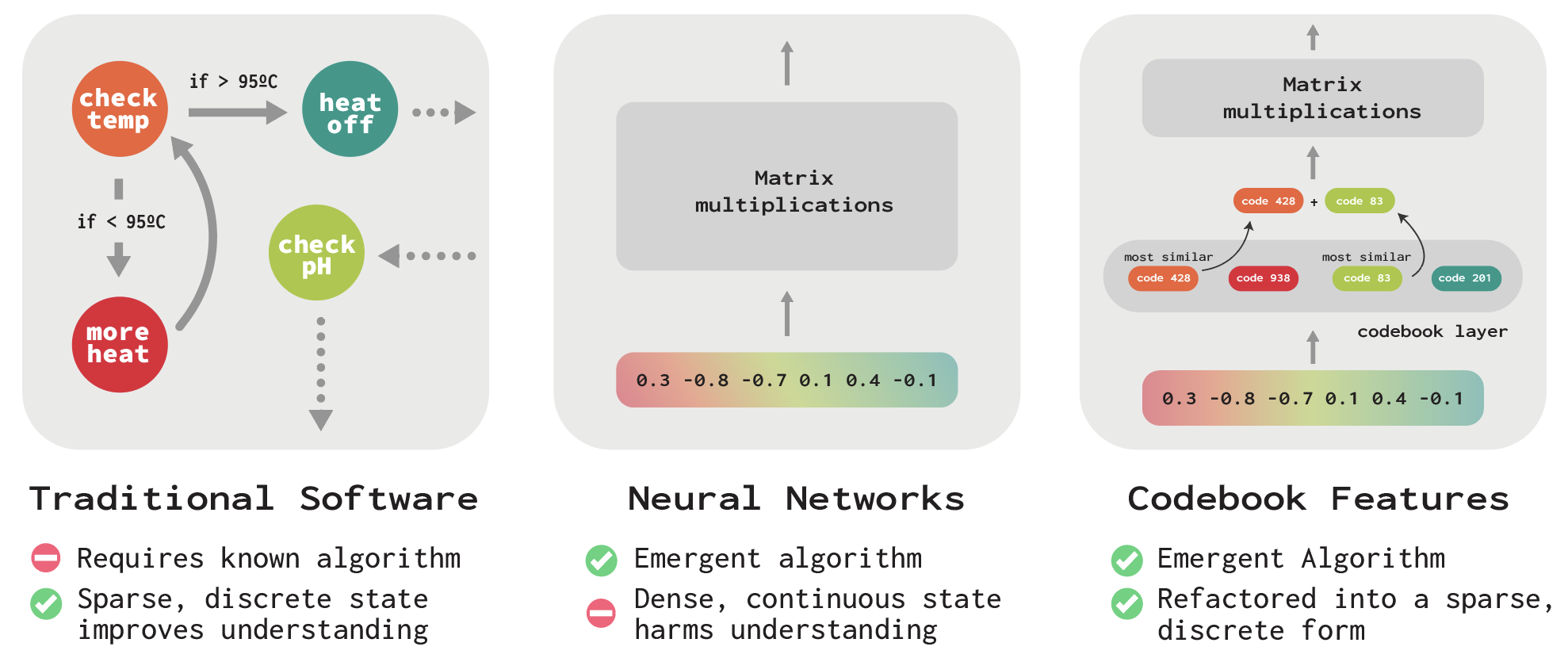
Neural networks like image classifiers and language models remain challenging to understand. Unlike computers, their internal computations are dense and continuous, making it hard to know how they process inputs and arrive at predictions. In our new paper, we introduce codebook features to make progress on these challenges by training neural networks with sparse, discrete hidden states.
Method
The key idea in our approach is to discretize a network’s hidden states into a sparse combination of vectors. We do this by adopting a classical technique from signal processing called vector quantization1, where vectors are represented by a smaller set of learned embedding vectors. Originally developed for data compression, vector quantization has seen wide use in machine learning, most prominently in autoencoders like VQ-VAE2.
