![]()
The thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) 2021 is being hosted virtually from Dec 6th - 14th. We’re excited to share all the work from SAIL that’s being presented at the main conference, at the Datasets and Benchmarks track and the various workshops, and you’ll find links to papers, videos and blogs below.
Some of the members in our SAIL community also serve as co-organizers of several exciting workshops that will take place on Dec 13-14, so we hope you will check them out!
Feel free to reach out to the contact authors and the workshop organizers directly to learn more about the work that’s happening at Stanford!
Main Conference
Improving Compositionality of Neural Networks by Decoding Representations to Inputs
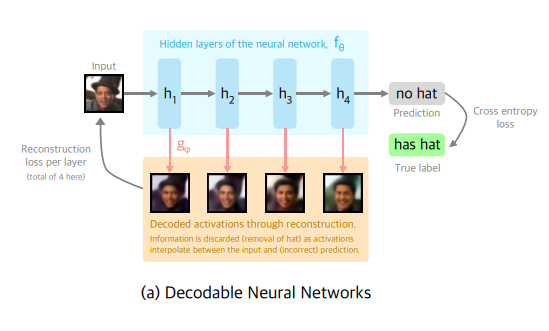 Authors: Mike Wu, Noah Goodman, Stefano Ermon
Authors: Mike Wu, Noah Goodman, Stefano Ermon
Contact: wumike@stanford.edu
Links: Paper
Keywords: generative models, compositionality, decoder
Reverse engineering recurrent neural networks with Jacobian switching linear dynamical systems
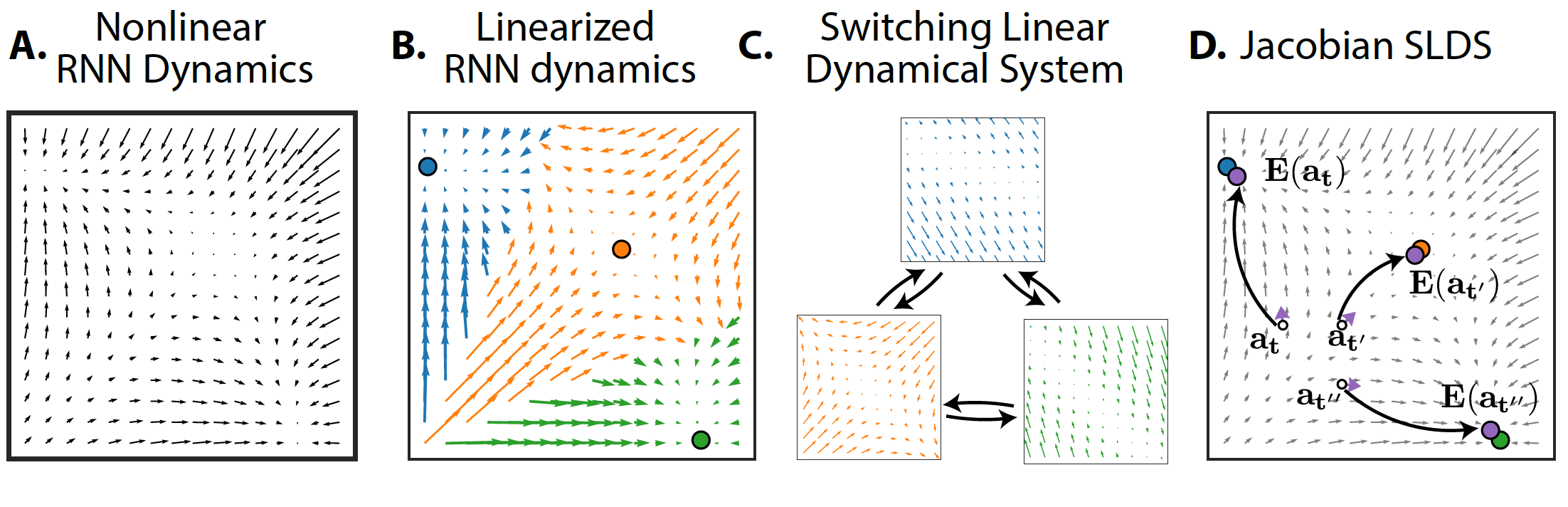 Authors: Jimmy T.H. Smith, Scott W. Linderman, David Sussillo
Authors: Jimmy T.H. Smith, Scott W. Linderman, David Sussillo
Contact: jsmith14@stanford.edu
Links: Paper | Website
Keywords: recurrent neural networks, switching linear dynamical systems, interpretability, fixed points
Compositional Transformers for Scene Generation
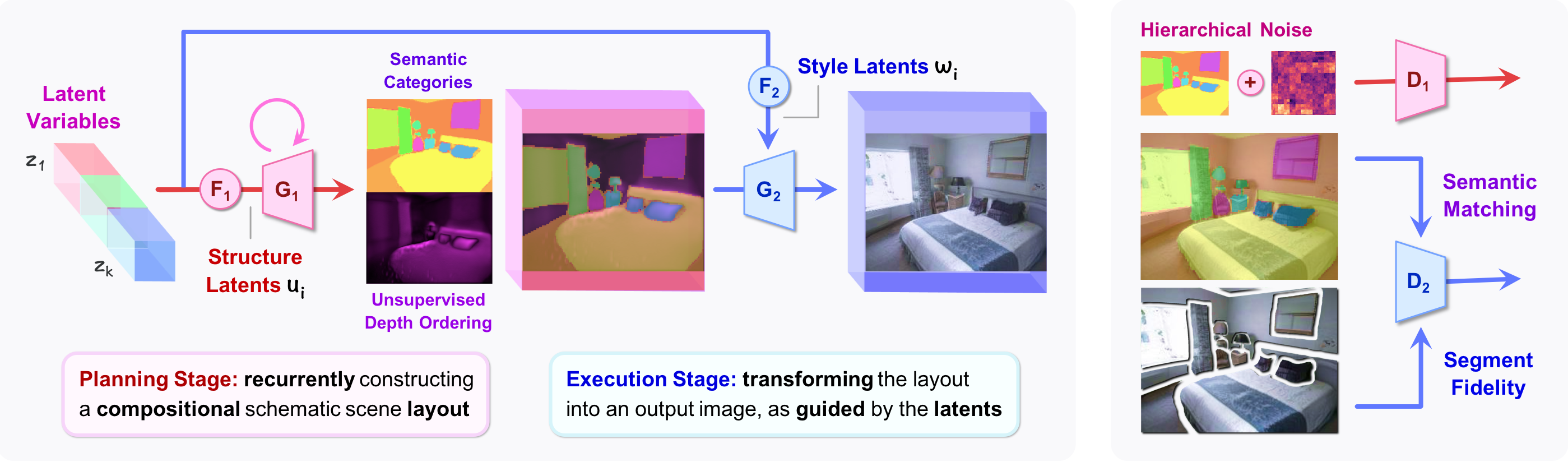 Authors: Drew A. Hudson, C. Lawrence Zitnick
Authors: Drew A. Hudson, C. Lawrence Zitnick
Contact: dorarad@cs.stanford.edu
Links: Paper | Github
Keywords: GANs, transformers, compositionality, scene synthesis
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State Space Layers
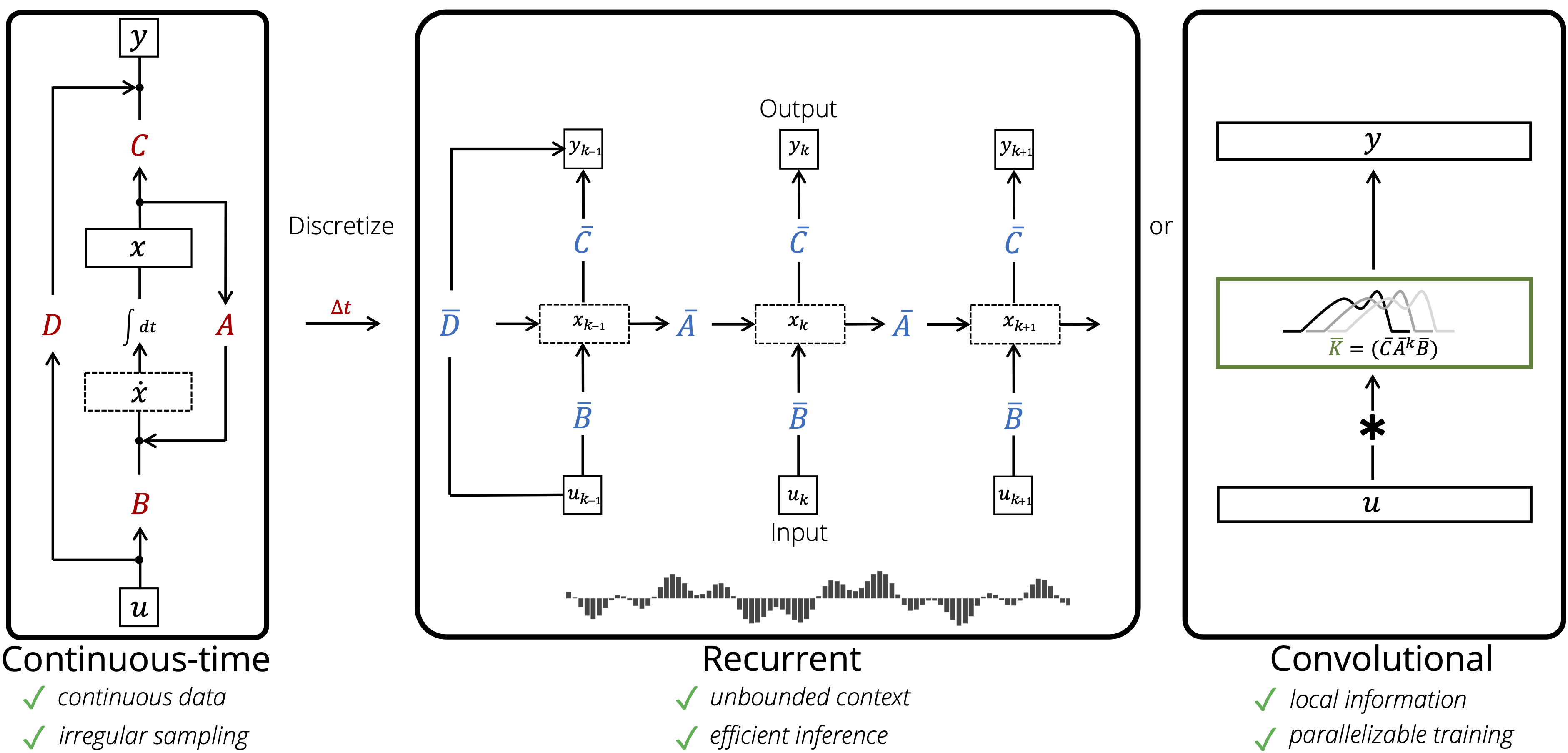 Authors: Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, Chris Ré
Authors: Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, Chris Ré
Contact: albertgu@stanford.edu
Links: Paper
Keywords: recurrent neural networks, rnn, continuous models, state space, long range dependencies, sequence modeling
Emergent Communication of Generalizations
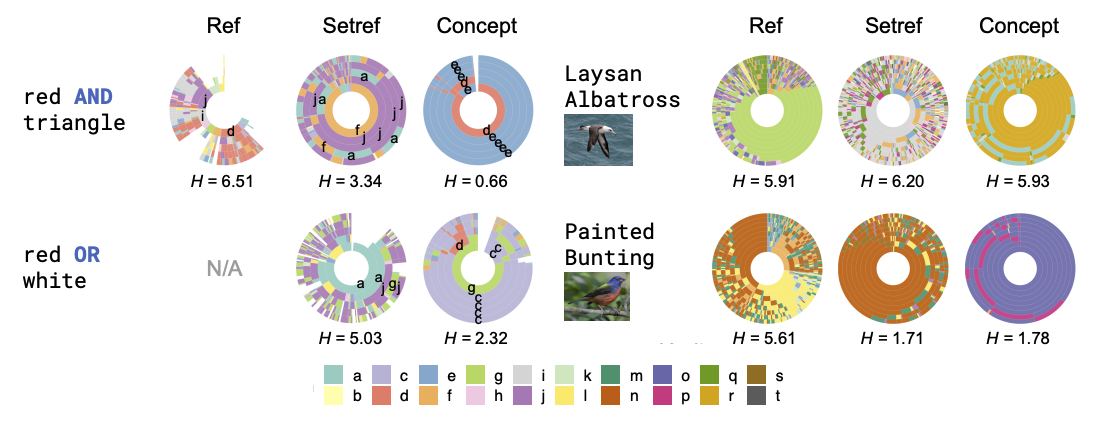 Authors: Jesse Mu, Noah Goodman
Authors: Jesse Mu, Noah Goodman
Contact: muj@stanford.edu
Links: Paper | Video
Keywords: emergent communication, multi-agent communication, language grounding, compositionality
