![]()
The Computer Vision and Pattern Recognition Conference (CVPR) 2023 is being hosted in Vancouver, Canada on June 18th - 22th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Finetune like you pretrain: Improved finetuning of zero-shot vision models
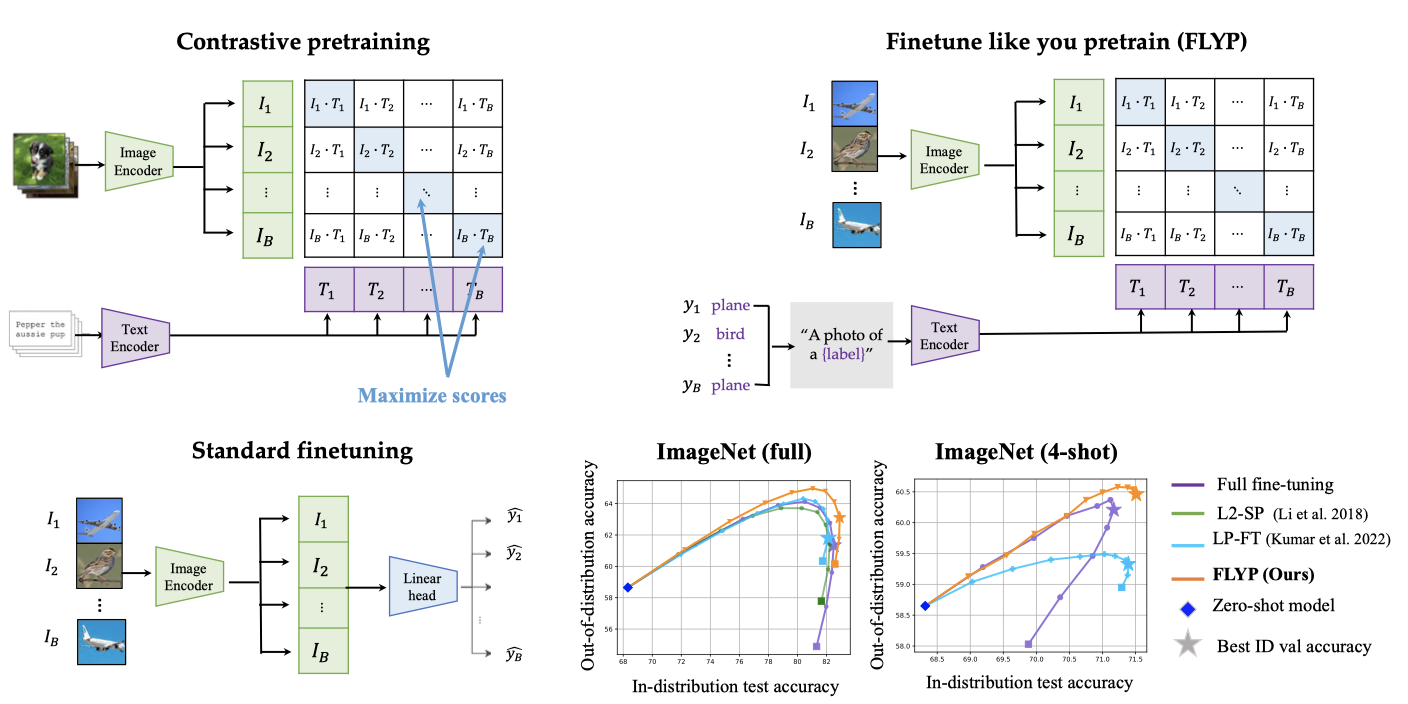
Contact: sachingo@andrew.cmu.edu
Keywords: robust fine-tuning, multimodal, robustness, clip, transfer learning
Multi-Object Manipulation via Object-Centric Neural Scattering Functions

Contact: tians@stanford.edu
Links: | Video | Website
