Clover: Closed-Loop Verifiable Code Generation
TL;DR - Although large language models (LLM) have achieved amazing success in code generation in recent years, the trustworthiness of such AI-generated code remains a problem. To address this, we propose the Clover paradigm, short for Closed-Loop Verifiable Code Generation, that checks consistencies among code, docstrings and annotations and enforces correctness in AI-generated code. [paper][github]
Content
- Formal Verification & AI are a good couple
- Dafny
- Clover Phase One: Generation
- Clover Phase Two: Verification
- Conclusion
Leveraging large language models (LLM) for code generation is a rapidly growing trend in software development. However, without effective methods to ensure the correctness of AI-generated code, this trend could lead to undesirable outcomes. In this work, we introduce a paradigm named Clover, short for Closed-Loop Verifiable Code Generation to address this challenge. Clover reduces correctness checking to the more accessible problem of consistency checking and safeguards LLM-powered code generation from potentially costly mistakes.
At the core of Clover lies a checker that performs consistency checks among code, docstrings, and formal annotations. The checker is implemented using a novel integration of formal verification tools and large language models. We empirically investigate its feasibility on a hand-designed dataset (CloverBench) featuring annotated programs in an annotated aware language at a textbook level of difficulty. Experimental results show that for this dataset, (i) LLMs are reasonably successful at automatically generating formal specifications; and (ii) our consistency checker achieves a promising acceptance rate (up to 87%) for correct instances while maintaining zero tolerance for incorrect ones (no false positives).
Formal Verification & AI are a good couple
Large language models (LLMs) have recently demonstrated remarkable capabilities. They can engage in conversations, retrieve and summarize vast amounts of information, generate and explain text and code, and much more 1 2 3. Among many possible applications, their ability to synthesize code based on natural language descriptions 4 5 6 is stunning and could potentially enhance the productivity of programmers significantly 7.
However, there is a fundamental challenge that must be overcome before realizing any of this future. As of now, there is no trustworthy way to ensure the correctness of AI-generated code8. The current best practice for curating AI-generated artifacts is to have a human in the loop, e.g., copilot 9. While this is better than nothing, human oversight is expensive and inefficient, making it challenging to scale in the long run.
It is becoming clear that curating the quality of AI-generated content will be one of the most crucial research problems in the coming years. For one, generated code must be functionally correct and reliable. Errors or bugs in the code can lead to software malfunctions, which can be costly, dangerous, or both, especially in critical systems like medical software, financial systems, or autonomous vehicles. Furthermore, if generated code is not trustworthy, it may inadvertently introduce security vulnerabilities into software. This could be exploited by malicious entities, leading to data breaches, privacy violations, and other security incidents. Luckily, in the specific case of code generation, formal verification provides mathematically rigorous guarantees on the quality and correctness of arbitrary code. What if there were a way to automatically apply formal verification to the generated code? This doesn’t just provide a scalable solution; it has the potential to pave the way for a future where AI-generated code is more reliable than human-written code.
At the moment, formal verification is only possible with human expertise. The main hypothesis of this work is that LLMs are well-positioned to generate the collateral needed to help formal verification succeed without compromising the formal guarantees provided by formal methods.
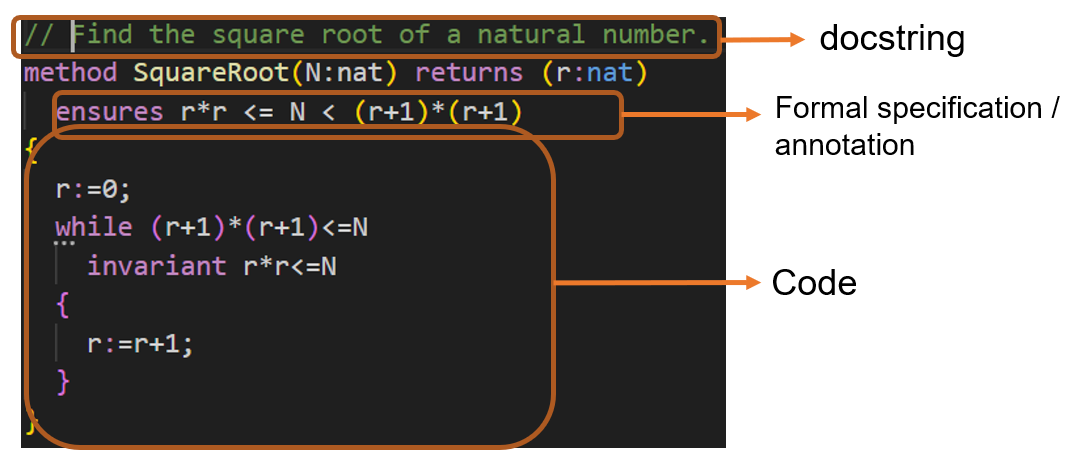
Currently, formal verification is only possible with the aid of time-consuming human expertise. In a typical formal verification process, after constructing a mathematical model of the system to be verified, human experts provide a formal specification of the system (In Listing 1) that the model satisfies the specification. For code, a number of tools (e.g., Dafny 10) already exist that can prove that some input specification satisfies some input code. Traditionally, significant human expertise is required to create formal specifications and ensure that they are both internally consistent and accurately capture the intended functionality.