Deep Learning on a Data Diet: Finding Important Examples Early in Training
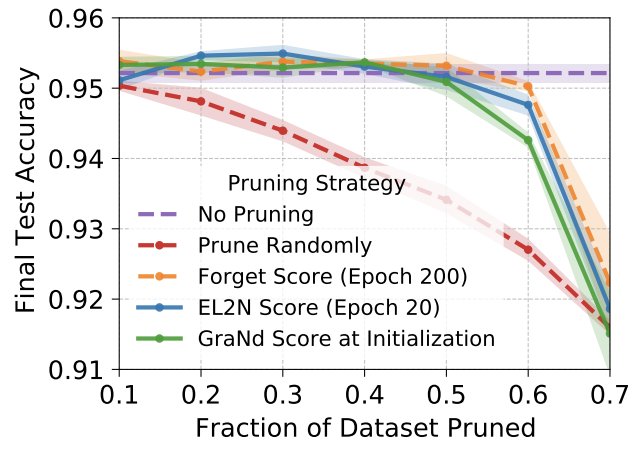 Authors: Mansheej Paul, Surya Ganguli, Gintare Karolina Dziugaite
Authors: Mansheej Paul, Surya Ganguli, Gintare Karolina Dziugaite
Contact: mansheej@stanford.edu
Links: Paper
Keywords: data pruning
ELLA: Exploration through Learned Language Abstraction
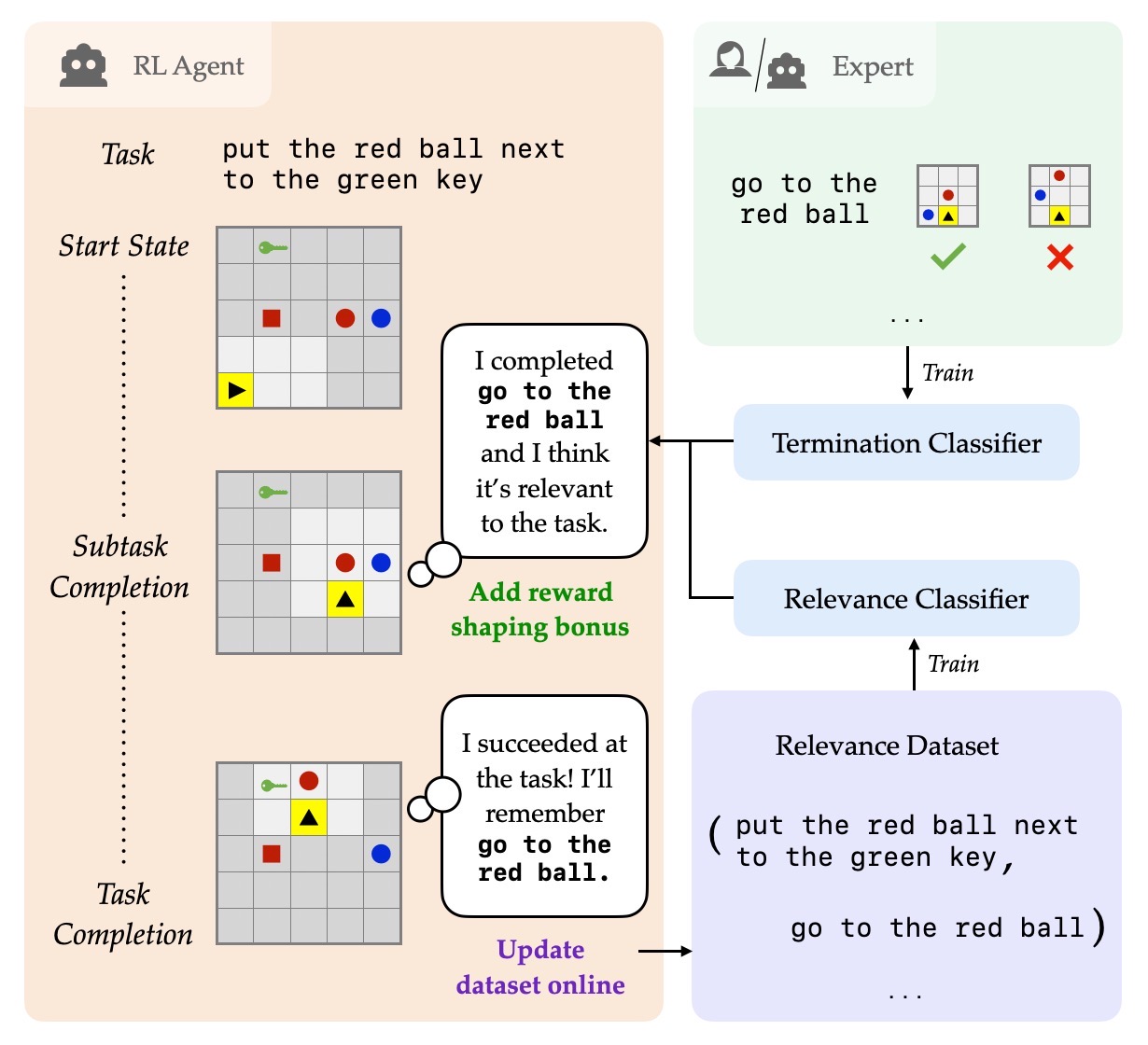 Authors: Suvir Mirchandani, Siddharth Karamcheti, Dorsa Sadigh
Authors: Suvir Mirchandani, Siddharth Karamcheti, Dorsa Sadigh
Contact: suvir@cs.stanford.edu
Links: Paper | Video
Keywords: instruction following, reward shaping, reinforcement learning
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
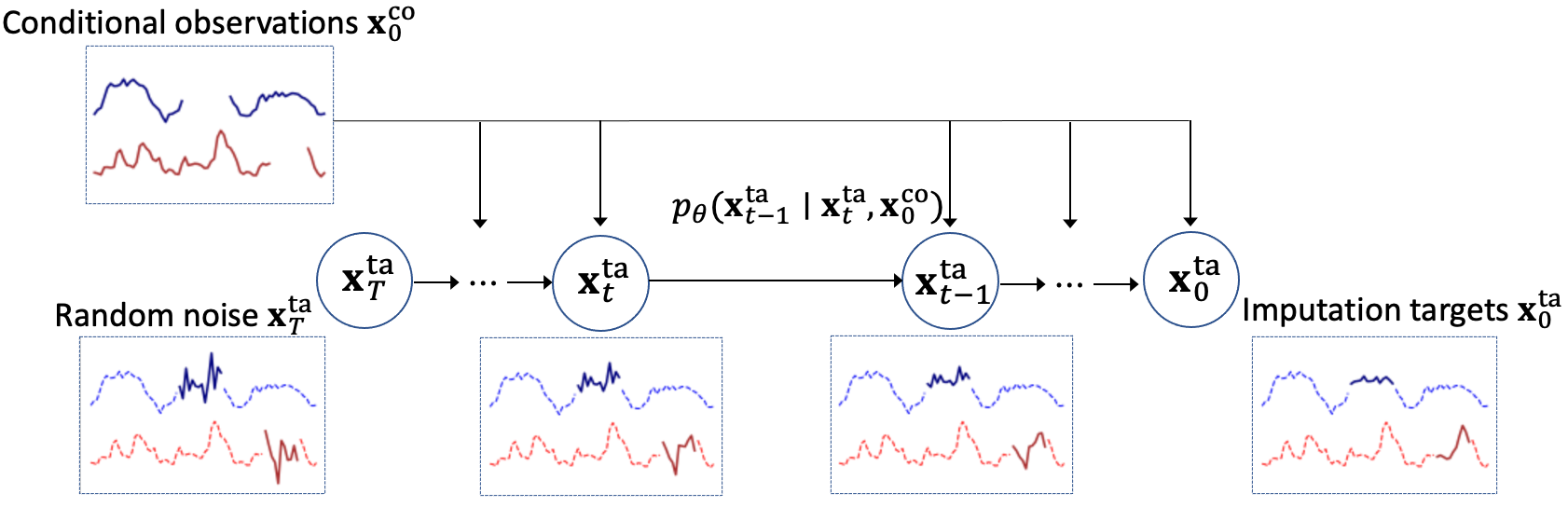 Authors: Yusuke Tashiro, Jiaming Song, Yang Song, Stefano Ermon
Authors: Yusuke Tashiro, Jiaming Song, Yang Song, Stefano Ermon
Contact: ytashiro@stanford.edu
Links: Paper | Website
Keywords: score-based generative modeling, time series imputation
Confidence-Aware Imitation Learning from Demonstrations with Varying Optimality
 Authors: Songyuan Zhang, Zhangjie Cao, Dorsa Sadigh, Yanan Sui
Authors: Songyuan Zhang, Zhangjie Cao, Dorsa Sadigh, Yanan Sui
Contact: szhang21@mit.edu
Links: Paper | Video | Website
Keywords: imitation learning, learning from demonstration, learning from suboptimal demonstrations
Explaining heterogeneity in medial entorhinal cortex with task-driven neural networks
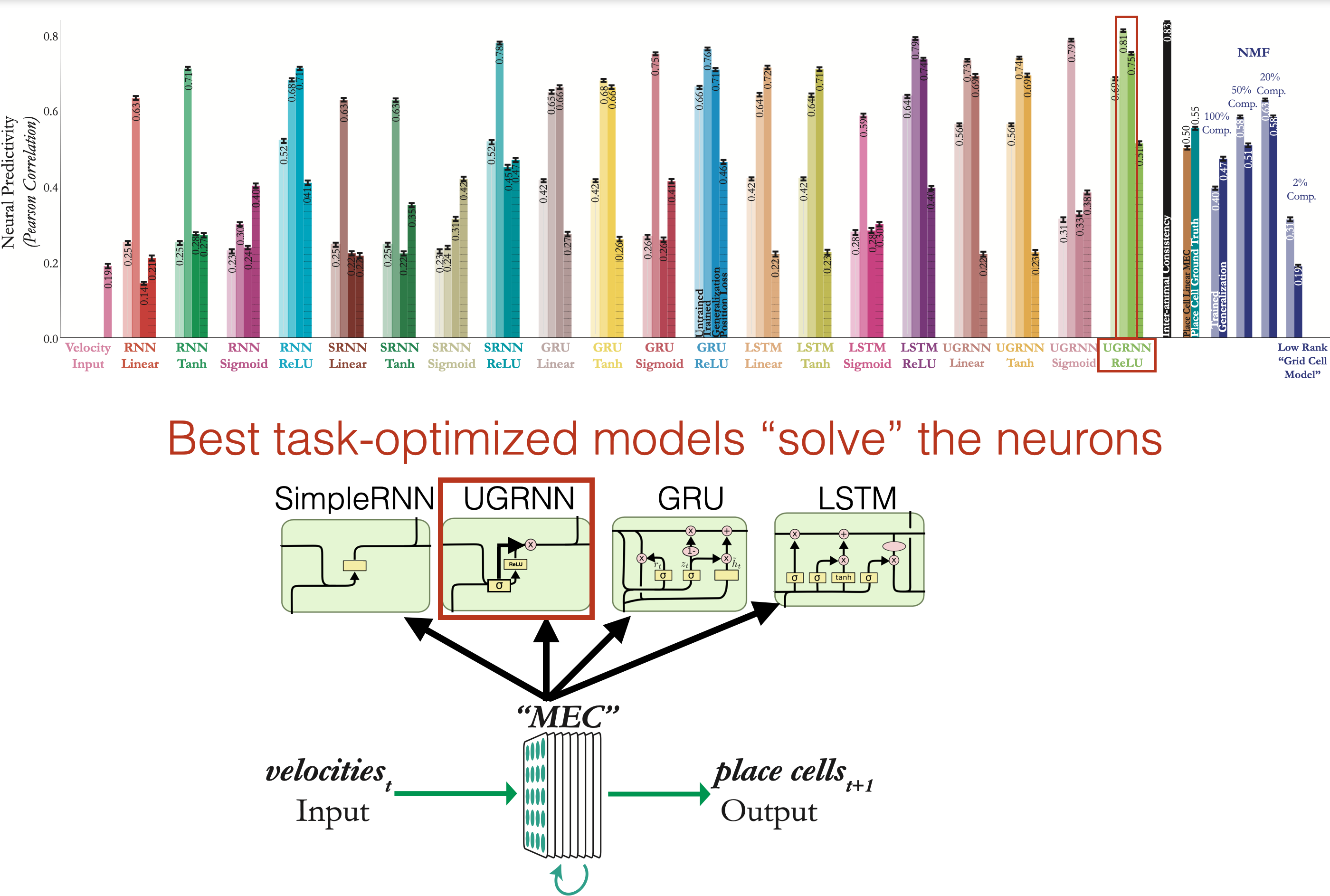 Authors: Aran Nayebi, Alexander Attinger, Malcolm G. Campbell, Kiah Hardcastle, Isabel I.C. Low, Caitlin S. Mallory, Gabriel C. Mel, Ben Sorscher, Alex H. Williams, Surya Ganguli, Lisa M. Giocomo, Daniel L.K. Yamins
Authors: Aran Nayebi, Alexander Attinger, Malcolm G. Campbell, Kiah Hardcastle, Isabel I.C. Low, Caitlin S. Mallory, Gabriel C. Mel, Ben Sorscher, Alex H. Williams, Surya Ganguli, Lisa M. Giocomo, Daniel L.K. Yamins
Contact: anayebi@stanford.edu
Award nominations: Spotlight Presentation
Links: Paper | Website
Keywords: neural coding, medial entorhinal cortex, grid cells, biologically-inspired navigation, path integration, recurrent neural networks
On the theory of reinforcement learning with once-per-episode feedback
 Authors: Niladri Chatterji, Aldo Pacchiano, Peter Bartlett, Michael Jordan
Authors: Niladri Chatterji, Aldo Pacchiano, Peter Bartlett, Michael Jordan
Contact: niladri@cs.stanford.edu