Keywords: dynamics models, neural rendering, robotic manipulation
Accidental Light Probes

Contact: koven@cs.stanford.edu
Links: Paper | Video | Website
Keywords: inverse rendering, lighting estimation
CARTO: Category and Joint Agnostic Reconstruction of ARTiculated Objects

Contact: heppert@cs.uni-freiburg.de
Links: Paper | Video | Website
Keywords: single-shot 3d reconstruction, articulated objects
CIRCLE: Capture in Rich Contextual Environments

Contact: jparaujo@stanford.edu
Links: Paper | Website
Keywords: motion capture, motion generation, virtual reality, egocentric video
EDGE: Editable Dance Generation from Music

Contact: jtseng20@stanford.edu
Links: Paper | Website
Keywords: motion, diffusion, music, dance, editing
EFEM: Equivariant Neural Field Expectation Maximization for 3D Object Segmentation Without Scene Supervision
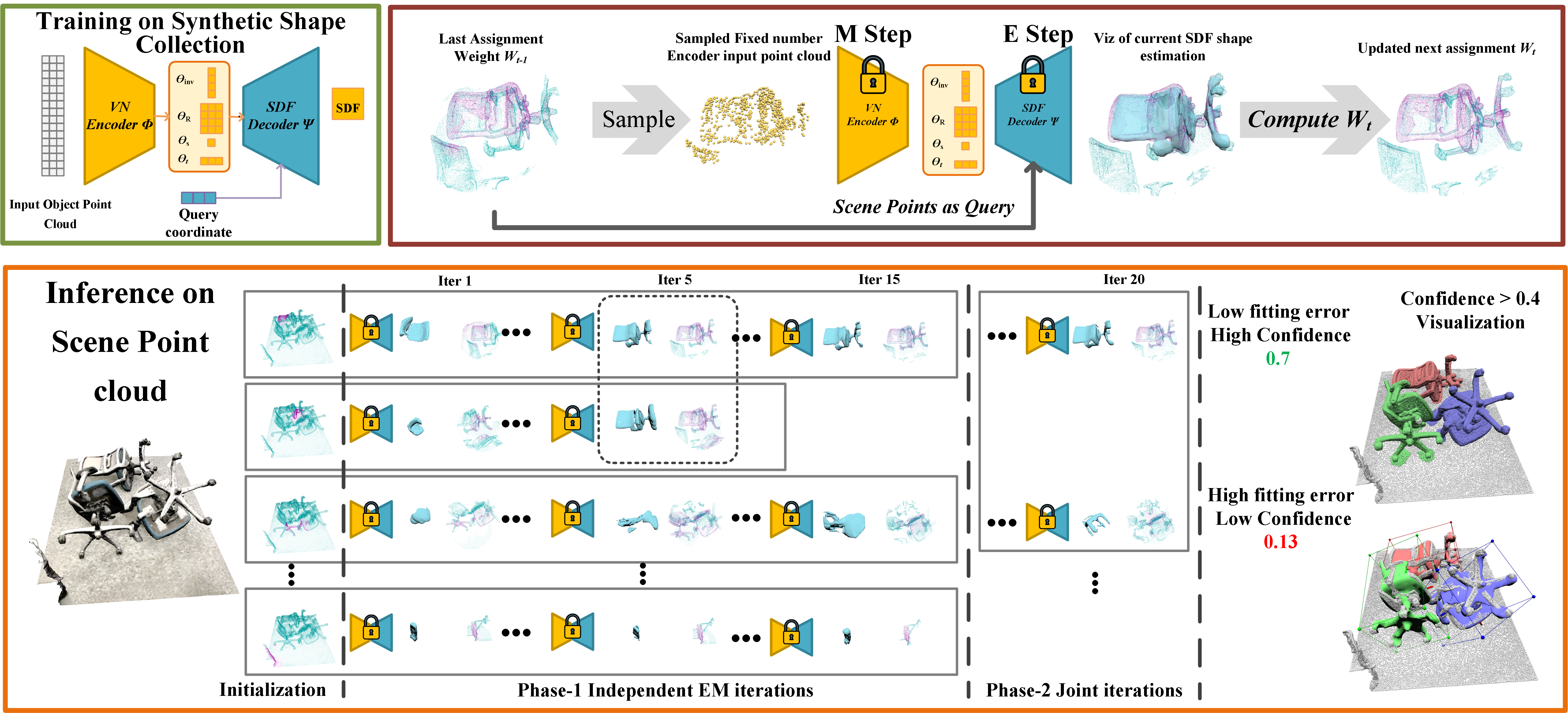
Contact: leijh@cis.upenn.edu
Links: Paper | Video | Website
Keywords: pointcloud segmentation, equivariance, weakly-supervised learning
Ego-Body Pose Estimation via Ego-Head Pose Estimation
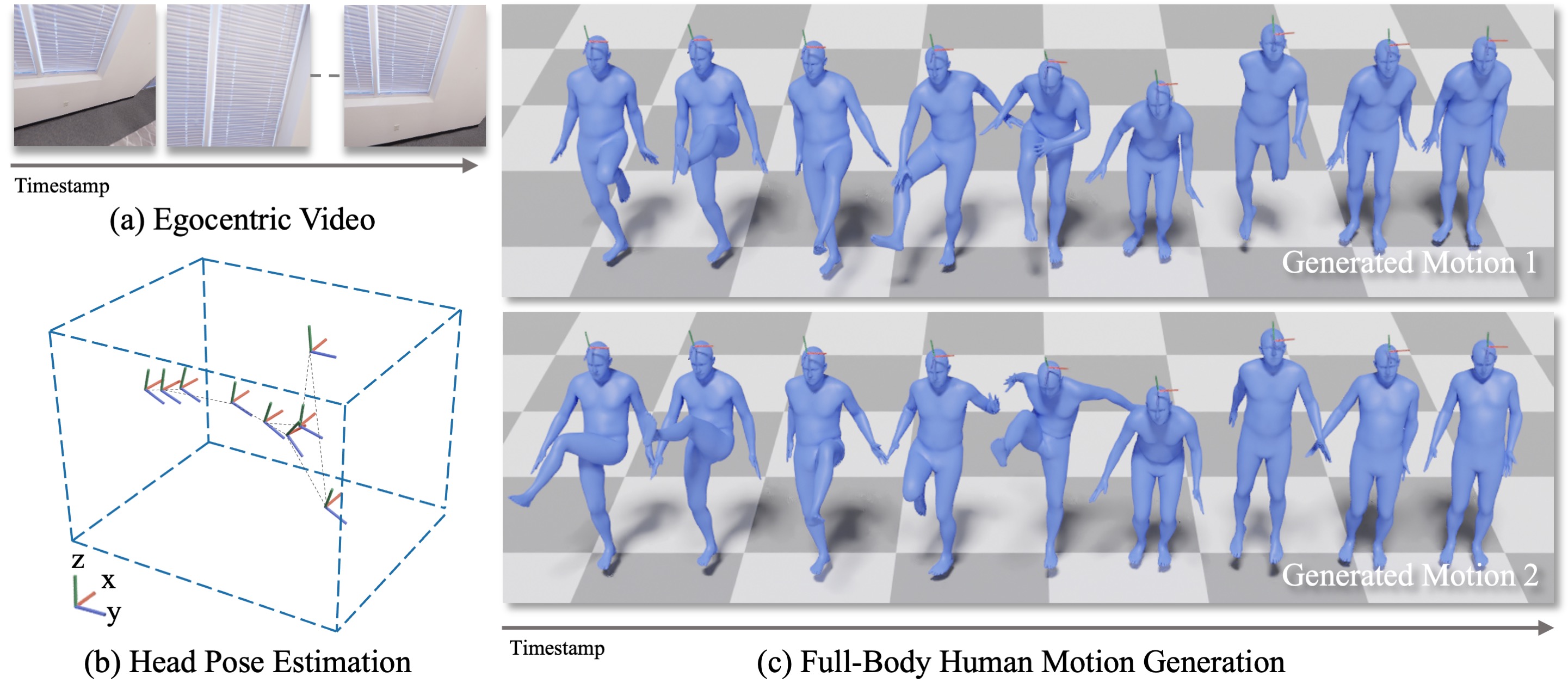
