![]()
The Conference on Computer Vision and Pattern Recognition (CVPR) 2026 is being hosted in Denver, Colorado from June 3 - 7. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
BAgger: Backwards Aggregation for Mitigating Drift in Autoregressive Video Diffusion Models
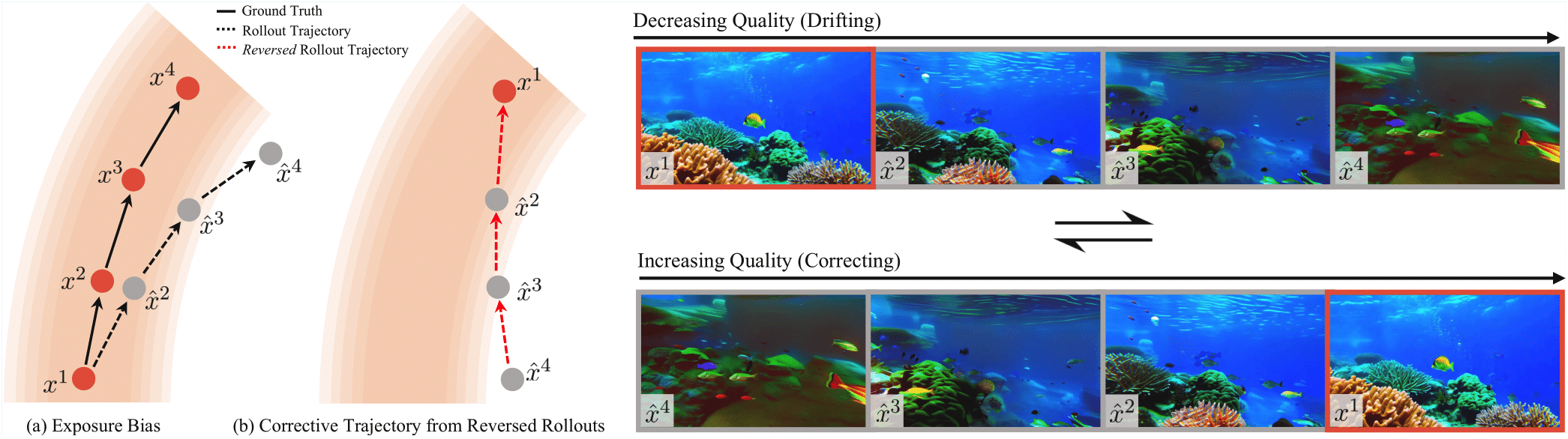
Contact: gordonwz@stanford.edu
Links: Paper | Website
Keywords: autoregressive video generation, exposure bias, diffusion transformers, backwards aggregation
BulletTime: Decoupled Control of Time and Camera Pose for Video Generation

Contact: gordonwz@stanford.edu