Keywords: theoretical reinforcement learning, binary rewards, non-markovian rewards
HyperSPNs: Compact and Expressive Probabilistic Circuits
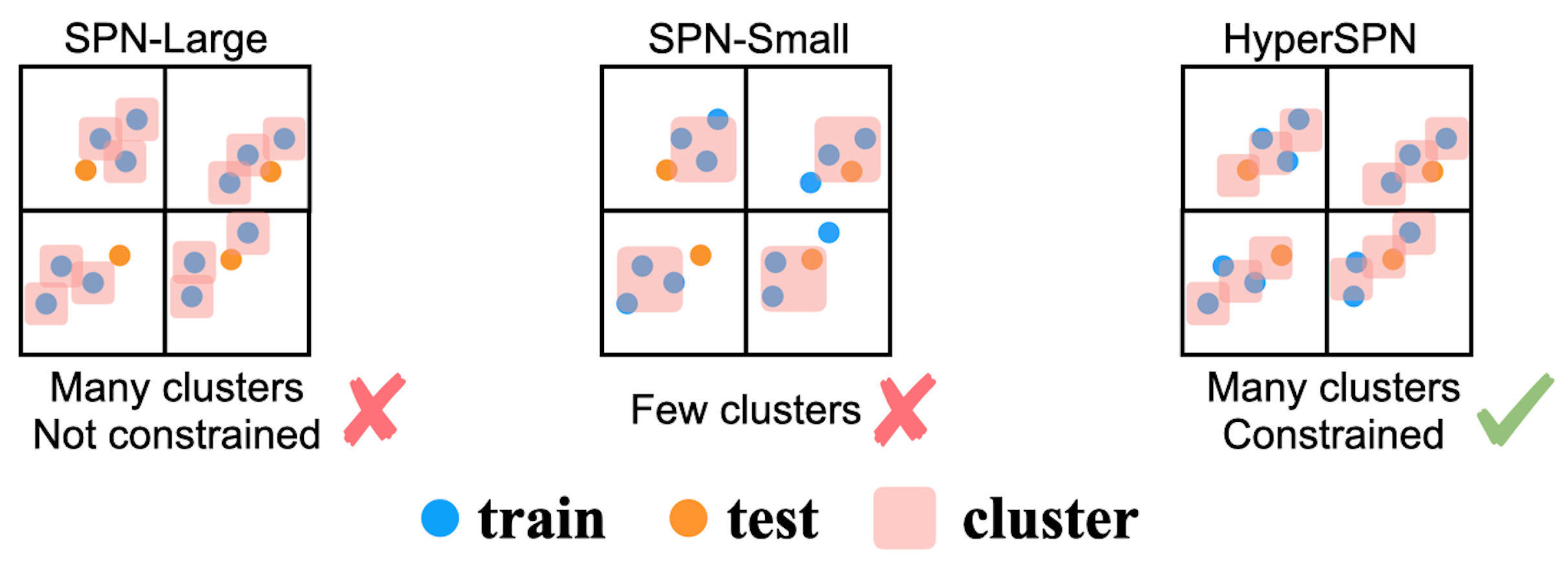 Authors: Andy Shih, Dorsa Sadigh, Stefano Ermon
Authors: Andy Shih, Dorsa Sadigh, Stefano Ermon
Contact: andyshih@stanford.edu
Links: Paper | Video | Website
Keywords: generative models, tractable probabilistic models, sum product networks, probabilistic circuits
COMBO: Conservative Offline Model-Based Policy Optimization
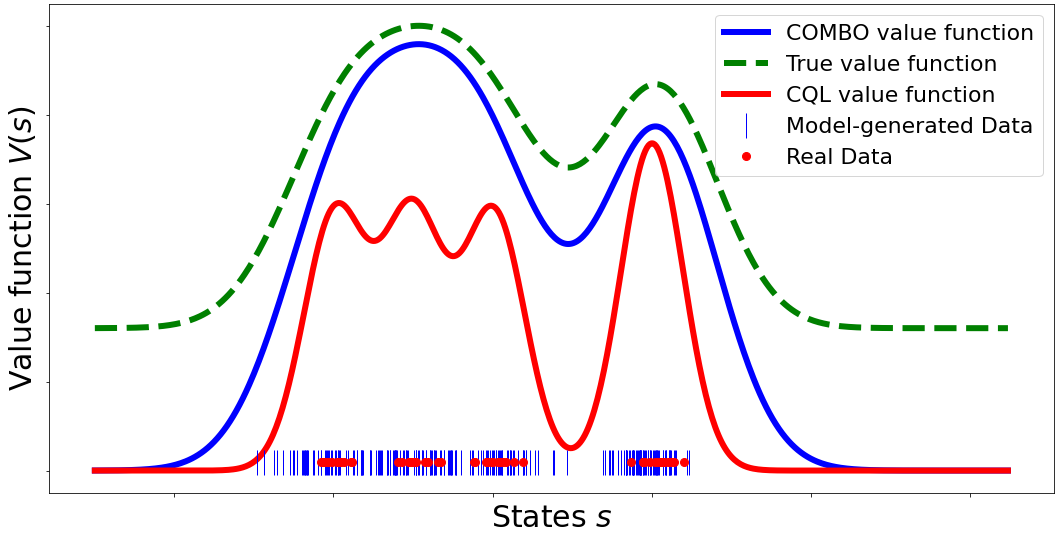 Authors: Tianhe Yu*, Aviral Kumar*, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, Chelsea Finn
Authors: Tianhe Yu*, Aviral Kumar*, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, Chelsea Finn
Contact: tianheyu@cs.stanford.edu
Links: Paper
Keywords: offline reinforcement learning, model-based reinforcement learning, deep reinforcement learning
Conservative Data Sharing for Multi-Task Offline Reinforcement Learning
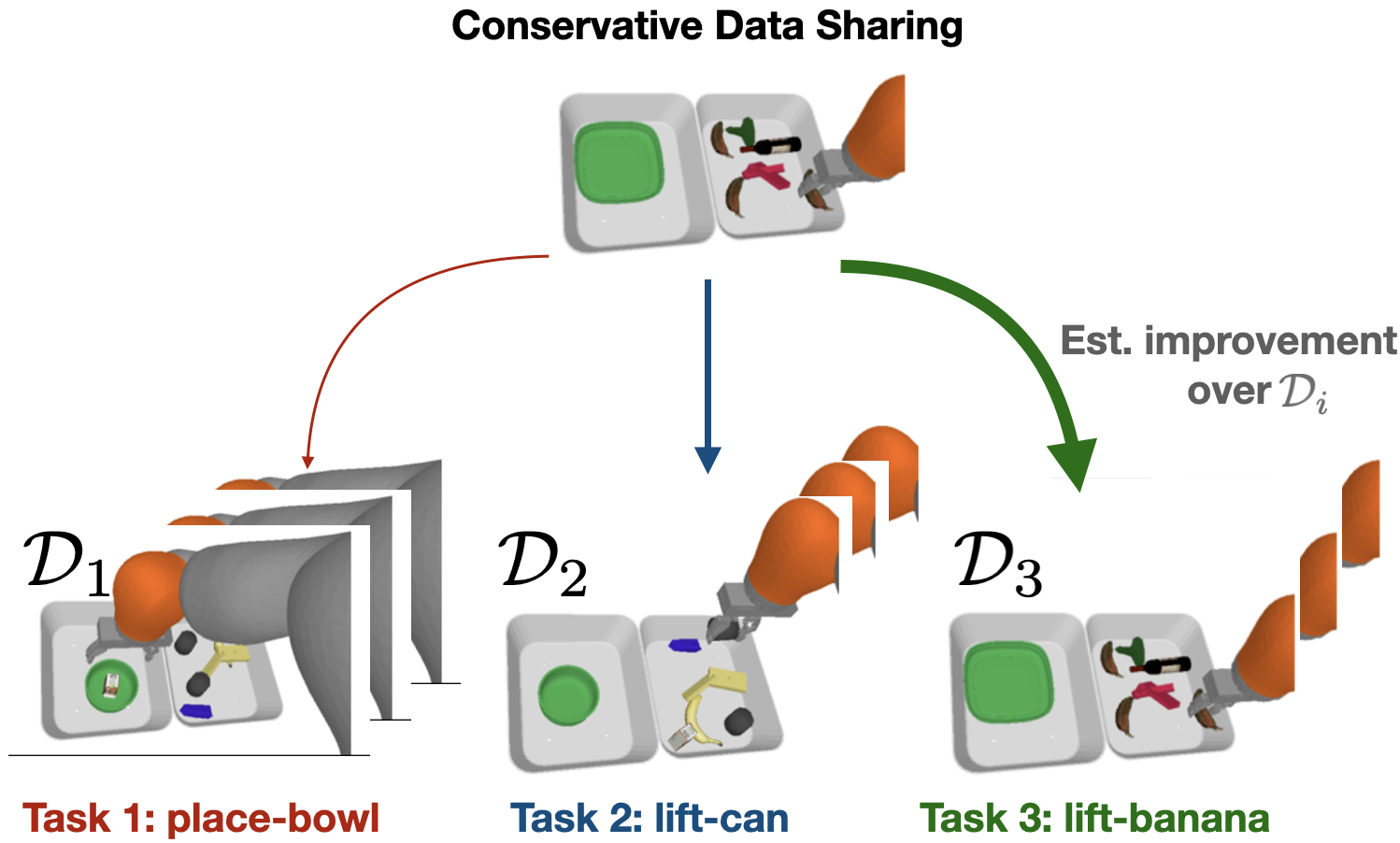 Authors: Tianhe Yu*, Aviral Kumar*, Yevgen Chebotar, Karol Hausman, Sergey Levine, Chelsea Finn
Authors: Tianhe Yu*, Aviral Kumar*, Yevgen Chebotar, Karol Hausman, Sergey Levine, Chelsea Finn
Contact: tianheyu@cs.stanford.edu
Links: Paper
Keywords: offline reinforcement learning, multi-task reinforcement learning, deep reinforcement learning
Autonomous Reinforcement Learning via Subgoal Curricula
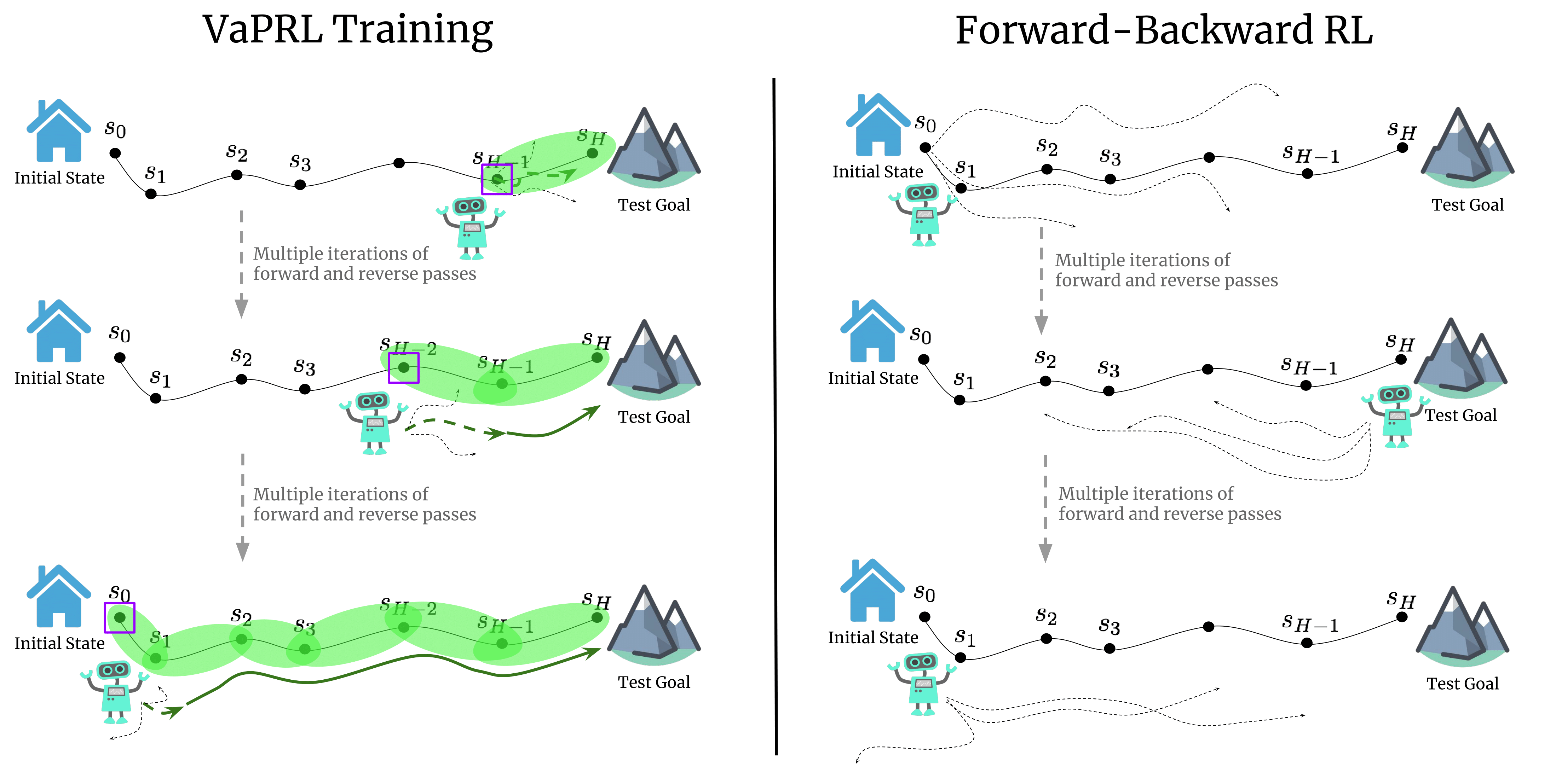 Authors: Archit Sharma, Abhishek Gupta, Sergey Levine, Karol Hausman, Chelsea Finn
Authors: Archit Sharma, Abhishek Gupta, Sergey Levine, Karol Hausman, Chelsea Finn
Contact: architsh@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, curriculum, autonomous learning, reset-free reinforcement learning
Lossy Compression for Lossless Prediction
 Authors: Yann Dubois, Benjamin Bloem-Reddy, Karen Ullrich Chris J. Maddison
Authors: Yann Dubois, Benjamin Bloem-Reddy, Karen Ullrich Chris J. Maddison
Contact: yanndubs@stanford.edu
Award nominations: Spotlight Presentation
Links: Paper | Video | Website
Keywords: compression, invariances, information theory, machine learning, self-supervised learning
Capturing implicit hierarchical structure in 3D biomedical images with self-supervised hyperbolic representations
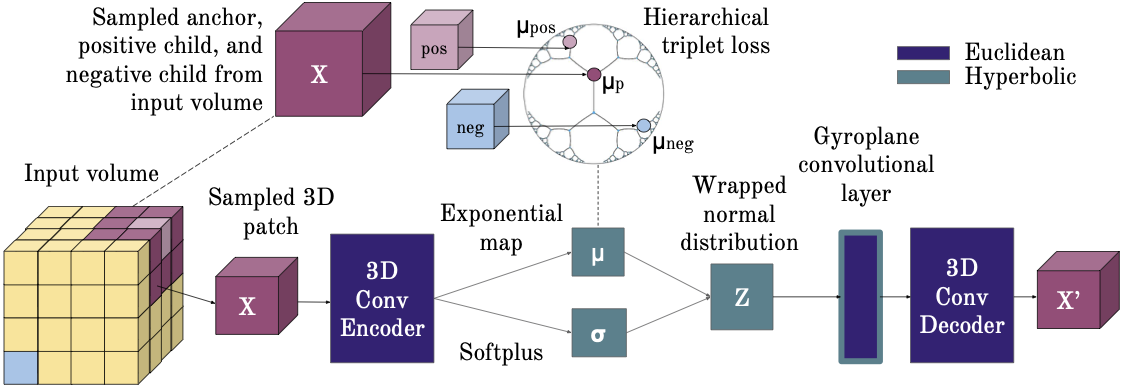 Authors: Joy Hsu, Jeffrey Gu, Gong-Her Wu, Wah Chiu, Serena Yeung
Authors: Joy Hsu, Jeffrey Gu, Gong-Her Wu, Wah Chiu, Serena Yeung