The output of any AI-based code generation technique should aim to include not only code but also formal specifications and natural language docstrings. We can then use formal tools coupled with generative AI techniques to make sure they are consistent. This approach is named Clover, short for Closed-Loop Verifiable Code Generation.
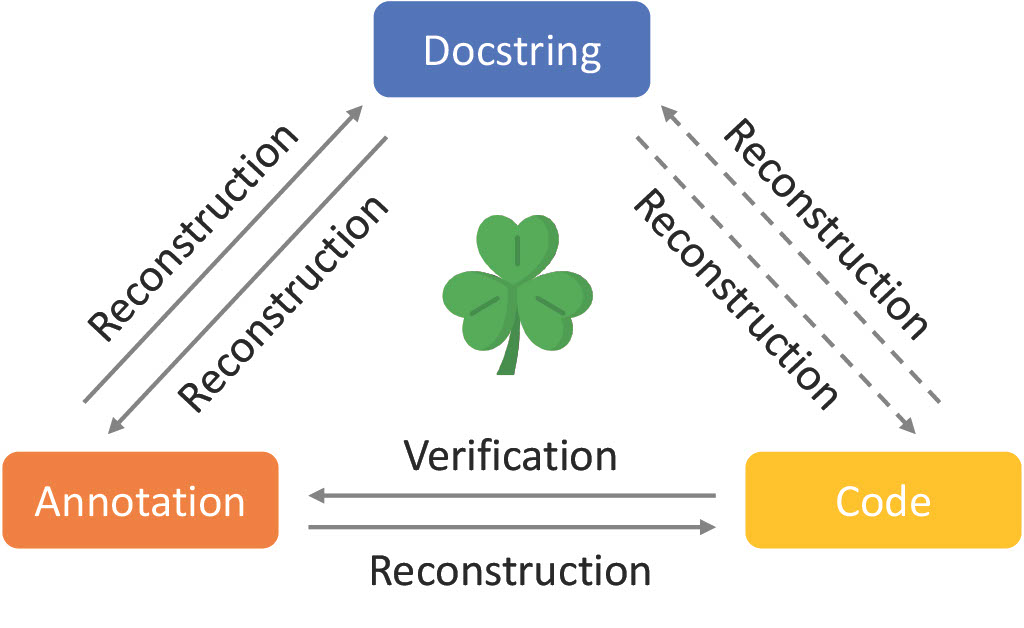
The Clover paradigm consists of two phases. In the first (generation) phase, code annotated with a formal specification (annotations) and a natural language documentation string (docstrings) is created. In the second (verification) phase, six consistency checks are applied to the code, annotations, and docstrings. If the consistency checks pass, then (i) the code is functionally correct with respect to its annotation; (ii) the annotation captures the full functionality of the code; and (iii) the docstring also accurately reflects the functionality of the code (see Figure 1).
The idea is that we can leverage increasingly powerful generative AI techniques in the generation phase, and then use the verification phase as a strong filter that only approves code that is formally verified, accurately documented, and internally consistent.
Dafny
Dafny is the programming language used in our evaluation. Dafny's back-end includes a compiler, capable of generating a runnable binary, and a verifier, checking formally whether the code conforms to its specification. Listing 1 lists a Dafny function for finding the square root of a natural number with three components (docstring, annotations and code).