Links: Paper | Website
Keywords: controllable video generation, video diffusion models, camera trajectory control, 4d video synthesis
Choreographing a World of Dynamic Objects
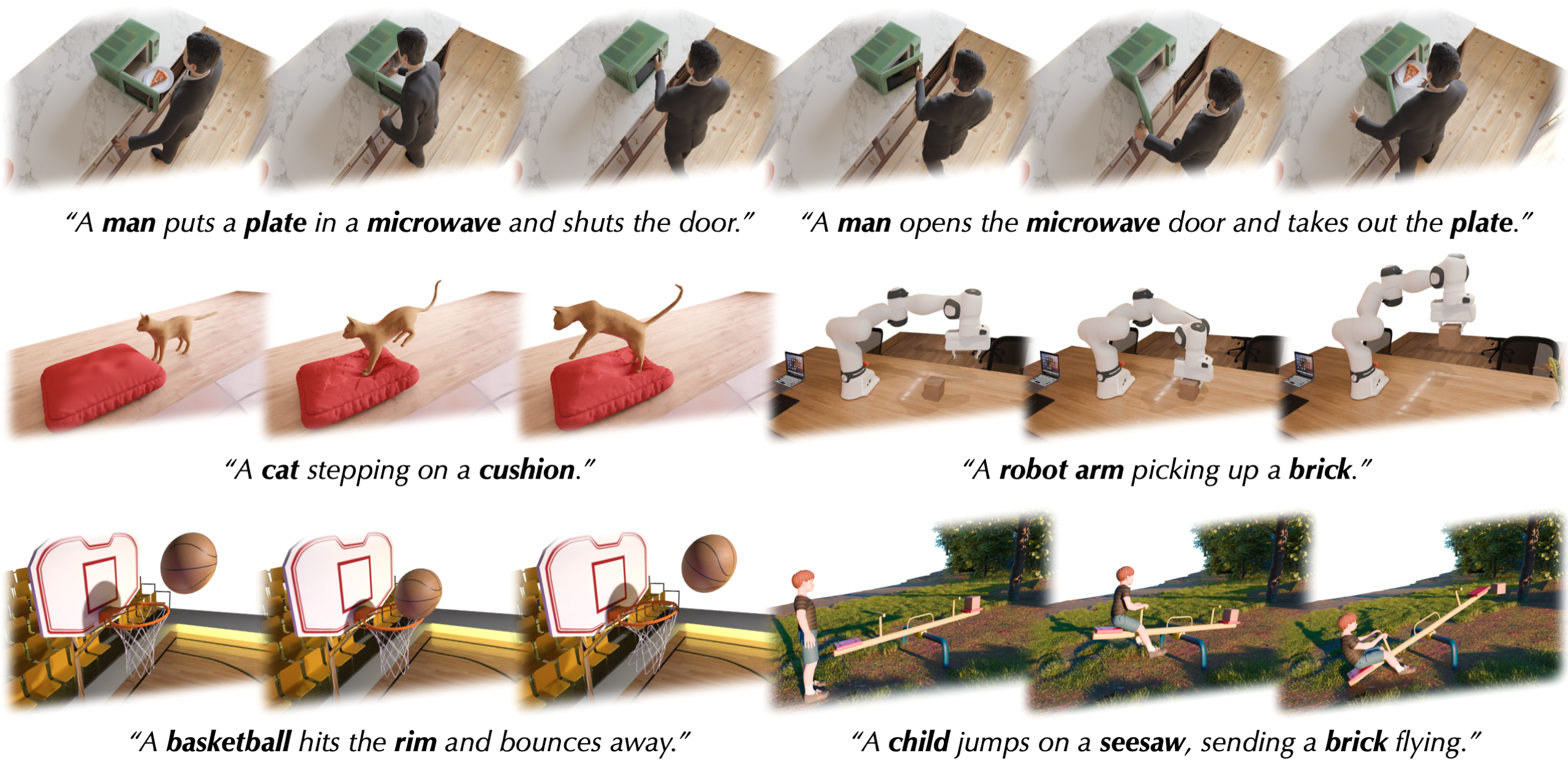
Contact: yanzhel@stanford.edu
Links: Paper | Website
Keywords: 4d generation, diffusion models, score distillation sampling, motion generation
Downscaling Intelligence: Exploring Perception and Reasoning Bottlenecks in Small Multimodal Models

Contact: markendo@stanford.edu
Links: Paper | Website
Keywords: small multimodal models, perception, reasoning