Contact: joycj@stanford.edu
Links: Paper
Keywords: hyperbolic representations, hierarchical structure, biomedical
Estimating High Order Gradients of the Data Distribution by Denoising
 Authors: Chenlin Meng, Yang Song, Wenzhe Li, Stefano Ermon
Authors: Chenlin Meng, Yang Song, Wenzhe Li, Stefano Ermon
Contact: chenlin@stanford.edu
Keywords: score matching, langevin dynamics, denoising, generative modeling
Universal Off-Policy Evaluation
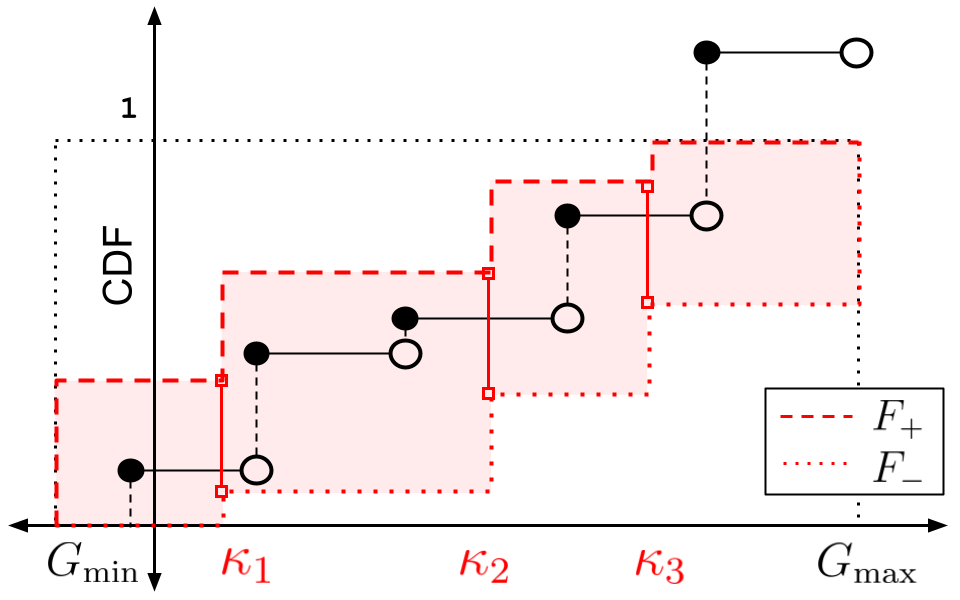 Authors: Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, Philip Thomas
Authors: Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, Philip Thomas
Contact: ychandak@cs.umass.edu
Links: Paper | Website
Keywords: metrics, risk, distribution, cdf, off-policy evaluation, ope, reinforcement learning, counterfactuals, high-confidence bounds, confidence intervals
Evidential Softmax for Sparse Multimodal Distributions in Deep Generative Models
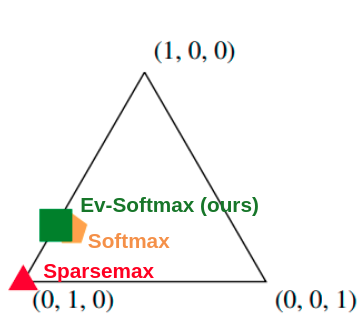 Authors: Phil Chen, Masha Itkina, Ransalu Senanayake, Mykel J. Kochenderfer
Authors: Phil Chen, Masha Itkina, Ransalu Senanayake, Mykel J. Kochenderfer
Contact: philhc@stanford.edu
Links: Paper
Keywords: deep learning or neural networks, sparsity and feature selection, variational inference, (application) natural language and text processing
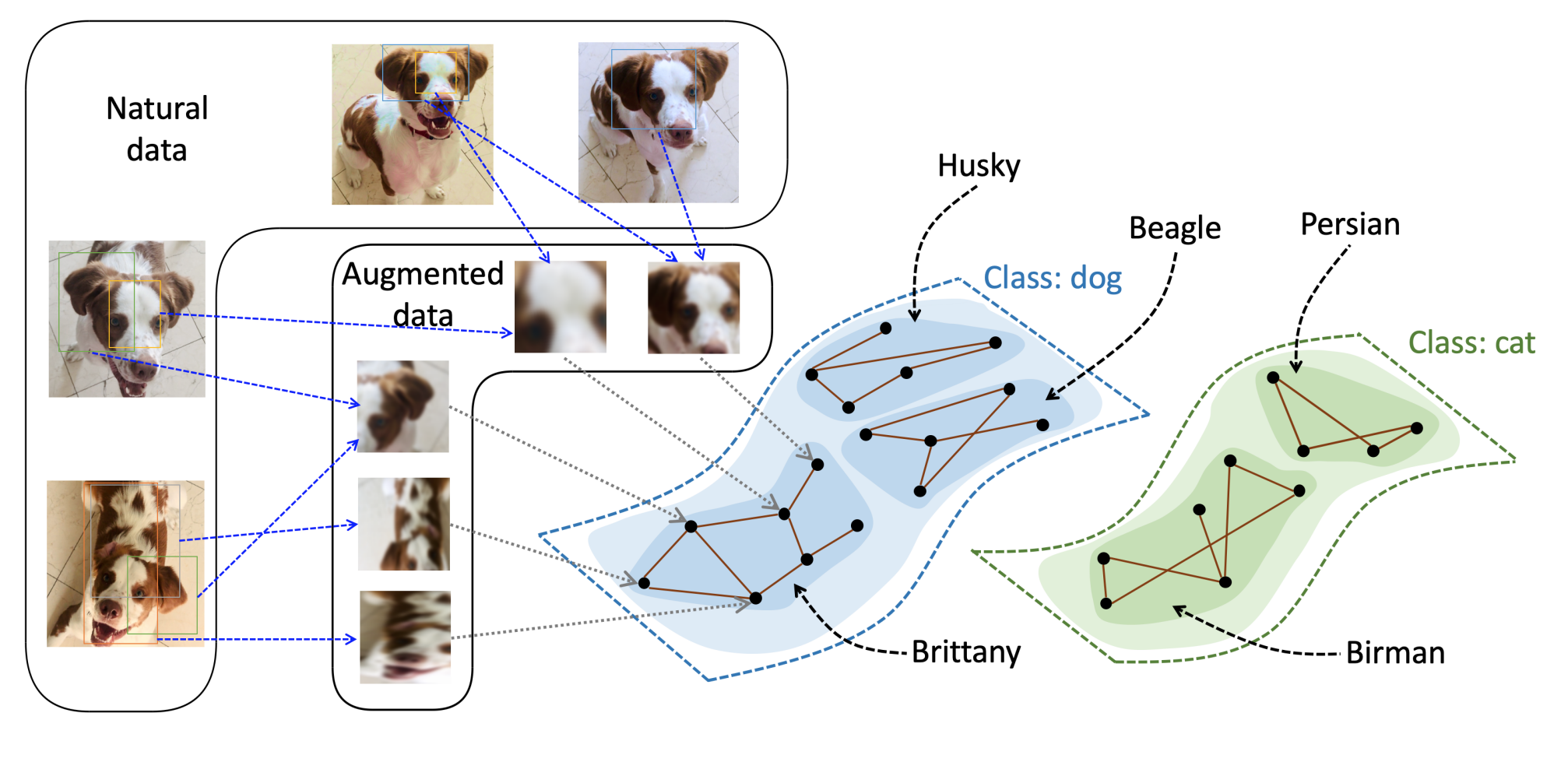
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss
 Authors: Jeff Z. HaoChen, Colin Wei, Adrien Gaidon, Tengyu Ma
Authors: Jeff Z. HaoChen, Colin Wei, Adrien Gaidon, Tengyu Ma
Contact: jhaochen@stanford.edu
Links: Paper
Keywords: deep learning theory, unsupervised learning theory, representation learning theory
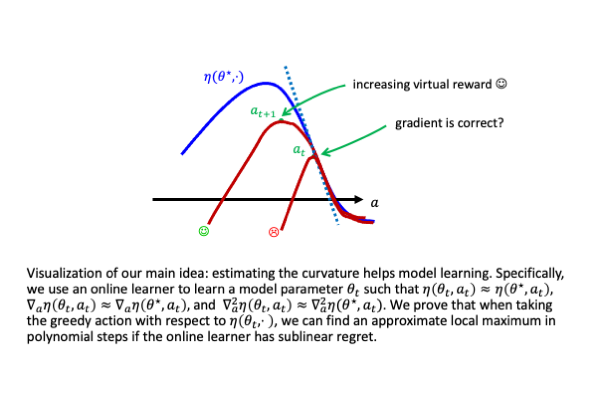
Provable Model-based Nonlinear Bandit and Reinforcement Learning: Shelve Optimism, Embrace Virtual Curvature
 Authors: Kefan Dong, Jiaqi Yang, Tengyu Ma
Authors: Kefan Dong, Jiaqi Yang, Tengyu Ma
Contact: kefandong@stanford.edu
Links: Paper | Video
Keywords: nonlinear bandits, online learning, deep reinforcement learning theory, sequential rademacher complexity
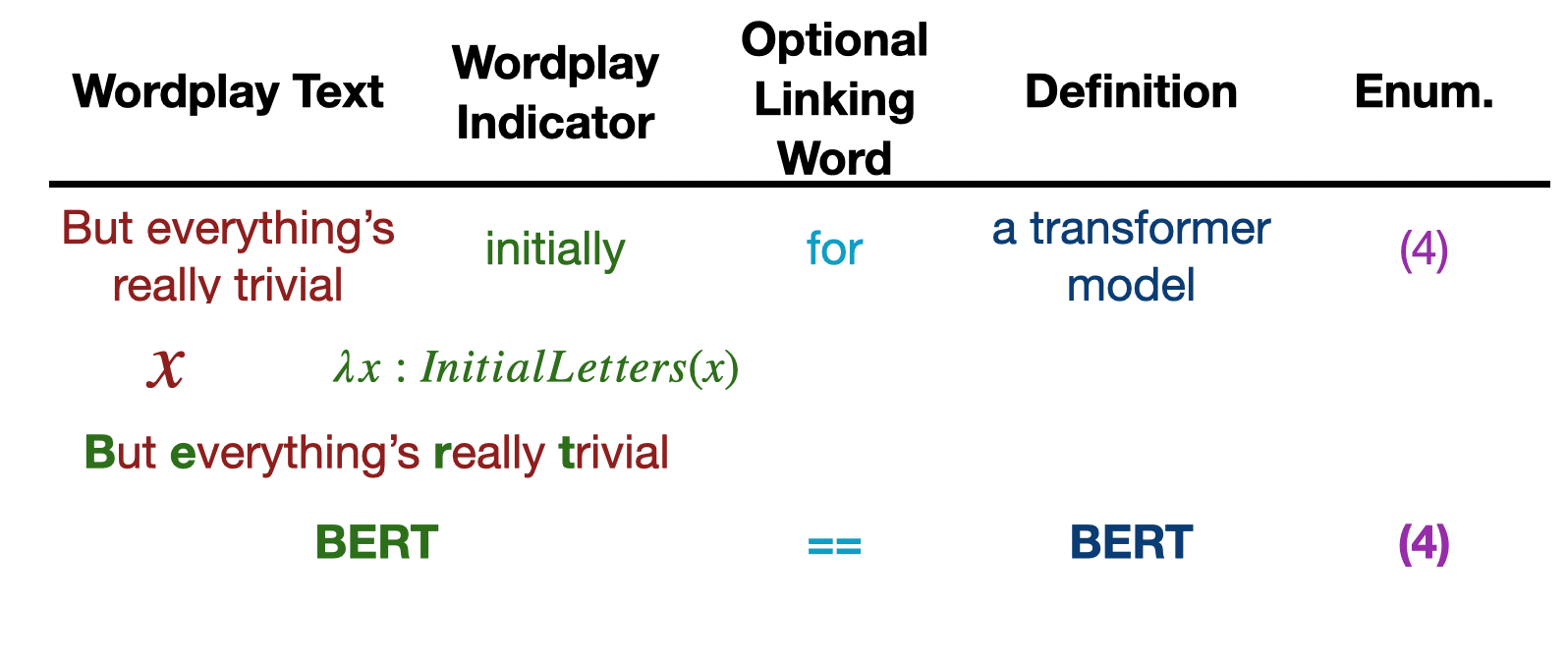
Decrypting Cryptic Crosswords: Semantically Complex Wordplay Puzzles as a Target for NLP
 Authors: Joshua Rozner, Christopher Potts, Kyle Mahowald
Authors: Joshua Rozner, Christopher Potts, Kyle Mahowald
Contact: rozner@stanford.edu
Links: Paper | Website
