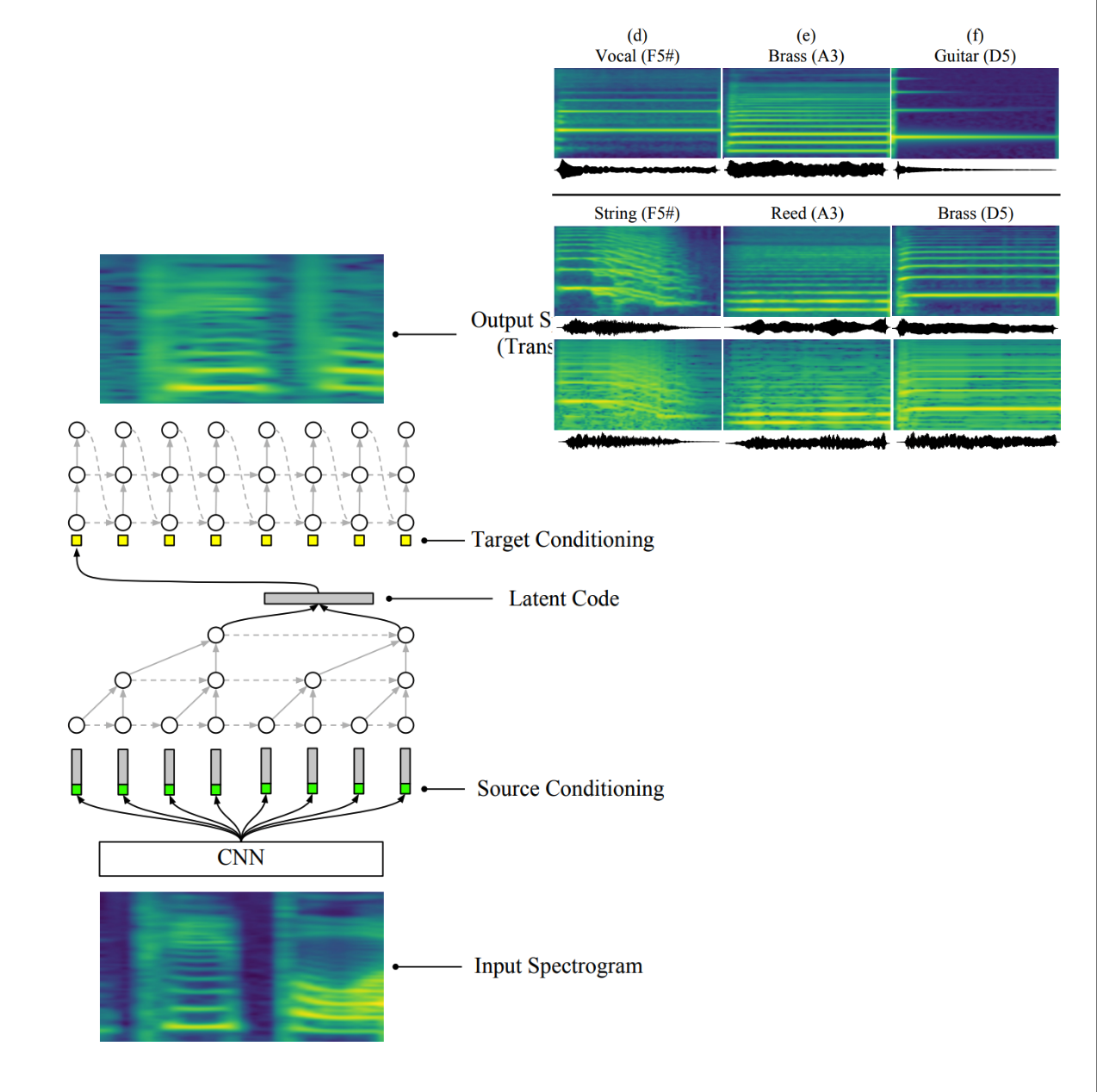 |
Albert Haque, Michelle Guo, Prateek Verma, “Conditional End-to-End Audio Transforms”, 19th InterSpeech, 2018, Hyderabad, India.