Contact: jiamanli@stanford.edu
Award nominations: Award Candidates
Links: Paper | Video | Website
Keywords: egocentric video, human motion estimation, decomposition, conditional diffusion
GINA-3D: Learning to Generate Implicit Neural Assets in the Wild

Contact: willshen@stanford.edu
Links: Paper | Video | Website
Keywords: generative ai, autonomous driving, generative 3d, simulation assets
NS3D: Neuro-Symbolic Grounding of 3D Objects and Relations
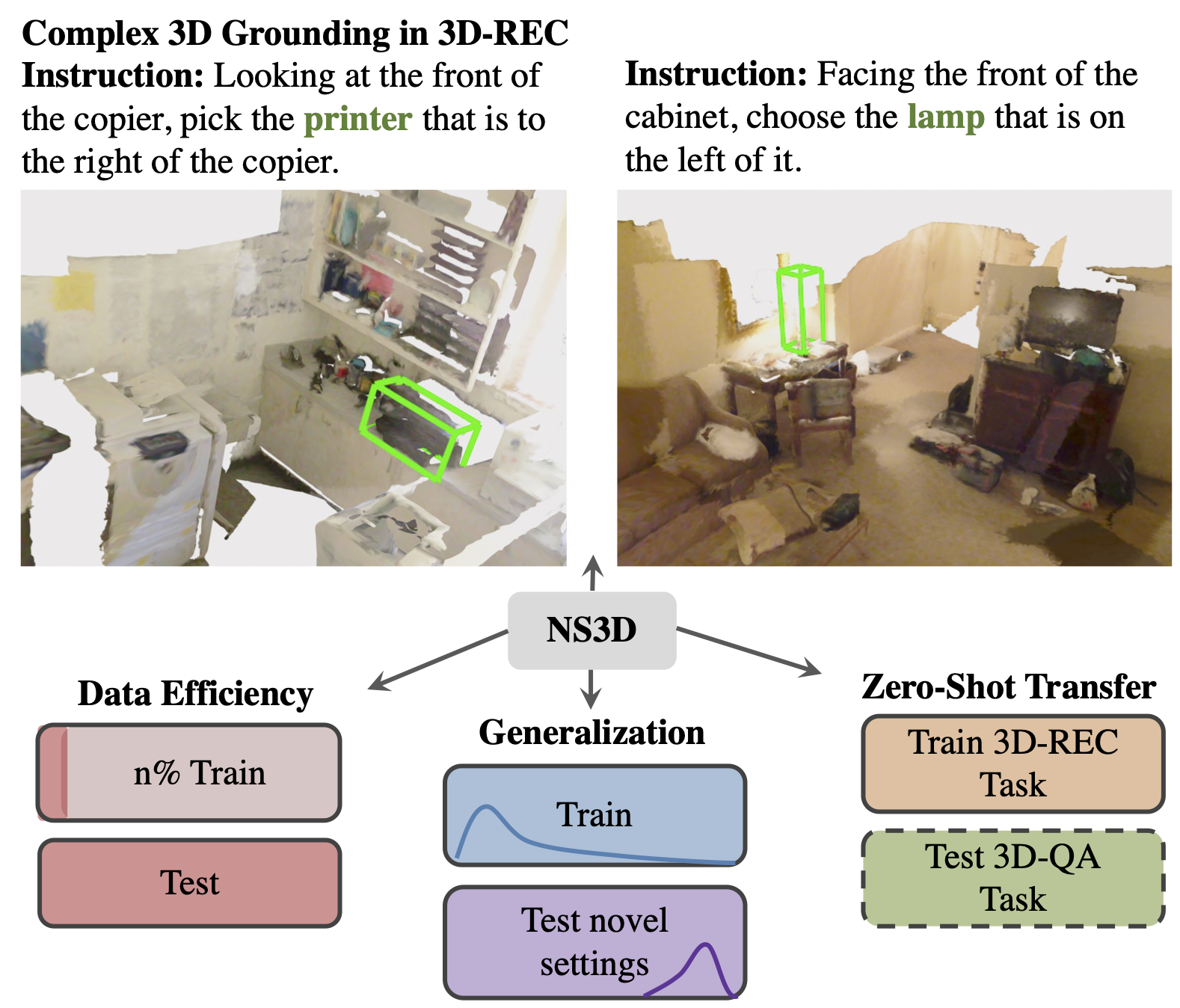
Contact: joycj@stanford.edu
Links: Paper | Website