Keywords: compositionality in language, curriculum learning, meta-linguistics, systematicity, generalization
Design of Experiments for Stochastic Contextual Linear Bandits
 Authors: Andrea Zanette*, Kefan Dong*, Jonathan Lee*, Emma Brunskill
Authors: Andrea Zanette*, Kefan Dong*, Jonathan Lee*, Emma Brunskill
Contact: zanette@berkeley.edu
Links: Paper
Keywords: linear bandits, design of experiments
Provable Benefits of Actor-Critic Methods for Offline Reinforcement Learning
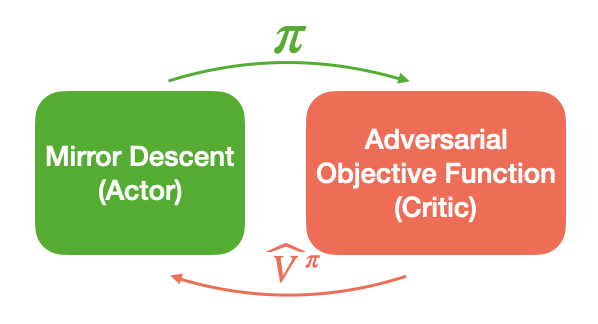 Authors: Andrea Zanette, Martin J. Wainwright, Emma Brunskill
Authors: Andrea Zanette, Martin J. Wainwright, Emma Brunskill
Contact: zanette@berkeley.edu
Links: Paper
Keywords: offline rl, mirror descent, bellman closure
A Topological Perspective on Causal Inference
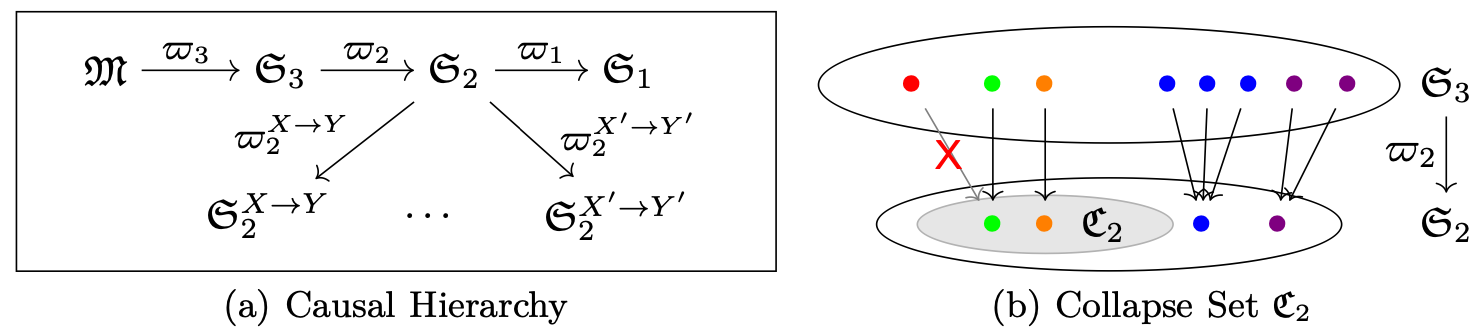 Authors: Duligur Ibeling, Thomas Icard
Authors: Duligur Ibeling, Thomas Icard
Contact: icard@stanford.edu
Links: Paper
Keywords: causal inference, topological learning theory
Adversarial Training Helps Transfer Learning via Better Representations
 Authors: Zhun Deng, Linjun Zhang, Kailas Vodrahalli, Kenji Kawaguchi, James Zou
Authors: Zhun Deng, Linjun Zhang, Kailas Vodrahalli, Kenji Kawaguchi, James Zou
Contact: jamesyzou@gmail.com
Links: Paper
Keywords: transfer learning, adversarial training
Widening the Pipeline in Human-Guided Reinforcement Learning with Explanation and Context-Aware Data Augmentation
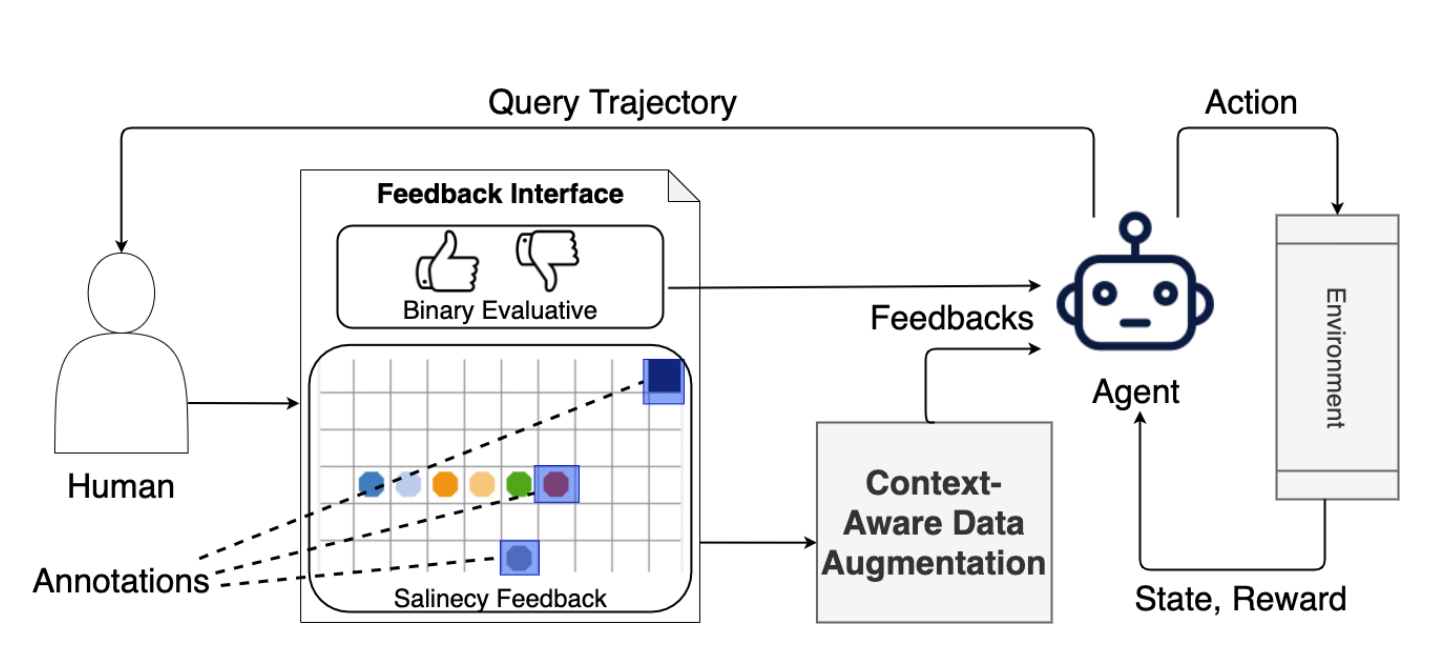 Authors: Lin Guan,Mudit Verma,Sihang Guo,Ruohan Zhang,Subbarao Kambhampati
Authors: Lin Guan,Mudit Verma,Sihang Guo,Ruohan Zhang,Subbarao Kambhampati
Contact: zharu@stanford.edu
Award nominations: Spotlight
Links: Paper | Website
Keywords: human-in-the-loop reinforcement learning, evaluative feedback, saliency map, visual explanation
Machine versus Human Attention in Deep Reinforcement Learning Tasks
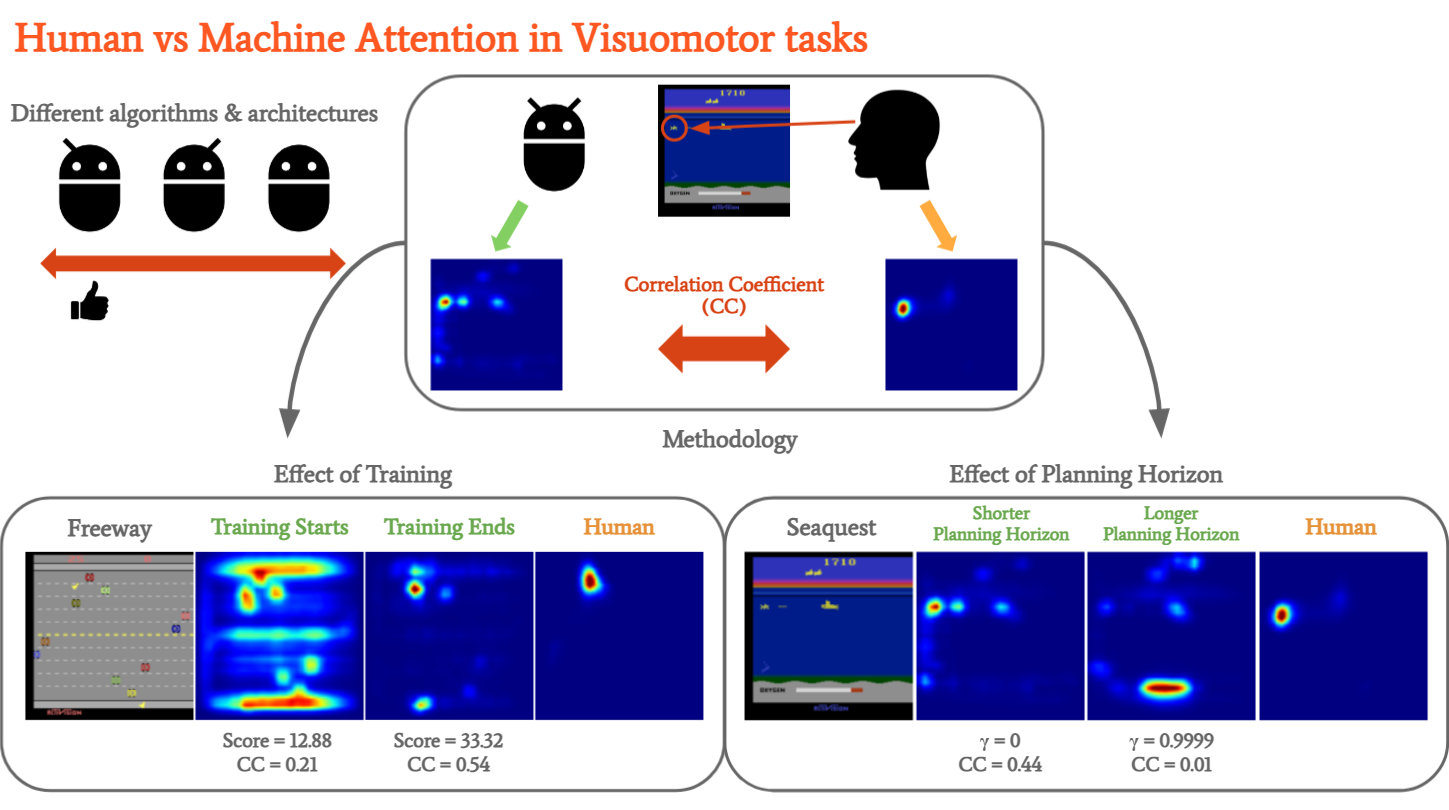 Authors: Sihang Guo, Ruohan Zhang, Bo Liu, Yifeng Zhu, Dana Ballard, Mary Hayhoe, Peter Stone
Authors: Sihang Guo, Ruohan Zhang, Bo Liu, Yifeng Zhu, Dana Ballard, Mary Hayhoe, Peter Stone
Contact: zharu@stanford.edu
Links: Paper
Keywords: deep reinforcement learning, interpretability, attention, eye tracking
Play to Grade: Testing Coding Games as Classifying Markov Decision Process
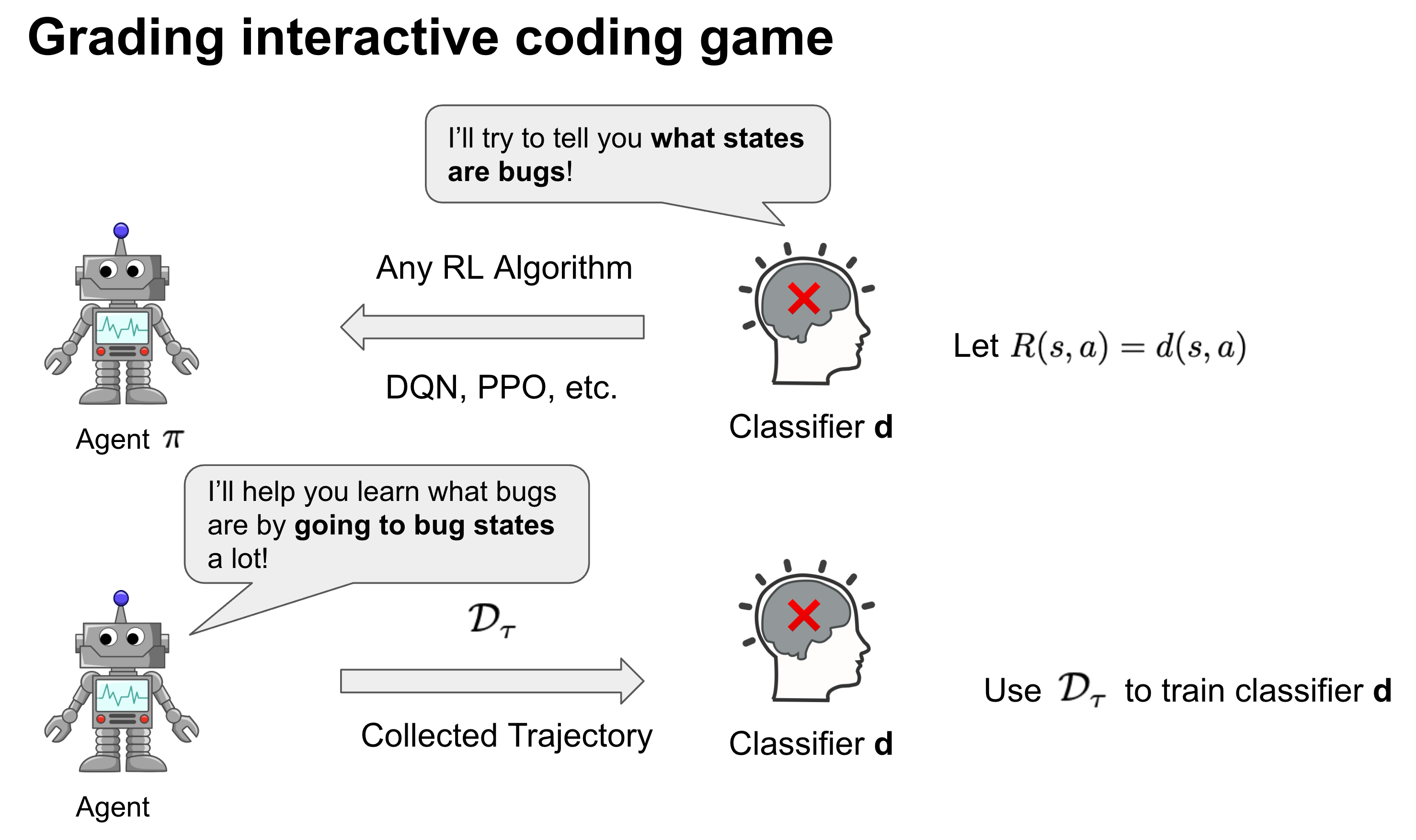 Authors: Allen Nie, Emma Brunskill, Chris Piech
Authors: Allen Nie, Emma Brunskill, Chris Piech