Quite a strong idea adopted widely across the industry, including Google’s first speech-to-speech translation work. We present a framework for autoregressive mapping of audio signals to other audio signals conditioned on desired input signals. We present an end-to-end method for transforming audio from one style to another. For the case of speech, by conditioning on speaker identities, we can train a single model to transform words spoken by multiple people into multiple target voices. In the case of music, we can specify musical instruments and achieve the same result. Architecturally, our method is a fully-differentiable sequence-to-sequence model based on convolutional and hierarchical recurrent neural networks. It is designed to capture long-term acoustic dependencies, requires minimal post-processing, and produces realistic audio transforms.
|
2017
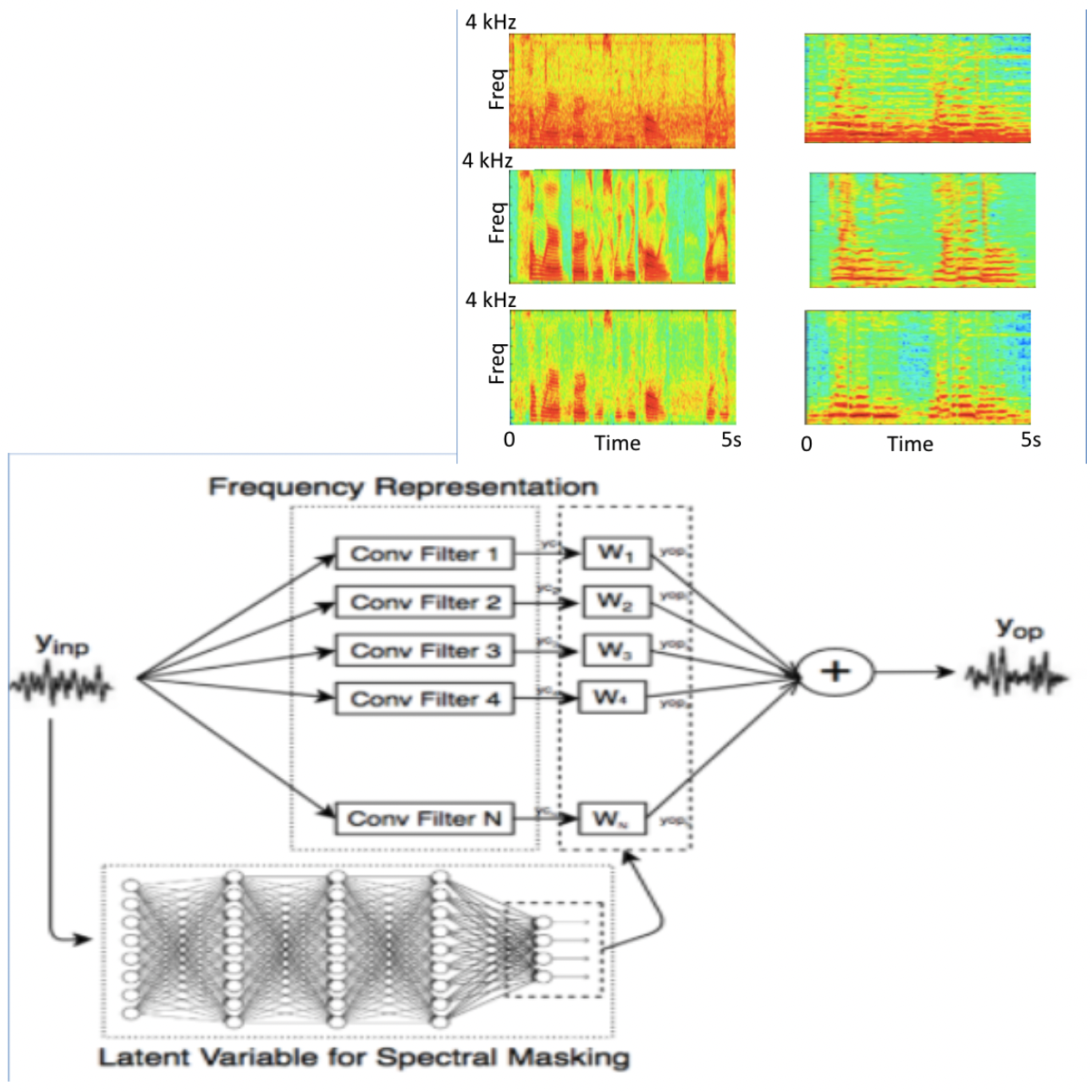 |
Prateek Verma & Dan Jurafsky, “Best of Both Worlds: Combining Signal Processing with Deep Learning for Speech Enhancement” Stanford Computer Science Annual Research Showcase Session, Stanford, CA, 2017
A lightweight deep learning algorithm that mimics a signal processing pipeline to separate a mixture of two sounds or 1-d signals. A conv layer can approximate taking a short time Fourier transform. In order to separate sounds, we typically mask a time-frequency representation like a spectrogram. We take the output of the first layer of the conv filter and, given the same input as that of the conv layers, learn which conv filters to turn off, mimicking a mixture of expert-style approaches. We present the results for music and speech.