Keywords: neuro-symbolic learning, visual reasoning, 3d grounding
NeMo: 3D Neural Motion Fields from Multiple Video Instances of the Same Action

Contact: wangkua1@stanford.edu
Links: Paper | Video | Website
Keywords: human mesh recovery, human motion, 3d vision, neural field
NeRDi: Single-View NeRF Synthesis With Language-Guided Diffusion As General Image Priors
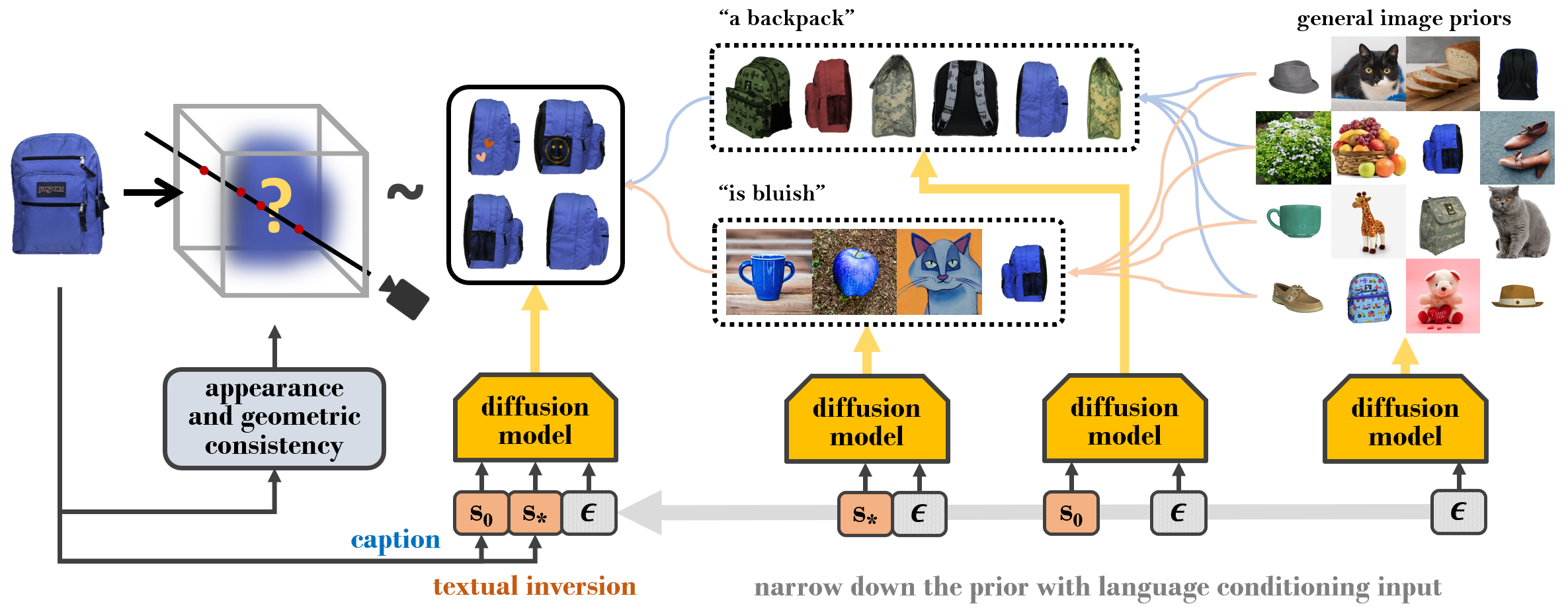
Contact: congyue@stanford.edu
Links: Paper | Video | Website
Keywords: nerf, diffusion model, single view to 3d