Contact: anie@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, computational education, collaborative training, markov decision process
The Value of Information When Deciding What to Learn
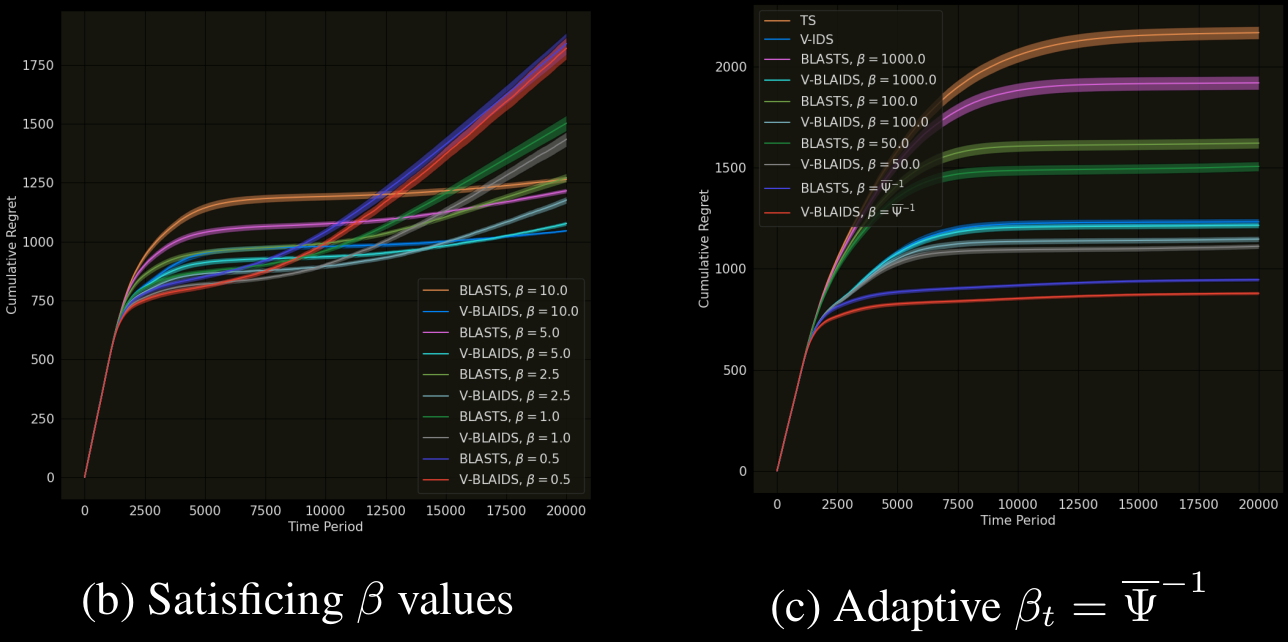 Authors: Dilip Arumugam, Benjamin Van Roy
Authors: Dilip Arumugam, Benjamin Van Roy
Contact: dilip@cs.stanford.edu
Links: Paper
Keywords: exploration, information theory, multi-armed bandits, reinforcement learning
Diversity Matters When Learning From Ensembles
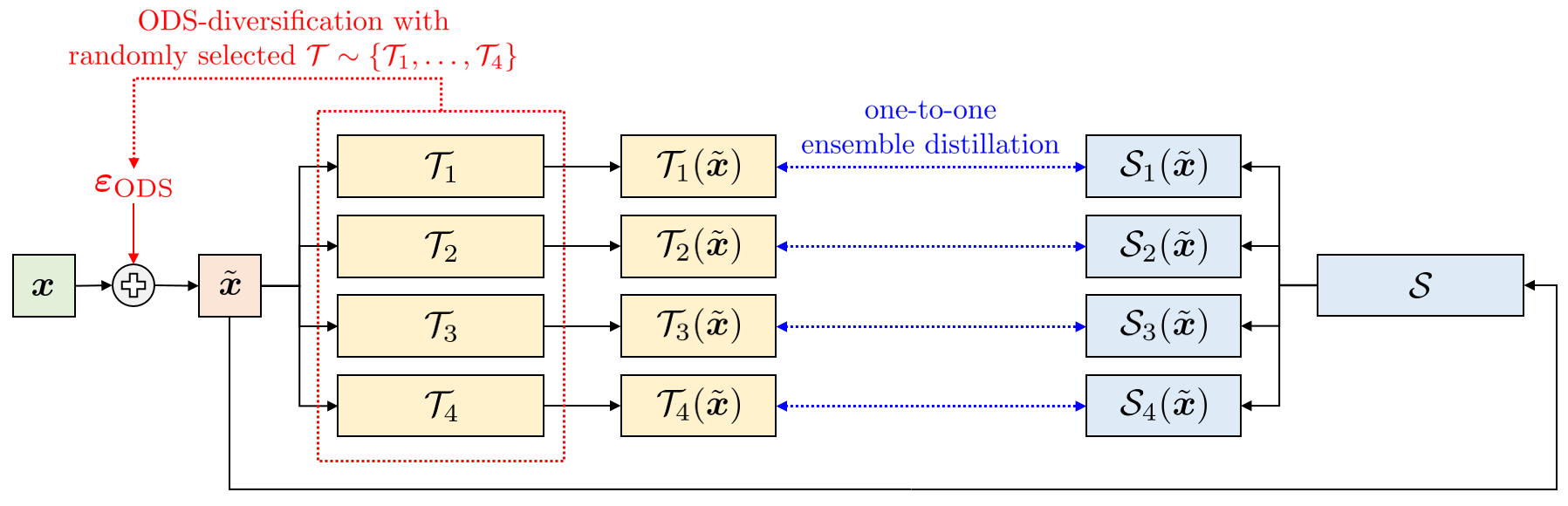 Authors: Giung Nam*, Jongmin Yoon*, Yoonho Lee, Juho Lee
Authors: Giung Nam*, Jongmin Yoon*, Yoonho Lee, Juho Lee
Contact: yoonho@cs.stanford.edu
Links: Paper | Website
Keywords: deep ensembles, knowledge distillation, calibration, output diversified sampling, batchensemble
Reinforcement Learning with State Observation Costs in Action-Contingent Noiselessly Observable Markov Decision Processes
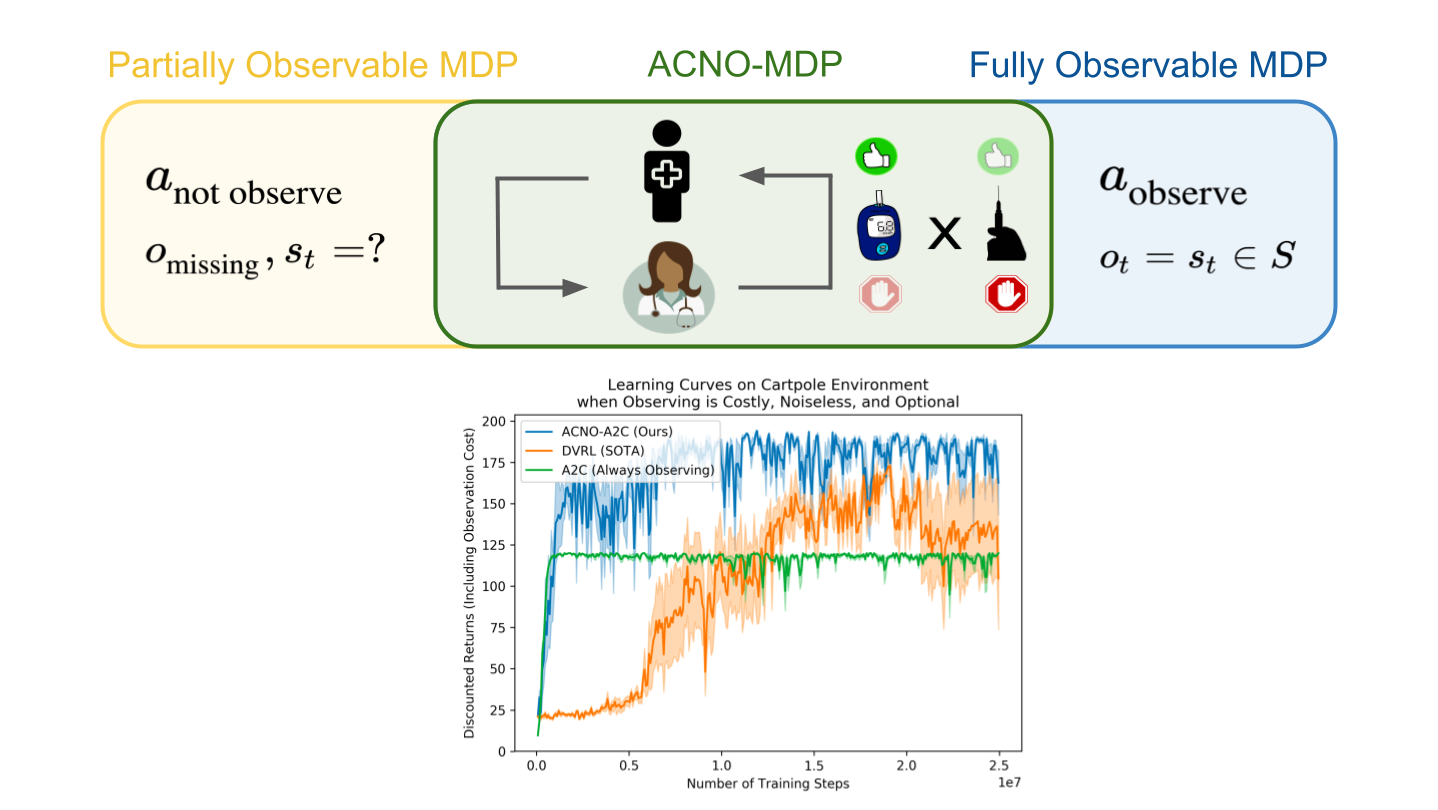 Authors: HyunJi Nam, Scott Fleming, Emma Brunskill
Authors: HyunJi Nam, Scott Fleming, Emma Brunskill
Contact: scottyf@stanford.edu
Links: Paper | Website
Keywords: reinforcement learning, observation cost, markov decision process, mdp, partially observable markov decision process, pomdp, probably approximately correct, pac, healthcare, health care
Meta-learning with an Adaptive Task Scheduler
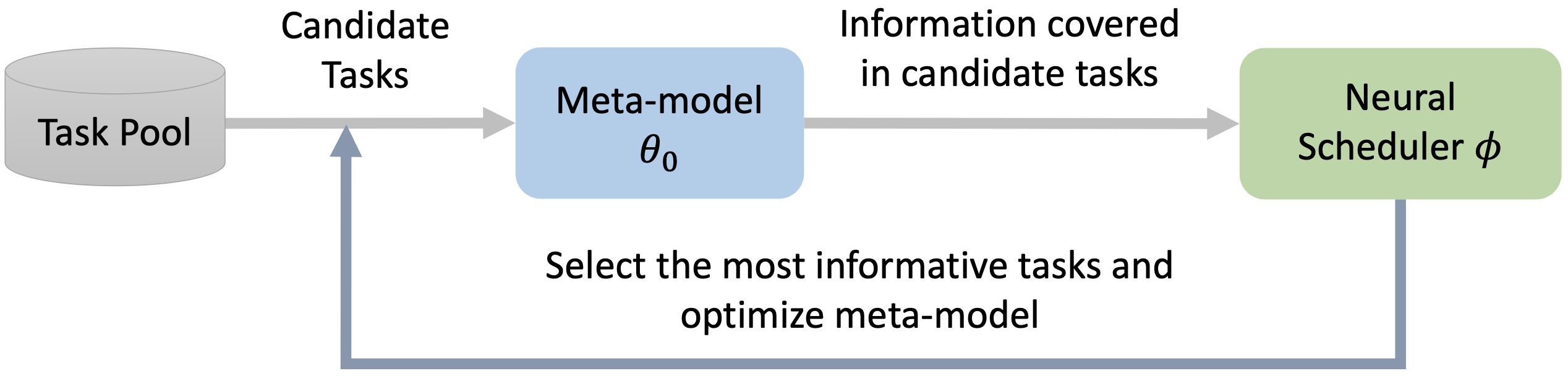 Authors: Huaxiu Yao, Yu Wang, Ying Wei, Peilin Zhao, Mehrdad Mahdavi, Defu Lian, Chelsea Finn
Authors: Huaxiu Yao, Yu Wang, Ying Wei, Peilin Zhao, Mehrdad Mahdavi, Defu Lian, Chelsea Finn
Contact: huaxiu@cs.stanford.edu
Links: Paper
Keywords: adaptive task scheduler, meta-learning, sampling
Spatial-Temporal Super-Resolution of Satellite Imagery via Conditional Pixel Synthesis
 Authors: Yutong He, Dingjie Wang, Nicholas Lai, William Zhang, Chenlin Meng, Marshall Burke, David B. Lobell, Stefano Ermon
Authors: Yutong He, Dingjie Wang, Nicholas Lai, William Zhang, Chenlin Meng, Marshall Burke, David B. Lobell, Stefano Ermon
Contact: kellyyhe@stanford.edu
Links: Paper | Video | Website
Keywords: remote sensing, super-resolution, generative models
Scatterbrain: Unifying Sparse and Low-rank Attention
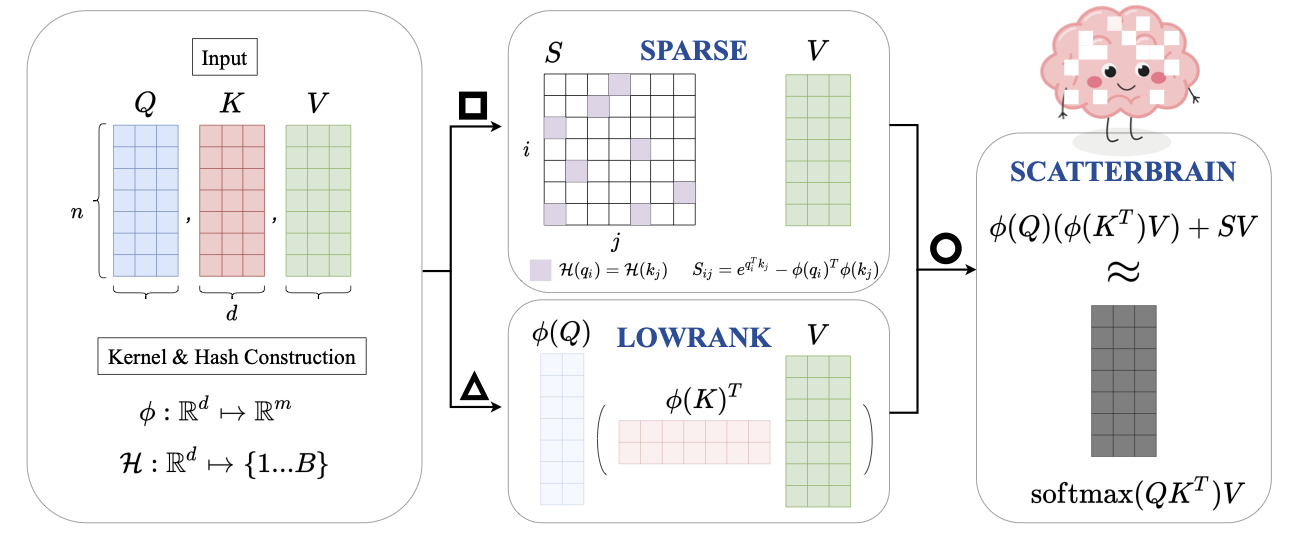 Authors: Beidi Chen*, Tri Dao*, Eric Winsor, Zhao Song, Atri Rudra, Christopher Ré.
Authors: Beidi Chen*, Tri Dao*, Eric Winsor, Zhao Song, Atri Rudra, Christopher Ré.