Dual Ascent Diffusion for Inverse Problems
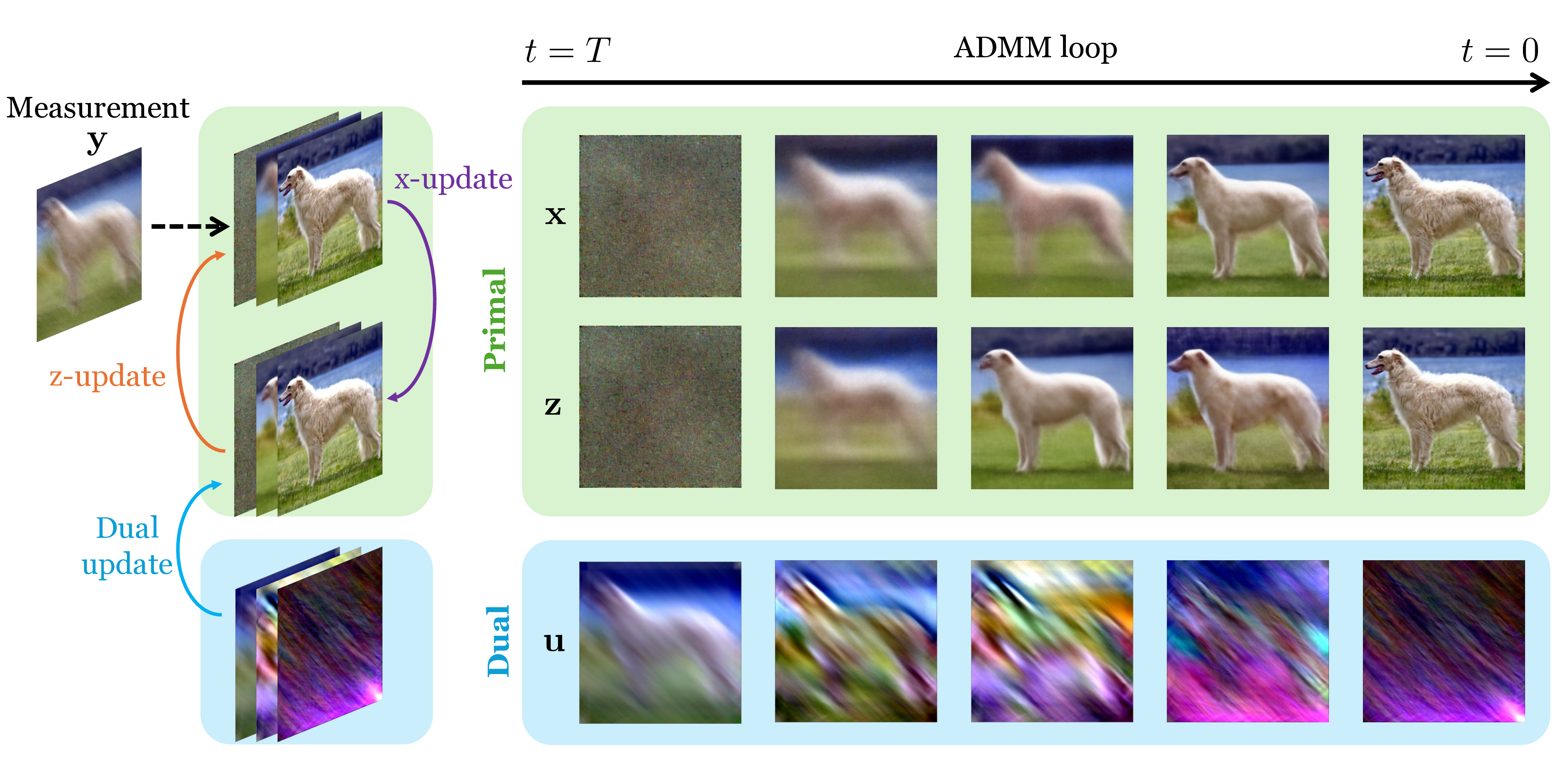
Contact: gordonwz@stanford.edu
Links: Paper | Video | Website
Keywords: inverse problems, diffusion priors, constrained optimization, image restoration
Ego-Pi: VLA Fine-Tuning for Ego-Centric Human and Robot Data
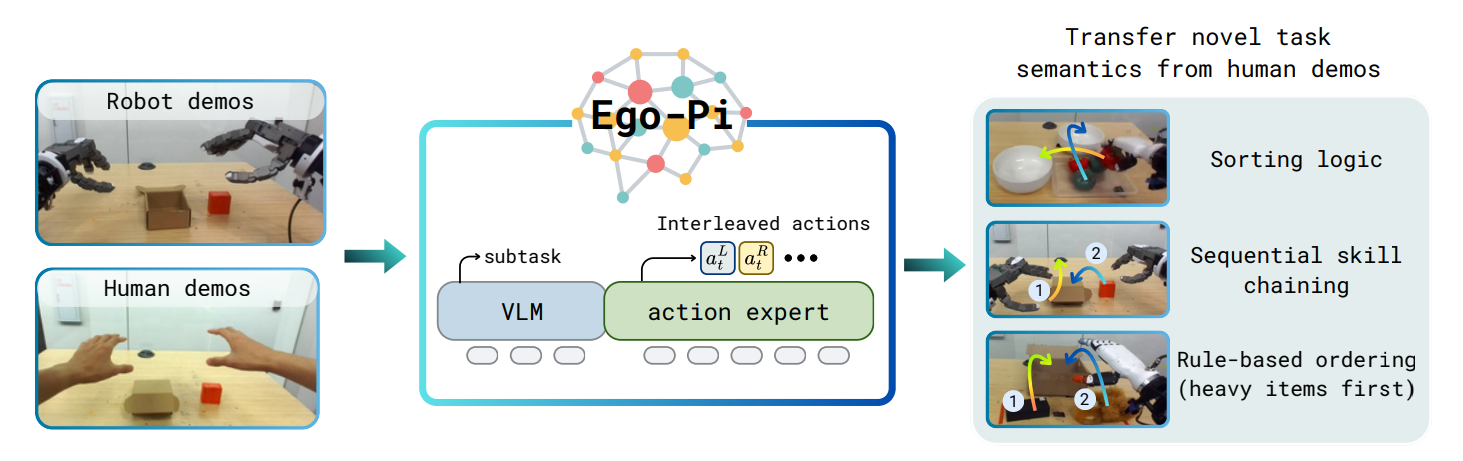
Contact: jwbkim@stanford.edu
Links: Paper | Video | Website
Keywords: humanoid robots, robot learning, vla, human data
GaussFusion: Improving 3D Reconstruction in the Wild with Geometry-Informed Video Generator