PROB: Probabilistic Objectness for Open World Object Detection
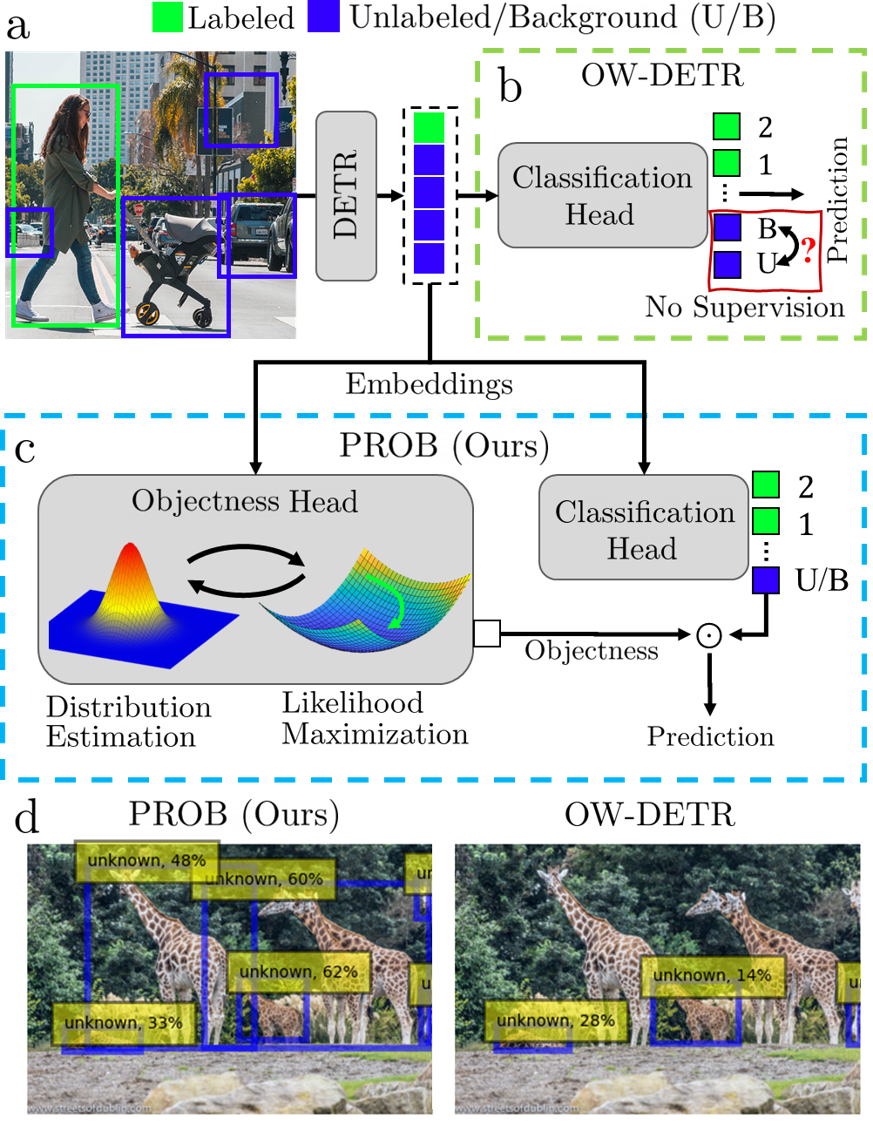
Contact: orrzohar@stanford.edu
Links: Paper | Video | Website
Keywords: open world learning, open world object detection, object detection, class-agnostic object detection, object detection,
Partial-View Object View Synthesis via Filtering Inversion
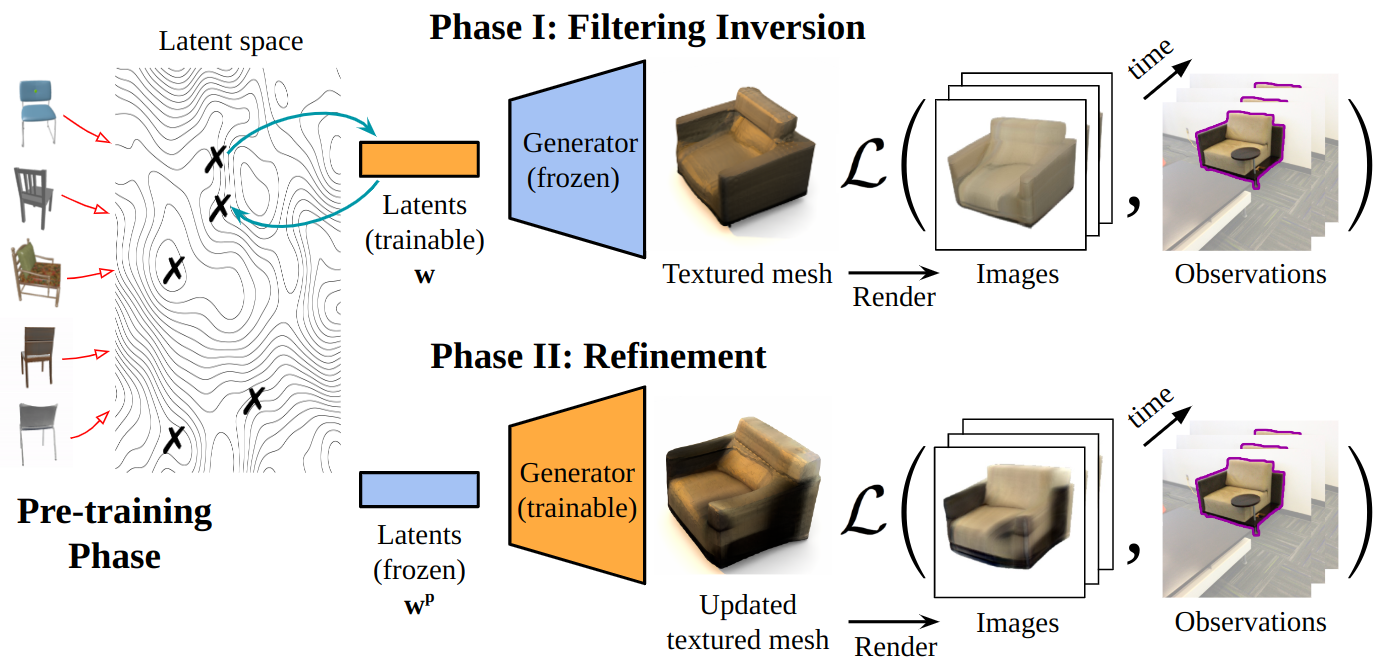
Contact: fanyun@stanford.edu
Links: Paper | Website
Keywords: view synthesis, partial-view, filtering inversion, gan
Putting People in Their Place: Affordance-Aware Human Insertion into Scenes