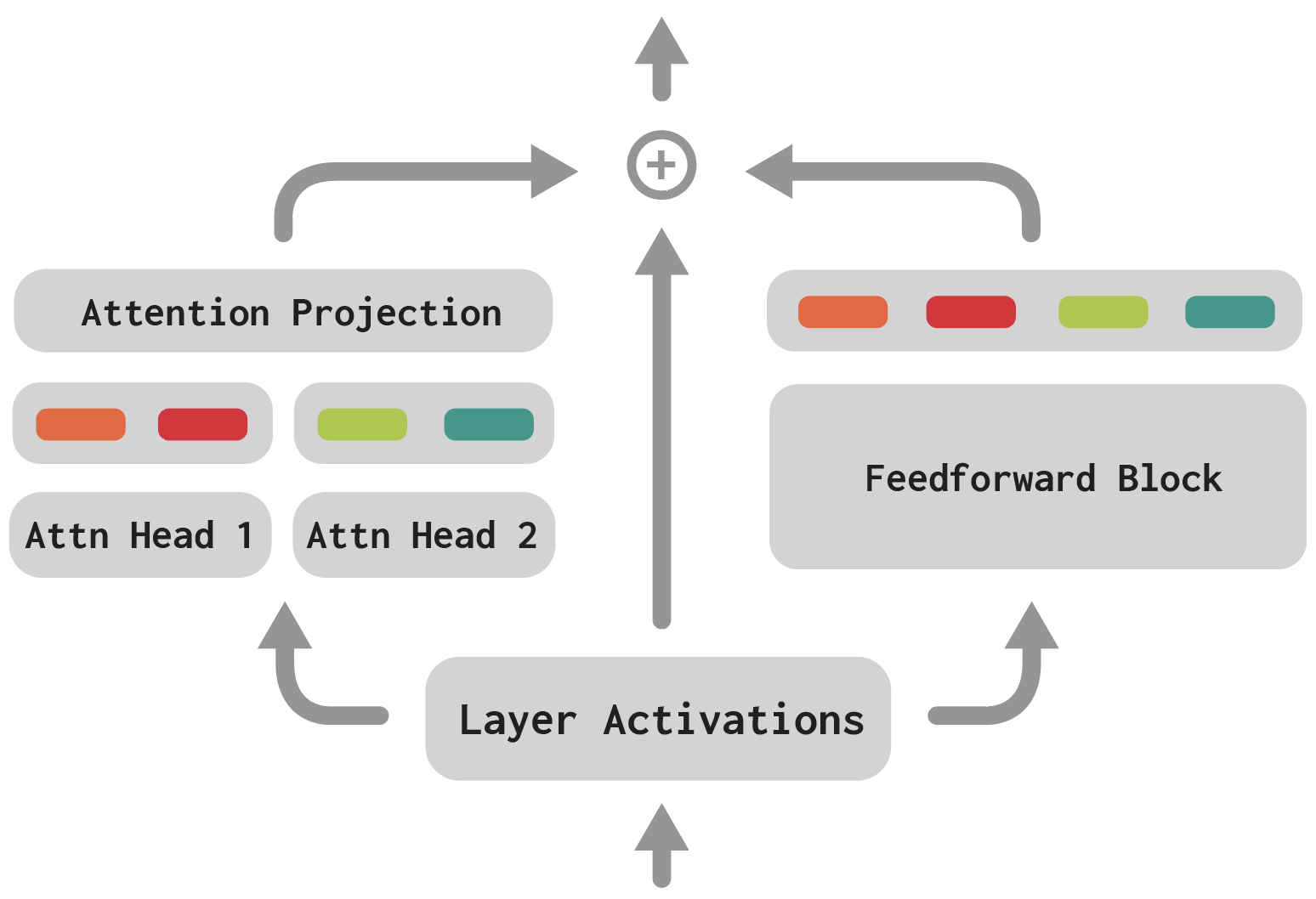
In our approach, we learn a large set of vectors during training called a codebook. This specifies all the states a network’s layer can be in at a given time. When we see a new input, we compute the top-k most similar vectors for the network’s activations at that layer, and pass the sum of those vectors on to the next layer. By training a network with these sparse, discrete bottlenecks, we hope to refactor a neural network’s internals into a more interpretable form. Surprisingly, we find that we are able to train transformer language models with this sparse bottleneck that exhibit little drop in accuracy: we place the codebooks after each attention head and MLP block and train the model end-to-end (Figure 2).