|
2016
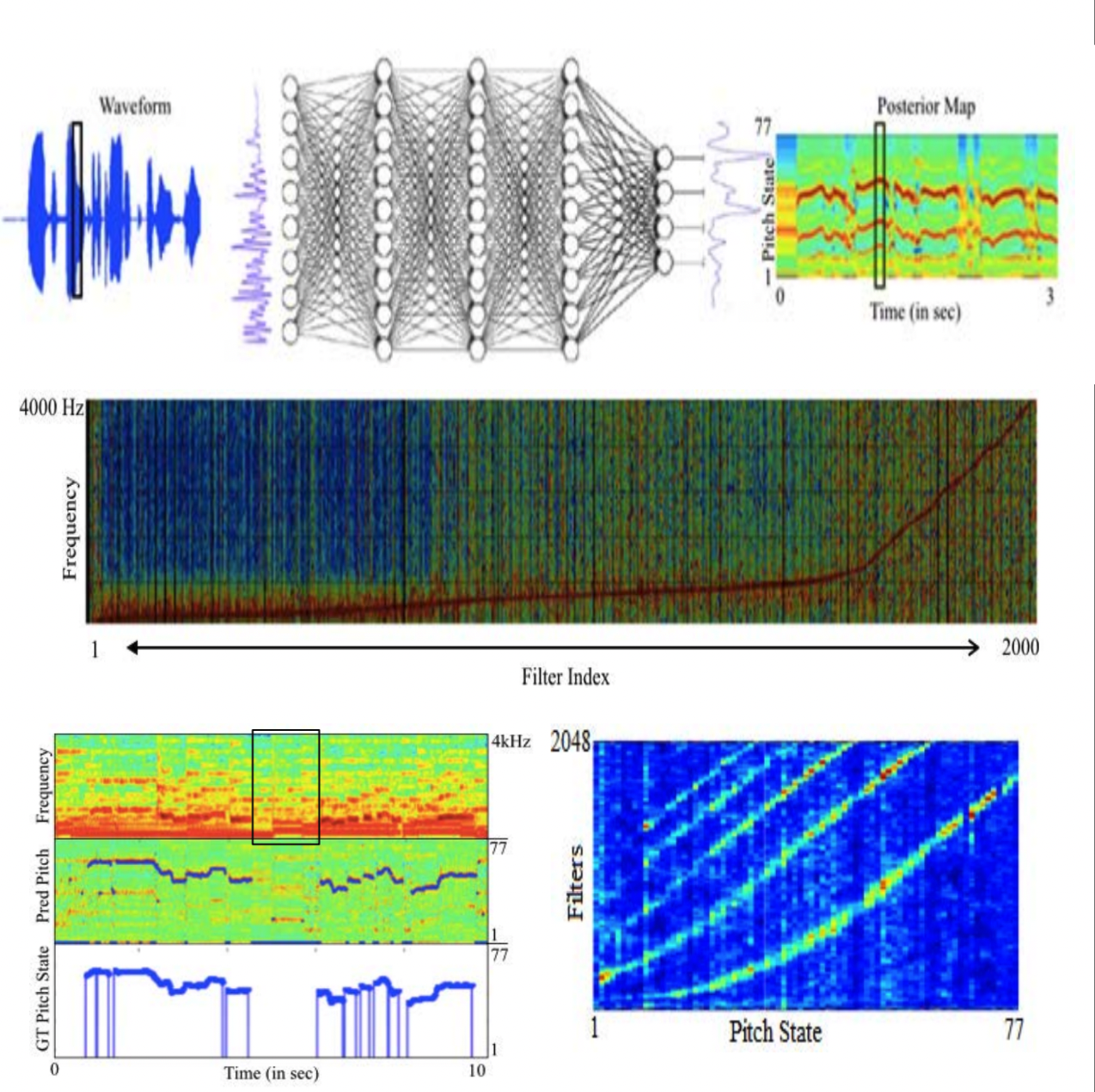 |
Prateek Verma & Ron Schafer, “Estimating fundamental frequency from time domain signals using Multi-Layered Neural Networks” 17th Interspeech 2016, San Francisco, USA.