Contact: trid@stanford.edu
Links: Paper
Keywords: efficient attention, sparse, low-rank
BCD Nets: Scalable Variational Approaches for Bayesian Causal Discovery
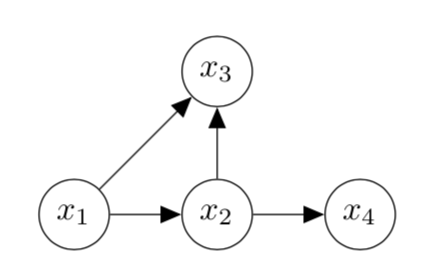 Authors: Chris Cundy, Aditya Grover, Stefano Ermon
Authors: Chris Cundy, Aditya Grover, Stefano Ermon
Contact: cundy@stanford.edu
Keywords: causal inference, variational inference
Calibrating Predictions to Decisions: A Novel Approach to Multi-Class Calibration
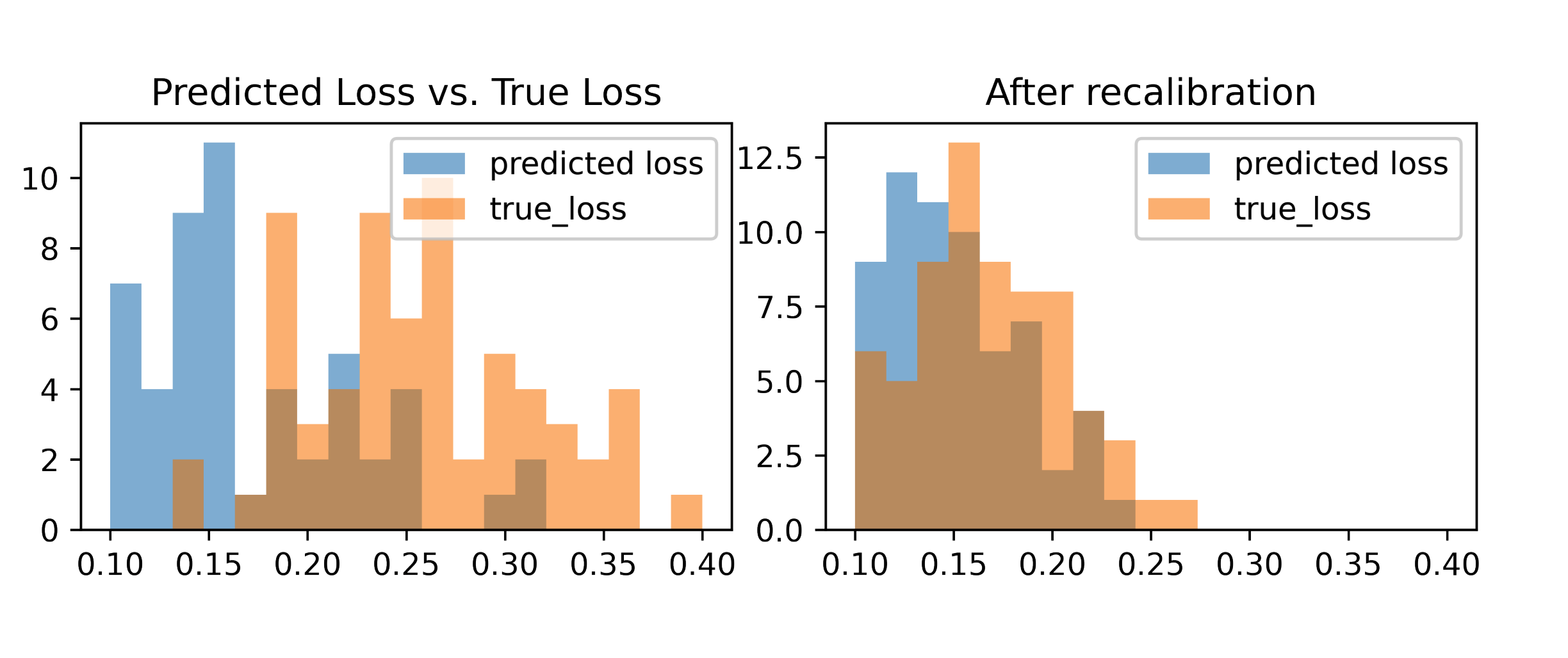 Authors: Shengjia Zhao, Michael P Kim, Roshni Sahoo, Tengyu Ma, Stefano Ermon
Authors: Shengjia Zhao, Michael P Kim, Roshni Sahoo, Tengyu Ma, Stefano Ermon
Contact: sjzhao@stanford.edu
Links: Paper
Keywords: calibration, decision making under uncertainty
Beyond Pinball Loss: Quantile Methods for Calibrated Uncertainty Quantification
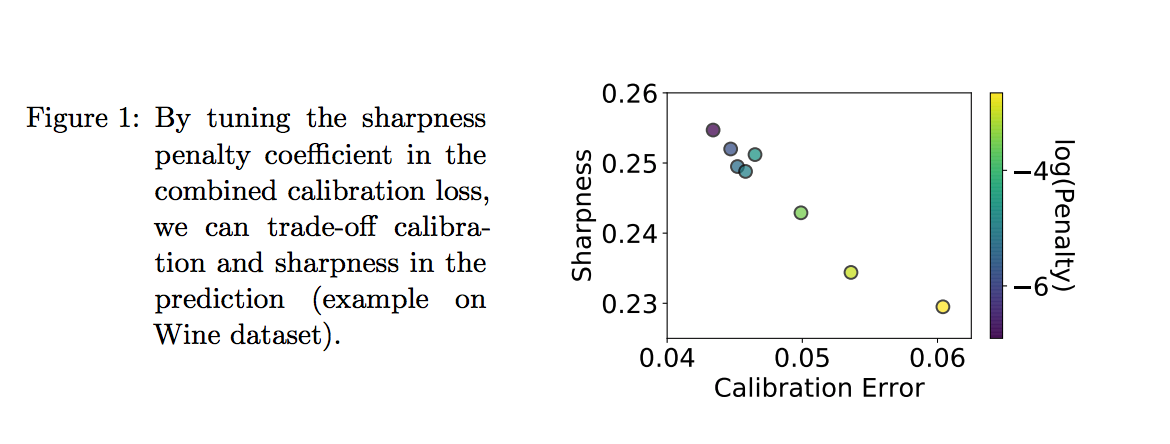 Authors: Youngseog Chung, Willie Neiswanger, Ian Char, Jeff Schneider
Authors: Youngseog Chung, Willie Neiswanger, Ian Char, Jeff Schneider
Contact: youngsec@andrew.cmu.edu, neiswanger@cs.stanford.edu
Links: Paper | Website
Keywords: uncertainty quantification, uq, quantile regression, pinball loss
Causal Abstractions of Neural Networks
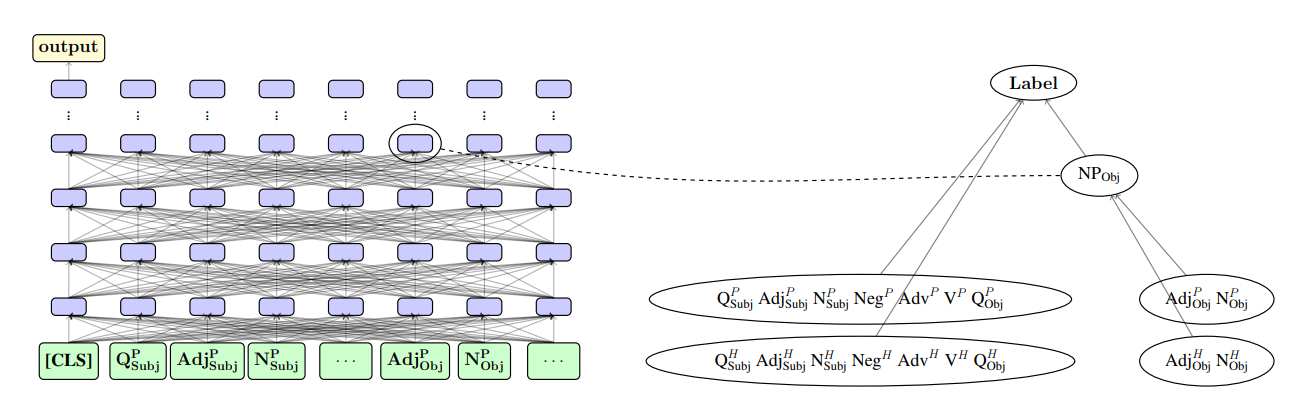 Authors: Atticus Geiger*, Hanson Lu*, Thomas Icard, Christopher Potts
Authors: Atticus Geiger*, Hanson Lu*, Thomas Icard, Christopher Potts
Contact: atticusg@stanford.edu
Links: Paper
Keywords: interpretability, analysis, nlp, causality
Generalized Shape Metrics on Neural Representations
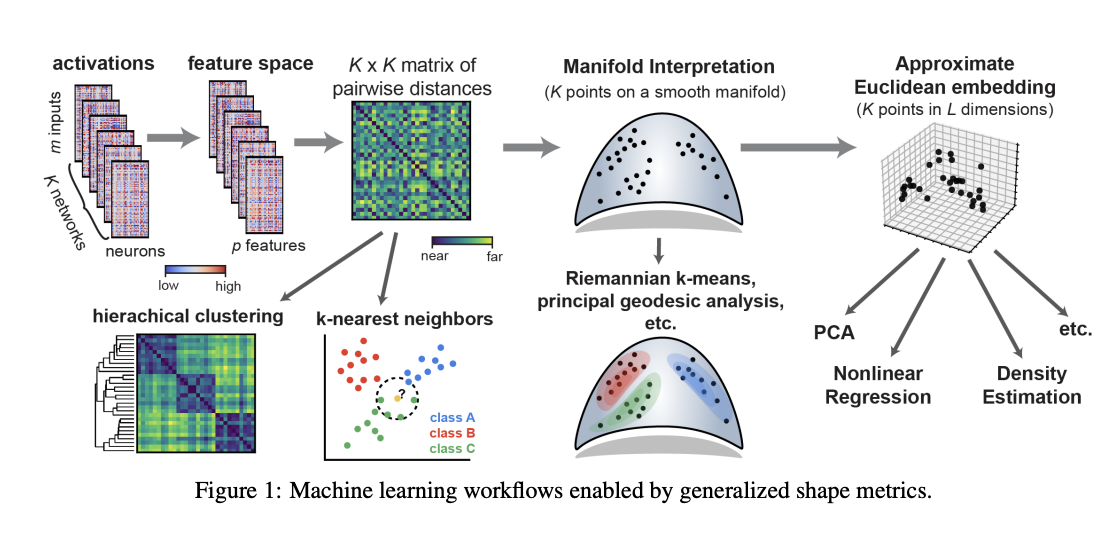 Authors: Alex H Williams, Erin Kunz, Simon Kornblith, Scott Linderman
Authors: Alex H Williams, Erin Kunz, Simon Kornblith, Scott Linderman
Contact: alex.h.willia@gmail.com
Keywords: representational similarity analysis, neural representations, shape analysis, metric space
D2C: Diffusion-Denoising Models for Few-shot Conditional Generation
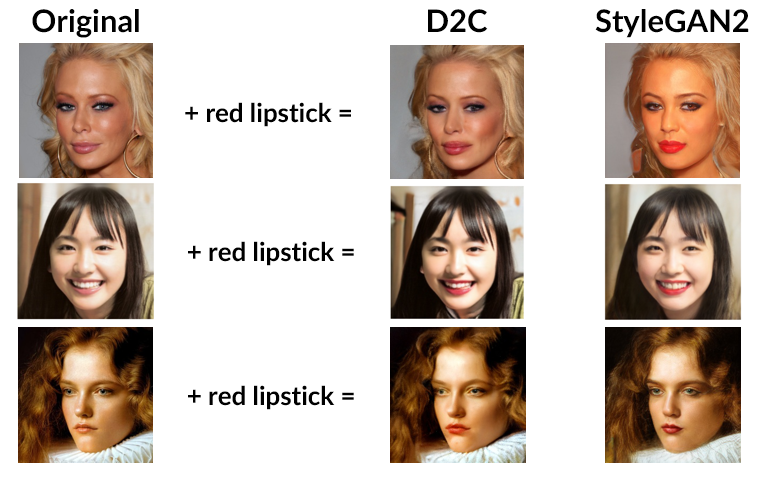 Authors: Abhishek Sinha*, Jiaming Song*, Chenlin Meng, Stefano Ermon
Authors: Abhishek Sinha*, Jiaming Song*, Chenlin Meng, Stefano Ermon
Contact: tsong@cs.stanford.edu
Links: Paper | Website
Keywords: generative modeling, contrastive learning, conditional generation
Combiner: Full Attention Transformer with Sparse COmputation Cost
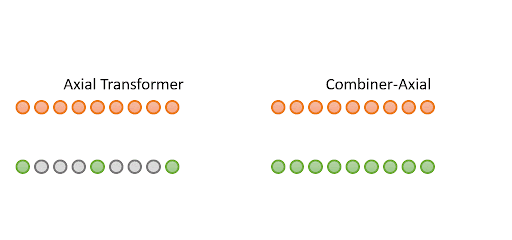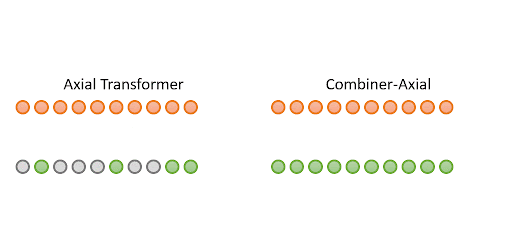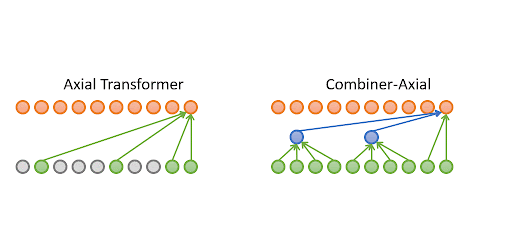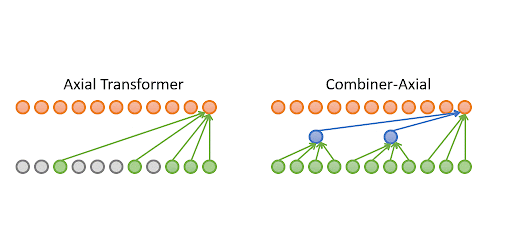 Authors: Hongyu Ren, Hanjun Dai, Zihang Dai, Mengjiao Yang, Jure Leskovec, Dale Schuurmans, Bo Dai
Authors: Hongyu Ren, Hanjun Dai, Zihang Dai, Mengjiao Yang, Jure Leskovec, Dale Schuurmans, Bo Dai
Contact: hyren@cs.stanford.edu
Links: Paper
Keywords: efficient transformer
Maximum Likelihood Training of Score-Based Diffusion Models
 Authors: Yang Song, Conor Durkan, Iain Murray, Stefano Ermon
Authors: Yang Song, Conor Durkan, Iain Murray, Stefano Ermon
Contact: yangsong@cs.stanford.edu
Award nominations: Spotlight presentation
Links: Paper
Keywords: score-based generative models, denoising score matching, diffusion models, maximum likelihood training
Contrastive Reinforcement Learning of Symbolic Reasoning Domains
 Authors: Gabriel Poesia, WenXin Dong, Noah Goodman
Authors: Gabriel Poesia, WenXin Dong, Noah Goodman
Contact: poesia@stanford.edu
Keywords: reinforcement learning, education, contrastive learning, symbolic reasoning
Equivariant Manifold Flows
 Authors: Isay Katsman, Aaron Lou, Derek Lim, Qingxuan Jiang, Ser Nam Lim, Christopher M. De Sa
Authors: Isay Katsman, Aaron Lou, Derek Lim, Qingxuan Jiang, Ser Nam Lim, Christopher M. De Sa
Contact: aaronlou@stanford.edu
Links: Paper | Website
Keywords: manifold, normalizing flow, equivariant, invariant
Lower Bounds on Metropolized Sampling Methods for Well-Conditioned Distributions
 Authors: Yin Tat Lee, Ruoqi Shen, Kevin Tian
Authors: Yin Tat Lee, Ruoqi Shen, Kevin Tian
Contact: kjtian@stanford.edu
Award nominations: Oral presentation
Links: Paper | Video
Keywords: sampling, lower bounds, langevin dynamics, hamiltonian monte carlo
List-Decodable Mean Estimation in Nearly-PCA Time
 Authors: Ilias Diakonikolas, Daniel M. Kane, Daniel Kongsgaard, Jerry Li, Kevin Tian
Authors: Ilias Diakonikolas, Daniel M. Kane, Daniel Kongsgaard, Jerry Li, Kevin Tian
Contact: kjtian@stanford.edu
Award nominations: Spotlight presentation
Links: Paper
Keywords: robust statistics, semidefinite programming, mixture models
Robust Regression Revisited: Acceleration and Improved Estimation Rates
 Authors: Arun Jambulapati, Jerry Li, Tselil Schramm, Kevin Tian
Authors: Arun Jambulapati, Jerry Li, Tselil Schramm, Kevin Tian
Contact: kjtian@stanford.edu
Links: Paper
Keywords: robust statistics, regression, generalized linear models, acceleration, sum of squares methods
Learning with User-Level Privacy
 Authors: Daniel Levy*, Ziteng Sun*, Kareem Amin, Satyen Kale, Alex Kulesza, Mehryar Mohri, Ananda Theertha Suresh
Authors: Daniel Levy*, Ziteng Sun*, Kareem Amin, Satyen Kale, Alex Kulesza, Mehryar Mohri, Ananda Theertha Suresh
Contact: danilevy@stanford.edu
Links: Paper
Keywords: differential privacy user-level
Adapting to Function Difficulty and Growth Conditions in Private Optimization
 Authors: Hilal Asi*, Daniel Levy*, John C. Duchi
Authors: Hilal Asi*, Daniel Levy*, John C. Duchi
Contact: asi@stanford.edu
Links: Paper
Keywords: differential privacy adaptivity optimization
Imitation with Neural Density Models
 Authors: Kuno Kim, Akshat Jindal, Yang Song, Jiaming Song, Yanan Sui, Stefano Ermon
Authors: Kuno Kim, Akshat Jindal, Yang Song, Jiaming Song, Yanan Sui, Stefano Ermon
Contact: khkim@cs.stanford.edu
Links: Paper
Keywords: rl; imitation learning; density estimation
Why Do Pretrained Language Models Help in Downstream Tasks? An Analysis of Head and Prompt Tuning
 Authors: Colin Wei, Sang Michael Xie, Tengyu Ma
Authors: Colin Wei, Sang Michael Xie, Tengyu Ma
Contact: colinwei@stanford.edu
Links: Paper
Keywords: nlp pretraining, theoretical analysis
Safe Reinforcement Learning by Imagining the Near Future
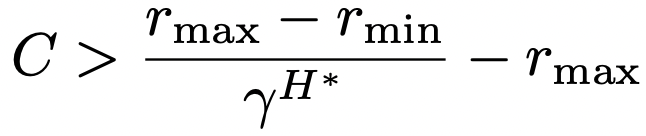 Authors: Garrett Thomas, Yuping Luo, Tengyu Ma
Authors: Garrett Thomas, Yuping Luo, Tengyu Ma
Contact: gwthomas@stanford.edu
Links: Paper
Keywords: safe exploration, model-based rl
Pseudo-Spherical Contrastive Divergence
 Authors: Lantao Yu, Jiaming Song, Yang Song, Stefano Ermon
Authors: Lantao Yu, Jiaming Song, Yang Song, Stefano Ermon
Contact: lantaoyu@cs.stanford.edu
Links: Paper
Keywords: deep generative models, energy-based models, proper scoring rules
