“Simple justice requires that public funds, to which all taxpayers of all races contribute, not be spent in any fashion which encourages, entrenches, subsidizes or results in racial discrimination.”
John F. Kennedy, 1963
This blog post is the second of a series about discrimination in law and it explains one form of discrimination known as disparate impact (see first part about disparate treatment). It is based on CM-604 Theories of Discrimination (Title VII) and chapters 6 and 7 of TITLE VI Legal Manual. This blog post assists researchers in identifying and mitigating discriminatory models by providing a parallel between proving discrimination in law and proving discrimination in machine learning.
| Machine Learning Analogy | |
|---|---|
| For each section, we give a brief history of related efforts in machine learning in a green box like this one! |
| Main Point | |
|---|---|
| We write the main point for each section in a blue box like this one! |
 The U.S. Equal Employment Opportunity Commission (EEOC) is responsible for enforcing federal laws that make it illegal to discriminate against a job applicant or an employee because of the protected attributes. Most employers with at least 15 employees are covered by EEOC laws. EEOC charges around 90000 cases each year, of which around 15% result in monetary benefit for the charging party. ( ~300 million dollars per year). The processing time for each charge usually takes ten months.
The U.S. Equal Employment Opportunity Commission (EEOC) is responsible for enforcing federal laws that make it illegal to discriminate against a job applicant or an employee because of the protected attributes. Most employers with at least 15 employees are covered by EEOC laws. EEOC charges around 90000 cases each year, of which around 15% result in monetary benefit for the charging party. ( ~300 million dollars per year). The processing time for each charge usually takes ten months.
Table of Contents
- Protected Attributes
- Definition
- Legal Procedure
- Real Legal Cases
- Other Types of Discrimination
- Conclusion
Protected Attributes
Anti-discrimination laws are designed to prevent discrimination based on one of the following protected attributes:
- Race – Civil Rights Act of 1964
- Religion – Civil Rights Act of 1964
- National origin – Civil Rights Act of 1964
- Age (40 and over) – Age Discrimination in Employment Act of 1967
- Sex – Equal Pay Act of 1963 and Civil Rights Act of 1964
- Pregnancy – Pregnancy Discrimination Act
- Familial status – Civil Rights Act of 1968
- Disability status – Rehabilitation Act of 1973 and Americans with Disabilities Act of 1990
- Veteran status – Vietnam Era Veterans’ Readjustment Assistance Act of 1974 and Uniformed Services Employment and Reemployment Rights Act
- Genetic information – Genetic Information Nondiscrimination Act (GINA)
Definition
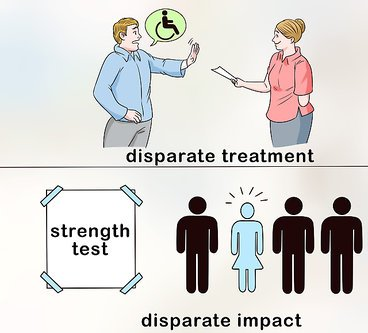
Disparate impact occurs when policies/practices that appear neutral result in a disproportionate impact on a protected group without any business necessity 2.
Business necessity is context dependent; for example, a university that hires professors can argue that having a Ph.D. for employment is necessary (although this requirement might cause a disproportionate impact for different races); however, the university cannot argue something like physical strength as a business necessity (which lead to disproportionate impact for different genders).