We mimic computing Fourier Transforms by learning an MLP layer perceptron directly over waveform patches, mimicking an STFT pipeline. A traditional Fourier Transform has a sub-optimal representation as it learns sinusoidal basis functions linearly with constant bandwidth. Training neural architectures helps us learn a non-linear, non-constant bandwidth filter bank that optimizes a time-frequency representation like Fourier Transform according to the task at hand. On inspecting the second layer, we find that the model discovers a comb filter pattern, a fundamental signal processing algorithm used by signal processing researchers for the same task, which is so cool.
|
Before 2015
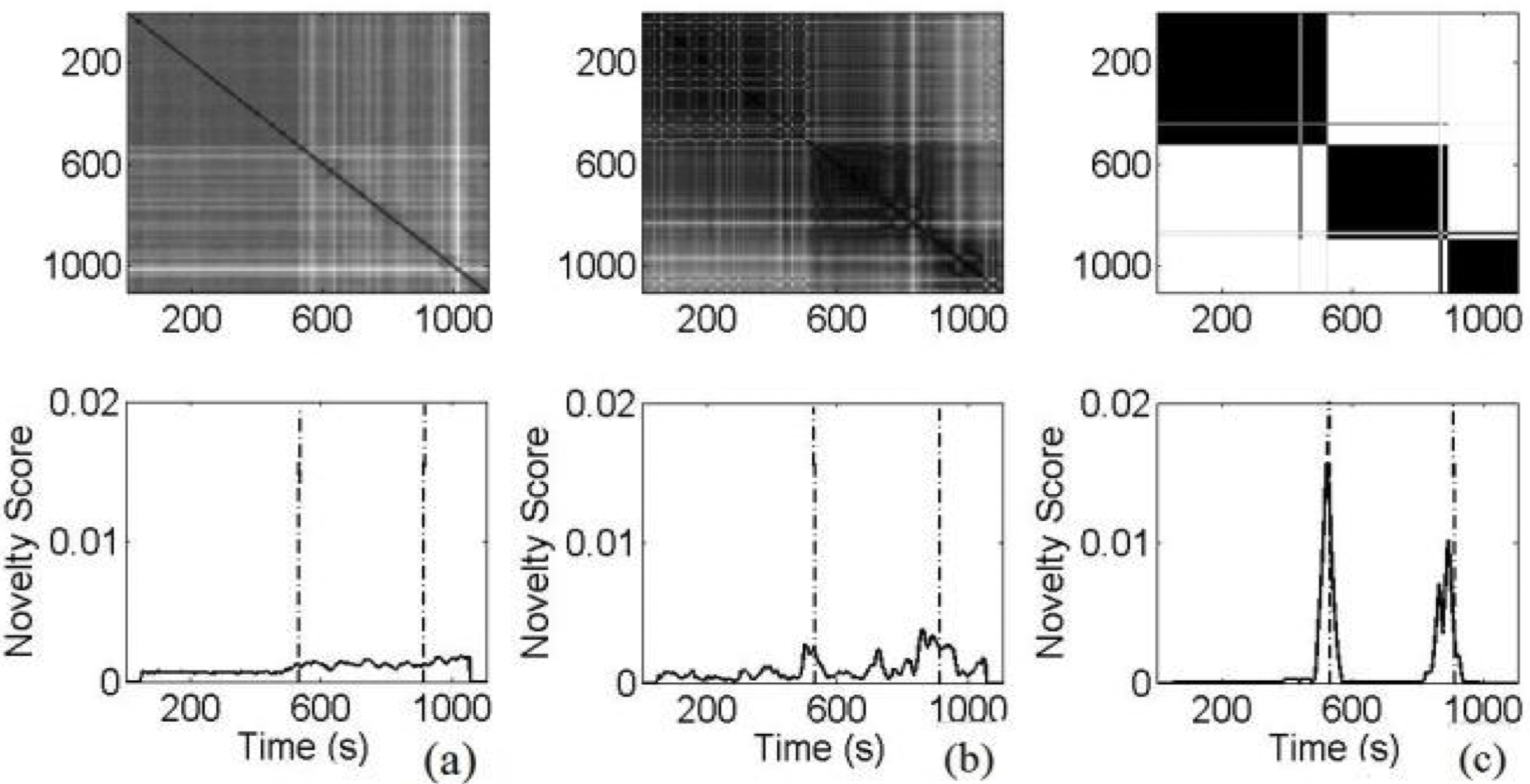 |
Prateek Verma, T.P. Vinutha, Parthe Pandit and Preeti Rao,“Structural Segmentation of Hindustani Concert Audios with Posterior Features” 40th IEEE International Conference on Acoustics Speech and Signal Processing 2015, (ICASSP) , Brisbane, Australia.
A classic signal processing paper. We address the segmentation of Hindustani instrumental concert recordings at the largest time scale: concert sections marked by prominent changes in rhythmic structure. Typical