Finite State Machine (FSM)
In our first set of experiments, we create a sequence modeling dataset where we know the latent structure a model has to learn in order to predict the next token. This enables us to measure how well the neurons of the network, as well as our codebooks, are able to capture this structure.
We generate this dataset via rollouts of a finite state machine (FSM) with 100 discrete states, where each state can transition to one of 10 other states with uniform probability. Each state is written as two separate tokens, meaning that the transformer needs to make use of its attention layers in order to identify which state it is in and predict the next token. As an example, the trajectory 42 -> 95 -> 12 -> ... would be written as the sequence of tokens [4, 2, 9, 5, 1, 2].
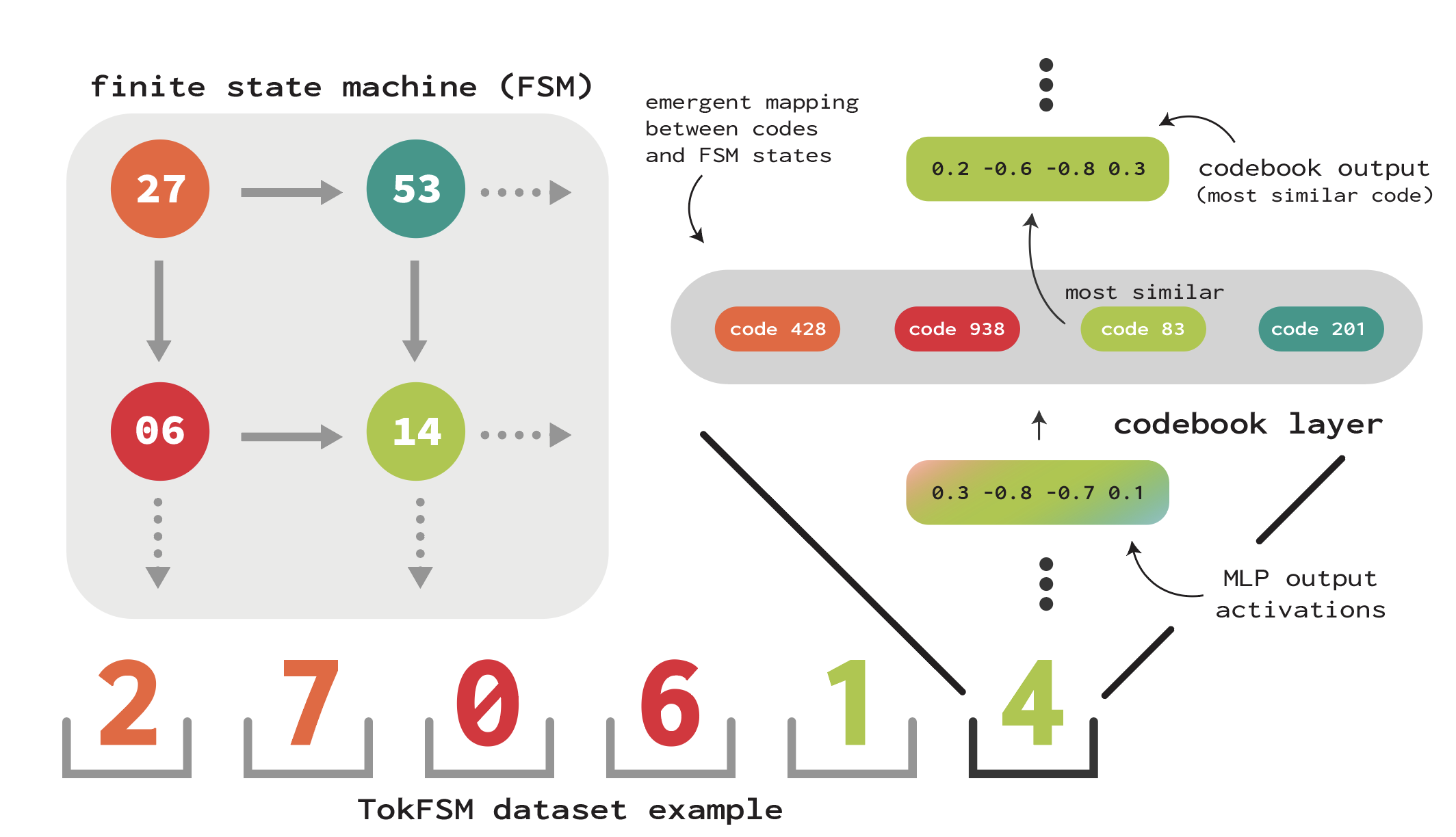
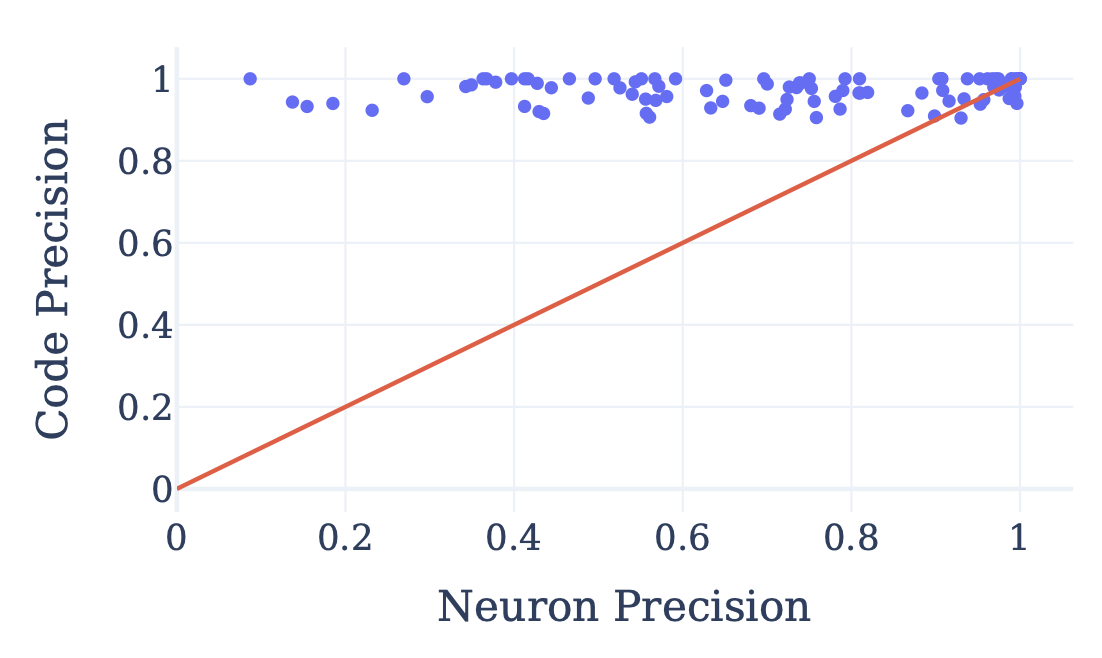
Remarkably, when we train the model with codebooks at each layer, the model learns to allocate almost every FSM state a separate code in the MLP layer’s codebook. We can quantify this by treating whether a code is on or off as a classifier for whether the state machine is in a particular state; for example, a code that only activates when the machine is in state 42 would be a classifier with high precision for that state. We can then search for the neuron with the best precision at the code’s recall level and compare how well neurons and codes detect different states. Encouragingly, codes classify states with over 97% precision, far better than individual neurons.
But correlation isn't causation. Just because codes activate in the presence of states doesn’t mean these states are used by the network. To test this, we conducted intervention experiments, replacing active codes with ones linked to other states. This consistently shifted the model's next token predictions to align with the new states, providing strong evidence that codes play a causal role in controlling behavior.