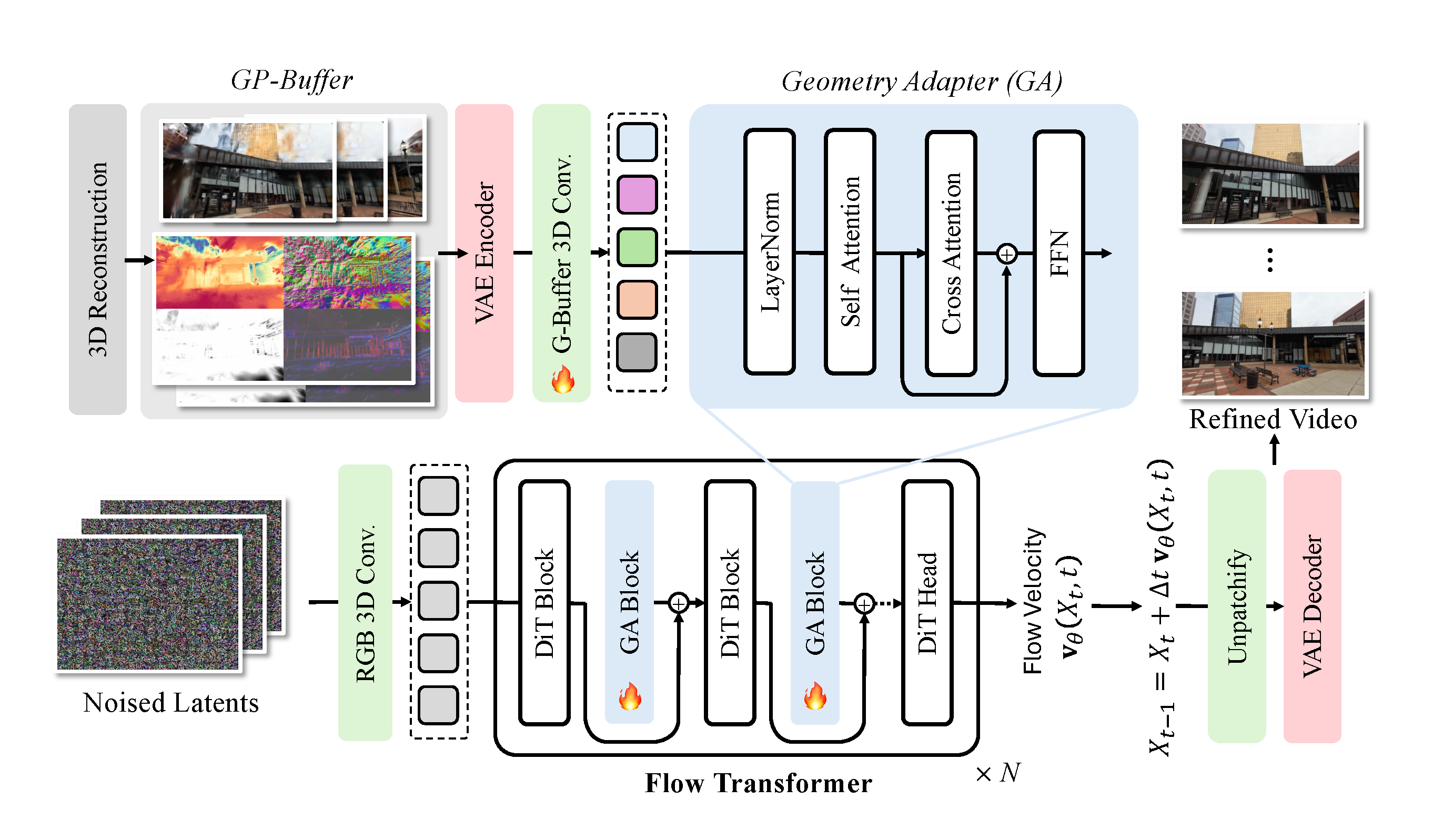
Contact: gordonwz@stanford.edu
Links: Paper | Website
Keywords: 3d gaussian splatting, novel view synthesis, geometry-guided video generation, neural rendering
Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
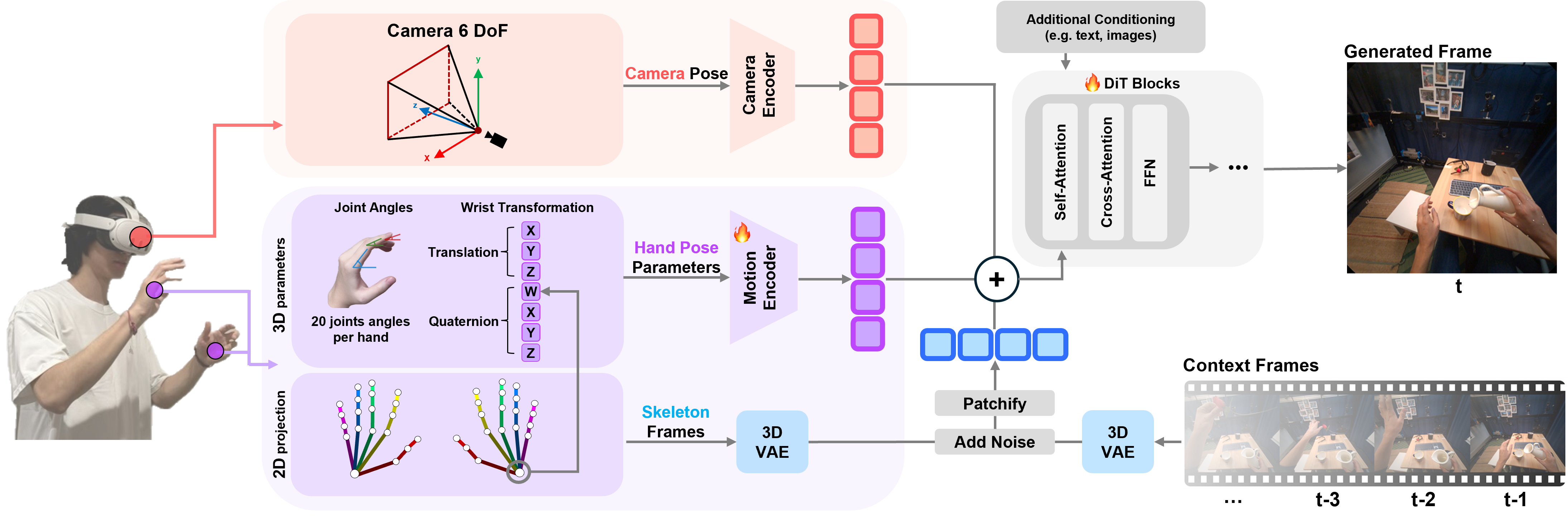
Contact: gordonwz@stanford.edu
Workshop: Findings
Links: Paper | Website
Keywords: video world models, interactive video generation, hand pose control, embodied ai
GeoSAE: Geometric Prior-Guided Layer-Wise Sparse Autoencoder Annotation of Brain MRI Foundation Models