| Disparate Impact in Machine Learning |
|---|
| Consider pedestrian detection models used in autonomous cars. Assume that the model prediction appears neutral and performs the same for black and white pedestrians in any situation. If there are more reported accidents with black pedestrians than the general population (e.g., the model performs poorly in black-dominated neighborhoods), and the developers cannot provide any business reason for this disparity then this can be considered as a disparate impact case. In contrast, if the model fails to recognize a black pedestrian in a specific situation but recognizes a white pedestrian in the same situation (same place, same outfit, same time of the day, etc.), this can be considered a disparate treatment case. |
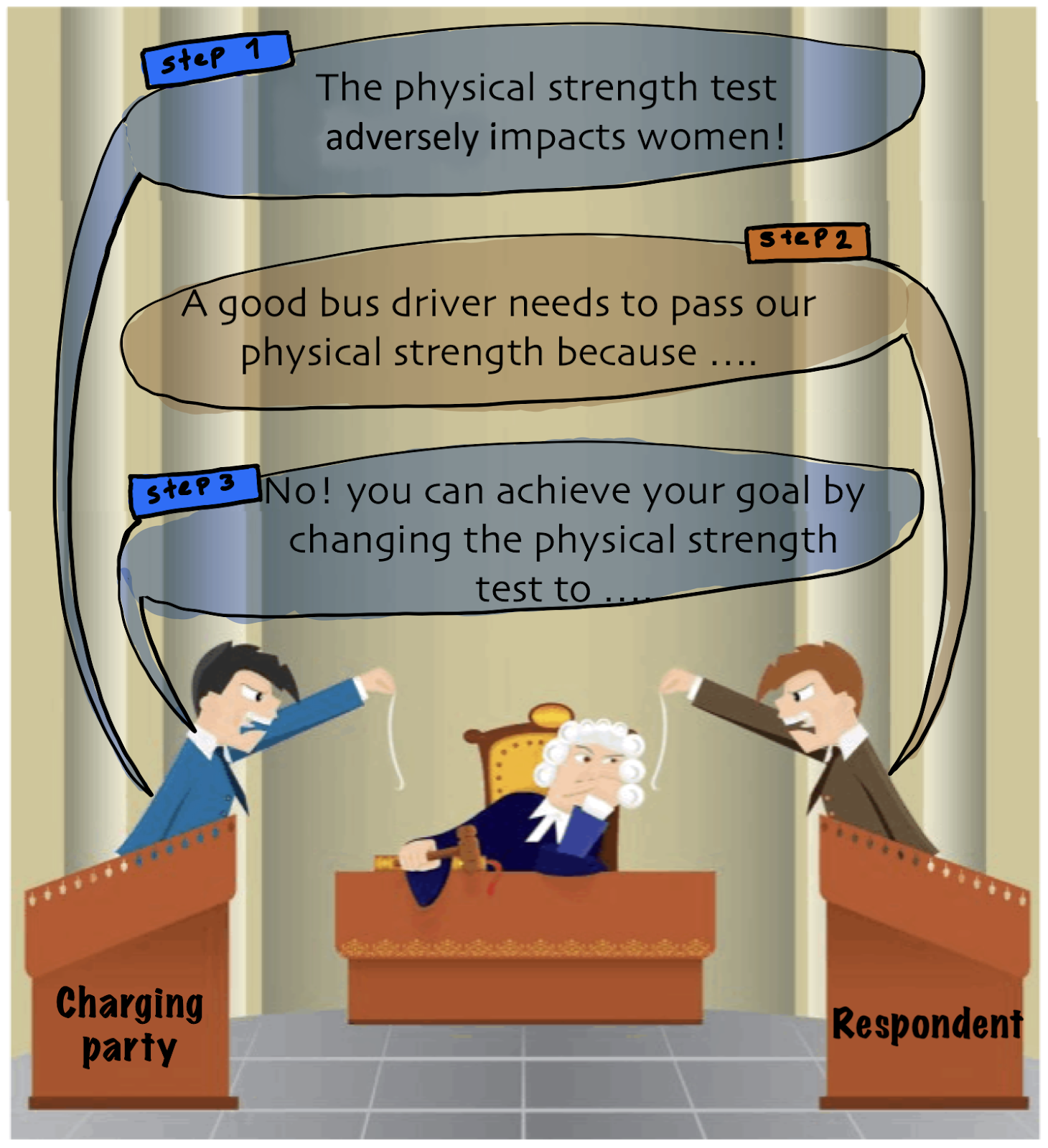
Legal Procedure
The legal procedure for proving disparate impact consists of three steps (figure below):
- The charging party (the party that believes it has suffered from disparate impact) needs to show that a specific practice caused people in a protected group to be treated worse than people not in the protected class.