Language modeling
In addition to the state machine results, we also scale up codebook features to large transformer language models with over 400 million parameters. Remarkably, despite the sparse bottleneck, these models maintain strong performance on language modeling benchmarks like WikiText-103.
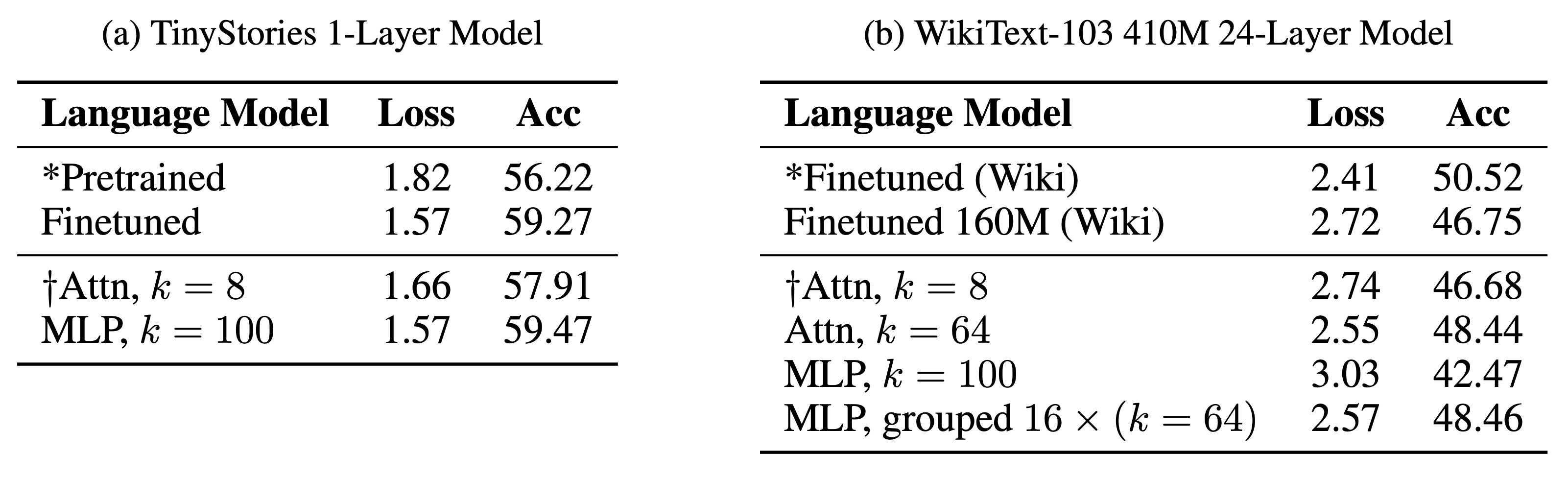 Codebook models are still capable language models. See the paper for more details.
Codebook models are still capable language models. See the paper for more details.
More importantly, we found codes clearly representing diverse linguistic phenomena — from punctuation and syntax to semantics and topics. For example, certain codes selectively activated on months, names starting with "B", or abstract concepts like flowers.