concerts are about an hour long. How can we mark segments and understand structure in long-concert pieces? We propose clustering algorithms that enable this by clustering low-level features and using posterior probability to compute self-distance matrices surpassing previous work on Western classical music. Posterior probability features from the unsupervised model fitting of the frame-level acoustic features significantly improve robustness to local acoustic variations.
|
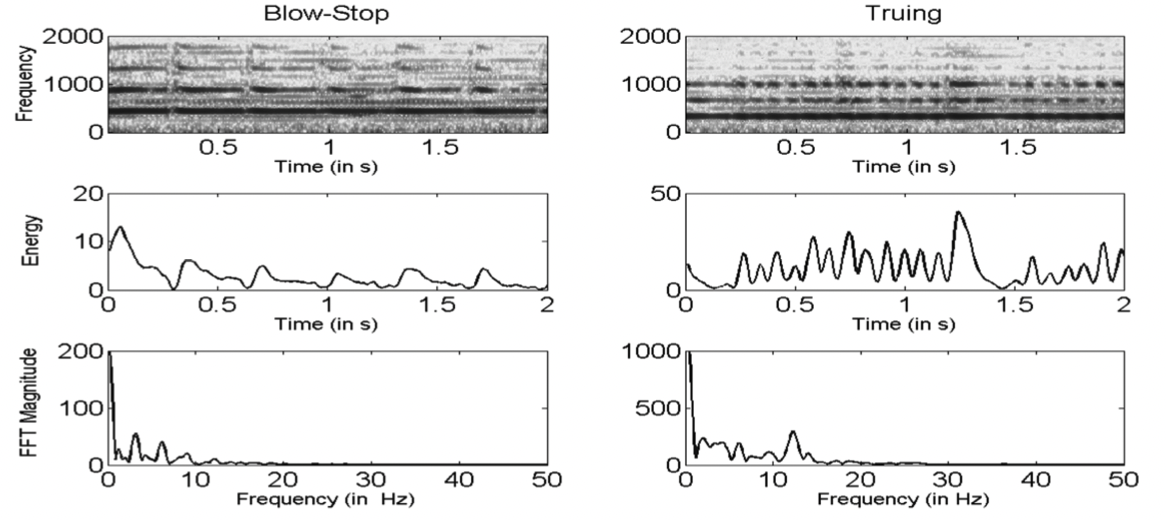 |
Prateek Verma and Preeti Rao, “Distinguishing Music Instrument Playing Styles with Acoustic Signal Analysis,” Acoustical Society of India & French Acoustical Society, Acoustics 2013, Delhi, India
In this work, we study the different playing styles of Indian classical instrumental music concerning signal characteristics from flute solo concert performances by prominent artists. Like other Hindustani classical instrumentalists, flutists have evolved Gayaki (vocal) and Tantrakari (plucked string) playing styles. The production and acoustic characteristics of the music signal are discussed. Computational features that serve to discriminate the two styles are proposed.