- The respondent (the party that is accused of disparate impact, e.g., employer) attempts to show that it had a legitimate business reason for this specific practice.
- If the business reason is legitimate, the charging party can show that the respondent could have achieved the same business goal by a less discriminatory method.
In a disparate treatment case, the charging party must only prove that the correspondent is using the protected attribute for its decision. On the other hand, in the disparate impact case, in addition to proving that there is a disparate impact, the charging party needs to show that there is no business necessity for the policy or there is an alternative that leads to the same performance but less disparate impact.
Example3
A middle school has a “zero tolerance” tardiness policy. Late students must stay in the principal’s office for the rest of the class period regardless of their reason for tardiness.
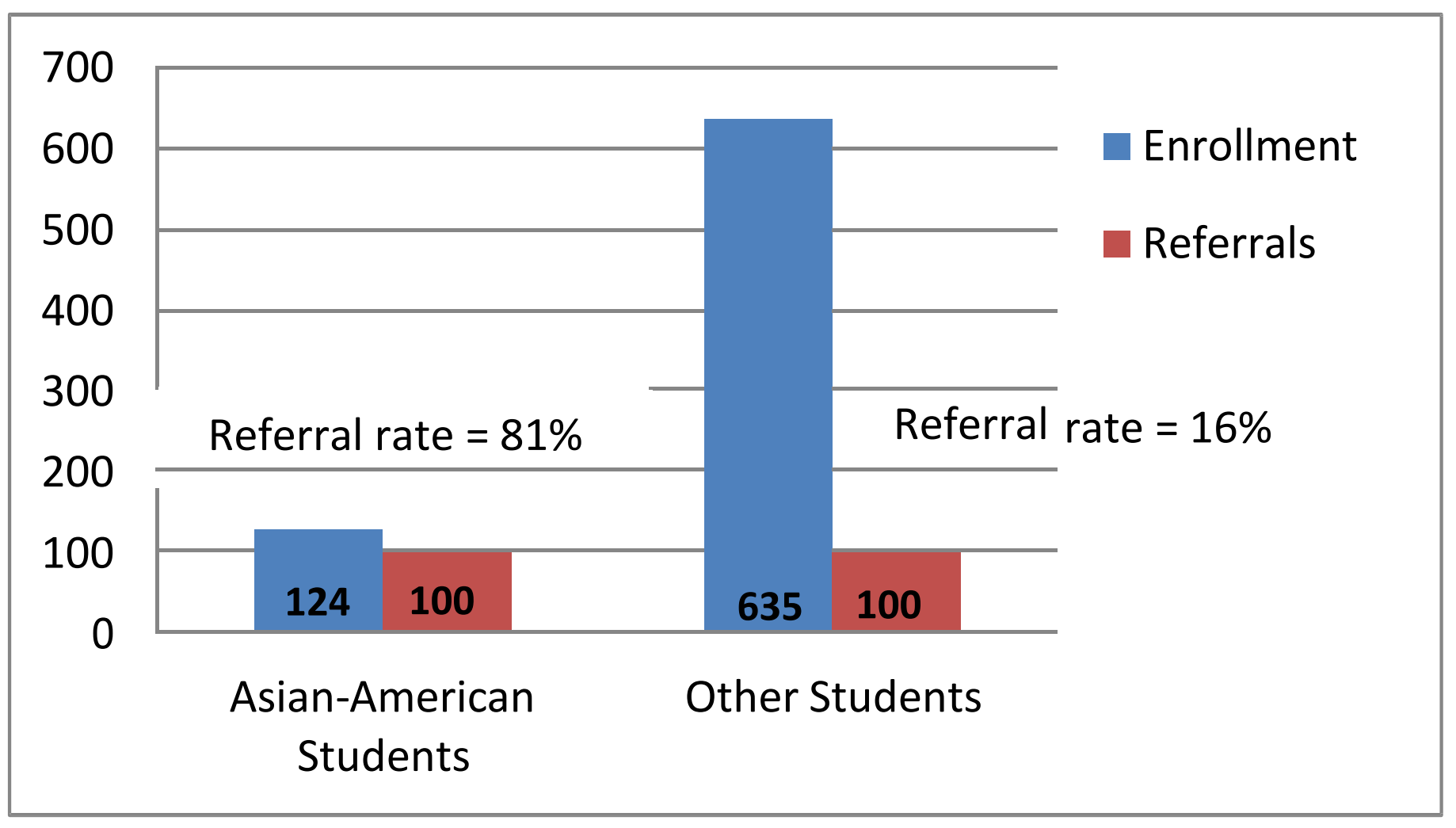
Step 1: Proof of disparate impact: The evidence shows that Asian-American students are disproportionately losing instruction time under the school’s “zero tolerance” tardiness policy. A further investigation reveals that whites and Hispanics are more likely to live within walking distance of the school, while Asian-American students typically live farther away and must take public transportation. Even if they take the first bus available in the morning, they are often dropped off after school starts.