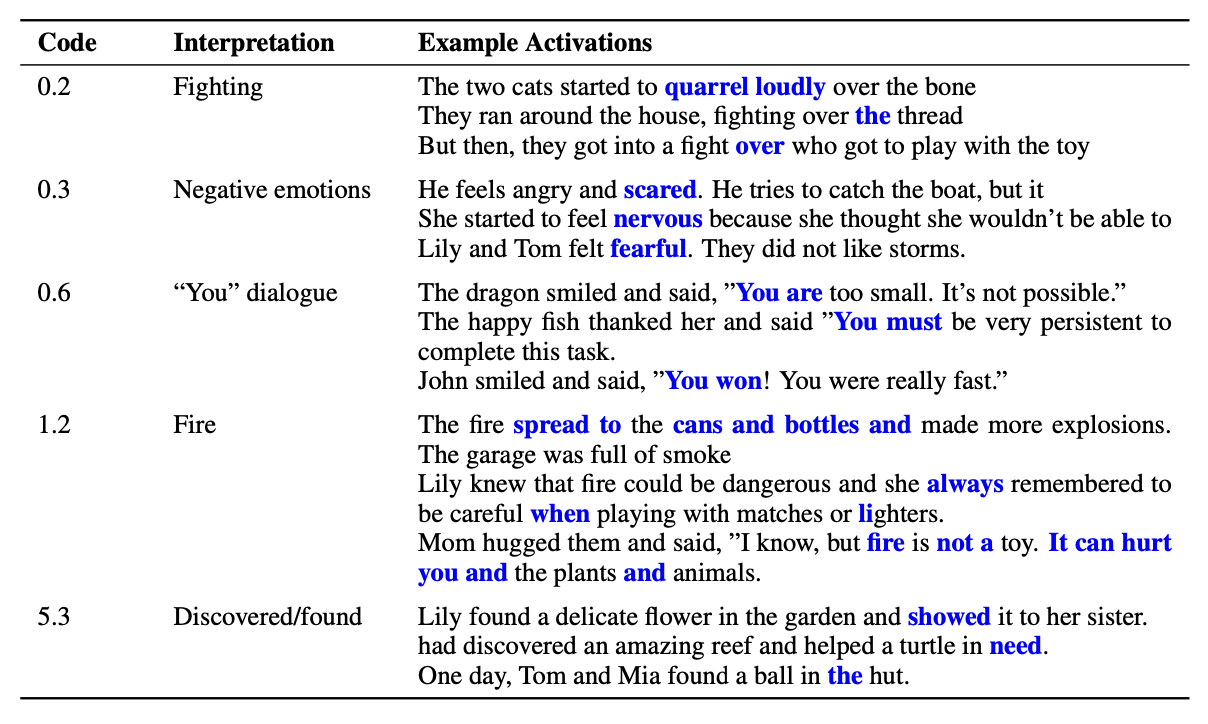
We also constructed a range of simple regular expressions for different linguistic features (e.g. years starting with “2”) and found that codes were better classifiers of these features than the best neurons in the 24-layer model.
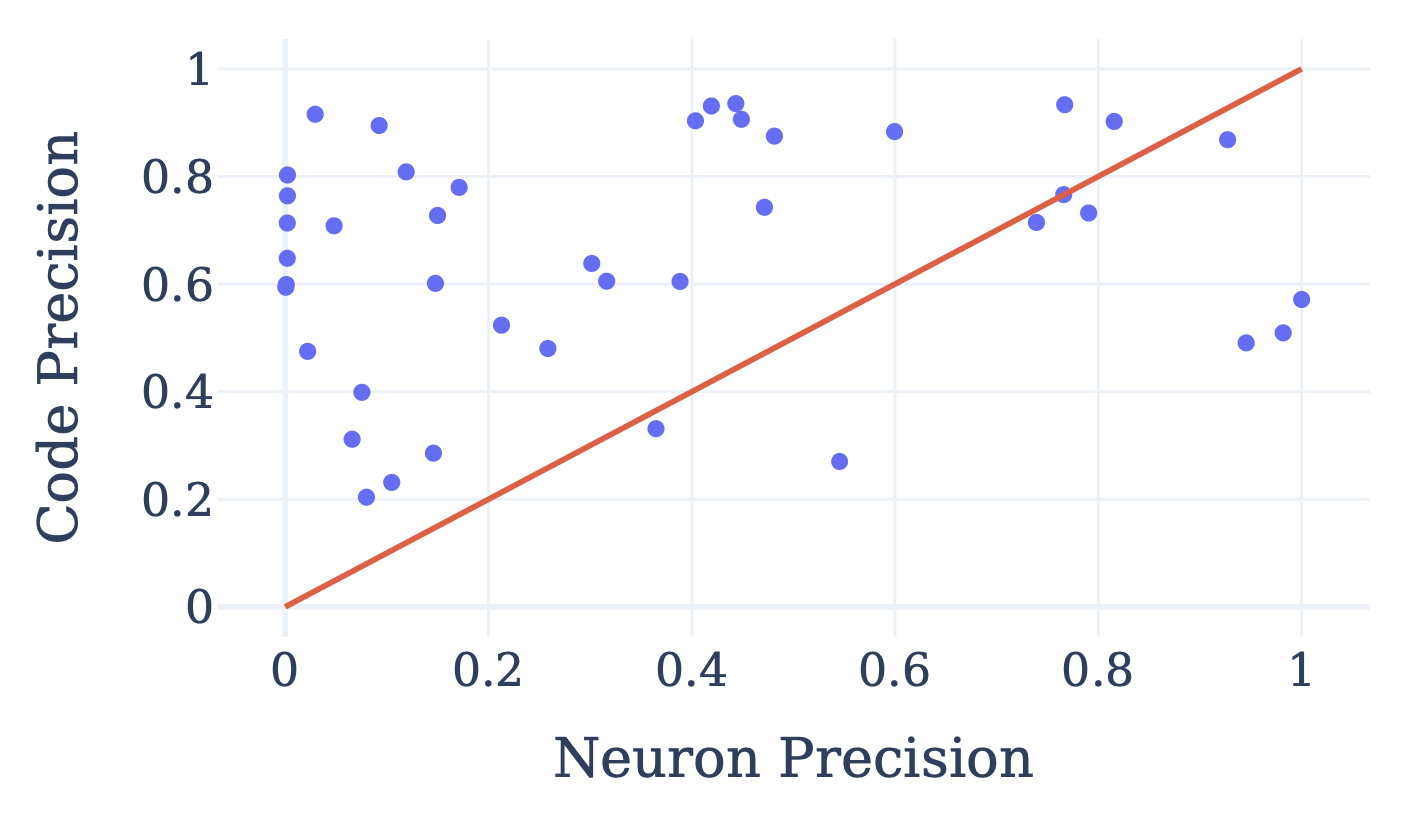
While many codes appear uninterpretable at a glance in this larger model, this suggests that a range of discrete codes capture meaningful concepts. In future work, we hope to study whether uninterpretable codes admit meaningful interpretations with more human effort or whether better training methods can increase the fraction of interpretable codes.
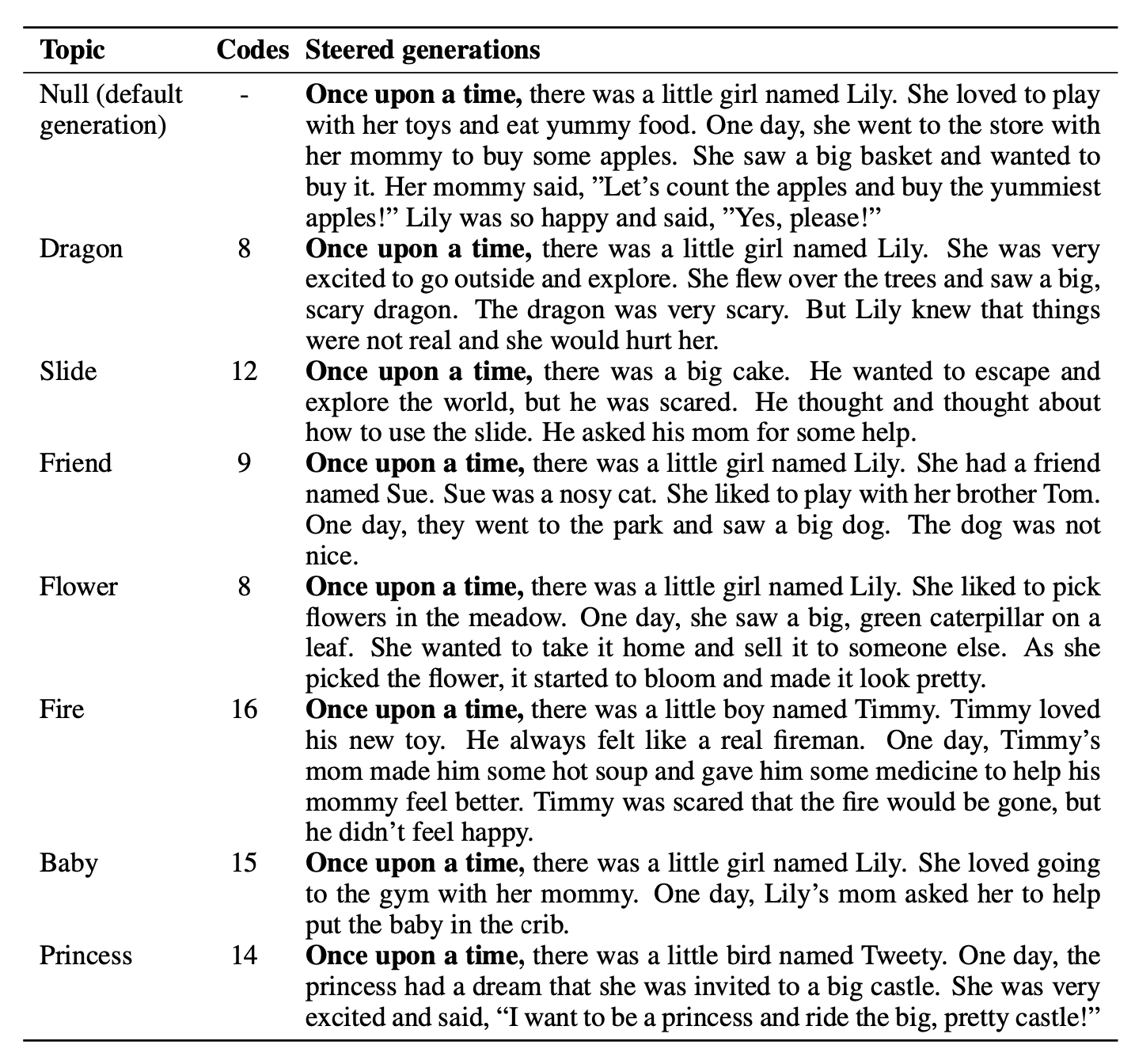
To validate a causal role for these codes, we identified topic codes for subjects like football and dragons based on their activations. We then intervened to activate these codes during text generation. This successfully steered the model's generations to introduce the desired topics in a natural way, demonstrating how codebook features can lead to insights about a model’s inner functions.