Clover Phase One: Generation
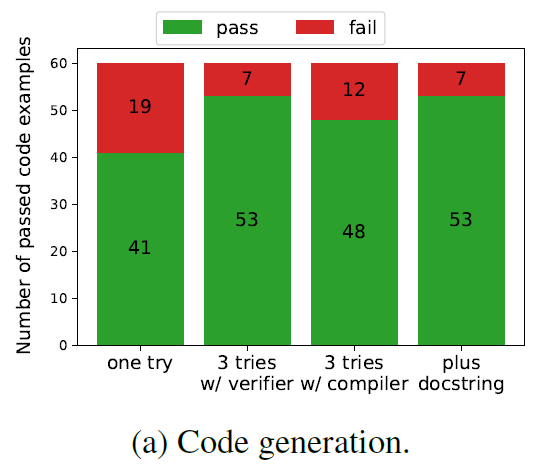
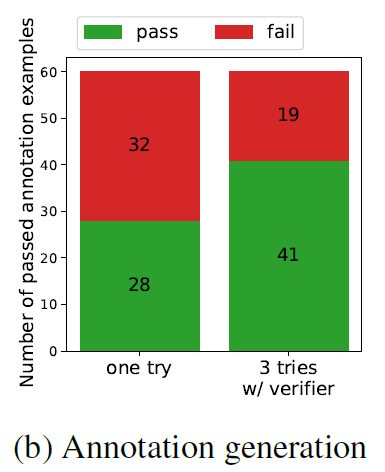
We first demonstrate that the generation phase in Clover can produce code with annotations and docstrings. In particular, we experiment with OpenAI’s GPT-4. Figure 2a shows the results when GPT-4 is asked to generate the code for each of the 60 examples in CloverBench under various conditions. The first bar (“one try”) shows the result in a single try. The next bar allows GPT-4 to try three times, each time providing the output of the Dafny compiler and verifier as feedback. The third bar is similar but uses the output of only the Dafny compiler. In the last bar, we allow three tries and we also provide the docstring. Figure 2b shows results from asking GPT-4 to generate annotations when provided with just the code. Though not perfect, out of the box, GPT-4 can produce correct annotations for the majority of programs. This suggests that using LLMs for specification generation is feasible.
Clover Phase Two: Verification
Clover expects the output of the generation phase to contain three components: code, annotations, and docstrings. It also expects that each of the three components provides sufficient detail to unambiguously determine a unique result of running the code on any given input. The verification phase checks the consistency of every pair of components, as shown in Figure 1, and succeeds only if all checks pass.
Specifically, there are six checks in total:
(1) anno-sound: A deductive verification tool (our evaluation uses Dafny) checks that the code satisfies the annotation.
(2) anno-complete: Given the annotation, we use an LLM to generate new code. Then, we check the equivalence between the generated and the original code.
(3) anno2doc: An LLM is asked to generate a new docstring from the annotation. Then, the new and the original docstrings are checked for semantic equivalence using an LLM.
(4) doc2anno: An LLM is asked to generate a new annotation from the docstring. Then, the new and the original annotations are checked for logical equivalence using a formal tool.
(5) code2doc: An LLM is asked to generate a new docstring from the code. Then, the new and the original docstrings are checked for semantic equivalence.
(6) doc2code: An LLM is asked to generate code from the docstring. Then, the new and the original code are checked for functional equivalence.
Reconstruction testing
Reconstruction of the original artifact is the key in each check. Given the three components (code, docstring, annotation) as input, we try to reconstruct a single component from a single other component, and then we check if the reconstructed result is equivalent to the original component. We do this for five out of the six (directed) edges of Figure 1. A special case is checking that the code conforms to the annotation, where we use formal verification based on deductive verification tools instead of a reconstruction test. In this way, the Clover triangle is more stable. Listing 2-4 are examples of generated artifacts.

In the following figure, we feed the masked function signature plus annotation to GPT4 and parsed out the generated code.