Step 2: Justification: As justification for the “zero tolerance” tardiness policy, the school articulates the goals of reducing disruption caused by tardiness and encouraging good attendance, all of which the federal funding agency accepts as important educational goals.
Step 3: Assessment of justification and alternatives: The plaintiff first assesses the justification— including whether the policy is reasonably likely to reduce tardiness for these students under these circumstances. If the justification is valid, the plaintiff would then investigate alternatives that would achieve the important educational goals while reducing the adverse impact on Asian-American students (e.g., aligning class schedules and bus schedules). If such alternatives are present, the school is violating Title VI.
First Step: Charging Party Provides Proof of Disparate Impact
Proving disparate impact involves four substeps:
(a) Identifying the Facially Neutral Policy
As the first step, the charging party should Identify the policy or practice that allegedly caused disparate harm.
(b) Establishing Adversity/Harm
In the second step, the charging party should identify the kind of harm. Examples include fewer or inferior services or benefits, distribution of burdens and negative effects, threatened or imminent harm, etc.
(c) Establishing Disparity
In the third step, the charging party should show that a disproportionate share of the adversity/harm is on protected groups. For doing so, they first need to define the correct population base (individuals affected by the policy or who may be affected by changes to or elimination of the policy). Secondly, they should determine that the disparity is large enough to matter (i.e., is it sufficiently significant to establish a legal violation)4.
(d) Establishing Causation
In the last step, the charging party should show that the policy actually caused that effect. A disparate impact claim is not valid if the evidence shows that even without the challenged practice, the same disparate impact would have existed. In particular, the Supreme Court has emphasized that entities should not be “held liable for racial disparities they did not create.”5
| Machine Learning Analogy for Step 1: Proof of Disparate Impact |
|---|
| We now briefly explain efforts in ML for each step: |
| Identifying the policy: ML researchers usually investigate a specific ML application (e.g., a face recognition model). However, there are tasks where model predictions do not deterministically define the final decisions. For example, in risk assessment methods in criminal justice, the model’s scores are shown to the judges to decide, thus it is not clear how it changes the judge’s decision 6. It is important to pinpoint the exact policy for investigation. |
| Defining harm: There have been many proposals to define the harms of ML models (e.g., false-positive parity 7, demographic parity 8, parity in amount of actions that need to be done to flip the decision 9). |
| Establishing disparity: ML researchers usually assume they have access to the protected attributes.10 It is important to note that disparate impact (unlike disparate treatment) is very sensitive to the distribution of protected groups. The same policy could have significant disparate impact in one location but not another! Therefore, exactly understanding who is impacted by the model’s decision is crucial for this step. |
| Establishing causation: As explained in step 1, it is a common practice to only investigate an ML model in isolation. In this case, model prediction is a causal outcome of the model itself! However, we should be careful when we study a process that is caused by interaction between humans and ML models. For example, in hiring through Linkedin, discrimination can happen because of the ML model recommendation or biased recruiters. |
| Main point of Step 1: Proof of Disparate Impact |
|---|
| Proving disparate impact involves four steps: 1) identifying the policy, 2) establishing harms, 3) establishing disparity, and 4) establishing causation. All of these components in both ML and law are hard to define and are highly context-dependent. |
Second Step: Respondent Provides Legitimate Business Reasons (justifications)
In this step, the respondent should articulate a “substantial legitimate justification” for the challenged policy or practice. Agencies should thoroughly investigate the facts to determine whether these rationales are supported by sufficient evidence.