|
 |
Philipp Muller, Sikandar Amin, Prateek Verma, Mykhaylo Andriluka and Andreas Bulling, “Emotion recognition from embedded bodily expressions and speech during dyadic interactions”, 6th International Conference on Affective Computing and Intelligent Interaction, 2015, Xian, China.
We study the problem of emotion recognition from bodily expressions and speech during dyadic (person-person) interactions in a real kitchen instrumented with ambient cameras and microphones. We specifically focus on bodily expressions embedded in regular interactions and background activities and recorded without human augmentation to increase the naturalness of the expressions.
|
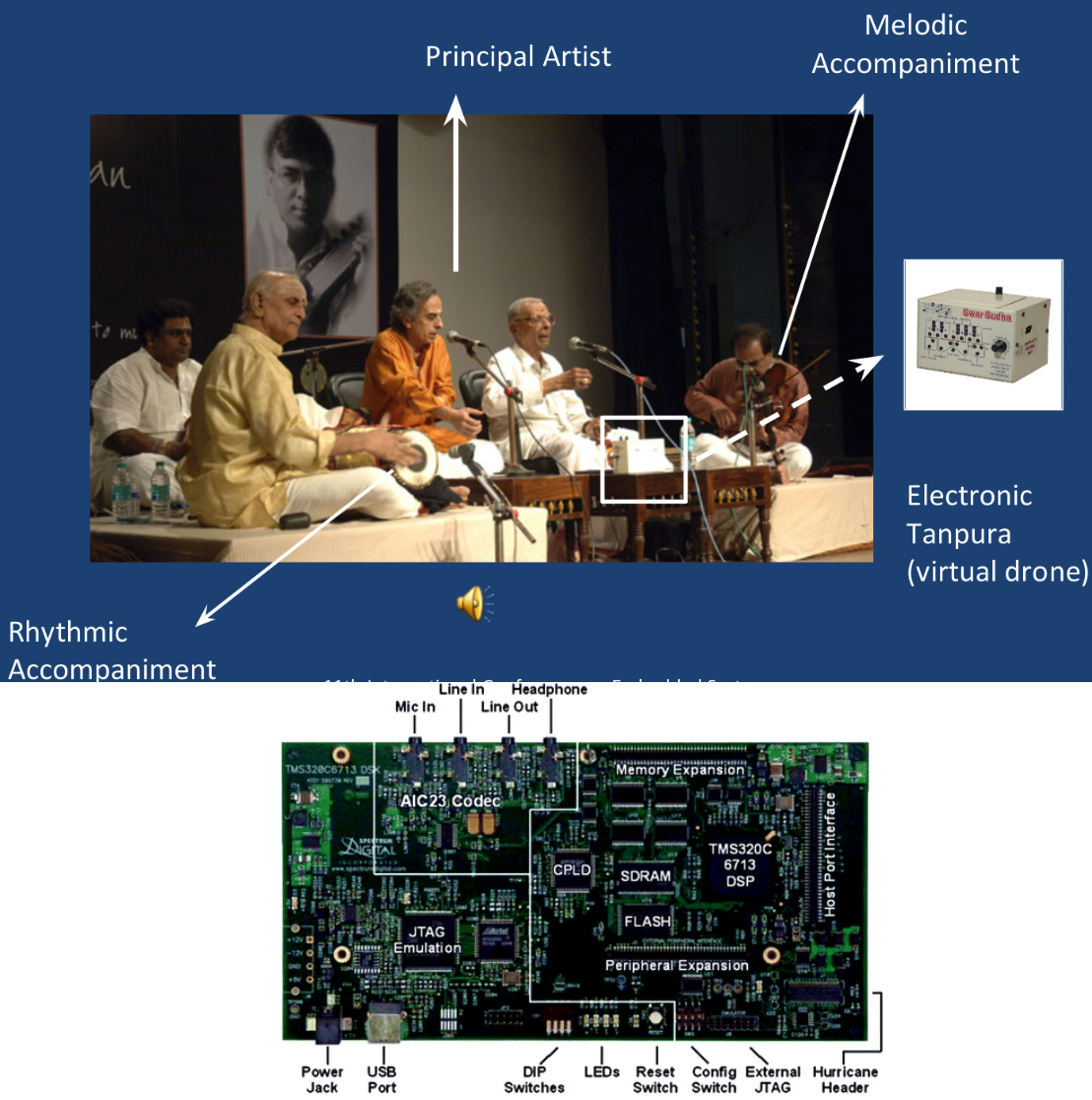 |
Prateek Verma and Preeti Rao,“Real Time Melodic Accompaniment System for Indian Music using TMS320C6713”, 25th IEEE International Conference on VLSI Design and Embedded Systems 2012, Hyderabad, India