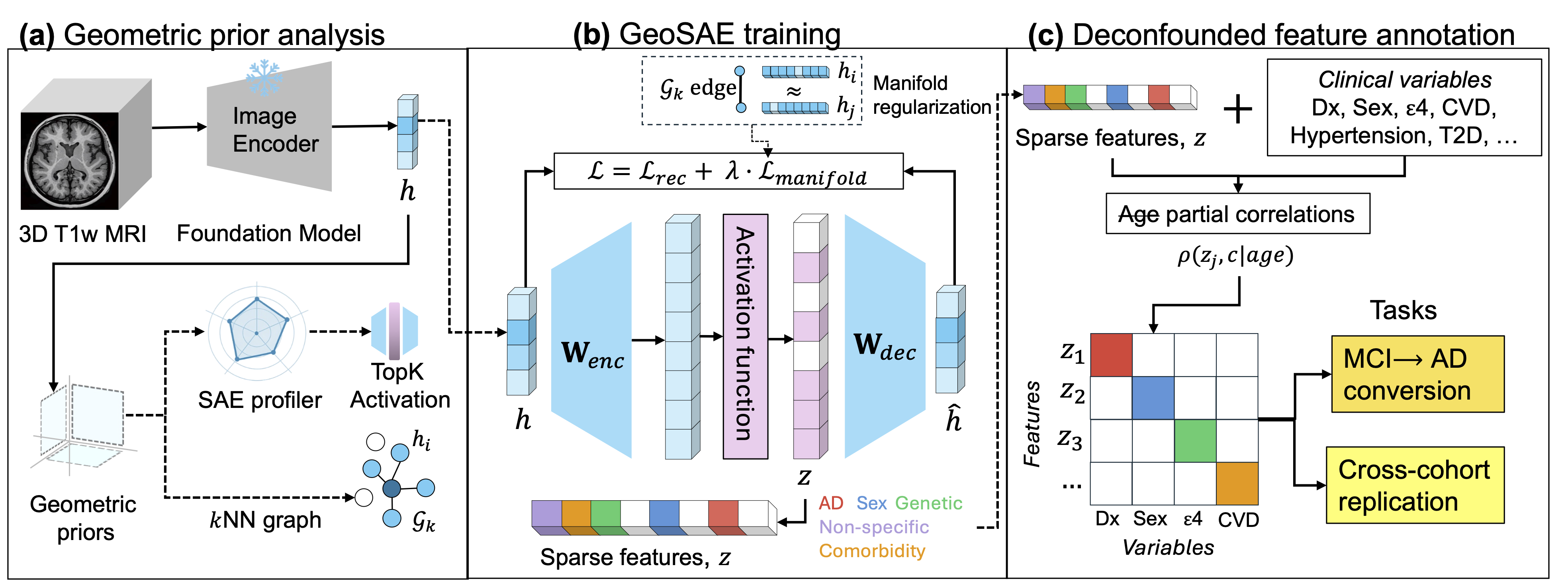
Contact: fnerrise@stanford.edu
Workshop: CV4Clinic (Computer Vision for Real-world Clinical Translation) 2026
Links: Paper | Website
Keywords: brain mri foundation models; sparse autoencoders; mechanistic interpretability; biomarker discovery; alzheimer’s disease
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations

Contact: xuxm@stanford.edu
Workshop: Embodied AI Workshop
Links: Paper | Video | Website
Keywords: mobile manipulation, learning from human demonstrations, imitation learning
Physical Object Understanding with a Physically Controllable World Model