Example11. Alexander v. Sandoval, 532 U.S. 275 (2001). James Alexander, Director of the Alabama Department of Public Safety, ordered that the test for Alabama driver’s license test needs to be done in English. Martha Sandoval sued Alexander and claimed that the English-only test policy was discriminatory. The state agency offered several justifications for the English-only rule: highway safety concerns, exam administration difficulties, exam integrity, and budgetary constraints.
The district court found that the recipient had produced no evidence at trial that non-English speakers posed a greater driving safety risk than English speakers; the recipient had undermined its own safety argument by recognizing valid licenses from non-English speakers of other locales; making test accommodations for illiterate, deaf, and disabled drivers; and having previously offered the examination in fourteen languages without administrative difficulty.
The court further noted that cost had not been a real factor in making the decision to administer the examination only in English and that the recipient could afford the costs of language assistance in light of its $50 million dollar budget. Affirming the district court, the Eleventh Circuit ruled that the state agency’s rationales constituted a pretext for the policy.
| Machine Learning efforts for Providing Legitimate Business Reasons |
|---|
| At first, ML researchers accused several ML models of not satisfying demographic parity 12 (i.e., the prediction should be independent of protected attributes). In response, other ML researchers argued that the protected groups can have different base rates (e.g., in hiring, there might be a different number of qualified people in the different groups). As a result, equalized opportunity measure 137 was proposed. This measure considers the difference in base rate and asks to have the same acceptance rate for data points with the same ground truth (e.g., in hiring the same acceptance rate among qualified individuals in each group). ML researchers then accused several models of not satisfying equal opportunity. As a rebuttal, 14 argued that groups can have different risk distributions, thus making it hard for the models to satisfy equal opportunity. |
| A common practice in law is to consider some features (e.g., education) and then show that there are no disparities between groups conditioned on those features. They then argue that such features are business necessities. In Machine learning error analysis and understanding what causes a group to have higher error is necessary for this step. |
| Finally, note that ML researchers show that the model satisfies some measures according to validation/test data. However, ML models usually work with historical data. The labels and features in training data can be biased (e.g., women who deserve promotion get no promotion in data or minorities who got arrested without any crime). In these cases, showing that the model does not demonstrate disparate impact or the distribution of the groups is the same for some features will not be accepted since the real distribution is different. |
| Main Point of Step 2: Providing Legitimate Business Reason |
|---|
| ML researchers should put more effort into error analysis of ML models 151617. By error analysis, one can better understand if the disparity between groups is because of business necessity (e.g., population X has more images at night which cause bad performance for the pedestrian detection model) or cannot be explained by business necessity (e.g., the pedestrian detection model has bad performance in some neighborhoods). |

Third step: Charging Party Provides a Less Discriminatory Alternative
If the justification were valid, the investigating agency should investigate if there are equally effective alternative practices with less disparate impact.
| Machine Learning efforts for Providing Less Discriminatory Alternatives |
|---|
| In deep learning networks, many models have the same performance on train and test but exhibit disparities in performance across groups 18. ML researchers have put a lot of effort into finding alternatives that are less discriminatory! For example by adding a regularization term while training 19 18. |
| Model developers should always study the existence of alternatives with less discriminatory behavior, since the alternatives may be used as evidence for the disparate impact case. |
Real Legal Cases20
Age Discrimination
“Under the Age Discrimination in Employment Act (ADEA), the EEOC charged that in the year 2000 Allstate adopted a hiring moratorium for a period of one year, or while severance benefits were being received, that applied to all its employee-sales agents who were part of its ‘‘Preparing For The Future Reorganization Program’. The program was part of Allstate’s reorganization from employee agents to what the company considered independent contractors. The EEOC alleged that the policy had a disproportionate impact on Allstate’s employees over the age of 40 because more than 90 percent of the agents subjected to the hiring moratorium were 40 years of age or older.”