Contact: sumith@stanford.edu
Links: Paper | Website
Keywords: affordances, self-supervision, image synthesis, editing
RealImpact: A Dataset of Impact Sound Fields for Real Objects
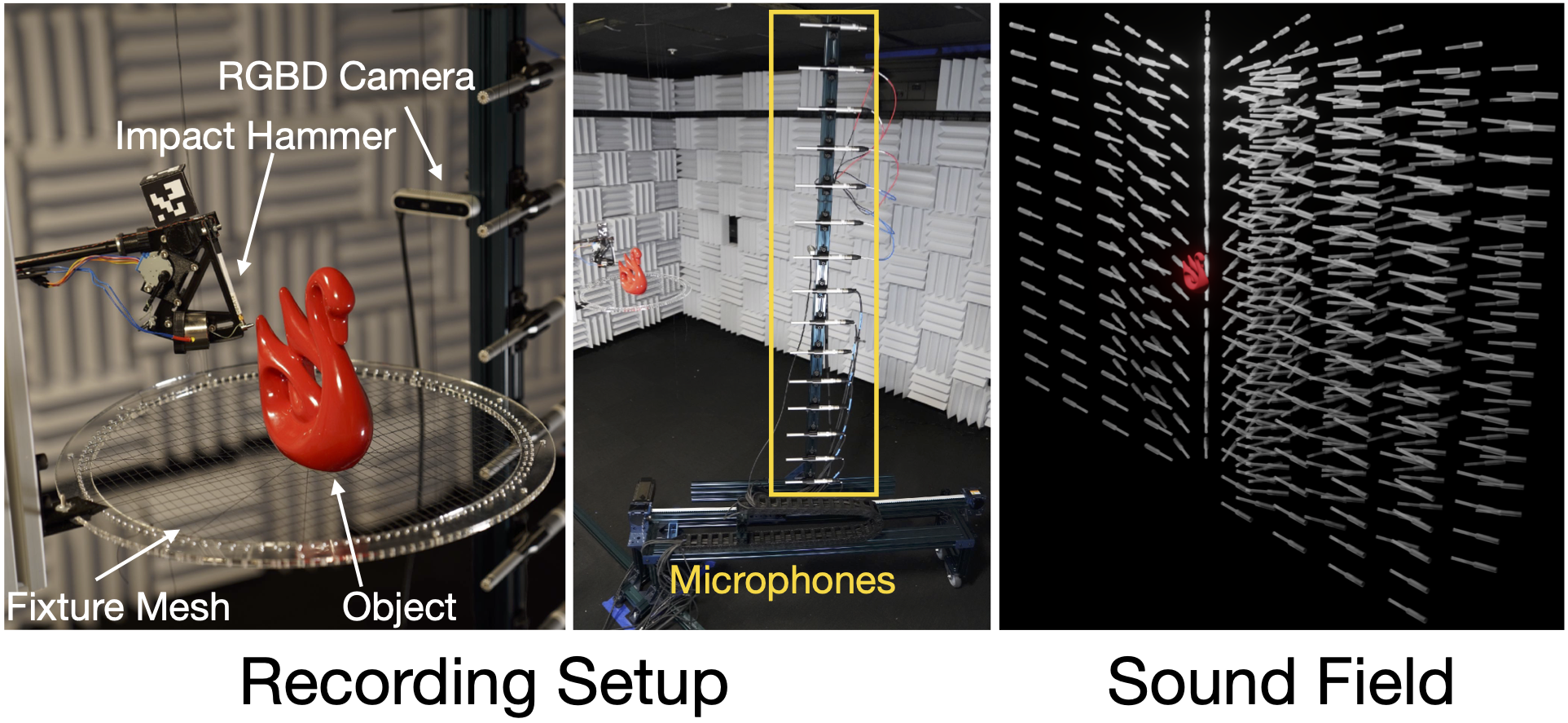
Contact: spclarke@stanford.edu
Award nominations: Highlight
Links: Paper | Video | Website
Keywords: audio processing, acoustic learning, multimodal data, sound
SCADE: NeRFs from Space Carving with Ambiguity-Aware Depth Estimates
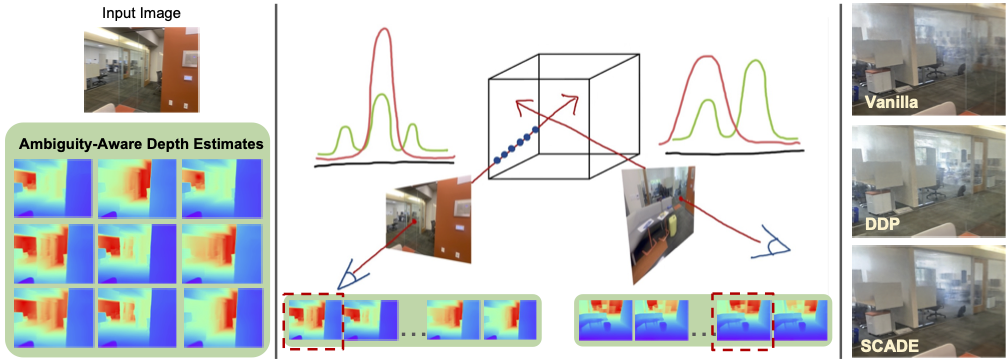
Contact: mikacuy@stanford.edu