Conclusion
Despite these initial successes with codebook features, many open questions remain. Do codebook features generalize across diverse domains and modalities3 4? Can we automate discovering higher-level circuits5 that connect codes? Can we improve the fraction of interpretable codes in larger models?
Our work also raises questions about how transformers language models can function given such an extreme bottleneck at every layer. This implies their computation may be sparse and discrete in understandable ways given the right architecture and training setup. We expect further optimizations to improve performance—and perhaps even sparsity—even further.
In summary, by constraining neural networks to use sparse, discrete hidden states, codebook features enable improved interpretability and control of neural networks. This refactoring of neural network internals provides a potential path toward safer and more reliable machine learning systems.
Read the paper here: https://arxiv.org/abs/2310.17230
Browse examples here: https://huggingface.co/spaces/taufeeque/codebook-features
And view our codebase and tutorials here: https://github.com/taufeeque9/codebook-features
BibTeX Citation
@misc{tamkin2023codebookfeatures,
title={Codebook Features: Sparse and Discrete Interpretability for Neural Networks},
author={Alex Tamkin and Mohammad Taufeeque and Noah D. Goodman},
year={2023},
eprint={2310.17230},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
-
Gray, Robert. “Vector quantization.” IEEE Assp Magazine 1.2 (1984): 4-29. ↩
-
Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017). ↩
-
Tamkin, Alex, et al. “DABS: A domain-agnostic benchmark for self-supervised learning.” arXiv preprint arXiv:2111.12062 (2021). ↩
-
Tamkin, Alex, et al. “DABS 2.0: Improved datasets and algorithms for universal self-supervision.” Advances in Neural Information Processing Systems 35 (2022): 38358-38372. ↩
-
Elhage, Nelson, et al. “A mathematical framework for transformer circuits.” Transformer Circuits Thread 1 (2021). ↩