Ramifications: “Allstate Insurance Company, one of the nation’s largest insurers, for $4,500,000 to approximately 90 older former employees, in addition to significant remedial relief.”
Sex Discrimination
“CSXT Transportation conducted isokinetic strength testing as a requirement for workers to be hired for various jobs. The EEOC said that the strength test used by CSXT, known as the “IPCS Biodex” test, caused an unlawful discriminatory impact on female workers seeking jobs as conductors, material handler/clerks, and a number of other job categories. The EEOC also charged that CSXT used two other employment tests, a three-minute step test seeking to measure aerobic capacity and a discontinued arm endurance test, as a requirement for selection into certain jobs, and that those tests also caused an unlawful discriminatory effect on female workers.”
Ramifications: “CSXT had to pay them $3.2 Million to settle the disparate impact sex discrimination case.”
Race Discrimination
“Dollar General, the largest small-box discount retailer in the United States, violated federal law by denying employment to African Americans at a significantly higher rate than white applicants for failing the company’s broad criminal background check. Employment screens that have a disparate impact on the basis of race violate Title VII of the Civil Rights Act of 1964, unless an employer can show the screen is job-related and is a business necessity.”
Ramifications: Dollar General had to pay $6 million and furnish other relief to settle a class race discrimination lawsuit brought by the U.S. Equal Employment Opportunity Commission (EEOC).
Other Types of Discrimination
Title VII (Theories of discrimination) prohibited 5 kinds of discrimination in employment. Our previous post covered disparate treatment; this post covers disparate impact; for completeness, we will briefly mention other types of discrimination here.
Perpetuation of Previous Discriminations
This kind of discrimination occurs when a neutral employment system continues to perpetuate the effects of past discrimination. For proving the perpetuation of past discrimination, the charging party must establish a causal connection between the past discrimination and the current policy’s adverse effects.
Example. Jamal claims that GE refuses to hire Blacks as summer employees. GE contends that it gives preference to the children of employees. Prior to 1964, GE employed very few Blacks due to discriminatory hiring practices. The policy of giving a preference to the children of employees perpetuates GE’s past discriminatory practices.
| Perpetuation of Previous Discrimination in Machine Learning |
|---|
| As there is almost no regulation regarding Machine learning models, these models can cause some discrimination that can get perpetuated. For example, assume company X gives access to its API only to the white majority and stores data from their interaction for training. As a result, the final model performs poorly for non-white groups. Company X can argue that collecting data from non-whites is very costly. This reason cannot be made since this behavior would be an instance of the perpetuation of previous discrimination. |
Accommodation
This type of discrimination occurs by failing to accommodate a prospective or existing employee’s disability or religious practices. The charging party can establish a case by showing that they informed the respondent of the accommodation, but the respondent fails to accommodate (note that there is no need to compare similarly situated individuals or show adverse impacts). In response, the respondent can show that accommodation would have created an undue hardship on the conduct of its business.
| Accommodation in Machine Learning |
|---|
| The concept of accommodating in machine learning models is not immediately clear. Should features be chosen such that disabled people can provide data too? Should the task be defined in a way that can be applied to disabled people as well? Should the test data (for tasks such as pedestrian detection) report accuracy for disabled people (e.g., people with wheelchairs) separately? All of these could fall under the scope of discrimination wrt accommodation. |
Retaliation
Title VII prohibits discrimination against individuals because they have filed a Title VII charge, have participated in a Title VII investigation, or have otherwise opposed Title VII discrimination.
Conclusion
Discrimination in law has been studied for over seven decades now. There are definitions and clear procedures for proving discrimination. The procedure involves two parties: (1) the charging party who tries to show discrimination has happened and (2) the respondent who tries to show that the charging party’s evidence is not valid. Understanding their process and the challenges will help ML researchers develop better methods to facilitate auditing models and develop mitigation methods.