Developing a real-time melodic accompaniment system on a DSP hardware chip. An instrumental accompaniment system for Indian classical vocal music is designed and implemented on a Texas Instruments Digital Signal Processor TMS320C6713. This will be a virtual accompanist following the main artist, possibly a vocalist. The melodic pitch information drives an instrument synthesis system, which allows us to play any pitched musical instrument virtually following the singing voice in real time with a small delay. Additive synthesis generates the desired tones of the instrument with the needed instrument constraints incorporated. The proposed system complements the automatic accompaniment for Indian classical music, namely the sruti and taala boxes.
|
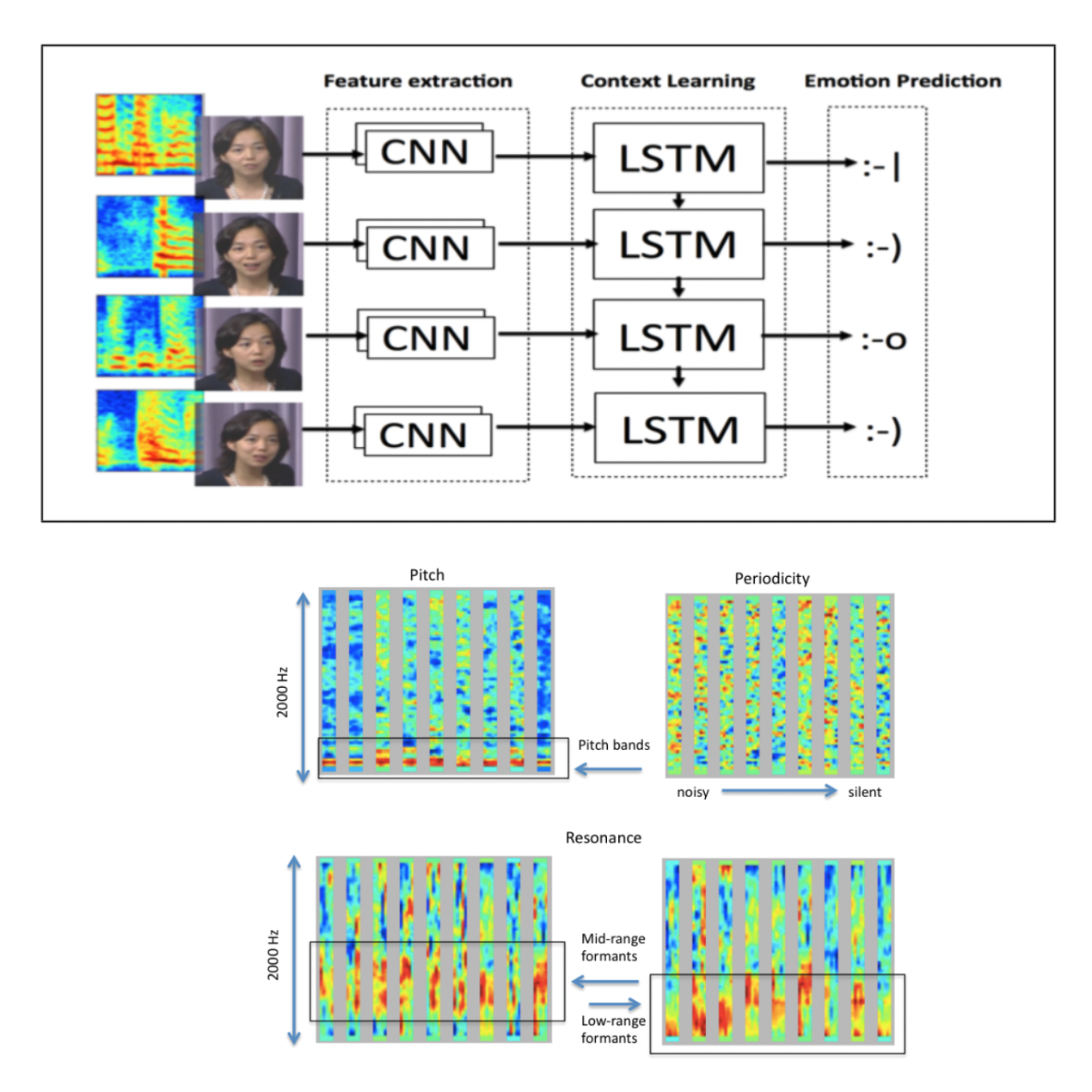 |
Namrata Anand and Prateek Verma, “Convoluted Feelings: Convolutional and Recurrent Networks for Emotion Recognition”, CS 231n Poster Session, 2015, Stanford, CA: 3rd Best Project out of more than 60 projects, 30 citations