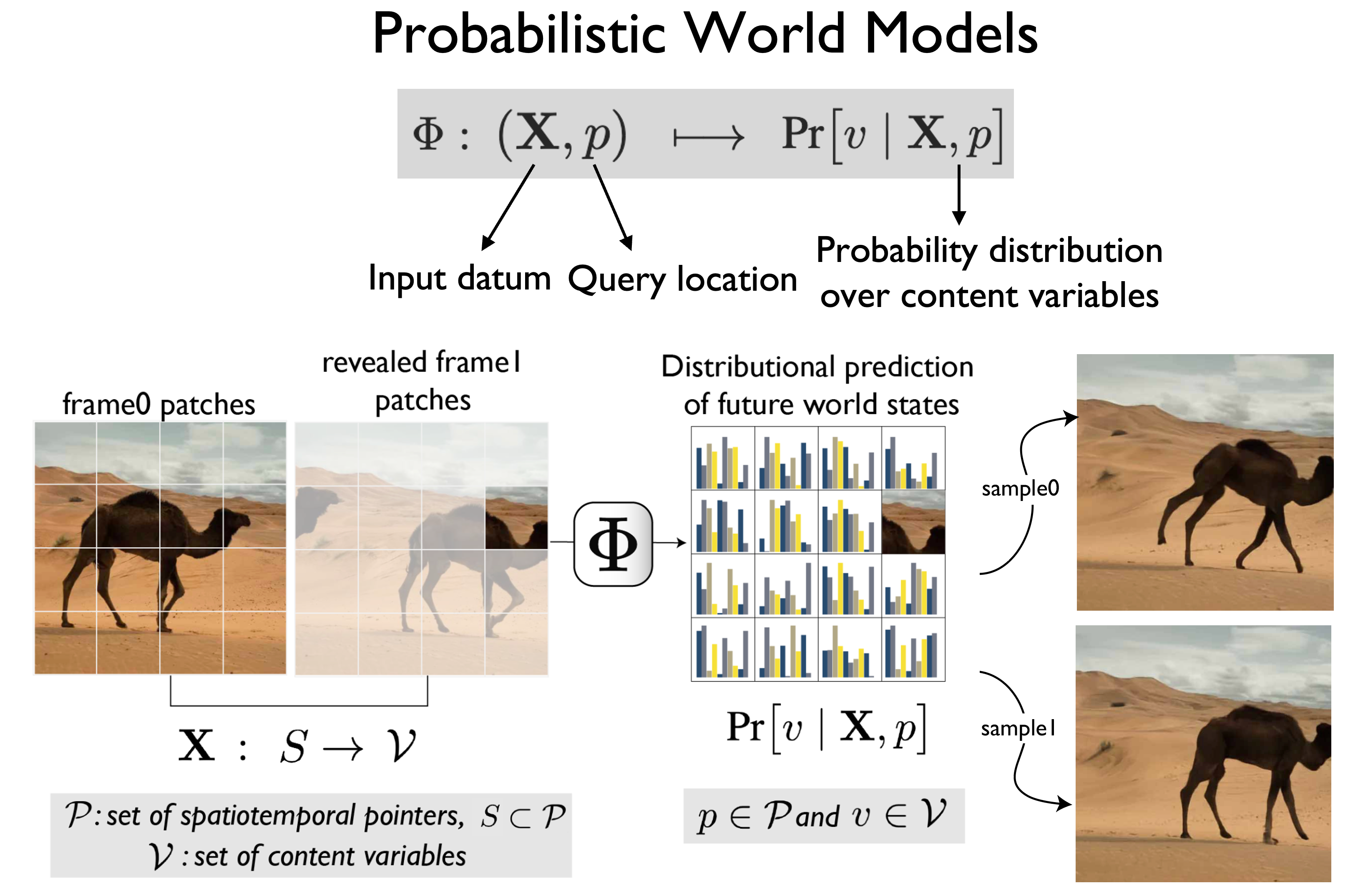
Contact: rmvenkat@stanford.edu
Award nominations: Highlight
Links: Paper | Blog Post | Video | Website
Keywords: visual world models, object understanding, physical control
Spherical Leech Quantization for Visual Tokenization and Generation
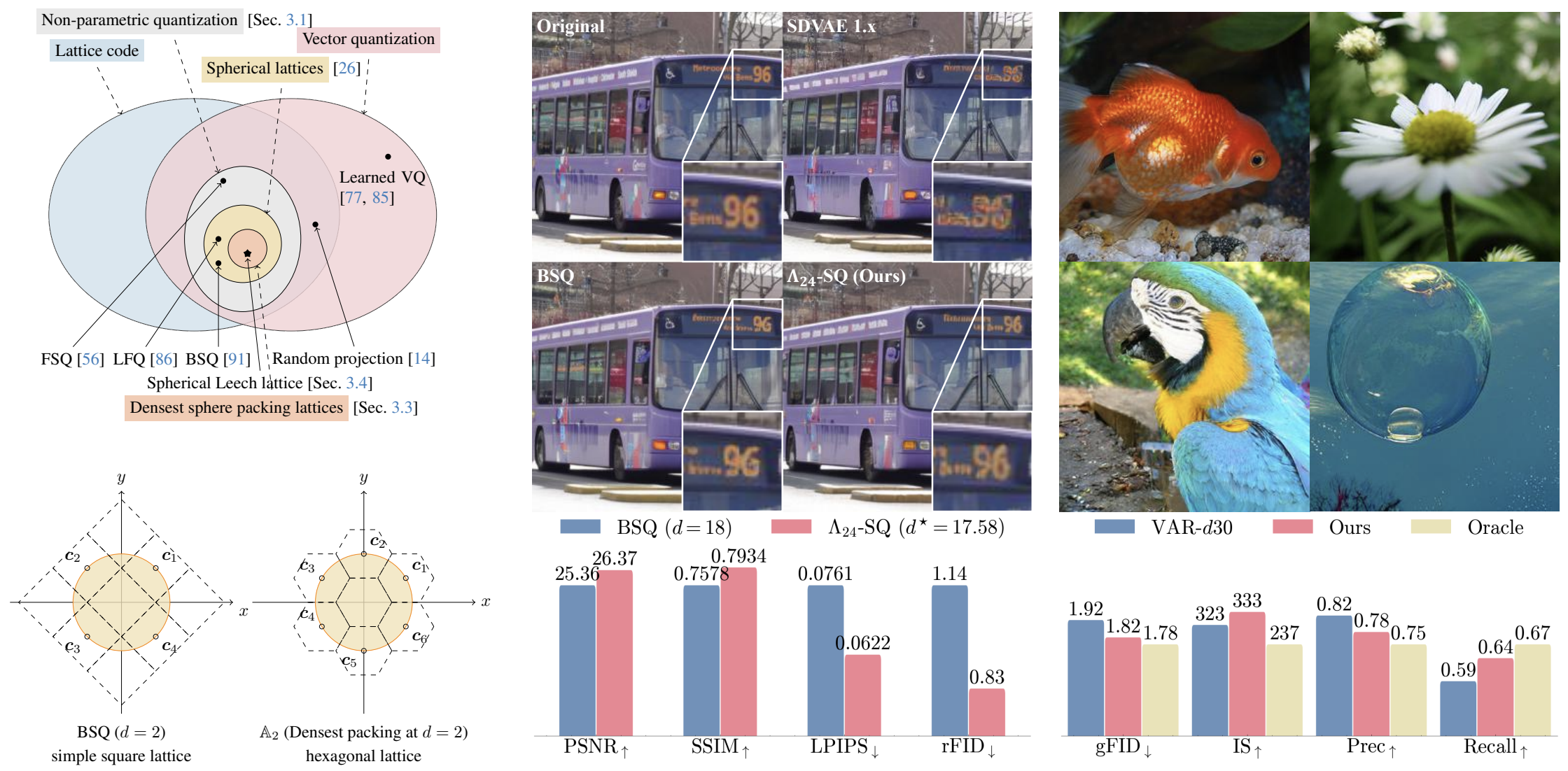
Contact: yzz@stanford.edu
Award nominations: Highlight
Links: Paper | Blog Post | Website
Keywords: quantization, tokenization, compression, generation
Scaling Verification Can Be More Effective than Scaling Policy Learning for Vision-Language-Action Alignment