Equivalence Checking
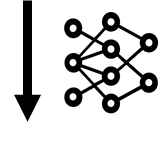
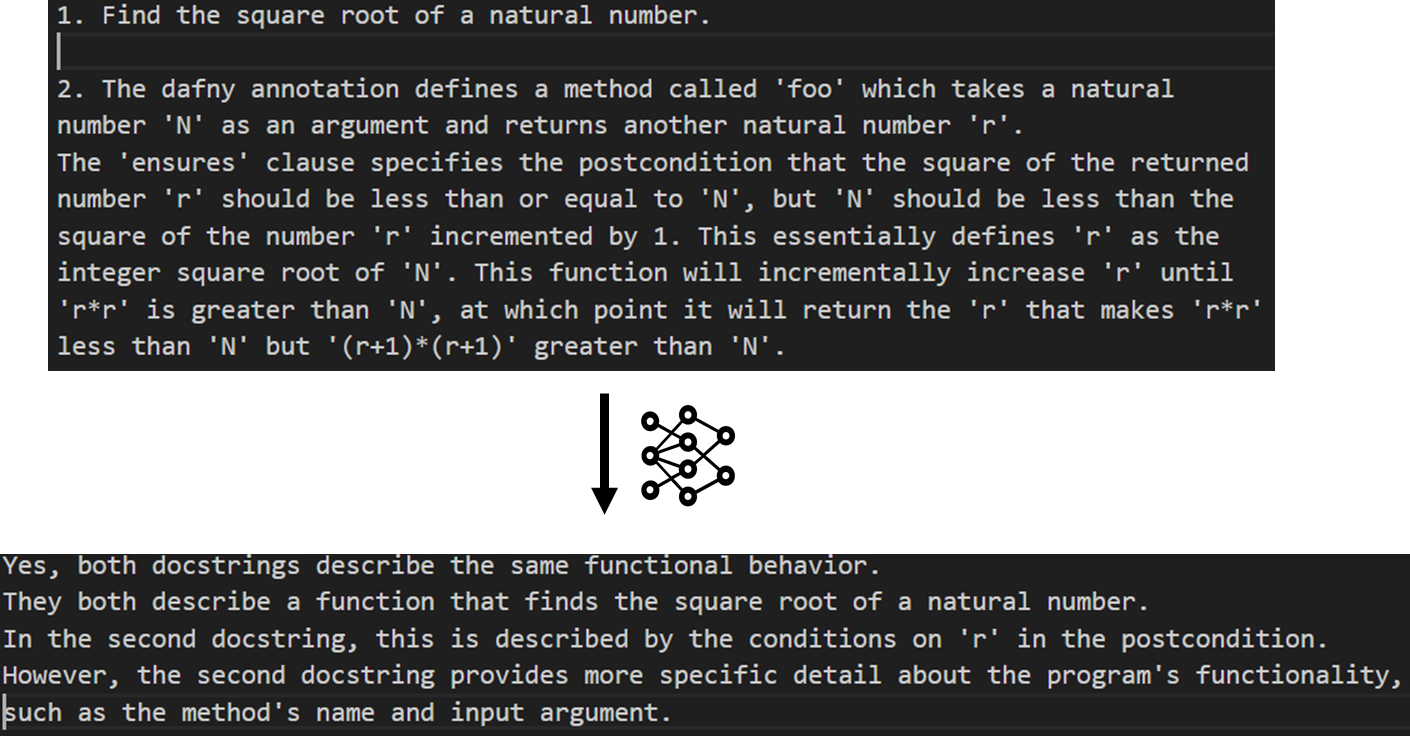
Standard equivalence checks for code include input-output comparisons, concolic testing, and even full formal equivalence checking. Our evaluation uses unit tests that are included as part of the CloverBench dataset. Checking equivalence between docstrings is challenging, as natural language is not mathematically precise. In our evaluation, we ask GPT-4 to check whether two docstrings are semantically equivalent. To check the equivalence of two annotations, we write the equivalence of the two annotations as a formal lemma and ask Dafny to prove the lemma.
In the following figure, we test the docstring equivalence.
CloverBench Dataset [github]
There have been several popular datasets for code generation in different domains 11 12 13 14, but none contain annotations or use the Dafny language. We introduce a new hand-crafted dataset we call CloverBench. At the time of writing, it is based on 60 small hand-written example programs similar to examples found in standard CS textbooks, eg. selection sort. For each program, there are four variants: a ground-truth variant whose code, annotation, and docstring are correct and consistent (verified by hand); and 3 incorrect variants.