Understanding human emotions via an architecture that can see and hear. We ingest images and audio and designed a novel CNN+LSTM architecture back in 2015 to classify human emotions into seven categories. Further, when we inspected the learned filters, to our amazement, we found that the filters learned formats and frequency activations that are salient and were part of the human-designed feature taxonomy for the same task.
|
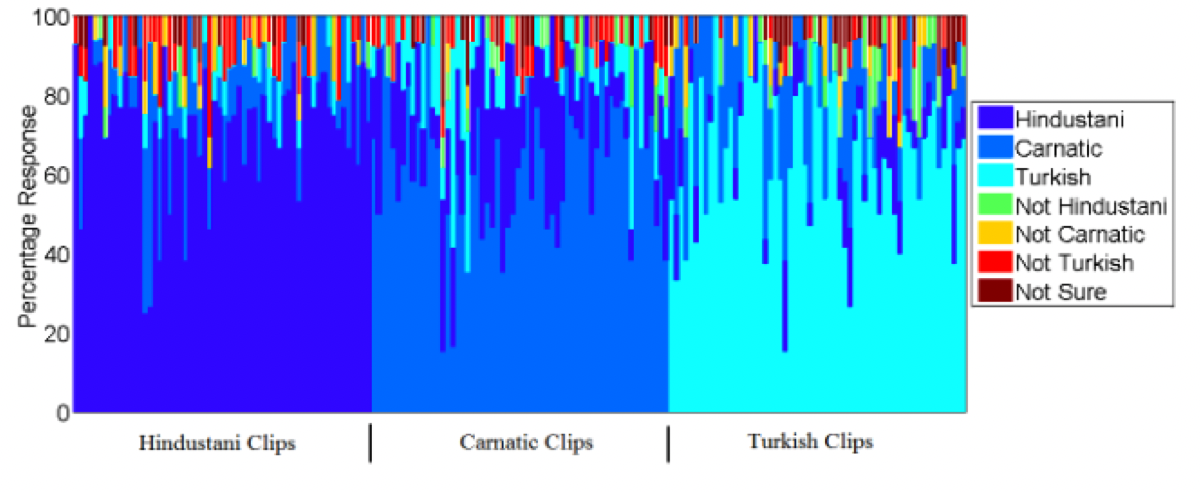 |
Amruta Vidwans, Prateek Verma, Preeti Rao, “Melodic Style Detection in Hindustani-Carnatic-Turkish Music”, 3rd CompMusic Workshop, IIT Madras, Chennai, India, 2013
Identifying culture-specific music using melodic lines alone sharing the same key/raga structure. This involved devising hand-crafted signal processing attributes devised after consultation together with musicians
|
|