Contact: jackykwok@stanford.edu
Workshop: CVPR 2026 Scalable Robot Learning Systems Workshop
Award nominations: Best Paper Finalist
Links: Paper | Website
Keywords: vision-language-action models, test-time scaling, contrastive learning, visuomotor control
Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation
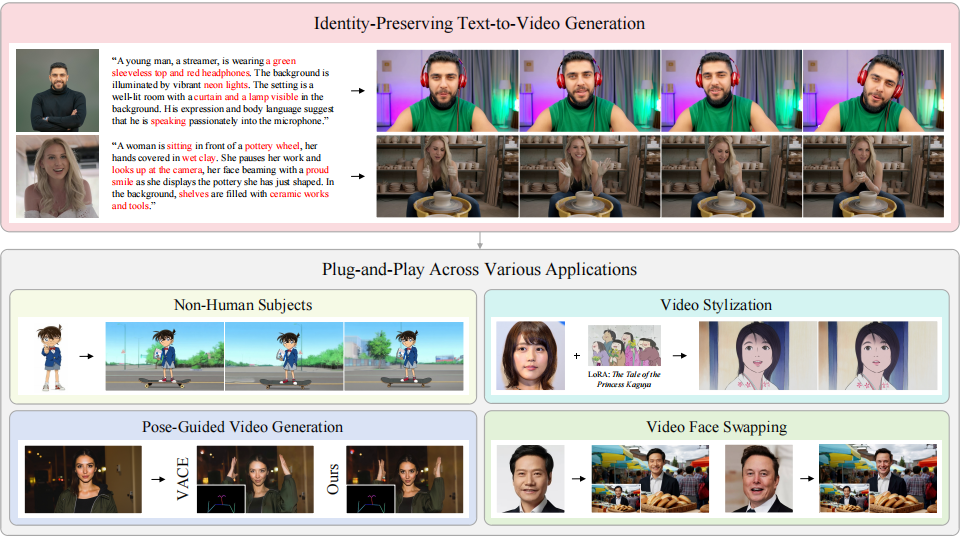
Contact: bowenxue@stanford.edu
Links: Paper | Video | Website
Keywords: video generation, identity control
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?