IQ-Learn: Inverse soft-Q Learning for Imitation
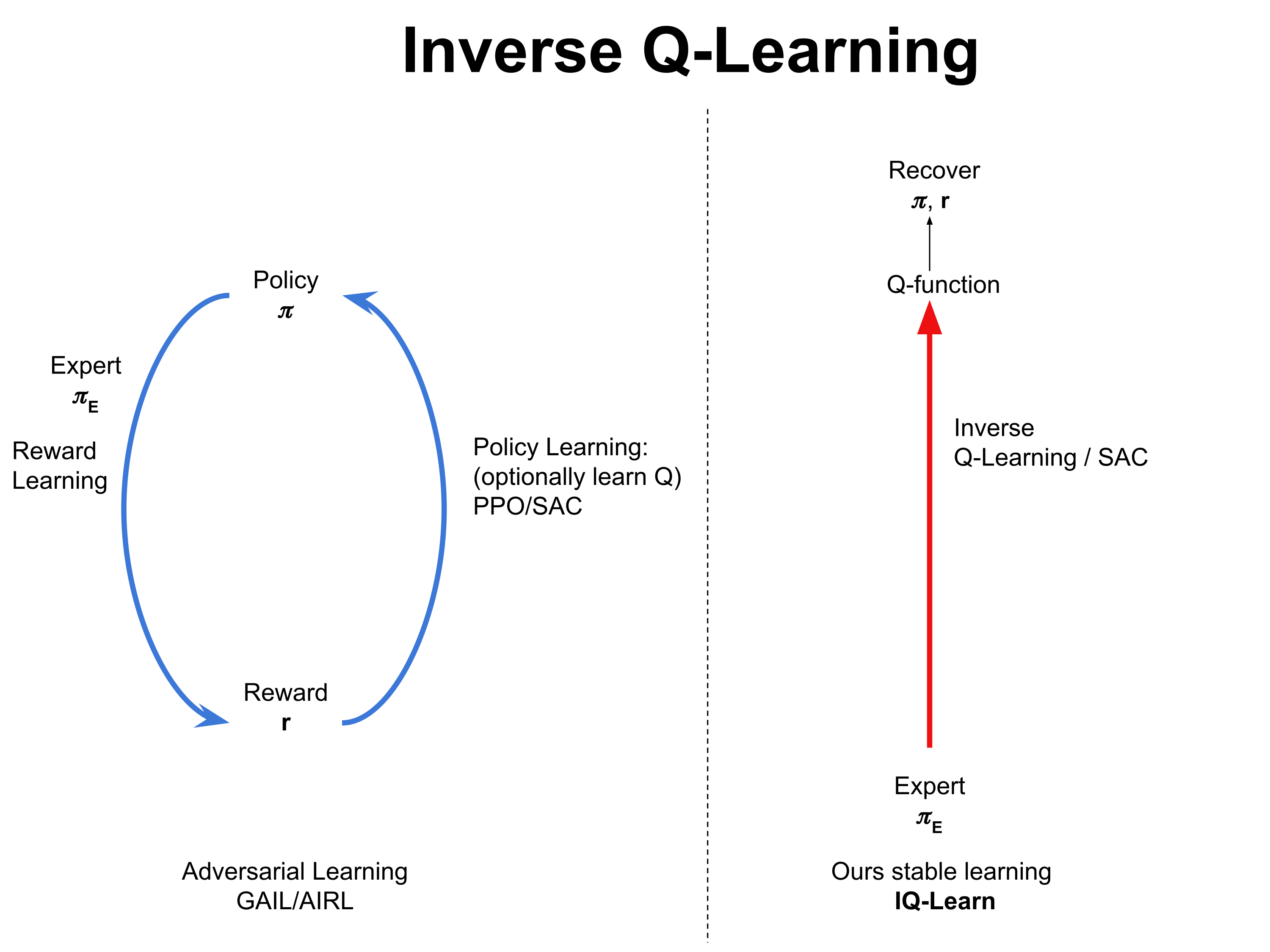 Authors: Divyansh Garg, Shuvam Chakraborty, Chris Cundy, Jiaming Song, Stefano Ermon
Authors: Divyansh Garg, Shuvam Chakraborty, Chris Cundy, Jiaming Song, Stefano Ermon
Contact: divgarg@stanford.edu
Award nominations: Spotlight
Links: Paper | Website
Keywords: reinforcement learning, imitation learning, inverse reinforcement learning, statistical learning, energy-based models
Intrinsic Dimension, Persistent Homology and Generalization in Neural Networks
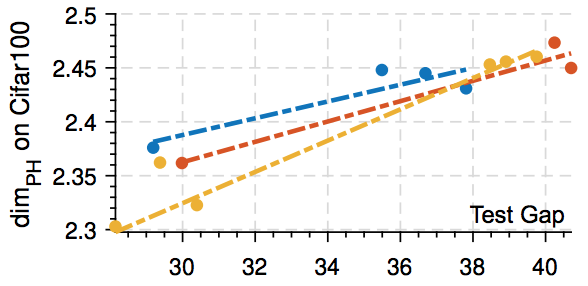 Authors: Tolga Birdal ~Tolga_Birdal3 , Aaron Lou, Leonidas Guibas, Umut Simsekli
Authors: Tolga Birdal ~Tolga_Birdal3 , Aaron Lou, Leonidas Guibas, Umut Simsekli
Contact: aaronlou@stanford.edu
Links: Paper | Website
Keywords: generalization, persistent homology, intrinsic dimension, deep networks
Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval
 Authors: Omar Khattab, Christopher Potts, Matei Zaharia
Authors: Omar Khattab, Christopher Potts, Matei Zaharia
Contact: okhattab@stanford.edu
Award nominations: Spotlight paper
Links: Paper | Blog Post
Keywords: neural retrieval, multi-hop question answering, claim verification, reasoning, colbert
Datasets and Benchmarks Track
- ReaSCAN: Compositional Reasoning in Language Grounding | Website by Zhengxuan Wu*, Elisa Kreiss*, Desmond Ong, Christopher Potts
- ATOM3D: Tasks on Molecules in Three Dimensions | Website by Raphael J.L. Townshend, Martin Vögele, Patricia Suriana, Alexander Derry, Alexander S. Powers, Yianni Laloudakis, Sidhika Balachandar, Bowen Jing, Brandon Anderson, Stephan Eismann, Risi Kondor, Russ B. Altman, Ron O. Dror
- Dynamic Environments with Deformable Objects | Video | Website by Rika Antonova, Peiyang Shi, Hang Yin, Zehang Weng, Danica Kragic
- Personalized Benchmarking with the Ludwig Benchmarking Toolkit | Website by Avanika Narayan, Piero Molino, Karan Goel, Willie Neiswanger, Christopher Ré
- SKM-TEA: A Dataset for Accelerated MRI Reconstruction with Dense Image Labels for Quantitative Clinical Evaluation | Website by Arjun D Desai, Andrew M Schmidt, Elka B Rubin, Christopher M Sandino, Marianne S Black, Valentina Mazzoli, Kathryn J Stevens, Robert Boutin, Christopher Ré, Garry E Gold, Brian A Hargreaves, Akshay S Chaudhari
- Are We Learning Yet? A Meta Review of Evaluation Failures Across Machine Learning by Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, Ludwig Schmidt
- DABS: a Domain-Agnostic Benchmark for Self-Supervised Learning | Website by Alex Tamkin, Vincent Liu, Rongfei Lu, Daniel Fein, Colin Schultz, Noah Goodman
- SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning | Video | Website by Christopher Yeh, Chenlin Meng, Sherrie Wang, Anne Driscoll, Erik Rozi, Patrick Liu, Jihyeon Lee, Marshall Burke, David Lobell, Stefano Ermon
- OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs | Website by Weihua Hu
Workshops
This year, multiple members of the SAIL community are also involved in great workshops that will take place on Dec 13-14. We hope you’ll check them out!
Machine Learning for Structural Biology Workshop (Dec 13)

Organizers: Namrata Anand, Bonnie Berger, Wouter Boomsma, Erika DeBenedictis, Stephan Eismann, John Ingraham, Sergey Ovchinnikov, Roshan Rao, Raphael Townshend and Ellen Zhong
Controllable Generative Modeling in Language and Vision (CtrlGen Workshop) (Dec 13)

Organizers: Steven Y. Feng, Drew A. Hudson, Anusha Balakrishnan, Varun Gangal, Dongyeop Kang, Tatsunori Hashimoto and Joel Tetreault
DistShift Workshop (Dec 13)

Organizers: Shiori Sagawa, Pang Wei Koh, Fanny Yang, Hongseok Namkoong, Jiashi Feng, Kate Saenko, Percy Liang, Sarah Bird and Sergey Levine
Data-centric AI Workshop (Dec 14)

Organizers: Andrew Ng, Lora Aroyo, Cody Coleman, Greg Diamos, Vijay Janapa Reddi, Joaquin Vanschoren,Carole-Jean Wu and Sharon Zhou
Physical Reasoning and Inductive Biases for the Real World Workshop (Dec 14)

Organizers: Krishna Murthy Jatavallabhula, Rika Antonova, Kevin Smith, Hsiao-Yu (Fish) Tung, Florian Shkurti, Jeannette Bohg and Josh Tenenbaum
Workshop Papers
- How Does Contrastive Pre-training Connect Disparate Domains? by Kendrick Shen*, Robbie Jones*, Ananya Kumar*, Sang Michael Xie*, Percy Liang (DistShift Workshop)
- Optimal Representations for Covariate Shifts by Yann Dubois, Yangjun Ruan, Chris J. Maddison (DistShift Workshop)
- Correct-N-Contrast: a Contrastive Approach for Improving Robustness to Spurious Correlations by Michael Zhang, Nimit S. Sohoni, Hongyang R. Zhang, Chelsea Finn, Christopher Ré (DistShift Workshop)
- Extending the WILDS Benchmark for Unsupervised Adaptation by Shiori Sagawa*, Pang Wei Koh*, Tony Lee*, Irena Gao*, Sang Michael Xie, Kendrick Shen, Ananya Kumar, Weihua Hu, Michihiro Yasunaga, Henrik Marklund, Sara Beery, Etienne David, Ian Stavness, Wei Guo, Jure Leskovec, Kate Saenko, Tatsunori Hashimoto, Sergey Levine, Chelsea Finn, Percy Liang (DistShift Workshop)
- Calibrated Ensembles: A Simple Way to Mitigate ID-OOD Accuracy Tradeoffs by Ananya Kumar, Aditi Raghunathan, Tengyu Ma, Percy Liang (DistShift Workshop)
- Sharp Bounds for Federated Averaging (Local SGD) and Continuous Perspective by Margalit Glasgow*, Honglin Yuan*, Tengyu Ma (New Frontiers in Federated Learning)
- What Matters in Learning from Offline Human Demonstrations for Robot Manipulation | Blog Post | Video | Website by Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, Roberto Martín-Martín (Offline Reinforcement Learning Workshop)
- An Algorithmic Theory of Metacognition in Minds and Machines | Blog Post by Rylan Schaeffer (Metacognition in the Age of AI: Challenges and Opportunities)
- Beyond Ads: Sequential Decision-Making Algorithms in Public Policy by Peter Henderson, Ben Chugg, Brandon Anderson, Daniel E. Ho (Workshop on Causal Inference Challenges in Sequential Decision Making)
- Tracking Urbanization in Developing Regions withRemote Sensing Spatial-Temporal Super-Resolution by Yutong He*, William Zhang*, Chenlin Meng, Marshall Burke, David B. Lobell, Stefano Ermon (Workshop on Machine Learning for the Developing World (ML4D))
- Likelihood-free Density Ratio Acquisition Functions are not Equivalent to Expected Improvements by Jiaming Song, Stefano Ermon (Bayesian Deep Learning Workshop)
- Exploiting Proximity Search and Easy Examples to Select Rare Events by Daniel Kang, Alex Derhacobian, Kaoru Tsuji, Trevor Hebert, Peter Bailis, Tadashi Fukami, Tatsunori Hashimoto, Yi Sun, Matei Zaharia (Data Centric AI workshop)
We look forward to seeing you at NeurIPS 2021!