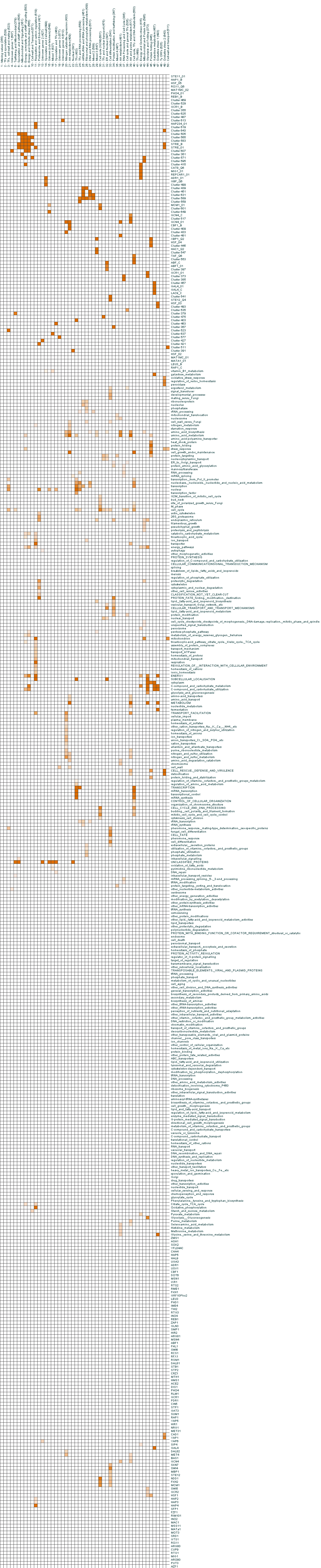
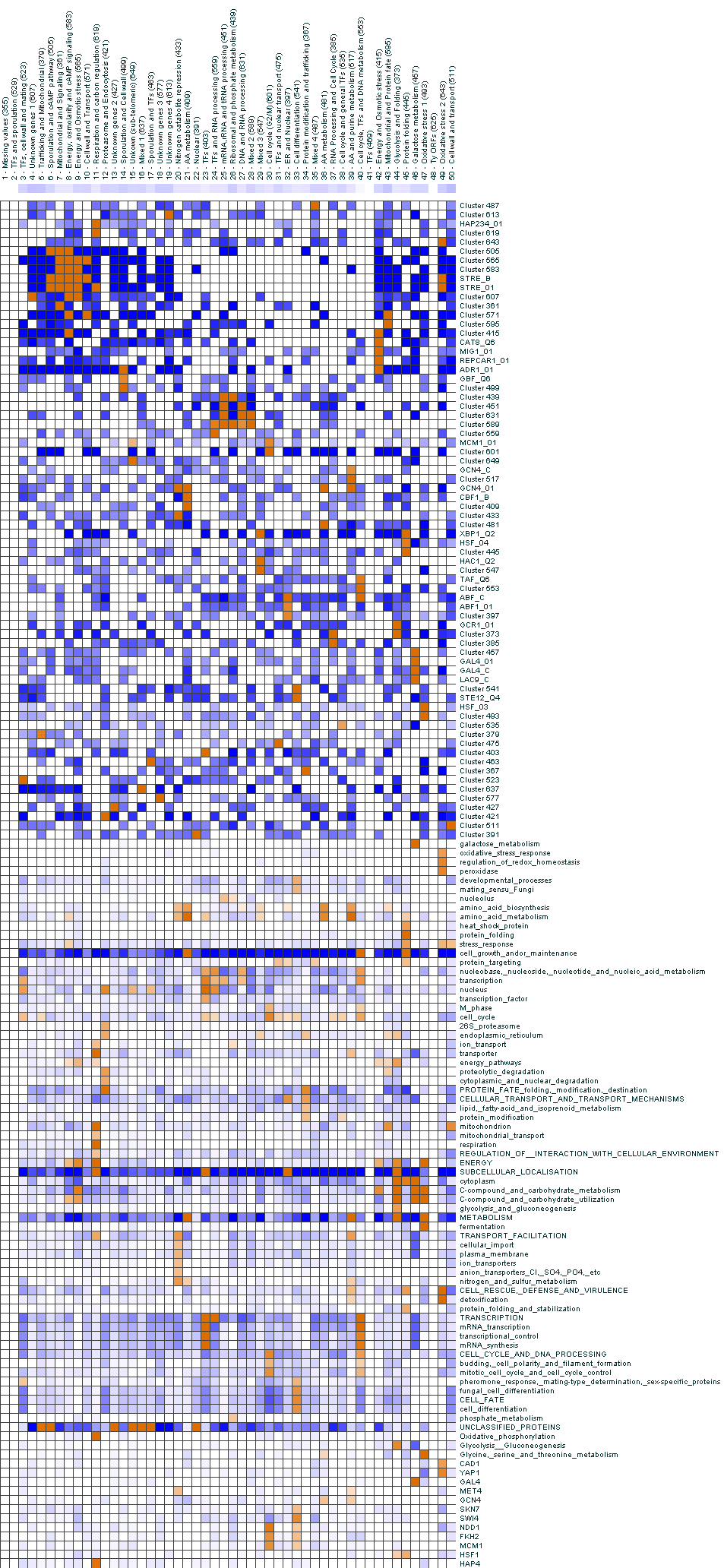
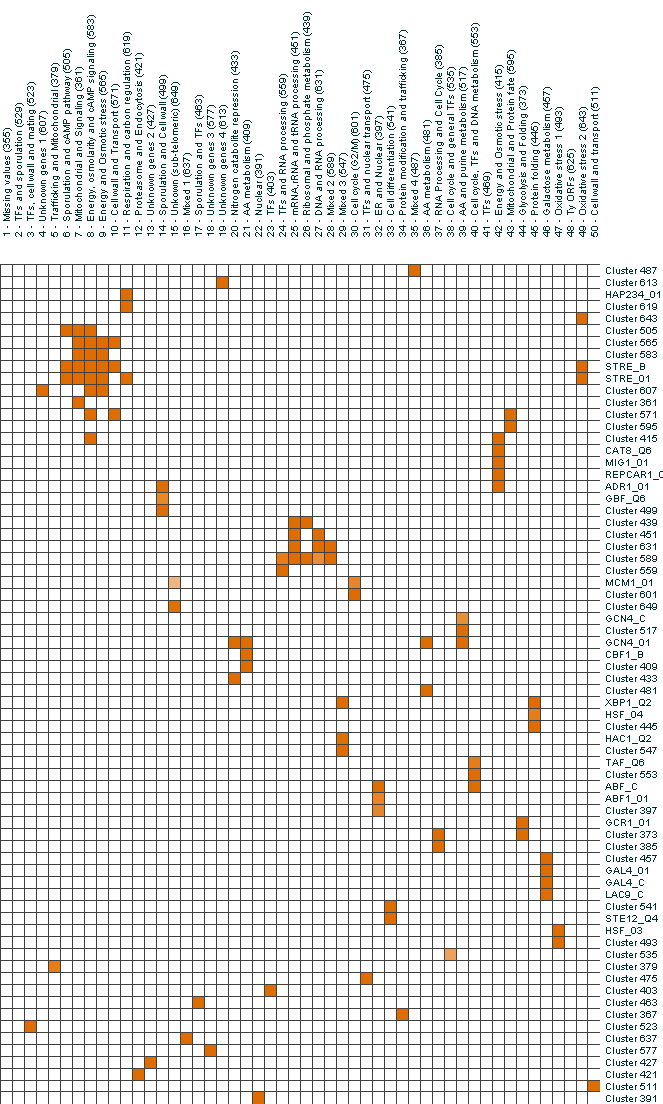
Modules Analysis
To analyze the assignments of genes to modules, we checked whether modules were
significantly enriched for different annotations. The sources of annotations were:
- Functional gene annotations (Gene Ontology, MIPS and KEGG)
- Motif binding sites (known motifs from TRANSFAC
and de-novo motifs learned using a method previously published by Segal, Barash, Simon, Friedman and Koller in
RECOMB 2002)
- Protein-DNA binding assays published in Lee et al, Science...
For each module and each of the above attributes, we compared the fraction of genes
in the module with the attribute to the fraction of genes with the attribute in the entire
dataset. For each such event we compute a pvalue, correcting for the multiple hypothesis
testing. In the following matrices, we show the fraction of genes in each module that
have each attribute, by the intensity of the color in each square of the matrix.
Significant events are colored in shades of orange and insignificant events are colored
in shades of blue (significance was determined by a pvalue of 0.05 after multiple correction).
For convenience, we also show matrices in which we filtered only annotations that
were significant as well as matrices in which only significant events appear.
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}