Contact: PingyueZhang2029@u.northwestern.edu
Links: Paper | Blog Post | Website
Keywords: large language mode, vision-language model, spatial reasoning, spatial agent, active exploration
VULCAN: Tool-Augmented Multi Agents for Iterative 3D Object Arrangement
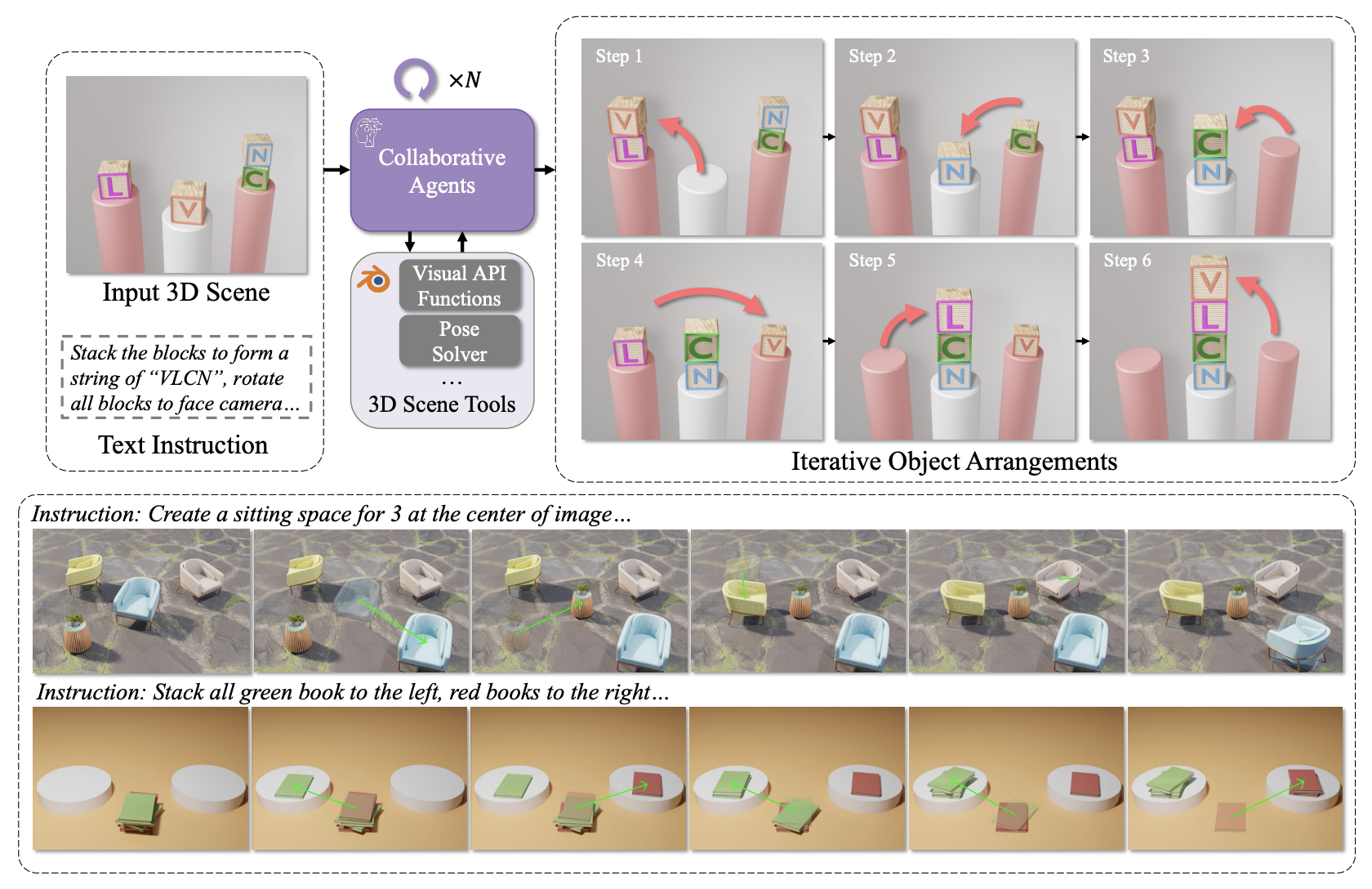
Contact: gordonwz@stanford.edu
Links: Paper | Website
Keywords: 3d scene understanding, multi-agent systems, spatial reasoning, embodied ai
We look forward to seeing you at CVPR!