Acknowledgment
We would like to thank Alex Tamkin, Jacob Schreiber, Neel Guha, Peter Henderson, Megha Srivastava, and Michael Zhang for their useful feedback on this blog post.
-
https://www.nytimes.com/2020/06/15/us/gay-transgender-workers-supreme-court.html ↩
-
Paraphrased from Fick, Barbara J. (1997). The American Bar Association guide to workplace law : everything you need to know about your rights as an employee or employer (1st ed.). New York: Times Books. ISBN 9780812929287. ↩
-
Example from page 8 in section 7 of TITLE VI LEGAL MANUAL ↩
-
In many cases, courts have shied away from drawing clear lines. See Clady v. Cty. of Los Angeles, 770 F.2d 1421, 1428–29 (9th Cir. 1985); accord Smith v. Xerox Corp., 196 F.3d at 366 (“[T]he substantiality of a disparity is judged on a case-by-case basis.”); Groves, 776 F. Supp. at 1526 (“There is no rigid mathematical threshold that must be met to demonstrate a sufficiently adverse impact.”). ↩
-
Inclusive Communities, 135 S. Ct. at 2523 (citing Wards Cove, 490 U.S. at 653) ↩
-
Albright, Alex. “If you give a judge a risk score: evidence from Kentucky bail decisions.” Harvard John M. Olin Fellow’s Discussion Paper 85 (2019). ↩
-
Hardt, Moritz, Eric Price, and Nati Srebro. “Equality of opportunity in supervised learning.” Advances in neural information processing systems 29 (2016): 3315-3323. ↩ ↩2
-
Kamiran, Faisal, and Toon Calders. “Data preprocessing techniques for classification without discrimination.” Knowledge and Information Systems 33.1 (2012): 1-33. ↩
-
Milli, Smitha, et al. “The social cost of strategic classification.” Proceedings of the Conference on Fairness, Accountability, and Transparency. 2019. ↩
-
There are cases where the protected attributes are not known a priori. There are some methods to deal with disparity when protected attributes are not known, e.g., study the worst case group as a proxy for the protected groups in Hashimoto, Tatsunori, et al. “Fairness without demographics in repeated loss minimization.” International Conference on Machine Learning. PMLR, 2018 and Khani, Fereshte, Aditi Raghunathan, and Percy Liang. “Maximum weighted loss discrepancy.” arXiv preprint arXiv:1906.03518 (2019). ↩
-
Example is taken from section 7 page 33 of Legal Manual of title VI ↩
-
Pedreshi, Dino, Salvatore Ruggieri, and Franco Turini. “Discrimination-aware data mining.” Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 2008. ↩
-
Proposed as outcome test [^becker] in 1959. ↩
-
Corbett-Davies, Sam, and Sharad Goel. “The measure and mismeasure of fairness: A critical review of fair machine learning.” arXiv preprint arXiv:1808.00023 (2018). ↩
-
Nushi, Besmira, Ece Kamar, and Eric Horvitz. “Towards accountable ai: Hybrid human-machine analyses for characterizing system failure.” Proceedings of the AAAI Conference on Human Computation and Crowdsourcing. Vol. 6. 2018. ↩
-
Singla, Sahil, et al. “Understanding failures of deep networks via robust feature extraction.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. ↩
-
Ribeiro, Marco Tulio, et al. “Beyond accuracy: Behavioral testing of NLP models with CheckList.” arXiv preprint arXiv:2005.04118 (2020). ↩
-
D’Amour, Alexander, et al. “Underspecification presents challenges for credibility in modern machine learning.” Journal of Machine Learning Research (2020). ↩ ↩2
-
Khani, Fereshte, Aditi Raghunathan, and Percy Liang. “Maximum weighted loss discrepancy.” arXiv preprint arXiv:1906.03518 (2019). ↩
-
Examples from https://www.digitalhrtech.com/disparate-treatment/ ↩