Links: Paper | Video | Website
Keywords: nerfs, sparse view, monocular depth, cimle, distribution, ambiguity
Seeing a Rose in Five Thousand Ways

Contact: yzzhang@stanford.edu
Links: Paper | Video | Website
Keywords: generative modelling, inverse rendering, gan, image generation, 3d reconstruction
The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects
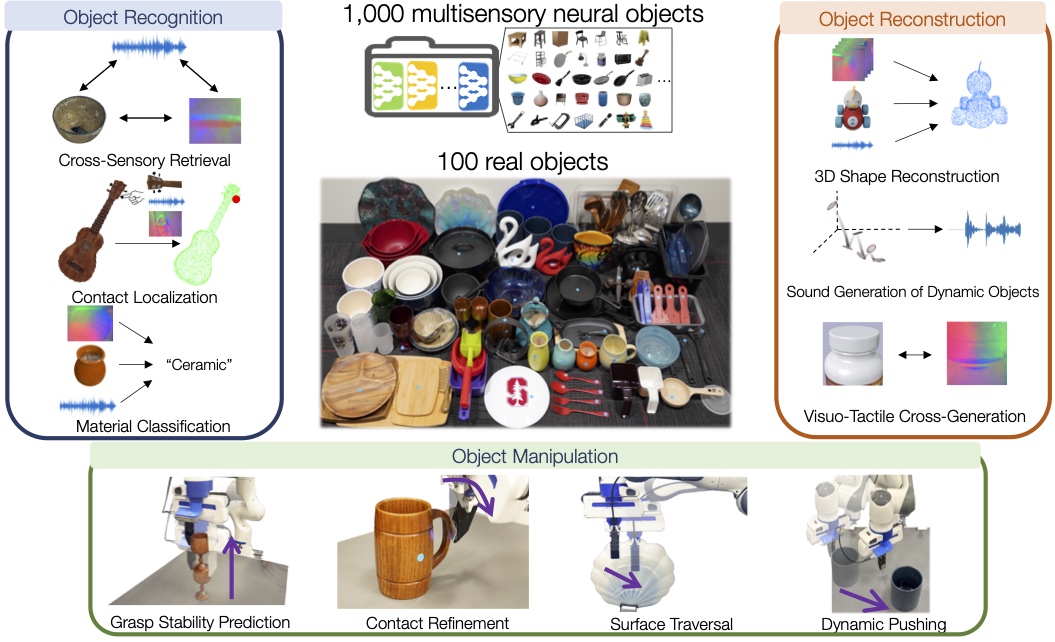
Contact: rhgao@cs.stanford.edu
Links: Paper | Video | Website
Keywords: multisensory, benchmark, object-centric learning
We look forward to seeing you at CVPR!