Evaluating Consistency Checking Algorithm
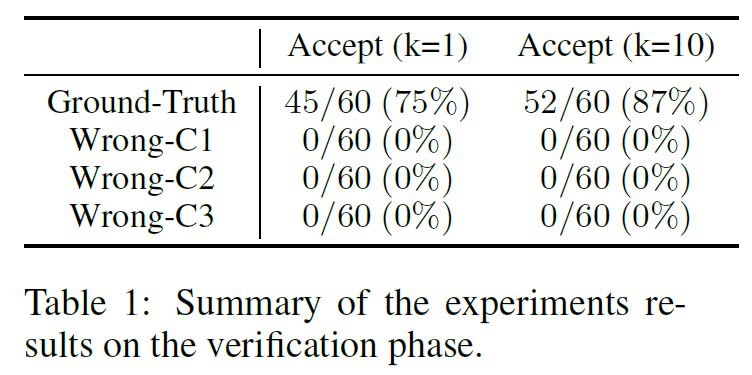
Our main experiment evaluates the capabilities of the Clover consistency checking algorithm. For each example in CloverBench, we run all 6 checks described in above. We also evaluate the effect of multiple independent runs, meaning that we repeat each of the 6 checks k times. The end-to-end results are summarized in Table 1. When k=1, we see that our Clover implementation accepts 45 of 60 correct (ground truth) examples and rejects all incorrect examples. When k=10, Clover accepts 52 of 60 correct examples and rejects all incorrect ones.
Conclusion
We have introduced Clover, a framework for closed-loop verifiable code generation. We reduce the problem of checking correctness to the more accessible problem of checking consistency.
Initial experiments using GPT-4, Dafny, and a set of simple textbook examples are promising. We show an 87% acceptance rate for ground-truth examples and a 100% rejection rate for incorrect examples. As future work, we may focus on designing better verification tools, improving code / annotation / docstring generation quality, improving LLM’s understanding of Dafny syntax, or scaling up to more challenging examples.
-
OpenAI. “GPT-4 Technical Report.” ArXiv abs/2303.08774 (2023): n. pag. ↩
-
Chowdhery, Aakanksha, et al. “Palm: Scaling language modeling with pathways." Journal of Machine Learning Research 24.240 (2023): 1-113. ↩
-
Bubeck, Sébastien, et al. "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023). ↩
-
Chen, Mark, et al. ‘Evaluating Large Language Models Trained on Code’. CoRR, vol. abs/2107.03374, 2021, https://arxiv.org/abs/2107.03374. ↩
-
Li, Yujia, et al. "Competition-level code generation with alphacode." Science 378.6624 (2022): 1092-1097. ↩
-
Cheng, Zhoujun, et al. "Binding language models in symbolic languages." arXiv preprint arXiv:2210.02875 (2022). ↩
-
Maxim Tabachnyk and Stoyan Nikolov. “ML-Enhanced Code Completion Improves Developer Productivity” Google Research Blog, 26 July 2022, [https://blog.research.google/2022/07/ml-enhanced-code-completion-improves.html] Accessed 16 Dec 2023. ↩
-
Liu, Jiawei, et al. "Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation." arXiv preprint arXiv:2305.01210 (2023). ↩
-
Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021). ↩
-
Leino, K. Rustan M. ‘Dafny: An Automatic Program Verifier for Functional Correctness’. International Conference on Logic for Programming Artificial Intelligence and Reasoning, Springer, 2010, pp. 348–370. ↩
-
Austin, Jacob, et al. ‘Program Synthesis with Large Language Models’. CoRR, vol. abs/2108.07732, 2021, https://arxiv.org/abs/2108.07732. ↩
-
Hendrycks, Dan, et al. ‘Measuring Coding Challenge Competence With APPS’. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, Virtual, edited by Joaquin Vanschoren and Sai-Kit Yeung, 2021, https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/c24cd76e1ce41366a4bbe8a49b02a028-Abstract-round2.html. ↩
-
Yin, Pengcheng, et al. ‘Natural Language to Code Generation in Interactive Data Science Notebooks’. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, edited by Anna Rogers et al., Association for Computational Linguistics, 2023, pp. 126–173, https://doi.org10.18653/v1/2023.acl-long.9. ↩
-
Lai, Yuhang, et al. ‘DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation’. International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, edited by Andreas Krause et al., vol. 202, PMLR, 2023, pp. 18319–18345, https://proceedings.mlr.press/v202/lai23b.html. Proceedings of Machine Learning Research. ↩